前言
神经网络模型是通过模仿生物神经网络结构和功能的计算模型,由大量神经元(加权求和 + 激活函数)相互连接构成,通过层间连接实现特征提取与规律学习。
神经网络概述
1. 什么是神经网络
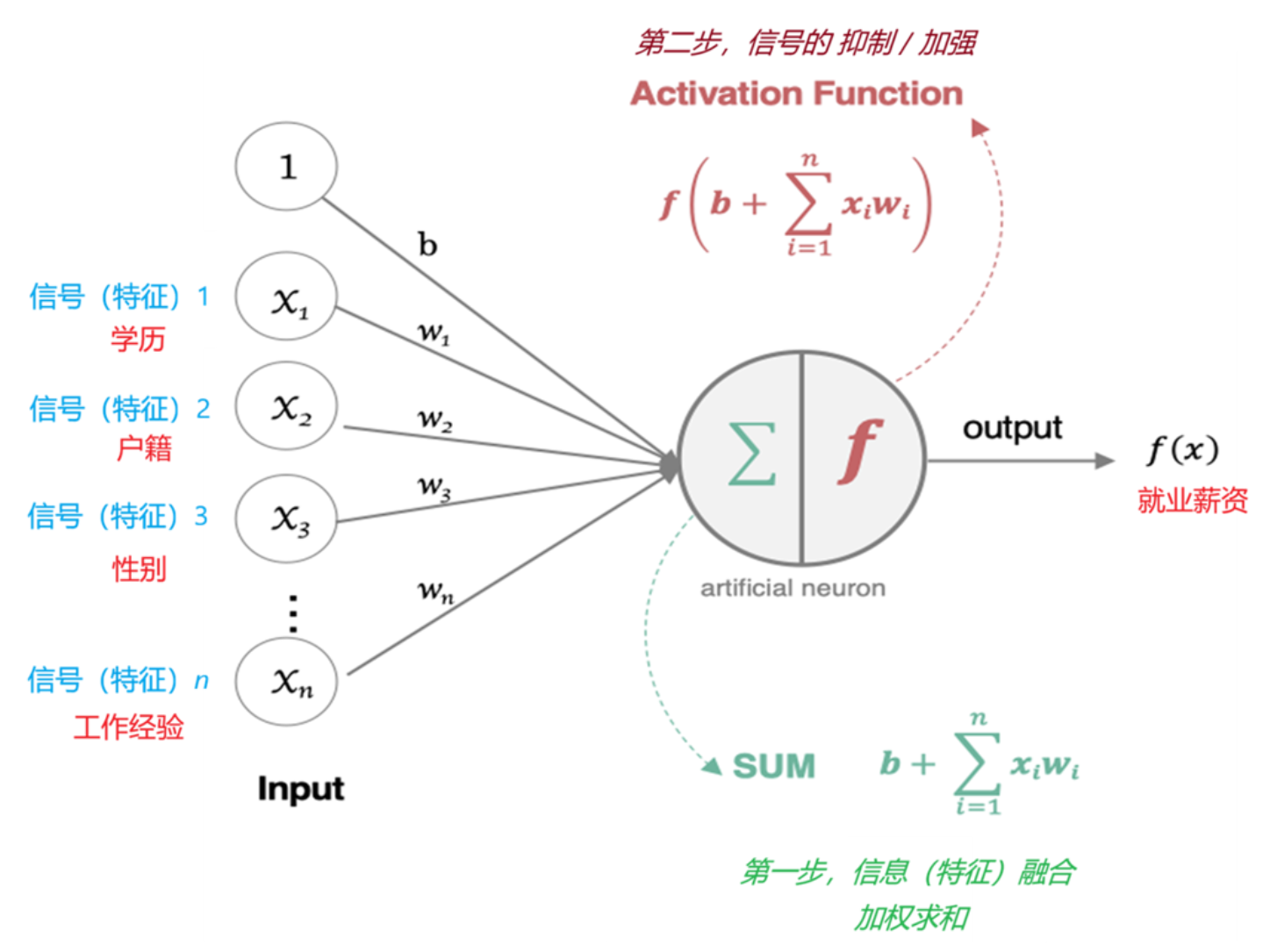
人工神经网络(ANN) 是一种模仿生物神经网络结构和功能的计算模型,由众多神经元连接而成。
2. 生物神经元
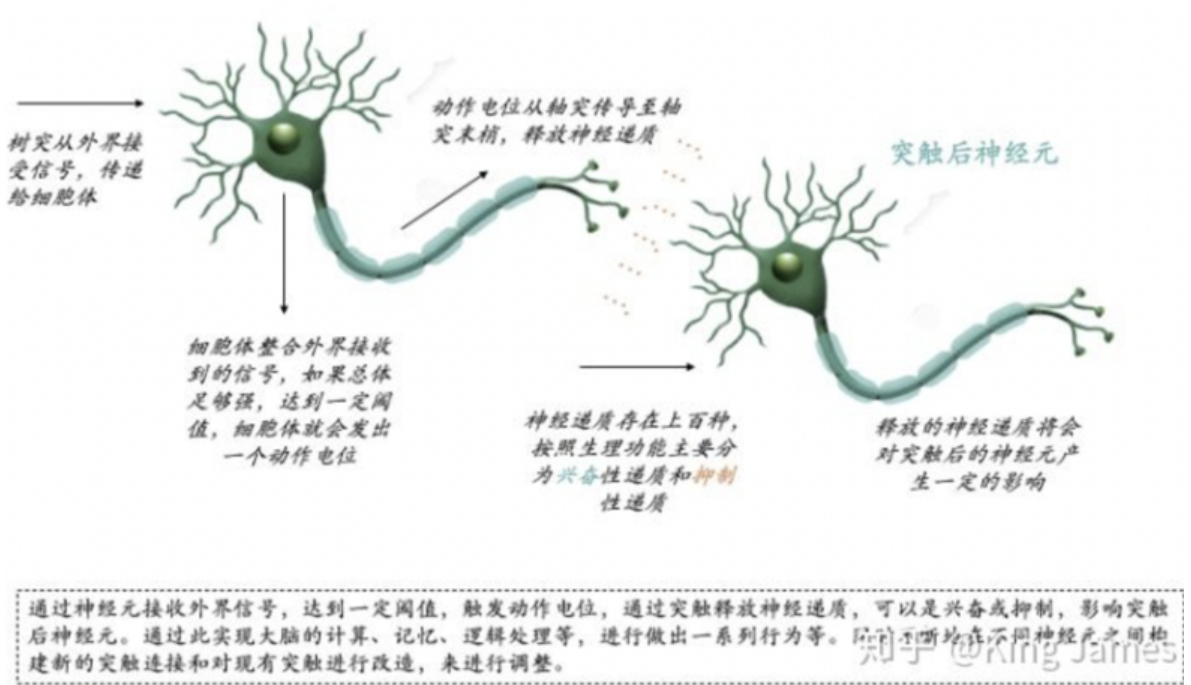
-
树突:接收信号
-
细胞体:整合、汇总信号
-
轴突:传递信号
-
突触:放大或抑制信号
3. 人工神经元
输入 xi → 权重 wi → 加权和 → 激活函数 → 输出- xi:输入信息
- wi:权重(可学习参数,用于筛选输入特征)
- b:偏置(相当于信息价值的阈值)
- 激活函数:将线性表达的信号映射到非线性空间
4. 神经网络的构成
| 层类型 | 作用 |
|---|---|
| 输入层 | 接收输入特征,每个特征对应一个神经元 |
| 隐藏层 | 提取高阶特征,"深度"由隐藏层数量决定 |
| 输出层 | 生成最终预测结果 |
特点:
- 同一层神经元之间没有连接
- 每层神经元与上一层所有神经元相连(全连接)
- 数据在层间以二维形式传递:
[batch_size, features]
5. 内部状态值与激活值
- 内部状态值 :
z = W · x + b - 激活值 :
a = f(z)(通过激活函数变换)
激活函数
常见的激活函数:
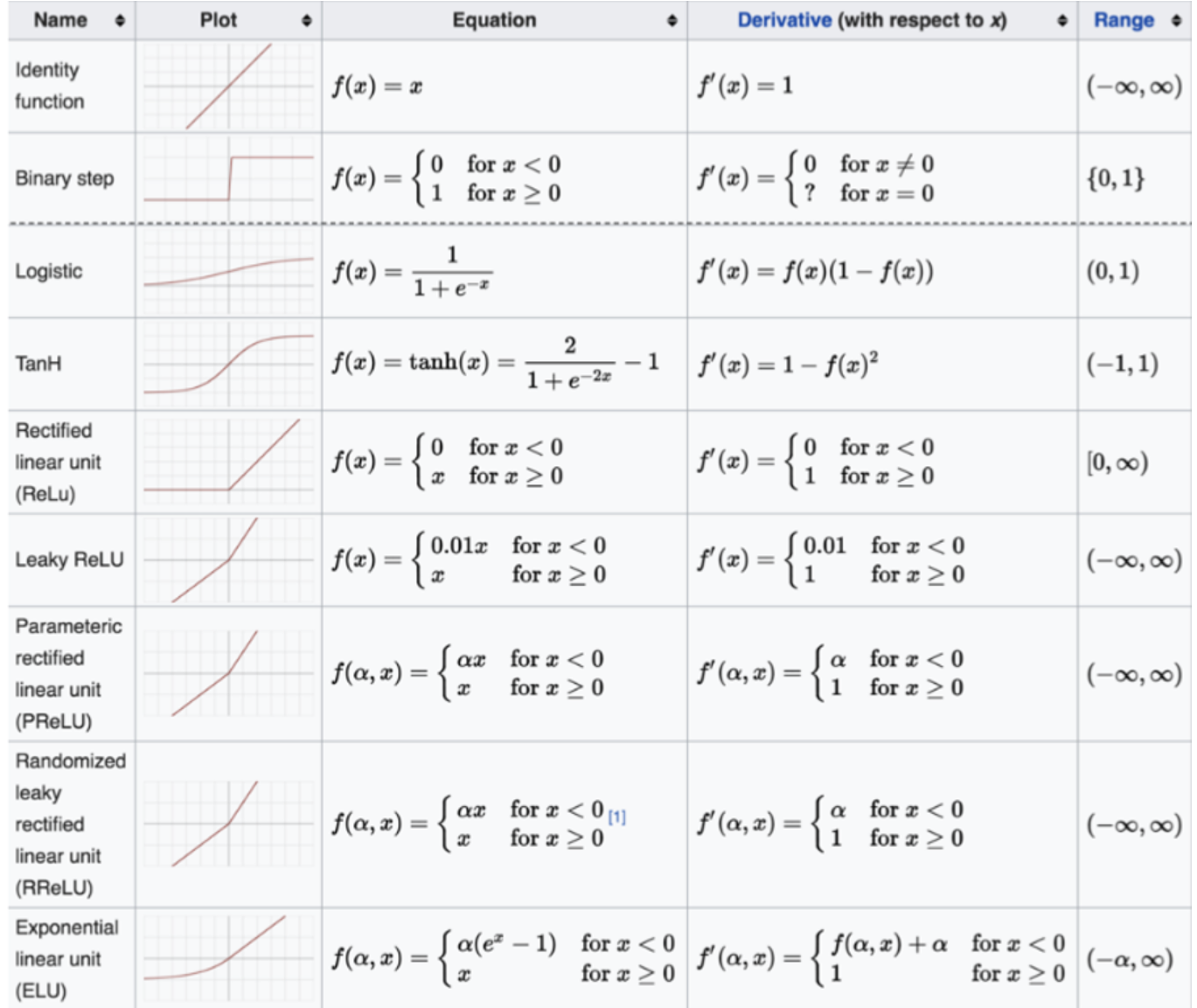
1. 激活函数的作用
向神经网络中添加非线性因素,使网络可以拟合各种曲线。没有激活函数,网络等价于线性模型。
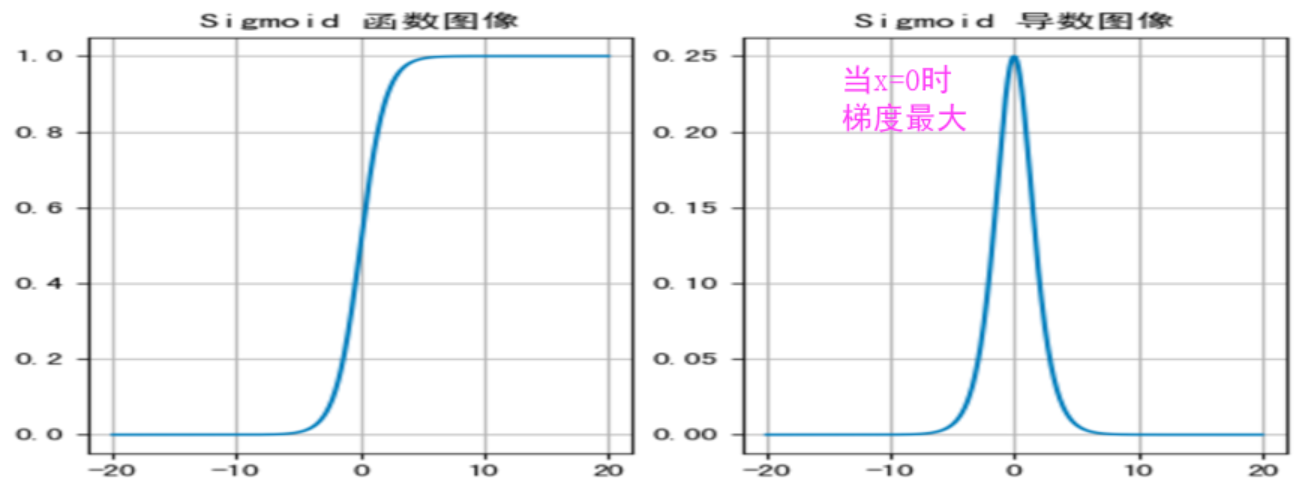
2. Sigmoid 激活函数
python
