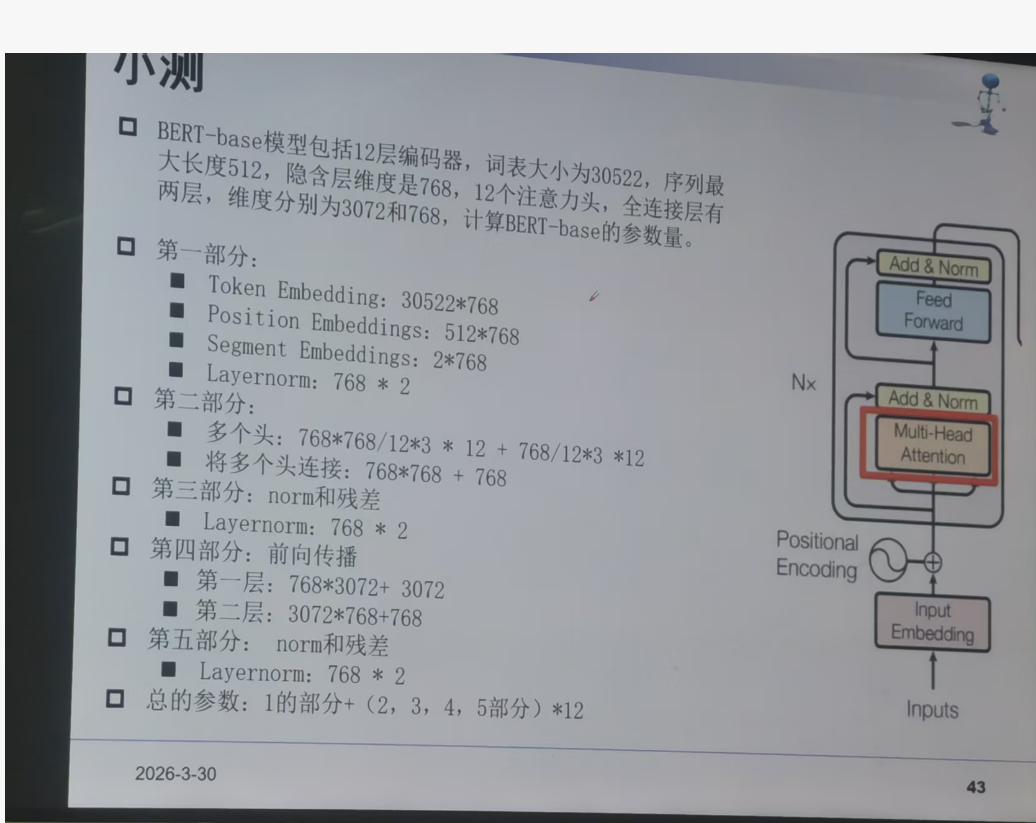
**1. Token Embedding:**嵌入层的作用是将输入的词或标记转换为固定维度的向量。假设词汇表的大小为 V,嵌入向量的维度为 d_model。那么嵌入层的参数量就是 V × d_model
2. 位置编码
(1) Position Embeddings: max_position×d_model
(2) Segment Embeddings: num_segments×d_model
3. Multi-Head Attention: 多头自注意力机制由多个注意力头组成。每个注意力头包括三个线性变换,分别是查询(Query)、键(Key)和值(Value)的变换。假设有 h 个注意力头,每个头的维度为 d_k(通常 d_k = d_model / h)。
对于每个注意力头的查询、键和值的变换,参数量分别是 d_model × d_k。因为有 h 个注意力头,所以总共有 3 × h × d_model × d_k 参数用于这些线性变换。
**4. Layernorm:**残差连接和层归一化(Layer Normalization)部分。层归一化部分的参数量相对较少,每个层归一化有 2 × d_model 个参数(包括一个缩放参数和一个偏移参数)。5.前馈网络: Transformer 中的前馈神经网络通常是位置 - 智能的,每个位置都有相同的结构。它包括两个线性变换,中间有一个激活函数(一般是 ReLU)。假设前馈神经网络的隐藏层维度为 d_ff。
第一个线性变换的参数量是 d_model × d_ff,第二个线性变换的参数量是 d_ff × d_model。因此,前馈神经网络的参数量为 d_model × d_ff + d_ff × d_model + d_model + d_ff (别忘记偏置项)
Transformer参数量
丰海洋2026-04-04 13:47
相关推荐
Litluecat23 分钟前
2026年7月22日科技热点新闻To_OC31 分钟前
别再傻傻分不清:Workflow 和 Agent 到底不是一回事触底反弹1 小时前
🔥 2026 大模型选择指南:别再只看 Benchmark 了,这些维度才是关键!神奇霸王龙1 小时前
GB/T 46886 闭环屠夫:5 旗舰多模态 LLM 工业质检实测南讯股份Nascent1 小时前
洽洽全域会员项目启动会圆满召开大郭鹏宇2 小时前
基于 LangGraph 构建智能分诊系统(一):项目概述与环境搭建小林ixn2 小时前
大模型的“高考成绩单”:读懂Benchmark,选对真·生产力模型冬奇Lab2 小时前
AI 评测系列(04):RAG 评测——RAGAS 四指标实战与一个反直觉发现三声三视2 小时前
uni-app 鸿蒙端传参变成 [object Object]?顺着源码追到 ArkTS router 底层才搞明白fthux2 小时前
“装闭”,让装修套路“装”不下去