练习(续)
查询同学的每门课程成绩,及同学的个人信息
1.确定要参与查询的表
学生表,课程表,成绩表
2.取笛卡尔积

MySQL在10ms之内就把这个查询执行完了
显示这么慢的原因并不是MYSQL执行有什么问题,也不是SQL语句的编写有什么问题,而是CMD本身的显示问题
也可以通过表结构来查看连接条件
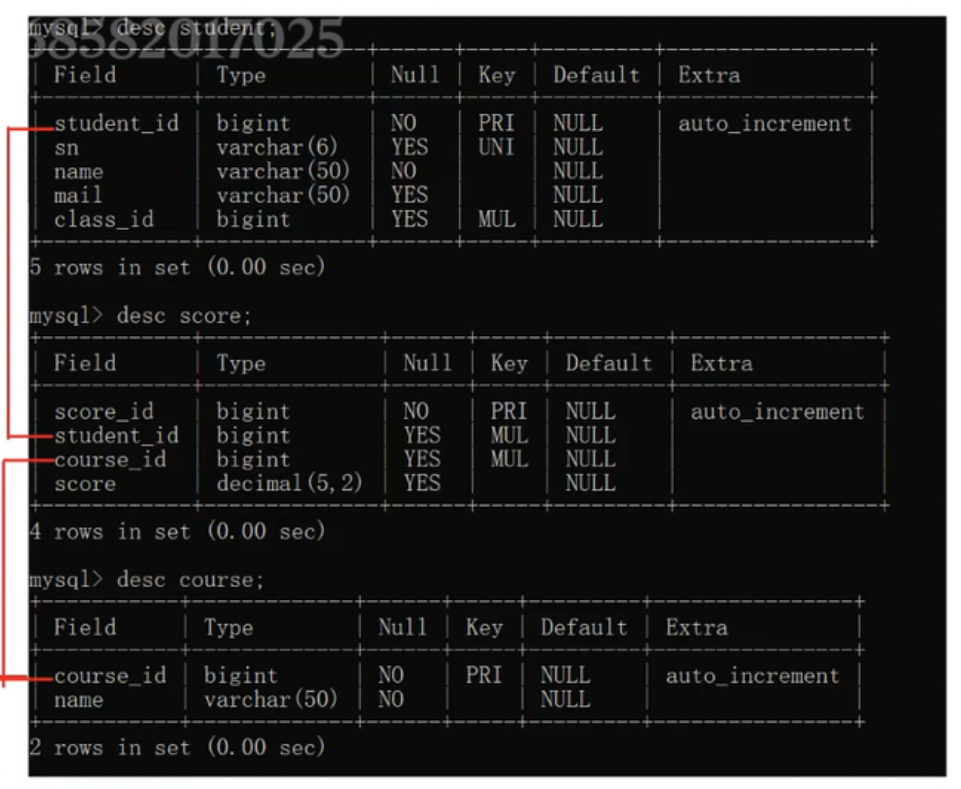
student.student_id=score.student_id
course.course_id=score.course_id

4.确定查询过滤条件where
不需要
5.精简查询字段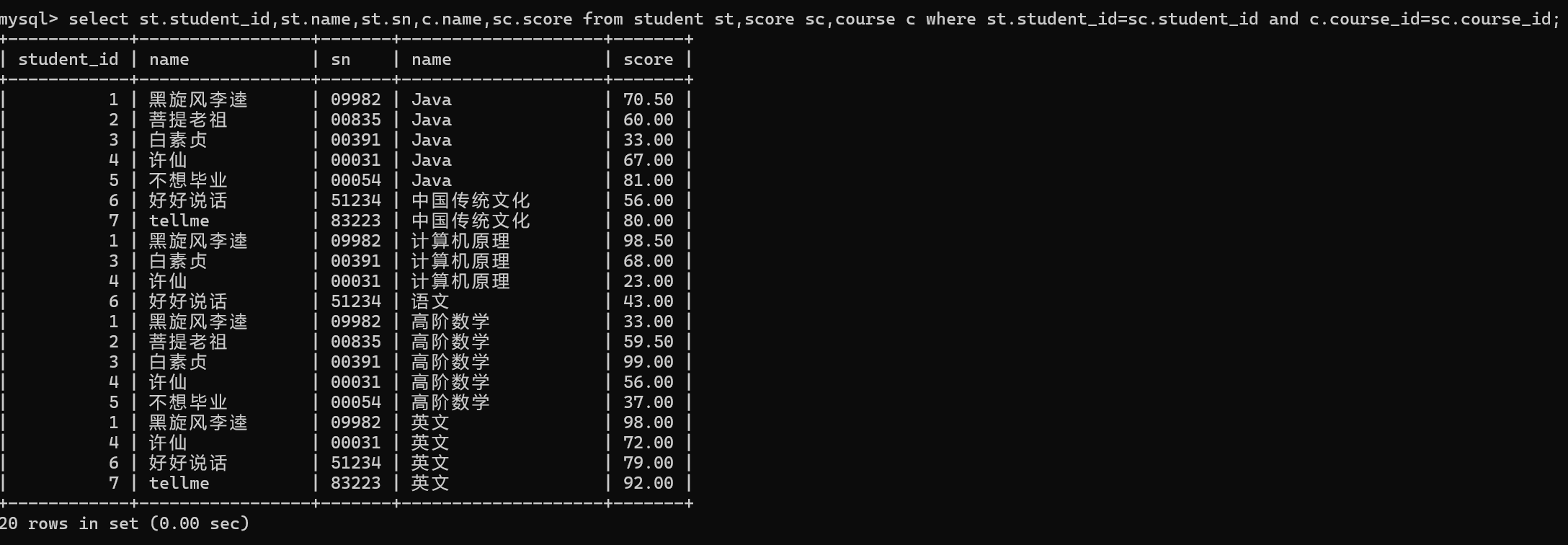
