****论文题目:****Energy-Efficient Fast Object Detection on Edge Devices for IoT Systems(物联网系统边缘设备上的节能快速目标检测)
****期刊:****IEEE INTERNET OF THINGS JOURNAL(IOTJ 计算机科学top)
****摘要:****本文介绍了一种物联网(IoT)应用程序,该应用程序利用AI分类器使用帧差分方法进行快速目标检测。这种方法持续时间较短,最有效,适用于物联网系统中的快速物体检测,与端到端方法相比,物联网系统需要节能应用。我们已经在三个边缘设备上实现了该技术:1)AMD AlveoTMU50;2) Jetson Orin Nano;3) Hailo-8TMAI加速器,以及采用人工神经网络和变压器模型的4种模型。我们检查了各种类别,包括鸟类、汽车、火车和飞机。使用帧差方法,MobileNet模型始终具有高精度、低延迟和高能效的特点。YOLOX始终显示出最低的准确性、最低的延迟和最低的效率。实验结果表明,与端到端方法相比,该算法平均准确率提高28.314%,平均效率提高3.6倍,平均时延降低39.305%。在所有这些类中,速度较快的对象是火车和飞机。实验表明,火车和飞机的准确率低于其他类别。因此,在需要快速检测和准确结果的任务中,端到端方法可能是一场灾难,因为它们无法处理快速物体检测。为了提高计算效率,我们将提出的方法设计为一种轻量级的检测算法。它非常适合物联网系统中的应用,特别是那些需要快速移动物体检测和更高精度的应用。
帧差法 + 轻量级AI:在IoT边缘设备上实现高效快速目标检测
引言:一个被忽视的现实难题
想象这样一个场景:你在铁路沿线部署了一套基于IoT的智能监控系统,需要实时识别高速驶过的列车,判断其类型并触发相应的响应逻辑。你的摄像头连接着一块边缘计算板卡,电池供电,无法频繁更换。
你打算用YOLO来做检测------但很快你会发现:列车速度太快,YOLO的准确率惨不忍睹;功耗太高,电池撑不过几天;延迟也偏高,实时性存疑。
这正是本文要解决的核心问题:在能量受限的IoT边缘设备上,如何对快速移动目标进行高效、准确、低延迟的检测?
一、现有方法的问题在哪?
1.1 端到端方法(以YOLO为代表)的瓶颈
以YOLO系列为代表的端到端目标检测方法,将特征提取、目标分类、边界框回归融合在一次前向推理中完成,功能强大,但在IoT场景下暴露出明显缺陷:
- 计算量巨大:需要对整张图像进行多层卷积,处理全局特征,计算开销远高于局部方法。