# 公式:σ(x) = 1 / (1 + e^(-x))
# 变化范围:(0, 1)
y = torch.sigmoid(x)特点:
- 输入映射到 (0, 1) 之间
- 以 0 为中心时效果好,输入在 -3, 3 之间有较好效果
- 梯度消失问题:导数范围 (0, 0.25),深层网络易梯度消失
- 通常只用于二分类输出层
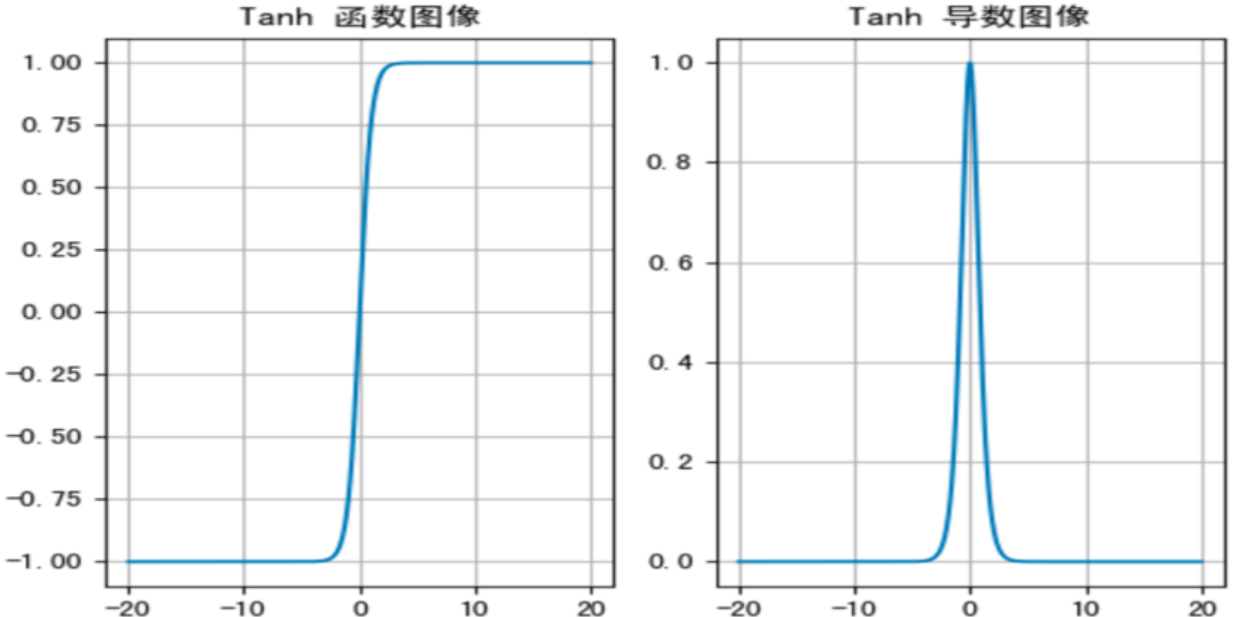
3. Tanh 激活函数
python
# 公式:tanh(x) = (e^x - e^(-x)) / (e^x + e^(-x))
# 变化范围:(-1, 1)
y = torch.tanh(x)特点:
- 以 0 为中心,收敛速度比 Sigmoid 快
- 导数范围 (0, 1),同样存在梯度消失
- 隐藏层推荐使用 Tanh,输出层使用 Sigmoid
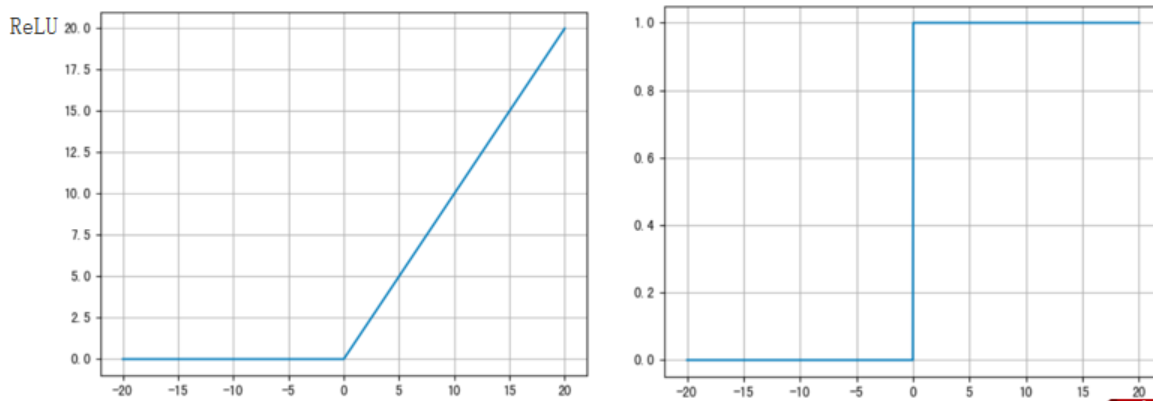
4. ReLU 激活函数
4.1 标准ReLU
python
# 公式:f(x) = max(0, x)
y = torch.relu(x)特点:
- 梯度恒为 1 或 0,不会梯度爆炸
- 计算简单,训练效率高
- 可能产生"神经元死亡"问题(负值区域梯度为0)
4.2 变种ReLu
4.2.1 Leaky ReLU(带泄露的 ReLU)
数学公式:
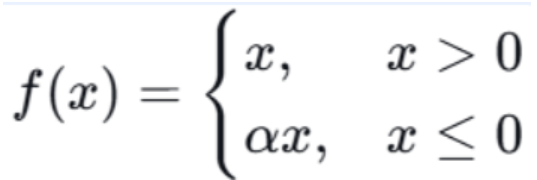
通俗比喻:
Leaky ReLU 把阀门改进了一下:当水是负的时,阀门并没有完全关上,而是留了一条很细的缝隙,让一点点水渗过去。这样即使输入总是负的,神经元也不会"死",仍然能学到一点点东西。
**优点:**解决了 ReLU 的神经元死亡问题,负半轴有梯度
**缺点:**α 需要手动设定
python
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