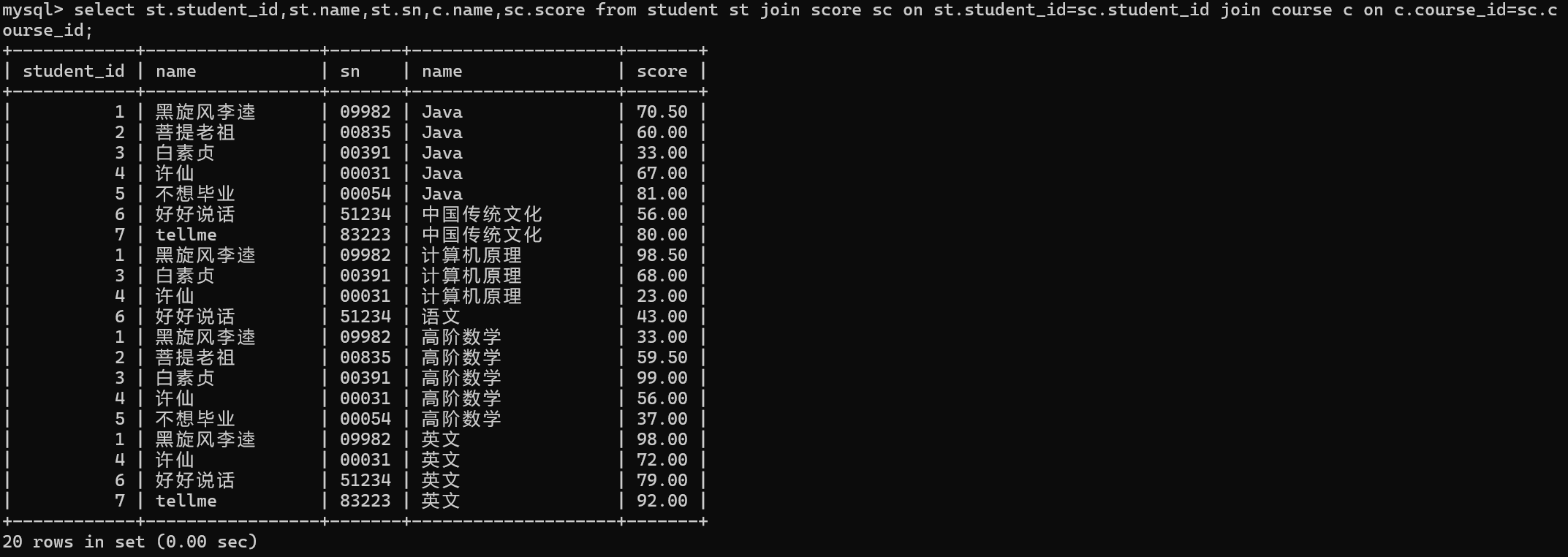
也可以使用过join on的方式来查询
外连接
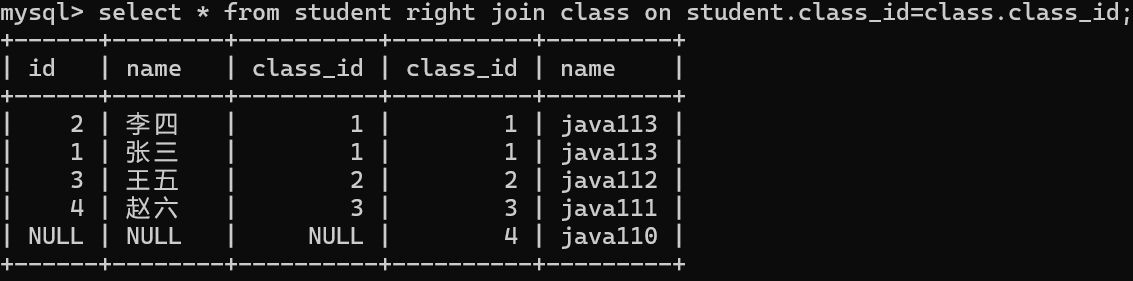
右连接
是以join右边的表为基准,这个表中的数据会全部显示出来,左边的表没有与之匹配的记录全部分NULL去填充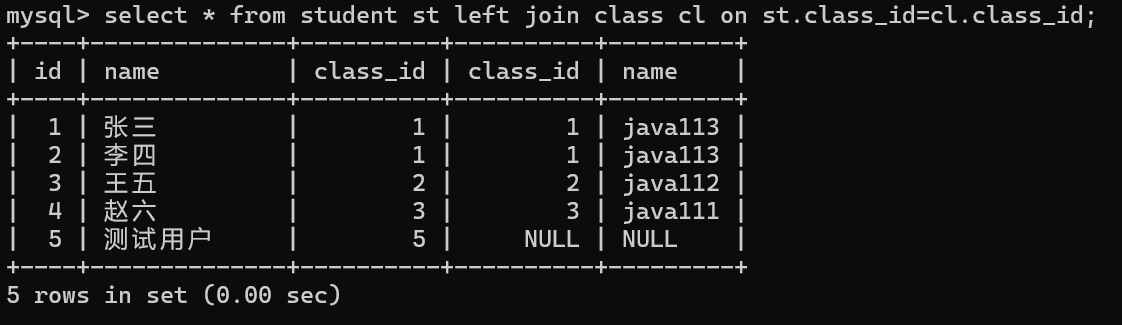
此时student是基准表,数据会全部显示,没有基准匹配的记录,显示为null
查询那位没有考试成绩
1.在同学表中有记录
2.在分数表中没有该同学的记录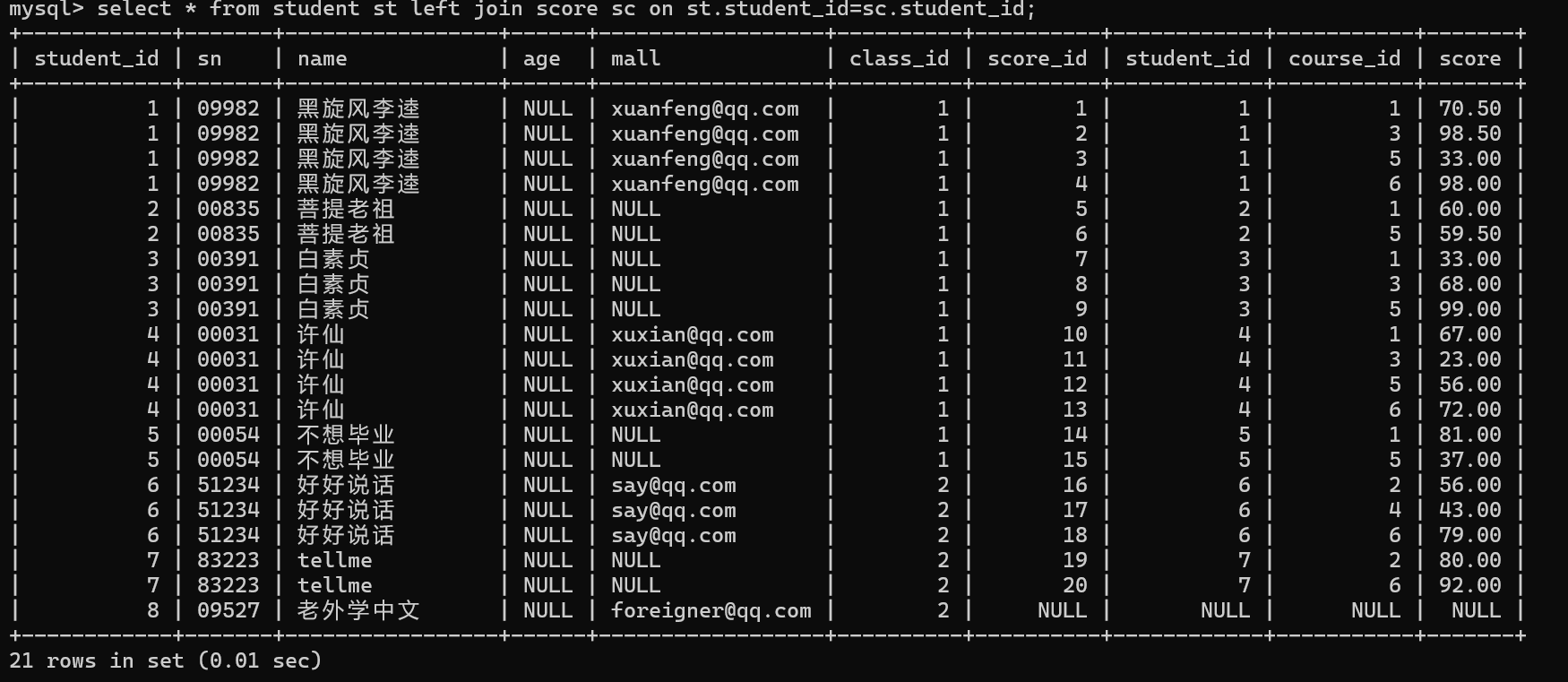

