摘要
本文介绍了K近邻(KNN)算法的基本原理与实现方法。KNN通过计算样本间距离,依据最近的K个邻居进行多数投票(分类)或均值计算(回归)来预测新样本的类别或数值。文章阐述了欧式距离的计算方式,分析了K值过小或过大对模型的影响,并给出了分类与回归的标准流程。此外,文中还展示了基于scikit-learn库的KNN分类与回归代码示例。KNN是一种简单有效的非参数机器学习方法。
Abstract
This article introduces the basic principles and implementation of the K-Nearest Neighbors (KNN) algorithm. KNN predicts the category or value of a new sample by calculating distances between samples and performing majority voting (classification) or averaging (regression) based on its K nearest neighbors. It explains the calculation of Euclidean distance, analyzes the impact of too small or too large K values, and presents the standard procedures for classification and regression. Additionally, code examples for KNN classification and regression using the scikit-learn library are demonstrated. KNN is a simple and effective non-parametric machine learning method.
一. K近邻算法
KNN算法思想:如果一个样本在特殊空间中的k个最相似的样本中的大多数属于一个类别,则该样本也属于该类别。
就如利用K近邻算法预测电影类型,如下表,其中1到9的电影名称以及三个不同类别的镜头为x_train,对应的电影类型为y_train,而第10个的电影名称以及三个不同类别的镜头为x_test,我们要预测的就是其对对应的电影类别y_test。
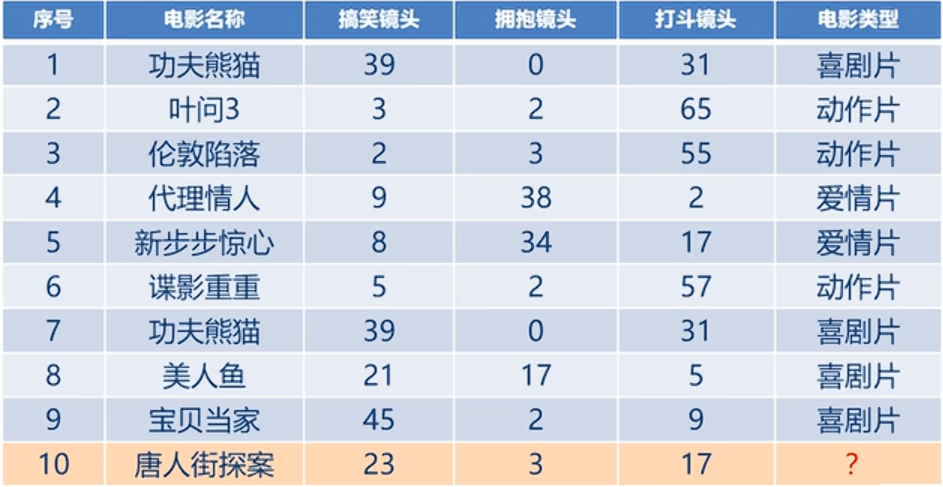
这时K近邻,若K等于5,则是找最近的5个进行投票,这个5个中那个电影类型多,则第10个电影的类型就是谁。
样本的相似性中样本都是属于一个任务数据集的,样本间的距离越近相似度越高。距离有很多种计算方式对此我们先了解最简单的欧式距离。
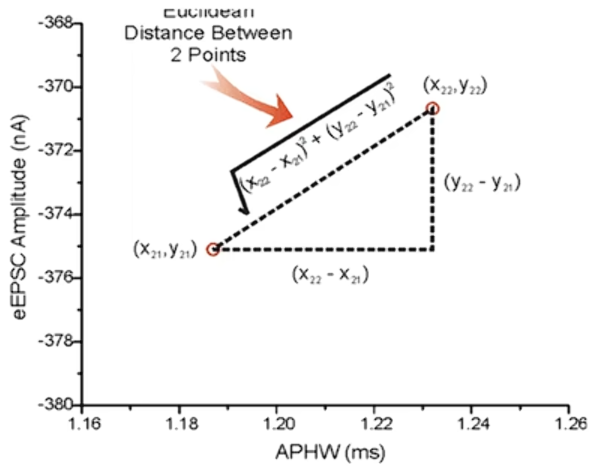
欧式距离就是对应维度差值的平方和再开平方跟,在二维平面上的欧式距离就相当于我们学过的勾股定理用两直角边求斜边。

对此在下面这个表中,唐人街探案与功夫熊猫之间的距离为\sqrt{(39−23)^2−3−(31−17)^2}=21.47
对此通过计算后得到五个距离最近的的样本如下:
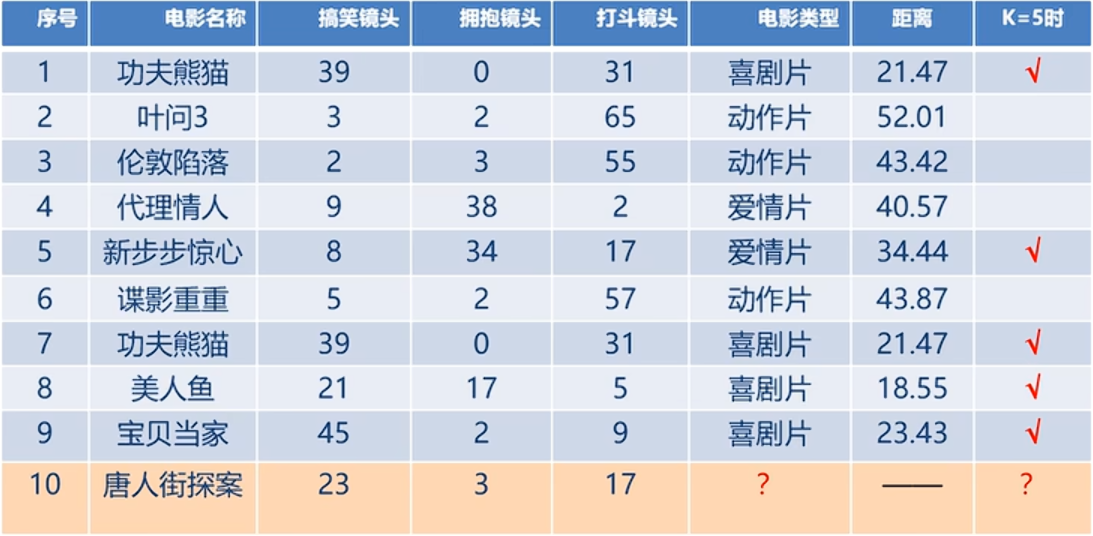
在这5个电影中,我们可以发现喜剧片有四个,所以对应的唐人街探案电影对应的类别就是喜剧片。
回到算法本身,K近邻算法中的K值的选择也是很重要的。
若k值过小,也就是用较小领域中的训练实例进行预测,这时就容易受到异常点的影响,k值的减小就意味着整个模型变得复杂,容易发生过拟合。
若k值过大,也就是用较大领域中的训练实例进行预测,这时就容易样本均衡的问题,k值的增大就意味着整个模型变得简单,容易发生欠拟合。
例如当K=N(N为训练样本个数),所以无论输入的实例是什么,只会按训练集中最多的类别进行预测。
对此我们就要对K超参数进行调优,也就是用一些方法寻找合适的k,例如交叉验证和网格搜索。
