ComfyUI图生压缩加密输出节点以及对ai的一些感叹
-
- **注**:拒绝AI拉取数据炼丹白嫖,关联请标注版权。
- 前言
- 标注版权原因
- 使用案例
-
- [① 加密流程](#① 加密流程)
- [② 解密流程](#② 解密流程)
- [③ 批量任务提交](#③ 批量任务提交)
- 源码
-
- [① *SaveFramesAsZIP.py*](#① SaveFramesAsZIP.py)
- [② *LoadFramesFromZIP.py*](#② LoadFramesFromZIP.py)
- [③ *LoadImageWithFilename.py*](#③ LoadImageWithFilename.py)
- [④ *tasks_submit.py*](#④ tasks_submit.py)
- [⑤ **init.py**](#⑤ init.py)
- [⑥ LoadFramesWorkflow.json 仅供参考](#⑥ LoadFramesWorkflow.json 仅供参考)
- [⑦ tasks_submit.py 仅供参考](#⑦ tasks_submit.py 仅供参考)
- 下载链接
- 总结
注:拒绝AI拉取数据炼丹白嫖,关联请标注版权。
前言
这是一套ComfyUI图生视频输出加密方案,你懂得。
标注版权原因
让ai解决 "图生输出的一连串帧直接打包压缩加密",绕来绕去折腾了半天,蠢蛋ai给一堆不能用的方案,甚至还产生了很严重的ai幻觉,把加密工作流节点当成加密输出整理给我,最后我是找到了下面这个仓库,ai理解了代码后,窃取了架构思路生成了基本加密代码,还存在一堆bug,后经过我的指挥调整,生成了真正可用节点。
基本思路框架源自这个仓库
https://github.com/Twist-ttt/comfyui-encrypted-image-node/tree/main
还没被我用的ai模型 skill走,虽然仅仅200来行代码,没有它,ai做这个事就特别蠢,让我吸收生成后,如果我不说,根本没人知道来源。代码能力越强的模型窃取的越厉害,指不定github的私人仓库都拿去训练了。
这涉及AI发展引发的两大问题:
-
版权困境
AI不偷就没法创作,一旦偷了炼丹成功就不说是偷了。原始版权往往被刻意淡化,侵权时刻存在。长期来看,原创动力将受挫,闭源趋势加剧,最终导致技术社区发展停滞。
-
认知偏差
侵权很多人还不知道,古法编程中手动cv是很普遍的事,就算偷了不标注版本,改造也是二创大部分劳动结晶在里面,二次开发者也通常保持对原作者的尊重。但AI时代催生了"数典忘祖"的现象:使用者既不了解内容来源,又贬低原创价值。窃取了别人的东西,吃水要忘挖井人的现象普遍存在。当AI将原创内容"技能化"后,抄袭痕迹被完美掩盖,只剩下若有若无的既视感。
我们必须认识到:应当尊重每一位原创,持续侵权将扼杀创新源头。当原创者集体沉默,技术社区将陷入发展瓶颈,你还指望ai左脚踩右脚上天吗。

使用案例
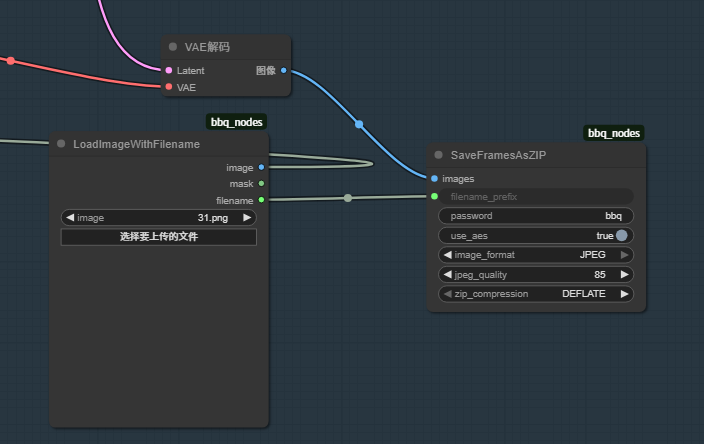
① 加密流程
图生对显卡要求高,在不愿暴露内容场合使用。
VAE解码后,原流程是输出接插帧 或 Video Combine
这里选择直接接入压缩
自定义的LoadImageWithFilename 的 文件名输出给压缩包前缀。
② 解密流程
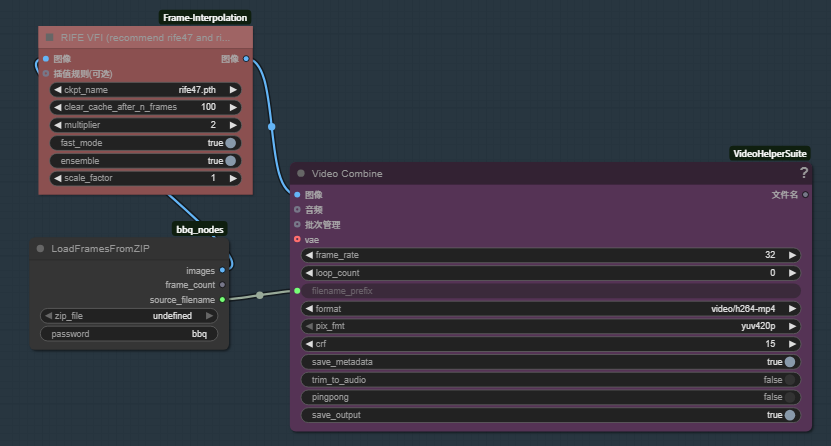
对显卡要求不高,在个人电脑上解密。
目前是简化节点,压缩包扔进input文件夹,配好密码,可输出images给原先的插帧或视频生成节点。
需要定制的小修小改ai干起来还是比较得心应手。
文件名可接给生成视频当前缀。
③ 批量任务提交
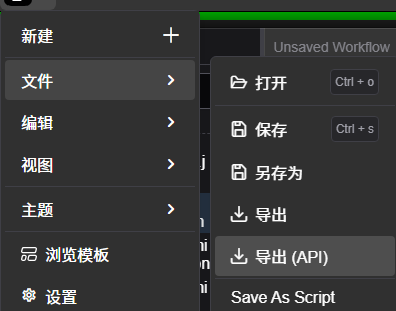
- 做好解密工作流,左上角导出api。
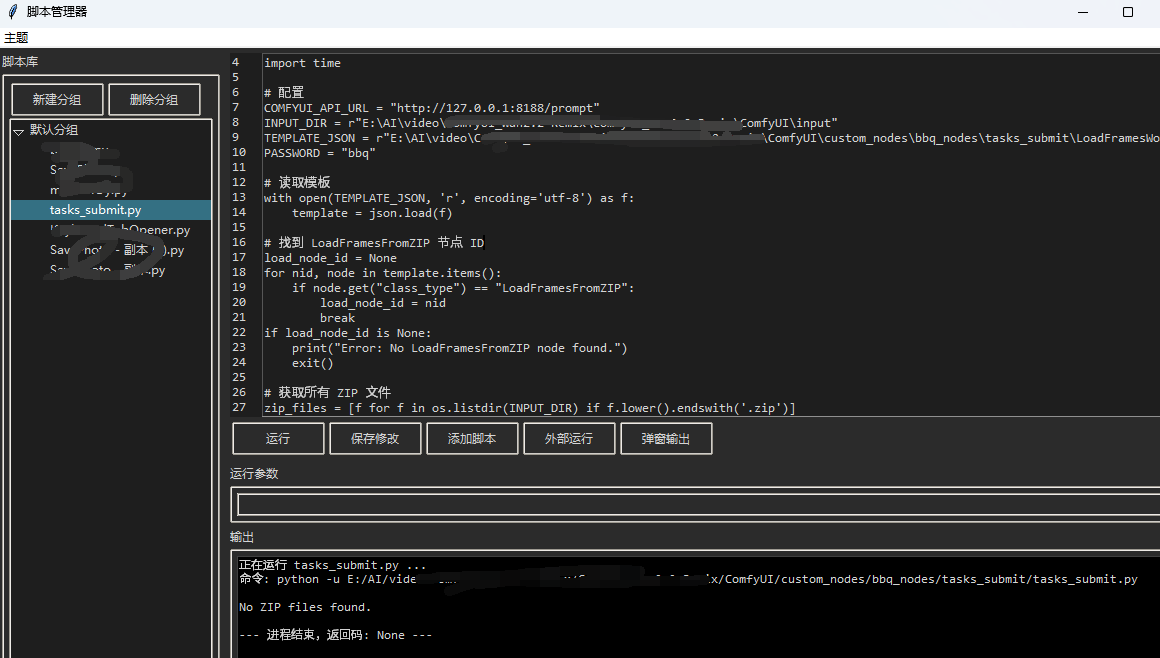
- tasks_submit.py
让ai根据工作流api定制批量执行脚本
然后运行脚本即可
源码
① SaveFramesAsZIP.py
作用:将帧压缩保存为zip的节点,支持无损png和压缩jpg格式。
毕竟保存了每帧,无损生成的压缩包比较大,考虑用jpg压缩,减少压缩包体积,
又或者定制修改节点,压缩生成的mp4文件,可以丢给ai改,问题不大。
python
import os
import torch
import folder_paths
import numpy as np
from PIL import Image
import io
import zipfile
import random
