一、引言
在实际爬虫开发中,最复杂的场景莫过于:网站有多个导航分类,每个分类下又有分页,需要先遍历导航分类,再遍历每个分类下的分页,最后从每个文章页提取数据。这种"多级嵌套循环"的结构,对爬虫的流程控制能力提出了极高要求。
本文将深入分析一个针对 resource-recycling.com 新闻站点的爬虫设计案例。该爬虫创新性地解决了 "多级导航循环" 和 "class属性ID提取" 两大核心难题,实现了对多分类新闻网站的高效采集。
与之前案例的核心差异:
- 导航层级差异:先提取导航分类,再遍历每个分类(之前多为单一路径)
- ID存储差异:ID存储在article的class属性中,格式如"post-12345"
- 循环嵌套差异:三层循环(导航→分页→文章列表)
- 导航提取差异:从首页提取所有导航链接
- URL构建差异:导航路径 + 分类路径 + 分页路径
二、系统架构与核心流程
2.1 整体架构设计
该爬虫采用 "三层嵌套循环架构",整体流程如下:
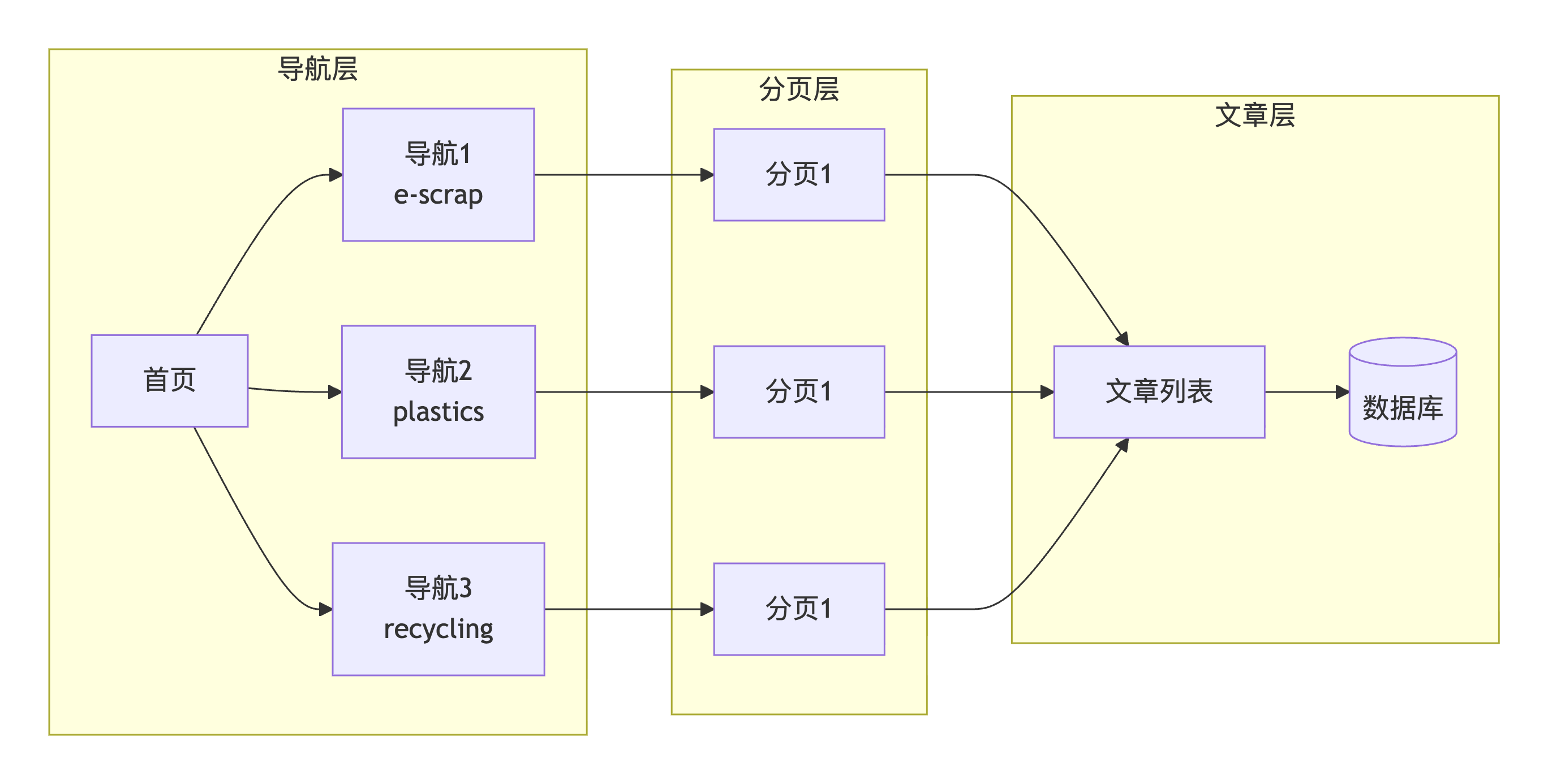
2.2 数据流向图

三、关键技术难点与解决方案
难点一:多级导航循环架构
问题描述:
该网站有多个新闻分类(如e-scrap、plastics等),需要先从首页提取所有导航链接,然后对每个导航分类分别进行分页抓取。这是一个典型的多级循环问题。
解决方案:
构建 "三层嵌套循环" 架构:
javascript
// 第一层:提取导航链接
{
"variable-name": ["navigation"],
