目录
[1. 键值对(Key-Value)存储](#1. 键值对(Key-Value)存储)
[2. 键(Key)的唯一性](#2. 键(Key)的唯一性)
[3. 值(Value)的可重复性](#3. 值(Value)的可重复性)
[4. 单向的映射关系](#4. 单向的映射关系)
[5. 顺序的差异化(根据具体实现类而定)](#5. 顺序的差异化(根据具体实现类而定))
[put(K key, V value)](#put(K key, V value))
前言
在之前学习了单列集合Collection接口,现在我们要学习的是Map双列集合,我们常说的双列集合 通常指的是基于 Map 接口实现的数据结构。与单列集合(如 List、Set,每次只存入一个独立元素)不同,双列集合每次存储的都是一对具有关联关系的数据。
一、双列集合的特点
1. 键值对(Key-Value)存储
这是双列集合最本质的特征。集合中的每一个元素实际上是一个 Entry(条目),它包含两个部分:
-
Key(键):数据的唯一标识,类似于数据库中的主键、学生的学号或字典里的单词。
-
Value(值):与键相关联的具体数据,类似于学生的具体档案或字典里单词的解释。
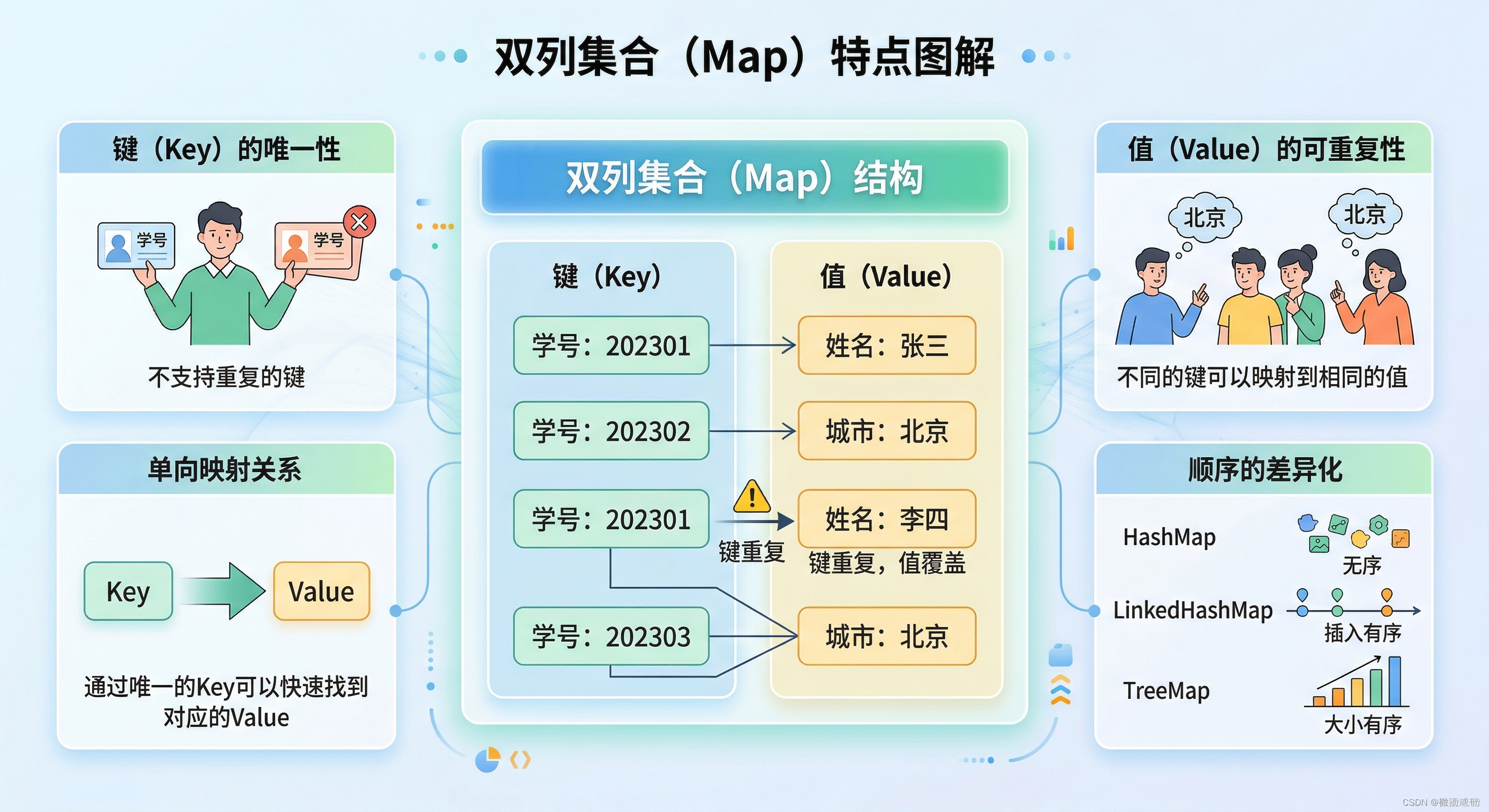
2. 键(Key)的唯一性
在一个双列集合中,绝对不允许存在两个完全相同的 Key。
-
如果你尝试向集合中添加一个已经存在的 Key,系统不会报错,而是会用新的 Value 覆盖掉旧的 Value。
-
举例 :如果你先存入了
<"001", "张三">,随后又存入<"001", "李四">,那么键"001"对应的值就会被更新为"李四"。
3. 值(Value)的可重复性
虽然 Key 必须唯一,但不同的 Key 可以映射到完全相同的 Value。
- 举例 :
<"001", "北京">和<"002", "北京">可以和谐地共存于同一个集合中(两个不同工号的员工都在北京分公司)。
4. 单向的映射关系
每个 Key 最多只能映射到一个确定的 Value,你通过 Key 可以极快地查找到对应的 Value,但通常不能直接通过 Value 反向高效地查找 Key。
如果你需要一个 Key 对应多个数据,通常需要将 Value 设置为一个单列集合(例如
Map<String, List<String>>)。
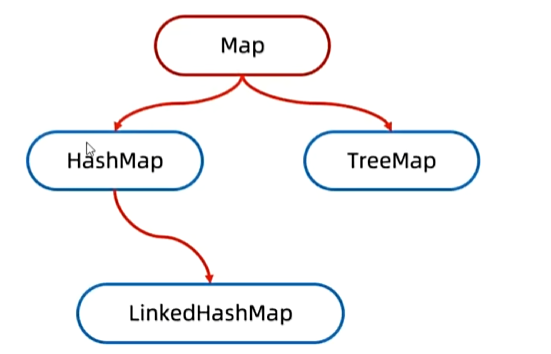
5. 顺序的差异化(根据具体实现类而定)
双列集合本身不保证元素的顺序,具体是否有序取决于你使用的底层实现类:
-
无序集合:如最常用的
HashMap,它存取元素的顺序是不一致的,但它的查找和插入效率最高。 -
插入有序:如
LinkedHashMap,它可以保证你遍历集合时,元素会按照你当初存入的顺序输出。 -
大小有序:如
TreeMap,它会根据 Key 的自然顺序(或者你指定的比较器)对所有的键值对进行自动排序。
二、双列集合Map常用的API
| 方法名 | 说明 |
|---|---|
| V put(K key, V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
put(K key, V value)
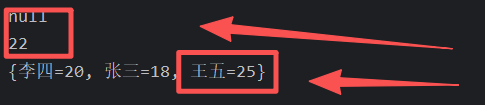
put方法的细节:添加/覆盖
- 在添加数据的时候,如果键不存在,那么直接把键值对对象添加到map集合中,方法返回null
