- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
LSTM (Long Short-Term Memory,长短期记忆网络) 是一种专为处理序列数据(如时间、文本、语音)而设计的循环神经网络 (RNN)。它最大的突破是解决了传统 RNN 无法处理长序列时的梯度消失问题,能够有效记住序列中相隔很远的关键信息。
一、为什么需要 LSTM?(传统 RNN 的痛点)
标准 RNN 的结构像一条链,每一时刻的信息只传给下一时刻。但在处理长序列(如长句子、长时间序列)时:
梯度消失:早期信息的梯度经过多次乘法后变得极小,网络无法学习到早期的重要信息("记不住很久以前的事")。
梯度爆炸:梯度变得极大,导致参数更新失控,训练崩溃。
举例:在句子 "我小时候在北京长大,那里的秋天很美,我很喜欢____。" 中,传统 RNN 可能早已忘记 "北京",而 LSTM 可以保留这个关键信息来预测空格内容。
二、LSTM 的核心结构
LSTM 的核心是细胞状态 (Cell State, Cₜ) 和三个门控 (Gate)。你可以把它想象成一个智能传送带和三个开关:
- 细胞状态 (Cell State, Cₜ) ------ 记忆传送带
贯穿整个网络的 "信息高速公路",信息在上面流动时只有少量线性操作,几乎无损。
负责长期记忆,像一条传送带,让重要信息可以一直传递下去。 - 三个门控 (Gates) ------ 信息管理员
门控本质是一个 Sigmoid 层 + 点乘运算:
Sigmoid 输出 0~1 之间的值:0 代表完全丢弃,1 代表完全保留。
三个门协同工作,控制信息的遗忘、存储、输出。
(1)遗忘门 (Forget Gate, fₜ) ------ 决定忘记什么
作用:决定从上一时刻的细胞状态 Cₜ₋₁ 中丢弃哪些无用信息。
输入:上一时刻的隐藏状态 hₜ₋₁ + 当前时刻输入 xₜ。
公式:fₜ = σ(Wf · hₜ₋₁, xₜ + bf)
(2)输入门 (Input Gate, iₜ) ------ 决定记住什么新信息
作用:决定将当前时刻的哪些新信息存入细胞状态。
两步:
输入门 iₜ:决定哪些值需要更新。
候选细胞状态 C̃ₜ:通过 tanh 生成待加入的新信息。
公式:
iₜ = σ(Wi · hₜ₋₁, xₜ + bi)
C̃ₜ = tanh(Wc · hₜ₋₁, xₜ + bc)
(3)更新细胞状态 (最核心步骤)
作用:结合遗忘门和输入门,更新长期记忆。
公式:Cₜ = fₜ ⊙ Cₜ₋₁ + iₜ ⊙ C̃ₜ
fₜ ⊙ Cₜ₋₁:保留一部分旧记忆。
iₜ ⊙ C̃ₜ:添加一部分新记忆。
(4)输出门 (Output Gate, oₜ) ------ 决定输出什么
作用:决定从当前细胞状态 Cₜ 中输出哪些信息作为当前隐藏状态 hₜ。
公式:
oₜ = σ(Wo · hₜ₋₁, xₜ + bo)
hₜ = oₜ ⊙ tanh(Cₜ)
三、LSTM 工作流程(一句话总结)
遗忘:忘记不重要的旧记忆。
输入:筛选并记住重要的新信息。
更新:合并新旧记忆,更新细胞状态。
输出:基于最新记忆,生成当前输出并传给下一时刻。
四、LSTM 的主要变体
GRU (Gated Recurrent Unit):简化版 LSTM,合并遗忘门和输入门为更新门,去掉细胞状态,只有隐藏状态,速度更快,效果接近 LSTM。
Bidirectional LSTM (Bi-LSTM):双向 LSTM,同时从前往后和从后往前处理序列,能同时利用过去和未来的信息(常用于 NLP)。
Stacked LSTM:多层 LSTM 堆叠,深层网络学习更抽象的特征。
五、典型应用场景
时间序列预测:代码场景 ------火灾温度预测、股价、天气、能耗预测。
自然语言处理 (NLP):文本生成、机器翻译、情感分析、命名实体识别。
语音处理:语音识别、语音合成。
其他:手写识别、视频行为分析。
六、回到代码
训练火灾温度预测的代码中:
输入 X:前 8 个时间步的 Tem1, CO1, Soot1 三维序列。
LSTM 层:网络自动学习这 8 步数据中的规律,记住与温度相关的关键特征(如 CO 浓度突增预示温度上升)。
输出 y:基于学到的规律,预测第 9 步的温度值。
总结
LSTM 就是一个拥有 "长期记忆力" 的神经网络。 它通过细胞状态和三重门控,像人一样选择性地忘记无关信息、记住关键信息,从而完美解决了长序列依赖问题,是深度学习处理时序数据的基石。
python