"variable-value": [
"${extract.selectors(resp.html, '.vc_figure>a', 'attr', 'href')}"
]
}
// 第二层:导航循环(固定3个分类)
{
"value": "循环",
"loopVariableName": "i",
"loopCount": "3",
"loopStart": "0"
}
// 在循环内构建分类URL
"url": "https://resource-recycling.com/${navigation[i]}/category/news/page/${page}/"
// 第三层:分页循环
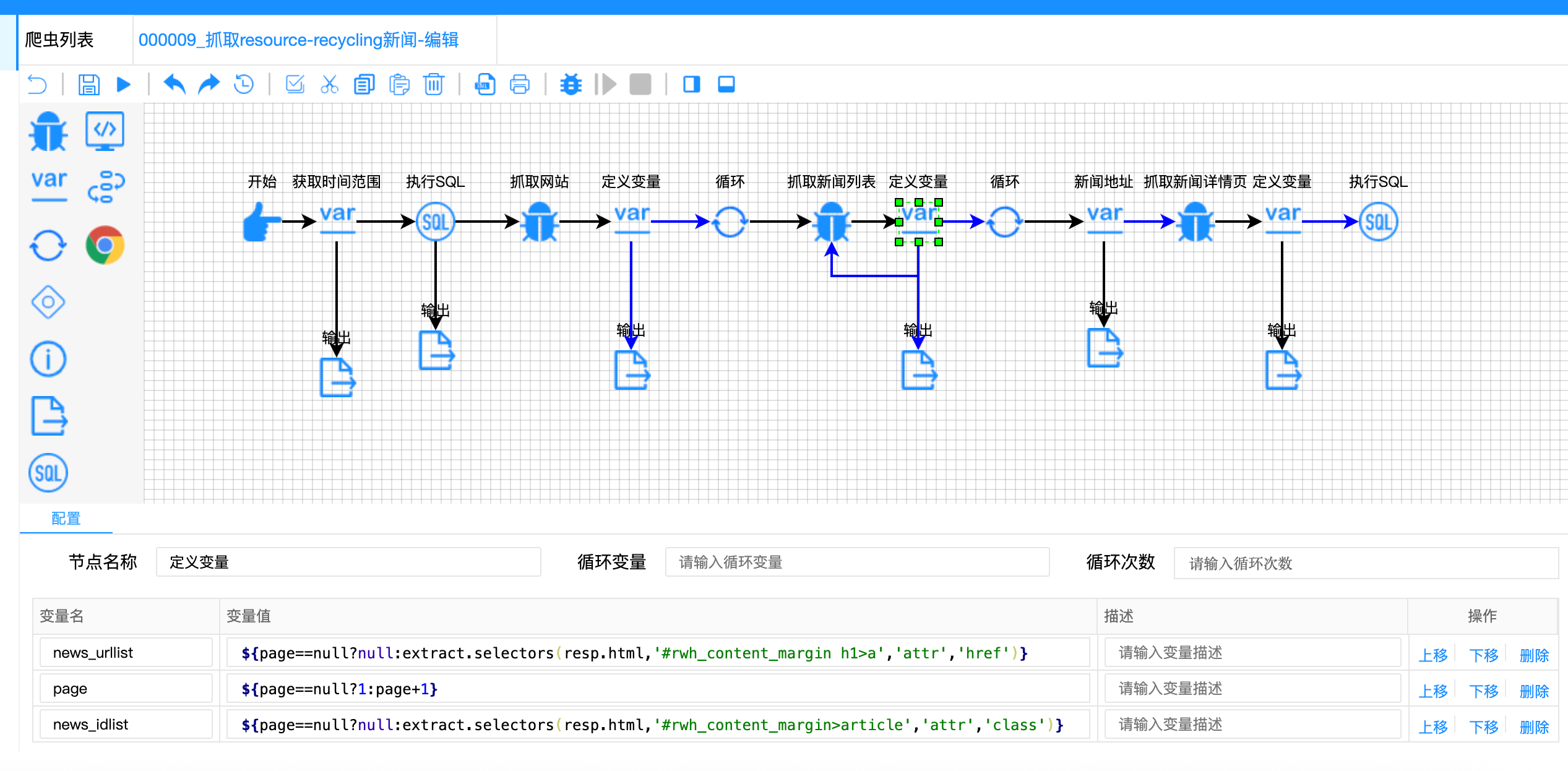
{
"variable-name": ["news_urllist", "page", "news_idlist"],
"variable-value": [
"${page==null?null:extract.selectors(resp.html, '#rwh_content_margin h1>a', 'attr', 'href')}",
"${page==null?1:page+1}",
"${page==null?null:extract.selectors(resp.html, '#rwh_content_margin>article', 'attr', 'class')}"
]
}
多级循环原理图:
文章层循环 index
分页层循环 page=1
导航层循环 i=0 to 2
i=0: e-scrap
分页循环
i=1: plastics
分页循环
i=2: recycling
分页循环
page=1
提取文章列表
page=1
提取文章列表
page=1
提取文章列表
遍历每篇文章
遍历每篇文章
遍历每篇文章
URL构建示例:
| 导航i | navigationi | page | 完整URL |
|---|---|---|---|
| 0 | e-scrap | 1 | /e-scrap/category/news/page/1/ |
| 1 | plastics | 1 | /plastics/category/news/page/1/ |
| 2 | recycling | 1 | /recycling/category/news/page/1/ |
难点二:class属性中的ID提取
问题描述:
新闻ID存储在article标签的class属性中,格式为"post-12345 post-xxx",需要从中提取数字ID。
解决方案:
使用正则表达式从class字符串中提取数字:
javascript
// 第一层:提取class属性
"${extract.selectors(resp.html, '#rwh_content_margin>article', 'attr', 'class')}"
// 返回: ["post-12345 post-xxx", "post-12346 post-xxx", ...]