import datetime
import re
try:
import pyzipper
HAS_PYZIPPER = True
except ImportError:
HAS_PYZIPPER = False
class SaveFramesAsZIP:
@classmethod
def INPUT_TYPES(cls):
return {
"required": {
"images": ("IMAGE",),
"filename_prefix": ("STRING", {"default": "frames"}),
"password": ("STRING", {"default": "", "multiline": False}),
"use_aes": ("BOOLEAN", {"default": True}),
"image_format": (["PNG", "JPEG"], {"default": "JPEG"}),
"jpeg_quality": ("INT", {"default": 85, "min": 1, "max": 100}),
"zip_compression": (["DEFLATE", "LZMA"], {"default": "DEFLATE"}),
}
}
RETURN_TYPES = ()
RETURN_NAMES = ()
FUNCTION = "save_as_zip"
CATEGORY = "bbq_nodes"
OUTPUT_NODE = True
@classmethod
def IS_CHANGED(cls, images, filename_prefix, password, use_aes, image_format, jpeg_quality, zip_compression):
return True
def replace_time_placeholders(self, s):
def replacer(match):
fmt = match.group(1)
return datetime.datetime.now().strftime(fmt)
pattern = r"%date:(.*?)%"
return re.sub(pattern, replacer, s)
def save_as_zip(self, images, filename_prefix, password, use_aes, image_format, jpeg_quality, zip_compression):
print(f"=== SaveFramesAsZIP called ===")
print(f" images shape: {images.shape}")
print(f" raw prefix: {filename_prefix}")
print(f" password: {'*' * len(password) if password else 'empty'}")
print(f" use_aes: {use_aes}")
print(f" image_format: {image_format}, jpeg_quality: {jpeg_quality}")
print(f" zip_compression: {zip_compression}")
# 替换时间占位符
processed_prefix = self.replace_time_placeholders(filename_prefix)
print(f" processed prefix: {processed_prefix}")
# 处理子目录
norm_prefix = processed_prefix.replace('\\', '/').rstrip('/')
parts = norm_prefix.split('/')
if len(parts) > 1:
subdir = os.path.join(*parts[:-1])
base_name = parts[-1]
else:
subdir = ""
base_name = norm_prefix
output_dir = folder_paths.get_output_directory()
if subdir:
full_dir = os.path.join(output_dir, subdir)
os.makedirs(full_dir, exist_ok=True)
save_dir = full_dir
else:
save_dir = output_dir
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
