第一个问题transformer:收敛太慢

transformer需要很长的时间去训练和收敛。(这里就是在说 transformer在图像上很难训练)
在参数初始化的时候服从均值0方差1的分布。
NLP和图像是有区别的,一个句子(NLP)通过就不过几个选择(就比如说:猫坐在垫子上,进行猫+坐 猫+垫 等的相关度计算 很容易区分) 但是如果是图像的话,一张图片可能就是几十万个像素,要判断猫和哪个像素相关,每个像素进行相关度计算,每个像素几乎都一样啊,因为选择太多,每个分到的注意力太少 。
刚开始训练的时候,模型啥都不知道,query:问"猫在哪"和key:每个像素的特征 两个都是随机向量,所以初始化的时候,没有重点,模型也学不懂啊 ; 怎么样才能学好呢? 要训练很久很久,让模型慢慢发现:"哦哦原来这些像素像猫,那些不像",但是太慢了!
那么**Deformable DETR解决的思路!**不要看全部几十万的像素,只看几十个关键位置,让模型自己学会看哪里,这样权重集中了,训练也就变快了。
第二个问题:计算量大

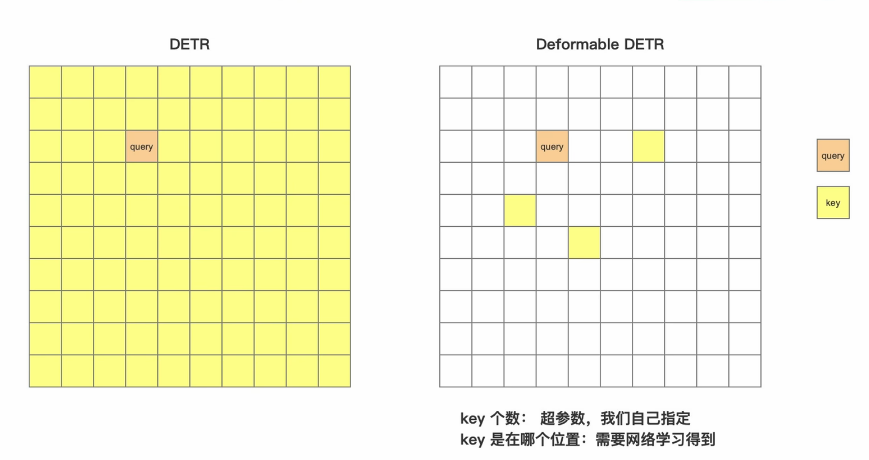
原始的DETR黄格子全部点亮,那就是query要和全图所有的位置都阿孙注意力,这样计算量就爆炸了(50*50个位置,要算2500*2500个相似度),那么deformable DETR只看几个关键点,每个query不再看全图,而是只看k个采样点(就是2500*4(k)),就是相当于老师问问题从一堆学生里面学几个最可能在知道的提问
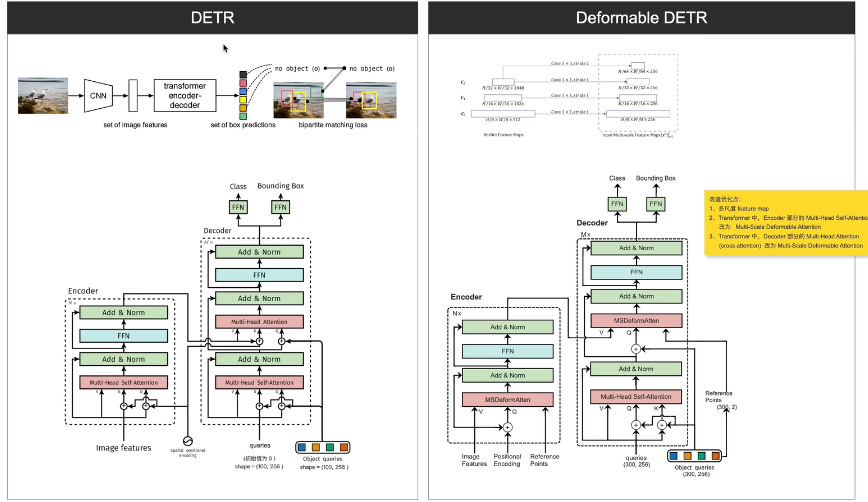
网络结构
-
使用cnn的backbone 从原图中提取feature map;一张 就是backbone 最后输出的feature map ;但是deformable detr 是使用backbone 从原图中提取多张feature map,几个中间层的输出也会提取出来,这样就构成的多尺度的feature map :作用:解决检测小物体分辨率差的问题分辨率大的feature map检测小物体有优势 大的检测大的有优势 这样两个都有 那么大小都可以