- 能耗高:通常需要GPU或TPU加速,在低功耗边缘设备上难以持续运行。
- 对快速目标不友好 :当目标移动速度过快时,运动模糊会使检测精度大幅下降。实验数据显示,YOLOX对飞机类的检测准确率仅为25.9%(Hailo-8)和23.11%(Jetson Orin Nano),几乎失去实用价值。
- 高分辨率性能不稳定:高分辨率视频中端到端方法无法提供最优性能。
1.2 传统运动检测方法的局限
- 光流法(Optical Flow):可以估计运动向量,但背景杂乱或目标高速运动时,梯度法精度显著下降,且计算复杂度高。
- 背景减除法(Background Subtraction):需要动态维护和更新背景模型,额外引入计算开销,对变化环境适应性差。
- 纯帧差法 :简单高效,但只能检测运动区域,无法对目标进行分类。
1.3 边缘硬件选型的困境
IoT系统中可用的硬件加速器种类繁多------FPGA、GPU、AI加速器各有优劣,技术参数差异大,缺乏针对快速目标检测场景的系统性横向对比,工程师在选型时往往无从下手。
二、本文的解决思路:帧差法 + 轻量级AI分类器
本文提出的核心思路非常清晰:用帧差法替代端到端方法来做运动检测和目标定位,再用轻量级AI分类器对定位到的ROI区域进行分类,从而将"繁重的全图推理"拆解为"轻量的运动检测 + 高效的局部分类"。
整个算法流程分为三个阶段:运动检测 → 预处理 → CNN/Transformer分类。
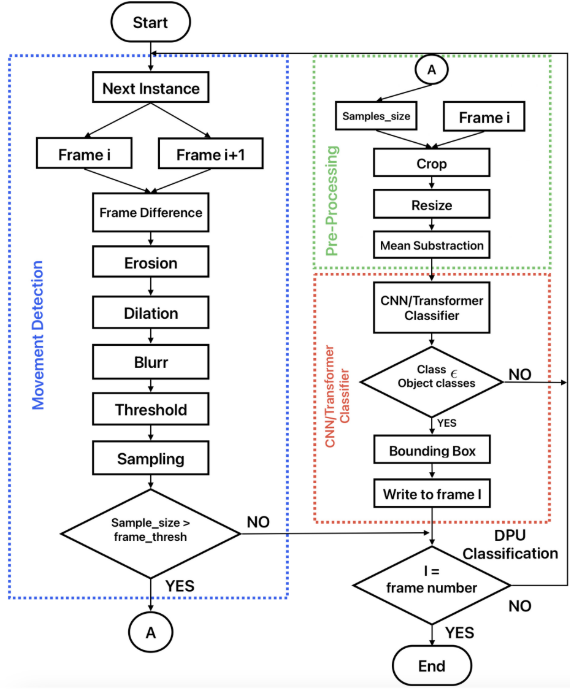
【此处配图:图1,论文算法流程图 Flow-chart of proposed algorithm】
2.1 阶段一:运动检测(Movement Detection)
这一阶段的目标是从视频流中找到运动区域,输出感兴趣区域(ROI)的坐标。
核心步骤如下:
① 读取相邻两帧,转换为灰度图
算法逐帧读取视频,将相邻的两帧(Frame i 和 Frame i+1)分别转换为灰度图像,作为后续计算的输入。
② 计算帧差(Frame Difference)
对两帧灰度图做逐像素绝对差值运算,得到差分图像。差值较大的区域即为发生运动的区域。

【此处配图:图2,帧差过程示意图 Frame difference process】
③ 形态学开运算:去除背景噪声
差分图像中仍然存在大量背景噪声(例如草地轻微晃动)。为此,算法依次执行:
- 腐蚀(Erosion):去除细小噪点
- 膨胀(Dilation):恢复目标轮廓,填充空洞
