仓库地址:https://github.com/ultralytics/yolov3
注意:官方维护版的requirements.txt文件里说明了它依赖的库及其最低版本,可以看到它是也依赖Ultralytics的,git clone的是yolov3网络结构,而所用的一些基础模块有些是Ultralytics库的。也要安装Ultralytics库。
学习目标 :
主干网络怎么实现?代码怎么对应上图的?
Neck网络如何实现?怎么对应上图的?
检测头怎么实现?怎么对应上图的?
后处理怎么实现的?
叠框怎么实现?
1 基础模块封装
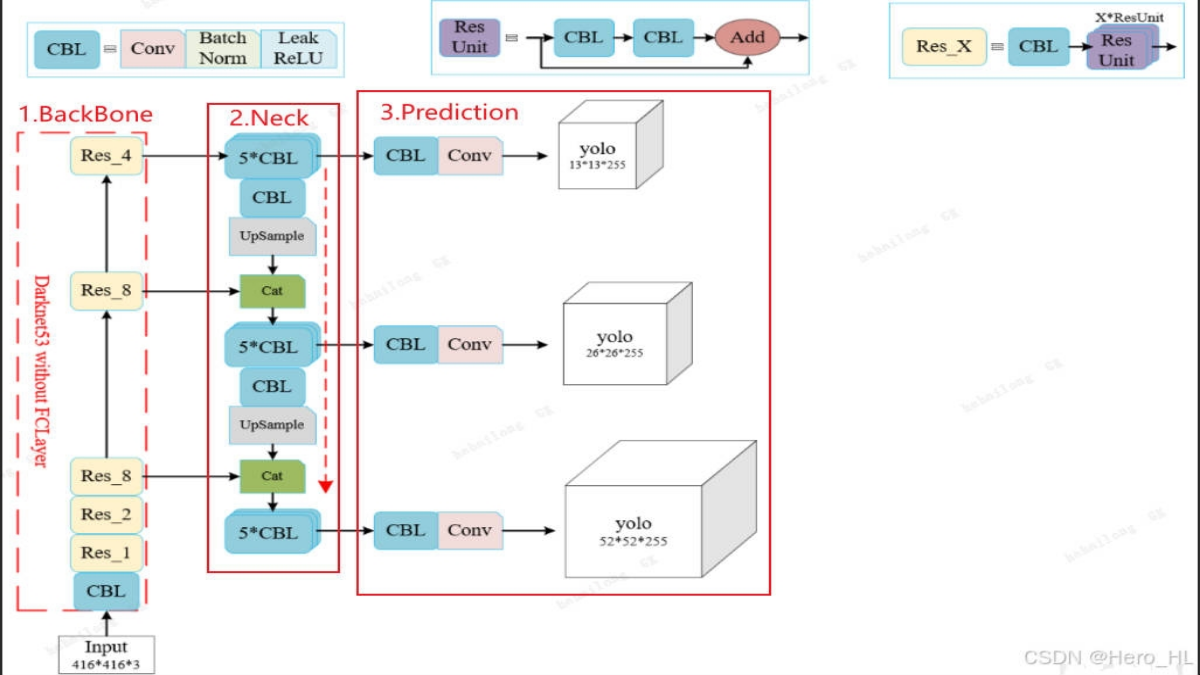
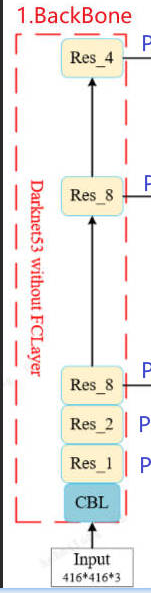
分析上图,yolov3的网络结构中CBL是最基础最基础的模块,所以可以搞个类把CBL实现。还有Res Unit残差块也是大的基础模块------构建主干网络,所以也可以用个类来实现它。剩下的能封装成类的就是检测头了就是prediction部分。
于是,yolov3官方源码把图中的CBL抽象出了Conv类、Res Unit抽象出了Bottleneck类、prediction部分抽象出了Detect类。
neck部分是没有封装的。
本节一一探索。
1.1 CBL (Conv + BN + LeakyReLU)

CBL 是什么:它是 YOLOv3 网络中最基础的构建块(Building Block),相当于神经网络中的"砖块"。
作用:负责特征提取和变换。通过组合不同的 k和 s,构成了 Darknet-53 的主干网络和特征金字塔。
关键特性:使用 BatchNorm且 bias=False,以及自动填充机制,保证了网络的稳定性和性能。
探索下yolov3官方维护代码如何实现的:
c
# models/common.py - Conv 类
class Conv(nn.Module):
# 标准卷积,包含 args(输入通道, 输出通道, 核大小, 步长, 填充, 组数, 激活)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
# 1. 卷积层 (Conv2d)
# 使用 autopad 函数自动计算 padding 以保持特征图尺寸
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
# 2. 批归一化层 (BatchNorm2d)
self.bn = nn.BatchNorm2d(c2)
# 3. 激活函数 (Activation)
# 判断逻辑:如果 act=True 则使用默认激活;如果是 nn.Module 则直接使用;否则使用恒等映射
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
# 前向传播顺序:Conv -> BN -> Act
return self.act(self.bn(self.conv(x)))Conv类实现了CBL 。
a) 参数定义逻辑
c1(输入通道) & c2(输出通道):定义卷积层的输入输出维度。
