讲解顺序 "先看pipeline → 拆模块 → 讲创新点 → 讲训练/损失 → 讲部署" ,重点以 Ultralytics 官方文档 + 官方 yolov8.yaml + 当前源码实现 为准。关键的事实:YOLOv8 没有一篇官方正式论文,Ultralytics 自己也明确说明,YOLOv8 更适合直接看官方文档和源码。 (GitHub)
1. YOLOv8 是什么
YOLOv8 是 Ultralytics 在 2023-01-10 发布的实时视觉框架。它不只是一个检测模型,而是一套统一框架:官方文档列出的原生任务包括 检测、实例分割、姿态估计、旋转框检测、分类 ,并且都支持 Inference / Validation / Training / Export 。(GitHub)
对"检测版"来说,YOLOv8 最核心的三个关键词是:
C2f 模块、anchor-free split head、统一导出部署链路。 官方文档明确写到它采用 anchor-free split Ultralytics head ;和 YOLOv5 对比页则明确指出,YOLOv8 用 C2f 替换了 YOLOv5 的 C3 ,并转向 anchor-free 检测头。(GitHub)
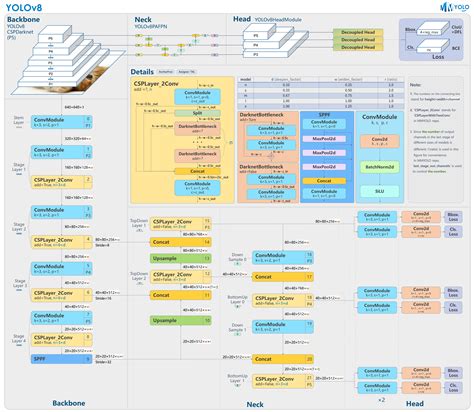
2. 标准 YOLOv8 检测版网络结构图
以官方默认检测配置 ultralytics/cfg/models/v8/yolov8.yaml 为准,标准 P5 检测模型输出 3 个检测层:P3/8、P4/16、P5/32 。n/s/m/l/x 五个规模共享同一拓扑,只通过 depth / width / max_channels 做复合缩放。(GitHub)
可以把它画成这张源码对应的结构图:
text
Input
└─ Backbone
├─ Conv(64, 3x3, s=2) -> P1/2
├─ Conv(128, 3x3, s=2) -> P2/4
├─ C2f(128, n=3)
├─ Conv(256, 3x3, s=2) -> P3/8
├─ C2f(256, n=6)
├─ Conv(512, 3x3, s=2) -> P4/16
├─ C2f(512, n=6)
├─ Conv(1024, 3x3, s=2) -> P5/32
├─ C2f(1024, n=3)
└─ SPPF
└─ Neck
├─ Upsample
├─ Concat(P4) + C2f
├─ Upsample
├─ Concat(P3) + C2f -> small branch
├─ Downsample + Concat + C2f -> medium branch
├─ Downsample + Concat + C2f -> large branch
└─ Detect(P3, P4, P5)
Outputs:
P3/8 small objects
P4/16 medium objects
P5/32 large objects这不是"经验图",而是直接对应官方 yolov8.yaml:Backbone 从两层 stride=2 的 Conv 开始,随后是多段 C2f,再到 SPPF;Head 里先两次上采样和拼接,再两次下采样和拼接,最后 Detect(P3, P4, P5)。(GitHub)
3. Backbone、Neck、Head 分别在做什么
3.1 Backbone:主干特征提取
默认 Backbone 的层序非常清楚:
Conv -> Conv -> C2f -> Conv -> C2f -> Conv -> C2f -> Conv -> C2f -> SPPF。其中 P3、P4、P5 三个主尺度特征分别在 1/8、1/16、1/32 下采样倍率处形成。(GitHub)
SPPF 仍然保留在 Backbone 末端,作用是扩大感受野并聚合上下文。YOLOv8 没有像某些后续模型那样大改末端金字塔池化,而是保留了这一块成熟设计。(GitHub)
3.2 Neck:FPN + PAN 风格的双向融合
虽然 Ultralytics 文档没有把它单独命名成某个固定 Neck 名字,但从 yolov8.yaml 的 Head 路径可以直接看出:它先 上采样 + Concat 把高层语义往浅层传,再 下采样 + Concat 把融合后的浅层细节回流到中高层,所以本质上就是 FPN/PAN 风格的双向特征融合 。(GitHub)
这个设计的工程意义很直接:
- P3/8 更偏小目标;
- P4/16 更偏中目标;
- P5/32 更偏大目标。 (GitHub)
3.3 Head:anchor-free 的分离式检测头