MYSQL不支持全外连接FULL JOIN
自连接
自己与自己进行表连接
可以把行转化为列,在查询的时候可以使用where条件进行过滤也就是说可以实现行与行之间的比较功能
显示所有"计算机原理"成绩比"java"成绩高的成绩信息
1.确定涉及的表
课程表,成绩表
2.取笛卡尔积

两个表名重复了,可以为每个表起别名

确定过滤条件

要么是s1表中的course_id=3并且s2表中的course_id=1;

加入最后的条件

子查询
也叫嵌套查询
子查询是把一条SQL的查询结果,当做另一条SQL的查询条件,可以嵌套很多很多层
由于嵌套的层级没有固定限制,如果多层嵌套是不可控的
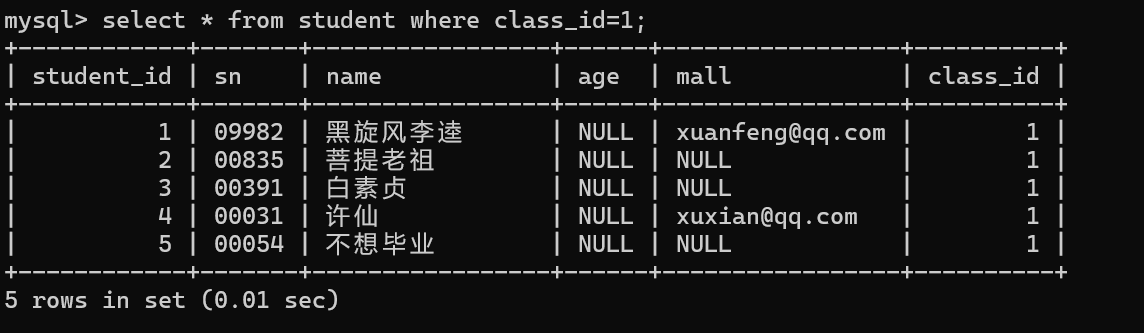
查询与"不想毕业"同学的同班同学
1.参与查询的表
持有一个学生表
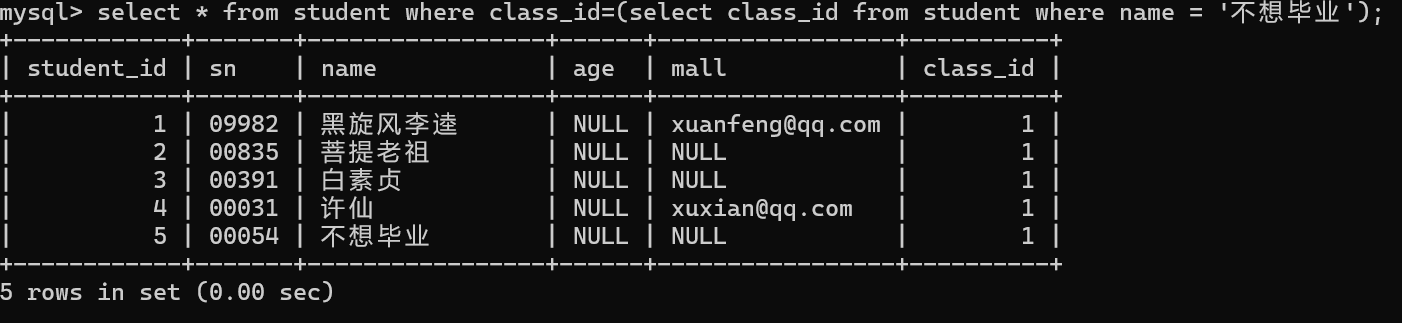
2.先查出不想毕业这位同学的班级编号
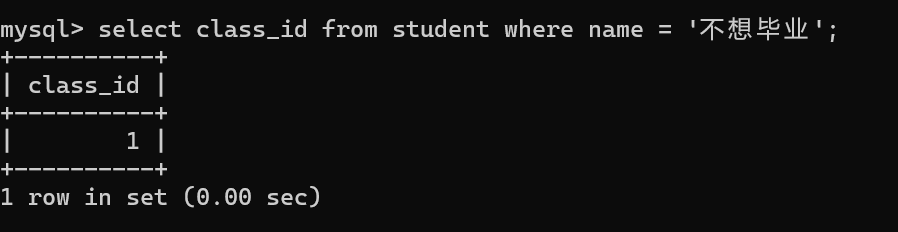
3.查出同班同学
通过子查询解决


单行子查询
返回一行记录的子查询,返回的是一个对象
多行子查询
返回多行记录的子查询,返回的是一个集合,集合中包含多个对象
语法:select * from table1 where table.id IN (select id from table2 where xxx=...)