两步合称"形态学开运算",有效压制背景噪声。

【此处配图:图3 ,图像膨胀过程 Image dilation process;图4,图像腐蚀过程 Image erosion process】
④ 图像模糊(Blurring)
使用低通滤波器对图像进行卷积,进一步平滑高频噪声。

【此处配图:图5,图像模糊过程 Image blurring process】
⑤ 二值化阈值(Thresholding)
将模糊后的图像与阈值比较:低于阈值的像素置0,高于阈值的像素置255,得到二值运动掩膜。
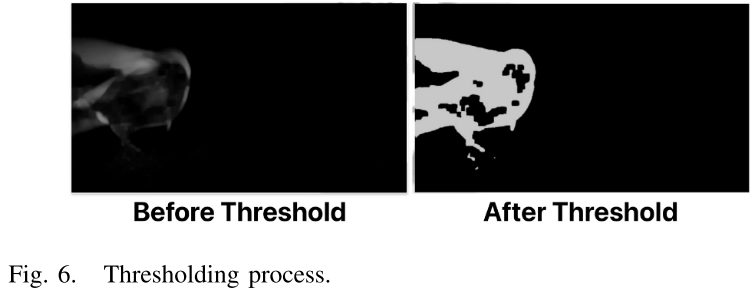
【此处配图:图6,阈值化过程 Thresholding process】
⑥ 采样确定ROI边界框
在二值图中寻找所有值为1的像素点,记录其X、Y坐标,计算坐标的最大值与最小值,从而确定ROI矩形框的位置和尺寸。
当ROI区域大小超过预设阈值(sample_size > frame_thresh)时,说明有显著运动目标出现,进入下一阶段处理。
2.2 阶段二:预处理(Pre-Processing)
将上一阶段定位到的ROI区域送入神经网络之前,需要进行标准化预处理:
-
裁剪:从原始BGR三通道彩色视频帧中,按照ROI坐标裁剪出目标区域。在AMD Alveo U50上采用流式(Stream-based)裁剪架构,与其硬件内核数据流类型匹配。
-
缩放:将裁剪区域统一缩放至神经网络输入尺寸:
- 大多数模型(MobileNet、ResNet50、ViT Base):224 × 224 × 3
- Inception-v4:299 × 299 × 3
- 缩放采用双线性插值,在保留三通道色彩信息的同时保持较高性能。
-
均值归一化:对图像数据进行归一化处理,适配各神经网络模型的输入规范。
-
序列化:将图像数据展开为数组,送入神经网络推理图(inference graph)。
2.3 阶段三:CNN/Transformer分类器
本文选用了四种主流神经网络模型,覆盖CNN和Transformer两大类架构,均在ImageNet数据集上预训练(包含超过1400万张图像、21000+类别,ILSVRC子集约120万张训练图):
MobileNet
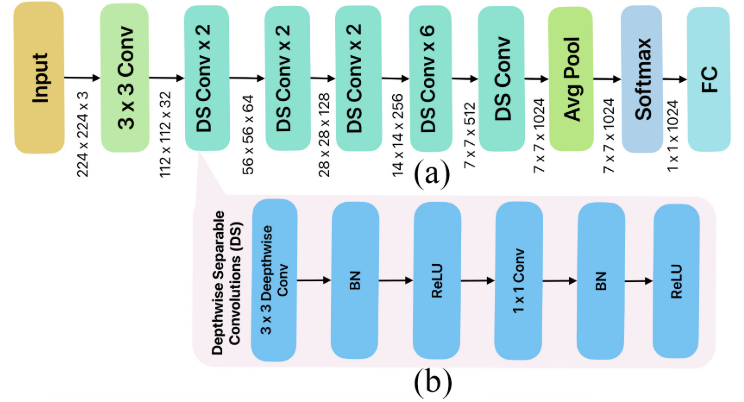
【此处配图:图7,MobileNet架构图】
专为移动端和嵌入式设备设计。核心创新是深度可分离卷积(Depthwise Separable Convolution, DS),将标准卷积拆分为:
