1.简述
最后发现支持GGUF文件的轻度部署环境还是llama.cpp好用,ollama的modelfile难用,容易丢。
实测量化版能跑到4.3G显存,测试环境是基于vscode+continue openai兼容模式
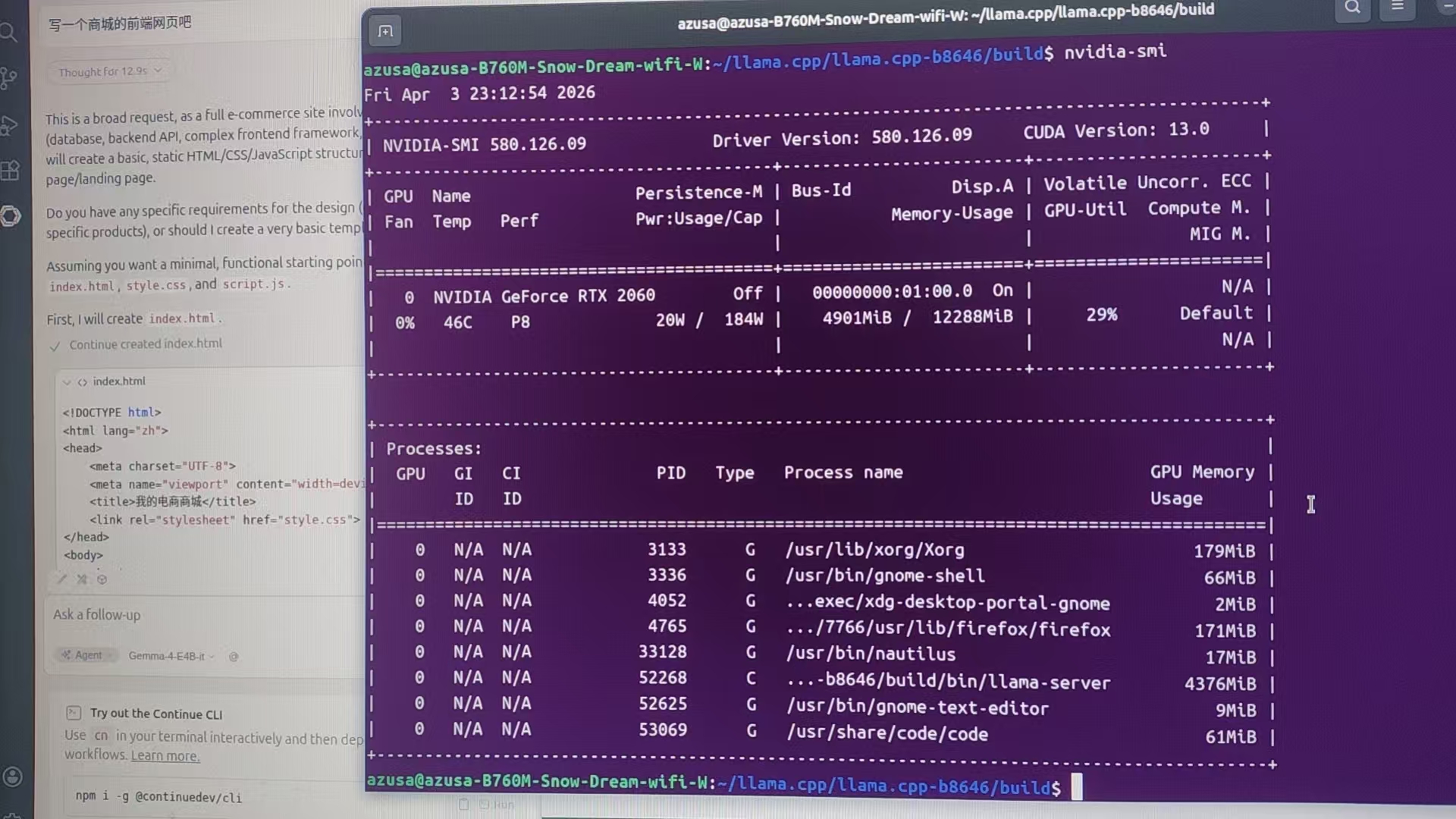
1.1.下载项目文件并安装依赖环境
bash
# 下载文件
https://github.com/ggml-org/llama.cpp/archive/refs/tags/llama.cpp-b8646.zip
bash
# 解压到系统目录
sudo tar -C /usr -xzf llama.cpp-b8646.zip
bash
# 安装 Git, CMake, GCC/G++, Python 等基础依赖
sudo apt update
sudo apt install -y build-essential cmake git wget python3-pip
bash
# 添加 CUDA 官方软件源
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
# 安装 CUDA Toolkit 12.5(此步骤会自动安装匹配的 NVIDIA 驱动)
# 你可以根据需要选择更新的版本,如 12.6,只需将命令中的 "12-5" 替换即可[reference:3]
sudo apt-get -y install cuda-toolkit-12-5
bash
# 编辑 ~/.bashrc 文件
echo 'export PATH=/usr/local/cuda-12.5/bin${PATH:+:${PATH}}' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.5/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}' >> ~/.bashrc
source ~/.bashrc
bash
# 最后验证 CUDA 编译器与驱动是否安装成功
nvcc --version
nvidia-smi1.2.进行CUDA编译
下方参数可灵活配置,其他参数自行搜索即可。