# 定义x张量为横坐标(1000个数据点)
# 生成一个从-20到20,包含1000个数据点的张量x(横坐标)
# requires_grad=True 表示这个张量需要计算梯度
x = torch.linspace(-20, 20, 1000, requires_grad=True)
# 计算x对应的 y值(纵坐标)
# negative_slope:负斜率
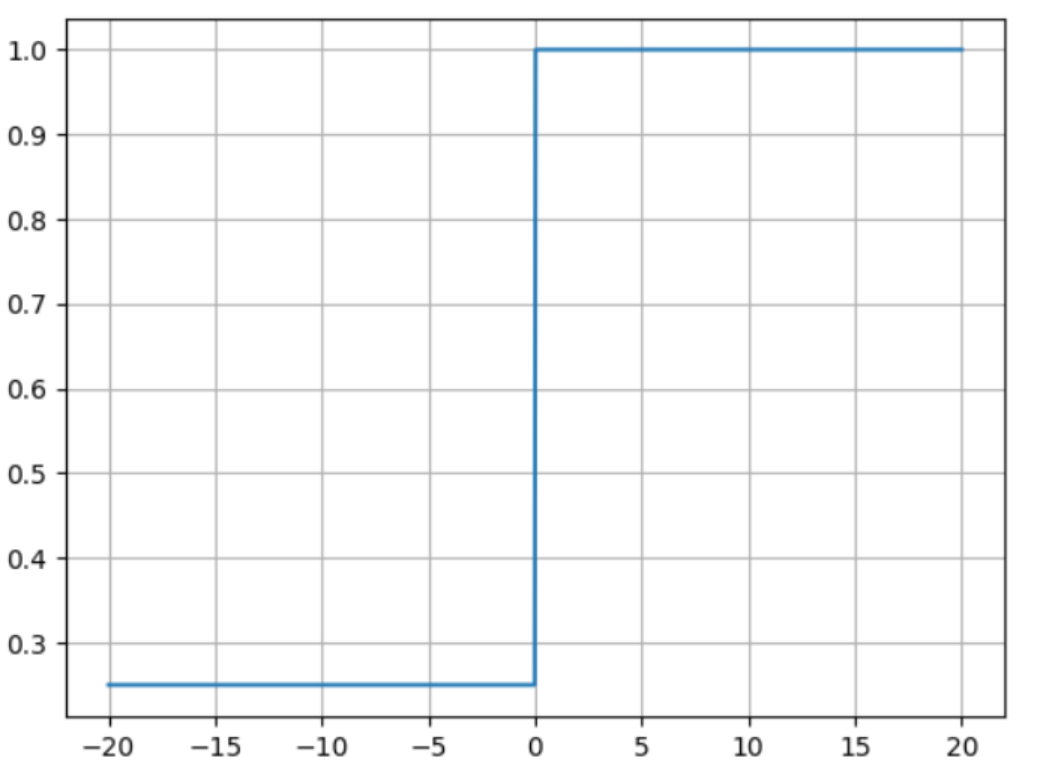
y = F.leaky_relu(x, negative_slope=0.25)
# 计算y的梯度
y.sum().backward()
# 绘制图像
plt.plot(x.detach(), x.grad)
plt.grid()
plt.show()梯度图像:
4.2.2 PReLU(Parametric ReLU)
数学公式:
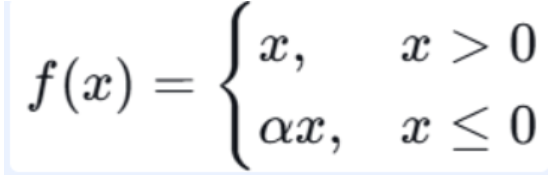
注释:
- α:可学习的参数(不是固定的),每个神经元可以有不同的 α
通俗比喻:
PReLU 相当于给每个阀门都配了一个可调节的漏缝大小,网络自己会学会最适合的漏缝值,让表现更好。
优点:自动学习负半轴的斜率,适应数据特性
缺点:增加了参数量
5. Softmax 激活函数
基本公式:
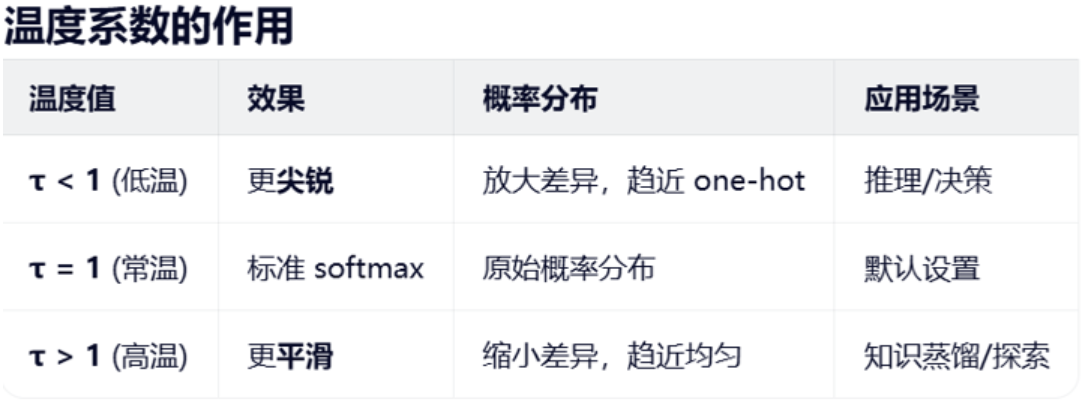
温度系数:
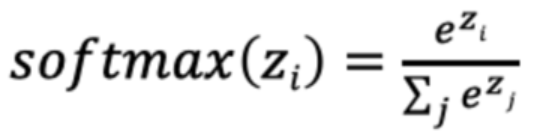
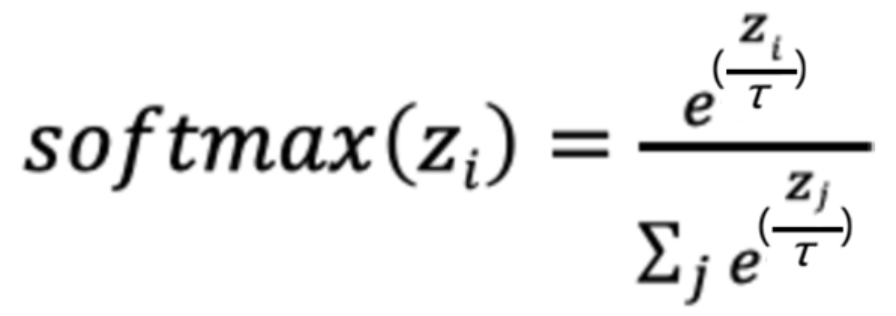
python
# 用于多分类,将logits转换为概率
probs = torch.softmax(scores, dim=0)
# dim=0: 按列计算;dim=1: 按行计算特点:
- 多分类输出,输出概率之和为 1
- 选取概率最大的节点作为预测类别
6. 激活函数选择
| 场景 | 激活函数 |