-


这个替换就是为了解决,模型收敛慢和计算量大的问题。因为之前再做self-attention 的时候,feature map里面的q要和所有其他的像素去做计算attention,计算量大 ;但是Deformable attention 每一个Q会和各k去做attention  没有k,因为都是Q学习得到的
没有k,因为都是Q学习得到的
backbone+多尺度特征图
backbone第一部分改造:多尺度特征(采样)

上面是ResNet-50的网络结构表,是deformable DETR中常用的backbone(主干网络)
输入: 3×608×888(3通道RGB图像,高608,宽888)
↓
ResNet-50(分5个stage)
↓
输出4个不同尺度的特征图(多尺度特征)
具体:
C3(layer2输出): H/8 × W/8 × 512 → 卷积→ 256通道
C4(layer3输出): H/16 × W/16 × 1024 → 卷积→ 256通道
C5(layer4输出): H/32 × W/32 × 2048 → 卷积→ 256通道
C6(额外下采样): H/64 × W/64 × 256(用3×3卷积,stride=2)
为啥要四个尺度?
Deformable DETR用多尺度特征:
大特征图(H/8×W/8):检测小物体,细节丰富
小特征图(H/64×W/64):检测大物体,语义丰富
4个尺度同时输入Transformer,兼顾大小物体
因为我们之后想要将这里得到的feature map都输入到transformer中,这三个featuremap肯定按我们想的要并行计算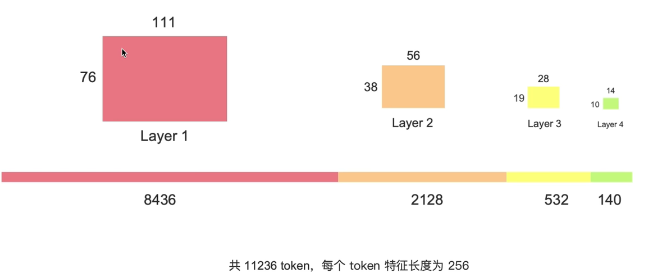
