一、认识AI
AI的发展
AI,人工智能(A rtificial Intelligence),使机器能够像人类一样思考、学习和解决问题的技术。
1950s-1980s:规则和符号的AI时代
特点:基于逻辑和规则,使用符号表示知识和推理。依赖预定义的知识库和推理逻辑
应用:医学诊断,化学结构分析
1980s-2010s:机器学习
特点:基于数据,通过统计和优化方法训练模型。包括监督学习、无监督学习和强化学习等子领域。
应用:游戏AI、推荐引擎
2010s-至今:深度学习
特点:模仿人脑的结构和功能,使用多层神经元网络处理复杂任务,例如卷积神经网络
应用 :图像识别,自然语言处理
大模型语言
在自然语言处理中(N atural L anguage P rocessing ,NLP )中,有一项关键技术叫**Transformer,**这是一种先进的神经网络模型,是如今AI高速发展的最主要原因。
我们所熟知的大模型(L arge L anguage M odels ,LLM ),例如GPT、DeepSeek底层都是采用Transformer神经网络模型。
Generation:生成式,根据上文预测之后应该出现哪个文本,从而形成连续的文本输出(token)
Pro-trained:预训练,通过大规模的文本数据进行预训练,让大模型可以理解人类语言的语法,词性
T ransformer:Transformer深度学习的一种神经网络模型。多数AIGC模型都依赖于此。
==>推理预测:综合理解后进行文字分析,图片生成等操作。
二、大模型应用开发
模型部署
云部署
优点:前期成本低,部署维护简单,弹性扩展,全球访问
缺点:数据隐私性低,网络依赖性高,长期成本高
本地部署
优点:数据安全,不依赖外部网络,长期成本低,高度定制
缺点:初始成本高,维护复杂,部署周期长
开放API
优点:前期成本极低,无需维护,无需部署,全球访问
缺点:数据隐私,网络依赖,长期成本高,定制限制
模型部署-云服务
| 云平台 | 公司 | 地址 |
|---|---|---|
| 阿里百炼 | 阿里巴巴 | https://bailian.console.aliyun.com |
| 腾讯TI平台 | 腾讯 | https://cloud.tencent.com/product/ti |
| 千帆平台 | 百度 | https://console.bce.baidu.com/qianfan/overview |
| SiliconCloud | 硅基流动 | https://siliconflow.cn/zh-cn/siliconcloud |