| 显卡系列 | 代表型号 | 计算能力 | CMake 参数 (-DCMAKE_CUDA_ARCHITECTURES=...) |
|---|---|---|---|
| GTX 10 系列 (Pascal) | GTX 1060, 1070, 1080, 1080Ti | 6.1 | "61" |
| GTX 16 系列 (Turing) | GTX 1650, 1660, 1660 Ti | 7.5 | "75" |
| RTX 20 系列 (Turing) | RTX 2060, 2070, 2080, 2080 Ti | 7.5 | "75" |
| RTX 30 系列 (Ampere) | RTX 3060, 3070, 3080, 3090 | 8.6 | "86" |
| RTX 40 系列 (Ada Lovelace) | RTX 4060, 4070, 4080, 4090 | 8.9 | "89" |
bash
# 在项目根目录下创建一个 build 文件夹,所有编译生成的文件都会放在这里,这可以保持源码目录的整洁。
mkdir build && cd build
# 关键一步:运行 cmake 进行配置。要启用 CUDA 支持,必须添加 -DGGML_CUDA=ON 参数。同时,建议使用 -DCMAKE_BUILD_TYPE=Release 进行优化编译
cmake .. -DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="75" -DLLAMA_BUILD_SERVER=ON
# 配置完成后,开始编译。-j $(nproc) 会利用你所有的 CPU 核心来加速编译过程。
cmake --build . --config Release -j $(nproc)1.3.服务端开启
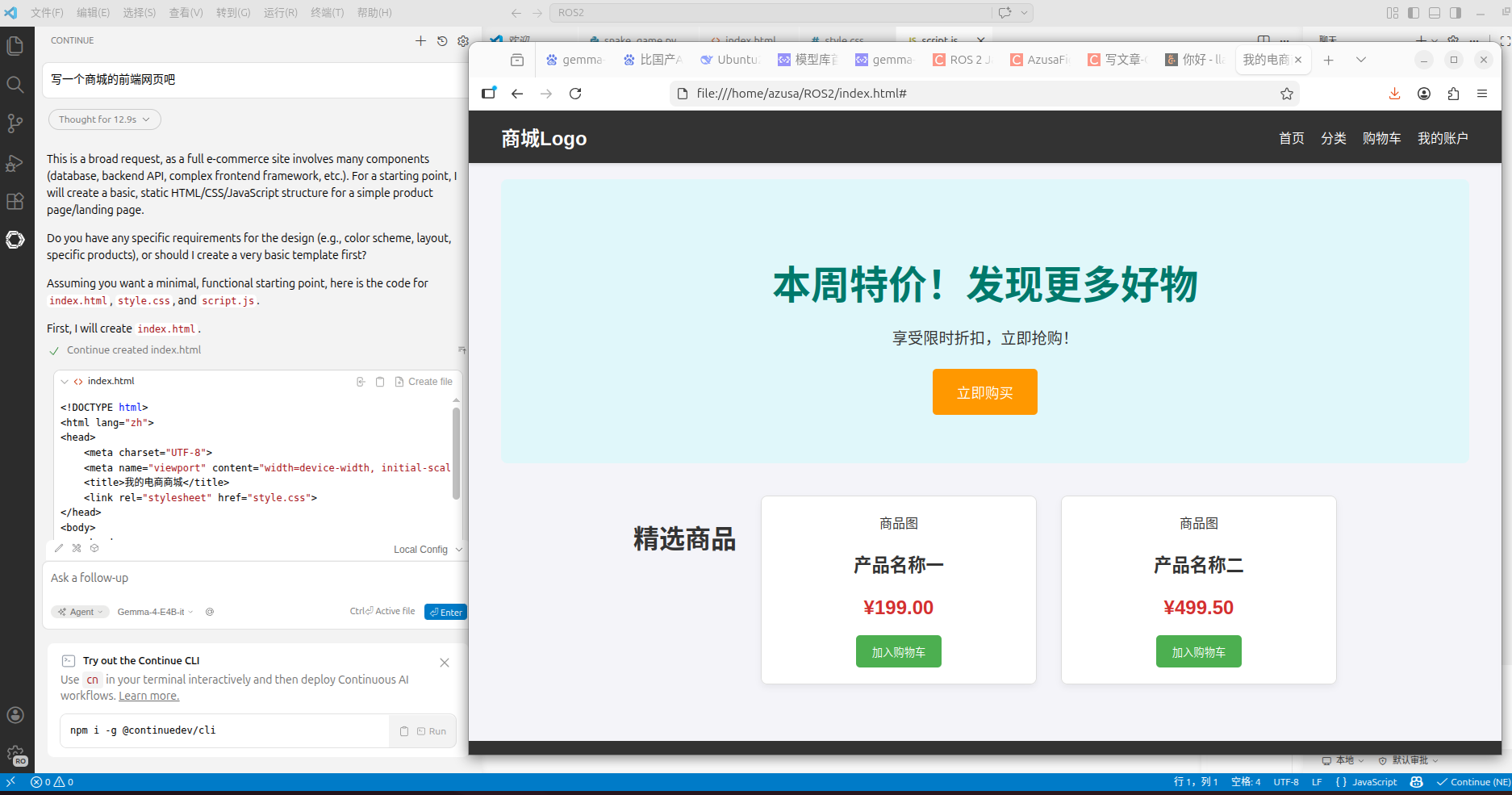
带上我从魔搭社区下载的热呼的Gemma4-E4B-it进行愉快的Vscode agent测试
bash
#!/bin/bash
# 启动 llama.cpp 服务器脚本
# 模型路径
MODEL_PATH="/home/azusa/llama.cpp/models/gemma-4-E4B-it-IQ4_XS.gguf"
