1.本课程使用的软件概述
本课程中使用的开发工具:
-
python 3.8 (尽量不要用最新版的python, 老师这里是3.7)
-
pycharm (舒服, 但收费, 联系作者有神秘工具为您解忧)
如果有基础或者玩儿的比较6的玩家也可以选择以下工具:
-
anaconda, jupyter
-
Visual Studio Code
-
python, IDLE (不推荐)
接下来就是安装了. Python安装过程就不赘述了. 注意安装的时候需要把python添加到环境变量中. 其他的没啥注意的
至于Pycharm的安装. 全程一路确定即可.
神秘工具的使用: 恕不外放. 需要的找客服.
2.第一个爬虫程序开发
from urllib.request import urlopen #urllib --- url:网址 lib --- 库 urllib跟网址相关的一个库 #该库中有一个request的模块 request翻译过来是请求的意思 #urllib.request 在这个模块里有个函数叫urlopen urlopen --- 打开一个网址 url = "https://www.baidu.com" #打开一个网址urlopen(url) 这里面肯定有内容 将其赋给req req = urlopen(url) #print()打印出该内容 --- 结果打印<http.client.HTTPResponse object at 0x000001452CFAF5B0> print(req) #想要拿到内容,就得read() --- 结果:b'<!DOCTYPE html>\n<html>\n<head>\n <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />\n <meta h。。。。。。。。。。。 #这里通过b' 可看出拿到是字节 这就需要我们手动把字节变成字符串 需要decode()进行解码 #decode(参数) 参数里得有字符集 --- 一般是 utf-8 或者 GBK 在终端中查看相关信息 或者俩者都试一下 print(req.read().decode('utf-8')) #此时拿到的是页面源代码 """ 打印出的结果: <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" /> <meta content="always" name="referrer" /> <meta name="description" ..... """
#爬虫的过程简易解释图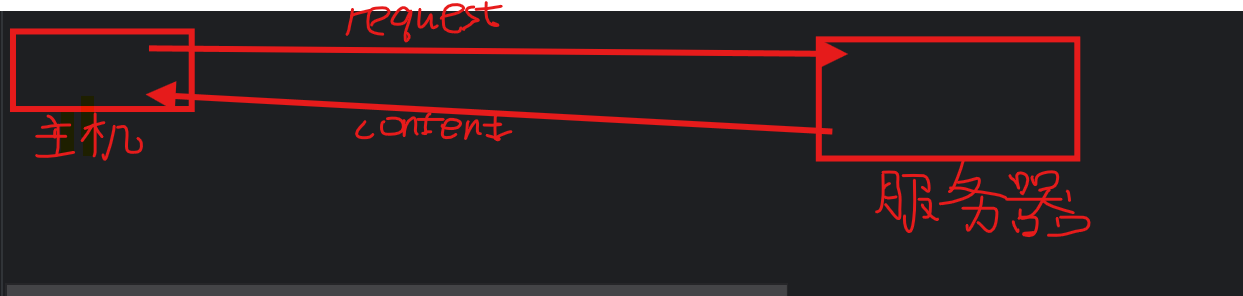
该图中俩者之间传播的是字符串,服务器中返回的是页面源代码 页面源代码有HTML-CSS-JS
#在运行下面代码时,需将上面的代码 print(req.read().decode('utf-8'))注释掉 with open("my_baidu.html",mode="w",encoding="utf-8") as f: f.write(req.read().decode("utf-8"))#使用with:自动管理文件资源
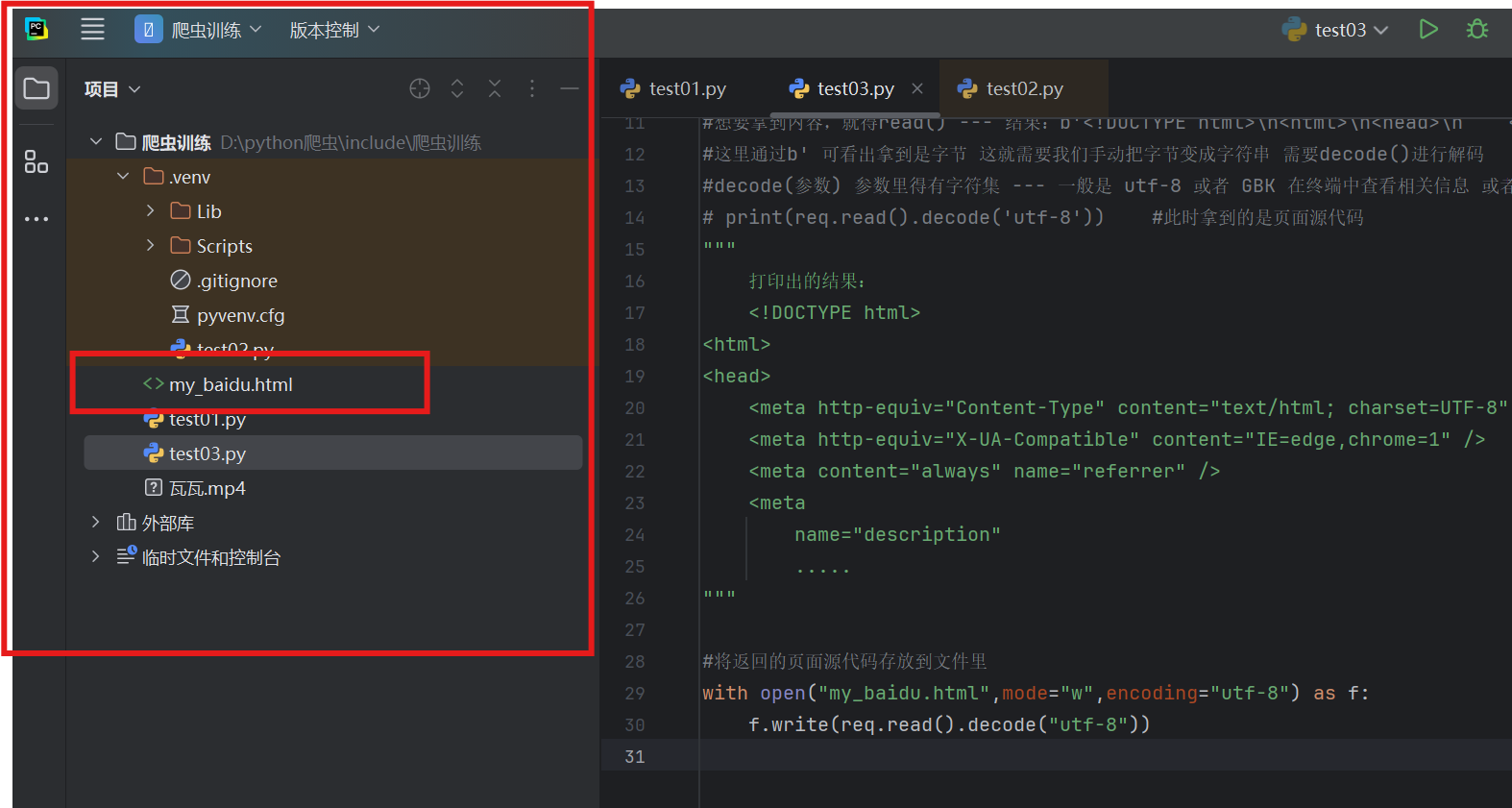
#当你一运行,左边项目中就会出现my_baidu.html文件 里面存放的就是页面源代码
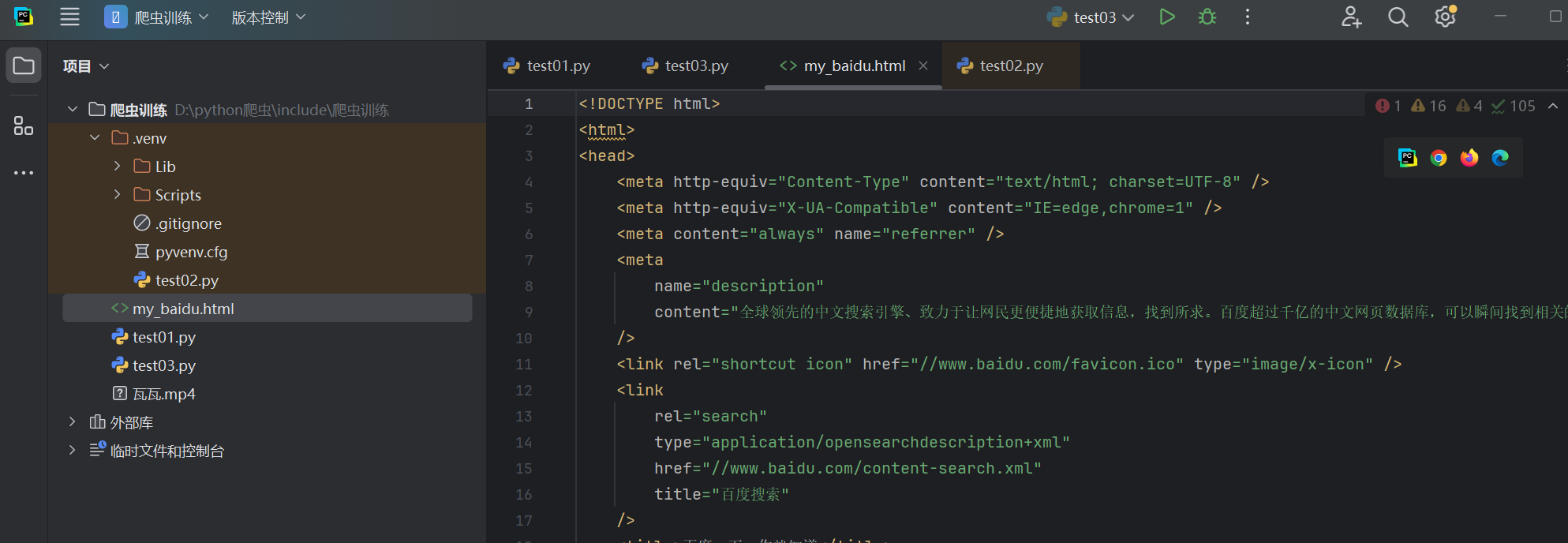
#随便打击括号的浏览器
#点击进入后即是跟百度网页相同的界面 --- 但这个界面属于你自己的

3.整体代码结构图