k(核大小):默认为 1,即 1x1 卷积。在 Darknet-53 中,通常用于改变通道数或残差连接。
s(步长):默认为 1。当 s=2时,该模块用于下采样(Downsample)。
p(填充):通常设置为 None,由 autopad函数自动计算。关键逻辑:autopad函数会根据卷积核大小 k自动计算 padding,使得当 stride=1时,输入输出特征图尺寸保持不变(Same Convolution)。
act(激活):默认使用 SiLU(Sigmoid Linear Unit,即 Swish 激活)。在早期的 YOLOv3 实现中,这里通常是 nn.LeakyReLU(0.1)。
可以看到源码实现不再是LeakyReLU了优化成了SiLU。
b) 结构顺序
在 forward函数中,执行顺序非常严格:
Conv2d:进行卷积运算。
BatchNorm2d:进行批归一化,加速收敛并防止梯度消失。
Activation:应用非线性激活函数。
核心辅助函数:autopad
autopad函数的主要功能是自动计算卷积层的填充值,确保在卷积操作后特征图尺寸保持不变(当 stride=1时)。特别地,它还考虑了膨胀卷积的情况。
python
# 步骤分解
def autopad(k, p=None, d=1):
# 1. 处理膨胀卷积 如果 d > 1,首先更新 k
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
# 2. 然后计算 p
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return pautopad函数流程:
开始
↓
输入参数: k, p, d
↓
if d > 1: 处理膨胀卷积
↓
├─ 如果 k 是整数: 计算有效核大小 = d × (k - 1) + 1
└─ 如果 k 是列表: 对每个元素计算有效核大小
↓
if p is None: 自动计算填充
↓
├─ 如果 k 是整数: 计算填充 = k // 2
└─ 如果 k 是列表: 对每个元素计算填充
↓
返回 p
↓
结束
核心算法:填充 = 核大小 // 2
为啥是它?因为它是默认stride为1保证特征尺寸不变,这样计算公式就蜕变为:
特征尺寸=输入特征尺寸-k +2p+1
也就是说这就要求k=2p+1
于是p=(k-1)/2
那上述代码怎么是p=k/2呢?
因为k一般为1/3/5等奇数,所以减不减1都一样!
对于膨胀卷积,需要计算下有效卷积核大小,然后根据有效卷积核大小计算填充。公式如下:
膨胀卷积有效核大小 = 膨胀率 × (原始核大小 - 1) + 1
膨胀卷积也叫空洞卷积,那个d就是dilation的首字母,叫膨胀率或者空洞率,具体概念和公式参考我的博客CNN基础学习
https://blog.csdn.net/yhb1206/article/details/156827841
autopad支持整数和列表形式的核大小。
关键一点,autopad只是保证stride为1时特征图尺寸不变,但是如果stride设为2那就是下采样了,注意这个特性啊!