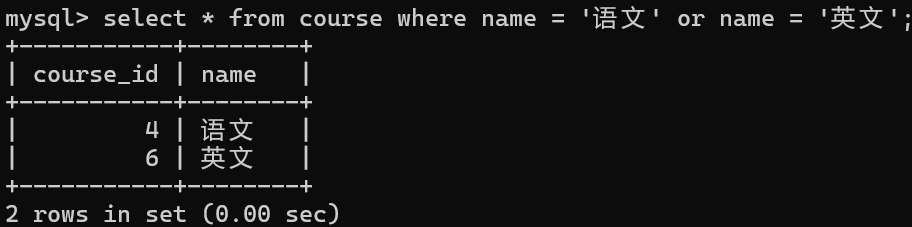
查询"语文"或"英文"课程的成绩信息
1.涉及哪些表
课程表,成绩表
2.在课程表中获取"语文"和"英文"课程的编号
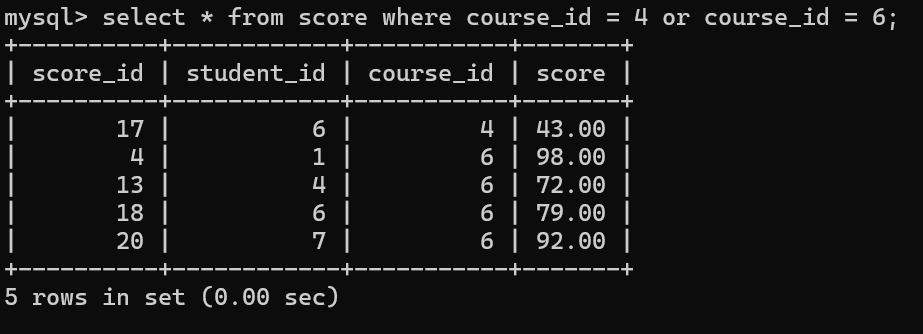
3.根据课程id,查对应分数
4.把以上分布查询的SQL拼装起来,变成子查询
多列包含(多列查询)
插入两条数据

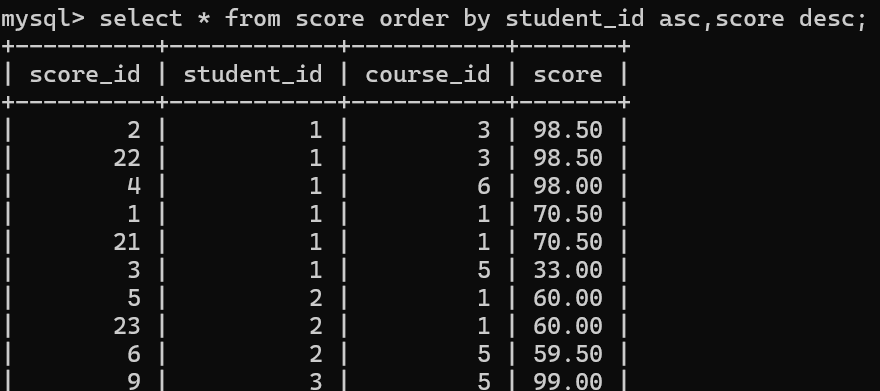
查询重复的分数
可以使用分组查询的方式
同一个学生,同一门课程,同样的成绩,按这三个列同时去分组
分组之后在having子句中,用count(*)判断分组中的记录数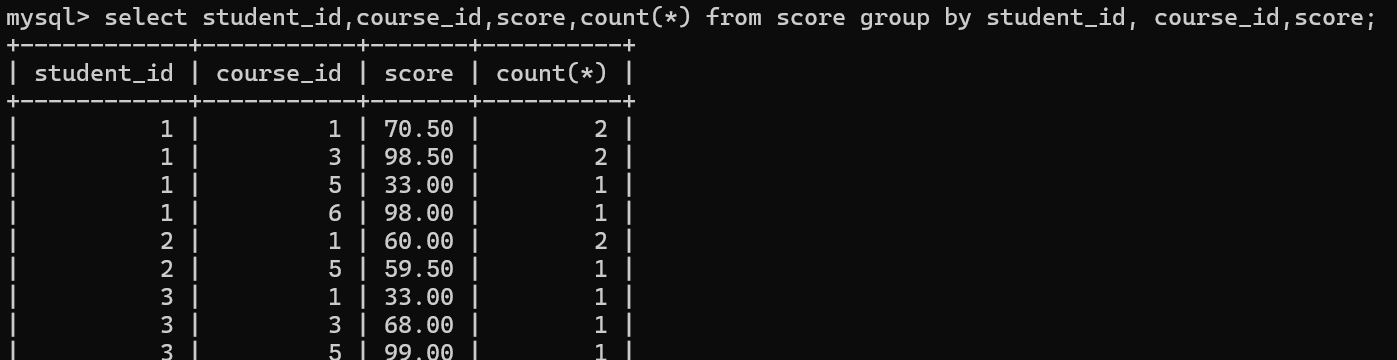