官方文档把它叫做 anchor-free split Ultralytics head 。源码里当前 Detect 头的实现也能看出来,它有两条主分支:
cv2:box branch ,输出4 * reg_maxcv3:class branch ,输出nc。(GitHub)
一个很重要、也很容易被旧资料误解的点是:当前 YOLOv8 检测头没有单独的 objectness 分支。 源码里 self.no = nc + self.reg_max * 4,不是旧 YOLO 常见的 nc + 5;训练损失里也是直接取 pred_scores 做分类 BCE,再配 box + dfl,没有单独的 obj loss 分支。(GitHub)
4. C2f 到底是什么,为什么它重要
C2f 是 YOLOv8 里最有辨识度的结构块。官方代码对它的定义非常直接:"Faster Implementation of CSP Bottleneck with 2 convolutions." 它先用 cv1 把输入映射到 2 * hidden_channels,再把特征拆成两路,后续把若干个 Bottleneck 的输出一路一路追加进来,最后全部 concat 后通过 cv2 融合。(GitHub)
从实现看,C2f 的关键信号流是:
cv1(x) -> chunk 成两部分 -> 一部分连续过 n 个 Bottleneck -> 把每一级输出都保留 -> concat -> cv2。(GitHub)
这和 YOLOv5 的 C3 相比,最大的直观差异不是"名字从 3 变 2",而是 中间更多保留分支级特征,再统一拼接融合 。官方对比页给出的总结是:C2f 相比 C3,主要目标是 更好的梯度流和更丰富的特征表达 ,同时不过度增加计算成本。(Ultralytics Docs)
5. YOLOv8 的关键创新点
5.1 从 anchor-based 转向 anchor-free
这是 YOLOv8 最核心的架构变化之一。官方对比页明确说,YOLOv8 的 anchor-free head 省去了手工 anchor 配置,并减少了框预测数量,从而让模型在自定义数据集上更稳,也会让后处理里的 NMS 更轻一些。(Ultralytics Docs)
可以这样理解:
YOLOv5/7 更像"基于预设框去修正",YOLOv8 更像"直接在网格点上回归目标"。 这让迁移到新数据集时,少了一层"先配 anchor"的工程成本。(GitHub)
5.2 分离式 Head
YOLOv8 的 Head 不是单一输出卷积,而是把 框回归 和 分类 分开做。当前源码里 one2many 直接暴露为 box_head=self.cv2, cls_head=self.cv3,这就是非常明确的 decoupled design。(GitHub)
分离式 Head 的意义在于:
定位和分类本来就是两个优化目标,拆开后一般更容易收敛,也更利于后续针对不同分支做轻量化或导出优化。(Ultralytics Docs)
5.3 DFL 回归
当前 Detect 头默认 reg_max=16,所以每个位置的框分支先输出 4 * 16 = 64 个通道;随后在损失和解码里,通过 softmax 加权投影恢复成四个连续距离值,再通过 dist2bbox 解码为框。(GitHub)
这意味着 YOLOv8 的框回归不是"直接回归 4 个数",而是 用离散分布去近似连续边距 。这通常比直接回归更稳,尤其是在高精度定位场景里。(GitHub)
5.4 任务对齐分配
当前 v8DetectionLoss 默认使用 TaskAlignedAssigner,源码里默认参数是 topk=10、alpha=0.5、beta=6.0;而 TaskAlignedAssigner 的说明写得也很清楚:它用一个同时结合 分类信息与定位信息 的 task-aligned metric 来做正负样本分配。(GitHub)
这比"只按 IoU"或者"只按中心点"更像一种联合筛选:
既看你分得像不像,又看你框得准不准。 (GitHub)
6. YOLOv8 检测版训练时到底优化什么
当前检测损失是 3 项:
- box loss
- cls loss
- dfl loss 。(GitHub)
源码里分类损失明确是 BCEWithLogitsLoss;框损失里 bbox_iou(..., CIoU=True),也就是当前实现默认用 CIoU ;如果启用 DFL,就再加一项 Distribution Focal Loss 。(GitHub)
理解:
TaskAlignedAssigner 先分配正样本 → 分类分支做 BCE → 回归分支做 CIoU → 分布式边距再做 DFL。 (GitHub)