// 第二层:正则提取数字
"${news_idlist[index].regx('(?<=post-)(\\d+)').toInt()}"
// 正则解释: (?<=post-) 匹配前面有"post-"的位置
// (\d+) 提取连续数字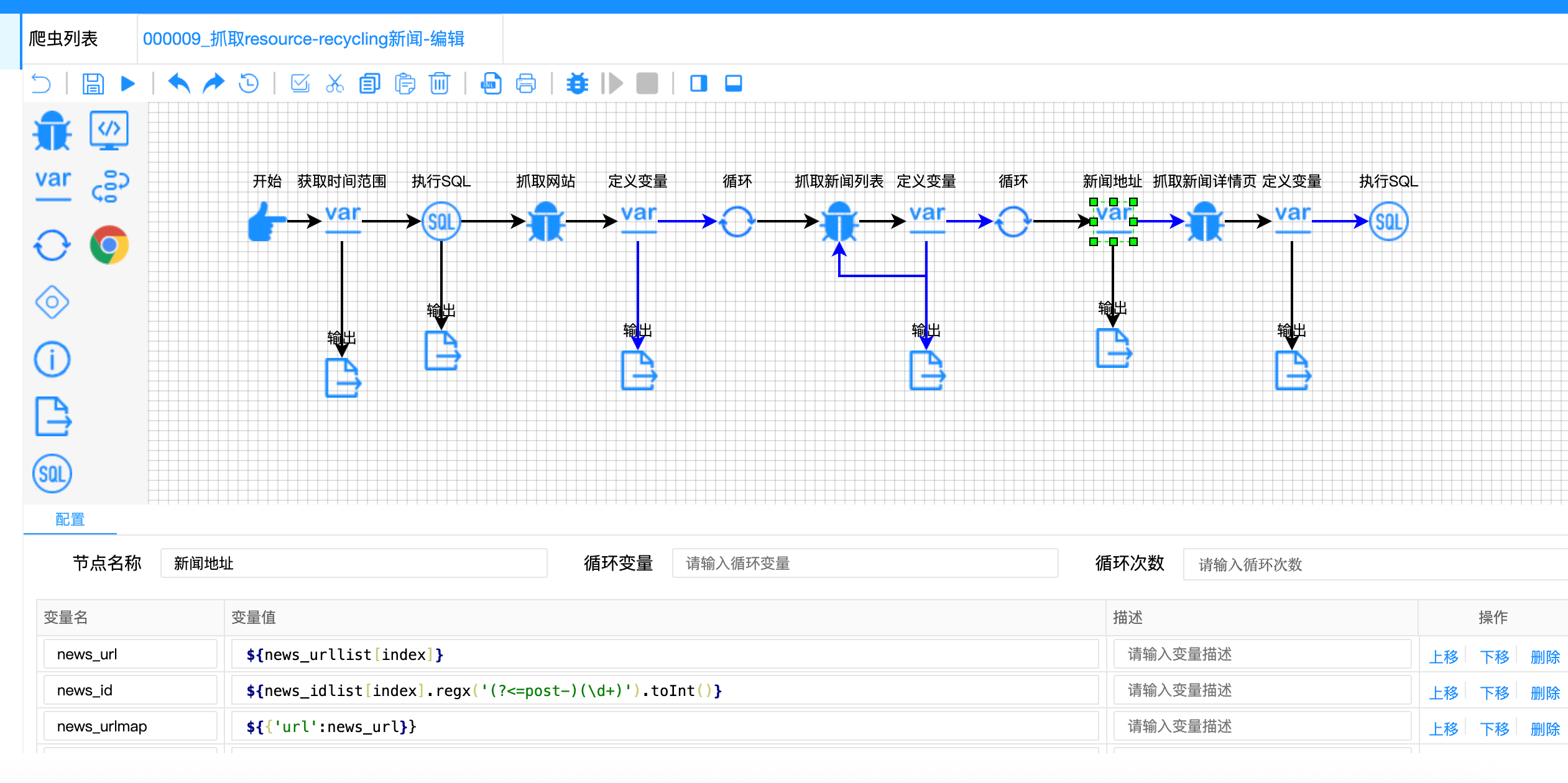
class属性提取原理图:
正则提取
提取class
HTML结构
标题
标题
post-12345 post-news
post-12346 post-news
(?<=post-)(\d+)
12345
12346
正则分解说明:
| 正则部分 | 含义 | 作用 |
|---|---|---|
(?<=post-) |
正向零宽断言 | 匹配位置:前面必须是"post-" |
(\d+) |
捕获组 | 匹配连续数字并捕获 |
难点三:双列表协同提取
问题描述:
需要同时提取URL列表(从h1>a)和ID列表(从article class),两者通过索引关联。
解决方案:
采用双列表并行提取,通过索引关联:
javascript
// 定义变量节点 - 双列表提取
{
"variable-name": ["news_urllist", "page", "news_idlist"],
"variable-value": [
// URL列表
"${page==null?null:extract.selectors(resp.html, '#rwh_content_margin h1>a', 'attr', 'href')}",
// 分页控制
"${page==null?1:page+1}",
// ID列表(从class属性)
"${page==null?null:extract.selectors(resp.html, '#rwh_content_margin>article', 'attr', 'class')}"
]
}
// 新闻地址节点 - 索引关联
{
"variable-name": ["news_url", "news_id", "news_urlmap", "query_result"],
"variable-value": [
"${news_urllist[index]}", // 通过索引获取URL
"${news_idlist[index].regx('(?<=post-)(\\d+)').toInt()}", // 通过索引获取ID
"${{'url': news_url}}",
"${!rs.contains(news_urlmap)}"
]
}难点四:固定导航循环次数
问题描述:
导航分类数量固定为3个(e-scrap、plastics、recycling),可以直接写死循环次数。
解决方案:
固定循环次数为3:
javascript
// 循环节点配置
{
"value": "循环",
"loopVariableName": "i",
"loopCount": "3", // 固定循环3次
"loopStart": "0"
}难点五:7天时间窗口
问题描述:
需要抓取最近7天的新闻,反映该网站更新频率较高。
解决方案:
动态时间范围计算:
javascript
// 获取时间范围节点
{
"variable-name": ["start_date", "end_date"],
"variable-value": [
"${date.format(date.addDays(date.now(),-7),'yyyy-MM-dd')}", // 7天前
"${date.format(date.addDays(date.now(),1),'yyyy-MM-dd')}" // 明天
]
}四、核心代码实现解析
4.1 多级导航循环控制器