首先图像转化为向量,Flatten开,展平;把这几张feature map 首尾相连给concat(连接)起来,这样的话就能把他们一并输入transformer中计算。
为了保证能首尾相连,就要保证特征向量长度是一样的,也就是图像中每个像素的channel数是一样的,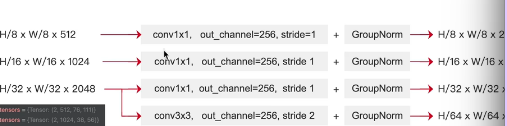 也就是提取这三个featuremap之后,我们要让他们分别去做1*1的卷积,把channel数都统一到256
也就是提取这三个featuremap之后,我们要让他们分别去做1*1的卷积,把channel数都统一到256
过一个groupnorm(一种归一化方法),神经网络训练的时候,数据分布会变化导致训练困难,收敛慢,归一化把数据拉到均值0,方差1的范围,稳定训练。
经过ResNet的layer2(C3): 原始: H × W 经过3次下采样(stride=2的卷积或池化) 每次尺寸减半: H → H/2 → H/4 → H/8 所以输出: H/8 × W/8 同理: C4(layer3): 再下采样1次 → H/16 × W/16 C5(layer4): 再下采样1次 → H/32 × W/32 C6(额外卷积): 再下采样1次 → H/64 × W/64每次下采样,尺寸减半,感受野翻倍,特征从局部细节走向全局语义。
这就是deformable detr的第一部分的改造(backbone)
backbone 第二部分改造:deformable attention 替换
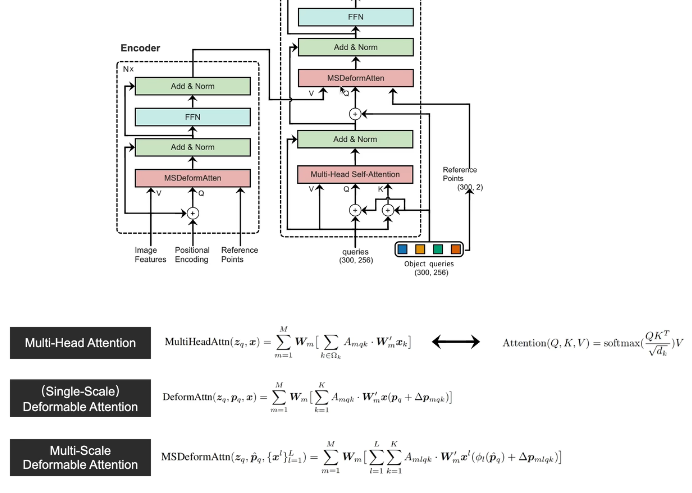
下面提供了三个公式
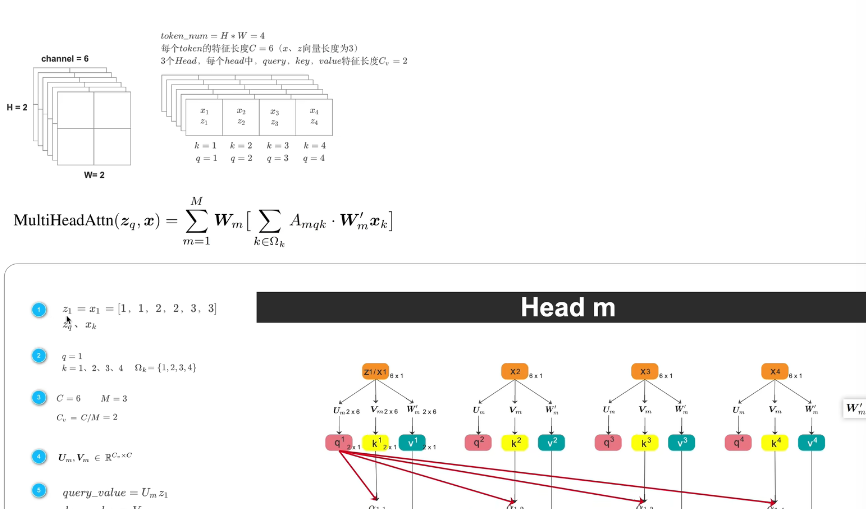