7. n/s/m/l/x 五种尺度模型选择
官方 yolov8.yaml 给了五个缩放档位,n/s/m/l/x 对应不同的 depth / width / max_channels;官方模型页也给了 COCO 检测版的参数量、FLOPs 和速度。(GitHub)
最常用的五档大致是:
- YOLOv8n:3.2M 参数,8.7B FLOPs,COCO mAP 37.3
- YOLOv8s:11.2M 参数,28.6B FLOPs,mAP 44.9
- YOLOv8m:25.9M 参数,78.9B FLOPs,mAP 50.2
- YOLOv8l:43.7M 参数,165.2B FLOPs,mAP 52.9
- YOLOv8x :68.2M 参数,257.8B FLOPs,mAP 53.9。(GitHub)
工程上一般可以这样选:
- n:机器人、无人机、边缘端、低功耗设备;
- s / m:大多数工业视觉项目的默认起点;
- l / x :追精度、算力相对充足的服务器侧。
这是基于官方参数和性能表做的工程建议。(GitHub)
8. YOLOv8 不只是检测:它其实是个多任务家族
官方模型页明确列出,YOLOv8 这代并不只做检测,还同时维护:
yolov8*.pt:检测yolov8*-seg.pt:实例分割yolov8*-pose.pt:姿态yolov8*-obb.pt:旋转框yolov8*-cls.pt:分类。(GitHub)
这对实际项目很重要:
如果想把"检测框"升级成"检测+mask"或者"检测+关键点",YOLOv8 的 API 和训练/导出方式是一套统一生态,不用整条工具链重搭。(GitHub)
9. 部署:YOLOv8 怎么落地
YOLOv8 属于 Ultralytics YOLO 统一导出体系的一部分。官方导出页给出的核心结论是:一个训练好的 Ultralytics YOLO 模型,可以导出到 ONNX、OpenVINO、TensorRT、CoreML、TF SavedModel、TFLite、NCNN、MNN、RKNN、ExecuTorch 等多种格式。 官方还给出经验值:ONNX / OpenVINO 最多可带来约 3× CPU speedup,TensorRT 最多可带来约 5× GPU speedup。 (Ultralytics Docs)
9.1 最常见的导出方式
Python:
python
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.export(format="onnx")CLI:
bash
yolo export model=yolov8n.pt format=onnxYOLOv8 模型页确认了 yolov8n.pt 这类检测模型支持 Export;导出页给出了统一的 model.export(format="onnx") 和 yolo export model=... format=onnx 用法。(GitHub)
9.2 你应该优先选哪种部署后端
针对:
- NVIDIA GPU / Jetson / 服务器 :优先 TensorRT
- x86 CPU / 通用服务端 :优先 ONNX 或 OpenVINO
- iPhone / Apple 生态 :优先 CoreML
- Android / 轻量边缘端 :优先 NCNN 或 TFLite
- 国产 SoC / NPU 链路 :看 RKNN / MNN / IMX500 / ExecuTorch 之类后端。
部署工程归纳。(Ultralytics Docs)
9.3 部署时最容易踩的坑
最常见的不是"模型不对",而是这三件事没对齐:
- 预处理:缩放、padding、通道顺序、归一化
- 输出特征解析对齐 :YOLOv8 现在是 box distribution + class scores ,不是老 YOLO 的
xywh + obj + cls - 后处理 :导出时是否把 NMS 一起导进图,要和你的推理代码保持一致。(GitHub)
尤其是第 2 点,很多旧 C++ 后处理代码默认假设输出里有 obj 分支,直接套 YOLOv5/7 的解析方式,结果就会错。YOLOv8 当前实现里,检测头和损失都表明它不是那种输出格式。(GitHub)
10.总结 YOLOv8
YOLOv8 = C2f 主干 + SPPF + FPN/PAN 风格双向融合 + anchor-free 分离式检测头 + TaskAlignedAssigner + CIoU/DFL + Ultralytics 统一部署生态。 它最大的价值不只是"精度更高",而是 从训练、迁移、多任务扩展到部署导出都更统一、更工程化。 (GitHub)
参考链接: