一、什么是哈夫曼树
哈夫曼树(Huffman Tree) 也叫最优二叉树 ,是一种带权路径长度(WPL)最小的二叉树。
- 节点带有权值(比如字符出现的频率)
- 树的带权路径长度 WPL = 所有叶子节点的权值 × 该节点到根的路径长度 之和
- 哈夫曼树的特点:
- 权值越大的节点,离根越近
- 只有度为 0(叶子)和度为 2的节点,没有度为 1 的节点
- n 个叶子节点的哈夫曼树,总共有 2n−1 个节点
二、哈夫曼编码与前缀码
哈夫曼树最经典的应用就是哈夫曼编码,它是一种无损数据压缩算法,核心是利用字符出现的频率(权值),为频率高的字符分配更短的二进制编码,频率低的字符分配更长的编码,从而大幅减少数据传输的总长度。
前缀码的定义
前缀码 :任意一个字符的编码,都不是其他字符编码的前缀。前缀码的核心作用是保证解码的唯一性:在没有分隔符的二进制串中,不会出现歧义,能唯一还原出原始字符。哈夫曼编码天然是前缀码,因为哈夫曼树中所有叶子节点的编码对应根到叶子的唯一路径,不存在一个叶子节点的路径是另一个叶子节点路径的前缀。
三、哈夫曼树构造步骤
哈夫曼树就是每次选两个最小权值节点合并,直到只剩一棵树,最终让整棵树的带权路径长度最小。
核心思想
权值越大的节点离根越近,使带权路径长度(WPL)最小。
构造步骤
| 步骤 | 操作 |
|---|---|
| 1. 初始化 | 将n个带权叶子节点各自作为独立的树(森林) |
| 2. 选最小 | 每次从森林中选取两个根节点权值最小的树 |
| 3. 合并 | 以这两棵树为左右子树,新建根节点(权值=两者之和) |
| 4. 重复 | 将新树放回森林,重复步骤2-3,直到只剩一棵树 |
以 6 个字母的频率表为例,完整演示哈夫曼编码的生成过程:
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 频率 | 27 | 8 | 15 | 15 | 30 | 5 |
步骤 1:构造哈夫曼树
按照哈夫曼树的构造规则,以频率为权值,构造出对应的哈夫曼树,并约定:左分支记为 0,右分支记为 1。
步骤 2:生成哈夫曼编码
从根节点出发,沿着到每个叶子节点的路径,记录 0/1 序列,即为该字母的哈夫曼编码:
- A:根→0→1 → 编码
01 - B:根→1→0→0→1 → 编码
1001 - C:根→1→0→1 → 编码
101 - D:根→0→0 → 编码
00 - E:根→1→1 → 编码
11 - F:根→1→0→0→0 → 编码
1000
最终编码表如下:
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 等长二进制编码 | 000 | 001 | 010 | 011 | 100 | 101 |
| 哈夫曼编码 | 01 | 1001 | 101 | 00 | 11 | 1000 |
步骤 3:编码效果对比
以字符串 BADCADFEED 为例,对比两种编码的总长度:
- 原等长编码二进制串:
001 000 011 010 000 011 101 100 100 011,总长度为 3×10=30 位 - 哈夫曼编码二进制串:
1001 01 00 101 01 00 1000 11 11 00,总长度为 4+2+2+3+2+2+4+2+2+2=25 位
可以看到,哈夫曼编码通过为高频字符分配短编码,成功压缩了数据长度,同时因为是前缀码,解码时不会出现歧义。
四、哈夫曼树的 C 语言实现
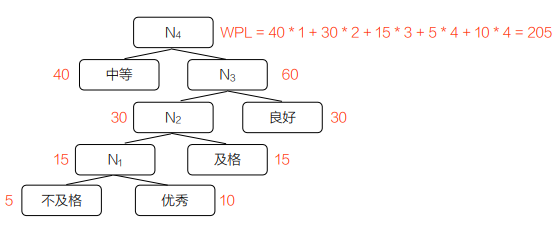
结合不同成绩等级占比的场景(不及格 5%、及格 15%、中等 40%、良好 30%、优秀 10%),用 C 语言实现哈夫曼树的构建与结构打印,代码遵循哈夫曼树的构造规则,注释清晰且易理解。

1. 数据结构设计
定义哈夫曼树的节点结构体,包含权值 、父节点下标 、左孩子下标 、右孩子下标四个核心字段,通过数组存储哈夫曼树的所有节点(顺序存储结构),便于节点的查找与合并。
cpp
#include <stdio.h>
#include <stdlib.h>
#define MAX_N 100 // 定义最大节点数,满足2n-1的需求
// 哈夫曼树节点结构体
typedef struct {