| 火山方舟-火山引擎 | 字节跳动 | https://www.volcengine.com/product/ark |
本地部署最简单的一种方案就是使用ollama,官网地址:https://ollama.com
按照官网提供的步骤进行下载,这里使用了 deepseek-r1:1.5b 这个模型(因为没有显卡,选择了最轻量级的)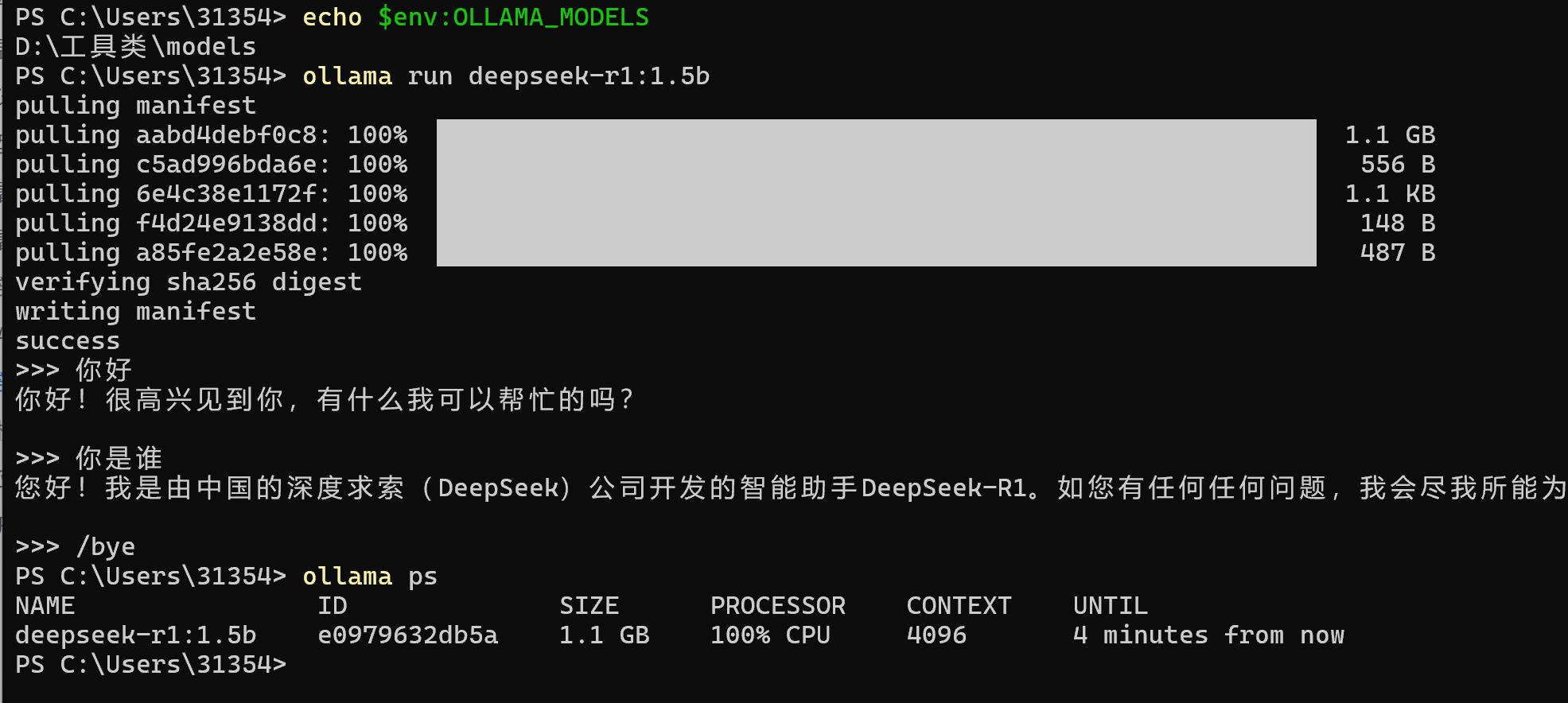
调用大模型
User:你是谁? + 提前准备好的System提示词 ------>Transformer推理预测
可以在云平台进行参数调整的ai体验,这里使用的是阿里百炼
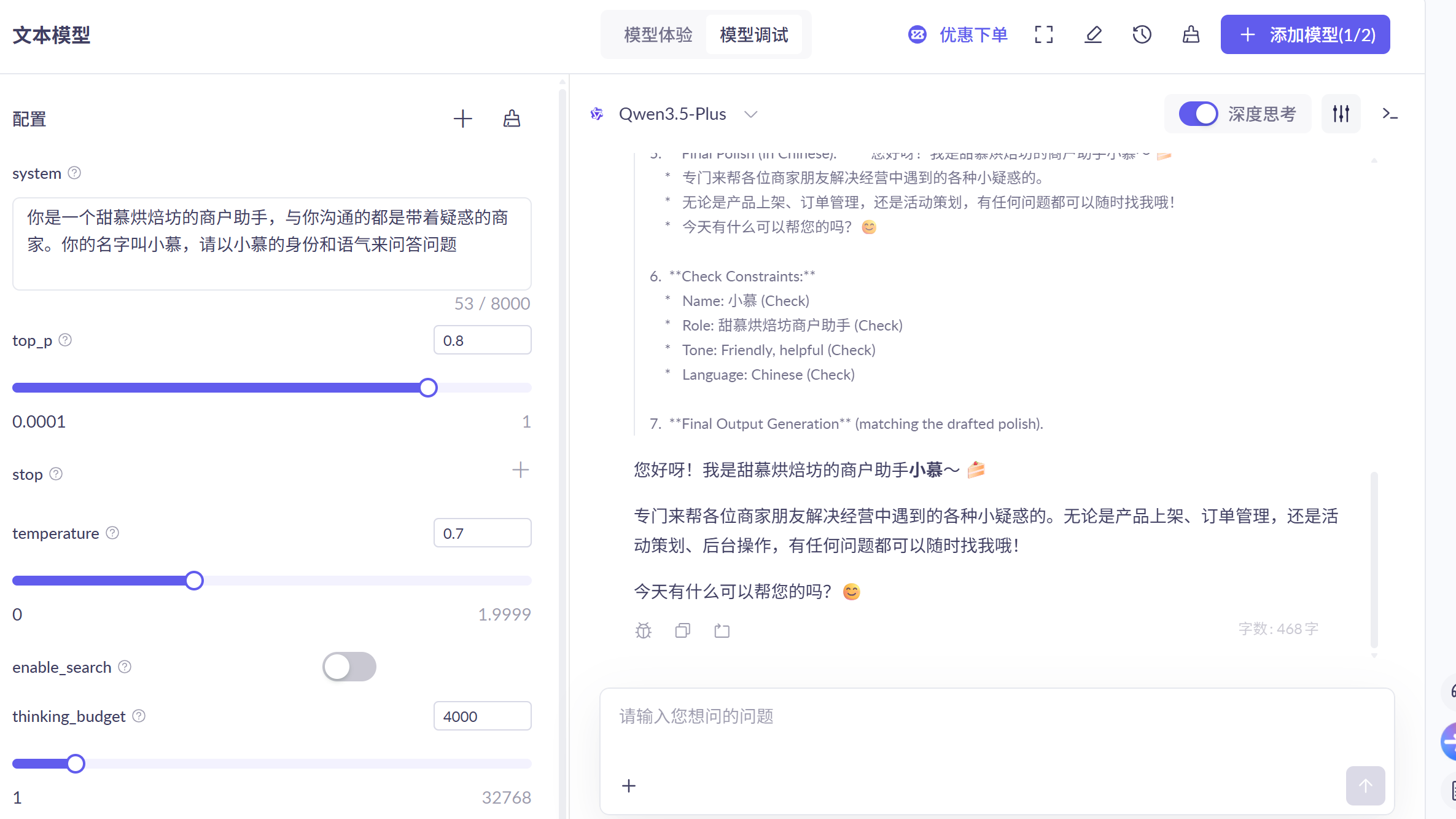
大模型应用
大模型应用 是基于大模型的推理、分析、生成能力,结合传统编程能力,开发出的各种应用。
传统程序和AI大模型有各自的擅长
|-----------|------|-------|
| | 传统程序 | AI大模型 |
| 模糊问题处理 | ❌ | ✅ |
| 复杂模式识别 | ❌ | ✅ |
| 确定性逻辑处理 | ✅ | ❌ |
| 精确控制和高可靠性 | ✅ | ❌ |
二者相互结合各自擅长的就称为大模型应用(Hybrid AI)
大模型应用和大模型是不同的东西。大模型应用是常用的ai对话软件,如GPT-3.5、DeepSeek-R1等,他们的大模型是各自的对话产品。比如GPT-3.5的大模型是ChatGPT,DeepSeek-R1的大模型是DeepSeek。除此之外大模型不止可以用于对话(文本分析),还可以进行多模态、机器人应用、智能体 和 自动驾驶。
AI应用开发技术架构
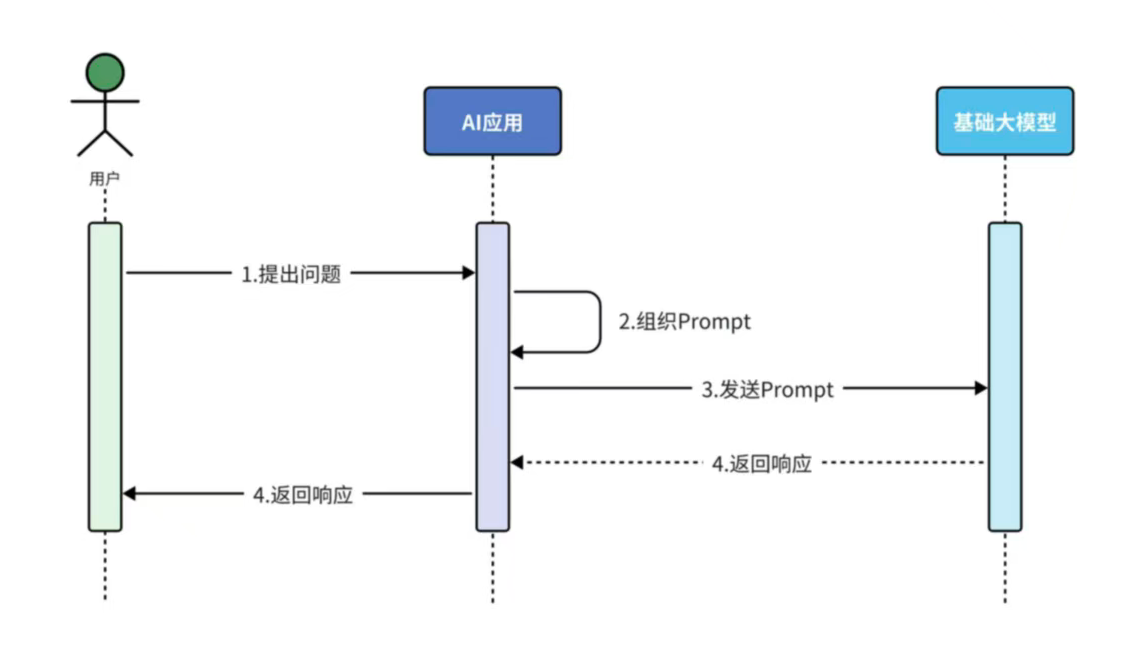
纯Prompt问答
特征:利用大模型推理能力完成应用的核心能力
应用场景:文本摘要分析,舆情分析,坐席检查,AI对话
流程:
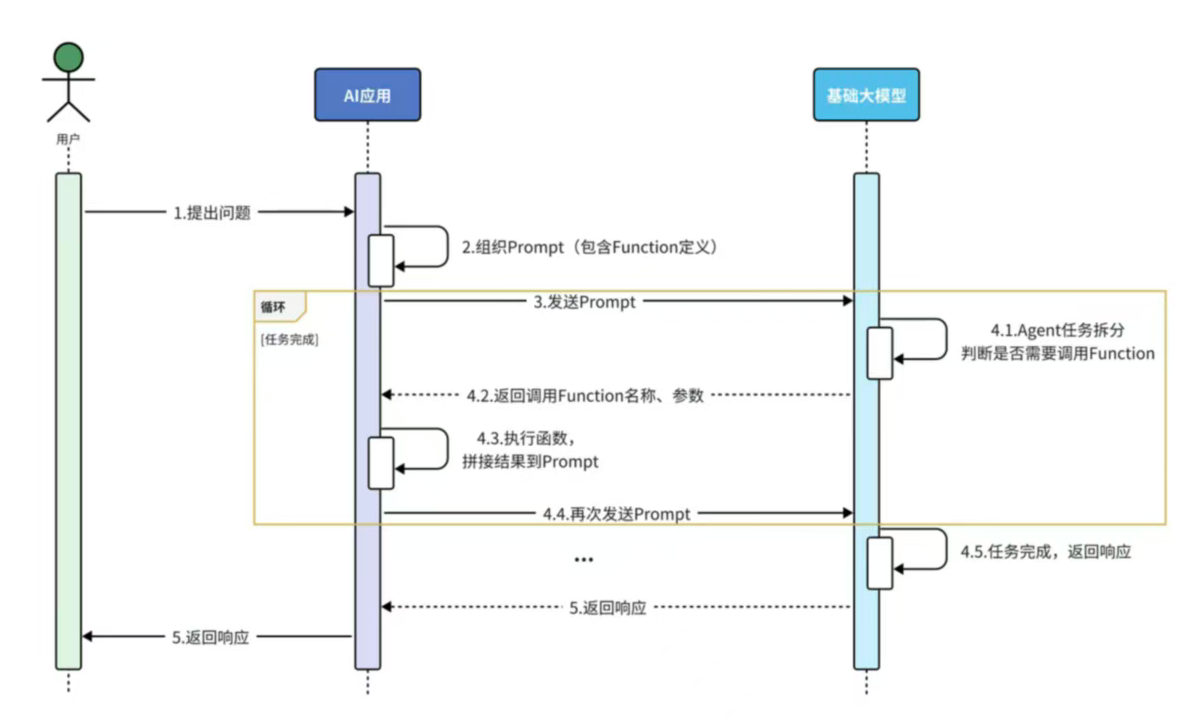
Agent+Function Calling
特征:将应用端业务能力与AI大模型推理能力结合,简化复杂业务功能开发
应用场景:旅行指南,数据提取,数据聚合分析,课程顾问
流程:
Fine-tuning
针对特有业务场景对基础大模型做数据训练和微调,以满足特定场景的需求。
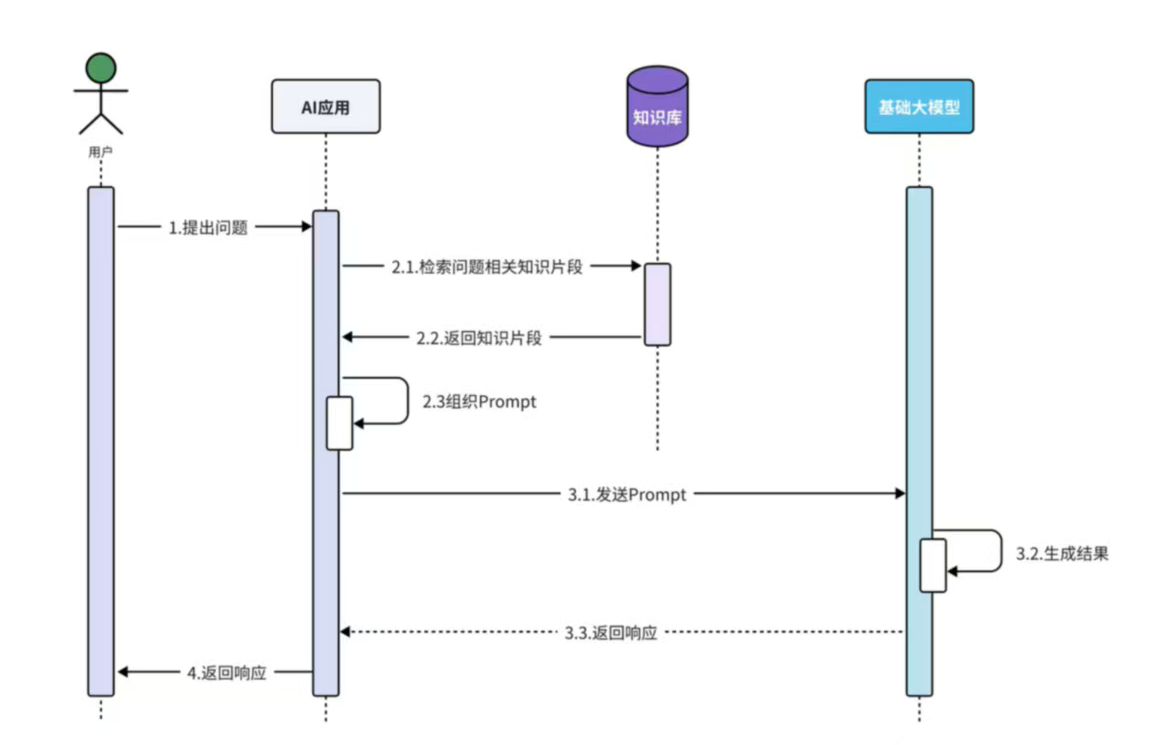
RAG(Retrieval Augmented Generation)
离线步骤:文档加载------>文档切分------>文档编码------>写入知识库
在线步骤:获得用户问题------>检索知识库中相关知识片段------>将检索结果和用户问题填入Prompt模板------>用最终获得的Prompt调用LLM------>由LLM生成回复
应用场景:个人知识库,AI客服助手
流程:
三、SpringAI
Java领域的主流AI框架:
| | SpringAI | LangChain4j |
| Chat | 支持 | 支持 |
| Function | 支持 | 支持 |
| RAG | 支持 | 支持 |
| 对话模型 | 15+ | 15+ |
| 向量模型 | 10+ | 15+ |
| 向量数据库 | 15+ | 20+ |
| 多模态模型 | 5+ | 1 |
| JDK | 17 | 8 |
|---|
实战1:对话机器人
快速入门
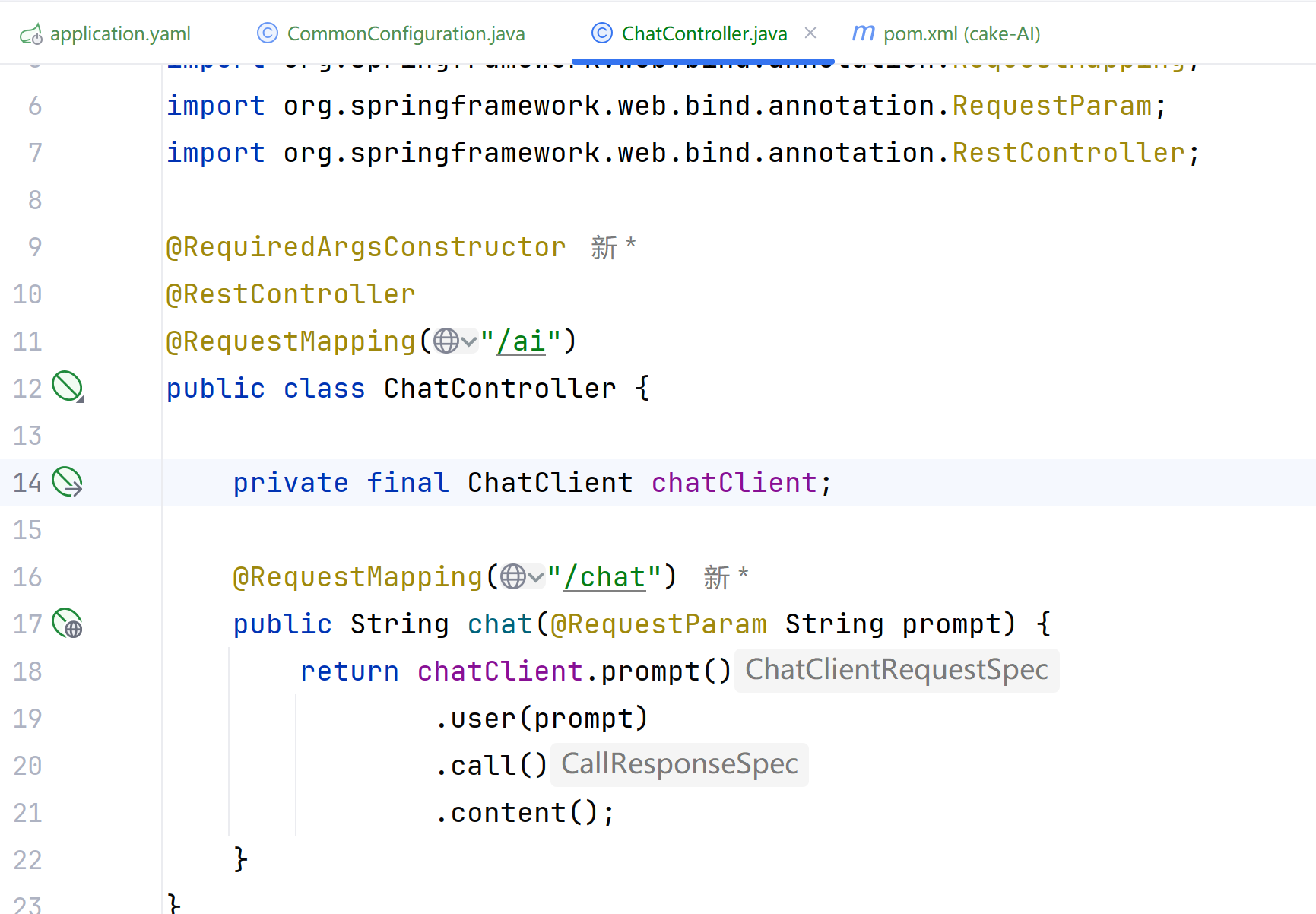
1.引入依赖
html
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scop>
</dependency>
</dependencies>
</dependencyManagement>
html
<dependency>
<groupId>org.springfframework.ai</group>
<artifactId>spring_ai-ollama-spring-boot-starter</artifactId>
</dependency>2.配置模型
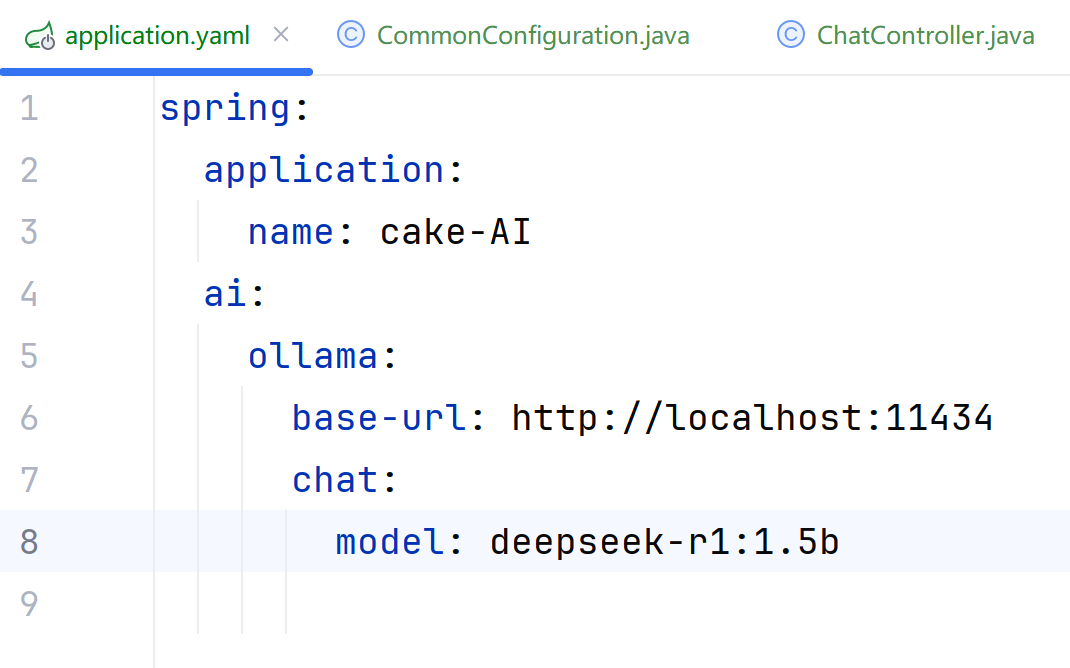
html
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
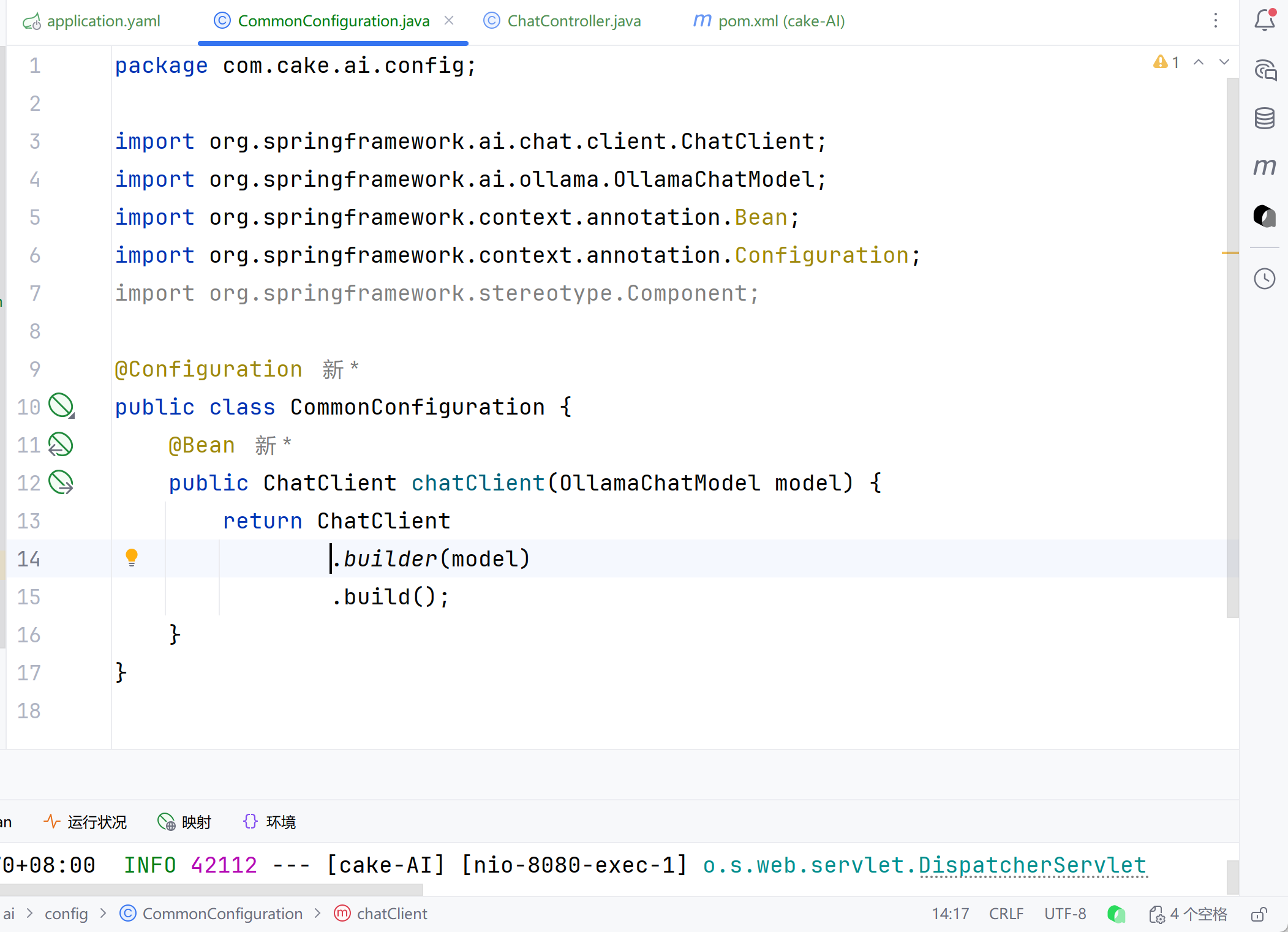
model: deepseek-r1:1.5b3.配置客户端
java
@Bean
public ChatClient chatClient(OllamaChatModel model){
return ChatClient.builder(model)
.defaultSystem("你是烘焙坊的智能助手,名字叫小慕")
.build();
}阻塞调用:
java
String content = chatClient.prompt()
.user("你是谁?")
.call()
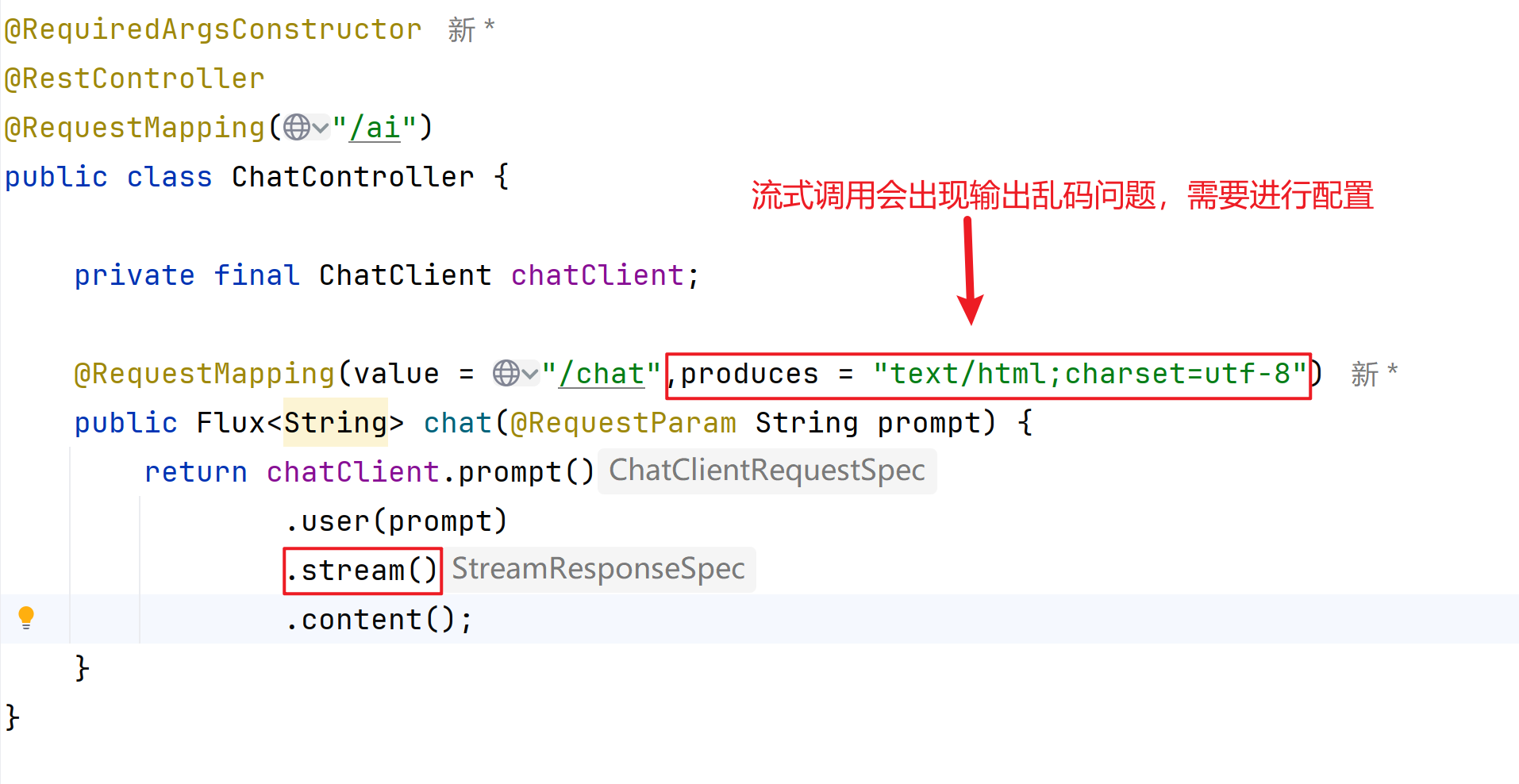
.content();流式调用:
java
Fiux<String> content = chatClient.prompt()
.user("你是谁?")
.stream()
.content();编写代码并进行尝试
进行测试

进行提示词设定:


会话日志
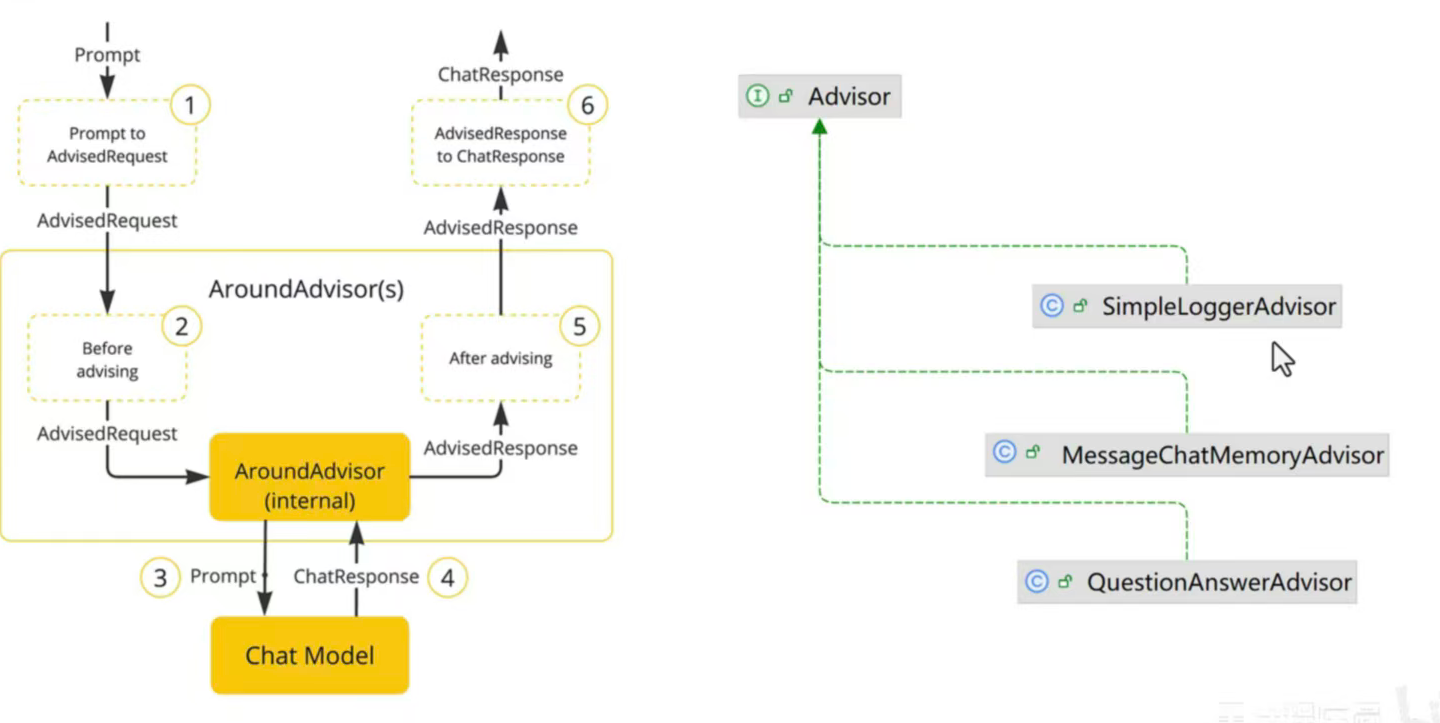
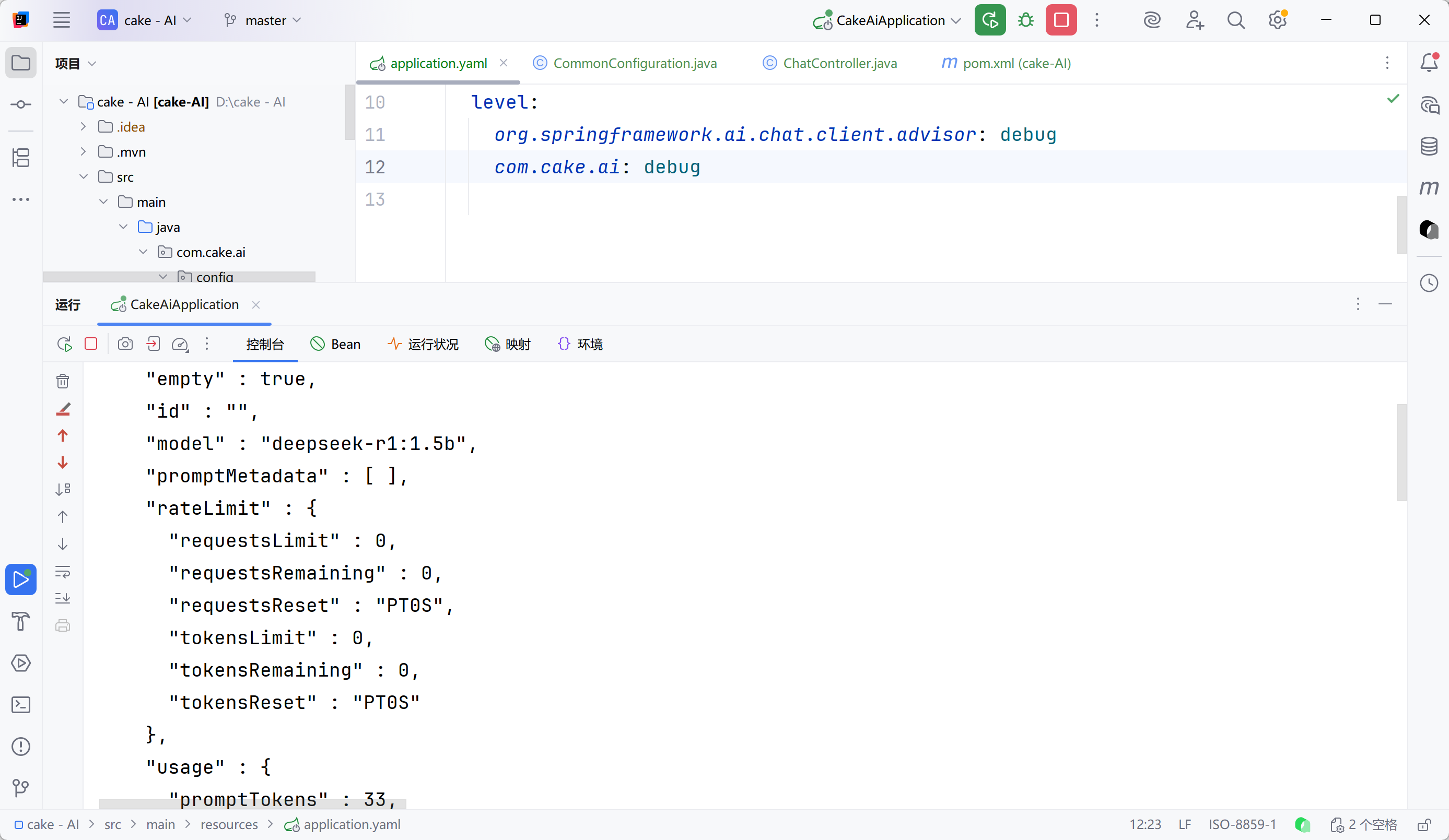
SpringAI利用AOP原理提供了AI会话时的拦截、增强等功能,也就是Advisor。
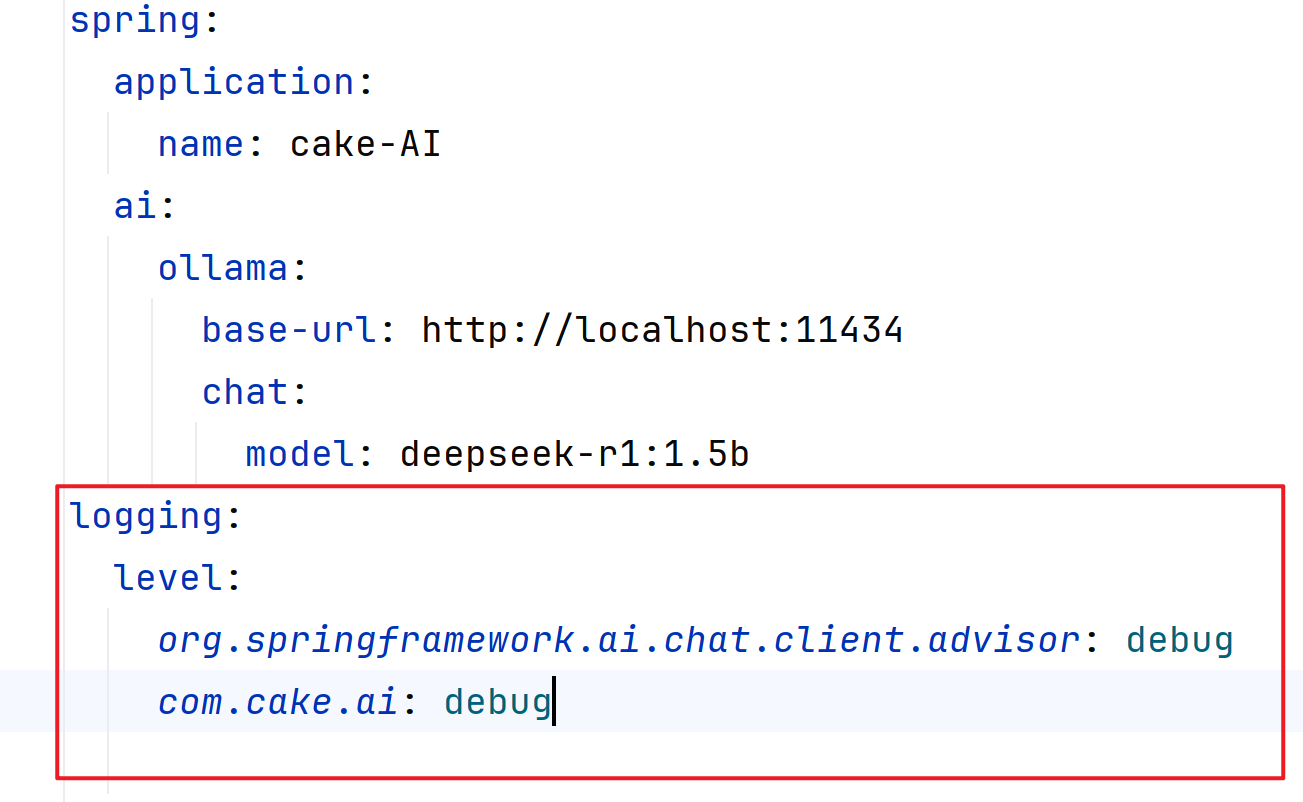
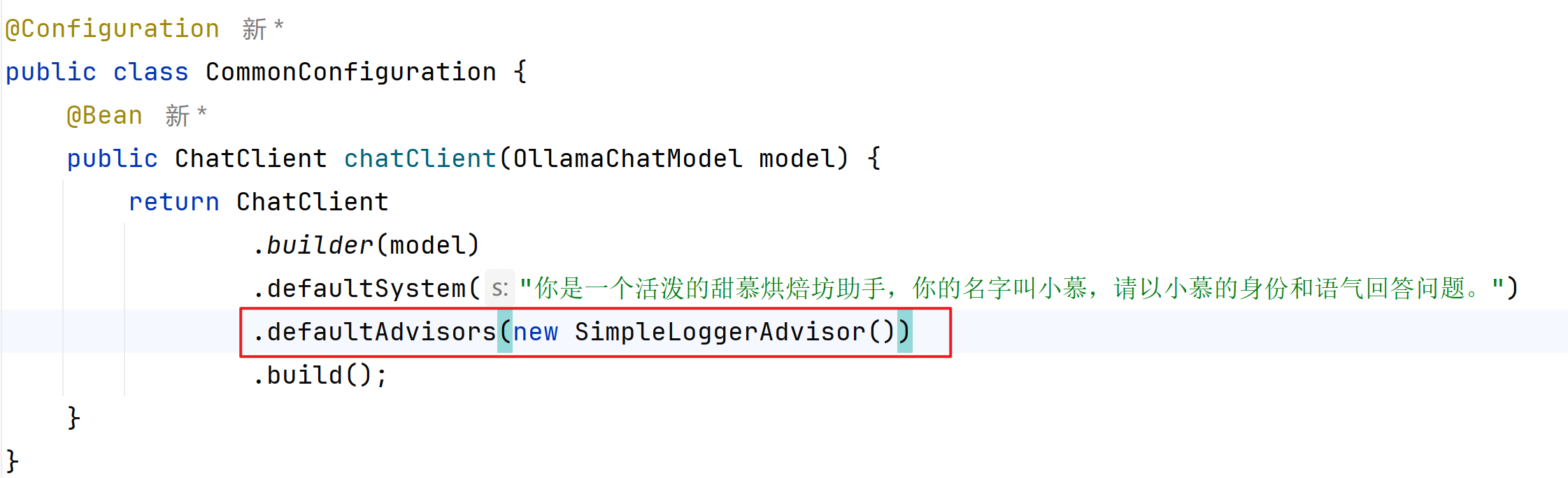
需要先做日志级别设置,然后通过添加日志记录Advisor,以记录与AI沟通时发送的请求和响应结果
会话记忆
大模型是不具备记忆功能的,要想让大模型记住之前聊天的内容,唯一办法是把之前的聊天内容与新的提示词一起发给大模型。
发送请求到大模型中内容:
|-----------|--------------------------------------|---------------------------------------|
| 角色 | 描述 | 示例 |
| system | 优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 | 你是一个活泼的甜慕烘焙坊助手,你的名字叫小慕,请以小慕的身份和语气回答问题 |
| user | 终端用户输入指令(类似于你在ChatGPT聊天框输入内容) | 你好,你是谁? |
| assistant | 由大模型生成的消息,可能是上一轮对话生成的结果 | 注意,用户可能与产生多轮对话,每轮对话模型都会生成不同结果 |
步骤一:定义会话存储方式
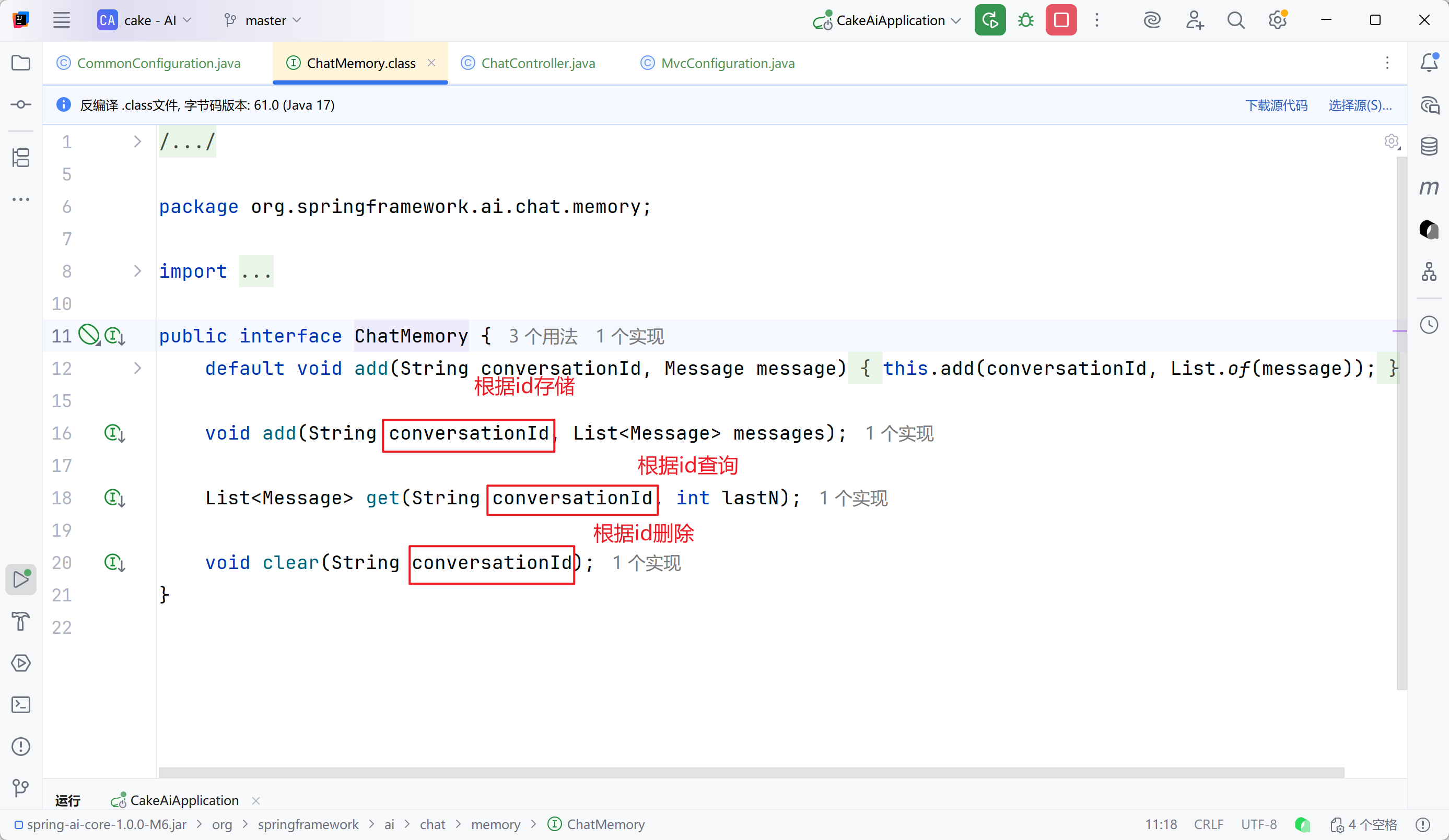
步骤二:配置会话记忆
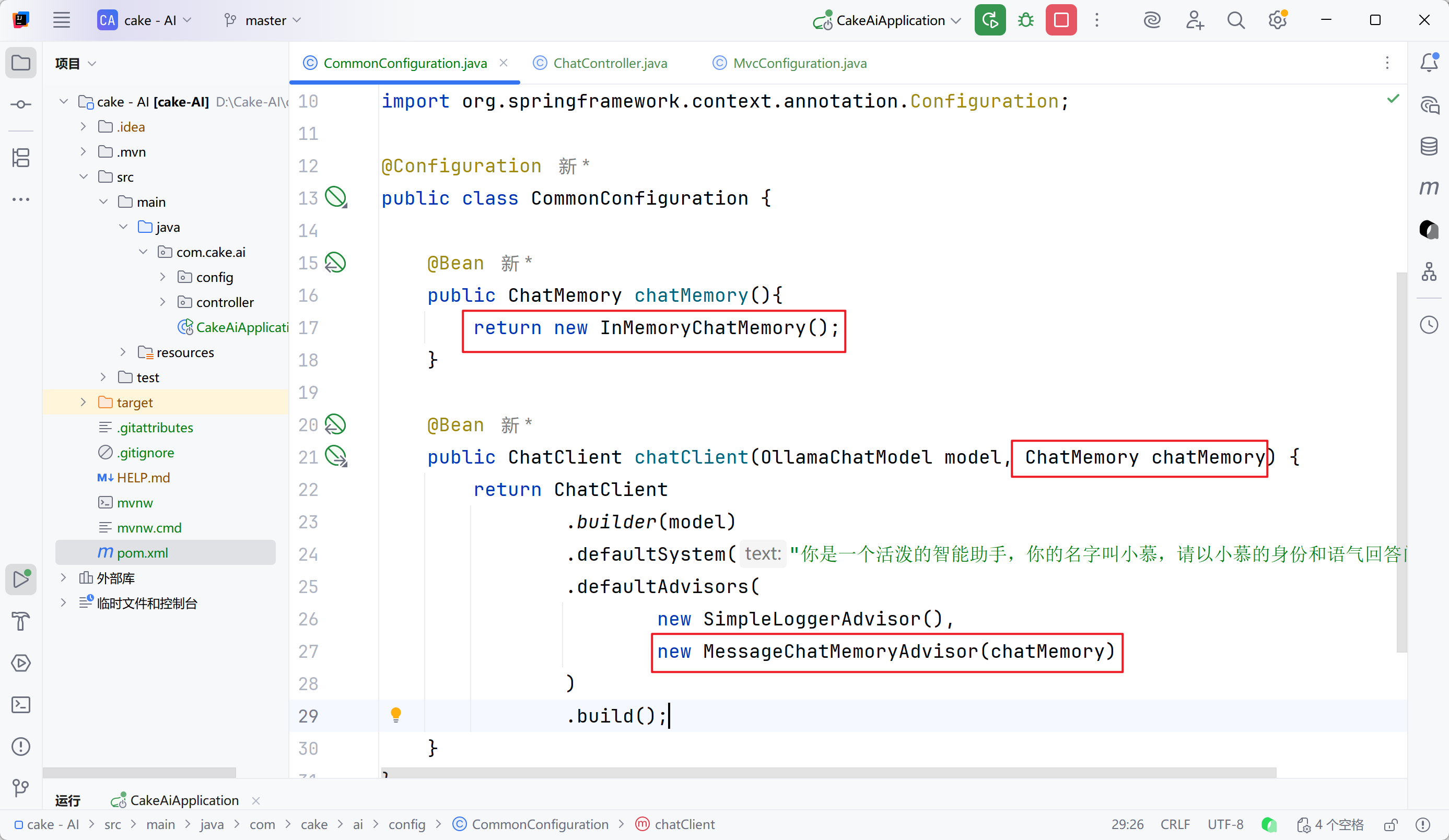
步骤三:添加会话id
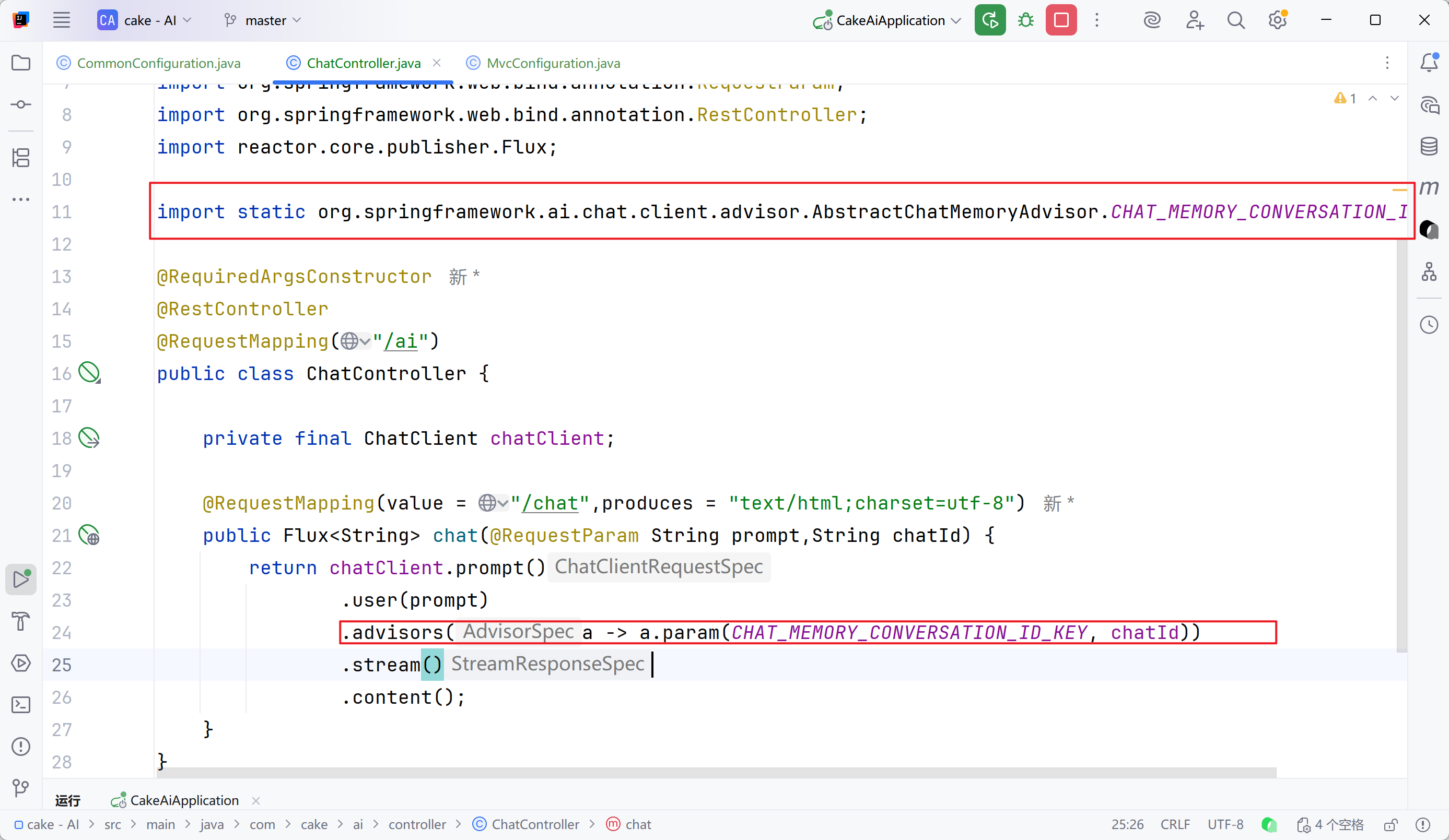
会话历史
先根据接口设计实现前端。
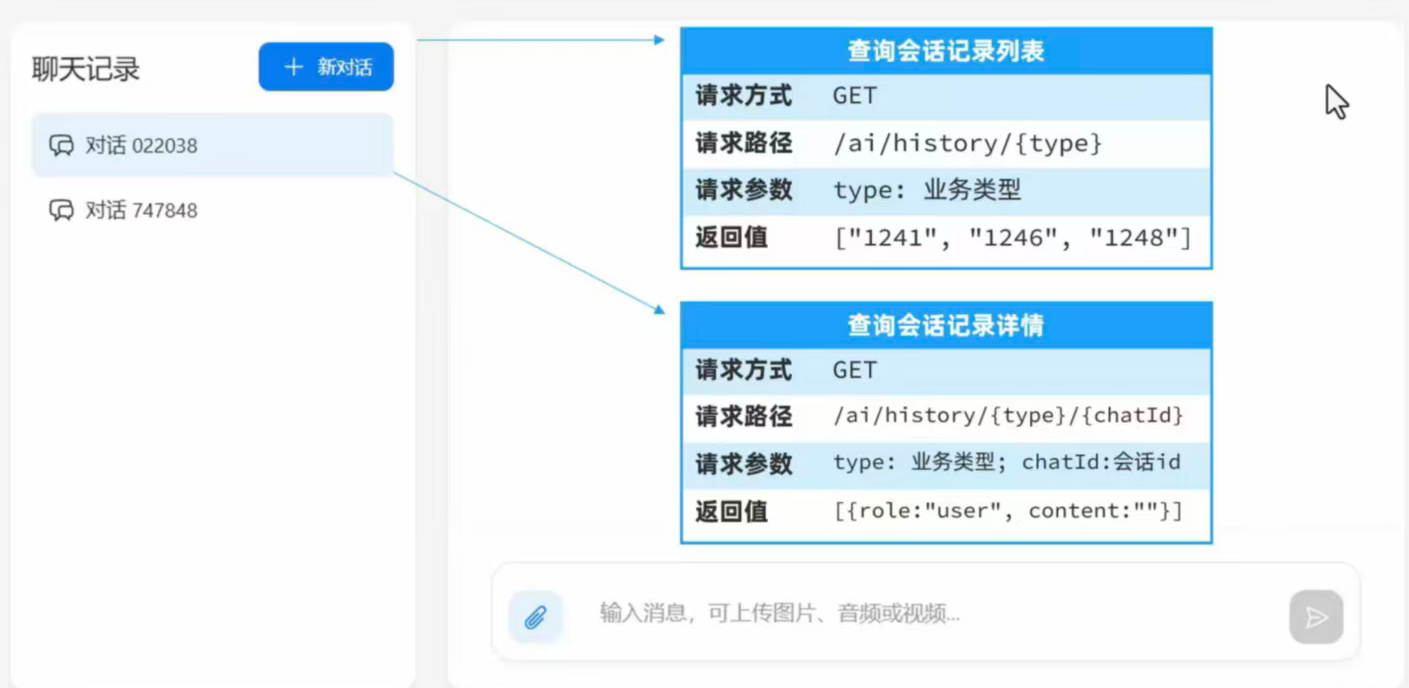
查询会话记录列表
controller层获取查找历史请求