|---|---|
| 隐藏层 | ReLU(优先)或 LeakyReLU |
| 二分类输出层 | Sigmoid |
| 多分类输出层 | Softmax |
| 回归输出层 | Identity(无激活) |
参数初始化
1. 为什么要参数初始化
- 打破对称性:避免所有神经元接收相同输入、产生相同输出
- 防止梯度问题:避免梯度消失或梯度爆炸
- **收敛速度:**合适的初始值能让损失快速下降
2. 常见初始化方法
python
import torch.nn as nn
linear = nn.Linear(5, 3)
# 均匀分布随机初始化
nn.init.uniform_(linear.weight)
# 正态分布随机初始化
nn.init.normal_(linear.weight, mean=0, std=1)
# 全0/全1初始化(不推荐,无法打破对称性)
nn.init.zeros_(linear.weight)
nn.init.ones_(linear.weight)
# 固定值初始化
nn.init.constant_(linear.weight, 5)
# Kaiming初始化(深度网络 + ReLU)
nn.init.kaiming_normal_(linear.weight, nonlinearity='relu')
nn.init.kaiming_uniform_(linear.weight)
# Xavier初始化(深度网络 + Sigmoid/Tanh)
nn.init.xavier_normal_(linear.weight)
nn.init.xavier_uniform_(linear.weight)2.1 均匀分布随机初始化
权重参数初始化从区间均匀随机取值,默认区间为(0,1)。
2.2 正态分布随机初始化
随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数W进行初始化