通过内层查询来确定要查询的记录,再通过外查询来查找相关的信息
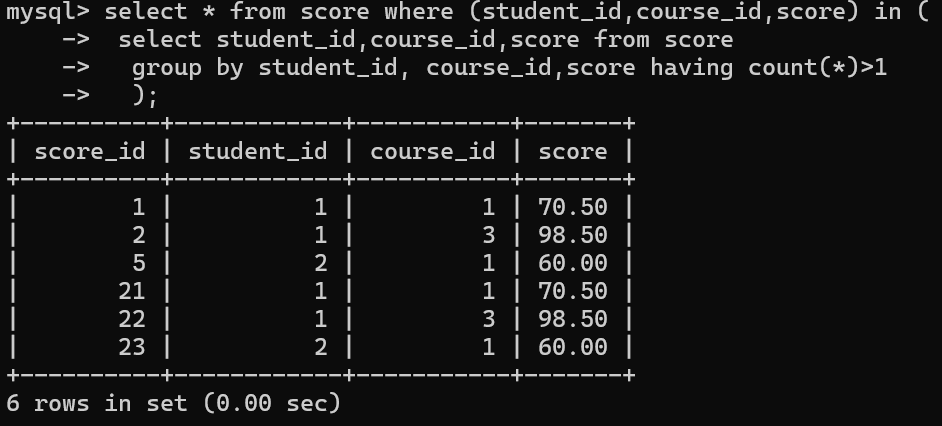
外层条件中的字段查询的字段条件,与内层查询中的结果,一一做比较,如果相等则满足条件,其中只要有一个不相等则不满足条件
NOT EXISTS
语法:select * from 表名 where exists (select * from 表名1);
exists后面括号中的查询语句,如果有结果返回,则执行外层的查询,如果返回的是一个空结果集,则不执行外层的查询
当内层结果集存在,会执行外层结果
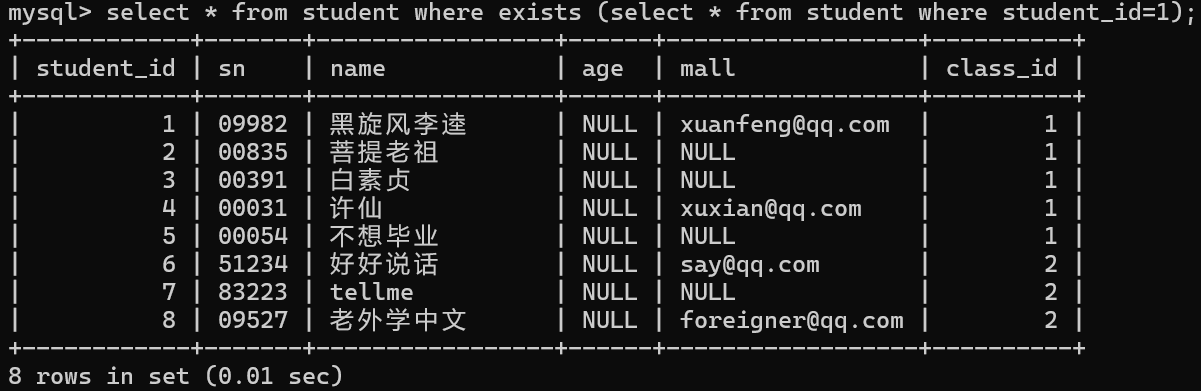
当内层返回的是空结果集