- 深度卷积(Depthwise Conv):每个输入通道独立做滤波
- 逐点卷积(Pointwise Conv, 1×1):合并各通道输出
配合批归一化(BN)和ReLU激活,在大幅降低计算量的同时保持良好精度。本文实验中表现最优的模型。
Inception-v4
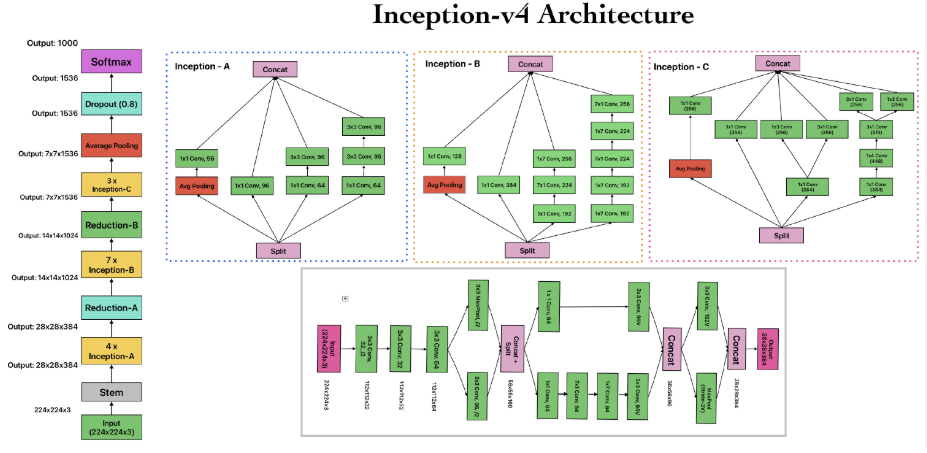
【此处配图:图8,Inception-v4架构图】
在Inception架构基础上引入残差连接,通过并行多尺度卷积(不同大小的卷积核并联)实现多尺度特征提取,配合贝叶斯超参数优化。精度高但功耗和延迟也相对较大。
ResNet50
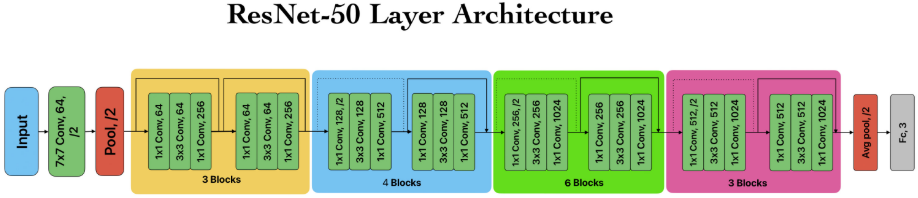
【此处配图:图9,ResNet50架构图】
50层残差网络,通过**跳跃连接(Skip Connection)**缓解深层网络梯度消失问题。分为恒等映射快捷连接(输入输出维度相同)和投影快捷连接(维度不同时)。在精度和效率之间取得良好平衡。
ViT Base(Vision Transformer)
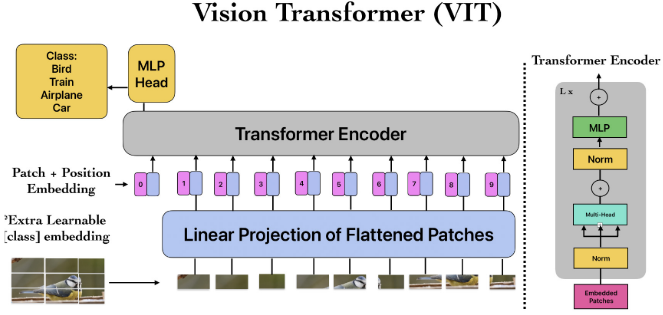
【此处配图:图10,ViT架构图】
将图像划分为固定大小的Patch,展平后通过线性嵌入映射到向量空间,叠加位置编码后输入标准Transformer编码器(多头自注意力 + 前馈网络)。通过全局自注意力机制捕捉图像中的长程依赖关系,精度最高,但延迟和能耗也最大,实时性受限。
对比基线(端到端方法):YOLOX,使用MS COCO数据集训练,代表当前主流端到端检测范式。
三、硬件部署:三种边缘平台
实验在三种具有代表性的边缘设备上部署,覆盖FPGA、AI加速器和GPU三大类型:
AMD Alveo U50(FPGA)
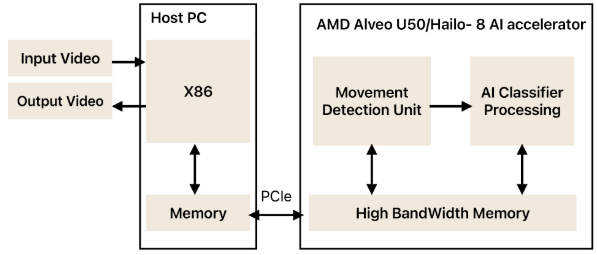
【此处配图:图11,Hailo和AMD Alveo U50系统架构图】
- 基于FPGA技术的AI加速器产品
- 系统由宿主PC(X86 CPU)+ Alveo U50两部分组成
- 宿主PC负责预处理,通过PCIe将数据传输至Alveo U50
- Alveo U50内部有运动检测单元 和AI分类处理模块 ,共享高带宽内存(HBM)
- 优势:低功耗、可重配置、自定义数据流;劣势:编程复杂,不支持ViT(Vitis AI暂不支持)
NVIDIA Jetson Orin Nano(GPU)
