研究背景
针对非平稳、非线性时间序列(如电力负荷、风速、股票价格、设备振动信号等)预测精度低的问题,传统单一分解方法(如EMD、EEMD)存在模态混叠、端点效应等缺陷,单一深度学习模型(如LSTM)难以充分提取复杂时序特征。本代码采用CEEMDAN(完全自适应噪声集合经验模态分解)与VMD(变分模态分解) 相结合的二级分解策略,并融合Transformer与LSTM构建混合预测模型,以提升预测精度和泛化能力。
主要功能
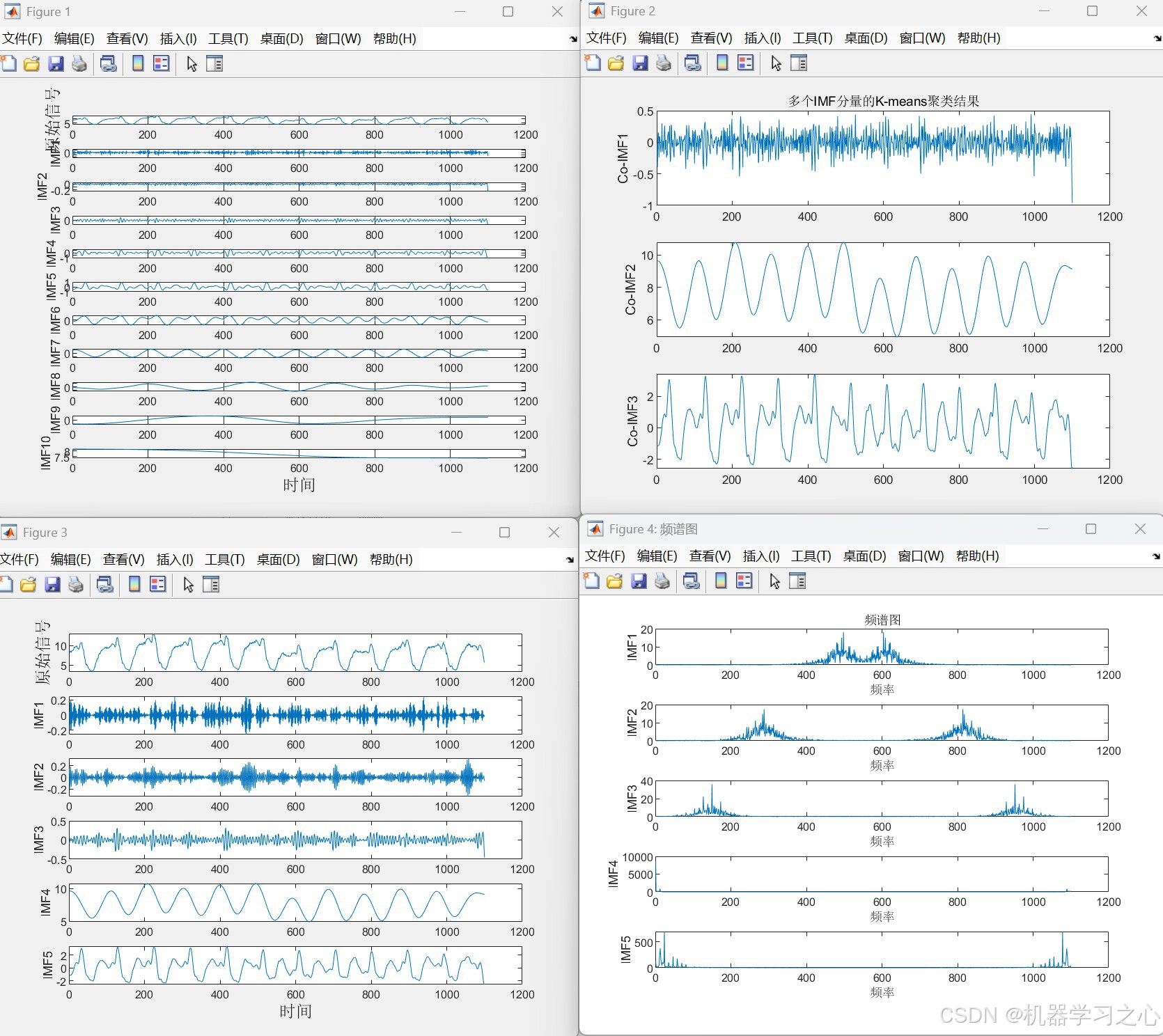
- 信号自适应分解:对原始序列进行CEEMDAN分解,基于样本熵和K-means聚类将IMF分量重组合并为高、中、低频三类,并对高频分量进一步VMD分解。
- 各分量预测:对每个分解子序列分别构建Transformer-LSTM网络进行训练和预测。
- 集成预测:将各分量预测结果线性相加得到最终预测值。
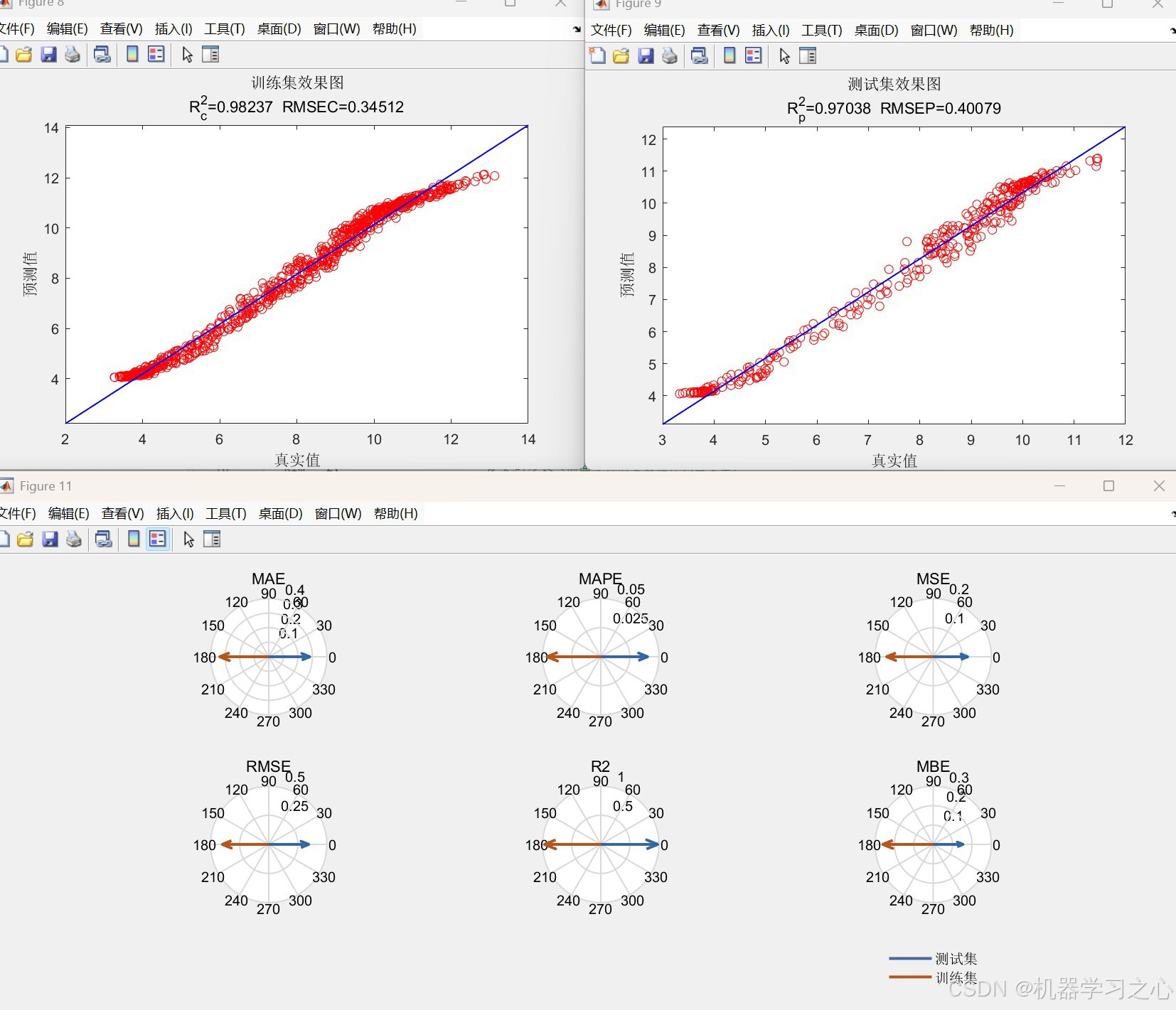
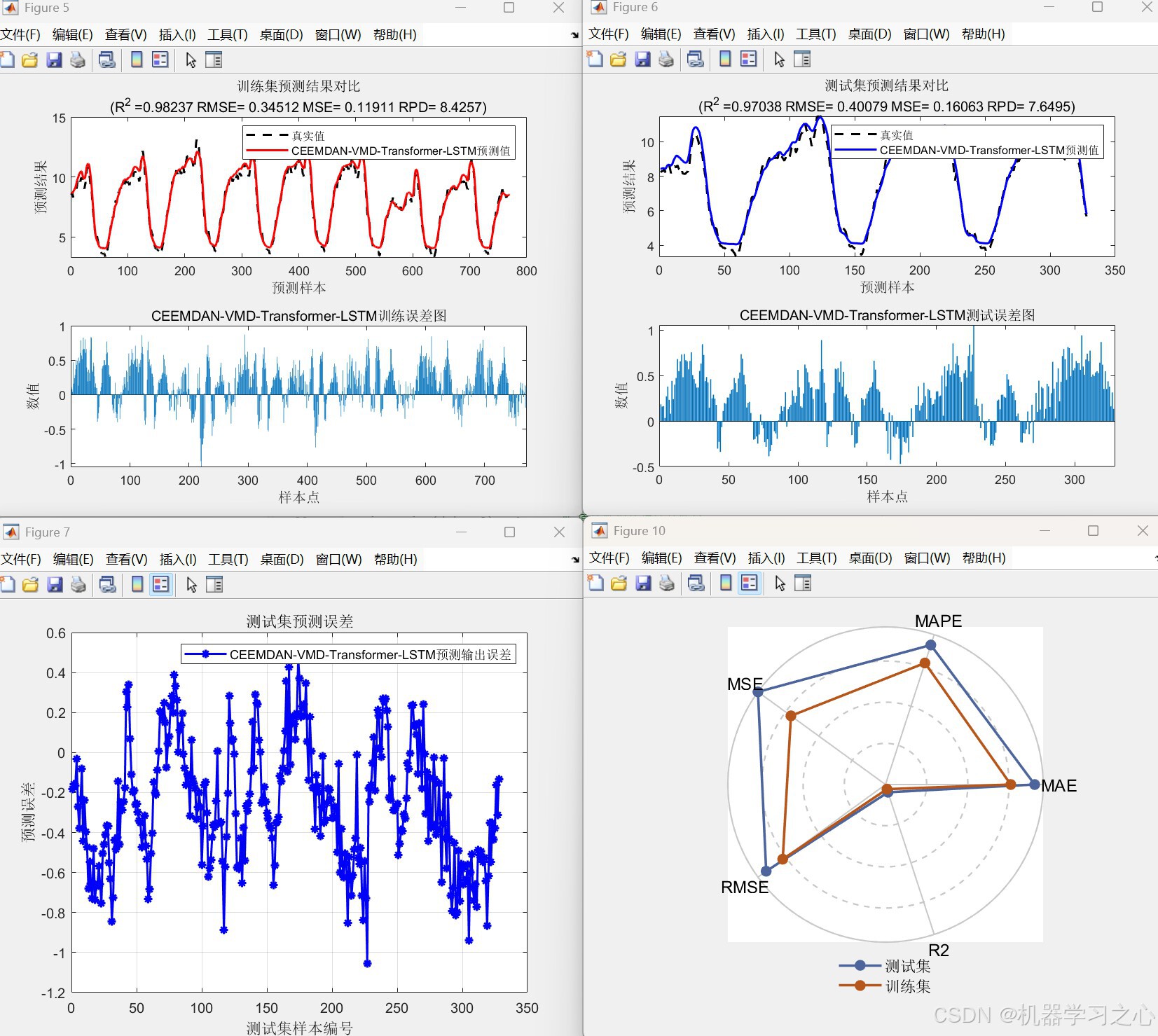
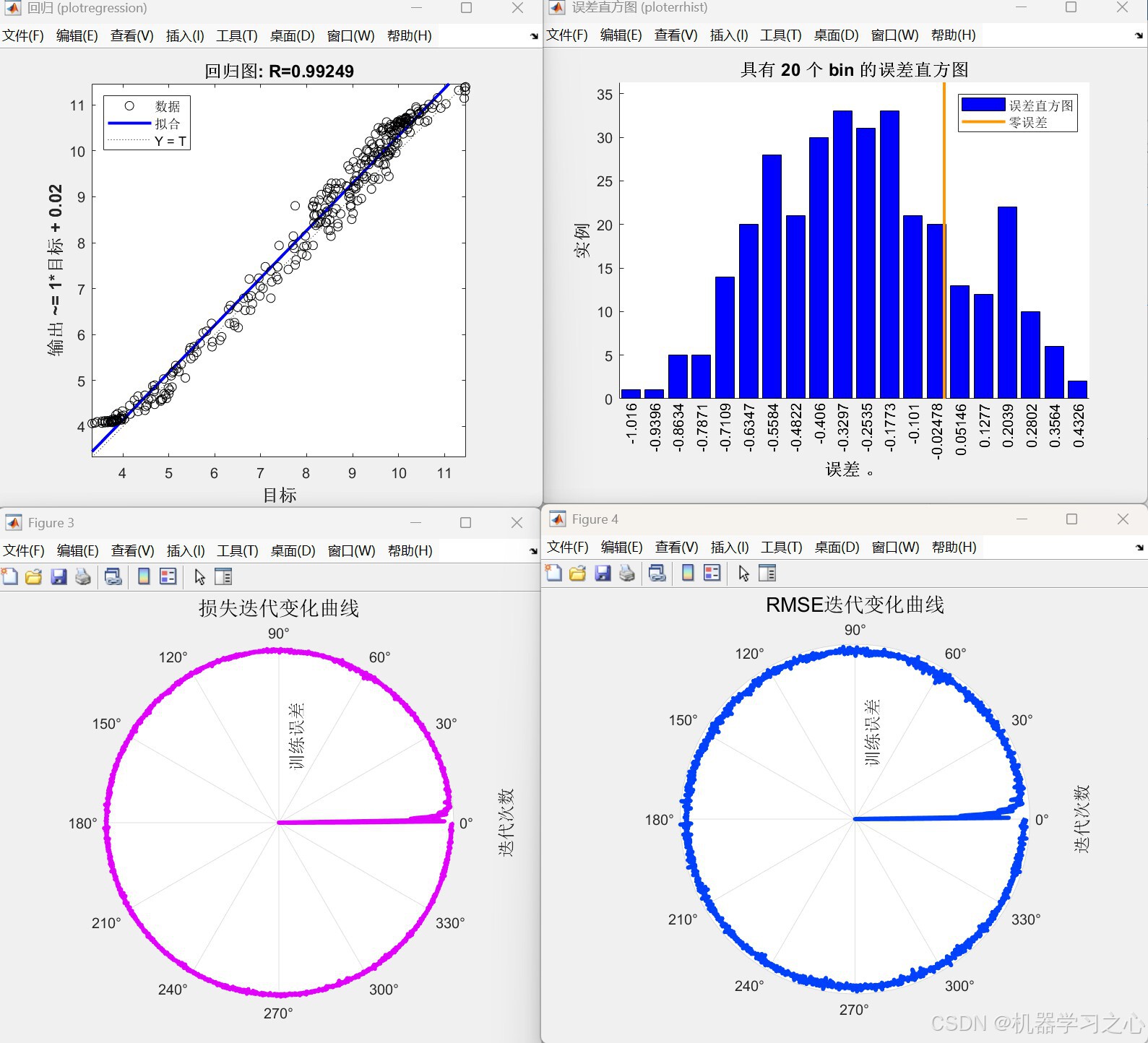
- 性能评估:输出MAE、MBE、MSE、RMSE、R²、RPD、MAPE等多项指标,并绘制回归图、误差图、雷达图、罗盘图等可视化结果。
算法步骤
- CEEMDAN分解 :对原始信号
X进行CEEMDAN,得到多个IMF分量。 - 计算样本熵 :对每个IMF计算样本熵(嵌入维数
dim=2,相似容限r=0.2*std)。 - K-means聚类 :将样本熵值聚为3类,对应高频、中频、低频分量,并分别求和得到
Co_IMF1(高频)、Co_IMF2(中频)、Co_IMF3(低频)。 - VMD二次分解 :对高频分量
Co_IMF1进行VMD(K=3),得到3个模态。 - 合并分量 :将VMD分解的3个模态与
Co_IMF2、Co_IMF3合并为最终子序列集Co_data。 - 数据重构 :对每个子序列,采用延时步长
kim=2、预测步长zim=1构造输入输出对。 - 数据集划分:70%训练集,30%测试集,并进行归一化。
- 各分量建模:构建Transformer(位置嵌入+自注意力层)+ LSTM网络,采用Adam优化器训练。
- 预测与反归一化:分别得到各分量的训练/测试预测值。
- 集成求和:将所有分量的预测值相加,得到最终预测结果。
- 误差计算与可视化:输出各项评价指标并绘图。
技术路线
原始信号 → CEEMDAN → IMFs → 样本熵 → K-means聚类 → 高/中/低频重组
↓
高频分量 → VMD二次分解 → 合并所有子序列
↓
对各子序列:划分训练/测试集 → 归一化 → Transformer-LSTM训练 → 预测 → 反归一化
↓
各分量预测结果求和 → 性能评估公式原理
- CEEMDAN :在EMD基础上向每一阶段添加自适应白噪声,通过计算唯一残差获得IMF,避免模态混叠。
x(t)+εkwk(t)x(t) + ε_k w_k(t)x(t)+εkwk(t) → EMD分解 → 取平均得到第k个IMF。 - 样本熵 :度量序列复杂度。给定嵌入维数mmm和相似容限rrr,
SampEn(m,r,N)=−ln(A/B)SampEn(m,r,N) = -ln(A/B)SampEn(m,r,N)=−ln(A/B),其中B为匹配向量对数,A为m+1维匹配对数。 - K-means :最小化簇内平方和 ∑i=1k∑x∈Ci∣∣x−μi∣∣2∑{i=1}^k ∑{x∈C_i} ||x - μ_i||^2∑i=1k∑x∈Ci∣∣x−μi∣∣2。
- VMD :变分框架下将信号分解为带宽受限的模态,通过求解优化问题 minuk,ωk∑k∣∣∂t(δ(t)+j/πt)∗uk(t)e−jωkt∣∣22min_{u_k,ω_k} {∑_k ||∂_t(δ(t)+j/πt)\*u_k(t)e^{-jω_k t}||^2_2}minuk,ωk∑k∣∣∂t(δ(t)+j/πt)∗uk(t)e−jωkt∣∣22实现非递归分解。
- Transformer自注意力 :Attention(Q,K,V)=softmax(QKT/√dk)VAttention(Q,K,V) = softmax(QK^T/√d_k)VAttention(Q,K,V)=softmax(QKT/√dk)V,捕获序列长程依赖。
- LSTM:通过遗忘门、输入门、输出门控制信息流,缓解梯度消失。
参数设定
| 模块 | 参数 | 值 |
|---|---|---|
| CEEMDAN | Nstd(噪声标准差) | 0.2 |
| NR(白噪声重复次数) | 500 | |
| MaxIter(最大迭代) | 5000 | |
| 样本熵 | dim(嵌入维数) | 2 |
| r(相似容限) | 0.2×std(x) | |
| K-means | 聚类数 | 3 |
| VMD | K(模态数) | 3 |
| 数据重构 | kim(延时步长) | 2 |
| zim(预测步长) | 1 | |
| 训练集比例 | 0.7 | |
| Transformer | numHeads(注意力头数) | 8 |
| numKeyChannels(键通道数) | 256 | |
| maxPosition(最大位置编码) | 512 | |
| LSTM | hidden units | 64 |
| 训练 | 优化器 | Adam |
| 最大轮数 | 500 | |
| 批量大小 | 256 | |
| 初始学习率 | 0.01 | |
| L2正则化系数 | 0.001 | |
| 学习率下降因子 | 0.1 | |
| 下降周期 | 300 | |
| 梯度裁剪阈值 | 10 |
运行环境
- 软件:MATLAB2024b
- 数据格式 :Excel文件
data.xlsx,最后一列为预测目标变量
应用场景
- 能源预测:电力负荷、光伏/风电功率、电池剩余容量
- 环境气象:风速、气温、降雨量时间序列
- 金融股票:股价、指数、汇率预测
- 工业运维:设备振动信号趋势预测、剩余寿命预测
- 交通流量:道路车流量、地铁客流量预测