外层也不会再去执行 exists相当于if语句的判断条件,有结果返回true没有结果集就返回false+
exists相当于if语句的判断条件,有结果返回true没有结果集就返回false+
在from字句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当作临时表使用。
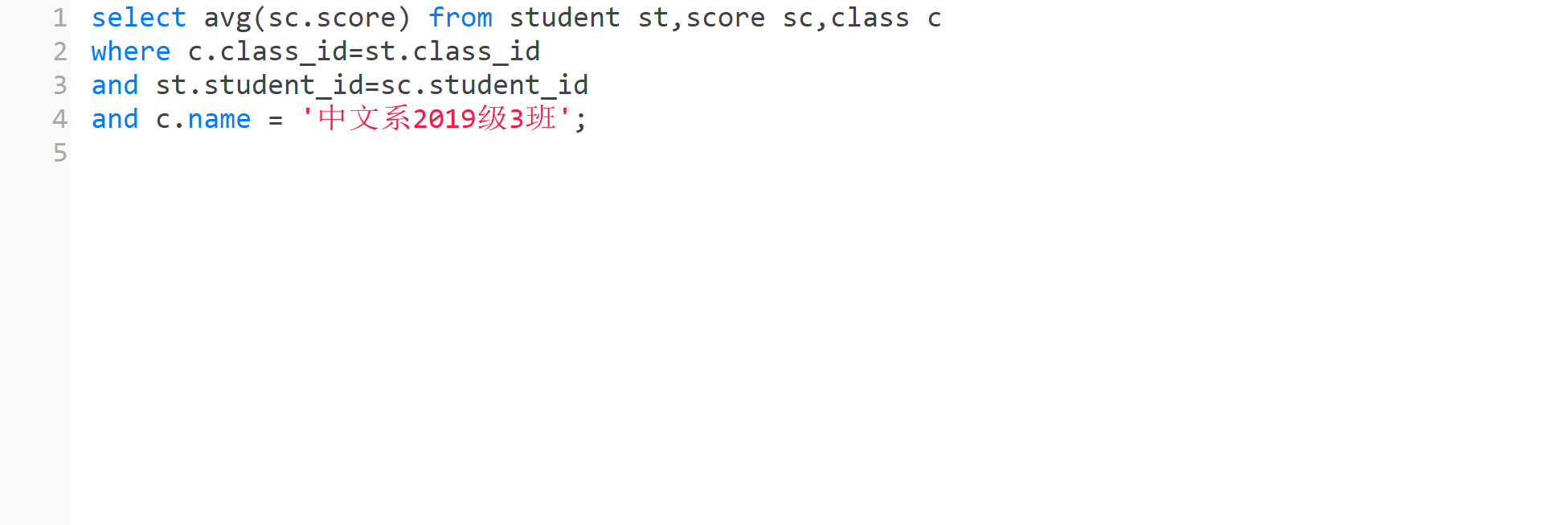
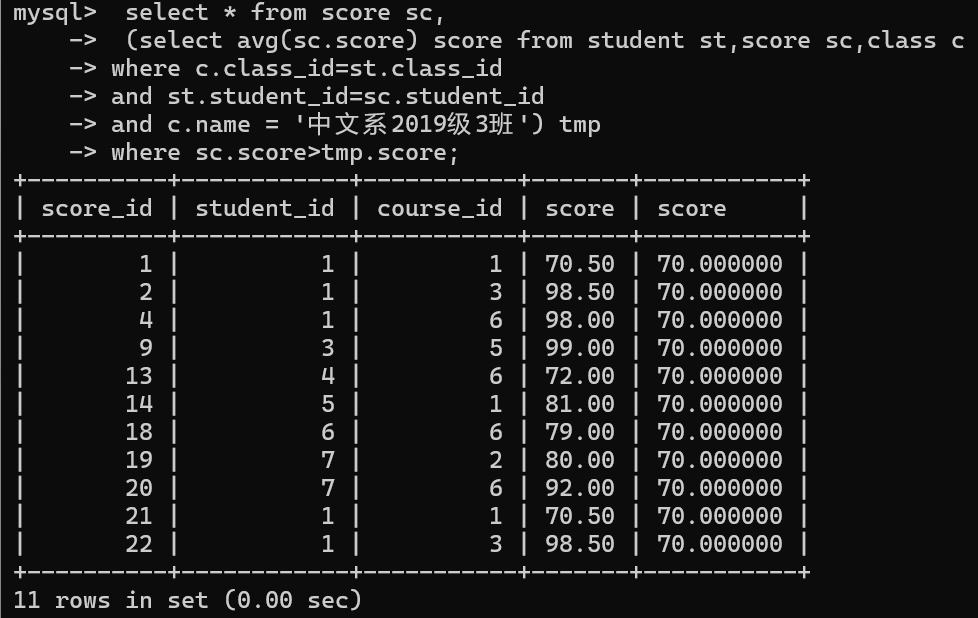
查询所有比"中文系2019级3班"平均分高的成绩信息
1.确定涉及的表
成绩表,班级表
2.再用表中学生的真实成绩和以上平均分作比较

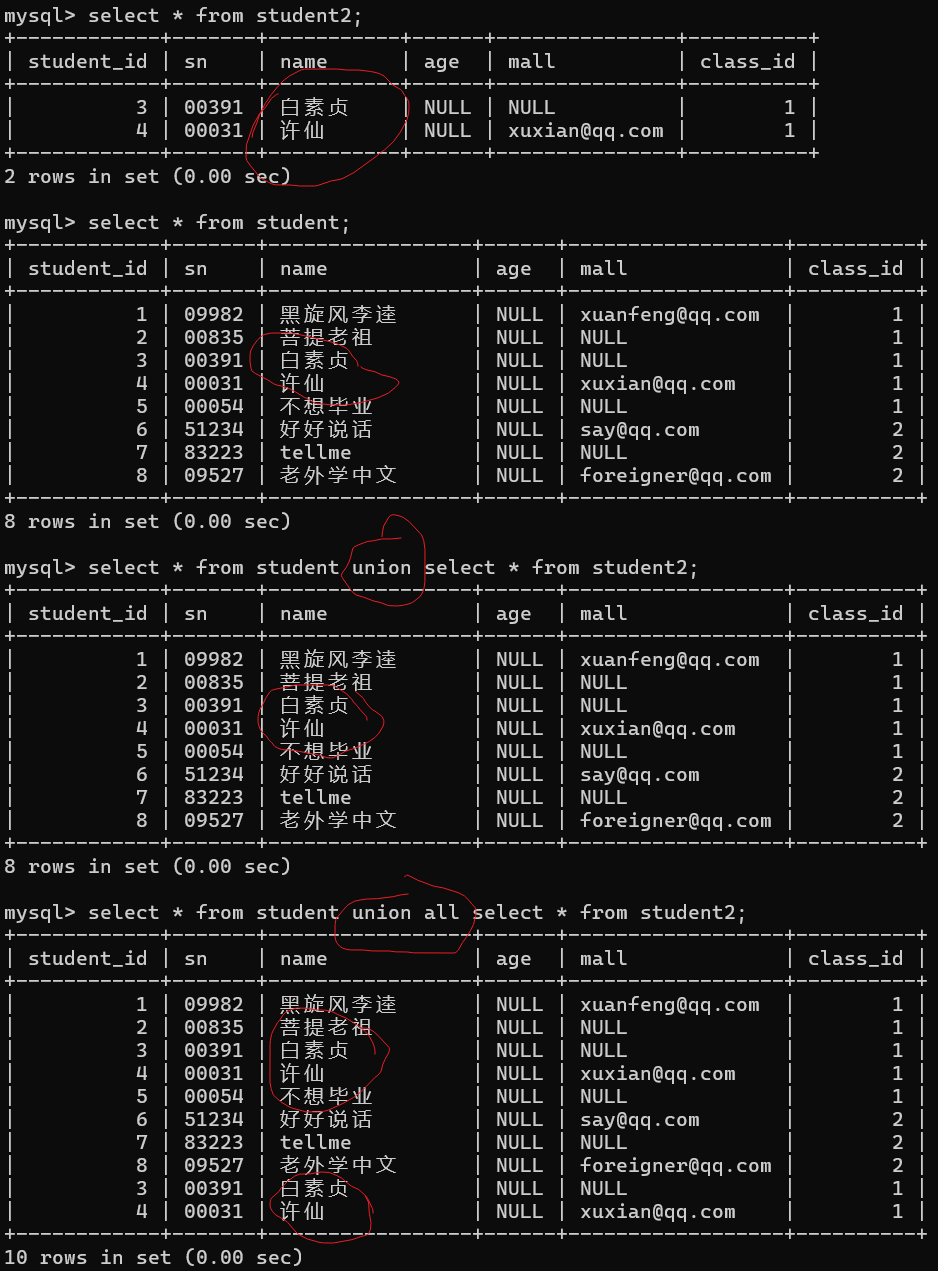
