1 多任务损失函数设计
YOLOv3 是一个单阶段、多尺度、多任务的目标检测器。其训练目标可分解为三个子任务:

总损失函数为三者的加权和:
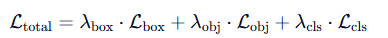
其中权重 λ通常来自超参数配置(如 hyp.scratch.yaml 中 box=0.05, obj=1.0, cls=0.5)。
2 损失函数(复合损失)
YOLOv3 的总损失由三部分加权组成:
(1)边界框坐标损失(Location Loss)
早期版本用 MSE,后续改进常用 CIoU Loss 或 GIoU Loss;
考虑重叠面积、中心点距离、宽高比,提升定位精度。
(2) 置信度损失(Confidence Loss)
对有目标的框(正样本)和无目标的框(负样本)分别计算;
使用 二元交叉熵(BCE);
可引入 Focal Loss 缓解正负样本不平衡。
(3)分类损失(Classification Loss)
对每个预测框,独立计算 80 个类别的 BCE;
使用 sigmoid 而非 softmax,支持多标签(如"猫"和"动物"可同时为真)。
注意:只有 负责预测某真实目标的锚框 才参与分类和坐标损失计算(基于 IoU 最大匹配原则)。
3 多尺度输出与损失分配
YOLOv3 通过 FPN 结构输出 3 个尺度的特征图:
P3/8: 8倍下采样 → 52×52特征图 → 检测小目标
P4/16: 16倍下采样 → 26×26特征图 → 检测中目标
P5/32: 32倍下采样 → 13×13特征图 → 检测大目标
每个尺度使用 3 个预定义锚框(anchor),共 9 个。
训练时:
对每个真实框(GT),选择 IoU 最大的 anchor 所在的尺度,仅该位置、该 anchor 的预测参与 box 和 cls 损失计算,其他位置作为负样本参与 obj 损失(若 IoU < ignore_thresh)。
这种"正样本稀疏分配"机制大幅减少无效梯度干扰。
4 训练策略与技巧
输入尺寸:通常为 416×416(可多尺度训练,如 320~608 随机调整);
YOLOv3训练使用了:
混合精度训练(AMP)
梯度累积
多尺度训练(可选)
标签平滑(可选)
5 关键问题:叠加损失会显著增加计算量吗?
答案:不会。计算量几乎不变,但显存略有增加。
为什么计算量不增加?
前向传播只执行一次:模型推理(Darknet53 + FPN)是主要开销,与损失数量无关
反向传播路径共享:多个损失的梯度在共享节点(如 backbone 输出)自动累加,后续反向只需一次。
损失函数本身极轻量:BCE/CIoU 等操作 FLOPs 可忽略(<0.5% 总计算量)。
也就是说在共享节点( backbone)之前是要同时在3个方向做反向传播,但是在共享节点( backbone)之后就一次反向传播了------这和数学链式求梯度有关。
核心机制:自动微分(Autograd)利用梯度线性性,将多损失反向转化为单次图遍历 + 梯度累加。
GPU显存和CPU开销什么会增加?
GPU 显存:需保留更多中间激活值供反向使用(约 +10%)。
少量 CPU 开销:标签匹配、IoU 计算等(通常非瓶颈)。
实测表明:三损失 vs 单损失,训练速度差异通常 < 5%。