# ===================== 1. 环境配置与库导入 =====================
# 解决matplotlib在部分电脑上可能出现的多线程冲突问题
import os
os.environ.setdefault("KMP_DUPLICATE_LIB_OK", "TRUE")
# 导入PyTorch核心库:神经网络函数、张量运算、网络层模块
import torch.nn.functional as F
import numpy as np # 数值计算库,处理数组
import pandas as pd # 数据处理库,读取csv、表格数据
import torch # 深度学习框架PyTorch
from torch import nn # PyTorch神经网络模块
# ===================== 2. 读取火灾数据集 =====================
# 定义csv数据文件路径(你本地的火灾实验数据)
file_path = 'D:\\my_project\\python\\365\\data\\woodpine2\\woodpine2.csv'
# 读取csv文件到DataFrame表格,包含温度、CO浓度、烟密度等火灾特征
data = pd.read_csv(file_path)
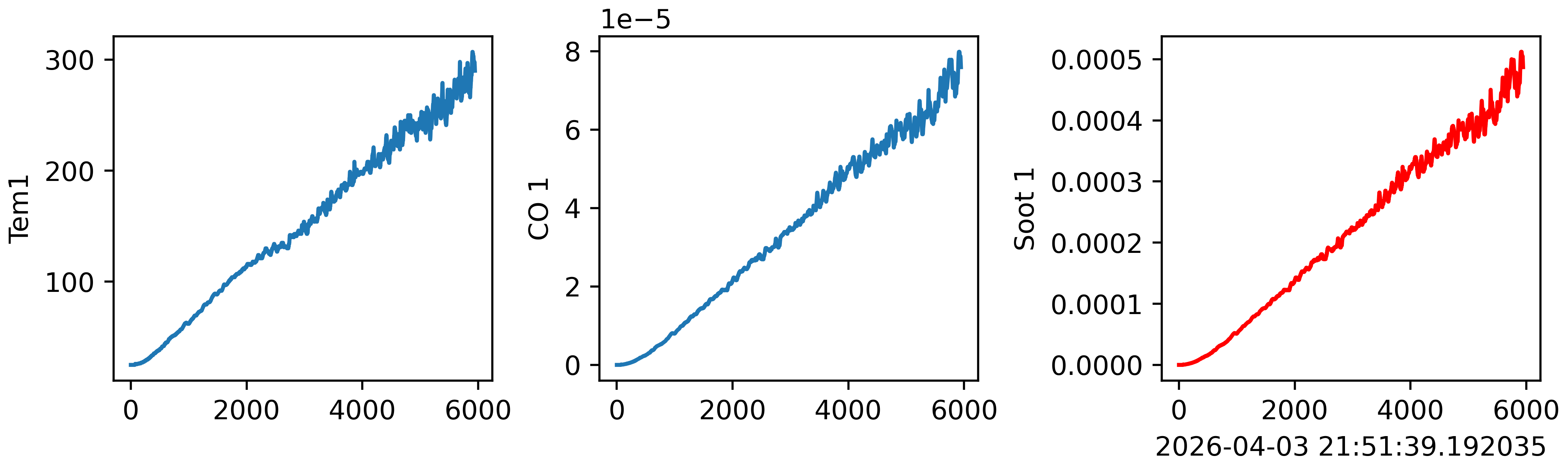
# ===================== 3. 原始数据可视化(画图) =====================
import matplotlib.pyplot as plt # 绘图库
import seaborn as sns # 基于matplotlib的高级绘图库
# 设置图片清晰度:保存分辨率500dpi,显示分辨率500dpi
plt.rcParams['savefig.dpi'] = 500
plt.rcParams['figure.dpi'] = 500
# 创建1行3列的子图,总尺寸14x3,自动布局防重叠
fig, ax = plt.subplots(1, 3, constrained_layout=True, figsize=(14, 3))
# 分别绘制三个特征的原始时序曲线
sns.lineplot(data = data['Tem1'], ax = ax[0]) # 子图1:温度Tem1
sns.lineplot(data = data['CO 1'], ax = ax[1]) # 子图2:一氧化碳浓度CO 1
sns.lineplot(data = data['Soot 1'], ax = ax[2], color='r') # 子图3:烟密度Soot 1,红色
from datetime import datetime
current_time = datetime.now() # 获取当前系统时间
plt.xlabel(current_time) # 横坐标标注当前时间
plt.show() # 显示原始数据图
# ===================== 4. 数据预处理 =====================
# 去掉第0列(索引/时间列),只保留特征:Tem1、CO 1、Soot 1
dataFrame = data.iloc[:, 1:]
from sklearn.preprocessing import MinMaxScaler # 数据归一化工具
# 归一化:把所有数据缩放到 0~1 之间,让神经网络训练更稳定
sc = MinMaxScaler(feature_range=(0, 1))
# 对三个特征分别做归一化
for i in ['CO 1', 'Soot 1', 'Tem1']:
# reshape(-1,1):把一维数据转成二维,满足sklearn输入格式
dataFrame[i] = sc.fit_transform(dataFrame[i].values.reshape(-1, 1))
# ===================== 5. 构造时序样本(核心!) =====================
width_X = 8 # 输入序列长度:用前8个时间点的数据
width_y = 1 # 预测长度:预测第9个时间点的温度
# 定义空列表存放输入X和标签y
X = []
y = []
in_start = 0 # 滑动窗口起始位置,从0开始
# 遍历每一行数据,滑动构造样本
for _, _ in data.iterrows():
in_end = in_start + width_X # 输入窗口结束:0~7(共8个)
out_end = in_end + width_y # 输出位置:第8号索引(第9个点)
# 防止越界:确保窗口不超出数据长度
if out_end < len(dataFrame):
# 取 前8个时间步 的所有特征(Tem1、CO、Soot)作为输入
X_ = np.array(dataFrame.iloc[in_start:in_end, ])
# 取 第9个时间步 的温度(第0列)作为预测目标y
y_ = np.array(dataFrame.iloc[in_end:out_end, 0])
X.append(X_) # 加入输入列表
y.append(y_) # 加入标签列表
in_start += 1 # 窗口向后滑动1步
# 把列表转成numpy数组,方便送入模型
X = np.array(X)
y = np.array(y).reshape(-1, width_y, 1) # 调整形状适配LSTM输入
# 检查数据是否有缺失值(NaN),确保数据干净
print(np.any(np.isnan(X)))
print(np.any(np.isnan(y)))
# ===================== 6. 划分训练集/测试集并转为张量 =====================
# 前5000个样本做训练集,转为float32张量(PyTorch默认类型)
X_train = torch.tensor(np.array(X[:5000]), dtype=torch.float32)
y_train = torch.tensor(np.array(y[:5000]), dtype=torch.float32)
# 剩余样本做测试集
X_test = torch.tensor(np.array(X[5000:]), dtype=torch.float32)
y_test = torch.tensor(np.array(y[5000:]), dtype=torch.float32)
# 封装成数据集加载器:自动分批、打乱
from torch.utils.data import TensorDataset, DataLoader
train_dl = DataLoader(TensorDataset(X_train, y_train),
batch_size=64, # 每批64个样本
shuffle=True) # 训练集打乱,提高泛化能力
test_dl = DataLoader(TensorDataset(X_test, y_test),
batch_size=64,
shuffle=True)
# ===================== 7. 定义第一个LSTM模型:预测单输出(温度) =====================
class model_lstm1(nn.Module):
def __init__(self):
super(model_lstm1, self).__init__()
# 第一层LSTM:输入3个特征(Tem1、CO、Soot),隐藏层320维,1层,batch优先
self.lstm0 = nn.LSTM(input_size=3, hidden_size=320,
num_layers=1, batch_first=True)
# 第二层LSTM:接收上一层320维输出,继续提取时序特征
self.lstm1 = nn.LSTM(input_size=320, hidden_size=320,
num_layers=1, batch_first=True)
# 全连接层:把320维特征映射为1个输出(预测温度)
self.fc0 = nn.Linear(320, 1)
def forward(self, x):
# 前向传播:数据流过网络
out, hidden1 = self.lstm0(x) # 第一层LSTM
out, _ = self.lstm1(out, hidden1) # 第二层LSTM
out = self.fc0(out) # 全连接输出
return out[:, -1:, :] # 只取最后1个时间步的预测值(我们只需要预测第9步温度)
model1 = model_lstm1() # 实例化模型
# ===================== 8. 定义训练函数 =====================
import copy
def train(train_dl, model, loss_fn, opt, lr_scheduler=None):
size = len(train_dl.dataset) # 训练集总样本数
num_batches = len(train_dl) # 总批次数
train_loss = 0 # 累计训练损失
for x, y in train_dl: # 遍历每一批数据
x, y = x.to(device), y.to(device) # 数据移到GPU/CPU
pred = model(x) # 模型前向预测
loss = loss_fn(pred, y) # 计算预测值与真实值误差(MSE)
opt.zero_grad() # 清空上一轮梯度
loss.backward() # 反向传播,计算梯度
opt.step() # 更新模型参数
train_loss += loss.item() # 累加损失
if lr_scheduler is not None:
lr_scheduler.step() # 更新学习率(余弦退火)
print("learning rate = {:.5f}".format(opt.param_groups[0]['lr']), end=" ")
train_loss /= num_batches # 平均每批次损失
return train_loss
# ===================== 9. 定义测试函数 =====================
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss = 0
with torch.no_grad(): # 测试时不计算梯度,节省显存
for x, y in dataloader:
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
test_loss += loss.item()
test_loss /= num_batches
return test_loss
# ===================== 10. 设置训练设备(GPU优先) =====================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ===================== 11. 开始训练模型 =====================
model = model_lstm1()
model = model.to(device) # 模型移到设备
loss_fn = nn.MSELoss() # 损失函数:均方误差(回归任务标配)
learn_rate = 1e-1 # 学习率0.1
opt = torch.optim.SGD(model.parameters(), lr=learn_rate, weight_decay=1e-4) # 优化器
epochs = 50 # 训练50轮
train_loss = [] # 记录每轮训练损失
test_loss = [] # 记录每轮测试损失
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt, epochs, last_epoch=-1) # 学习率余弦衰减
# 循环训练
for epoch in range(epochs):
model.train() # 训练模式
epoch_train_loss = train(train_dl, model, loss_fn, opt, lr_scheduler)
model.eval() # 评估模式
epoch_test_loss = test(test_dl, model, loss_fn)
train_loss.append(epoch_train_loss)
test_loss.append(epoch_test_loss)
# 打印本轮训练结果
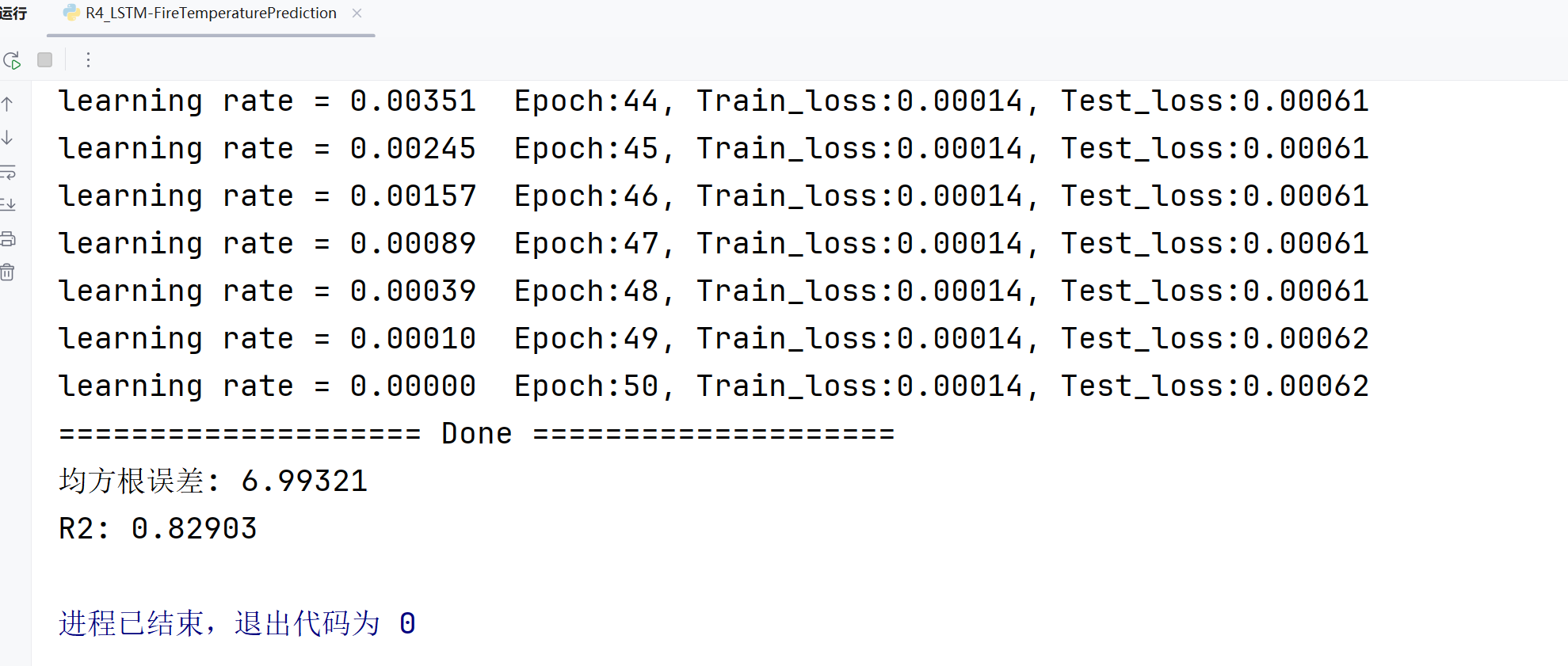
template = ('Epoch:{:2d}, Train_loss:{:.5f}, Test_loss:{:.5f}')
print(template.format(epoch + 1, epoch_train_loss, epoch_test_loss))
print("=" * 20, '训练完成', "=" * 20)
# ===================== 12. 绘制损失曲线 =====================
import matplotlib.pyplot as plt