 合并查询
合并查询
作用:合并多个查询结果到一个结果集中
union ,union all
可以使用union把结果集合并在一起

在单表中使用or去连接不同的查询条件
在多表中,就没有办法用or,如果最终的结果是从多个表中获取到的,必须用到union合并
用like可以快速复制一张表结构

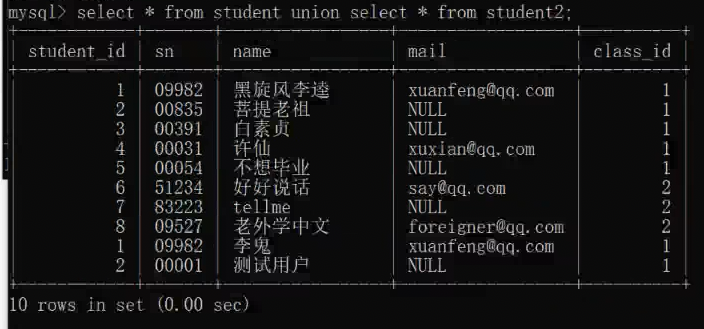
通过union把两张表中的数据显示在一个结果表中
列名不匹配返回的结果集是错误的结果集,这个结果集是没有意义的,需要人工去规避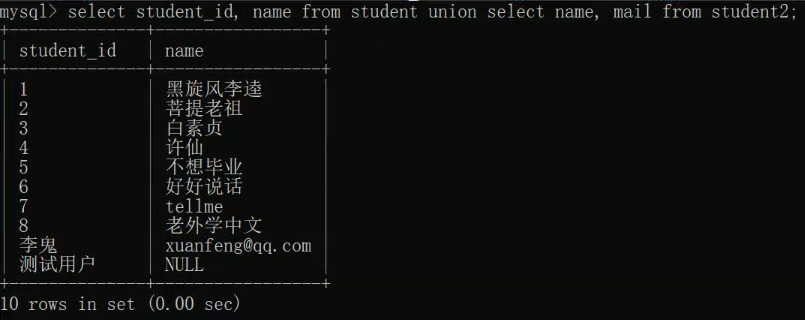
union
该操作会自动去掉结果集中的重复行
union all
该操作不会去掉结果集的重复行