论文地址:2106.09685 LoRA: Low-Rank Adaptation of Large Language Models
本笔记的目的不是完全对论文进行解释,而是重在理解LoRA的思想。
目录
1.核心思想
核心假设: 大模型适配时的权重更新矩阵具有低内在秩,无需全秩更新。
实现方式: 冻结预训练权重,注入低秩矩阵
,权重更新为
,前向传播为
。
初始化: 随机高斯初始化,
初始化为
,训练初
;用
缩放输出,稳定超参。
推理优势: 可将与
合并,无额外推理延迟。
2.关键优势
参数极省 :GPT-3 175B 场景下,可训练参数减少1 万倍 ,显存占用降3 倍。
训练高效:无需计算冻结参数梯度,训练吞吐量提升约 25%,硬件门槛降低。
部署灵活:共享预训练模型,仅切换小尺寸 LoRA 权重即可快速切任务。
效果等价:在 RoBERTa、DeBERTa、GPT-2、GPT-3 上,效果持平 / 优于全量微调。
兼容性强:可与 Prefix Tuning 等方法结合。
3.主体架构
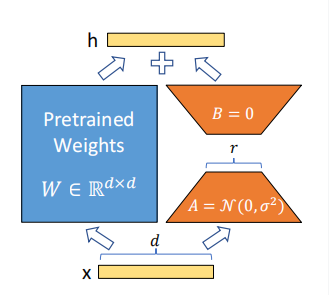
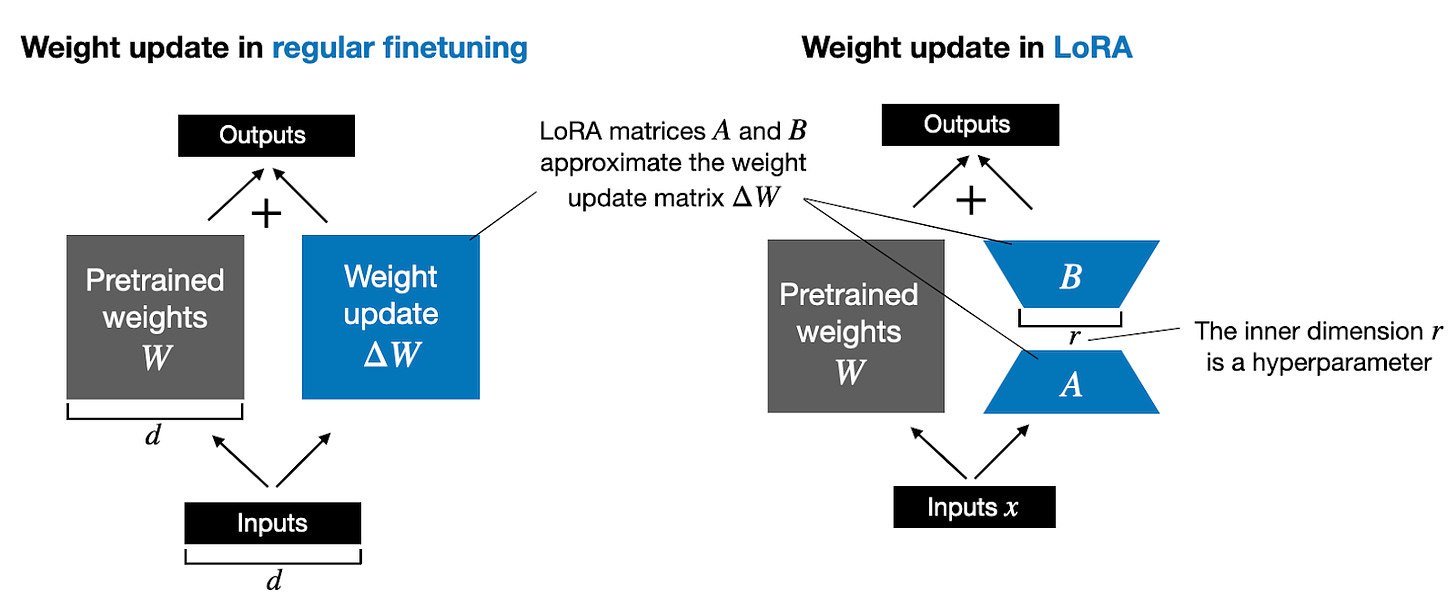
以上是LoRA结构的示意图,左侧为冻结参数,右侧为可训练的LoRA参数。
从结构上看,LoRA 并不是在原有大模型之外重新搭建一个完整的小模型,而是在原有线性层旁路引入一个低秩更新分支。对于原始线性变换
,LoRA 将其改写为
其中
如果从深度学习网络的一般训练原理来看,LoRA 与普通网络训练在流程上并没有本质区别:同样是输入样本、前向传播计算输出、根据损失进行反向传播,再通过梯度更新参数。
不同之处在于,传统全量微调会更新模型中的大部分甚至全部参数,而 LoRA 只允许误差梯度流向新增的低秩矩阵A与B,预训练权重仅参与前向计算,不再被更新。
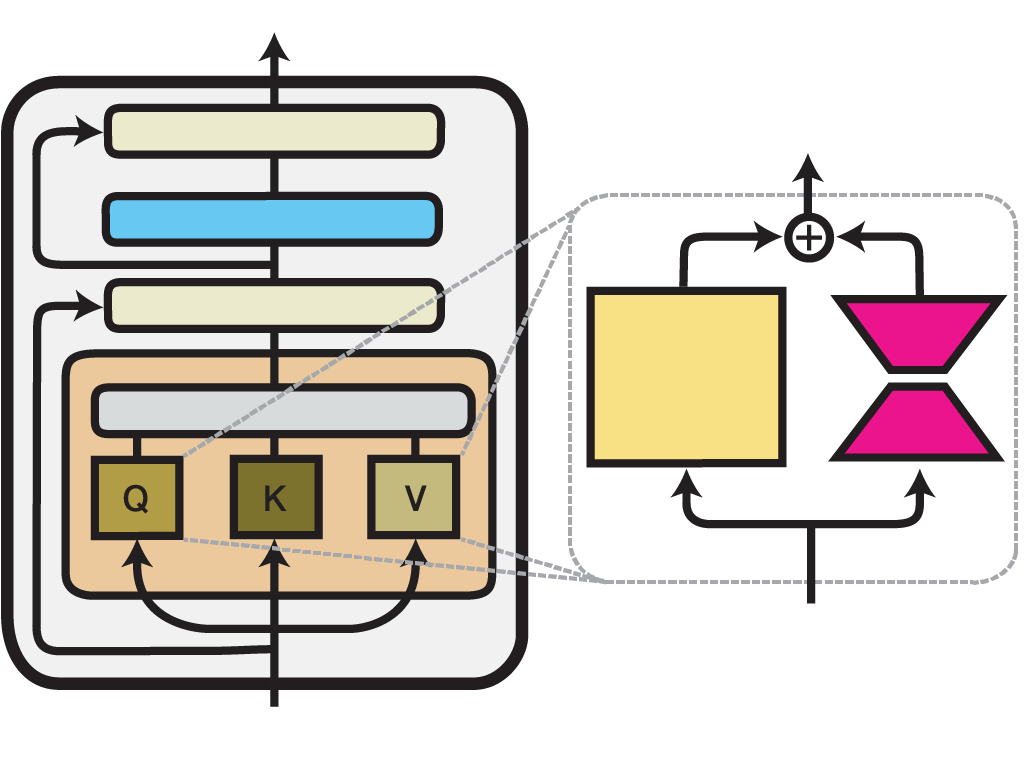
对于大模型,LoRA一般作用于多头自注意力机制(transformer)的K,Q,V矩阵上。上图更清楚的展示了LoRA是怎么插进一个Transformer layer的,尤其是attention里的投影位置
LoRA 之所以常被加在K,Q,V等投影矩阵上,是因为这些位置正好决定了注意力机制"看哪里、看什么、带回什么信息"。输入特征经过线性映射后形成查询、键和值,随后再完成相似度计算与加权汇聚。因此,一旦在这些投影矩阵上加入低秩增量,模型对上下文的关注方式、信息提取方式以及输出表征都会随之变化。也就是说,LoRA 虽然参数量很小,但它作用的位置并不边缘,而是直接切入了Transformer表征流动的关键环节。