javascript
// 伪代码:多级导航循环控制器
class MultiLevelNavigationController {
constructor(navigationUrls, maxPagePerCategory = 1) {
this.navigationUrls = navigationUrls; // 导航链接数组
this.maxPagePerCategory = maxPagePerCategory;
this.currentNavIndex = 0;
this.currentPage = null;
}
async run() {
// 第一层:导航循环
for (let i = 0; i < this.navigationUrls.length; i++) {
const navUrl = this.navigationUrls[i];
// 第二层:分页循环
let page = 1;
while (page <= this.maxPagePerCategory) {
const listUrl = this.buildListUrl(navUrl, page);
await this.processListPage(listUrl);
page++;
}
}
}
buildListUrl(navUrl, page) {
// 从导航URL提取路径
const path = navUrl.replace('https://resource-recycling.com/', '');
return `https://resource-recycling.com/${path}/category/news/page/${page}/`;
}
async processListPage(url) {
// 处理列表页,提取URL和ID
const html = await this.fetch(url);
const urls = this.extractUrls(html);
const ids = this.extractIds(html);
// 第三层:文章循环
for (let j = 0; j < urls.length; j++) {
await this.processArticle(urls[j], ids[j]);
}
}
}4.2 class属性ID提取器
javascript
// 伪代码:class属性ID提取器
class ClassAttributeIdExtractor {
constructor(pattern = /post-(\d+)/) {
this.pattern = pattern;
}
extractIdFromClass(classString) {
const match = classString.match(this.pattern);
return match ? parseInt(match[1]) : null;
}
extractIdsFromClassList(classList) {
return classList.map(cls => this.extractIdFromClass(cls))
.filter(id => id !== null);
}
// 批量处理
process(html) {
// 提取所有article的class
const classes = extract.selectors(html, 'article', 'attr', 'class');
return this.extractIdsFromClassList(classes);
}
}
// 使用示例
const extractor = new ClassAttributeIdExtractor();