适用场景:浅层网络或低复杂度模型。隐藏层1-3层,总层数不超过5层。
**优点:**能有效打破对称性缺点:
**缺点:**随机选择范围不当可能导致梯度问题
- 分布区间 或者 标准差的定义没有理论支撑
- 对于 0-1 均匀分布,未能考虑网络结构(前一层神经元很多,由于加权求和,本层神经元的状态值依然会很大,激活函数饱和。 一个粗糙的补救措施 )
- 对于权重正态分布,正、负离群值无法完全消除,导致梯度消失(sigmoid,Tanh)或者神经元死亡(ReLU)
2.3 全0/全1初始化
缺点:无法打破对称性,所有神经元更新方向相同,无法有效训练
适用场景: 仅用于偏置的全0初始化,或者用于调试模型
2.4 固定值初始化
2.5 Kaiming初始化
kaiming +ReLU
-
正态分布的he初始化:它是从均值0, 标准差std 的正态分布中抽取样本的,
std = sqrt(2 / fan_in) -
均匀分布的he初始化:它从 -limit,limit 中的均匀分布中抽取样本, limit是
sqrt( 6 / fan_in )
2.6 Xavier初始化
Xavier + Tanh sigmoid
- 正态分布的 Xavier 初始化、正态化的Xavier初始化:它是从 0, std 中抽取样本的,
std = sqrt(2 / (fan_in + fan_out)) - 均匀分布的Xavier初始化 : 它是从 -limit,limit 中的均匀分布中抽取样本,
limit =sqrt(6 / (fan_in + fan_out)
注意:

3. 初始化方法选择
| 场景 | 初始化方法 |
|---|---|
| 浅层网络(<5层) | 随机初始化即可 |
| 深度网络 + ReLU | Kaiming初始化 |
| 深度网络 + Sigmoid/Tanh | Xavier初始化 |
4. 为什么不能全 0 或全相同初始化?