因此,LoRA 可以理解为:在不破坏大模型主体结构的前提下,通过在注意力等关键线性层中加入低秩增量,用极少的训练参数完成对原有表示空间的任务定向修正。
4.思考
为什么插入K,V的效果最好?
Q(Query) 决定"当前 token 想找什么"。
V(Value) 决定"被注意到之后,实际传回来什么内容"。
因为 Q/V 直接控制"怎么找信息"和"把什么信息写回主干",在固定参数预算下,它们属于最能撬动注意力行为的位置;而论文实证上也确实发现
为什么不直接更新矩阵而是将其低秩分解为?
因为 如果直接更新W ,本质上就回到了全量微调,或者至少接近"直接学一个大更新矩阵
论文的出发点是这样的:
- 全量微调时,每个下游任务都要学一整套大参数增量
- 因此他们把任务增量重新编码成一个更小的参数集合
- 具体到单个矩阵,就是不直接学完整 ΔW\Delta WΔW,而是假设适配阶段的更新具有低内在秩 ,于是写成
其中
这样做有四个直接好处。
第一,参数量和显存会骤降。
第二,它押注"有效更新本来就是低秩的"。
第三,低秩分解不是削弱表达能力到不可恢复。
第四,可以合并回去,不增加推理延迟。
是不是本质上就是从特征交互上下功夫,让模型/网络像目标下游任务优化?
本质上不只是"从特征交互上下功夫",而是:
- 冻结原模型的大部分通用表征能力
- 只在少数高杠杆线性层上加入低秩更新
- 让模型沿着对下游任务更有用的方向发生偏移
LoRA 的核心抓手不是泛泛的特征交互,而是对参数更新空间做低秩约束,并把这类更新放在 attention 投影这类最能影响信息流的位置上。
可以总结为:LoRA 通过在关键线性层上施加低秩增量,不重写原模型主体,而是重定向原有特征的组织与交互方式,使其更贴合下游任务。
LoRA的思想理论上也可以用于其他深度网络?
理论上能。但不等于都同样划算。
LoRA 的原则首先适用于执行矩阵乘法的 dense layers, 虽然论文重点研究的是 Transformer 语言模型,但其提出的原则一般适用于任何带有 dense layers 的神经网络。
所以理论上它当然不只限于 Transformer,也可以用于:
- CNN 里的全连接层,甚至某些可重参数化卷积位置
- 多模态网络里的投影层
- 图网络里的线性变换层
- 其他带大量线性映射的深度模型
可总结为:LoRA 的核心并非重新训练整个模型,而是在保留预训练通用能力的基础上,通过对关键线性层施加低秩更新,调节特征表征与信息交互方式,使网络向目标下游任务定向适配。这一思想理论上可推广到其他含dense layers的深度网络。