二.K近邻算法分类流程与回归流程
KNN根据标签的连续,可分为分类问题与回归问题。其中我们可以将分类问题看作是投票,回归问题可以看作是均值。
其中分类流程如下:
1.计算未知样本到每一个训练样本的距离
2.将训练样本根据距离大小升序排列
3.取出距离最近的K个训练样本
4.进行多数表决,统计K个样本中哪个类别的样本个数最多
5.将未知的样本归属到出现次数最多的类别
而回归流程前三步是一样的,后两部不同:
1.计算未知样本到每一个训练样本的距离
2.将训练样本根据距离大小升序排列
3.取出距离最近的K个训练样本
4.把这个K个样本的目标值计算其平均值
5.作为将未知的样本预测的值
三.KNN算法API介绍
1.KNN算法分类API
KNN分类API:
sklearn.neighbors.KNeighborsClassifier(n_neighbors=3)
其中n_neighbors是int型,且值是可以选择的(默认为5),k_neighbors查询默认使用的邻居数。
对此KNN算法的分类思想的代码实现如下:
python
# 1.导包
from sklearn.neighbors import KNeighborsClassifier
# 2.装备数据集(测试集 和 训练集)
x_train = [[0], [1], [2], [3]] # 训练集的特征数据
y_train = [0, 0, 1, 1] # 训练集的标签数据
x_test = [[5]] # 测试集的特征数据
# 3.创建(KNN 分类模型)模型对象
# estimator:估计器 也可用model做接受
estimator = KNeighborsClassifier(n_neighbors=3)
# 4.模型训练
estimator.fit(x_train, y_train)
# 5.模型预测
y_pre = estimator.predict(x_test)
# 打印预测结果
print(f'预测值为:{y_pre}')其中训练集的特征与标签是手动输入的,最后运行的结果如下:
python
预测值为:[1]2.KNN算法回归API
KNN回归API:
sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
对此KNN算法的回归思想的代码实现如下:
python
from sklearn.neighbors import KNeighborsRegressor # KNN算法的回归模型
# 2.装备数据集(测试集 和 训练集)
x_train = [[0, 0, 1], [1, 1, 0], [3, 10, 10], [4, 11, 12]] # 训练集的特征数据,因为特征值有多个,所以是一个二维数组
y_train = [0.1, 0.2, 0.3, 0.4] # 训练集的标签数据
x_test = [[3, 11, 10]]
# 3.创建(KNN 回归模型)模型对象
# estimator:估计器 也可用model做接受
estimator = KNeighborsRegressor(n_neighbors=3)
# 4.模型训练
estimator.fit(x_train, y_train)
# 5.模型预测
y_pre = estimator.predict(x_test)
# 打印预测结果
print(f'预测结果:{y_pre}')其中训练集的特征与标签是手动输入的,最后运行的结果如下:
python
预测结果:[0.3]总结
本文系统讲解了KNN算法的核心思想------近朱者赤,通过距离度量与邻居投票完成预测。文中详细说明了欧式距离的计算,强调了K值选择对模型偏差与方差的影响:K过小易过拟合,K过大易欠拟合。同时,给出了分类与回归两种任务下的完整流程,并借助scikit-learn库提供了可运行的代码示例。KNN作为机器学习中的基础算法,理解其原理对后续学习其他基于实例的方法具有重要意义。