int weight; // 节点权值(如成绩等级占比)
int parent; // 父节点下标,-1表示无父节点
int lchild; // 左孩子下标,-1表示无左孩子
int rchild; // 右孩子下标,-1表示无右孩子
} HTNode;
typedef HTNode HuffmanTree[MAX_N]; // 数组形式存储哈夫曼树2. 核心辅助函数:选择两个最小权值节点
实现selectTwoMin函数,在未被合并的节点(父节点为 - 1)中选出权值最小的两个节点,返回其下标,这是哈夫曼树构造的核心步骤,直接体现贪心策略。
cpp
// 在 HT[0...n-1] 中选出两个无父节点的最小权值节点,下标存入 s1 和 s2
void selectTwoMin(HuffmanTree HT, int n, int *s1, int *s2) {
int i;
*s1 = *s2 = -1; // 初始化下标为-1,表示未找到
for (i = 0; i < n; ++i) {
if (HT[i].parent == -1) { // 仅选择未被合并的节点
if (*s1 == -1 || HT[i].weight < HT[*s1].weight) {
*s2 = *s1;
*s1 = i;
} else if (*s2 == -1 || HT[i].weight < HT[*s2].weight) {
*s2 = i;
}
}
}
}3. 哈夫曼树的构建函数
实现createHuffmanTree函数,遵循构造规则完成哈夫曼树的构建,核心步骤为初始化节点 和循环合并最小权值节点,最终生成总节点数为2n−1的哈夫曼树。
cpp
// 创建哈夫曼树,weights为权值数组,n为叶子节点个数
void createHuffmanTree(HuffmanTree HT, int weights[], int n) {
int i;
int m = 2 * n - 1; // 哈夫曼树总节点数:2n-1
// 初始化所有节点
for (i = 0; i < m; ++i) {
HT[i].weight = (i < n) ? weights[i] : 0; // 前n个为叶子节点,赋权值;其余初始化为0
HT[i].parent = -1;
HT[i].lchild = -1;
HT[i].rchild = -1;
}
// 构造内部节点(从n到m-1)
for (i = n; i < m; ++i) {
int s1, s2;
selectTwoMin(HT, i, &s1, &s2); // 找到两个最小权值的未合并节点
// 合并s1和s2,创建新节点i
HT[i].weight = HT[s1].weight + HT[s2].weight;
HT[i].lchild = s1;
HT[i].rchild = s2;
HT[s1].parent = i; // 给s1和s2设置父节点
HT[s2].parent = i;
}
}4. 打印哈夫曼树结构
实现printHuffmanTree函数,打印哈夫曼树所有节点的索引、权值、双亲、左子、右子信息,便于验证哈夫曼树的构造结果。
cpp
// 打印哈夫曼树结构,直观查看节点关系
void printHuffmanTree(HuffmanTree HT, int n) {
int i;
int total = 2 * n - 1;
printf("索引 权值 双亲 左子 右子\n");
for (i = 0; i < total; ++i) {
printf("%3d %4d %4d %4d %4d\n",
i, HT[i].weight, HT[i].parent, HT[i].lchild, HT[i].rchild);
}
}5. 主函数测试
以成绩等级占比为权值,调用上述函数完成哈夫曼树的构建与打印,验证代码的正确性。
cpp
int main() {
// 权值数组:不及格5、及格15、中等40、良好30、优秀10
int weights[] = {5, 15, 40, 30, 10};
int n = sizeof(weights) / sizeof(weights[0]); // 叶子节点个数n=5
HuffmanTree HT;
createHuffmanTree(HT, weights, n); // 构建哈夫曼树
printHuffmanTree(HT, n); // 输出节点信息
return 0;
}6.完整可运行代码如下
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAXSIZE 100 // 最大节点数
#define MAXCODE 100 // 编码最大长度
// 哈夫曼树节点结构体定义
typedef struct {
int weight; // 节点权值
int parent, lchild, rchild; // 双亲、左孩子、右孩子下标
} HTNode, *HuffmanTree;
// 哈夫曼编码结构体:存储每个叶子节点的编码字符串
typedef char **HuffmanCode;
// ===================== 核心函数1:挑选两个权值最小的节点 =====================
// 在HT[0]~HT[n-1]中,选parent为-1(未合并)的两个最小权值节点,下标存入s1、s2
void Select(HuffmanTree HT, int n, int *s1, int *s2) {
int i, min1, min2; // min1最小权值,min2次小权值
min1 = min2 = 9999; // 初始化一个大数
*s1 = *s2 = -1;
// 遍历所有节点,找最小的两个
for (i = 0; i < n; i++) {
// 只处理没有双亲的节点
if (HT[i].parent == -1) {
// 当前节点权值比最小还小
if (HT[i].weight < min1) {
// 原来最小变成次小
min2 = min1;
*s2 = *s1;
// 更新最小
min1 = HT[i].weight;
*s1 = i;
}
// 当前节点权值比次小小
else if (HT[i].weight < min2) {
min2 = HT[i].weight;
*s2 = i;
}
}
}
}
// ===================== 核心函数2:构建哈夫曼树 =====================
// HT:哈夫曼树数组
// w:权值数组
// n:叶子节点个数
void CreateHuffmanTree(HuffmanTree *HT, int w[], int n) {
int i, s1, s2, m;
// 特殊情况:只有1个叶子节点
if (n <= 1) return;
// 哈夫曼树总结点数:2n-1
m = 2 * n - 1;
// 分配内存
*HT = (HTNode *)malloc((m) * sizeof(HTNode));
// ===================== 初始化所有节点 =====================
for (i = 0; i < m; i++) {
(*HT)[i].weight = 0;
(*HT)[i].parent = -1; // 双亲初始-1
(*HT)[i].lchild = -1; // 左孩子初始-1
(*HT)[i].rchild = -1; // 右孩子初始-1
}
// 给前n个叶子节点赋权值
for (i = 0; i < n; i++) {
(*HT)[i].weight = w[i];
}
// ===================== 开始构建哈夫曼树 =====================
// 循环创建 n-1 个内部节点(从n到m-1)
for (i = n; i < m; i++) {
// 挑选两个最小权值节点
Select(*HT, i, &s1, &s2);
// 合并两个节点,生成新节点i
(*HT)[s1].parent = i;
(*HT)[s2].parent = i;
(*HT)[i].lchild = s1;
(*HT)[i].rchild = s2;
(*HT)[i].weight = (*HT)[s1].weight + (*HT)[s2].weight;
}
}
// ===================== 核心函数3:生成哈夫曼编码(前缀码) =====================
// HT:哈夫曼树
// HC:存储哈夫曼编码
// n:叶子节点数
void CreateHuffmanCode(HuffmanTree HT, HuffmanCode *HC, int n) {
int i, start, c, p;
char *cd;
// 分配编码存储空间
*HC = (HuffmanCode)malloc(n * sizeof(char *));
// 临时存放编码的数组
cd = (char *)malloc(n * sizeof(char));
// 编码结束符
cd[n - 1] = '\0';
// 为每个叶子节点求编码
for (i = 0; i < n; i++) {
// 编码起始位置(从后往前存)
start = n - 1;
// c:当前节点
c = i;
// p:c的双亲节点
p = HT[c].parent;
// 向上遍历到根节点(根节点parent=-1)
while (p != -1) {
// 如果c是左孩子,编码为0
if (HT[p].lchild == c)
cd[--start] = '0';
// 如果c是右孩子,编码为1
else
cd[--start] = '1';
// 继续向上
c = p;
p = HT[c].parent;
}
// 为第i个编码分配空间
(*HC)[i] = (char *)malloc((n - start) * sizeof(char));
// 复制编码
strcpy((*HC)[i], &cd[start]);
}
// 释放临时空间
free(cd);
}
// ===================== 计算带权路径长度WPL =====================
int GetWPL(HuffmanTree HT, int n) {
int i, wpl = 0;
int c, p, len;
// 遍历每个叶子节点
for (i = 0; i < n; i++) {
len = 0;
c = i;
p = HT[c].parent;
// 统计路径长度
while (p != -1) {
len++;
c = p;
p = HT[c].parent;
}
// 累加 权值×路径长度
wpl += HT[i].weight * len;
}
return wpl;
}
// ===================== 打印哈夫曼树结构 =====================
void PrintHT(HuffmanTree HT, int n) {
int i, m = 2 * n - 1;
printf("\n===== 哈夫曼树节点信息 =====\n");
printf("下标\t权值\t双亲\t左孩子\t右孩子\n");
for (i = 0; i < m; i++) {
printf("%d\t%d\t%d\t%d\t%d\n",
i, HT[i].weight, HT[i].parent, HT[i].lchild, HT[i].rchild);
}
}
// ===================== 主函数:测试 =====================
int main() {
// 叶子节点权值(示例:不及格5、及格15、中等40、良好30、优秀10)
int w[] = {5, 15, 40, 30, 10};
// 叶子节点名称(对应上面权值)
char name[][20] = {"不及格", "及格", "中等", "良好", "优秀"};
int n = sizeof(w) / sizeof(w[0]); // 叶子节点数量 n=5
HuffmanTree HT; // 哈夫曼树
HuffmanCode HC; // 哈夫曼编码
int i, wpl;
// 1. 创建哈夫曼树
CreateHuffmanTree(&HT, w, n);
// 2. 打印哈夫曼树结构
PrintHT(HT, n);
// 3. 生成哈夫曼编码
CreateHuffmanCode(HT, &HC, n);
// 4. 打印哈夫曼编码(前缀码)
printf("\n===== 哈夫曼编码(前缀码) =====\n");
for (i = 0; i < n; i++) {
printf("%s\t(权值:%d)\t编码:%s\n", name[i], w[i], HC[i]);
}
// 5. 计算并打印WPL
wpl = GetWPL(HT, n);
printf("\n带权路径长度 WPL = %d\n", wpl);
// 6. 前缀码说明
printf("\n===== 前缀码特性说明 =====\n");
printf("1. 哈夫曼编码是前缀码:任意编码都不是其他编码的前缀\n");
printf("2. 解码无歧义,可唯一还原原始数据\n");
// 释放内存
for (i = 0; i < n; i++) {
free(HC[i]);
}
free(HC);
free(HT);
return 0;
}代码运行结果
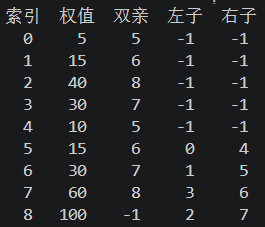
结果分析:总节点数为2×5−1=9,根节点为索引 8(权值 100,无父节点),
所有叶子节点(0-4)无孩子节点,内部节点均有左右两个孩子,符合哈夫曼树的特性。
五、哈夫曼树考研真题解析
哈夫曼树是数据结构考研的高频考点,题型主要包括哈夫曼树的构造 、带权路径长度(WPL)的计算 、哈夫曼编码的生成 、前缀码的判断等,以下结合考研经典真题,讲解解题思路与步骤。
真题 1:2010 年统考真题

答案:A
解析:
- A 错误:哈夫曼树是带权路径长度最短的二叉树,不是完全二叉树,完全二叉树是按层序编号的结构,哈夫曼树不满足该特性。
- B 正确:哈夫曼树的构造规则是每次合并两个节点,因此不存在度为 1 的节点。
- C 正确:构造哈夫曼树时,权值最小的两个节点会被优先合并为兄弟节点。
- D 正确:非叶节点的权值是子节点权值之和,因此一定大于等于子节点的权值,也一定不小于下一层的任意节点权值。
真题 2:2014 年统考真题

答案:D
解析 :前缀码的核心要求是任意编码都不是其他编码的前缀。
- D 选项中,
110是1100的前缀,因此不是前缀编码,其余选项均满足前缀码要求。
真题 3:2021 年统考真题

答案:B
解析:
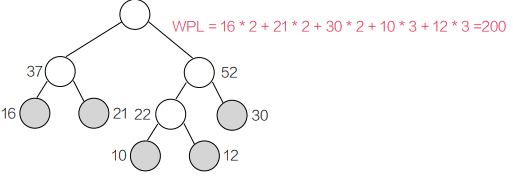
最小带权路径长度即哈夫曼树的 WPL,构造哈夫曼树后计算:
- 合并 10 和 12 → 22;合并 22 和 16 → 38;合并 38 和 21 → 59;合并 59 和 30 → 89
- WPL = 16×2 + 21×2 + 30×2 + 10×3 + 12×3 = 32 + 42 + 60 + 30 + 36 = 200(也可通过累加内部节点权值计算:22+38+59+89=200)
真题 4:2019 年统考真题

答案:C
解析:
哈夫曼树的总节点数公式为 m=2n−1,代入 m=115:2n−1=115→2n=116→n=58
五、哈夫曼树的应用场景
哈夫曼树的核心价值是带权路径长度最短,基于这一特性,在实际开发和算法设计中有着广泛应用:
- 数据压缩:哈夫曼编码是无损数据压缩的经典算法,如 JPEG、ZIP、GZIP 等格式均采用了哈夫曼编码,对出现频率高的字符赋予短编码,频率低的字符赋予长编码,大幅减少数据存储体积。
- 权重决策:在任务调度、资源分配等场景中,对优先级(权值)高的任务赋予更短的处理路径,提高处理效率。
- 最优判定:在判定树设计中(如成绩等级判定、商品等级判定),哈夫曼树可使平均判定次数最少,优化判定逻辑。
- 通信编码:在远距离通信中,哈夫曼编码可减少数据传输的总长度,降低传输成本,同时保证解码的唯一性。
六、总结
哈夫曼树是数据结构中贪心算法的典型应用,其核心是通过 "每次合并最小权值节点" 的策略,构造出带权路径长度最短的二叉树。本文从基础概念出发,结合成绩占比场景实现了哈夫曼树的 C 语言代码,详解了哈夫曼编码与前缀码的原理,又通过考研真题讲解了构造、WPL 计算、编码生成等高频考点,核心要点总结:
- 哈夫曼树的结构特性:2n−1个总节点,无度为 1 的节点,是严格二叉树。
- 构造的核心是贪心策略,考研中需遵循固定的左右孩子约定。
- WPL 的简便计算方法为累加所有内部节点的权值,可快速解题。
- 哈夫曼编码是前缀编码,由根到叶子的左右分支 0/1 序列生成,保证解码唯一性。
- 前缀码的判断核心:任意编码都不是其他编码的前缀,是哈夫曼编码的核心特性。