const ids = extractor.process(html); // [12345, 12346, 12347]4.3 双列表关联器
javascript
// 伪代码:双列表关联器
class DualListAssociator {
constructor(urlList, idList) {
this.urls = urlList;
this.ids = idList;
this.count = Math.min(urlList.length, idList.length);
}
getAll() {
const results = [];
for (let i = 0; i < this.count; i++) {
results.push({
url: this.urls[i],
id: this.ids[i],
urlMap: { 'url': this.urls[i] }
});
}
return results;
}
getOne(index) {
if (index >= this.count) return null;
return {
url: this.urls[index],
id: this.ids[index],
urlMap: { 'url': this.urls[index] }
};
}
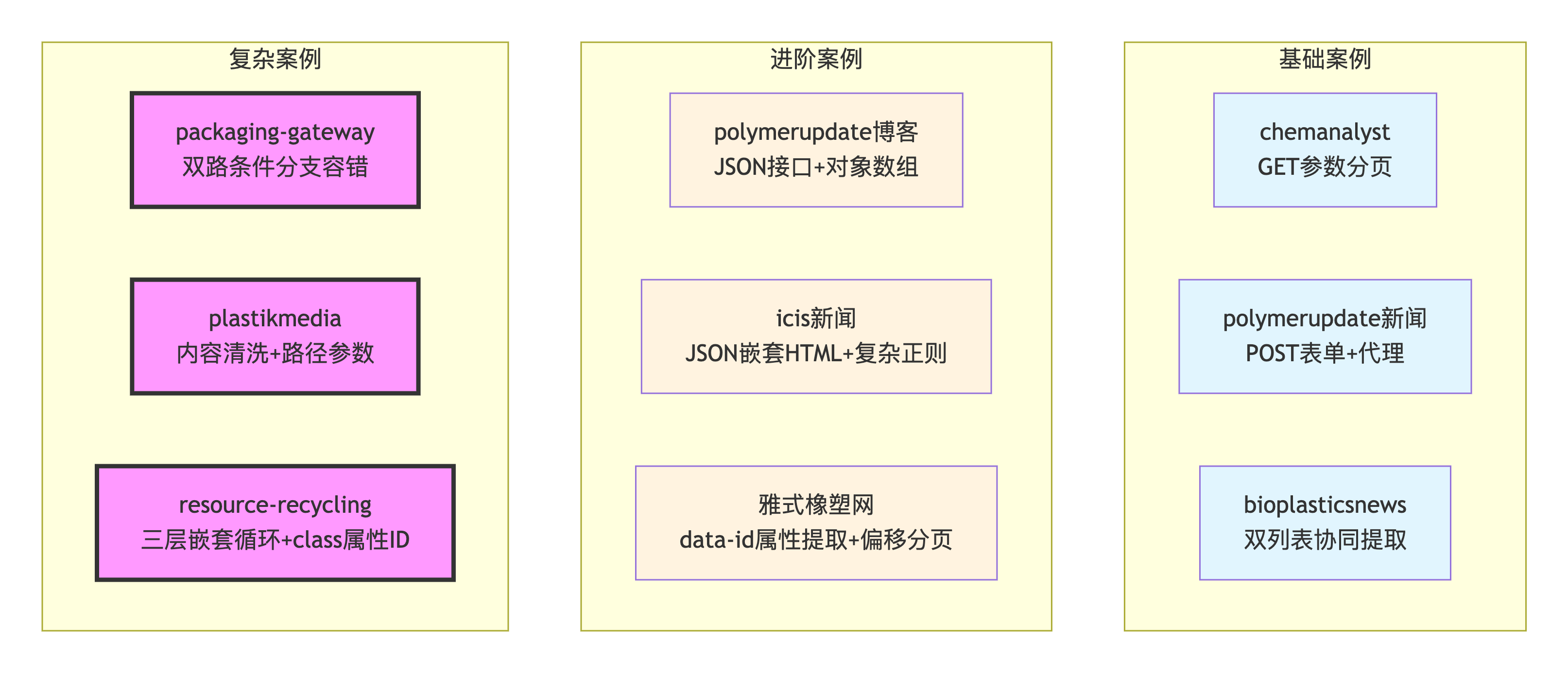
}五、与前八个案例的对比分析
5.1 核心差异点对比
| 维度 | resource-recycling | plastikmedia | packaging-gateway | 雅式橡塑网 | icis新闻 | polymerupdate博客 | bioplasticsnews | polymerupdate新闻 | chemanalyst |
|---|---|---|---|---|---|---|---|---|---|
| 核心架构 | 三层嵌套循环 | 单层循环 | 单层循环+容错 | 单层循环 | 单层循环 | 单层循环 | 单层循环 | 单层循环 | 单层循环 |
| 导航层级 | 首页→导航→分页 | 直接列表页 | 直接列表页 | 直接列表页 | 直接列表页 | 直接列表页 | 直接列表页 | 直接列表页 | 直接列表页 |
| ID存储 | article class | 无 | 无 | data-id | URL中 | 对象属性 | article id | URL中 | URL中 |
| ID格式 | post-12345 | - | - | 纯数字 | URL中数字 | 对象属性 | post-数字 | URL中数字 | URL中数字 |
| 循环嵌套 | 3层 | 2层 | 2层 | 2层 | 2层 | 2层 | 2层 | 2层 | 2层 |
| 导航提取 | ✅ .vc_figure>a | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| 代理策略 | 全流程 | 全流程 | 详情页 | 无 | 无 | 无 | 全流程 | 详情页 | 无 |
5.2 差异化技术难点
5.3 循环架构演进
单层循环
chemanalyst
双层循环
bioplasticsnews
三层嵌套循环
resource-recycling
六、性能优化与最佳实践
6.1 多级循环优化
javascript
// 控制循环深度
const MAX_NAV_ITEMS = 3;
const MAX_PAGES = 1;
for (let navIndex = 0; navIndex < MAX_NAV_ITEMS; navIndex++) {
for (let page = 1; page <= MAX_PAGES; page++) {