from datetime import datetime
current_time = datetime.now()
plt.figure(figsize=(5, 3), dpi=120)
plt.plot(train_loss, label='LSTM Training Loss') # 训练损失
plt.plot(test_loss, label='LSTM Validation Loss') # 验证损失
plt.title('Training and Validation Loss')
plt.xlabel(current_time) # 横坐标时间戳
plt.legend()
plt.show()
# ===================== 13. 模型预测 + 反归一化 =====================
model = model.to(device)
X_test = X_test.to(device)
# 模型预测 → 从GPU转到CPU → 转为numpy → 反归一化(还原成真实温度)
predicted_y_lstm = sc.inverse_transform(model(X_test).detach().cpu().numpy().reshape(-1, 1))
y_test_1 = sc.inverse_transform(y_test.reshape(-1, 1)) # 真实值也反归一化
# 转成一维列表方便画图
y_test_one = [i[0] for i in y_test_1]
predicted_y_lstm_one = [i[0] for i in predicted_y_lstm]
# ===================== 14. 绘制真实值 vs 预测值曲线 =====================
plt.figure(figsize=(5, 3), dpi=120)
plt.plot(y_test_one[:2000], color='red', label='real_temp') # 前2000点真实温度
plt.plot(predicted_y_lstm_one[:2000], color='blue', label='prediction') # 预测温度
plt.title('火灾温度预测结果')
plt.xlabel(current_time)
plt.ylabel('温度')
plt.legend()
plt.show()
# ===================== 15. 模型评估指标 =====================
from sklearn import metrics
# RMSE:均方根误差,越小越好
RMSE_lstm = metrics.mean_squared_error(predicted_y_lstm_one, y_test_1) ** 0.5
# R²:决定系数,越接近1拟合越好
R2_lstm = metrics.r2_score(predicted_y_lstm_one, y_test_1)
print('均方根误差: %.5f' % RMSE_lstm)
print('R2: %.5f' % R2_lstm)
# ===================== 16. 第二个LSTM模型:输出2个预测值(扩展用) =====================
class model_lstm2(nn.Module):
def __init__(self):
super(model_lstm2, self).__init__()
self.lstm0 = nn.LSTM(input_size=3, hidden_size=320, num_layers=1, batch_first=True)
self.lstm1 = nn.LSTM(input_size=320, hidden_size=320, num_layers=1, batch_first=True)
self.fc0 = nn.Linear(320, 2) # 输出2个值(可同时预测温度+CO等)
def forward(self, x):
out, hidden1 = self.lstm0(x)
out, _ = self.lstm1(out, hidden1)
out = self.fc0(out[:, -1, :])
return out.unsqueeze(2) # 形状调整为 (batch, 2, 1)
model2 = model_lstm2()