拿到2*2*6 的featuremap,展开之后,我们就得到了4个token,每个token特征向量长度=6,如果token1作为query(提问),token1的特征向量表达式就是z1,1-4个token就都是k,因为他自己也要对自己求相似度,token1是query的同时,它也是k,四个k的特征向量表达式就分别是x1234,token1作为query的时候她的特征向量z1,和他作为k的时候特征向量x1,内容是完全一样的(这个x和z 并不是处理后得到的qk 是在表明token的不同身份 )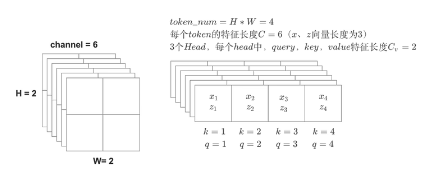
特征向量的长度用C来表示,就是=6 head的个数就是M表示=3,指定的head=3,m就是head的索引,这样qkv特征向量长度=2
UVW就是用来投影到低维的线性层,有多个,是可学习的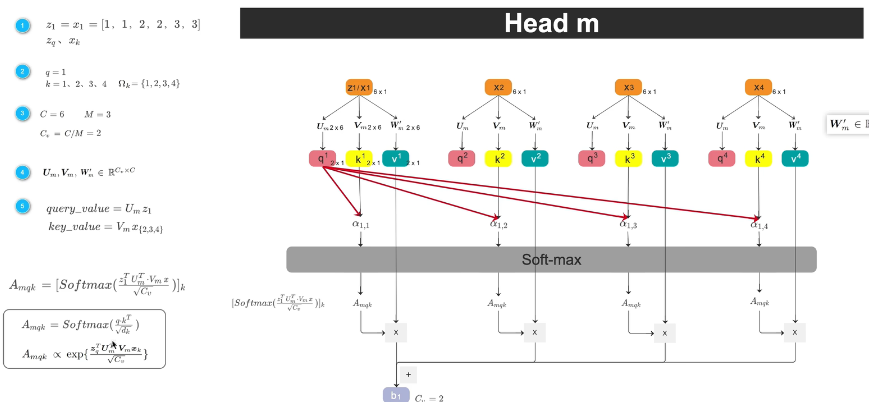
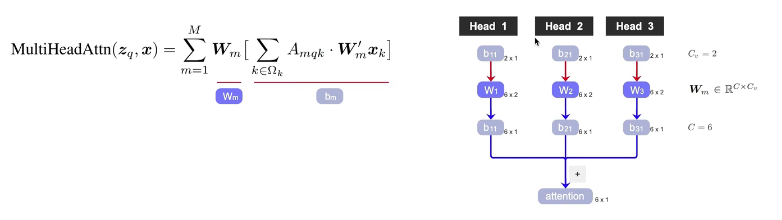
求多个head的b1 每个head里面都有求 在乘wm再加权和 多了个线性层,transformer是直接concat

multi-head attention 中这个key是遍历所有的像素的,deformable attention 中她的key只有几个,个数是我们自己指定的,第二个改动点就是x的取值pq表示的是query的坐标位置,△pmak表示的是k的坐标位置和query坐标位置的偏移量
接下来看看怎么生成的amqk和△pmqk: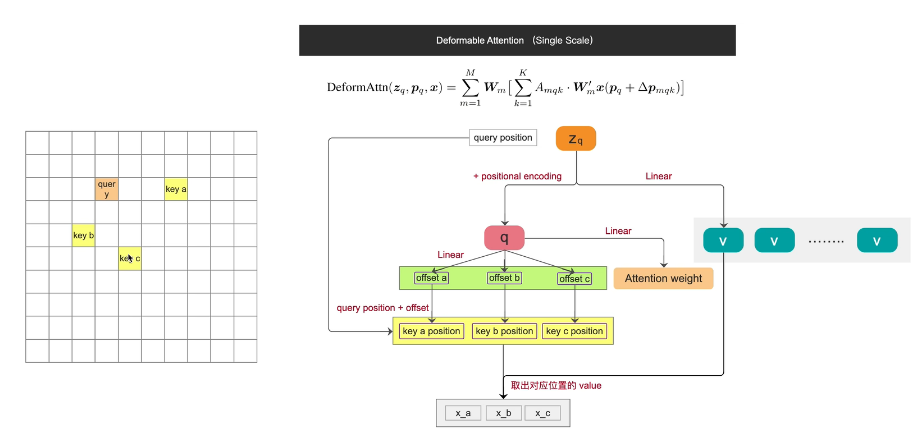
首先query的token杀死那个加上位置编码和position encoding 得到q ,然后做线性映射(全连接)得到三个三个位置偏移 就是那个△,之后我们用query的位置坐标加上刚才计算得到的偏移量,就得到了pq+△。
q再做线性映射 得到了attention weight 就是amqk
zq做线性映射就得到了token的v,后面几个v是其他token的v
用三个k的位置坐标 从feature取出对应位置的value x---abc 对应的就是三个k的x(oq+△)