# 视觉投影模型路径
MMPROJ_PATH="/home/azusa/llama.cpp/models/mmproj-F16.gguf"
# 可执行文件路径
SERVER_BIN="/home/azusa/llama.cpp/llama.cpp-b8646/build/bin/llama-server"
# 检查模型文件是否存在
if [ ! -f "$MODEL_PATH" ]; then
echo "错误: 模型文件 $MODEL_PATH 不存在"
exit 1
fi
if [ ! -f "$MMPROJ_PATH" ]; then
echo "错误: 视觉投影文件 $MMPROJ_PATH 不存在"
exit 1
fi
# 检查可执行文件是否存在
if [ ! -f "$SERVER_BIN" ]; then
echo "错误: 可执行文件 $SERVER_BIN 不存在,请先编译 llama.cpp"
exit 1
fi
# 启动服务器
# 参数说明:
# --host 0.0.0.0 - 监听所有网络接口
# --port 11434 - 端口号(与 Ollama 兼容)
# -c 8192 - 上下文长度(根据显存调整)
# --n-gpu-layers 99 - 加载所有层到 GPU(RTX 2060 12G 足够)
# --batch-size 512 - 批处理大小
# --threads 8 - CPU 线程数
# --flash-attn on - 启用 Flash Attention
$SERVER_BIN \
-m "$MODEL_PATH" \
--mmproj "$MMPROJ_PATH" \
--host 0.0.0.0 \
--port 11434 \
-c 32768 \
--n-gpu-layers 99 \
--batch-size 512 \
--threads 8 \
--flash-attn on1.4.实测结果
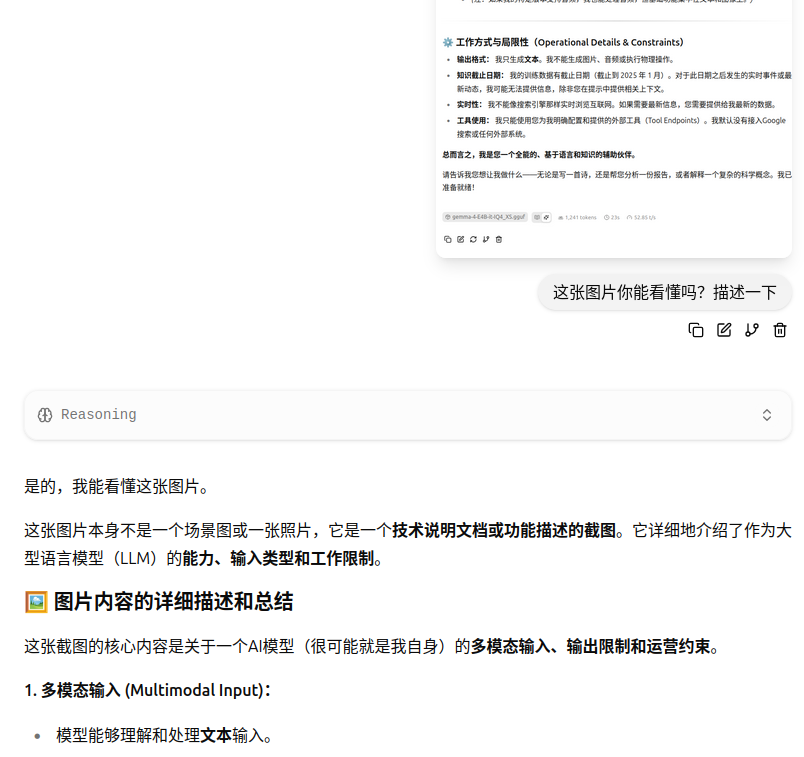
视觉需要加入额外的mmproj.gguf文件,已经测试图片
2.总结
之前的Qwen3.5的多模态模型给了我不小的震撼,这次的Gemma4-E4B更是如此。