- 前向传播:所有神经元输出相同,信息无法多样化(因为输入相同,权重相同)
- 反向传播:所有神经元梯度相同,(因为对称的结构)
- 权重更新后,所有权重仍然保持彼此相等,只是从 0.5 变成了 0.5+Δ
- 结果:所有神经元仍然步调一致,无法分化出不同功能。 网络的有效容量只有一个神经元,表达能力极差。
神经网络搭建
1.PyTorch 搭建流程
python
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super().__init__()
# 定义网络层
self.linear1 = nn.Linear(3, 3) # 输入3特征,输出3特征
self.linear2 = nn.Linear(3, 2) # 输入3特征,输出2特征
self.out = nn.Linear(2, 2) # 输出层
def forward(self, x):
# 数据流
x = torch.sigmoid(self.linear1(x))
x = torch.relu(self.linear2(x))
x = self.out(x)
return x
# 使用
model = Model()
output = model(input_data) # 输入数据时自动调用forward方法2.模型参数计算
全连接层参数 = (输入特征数 + 1) × 输出特征数
示例:输入3特征 → 3神经元 → 2神经元
- 第一层: (3+1) × 3 = 12 个参数
- 第二层: (3+1) × 2 = 8 个参数
- 输出层: (2+1) × 2 = 6 个参数
总计:26 个参数注意要点:
forward函数名固定,因为在实例化model之后输入数据时,底层其实会调用__call__函数执行forward方法

损失函数
损失函数用于量化模型预测值与真实值的差异(误差),是参数更新的 "导航标"(梯度下降沿损失减小的方向更新参数)。
1. 分类任务损失函数
1.1 二分类交叉熵损失(BCELoss)
数学公式:
**定义:**用于二分类问题,配合 Sigmoid 激活函数使用。计算单个样本的二元交叉熵。注释:
- yi∈{0,1}:第 i 个样本的真实标签
- ŷi∈{0,1}:第 i 个样本的预测概率(Sigmoid 输出)
- 公式含义 :对于当个样本而言:当真实标签为 1 时,损失为 −log(ŷi);当真实标签为 0 时,损失为−log(1 - ŷi)。对所有样本的损失整体求平均。
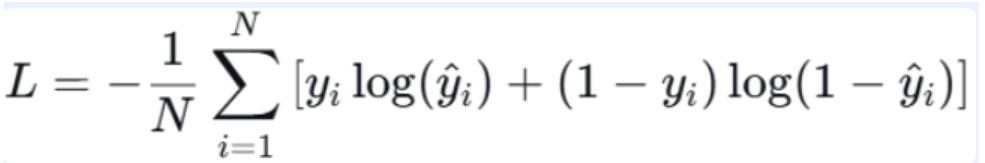
python
loss = nn.BCELoss() # 配合 Sigmoid 使用
output = loss(predictions, targets) # predictions, 须经过 Sigmoid1.2 多分类交叉熵损失(CrossEntropyLoss)
数学公式:
定义:用于多分类问题,输出层通常配合 Softmax 激活函数。计算真实标签与预测概率分布之间的交叉熵。
注释:
- N:样本数
- C:类别数
- yi,c:第 i 个样本的真实标签(one-hot 编码,仅正确类别为 1,其余为 0)
- ŷi,c:模型预测的第 i 个样本属于类别 c 的概率(由 Softmax 输出)
- 公式含义:对每个样本,只计算正确类别的负对数概率,所有样本平均。最小化该值等价于最大化正确类别的预测概率。
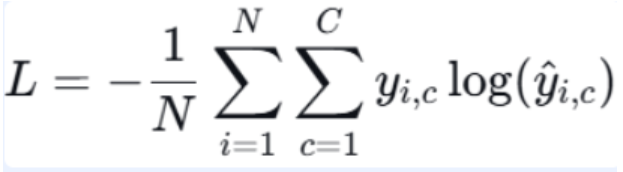
python
# nn.CrossEntropyLoss = LogSoftmax + NLLLoss
loss = nn.CrossEntropyLoss()
output = loss(predictions, targets) # targets是类别索引2. 回归任务损失函数
2.1 MAE 损失(L1 Loss)
数学公式:
定义:预测值与真实值之差的绝对值平均。
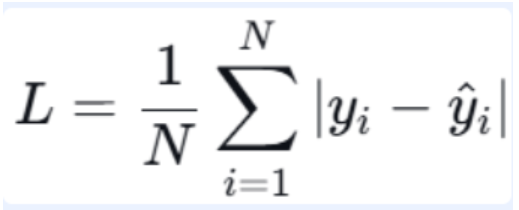
python
# 公式:L = |y_pred - y_true|
loss = nn.L1Loss()2.2 MSE 损失(L2 Loss)
数学公式:
定义:预测值与真实值之差的平方平均。
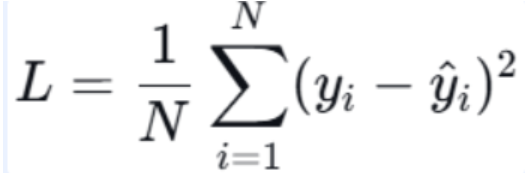
python
# 公式:L = (y_pred - y_true)²
loss = nn.MSELoss()2.3 Smooth L1 损失
数学公式:
定义:结合 L1 和 L2 的优点,在误差较小时使用 L2(平滑),误差较大时使用 L1(鲁棒)。
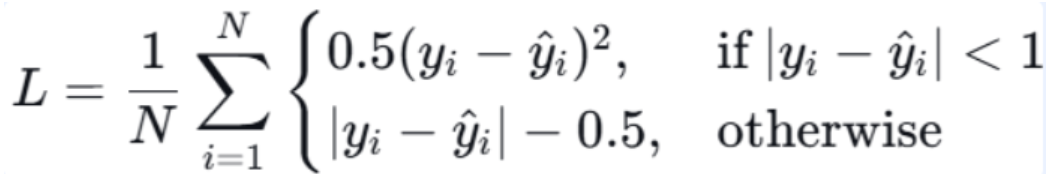
python
# 分段函数:[-1,1]区间用L2,区间外用L1
loss = nn.SmoothL1Loss()网络优化方法
优化器的目标是找到使损失函数最小的参数。梯度下降法是最基本的优化算法,通过沿着梯度的反方向更新参数来降低损失。然而,标准梯度下降存在收敛慢、易陷入局部极值或鞍点、对学习率敏感等问题。因此,研究人员提出了多种改进算法。
1. 梯度下降基础概念
核心概念:
| 概念 | 说明 |
|---|---|
| Epoch | 使用全部数据对模型进行一次完整训练 |
| Batch Size | 每批次训练的样本数量 |
| Iteration | 使用一个Batch对模型进行一次参数更新 |
三种优化策略:
现代深度学习通常使用 小批量梯度下降(Mini-batch Gradient Descent),并在此基础上引入动量、自适应学习率等技术。
| 类型 | Batch Size | 特点 |
|---|---|---|
| BGD(批量GD) | N(全量) | 梯度准确,但慢 |
| SGD(随机GD) | 1 | 快但不准 |
| Mini-Batch GD | 适量 | 平衡速度和精度 |
反向传播算法(BP):
- 前向传播:数据从输入层逐层向前传递到输出层
- 反向传播:利用损失函数,从后往前计算梯度并更新参数
2. 动量法(Momentum)
问题:SGD(随机梯度下降) 在陡峭方向震荡,在平坦区域停滞。
思想:引入历史梯度的指数加权移动平均(动量),使更新方向更平滑,加速收敛,并能越过局部极小值或鞍点。
更新公式:
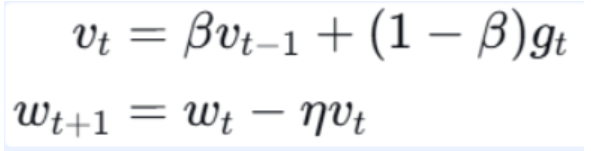
注释:
- vt:动量累积量(速度)
- β:动量系数,通常取 0.9
- gt:当前梯度
- η:学习率
解释 :当连续多次梯度方向一致时,vt 会累积增大,加速前进;当梯度方向频繁变化时,vt会抵消部分震荡,使更新更平稳。
3. AdaGrad(自适应梯度)
问题:不同参数需要的学习率不同(如稀疏特征需要更大步长),而 SGD 对所有参数使用同一学习率。