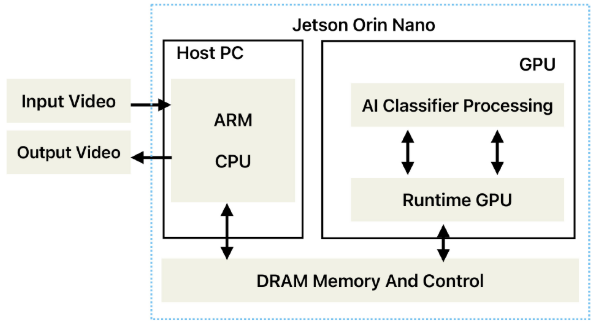
【此处配图:图12,Jetson Orin Nano系统架构图】
- 集成CPU(ARM)+ GPU于单芯片,支持TensorFlow、PyTorch等主流框架
- 系统架构:宿主PC(ARM+CPU)→ DRAM → GPU(AI分类处理 + Runtime)
- 开发生态完善(JetPack SDK),编程门槛低
- 非常适合自主机器、机器人、智能摄像头等场景
Hailo-8 AI Accelerator
- 专为深度学习推理优化的AI加速器,低功耗、高吞吐、紧凑外形
- 系统架构与Alveo U50相同(宿主PC + AI加速器),通过PCIe连接
- 在功耗和推理效率上表现突出,补充了CPU和GPU的短板
功耗测量工具 :Hailo-8和Alveo U50使用PowerTOP (Intel开发的Linux功耗监控工具);Jetson Orin Nano使用jtop(专为NVIDIA Jetson设计的监控工具)。
四、实验结果
4.1 实验设置
- 检测类别:鸟(Bird)、火车(Train)、飞机(Airplane)、汽车(Car)
- 评测指标:准确率(Acc%)、延迟(ms)、能耗(Joule)、效率(%/mW)
- 视频分辨率:3840×2160 和 4096×2016(超高清)
- 效率计算公式:引自文献55(EdgeViTs论文)
4.2 Hailo-8 AI Accelerator 实验结果
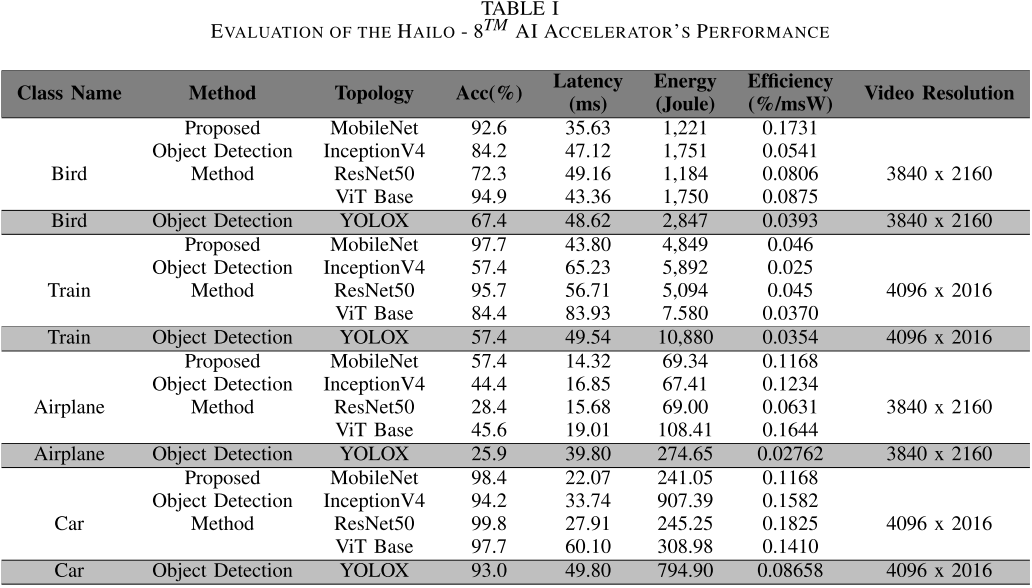
【此处配表:表I,Hailo-8 AI Accelerator性能评估结果】
关键结论:
- 鸟类:MobileNet准确率92.6%,延迟35.63 ms,能耗1,221 J,效率0.1731(最高);ViT Base准确率最高94.9%;YOLOX准确率仅67.4%,效率0.0393。
- 火车类:MobileNet准确率97.7%,延迟43.801 ms;YOLOX准确率骤降至57.4%,能耗高达10,880 J。
- 飞机类:MobileNet准确率57.4%(最高),延迟仅14.32 ms,能耗69.34 J;YOLOX准确率仅25.9%,效率0.02762。
- 汽车类:ResNet50准确率最高99.8%;MobileNet能耗241.05 J,延迟22.07 ms;YOLOX准确率93.0%但效率低。
总结:在Hailo-8上,MobileNet整体表现最优(准确率、延迟、能效均衡);YOLOX能耗和延迟显著偏高,对快速目标(飞机、火车)几乎失效。
4.3 Jetson Orin Nano 实验结果
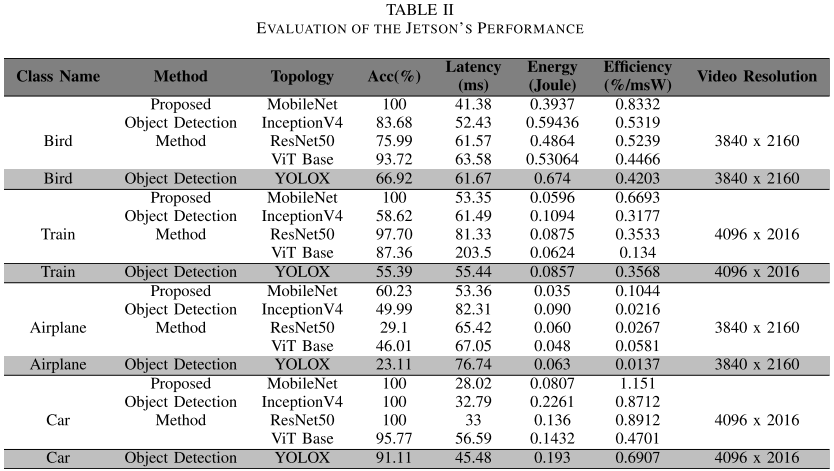
【此处配表:表II,Jetson Orin Nano性能评估结果】
关键结论:
- 鸟类 :MobileNet准确率100%,延迟41.38 ms,能耗仅0.3937 J,效率0.8332%/mW(最高);YOLOX准确率66.92%,效率0.4203%/mW。
- 火车类 :MobileNet准确率再次达到100%,延迟53.35 ms,能耗仅0.0596 J;YOLOX准确率仅55.39%,效率0.3568%/mW。
- 飞机类:MobileNet准确率60.23%,延迟53.36 ms,能耗0.035 J;YOLOX准确率23.11%,延迟76.74 ms,效率0.0137(极低)。
- 汽车类 :MobileNet准确率100%,延迟28.02 ms,能耗0.0807 J,效率高达1.151%/mW;YOLOX准确率91.11%,效率0.6907%/mW。
总结:Jetson上MobileNet表现极为亮眼,鸟、火车、汽车三类均实现满分准确率;飞机类准确率偏低(60.23%),反映高速运动模糊的固有挑战;YOLOX在延迟和效率上均落后。
4.4 AMD Alveo U50 实验结果
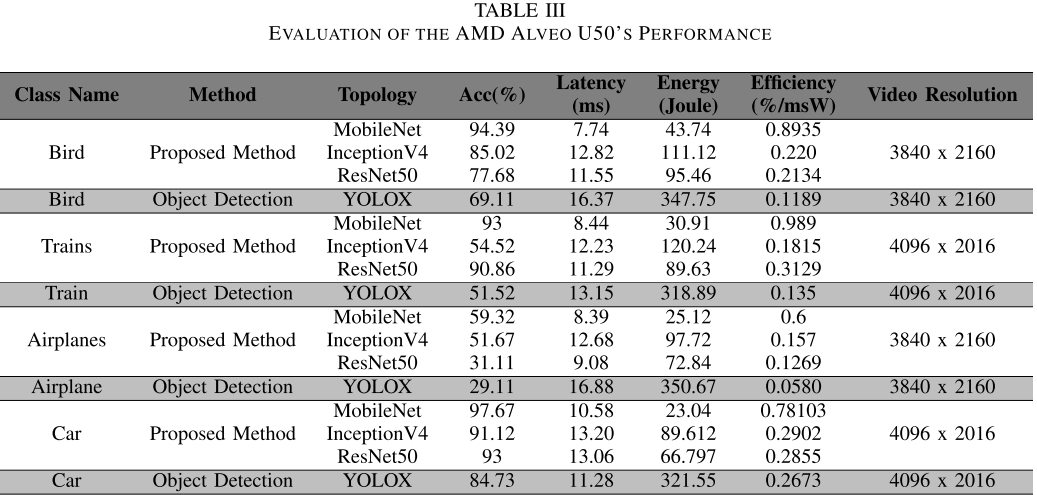
【此处配表:表III,AMD Alveo U50性能评估结果】
注:Vitis AI目前不支持ViT,因此Alveo上仅测试MobileNet、Inception-v4、ResNet50和YOLOX四个模型。
关键结论:
- 鸟类 :MobileNet准确率94.39%,延迟仅7.74 ms(三设备中最低),能耗43.74 J,效率0.8935%/mW(最高);YOLOX准确率69.11%,效率0.1189。
- 火车类:MobileNet准确率93%,延迟8.44 ms,能耗30.91 J;YOLOX准确率51.52%,效率0.135。
- 飞机类:MobileNet准确率59.32%,延迟8.39 ms,能耗25.12 J;YOLOX准确率29.11%,效率0.058。
- 汽车类:MobileNet准确率97.67%,延迟10.581 ms,能耗23.04 J,效率0.78103%/mW;YOLOX准确率84.73%,效率0.2673%/mW。
总结 :Alveo U50的最大优势是极低延迟(7~17 ms),MobileNet综合表现最优;但Vitis AI生态对新型Transformer架构支持有限。
4.5 总体性能对比:提出方法 vs. YOLOX端到端
| 指标 | 提升幅度 |
|---|---|
| 平均准确率提升 | +28.314% |
| 平均效率提升 | 3.6倍 |
| 平均延迟降低 | 39.305% |
这一提升来源于帧差法的根本优势:它只处理发生变化的局部像素区域,而YOLOX等端到端方法需要对整张图像进行全局特征提取,计算量远大于局部方法。
4.6 为什么飞机和火车的准确率偏低?
无论是提出方法还是YOLOX,飞机和火车类的准确率普遍低于鸟类和汽车类,原因在于:
- 运动速度最快:飞机和火车是本实验中速度最快的目标,运动模糊最严重,帧差法和端到端方法均受影响。
- 帧差法对运动模糊敏感:目标边缘在模糊状态下对比度降低,难以精确分割和定位。
- 背景动态噪声:草地、水面等动态背景会引入误检(假阳性)。
- 极快目标的阈值挑战:当目标移动过快时,相邻帧间的差异可能反而减小(目标完全离开检测区域),导致漏检。
五、方法的局限性
作者在论文中坦诚地指出了帧差法的三大固有缺陷:
-
对环境噪声敏感:动态背景(风吹树叶、水面波纹、光照变化)会被误判为运动,产生大量假阳性;摄像头轻微抖动也会引入误检。
-
对慢速/小目标不友好:当目标移动极慢时,相邻帧间像素差异可能低于阈值,导致漏检。
-
极速运动产生的模糊:目标速度过快时,运动模糊会降低目标边缘的对比度,使帧差法难以有效定量分析变化区域。
六、结论与启示
本文提出的帧差法 + 轻量级AI分类器混合算法,在IoT边缘设备上实现了快速移动目标检测的高效部署:
- 相比端到端方法:平均准确率提升28.3%,效率提升3.6倍,延迟降低39.3%。
- 最优模型:MobileNet在所有设备和类别上综合表现最优,是IoT场景的首选。
- 最优设备(延迟角度):AMD Alveo U50延迟最低(7~11 ms),适合对实时性要求极高的场景。
- 最优设备(易用性角度):Jetson Orin Nano生态最完善,开发部署最便捷。
- 适用场景:铁路监控、自动驾驶辅助(ADAS)、无人机目标检测、工业生产线质检、智能安防等需要快速移动目标检测的IoT应用。
这项研究的核心启示在于:在IoT场景中,"够用的精度 + 极高的效率"往往比"最高精度 + 高能耗"更有价值。用轻量化的任务分解思路取代重型端到端模型,是边缘AI落地的务实之道。