// 处理列表页
for (let articleIndex = 0; articleIndex < urls.length; articleIndex++) {
// 处理文章
}
}
}6.2 class属性提取优化
| class格式 | 正则表达式 | 提取结果 |
|---|---|---|
| post-12345 | post-(\d+) |
12345 |
| post-12345 post-news | (?<=post-)(\d+) |
12345 |
| article-12345 | article-(\d+) |
12345 |
6.3 导航提取优化
javascript
// 提取导航路径(而非完整URL)
function extractNavPath(href) {
// href: https://resource-recycling.com/e-scrap/
// 返回: e-scrap
return href.replace('https://resource-recycling.com/', '')
.replace(/\/$/, '');
}七、总结与经验分享
7.1 核心收获
- 多级嵌套循环:处理需要先遍历导航、再遍历分页的复杂场景
- class属性ID提取:从article的class属性中提取数字ID
- 动态URL构建:根据导航路径动态构建分类URL
- 三层循环架构:导航循环 + 分页循环 + 文章循环
7.2 可复用经验
- 分析网站结构:识别是否有多个导航分类需要分别处理
- 多级循环设计:根据实际层级设计相应层数的嵌套循环
- 属性ID提取:注意class属性可能包含多个类名,需要精确定位
- 导航路径提取:从完整URL中提取有用的路径部分
7.3 适用场景
该爬虫设计模式适用于:
- 有多个新闻分类的网站
- ID存储在class属性中的网站
- 需要多层遍历的复杂网站
- 分类+分页组合的网站结构
八、附录:核心配置对照表
| 节点类型 | 核心作用 | 关键技术点 |
|---|---|---|
| 获取时间范围 | 动态计算7天窗口 | date.addDays(now,-7) |
| 执行SQL(查询) | 获取已抓取URL | like '%resource-recycling.com%' |
| 抓取网站 | 获取首页 | 提取导航链接 |
| 定义变量(导航) | 提取导航列表 | .vc_figure>a href |
| 导航循环 | 遍历3个分类 | loopCount=3 |
| 抓取新闻列表 | 获取分类列表页 | / n a v / c a t e g o r y / n e w s / p a g e / {nav}/category/news/page/ nav/category/news/page/{page}/ |
| 定义变量(列表) | 双列表提取 | URL + class属性 |
| 分页循环 | page<=1 | 只抓第一页 |
| 文章循环 | 遍历文章 | list.length(news_urllist) |
| 新闻地址 | 正则提取ID | (?<=post-)(\d+) |
| 抓取新闻详情页 | 获取详情页 | 全流程代理 |
| 定义变量(详情) | 提取字段 | 标题/作者/时间/内容 |
| 执行SQL(插入) | 存储数据 | source='resource-recycling' |
通过以上设计,该爬虫成功应对了多级导航循环和class属性ID提取的双重挑战,实现了对resource-recycling.com新闻网站的高效稳定采集。其中的三层嵌套循环架构、class属性正则提取等思路,对于处理多分类复杂网站的爬虫开发具有很高的参考价值。