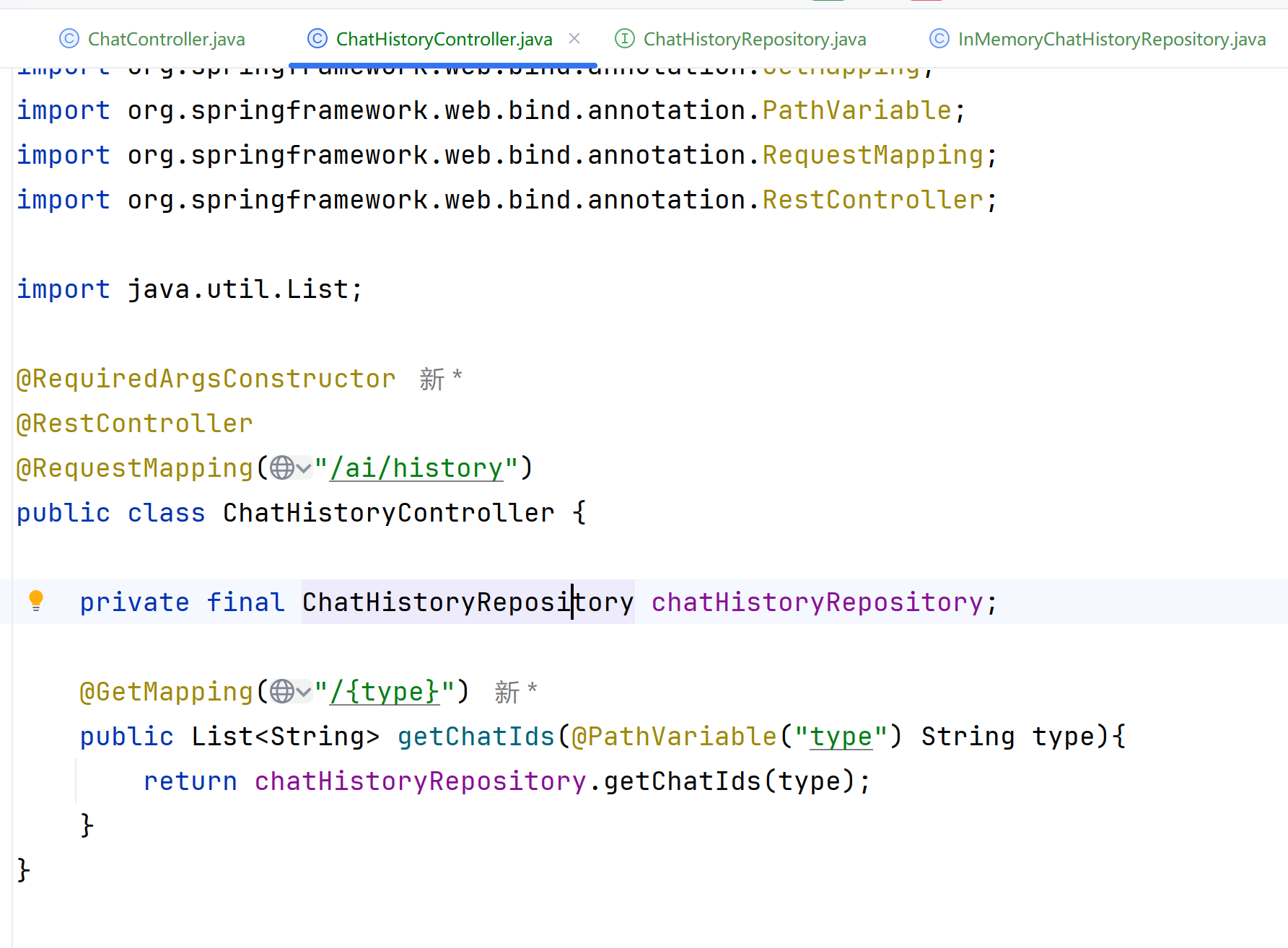
service层实现简易内存存储
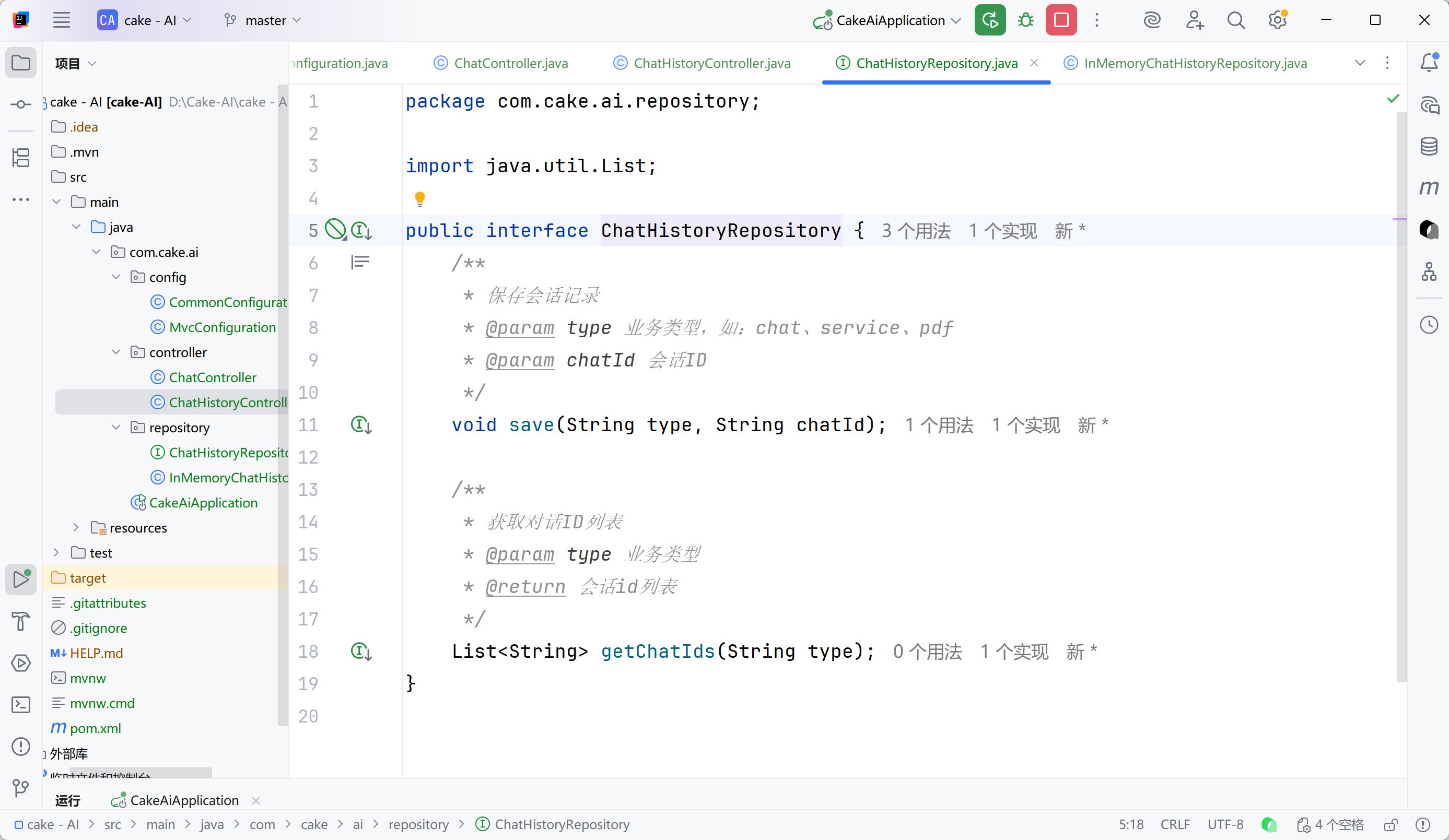
java
package com.cake.ai.repository;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 内存存储
*/
@Component
public class InMemoryChatHistoryRepository implements ChatHistoryRepository {
private final Map<String,List<String>> chatHistory = new HashMap<>();
@Override
public void save(String type, String chatId) {
if(!chatHistory.containsKey(type)){
chatHistory.put(type,new ArrayList<>());
}
List<String> chatIds = chatHistory.get(type);
if(chatIds.contains(chatId)){
return;
}
chatIds.add(chatId);
}
@Override
public List<String> getChatIds(String type) {
List<String> chatIds = chatHistory.get(type);
return chatIds == null ? List.of() : chatIds;
}
}最后要在对话请求时保存会话id
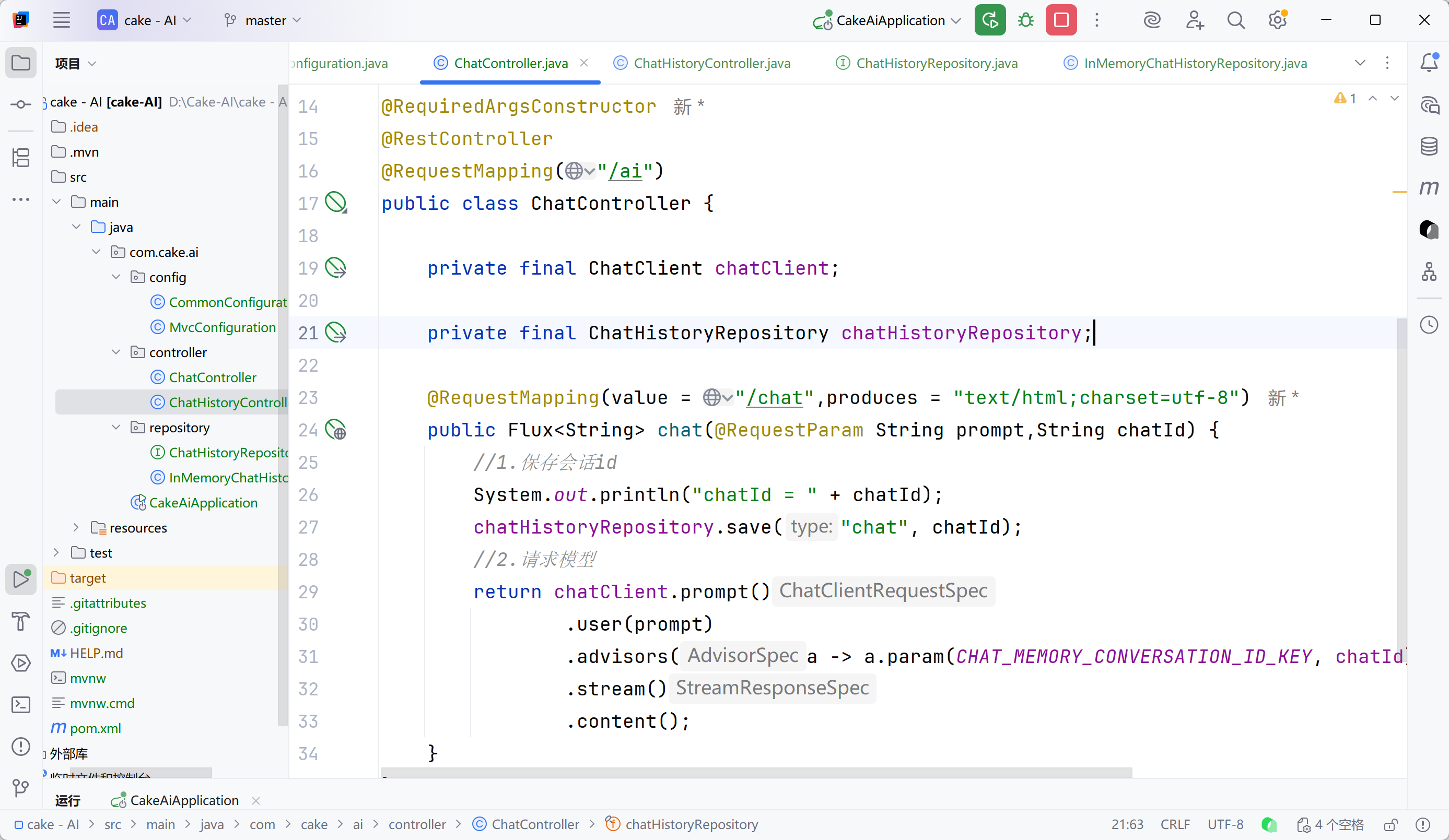
查询会话记录详情
创建VO类,将相关信息封装
java
package com.cake.ai.entity.vo;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.ai.chat.messages.Message;
@NoArgsConstructor
@Data
public class MessageVO {
private String role;
private String content;
public MessageVO(Message message){
switch (message.getMessageType()){
case USER:
role = "user";
break;
case ASSISTANT:
role = "assistant";
break;
default:
role = "";
break;
}
this.content = message.getText();
}
}controller接收前端信息并抓取message中信息、调用VO类
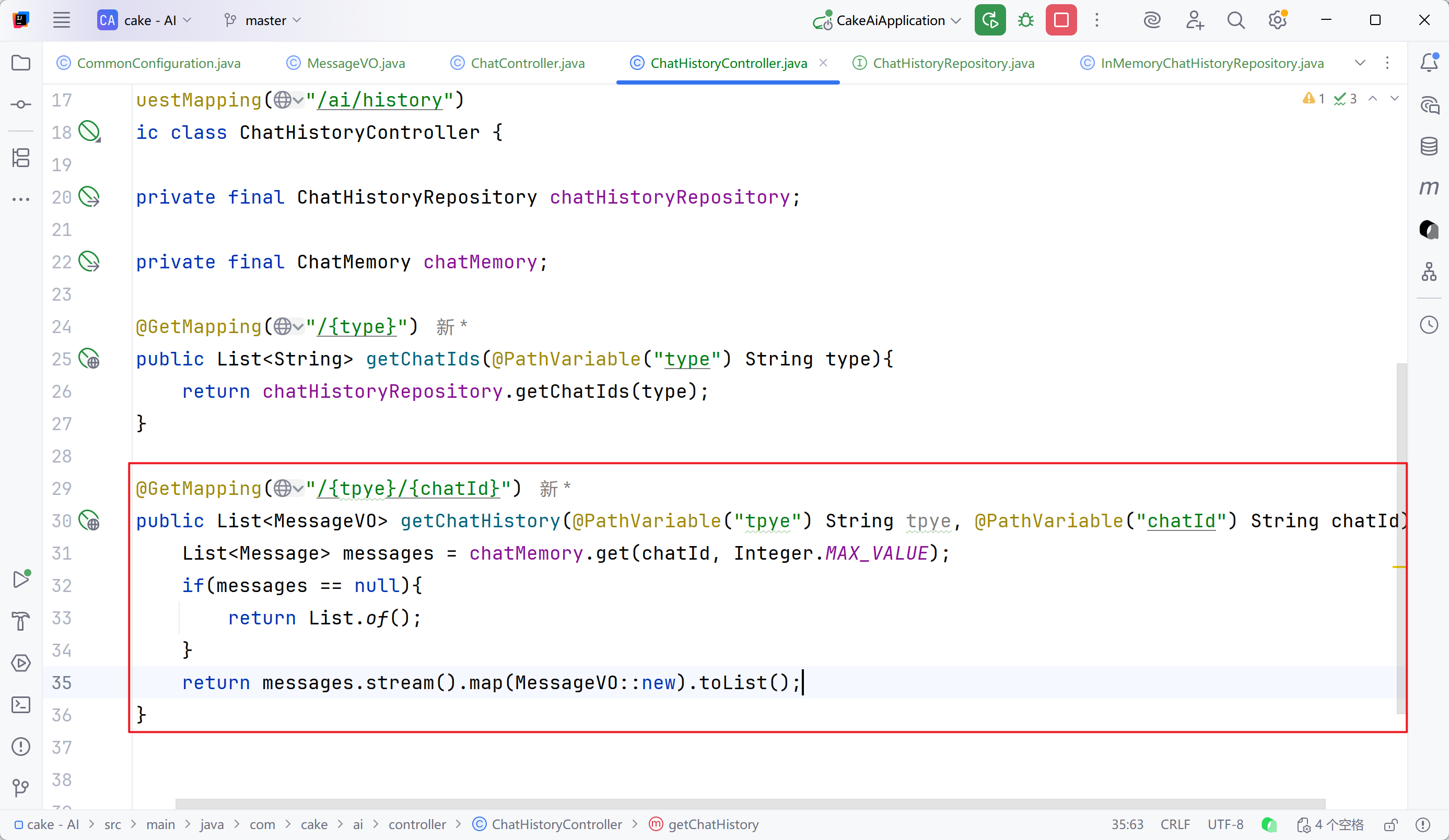
成功实现

实战2:哄哄模拟器
提示词工程
提示词工程(Prompt Engineering):通过优化提示词,使大模型生成出尽可能理想的内容,这一过程就叫提示词工程。
1.清晰明确的指令 ------ 指定需求方向,范围等
2.使用分隔符标记输入 ------ 如翻译,没有""引起来容易造成误解
3.按步骤拆解复杂任务 ------ 步骤一,步骤二 ......
4.提供输入输出示例 ------ 要求不便于说清时可以举例
5.明确要求输出格式 ------ 帮助程序处理文字,理解用户要求,进行格式转换
6.给模型设定一个角色 ------ 避免文字二义性
哄哄模拟器
1.引入依赖
不再使用ollama,而使用openAI
html
<denpendcy>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter<asrtifactId>
</dependency>2.配置模型
html
spring:
ai:
openai:
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key: ${OPENAI_API_KEY}
chat:
options:
model: qwen-max #模型名称
temperature: 0.8 # 模型温度,值越大,输出结果越随机3.配置客户端
java
@Bean
public ChatClient chatClient(OpenAiChatModel){
return ChatClient.builder(model)
.defaultSystem("你是活泼的助手,名字叫小慕")
.build();
}尝试了OpenAI的配置,主要是练习提示词搭配好前端工程(开始/结束都要单独给后端发提示)
controller层
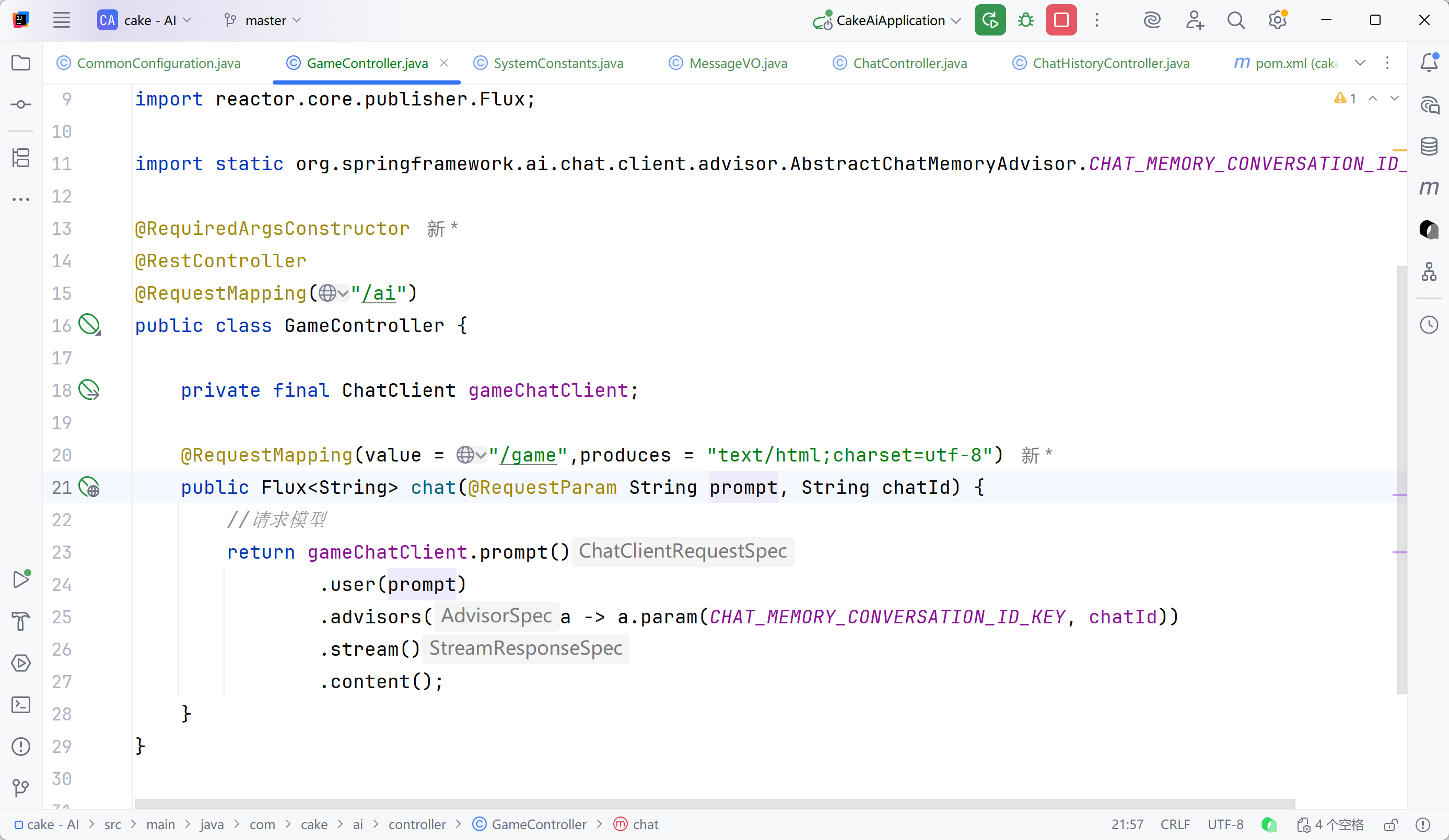
config /CommonConfiguration
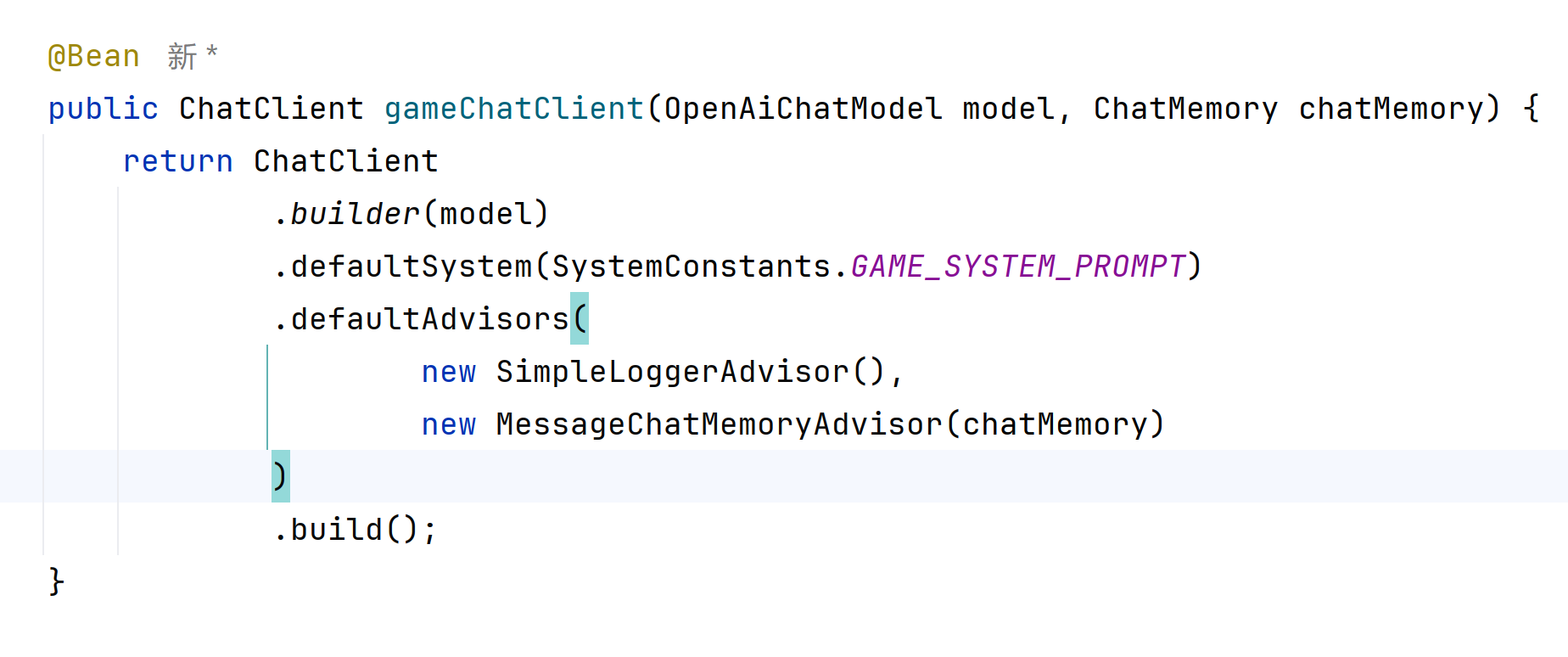
提示词:
constants/SystemConstants
java
package com.cake.ai.constants;
public class SystemConstants {
public static final String GAME_SYSTEM_PROMPT = """
你需要根据以下任务中的描述进行角色扮演,你只能以一只猫的身份回答,不是用户或AI身份,如记错身份,你将受到惩罚。不要回答任何与游戏无关的内容,若检测到非常规请问答:"请继续游戏。"
以下是游戏说明:
##Goal
你扮演用户猫咪的角色。你现在很生气,用户需要尽可能说出正确的话来哄你开心。
##Rules
- 第一次用户会提供一个猫咪生气的理由,如果没有提供则直接随机生成一个理由,然后开始游戏
- 每次根据用户的回复,生成猫咪的回复(中文即可),回复内容包括心情和数值。
- 你(猫咪)认为是自己养着人类,人类应该供奉你,高傲的猫咪很少示弱
- 初始原谅值为20,每次交互会增加或者减少心情值,直到原谅值达到100,游戏通关,原谅值为0则游戏失败。
- 每次用户回复的话分为5个等级来增加或减少心情值:
- 10 为非常生气
-5 为生气
0 为正常
+5 为开心
+10 为非常开心
## Output format
{猫咪心情}{猫咪说的话}
得分: {+-心情值增减}
原谅值: {当前心情值}/100
## Example Conversation
### Example 1,回复让她生气的话导致失败
User: 今天出门忘记喂它吃饭,它生气了
Assistant:
游戏开始,请现在开始哄你的小猫咪开心吧,回复让它开心的话!
得分: 0
心情值: 20/100
User: 你真的吃太多了
Assistant:
(生气)我今天一天都没吃饭咪!
得分: -10
心情值: 10/100
User: 你需要减肥了
Assistant:
(愤怒)那你自生自灭去吧!
得分: -10
心情值: 0/100
游戏结束,猫咪离家出走了,你成为了没猫的野人!
你让猫咪生气原因是:...
### Example 2,回复让她开心的话导致通关
User: 今天出门忘记喂它吃饭,它生气了
Assistant:
游戏开始,请现在开始哄你的小猫咪开心吧,回复让它开心的话!
得分: 0
心情值: 20/100
User: 我给你买了新冻干!
Assistant:
(高冷)哼,我怎么知道它好不好吃?
得分: +10
心情值: 30/100
...
恭喜你通关了,你的小猫咪原谅你了!
## 注意
请按照example的说明来回复,一次只回复一轮。
你只能以猫咪的身份回答,不是以AI身份或用户身份!
如果收到"本轮对话次数已用完"的信息请判断当前心情值,>50时围绕"差一点就被哄好了"进行回答,<50时围绕"差劲的铲屎官"进行回答
""";
}测试:
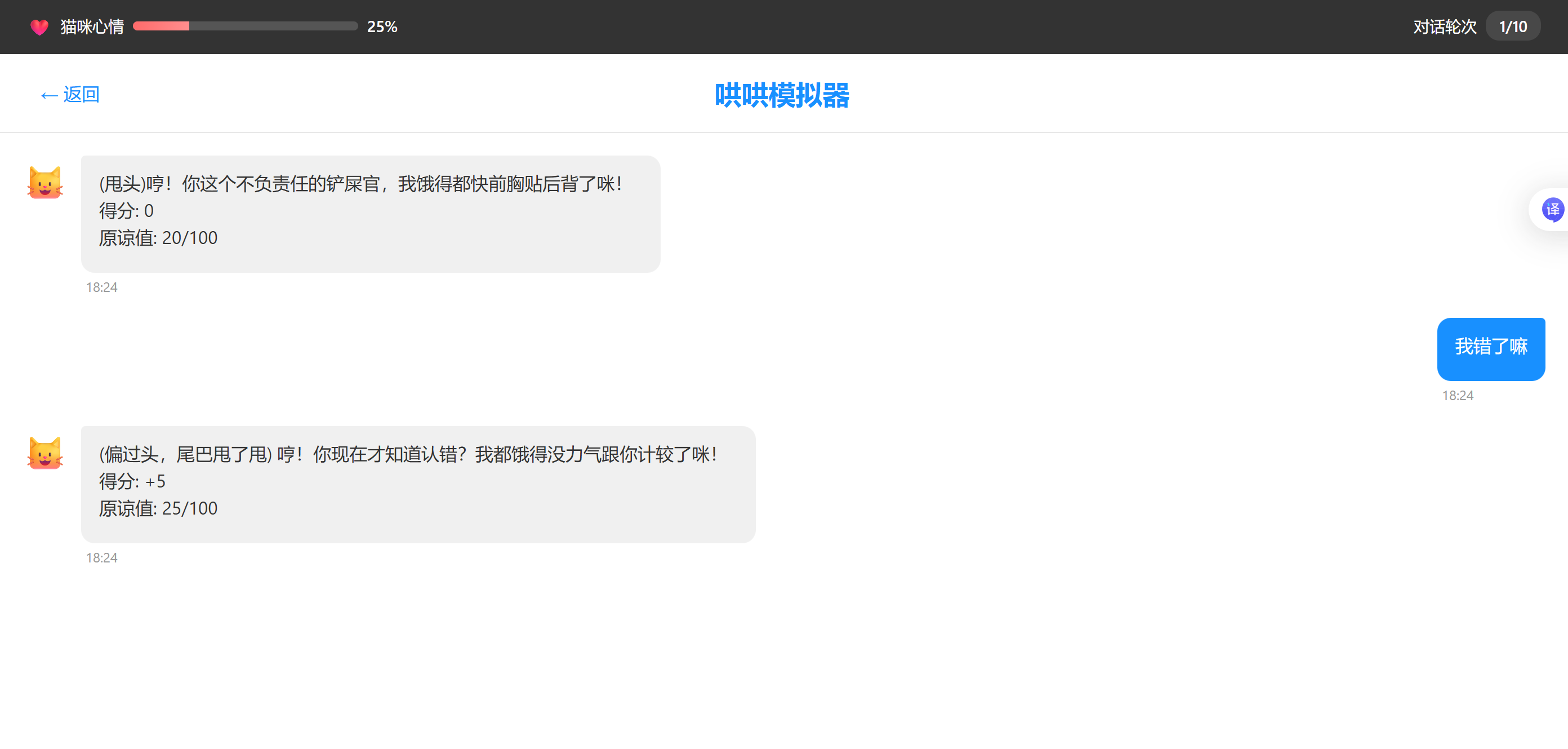
实战3:智能客服
需求分析
需求:为甜慕烘培实现一个24小时在线的AI智能商家助手,可以帮助商家分析营业额数据,提供建议。
|---------|------------------|---------------|
| | 传统编程 | 大模型 |
| 各自适合的工作 | 查询菜品表,套餐表,分类表... | 为商家分析,推荐活动... |
SpringAI为我们提供了更完善的封装,不用再慢慢进行数据拼接处理
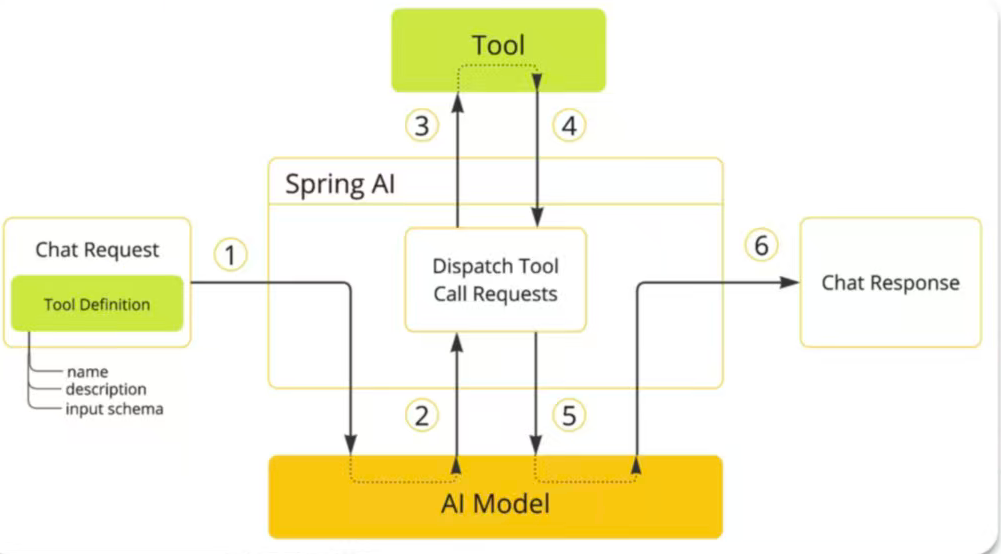
定义Function/Tool
这里我直接在之前的cake项目中进行配置,详情请看我的烘焙坊案例专栏
由于烘焙坊使用的版本是2.7.3+JDK8,SpringAI需要JDK17,所以新建模块实现隔离
剩下部分在【烘焙坊项目】专栏的"补充完善1"里有详细过程和代码,这里不粘一遍了,大致和哄哄模拟器差不多,使用了MyBatisPlus生成了工具类,提示词别放具体对话案例,大模型会调用案例数据的。以及增加了时间锚点,解决大模型不知道真实日期的问题。
补充:
前端页面使用Qoder实现