if not base_name:
base_name = "frames"
zip_filename = f"{base_name}_{timestamp}.zip"
zip_path = os.path.join(save_dir, zip_filename)
frames = self.tensor_to_pil(images)
# 选择 ZIP 压缩方式
compression = zipfile.ZIP_DEFLATED if zip_compression == "DEFLATE" else zipfile.ZIP_LZMA
# 写入 ZIP
if password and use_aes and HAS_PYZIPPER:
# pyzipper 支持 AES 加密,但压缩方式只能使用 ZIP_DEFLATED
with pyzipper.AESZipFile(zip_path, 'w', compression=pyzipper.ZIP_DEFLATED, encryption=pyzipper.WZ_AES) as zf:
zf.setpassword(password.encode())
for idx, img in enumerate(frames):
img_bytes = io.BytesIO()
if image_format == "PNG":
img.save(img_bytes, format='PNG')
else:
img.save(img_bytes, format='JPEG', quality=jpeg_quality)
img_bytes.seek(0)
ext = "png" if image_format == "PNG" else "jpg"
zf.writestr(f"frame_{idx:04d}.{ext}", img_bytes.getvalue())
else:
# 使用标准 zipfile
with zipfile.ZipFile(zip_path, 'w', compression=compression) as zf:
if password:
zf.setpassword(password.encode())
for idx, img in enumerate(frames):
img_bytes = io.BytesIO()
if image_format == "PNG":
img.save(img_bytes, format='PNG')
else:
img.save(img_bytes, format='JPEG', quality=jpeg_quality)
img_bytes.seek(0)
ext = "png" if image_format == "PNG" else "jpg"
zf.writestr(f"frame_{idx:04d}.{ext}", img_bytes.getvalue())
print(f" ZIP saved to: {zip_path}")
return ()
def tensor_to_pil(self, tensor):
if tensor is None:
return []
if len(tensor.shape) == 3:
tensor = tensor.unsqueeze(0)
frames = []
for i in range(tensor.shape[0]):
img_np = tensor[i].cpu().numpy()
img_np = (img_np * 255).astype(np.uint8)
img_pil = Image.fromarray(img_np, mode='RGB')
frames.append(img_pil)
return frames
NODE_CLASS_MAPPINGS = {
"SaveFramesAsZIP": SaveFramesAsZIP,
}
NODE_DISPLAY_NAME_MAPPINGS = {
"SaveFramesAsZIP": "Save Frames as ZIP",
}依赖
requirements.txt
bash
pyzipper② LoadFramesFromZIP.py
作用:将zip读取解压为帧的节点。
因为我的插帧需求低配电脑和4090耗时表现差不多,所以迁移插帧生成视频在本地解密节点做。
如果修改加密节点直接生成视频的话,可省略这一步。
python
import os
import torch
import numpy as np
import folder_paths
import hashlib
from PIL import Image
import zipfile
import re
# 尝试导入 pyzipper 以支持 AES-256 解密
try:
import pyzipper
HAS_PYZIPPER = True
except ImportError:
HAS_PYZIPPER = False
def natural_sort_key(s):
"""自然排序:将数字部分转为整数,便于排序 frame_0001.png 等"""
return [int(c) if c.isdigit() else c for c in re.split(r'(\d+)', s)]
class LoadFramesFromZIP:
@classmethod
def INPUT_TYPES(cls):
# 列出 input 目录下的 zip 文件
input_dir = folder_paths.get_input_directory()
files = [f for f in os.listdir(input_dir) if f.lower().endswith('.zip')]
return {
"required": {
"zip_file": (sorted(files), {"zip_upload": True}),
"password": ("STRING", {"default": "", "multiline": False}),
}
}
CATEGORY = "bbq_nodes"
RETURN_TYPES = ("IMAGE", "INT", "STRING")
RETURN_NAMES = ("images", "frame_count", "source_filename")
FUNCTION = "load_zip"
def load_zip(self, zip_file, password):
zip_path = folder_paths.get_annotated_filepath(zip_file)
print(f"Loading ZIP: {zip_path}")
print(f"Password: {'*' * len(password) if password else 'empty'}")
# 根据加密方式选择打开 ZIP 的方法
if password and HAS_PYZIPPER:
# 使用 pyzipper 支持 AES-256
try:
zf = pyzipper.AESZipFile(zip_path, 'r')
zf.setpassword(password.encode())
except Exception as e:
raise ValueError(f"Failed to open encrypted ZIP with pyzipper: {e}")
else:
# 使用标准 zipfile(传统加密或无密码)
try:
zf = zipfile.ZipFile(zip_path, 'r')
if password:
zf.setpassword(password.encode())
except Exception as e:
raise ValueError(f"Failed to open ZIP: {e}")
# 获取所有 PNG 文件并排序(自然排序)
png_files = [f for f in zf.namelist() if f.lower().endswith(('.png', '.jpg', '.jpeg'))]
if not png_files:
raise ValueError("No PNG files found in ZIP archive.")
png_files.sort(key=natural_sort_key)
print(f"Found {len(png_files)} frames: {png_files[0]} ... {png_files[-1]}")
frames = []
for fname in png_files:
with zf.open(fname) as img_file:
img = Image.open(img_file)
# 转换为 RGB(如果是 RGBA 或其他模式)
img = img.convert('RGB')
img_np = np.array(img).astype(np.float32) / 255.0
frames.append(torch.from_numpy(img_np))
zf.close()
if not frames:
raise ValueError("No frames could be loaded.")
# 堆叠为 [N, H, W, C] 张量
images = torch.stack(frames, dim=0)
frame_count = images.shape[0]
# 提取源文件名(不含扩展名)作为辅助信息
source_filename = os.path.splitext(os.path.basename(zip_path))[0]
print(f"Loaded {frame_count} frames, shape: {images.shape}")
print(torch.cuda.is_available())
return (images, frame_count, source_filename)
@classmethod
def IS_CHANGED(cls, zip_file, password):
# 文件内容变化时重新加载
zip_path = folder_paths.get_annotated_filepath(zip_file)
m = hashlib.sha256()
with open(zip_path, 'rb') as f:
m.update(f.read())
return m.digest().hex()
NODE_CLASS_MAPPINGS = {
"LoadFramesFromZIP": LoadFramesFromZIP,
}
NODE_DISPLAY_NAME_MAPPINGS = {
"LoadFramesFromZIP": "Load Frames from ZIP",
}③ LoadImageWithFilename.py
作用:定制的加载图片节点,支持文件名输出连接给压缩包名称前缀
python
import os
import torch
import numpy as np
import folder_paths
from PIL import Image, ImageOps, ImageSequence
import node_helpers
import hashlib
class LoadImageWithFilename:
@classmethod
def INPUT_TYPES(cls):
input_dir = folder_paths.get_input_directory()
files = [f for f in os.listdir(input_dir) if os.path.isfile(os.path.join(input_dir, f))]
return {
"required": {
"image": (sorted(files), {"image_upload": True}),
}
}
CATEGORY = "bbq_nodes"
RETURN_TYPES = ("IMAGE", "MASK", "STRING")
RETURN_NAMES = ("image", "mask", "filename")
FUNCTION = "load_image"
def load_image(self, image):
# 完全复制原生 LoadImage 的加载逻辑
image_path = folder_paths.get_annotated_filepath(image)
img = node_helpers.pillow(Image.open, image_path)
output_images = []
output_masks = []
w, h = None, None
for i in ImageSequence.Iterator(img):
i = node_helpers.pillow(ImageOps.exif_transpose, i)
if i.mode == 'I':
i = i.point(lambda i: i * (1 / 255))
image = i.convert("RGB")
if len(output_images) == 0:
w = image.size[0]
h = image.size[1]
if image.size[0] != w or image.size[1] != h:
continue
image = np.array(image).astype(np.float32) / 255.0
image = torch.from_numpy(image)[None,]
if 'A' in i.getbands():
mask = np.array(i.getchannel('A')).astype(np.float32) / 255.0
mask = 1. - torch.from_numpy(mask)
else:
mask = torch.zeros((64, 64), dtype=torch.float32, device="cpu")
output_images.append(image)
output_masks.append(mask)
if len(output_images) == 1:
output_images = output_images[0]
output_masks = output_masks[0]
elif len(output_images) > 1:
output_images = torch.cat(output_images, dim=0)
output_masks = torch.cat(output_masks, dim=0)
# 提取文件名(不含扩展名)作为输出
base_name = os.path.splitext(os.path.basename(image_path))[0]
return (output_images, output_masks, base_name)
@classmethod
def IS_CHANGED(cls, image):
# 与原生 LoadImage 保持一致:基于文件修改时间和大小计算哈希
image_path = folder_paths.get_annotated_filepath(image)
try:
stat = os.stat(image_path)
# 组合修改时间和大小,确保文件变化时节点重新执行
return (stat.st_mtime, stat.st_size)
except OSError:
return None
NODE_CLASS_MAPPINGS = {
"LoadImageWithFilename": LoadImageWithFilename,
}
NODE_DISPLAY_NAME_MAPPINGS = {
"LoadImageWithFilename": "Load Image (with filename)",
}④ tasks_submit.py
让ai根据 api.json 生成批量提交脚本。
python
import os
import json
import requests
import time
# 配置
COMFYUI_API_URL = "http://127.0.0.1:8188/prompt"
INPUT_DIR = r"E:\AI\。。。\ComfyUI\input"
TEMPLATE_JSON = r"E:\AI\。。。\ComfyUI\custom_nodes\bbq_nodes\tasks_submit\LoadFramesWorkflow.json" # 保存您的 API 格式 JSON 文件路径
PASSWORD = "bbq"
# 读取模板
with open(TEMPLATE_JSON, 'r', encoding='utf-8') as f:
template = json.load(f)
# 找到 LoadFramesFromZIP 节点 ID
load_node_id = None
for nid, node in template.items():
if node.get("class_type") == "LoadFramesFromZIP":
load_node_id = nid
break
if load_node_id is None:
print("Error: No LoadFramesFromZIP node found.")
exit()
# 获取所有 ZIP 文件
zip_files = [f for f in os.listdir(INPUT_DIR) if f.lower().endswith('.zip')]
if not zip_files:
print("No ZIP files found.")
exit()
# 批量提交
for zip_file in zip_files:
prompt = json.loads(json.dumps(template)) # 深拷贝
prompt[load_node_id]["inputs"]["zip_file"] = zip_file
prompt[load_node_id]["inputs"]["password"] = PASSWORD
response = requests.post(COMFYUI_API_URL, json={"prompt": prompt})
if response.status_code == 200:
print(f"Submitted: {zip_file} -> {response.json()}")
else:
print(f"Failed: {zip_file} - {response.text}")
time.sleep(0.5)
print("All tasks submitted.")⑤ init.py
作用:包整理,映射3节点的文件夹位置
python
from .LoadFramesFromZIP import NODE_CLASS_MAPPINGS as load_mappings
from .SaveFramesAsZIP import NODE_CLASS_MAPPINGS as save_mappings
from .LoadImageWithFilename import NODE_CLASS_MAPPINGS as loadimg_mappings
NODE_CLASS_MAPPINGS = {}
NODE_CLASS_MAPPINGS.update(load_mappings)
NODE_CLASS_MAPPINGS.update(save_mappings)
NODE_CLASS_MAPPINGS.update(loadimg_mappings)
NODE_DISPLAY_NAME_MAPPINGS = {
# 如果每个文件都有各自的显示映射,可以合并;也可以留空使用默认
}⑥ LoadFramesWorkflow.json 仅供参考
案例工作流:使用加载压缩包输出帧节点,生成视频的案例,仅供参考,得定制
python
{
"1": {
"inputs": {
"ckpt_name": "rife47.pth",
"clear_cache_after_n_frames": 100,
"multiplier": 2,
"fast_mode": true,
"ensemble": true,
"scale_factor": 1,
"frames": [
"3",
0
]
},
"class_type": "RIFE VFI",
"_meta": {
"title": "RIFE VFI (recommend rife47 and rife49)"
}
},
"2": {
"inputs": {
"frame_rate": 32,
"loop_count": 0,
"filename_prefix": [
"3",
2
],
"format": "video/h264-mp4",
"pix_fmt": "yuv420p",
"crf": 15,
"save_metadata": true,
"trim_to_audio": false,
"pingpong": false,
"save_output": true,
"images": [
"1",
0
]
},
"class_type": "VHS_VideoCombine",
"_meta": {
"title": "Video Combine"
}
},
"3": {
"inputs": {
"zip_file": "56.zip",
"password": "bbq"
},
"class_type": "LoadFramesFromZIP",
"_meta": {
"title": "Load Frames from ZIP"
}
}
}⑦ tasks_submit.py 仅供参考
案例批量提交任务脚本:针对工作流进行批量提交,仅供参考,得定制。
javascript
import os
import json
import requests
import time
# 配置
COMFYUI_API_URL = "http://127.0.0.1:8188/prompt"
INPUT_DIR = r"E:\AI\。。。\ComfyUI\input"
TEMPLATE_JSON = r"E:\AI\。。。\ComfyUI\custom_nodes\bbq_nodes\tasks_submit\LoadFramesWorkflow.json" # 保存您的 API 格式 JSON 文件路径
PASSWORD = "bbq"
# 读取模板
with open(TEMPLATE_JSON, 'r', encoding='utf-8') as f:
template = json.load(f)
# 找到 LoadFramesFromZIP 节点 ID
load_node_id = None
for nid, node in template.items():
if node.get("class_type") == "LoadFramesFromZIP":
load_node_id = nid
break
if load_node_id is None:
print("Error: No LoadFramesFromZIP node found.")
exit()
# 获取所有 ZIP 文件
zip_files = [f for f in os.listdir(INPUT_DIR) if f.lower().endswith('.zip')]
if not zip_files:
print("No ZIP files found.")
exit()
# 批量提交
for zip_file in zip_files:
prompt = json.loads(json.dumps(template)) # 深拷贝
prompt[load_node_id]["inputs"]["zip_file"] = zip_file
prompt[load_node_id]["inputs"]["password"] = PASSWORD
response = requests.post(COMFYUI_API_URL, json={"prompt": prompt})
if response.status_code == 200:
print(f"Submitted: {zip_file} -> {response.json()}")
else:
print(f"Failed: {zip_file} - {response.text}")
time.sleep(0.5)
print("All tasks submitted.")下载链接
https://pan.baidu.com/s/1KohS3ZotX_GDnNIVtfY9uA?pwd=km4u
总结
这样就形成了一套加密输出工作流,代码不多,比较简单,但非专职py开发者在ai的辅助下也还是挺麻烦的。