- 如果键已经存在,那么会把原有的键值对对象覆盖,会把覆盖的值进行返回。
java
public class Test {
public static void main(String[] args) {
Map<String, Integer> m = new HashMap<>();
Integer value1 = m.put("张三", 18);
System.out.println(value1);
m.put("李四", 20);
m.put("王五", 22);
Integer value2 = m.put("王五", 25);
System.out.println(value2);
System.out.println(m);
}
}
三、Map的遍历方式
Map有三种遍历方式:
- 键找值
- 键值对
- Lambda表达式
1.键找值遍历
主要是通过**get(K key)**方法通过键获取对应的值。
java
public class Test {
public static void main(String[] args) {
Map<String, Integer> m = new HashMap<>();
m.put("张三", 18);
m.put("李四", 20);
m.put("王五", 22);
//将map中的键,放入单列集合中
Set<String> s = m.keySet();
//通过单列集合中的键找值
s.forEach(key-> {
Integer value = m.get(key);
System.out.println(key + "=" + value);
});
}
}
2.键值对遍历
核心思路是通过获取Map集合中的entry来间接获取键和值。
java
public class Test {
public static void main(String[] args) {
Map<String, Integer> m = new HashMap<>();
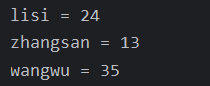
m.put("zhangsan", 13);
m.put("lisi", 24);
m.put("wangwu", 35);
//通过键值对遍历
Set<Map.Entry<String, Integer>> entries = m.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String key = entry.getKey();
int value = entry.getValue();
System.out.println(key + " = " + value);
}
}
}
3.Lambda表达式
java
public class Test {
public static void main(String[] args) {
Map<String, String> m = new HashMap<>();
m.put("2026001", "张三");
m.put("2026002", "李四");
m.put("2026003", "王五");
m.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key + " = " + value);
}
});
}
}
😎😎😎😎