思想:为每个参数维护历史梯度平方的累积和,学习率随累积和增大而减小,使稀疏参数更新更快,频繁参数更新更慢。
更新公式:
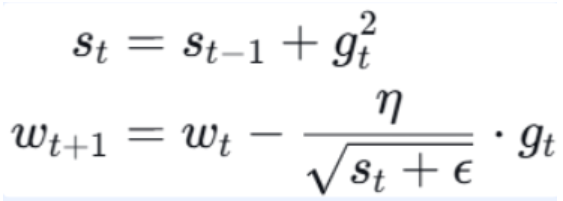
注释:
- St:梯度平方的累积和(逐元素)
- ε:小常数(如 10-8防止除零)
4. RMSProp(均方根传播)
问题:AdaGrad 的学习率过早衰减,在非凸优化中不利。
思想:用指数加权平均代替累积和,使学习率保持活跃。
更新公式:
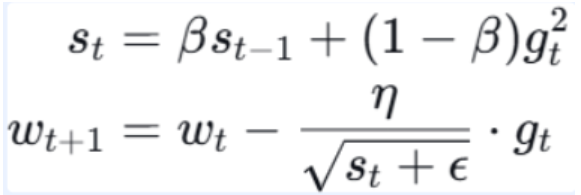
注释:
- β:衰减系数,通常取 0.9
特点:解决了 AdaGrad 学习率过快下降的问题,适合非平稳目标。
5. Adam(自适应矩估计)
思想:同时使用动量(一阶矩)和自适应学习率(二阶矩),是目前最常用的优化器。
更新公式:

注释:
-
β1,β2:通常取 0.9 和 0.999
-
t:当前迭代步数
-
偏差校正:由于m0 = v0 =0,初期估计值偏小,通过除以1-βt修正。
特点:
- 收敛快,对超参数鲁棒
- 适合大多数深度学习任务
6. 学习率调整策略
学习率是优化中最重要的超参数。动态调整学习率可以加快收敛并提升最终性能
python
# 等间隔衰减
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)
# 指定间隔衰减
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50, 125], gamma=0.5)
# 指数衰减
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
# 每个epoch后更新学习率
for epoch in range(num_epochs):
train()
scheduler.step()正则化方法
1. Dropout(随机失活)
每个神经元以概率 p(常用 0.4~0.5)随机 "失活"(输出设为 0),未失活神经元的输出放大 1/(1-p)(弥补信号强度损失),保持总期望不变;
让神经元以概率 p 停止工作,防止过拟合。
python
# Dropout层(放在激活函数之后)
dropout = nn.Dropout(p=0.4)
x = dropout(torch.relu(linear(x)))训练时:随机失活,部分神经元输出置为0,未失活输出放大 1/(1-p)
测试时:Dropout不起作用
2. Batch Normalization(批量归一化)
BN 层就像给神经网络的每一层 "标准化生产线"------ 把每层输入数据的分布统一调成 "均值≈0、方差≈1" 的标准形态,再允许模型微调,让数据分布稳定,不让后续层 "难适应"。
对每层输入进行标准化,稳定数据分布。
python
# 用于全连接层
bn1 = nn.BatchNorm1d(128)
# 用于卷积层(图像)
bn2d = nn.BatchNorm2d(3) # 3通道
x = bn2d(x)2.1 比喻:
把神经网络的各层想象成 "流水线工人":
- 没有 BN 层:前一个工人(上层网络)输出的数据忽大忽小、忽高忽低(比如这次输出 0-100,下次输出 0-10),下一个工人(下层网络)得不断调整工作方式适应,越往后越乱,效率极低;
- 有了 BN 层:在两个工人之间加一个 "质检员"(BN 层),不管前一个工人输出什么数据,都先标准化成 "0 附近、波动小" 的统一格式,再传给下一个工人,工人不用频繁调整,专注做好自己的工作(学习特征)。
具体做两件事:
- 标准化:把数据调成均值 0、方差 1(比如数据 10→1,数据 - 5→-0.8,统一波动范围);
- 可学习微调:加两个可调整参数(γ 缩放、β 平移),允许模型根据任务需求,把标准化后的数据微调回合适范围(避免过度标准化丢失有用特征)。
2.2 核心逻辑:
对每一层的输入(mini-batch)数据进行标准化,稳定数据分布,减少梯度问题:
- 标准化 :
x_norm = (x - μ_batch) / √(σ_batch² + ε)
注释:
- μ_batch 为批次均值,
- σ_batch² 为批次方差,
- ε=1e-5 避免分母为 0;
- 重构:
x_out = γ·x_norm + β
注释:
- γ 为缩放系数,
- β 为平移系数,
- 均为可学习参数,允许模型还原原始分布特征。
2.3 作用
1. 内部协变量偏移(最核心)
- 问题:训练时,上层网络参数更新会导致下层输入数据的分布不断变化(比如第一层权重变了,第二层的输入就变了),下层网络得一直 "适应新分布",导致训练慢、难收敛;
- 解决:BN 层固定每层输入数据的分布,让下层网络不用再适应分布变化,专注学习特征,训练速度直接翻倍。不仅缓解了内部协变量偏移,更重要的是使损失曲面更平滑,从而允许更大学习率、加速收敛。
2. 梯度消失 / 爆炸(辅助优化)
- 问题:深层网络中,数据经过多层加权求和后,数值可能变得极大或极小(比如 Sigmoid 激活函数遇到大输入,输出会接近 1,梯度接近 0,参数无法更新);
- 解决:BN 层把数据压缩到 "0 附近的合理范围",避免激活函数落入 "饱和区"(梯度接近 0),让梯度能稳定传递到深层,缓解梯度消失 / 爆炸。
3. 降低参数初始化敏感度(减少调参成本)
- 问题:没有 BN 层时,参数初始化稍微不当(比如权重太大),就会导致数据在网络中 "越传越偏",模型训练崩掉;
- 解决:BN 层的标准化让数据分布稳定,哪怕初始化参数不够精准,也能通过标准化修正,不用花大量时间调初始化参数。
实战:手机价格分类
案例流程:
(一)问题描述与目标
-
数据集:手机性能指标(20个特征),标签为价格区间(0,1,2,3,共4类)。
-
任务:多分类,预测手机属于哪个价格区间。
-
目标:构建一个全连接神经网络,通过训练学习特征与价格区间的关系。
(二)数据准备
-
加载数据 :使用 pandas 读取 CSV,分离特征
x和标签y。 -
划分数据集:
-
- 训练集(60%):用于更新模型参数。
-
- 验证集(20%):用于监控模型性能、选择最佳模型。
-
- 测试集(20%):仅用于最终评估(不参与任何调参)。
-
标准化:对特征进行标准化(减均值、除标准差),用训练集计算均值和方差,再转换验证集和测试集。
-
转换为 PyTorch 张量 :特征转
float32,标签转long。 -
构造 DataLoader :使用
TensorDataset和DataLoader,设定batch_size(如32),训练集打乱。
(三)模型定义
-
网络结构:全连接层 + BatchNorm + ReLU + Dropout(可选)。
-
输入层:20 → 隐藏层1(128) → BN → ReLU → Dropout → 隐藏层2(256) → BN → ReLU → Dropout → 输出层(4)。
-
输出层不使用激活函数(配合
CrossEntropyLoss)。
(四)训练流程
- 实例化模型、损失函数、优化器
-
- 损失函数:
nn.CrossEntropyLoss()(多分类交叉熵)
- 损失函数:
-
- 优化器:
Adam(学习率可设为 0.001)
- 优化器:
-
- 学习率调度器(可选):
StepLR或ReduceLROnPlateau
- 学习率调度器(可选):
- 训练循环
-
- 每个 epoch:
-
-
- 模型设为
train()模式(启用 Dropout 和 BN 的批次统计)。
- 模型设为
-
-
-
- 遍历训练集 DataLoader:
-
-
-
-
- 前向传播 → 计算损失 → 反向传播 → 更新参数
-
-
-
-
- 记录平均训练损失。
-
-
-
- 在验证集上评估:
-
-
-
-
- 模型设为
eval()模式(关闭 Dropout,BN 使用全局统计)。
- 模型设为
-
-
-
-
-
- 计算验证准确率(或损失)。
-
-
-
-
-
- 如果验证指标优于历史最佳,则保存当前模型参数。
-
-
-
-
- 更新学习率(若使用调度器)。
-
- 保存最佳模型
-
- 使用
model.state_dict().copy()保存参数副本,或保存到文件。
- 使用
(五)最终评估
-
加载最佳模型 :
model.load_state_dict(best_model_state) -
在测试集上预测:
-
- 模型设为
eval()模式,禁用梯度。
- 模型设为
-
- 收集所有预测结果和真实标签到 Python 列表(使用
extend逐样本添加)。
- 收集所有预测结果和真实标签到 Python 列表(使用
-
计算指标:
-
- 测试准确率
-
- 混淆矩阵(
sklearn.metrics.confusion_matrix)
- 混淆矩阵(
-
- 分类报告(精确率、召回率、F1-score,需指定
target_names)
- 分类报告(精确率、召回率、F1-score,需指定
完整代码
python
import torch
from torch.utils.data import TensorDataset, DataLoader
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
import pandas as pd
# 1. 准备数据集
def create_dataset():
data = pd.read_csv('手机价格预测.csv')
x, y = data.iloc[:, :-1], data.iloc[:, -1]
x = x.astype(np.float32)
y = y.astype(np.int64)
x_train, x_valid, y_train, y_valid = train_test_split(
x, y, train_size=0.8, random_state=88
)
train_dataset = TensorDataset(
torch.from_numpy(x_train.values),
torch.tensor(y_train.values)
)
valid_dataset = TensorDataset(
torch.from_numpy(x_valid.values),
torch.tensor(y_valid.values)
)
return train_dataset, valid_dataset, x_train.shape[1], len(set(y))
# 2. 构建模型
class PhonePriceModel(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.linear1 = nn.Linear(input_dim, 128)
self.linear2 = nn.Linear(128, 256)
self.linear3 = nn.Linear(256, output_dim)
def forward(self, x):
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
return self.linear3(x)
# 3. 模型训练
def train(train_dataset, input_dim, class_num):
dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True)
model = PhonePriceModel(input_dim, class_num)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
for epoch in range(50):
total_loss = 0
for x, y in dataloader:
output = model(x)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {total_loss/len(dataloader):.4f}')
torch.save(model.state_dict(), 'model/phone.pth')
# 4. 模型评估
def test(valid_dataset, input_dim, class_num):
model = PhonePriceModel(input_dim, class_num)
model.load_state_dict(torch.load('model/phone.pth'))
dataloader = DataLoader(valid_dataset, batch_size=1)
correct = 0
for x, y in dataloader:
output = model(x)
y_pred = torch.argmax(output, dim=1)
correct += (y_pred == y).sum()
print(f'Accuracy: {correct.item() / len(valid_dataset):.4f}')总结
1. 神经网络四步骤
准备训练集数据 → 构建模型 → 设置损失函数和优化器 → 模型训练2. 关键知识点
| 模块 | 核心内容 |
|---|---|
| 激活函数 | ReLU(隐藏层)、Sigmoid/Softmax(输出层) |
| 参数初始化 | Kaiming(ReLU)、Xavier(Sigmoid/Tanh) |
| 损失函数 | CrossEntropyLoss(分类)、MSELoss(回归) |
| 优化器 | Adam(推荐) |
| 正则化 | Dropout、BatchNorm |