因此,Conv类就有如此用法:
python
# 标准 3×3 卷积
conv1 = Conv(64, 128, k=3, s=1) # padding=1
# 膨胀卷积
conv2 = Conv(64, 128, k=3, s=1, d=2) # padding=2, dilation=2
# 1×1 卷积
conv3 = Conv(64, 128, k=1, s=1) # padding=0
# 下采样卷积
conv4 = Conv(64, 128, k=3, s=2) # padding=1, stride=2其应用可以在后续的构建主干网络、Res Uint等里可以看到它的身影,它就是"砖块"、"最基础的组件"。
1.2 Res Unit (残差块)
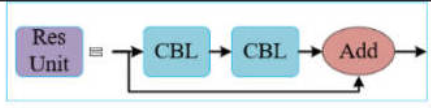
这个就是大的组件了,主干网络的核心组件。
借鉴 ResNet 的思想,防止深层网络梯度消失。
探索下yolov3官方维护代码如何实现的:
c
# models/common.py - Bottleneck 类
class Bottleneck(nn.Module):
# 标准瓶颈结构
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # 输入通道, 输出通道, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # 隐藏通道数
self.cv1 = Conv(c1, c_, 1, 1) # 1x1卷积压缩通道
self.cv2 = Conv(c_, c2, 3, 1, g=g) # 3x3卷积处理
self.add = shortcut and c1 == c2 # 判断是否需要残差连接
def forward(self, x):
# 前向传播:如果启用shortcut且输入输出通道相同,则进行残差连接,否则就是普通的前馈网络
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))Bottleneck实现了该Res Unit残差块。可以看到前面的Conv类(CBL)的身影了,不愧为基础"砖块"。
Bottleneck 结构采用"压缩-处理-扩展"的设计:
输入 (c1通道)
↓
1x1卷积: c1 → c_ (压缩)
↓
3x3卷积: c_ → c2 (处理)
↓
残差连接 (可选)
可以看到残差链接是可选的,为啥可选?这个是个伏笔,yolov3源码实现没有抽象出neck的类,neck的处理呢其中是5*CBL,这个就为了它准备的。
在 YOLOv3 的 Darknet53 骨干网络中,Bottleneck、Conv类是构建主干的核心,如下:
python
# yolov3.yaml 中的配置示例
# darknet53 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Bottleneck, [64]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 2, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 5-P3/8
[-1, 8, Bottleneck, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 8, Bottleneck, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
[-1, 4, Bottleneck, [1024]], # 10
]1.3 检测头
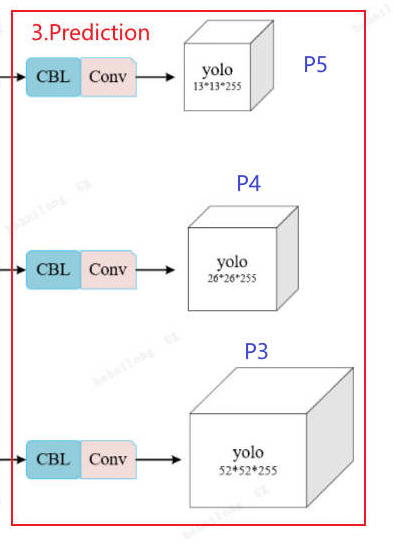
Prediction(预测头),它由 Detect 类实现:
python
# models/yolo.py - Detect类
class Detect(nn.Module):
"""YOLOv3 Detect head for processing detection model outputs, including grid and anchor grid generation."""
stride = None # strides computed during build
dynamic = False # force grid reconstruction
export = False # export mode
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
"""Initializes YOLOv3 detection layer with class count, anchors, channels, and operation modes."""
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.empty(0) for _ in range(self.nl)] # init grid
self.anchor_grid = [torch.empty(0) for _ in range(self.nl)] # init anchor grid
self.register_buffer("anchors", torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use inplace ops (e.g. slice assignment)
def forward(self, x):
"""Processes input through convolutional layers, reshaping output for detection.
Expects x as list of tensors with shape(bs, C, H, W).
"""
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
if isinstance(self, Segment): # (boxes + masks)
xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf.sigmoid(), mask), 4)
else: # Detect (boxes only)
xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, self.na * nx * ny, self.no))
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, "1.10.0")):
"""Generates a grid and corresponding anchor grid with shape `(1, num_anchors, ny, nx, 2)` for indexing anchors.
"""
d = self.anchors[i].device
t = self.anchors[i].dtype
shape = 1, self.na, ny, nx, 2 # grid shape
y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
yv, xv = torch.meshgrid(y, x, indexing="ij") if torch_1_10 else torch.meshgrid(y, x) # torch>=0.7 compatibility
grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
return grid, anchor_gridDetect 类 = YOLOv3 的"最终输出层",负责将 Neck 输出的多尺度特征图(P3/P4/P5)转换为最终的边界框、类别、置信度。
对每个特征图(P3/P4/P5)进行 卷积预测(输出通道数 = 3×(5+类别数))。
生成 网格(grid) 和 锚框(anchor_grid) 用于解码预测值。
支持 动态网格重建(训练/推理时自动调整)。
支持 导出模式(export)(用于 ONNX/TensorRT 等部署)。
但是呢,代码的实现和图上并不严格对应,因为源码没有CBL,只有单纯的卷积操作------因为CBL是在neck部分做的。而源码并没有单独的neck类,整个网络的创建是parse_model函数实现的,在neck部分实现时已经做完所有CBL,所以Detect类里就没有CBL了,只需要基本的conv2d操作了。

parse_model会调用 Detect类,将其加入 self.model(整个网络)。后续可以查看其实现。
2 动态创建整个网络
经探索发现整个网络都是通过yaml配置文件动态创建整个网络的。
灵活性很大------不仅能创建yolov3、还有yolov3_tiny/yolov3_spp/yolov5等等。
其动态创建实现是通过函数parse_model实现的:
c
# models/yolo.py - parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)
"""Parses a YOLOv3 model configuration from a dictionary and constructs the model."""
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw, act = d["anchors"], d["nc"], d["depth_multiple"], d["width_multiple"], d.get("activation")
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
with contextlib.suppress(NameError):
args[j] = eval(a) if isinstance(a, str) else a # eval strings
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
MixConv2d,
Focus,
CrossConv,
BottleneckCSP,
C3,
C3TR,
C3SPP,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace("__main__.", "") # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f"{i:>3}{f!s:>18}{n_:>3}{np:10.0f} {t:<40}{args!s:<30}") # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)可以看到,整个网络都在这里动态创建(通过yaml配置文件)。
虽然概念上分为三部分(Backbone、Neck 和 Head),但代码实现上是一个完整的、连续的网络。
2.1 parse_model解析yaml机制
在 YAML 配置中,每行的格式是:
from, number, module, args
from:输入来源索引
number:重复次数
module:模块类型
args:模块参数
无论哪种模块,parse_model都遵循相同的基本流程:
python
for i, (f, n, m, args) in enumerate(config):
# 1. 转换模块类型
m = eval(m) if isinstance(m, str) else m
# 2. 处理参数
# 不同类型有特殊处理
if m in {Conv, Bottleneck, ...}:
# 处理 Conv/Bottleneck
elif m is Concat:
# 处理 Concat
elif m in {Detect, Segment}:
# 处理 Detect/Segment
else:
# 其他模块
# 3. 创建模块
module = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args)
# 4. 添加到网络
layers.append(module)
ch.append(c2)Conv、Bottleneck、Upsample、 Concat、Detect各举一例来看其如何解析。
Conv 模块示例
python
# yolov3.yaml 行0
[-1, 1, Conv, [32, 3, 1]], # 0parse_model 处理流程:
python
# 在 parse_model 函数中处理
i = 0 # 第0行
f = -1 # 输入来源:上一层
n = 1 # 重复次数:1
m = "Conv" # 模块类型
args = [32, 3, 1] # 参数:输出通道32,核大小3,步长1
# 步骤1:转换模块类型
m = eval("Conv") # 转换为 Conv 类
# 步骤2:获取输入输出通道
c1 = ch[-1] # ch[-1] = 3(初始输入通道)
c2 = args[0] # 32
c2 = make_divisible(c2 * gw, 8) # 应用宽度倍数
# 步骤3:构建参数
args = [c1, c2] + args[1:] # args = [3, 32, 3, 1]
# 步骤4:创建模块
# 因为 n=1,直接创建
module = Conv(3, 32, 3, 1) # Conv(c1, c2, k, s)
# 步骤5:添加到网络
layers.append(module)
ch.append(c2) # ch 从 [3] 变为 [],然后添加 32Bottleneck 模块示例
python
# yolov3.yaml 行4
[-1, 2, Bottleneck, [128]],
python
# 在 parse_model 函数中处理
i = 4 # 第4行
f = -1 # 输入来源:上一层
n = 2 # 重复次数:2
m = "Bottleneck" # 模块类型
args = [128] # 参数:输出通道128
# 步骤1:转换模块类型
m = eval("Bottleneck") # 转换为 Bottleneck 类
# 步骤2:获取输入输出通道
c1 = ch[-1] # 假设 ch[-1] = 128(来自上一层)
c2 = args[0] # 128
c2 = make_divisible(c2 * gw, 8) # 应用宽度倍数
# 步骤3:构建参数
args = [c1, c2] + args[1:] # args = [128, 128]
# 步骤4:创建模块
# 因为 n=2 > 1,创建 Sequential
bottleneck_list = []
for _ in range(2):
# Bottleneck 默认参数:shortcut=True, g=1, e=0.5
bottleneck = Bottleneck(128, 128, shortcut=True, g=1, e=0.5)
bottleneck_list.append(bottleneck)
module = nn.Sequential(*bottleneck_list) # 包含2个 Bottleneck 的 Sequential
# 步骤5:添加到网络
layers.append(module)
ch.append(c2) # 添加 128Upsample 模块示例
python
# yolov3.yaml 行17
[-1, 1, nn.Upsample, [None, 2, "nearest"]],parse_model 处理流程:
python
# 在 parse_model 函数中处理
i = 17 # 第17行
f = -1 # 输入来源:上一层
n = 1 # 重复次数:1
m = "nn.Upsample" # 模块类型
args = [None, 2, "nearest"] # 参数
# 步骤1:转换模块类型
m = eval("nn.Upsample") # 转换为 torch.nn.Upsample 类
# 步骤2:参数处理
# 对 Upsample 的特殊处理
# scale_factor=2, mode="nearest"
args = [2] # 只保留 scale_factor
# 在 yolo.py 的实际代码中,可能会对参数进行进一步处理
# 步骤3:创建模块
module = nn.Upsample(scale_factor=2, mode="nearest")
# 步骤4:添加到网络
layers.append(module)
# Upsample 不改变通道数,c2 = ch[-1]
ch.append(ch[-1]) # 保持相同通道数Concat 模块示例
python
# yolov3.yaml 行18
[[-1, 8], 1, Concat, [1]], # cat backbone P4parse_model 处理流程:
python
# 在 parse_model 函数中处理
i = 18 # 第18行
f = [-1, 8] # 输入来源:上一层和索引8
n = 1 # 重复次数:1
m = "Concat" # 模块类型
args = [1] # 参数:维度1(通道维度)
# 步骤1:转换模块类型
m = eval("Concat") # 转换为 Concat 操作
# 步骤2:计算输出通道数
# Concat 的特殊处理
c2 = sum(ch[x] for x in f) # 计算拼接后的总通道数
# ch[-1] = 上一层的输出通道
# ch[8] = 索引8的输出通道
# 假设 ch[-1] = 256, ch[8] = 512
# 则 c2 = 256 + 512 = 768
# 步骤3:创建模块
# Concat 可能是自定义的拼接操作
# 在某些实现中,可能是 torch.cat 的包装
module = Concat(dim=1) # 在通道维度拼接
# 步骤4:添加到网络
layers.append(module)
ch.append(c2) # 添加拼接后的通道数 768Detect 模块示例
python
# yolov3.yaml 行28
[[27, 22, 15], 1, Detect, [nc, anchors]],parse_model 处理流程:
python
# 在 parse_model 函数中处理
i = 28 # 第28行
f = [27, 22, 15] # 输入来源:三个特征图
n = 1 # 重复次数:1
m = "Detect" # 模块类型
args = [nc, anchors] # 参数:类别数和锚框
# 步骤1:转换模块类型
m = eval("Detect") # 转换为 Detect 类
# 步骤2:特殊处理 Detect
# 添加输入通道列表
args.append([ch[x] for x in f]) # 获取每个输入特征图的通道数
# 假设 ch[27]=256, ch[22]=512, ch[15]=1024
# args 变为 [nc, anchors, [256, 512, 1024]]
# 步骤3:处理锚框
if isinstance(args[1], int): # 如果 anchors 是整数
args[1] = [list(range(args[1] * 2))] * len(f)
# 步骤4:创建模块
# Detect 参数:nc, anchors, ch, inplace=True
nc = args[0] # 类别数,假设 80
anchors = args[1] # 锚框
ch_list = args[2] # 输入通道列表 [256, 512, 1024]
module = Detect(nc=nc, anchors=anchors, ch=ch_list, inplace=True)
# 步骤5:添加到网络
layers.append(module)
# Detect 的输出通道数不是固定的
# 通常设置为 None 或特殊值
c2 = c2 # 保持原值或特殊处理
ch.append(c2)
2.2 parse_model返回值
python
return nn.Sequential(*layers), sorted(save)返回值是一个元组,包含两个元素:
nn.Sequential(*layers):构建的神经网络模型
sorted(save):排序后的保存索引列表
nn.Sequential(*layers)总layers说明
python
# 假设构建的 layers 列表包含
layers = [
Conv(3, 32, 3, 1), # 索引0: 行0
Conv(32, 64, 3, 2), # 索引1: 行1
Bottleneck(64, 64), # 索引2: 行2
Conv(64, 128, 3, 2), # 索引3: 行3
nn.Sequential( # 索引4: 行4
Bottleneck(128, 128),
Bottleneck(128, 128)
),
# ... 更多层
Detect(nc, anchors, ch_list) # 最后一层: 检测头
]
# 返回的 nn.Sequential 会将这些层按顺序组合sorted(save)保存啥,用来干啥?
python
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1)规则:
收集所有非 -1 的输入来源索引
对索引取模 i(当前行索引)
去重后排序
python
# yolov3.yaml 中的配置
backbone: [
[-1, 1, Conv, [32, 3, 1]], # 行0
[-1, 1, Conv, [64, 3, 2]], # 行1
# ...
]
head: [
# ... 中间层
[[-1, 8], 1, Concat, [1]], # 行18: 引用了索引8
[[-1, 6], 1, Concat, [1]], # 行25: 引用了索引6
[[27, 22, 15], 1, Detect, [nc, anchors]], # 行28: 引用了27,22,15
]save列表的保存逻辑:
python
# 处理行18: f = [-1, 8]
# 8 != -1,所以添加 8 % 18 = 8
save.append(8)
# 处理行25: f = [-1, 6]
# 6 != -1,所以添加 6 % 25 = 6
save.append(6)
# 处理行28: f = [27, 22, 15]
# 27, 22, 15 都不等于 -1
save.extend([27%28, 22%28, 15%28]) # 即 [27, 22, 15]
# 最后排序
sorted_save = sorted([8, 6, 27, 22, 15]) # 返回 [6, 8, 15, 22, 27]save列表记录了需要保存输出的层索引,这些层的输出会在训练或推理中被缓存,用于:
(1)特征重用:如 FPN 中的特征拼接
(2)多尺度检测:不同尺度的特征图用于检测
(3)中间特征可视化:用于调试和分析
2.3 parse_model调用链
parse_model函数被 DetectionModel类的 __init__方法调用,如下:
python
class DetectionModel(BaseModel):
def __init__(self, cfg="yolov5s.yaml", ch=3, nc=None, anchors=None):
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml
self.yaml_file = Path(cfg).name
with open(cfg, encoding="ascii", errors="ignore") as f:
self.yaml = yaml.safe_load(f) # model dict
# 定义模型参数
ch = self.yaml["ch"] = self.yaml.get("ch", ch)
if nc and nc != self.yaml["nc"]:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml["nc"] = nc
if anchors:
LOGGER.info(f"Overriding model.yaml anchors with anchors={anchors}")
self.yaml["anchors"] = round(anchors)
# 🔴 关键调用行:调用 parse_model
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # 模型构建再探索整个完整调用链:
python
训练或特殊推理 → 创建 DetectionModel 实例 → DetectionModel.__init__() → parse_model()也就是训练或特殊推理时会根据yaml配置文件动态创建整个网络(主干+neck+头)!
总言之,动态整个网络构建 = 配置文件定义 + 代码解析构建。
2.4 yolov3.yaml配置文件
结合yolov3.yaml进行探索,yolov3.yaml配置文件如下:
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# darknet53 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Bottleneck, [64]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 2, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 5-P3/8
[-1, 8, Bottleneck, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 8, Bottleneck, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
[-1, 4, Bottleneck, [1024]], # 10
]
# YOLOv3 head
head: [
[-1, 1, Bottleneck, [1024, False]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [1024, 3, 1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 8], 1, Concat, [1]], # cat backbone P4
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 1, Bottleneck, [256, False]],
[-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
[[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]该配置文件配置了整个网络结构,当创建DetectionModel后就传入yolov3.yaml配置文件,__init__方法解析yolov3.yaml并保存到DetectionModel类的yaml字典成员中。
然后深拷贝传递给parse_model进行解析:
python
# 🔴 关键调用行:调用 parse_model
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # 模型构建2.5 主干网络创建
c
开始 parse_model
↓
初始化: ch=[3], layers=[], save=[]
↓
遍历 backbone 配置的11行
↓
对每一行配置:
↓
解析: [from, number, module, args]
↓
获取输入通道: c1 = ch[from]
↓
获取输出通道: c2 = args[0]
↓
应用宽度倍数: c2 = make_divisible(c2 * gw, 8)
↓
构建参数列表: args = [c1, c2, *args[1:]]
↓
处理重复次数: n = max(round(n * gd), 1)
↓
创建模块实例:
if n > 1: nn.Sequential(*(m(*args) for _ in range(n)))
else: m(*args)
↓
添加到 layers
↓
更新通道列表: ch.append(c2)
↓
记录需要保存的层索引
↓
继续下一行
↓
遍历完成
↓
返回: nn.Sequential(*layers), sorted(save)最终主干网络结构:
c
输入(416×416×3)
↓ Conv3x3 stride1 → 32通道
↓ Conv3x3 stride2 → 64通道,下采样到208×208
↓ 1×Bottleneck
↓ Conv3x3 stride2 → 128通道,下采样到104×104
↓ 2×Bottleneck
↓ Conv3x3 stride2 → 256通道,下采样到52×52
↓ 8×Bottleneck
↓ Conv3x3 stride2 → 512通道,下采样到26×26
↓ 8×Bottleneck
↓ Conv3x3 stride2 → 1024通道,下采样到13×13
↓ 4×Bottleneck和主干图保持了一致。
2.6 neck创建
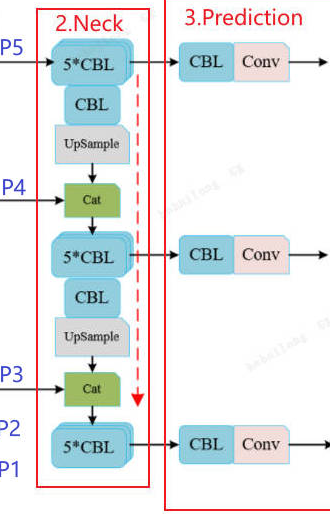
这个neck部分yolov3源码实现就和上图是一样的,但是有2个地方需要说下:
第一,它Prediction部分的CBL给做了,所以Prediction的Detect类就只有单纯的卷积操作conv。
第二,图上neck部分P3/P4/P5的5*CBL的实现组合不一样(用的Bottleneck类和Conv类组合个数不通),具体是怎么组合的如下:
P5的5个CBL在源码中配置实现如下:
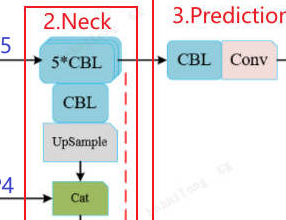
python
[-1, 1, Bottleneck, [1024, False]], # 1个Bottleneck(2个CBL)
[-1, 1, Conv, [512, 1, 1]], # 1个CBL(1x1卷积)
[-1, 1, Conv, [1024, 3, 1]], # 1个CBL(3x3卷积)
[-1, 1, Conv, [512, 1, 1]], # 1个CBL(1x1卷积)
[-1, 1, Conv, [1024, 3, 1]], # 向右分支:3x3卷积 → 输出P5
[-2, 1, Conv, [256, 1, 1]], # 向下分支 1x1卷积->上采样准备
[-1, 1, nn.Upsample, [None, 2, "nearest"]], # 上采样
[[-1, 8], 1, Concat, [1]], # cat backbone P4P5的5*CBL的实现:用了1个Bottleneck+3个CBL,Bottleneck其参数false是不开启残差操作,类似是2个CBL,这个伏笔在这里用啊。其实本质上也是CBL。
P4的5个CBL在源码中配置实现如下:
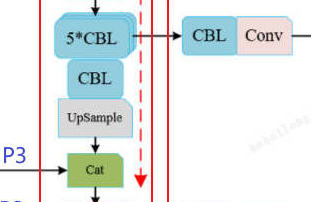
python
# 行19-22:P4 分支
[-1, 1, Bottleneck, [512, False]], # 第1个:Bottleneck
[-1, 1, Bottleneck, [512, False]], # 第2个:Bottleneck
[-1, 1, Conv, [256, 1, 1]], # 第3个:1x1卷积
[-1, 1, Conv, [512, 3, 1]], # 向右分支:3x3卷积 → 输出P4
[-2, 1, Conv, [128, 1, 1]], # 向下分支 1x1卷积->上采样准备
[-1, 1, nn.Upsample, [None, 2, "nearest"]], # 上采样
[[-1, 6], 1, Concat, [1]], # cat backbone P3P4的5*CBL的实现:用了2个Bottleneck(本质上也是4个CBL)+1个CBL。和图中逻辑一样。
P3的5个CBL在源码中配置实现如下:
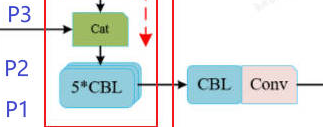
python
# 行26-27:P3 分支
[-1, 1, Bottleneck, [256, False]], # 第1个:Bottleneck
[-1, 2, Bottleneck, [256, False]], # 第2-3个:Bottleneck(重复2次)最后一个P3呢只有一个向右的分支了,就和Predicton部分的CBL合并了,即5+1=6个CBL,所以就用了1+2=3个Bottleneck来搞了。
因此,yolov3的neck部分源码实现完全和图中逻辑实现一致,只是有的是Bottleneck(false不参数不开启残差连接,相当于2个CBL),有的是Conv。
既然Bottleneck相当于2个CBL(即2个Conv),那为啥不全部用它替代呢?通道数一致时用 Bottleneck,不一致时用Conv了。
2.7 检测头创建
同样的,解析yaml的检测头部分从而调用Detect类来实现。
python
[[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
python
elif m in {Detect, Segment}:
args.append([ch[x] for x in f]) # 添加输入通道列表
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)调用链:
c
用户调用 → 创建 DetectionModel
↓
DetectionModel.__init__() → parse_model()
↓
parse_model 解析 YAML 配置
↓
创建 Detect 实例(最后一层)
↓
forward 时调用 Detect.forward()
↓
输入: [P3, P4, P5] 特征图
↓
处理每个尺度: 1x1卷积 + 形状变换
↓
推理时: 网格生成 + 坐标解码
↓
输出: 拼接后的检测结果2.8 构建的整个网络
python
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch])parse_model返回的是nn.Sequential(*layers)。
yolov3.yaml文件对应的完整Sequential内部具体模块如下(也即返回的model内部内容):
python
nn.Sequential= [
# 索引0-10: Backbone
Conv(3, 32, 3, 1), # 0
Conv(32, 64, 3, 2), # 1
Bottleneck(64, 64, shortcut=True, g=1, e=0.5), # 2
Conv(64, 128, 3, 2), # 3
nn.Sequential( # 4
Bottleneck(128, 128, shortcut=True, g=1, e=0.5),
Bottleneck(128, 128, shortcut=True, g=1, e=0.5)
),
Conv(128, 256, 3, 2), # 5
nn.Sequential( # 6
Bottleneck(256, 256, shortcut=True, g=1, e=0.5),
Bottleneck(256, 256, shortcut=True, g=1, e=0.5),
Bottleneck(256, 256, shortcut=True, g=1, e=0.5),
Bottleneck(256, 256, shortcut=True, g=1, e=0.5),
Bottleneck(256, 256, shortcut=True, g=1, e=0.5),
Bottleneck(256, 256, shortcut=True, g=1, e=0.5),
Bottleneck(256, 256, shortcut=True, g=1, e=0.5),
Bottleneck(256, 256, shortcut=True, g=1, e=0.5)
),
Conv(256, 512, 3, 2), # 7
nn.Sequential( # 8
Bottleneck(512, 512, shortcut=True, g=1, e=0.5),
Bottleneck(512, 512, shortcut=True, g=1, e=0.5),
Bottleneck(512, 512, shortcut=True, g=1, e=0.5),
Bottleneck(512, 512, shortcut=True, g=1, e=0.5),
Bottleneck(512, 512, shortcut=True, g=1, e=0.5),
Bottleneck(512, 512, shortcut=True, g=1, e=0.5),
Bottleneck(512, 512, shortcut=True, g=1, e=0.5),
Bottleneck(512, 512, shortcut=True, g=1, e=0.5)
),
Conv(512, 1024, 3, 2), # 9
nn.Sequential( # 10
Bottleneck(1024, 1024, shortcut=True, g=1, e=0.5),
Bottleneck(1024, 1024, shortcut=True, g=1, e=0.5),
Bottleneck(1024, 1024, shortcut=True, g=1, e=0.5),
Bottleneck(1024, 1024, shortcut=True, g=1, e=0.5)
),
# 索引11-28: Head
Bottleneck(1024, 1024, shortcut=False, g=1, e=0.5), # 11
Conv(1024, 512, 1, 1), # 12
Conv(512, 1024, 3, 1), # 13
Conv(1024, 512, 1, 1), # 14
Conv(512, 1024, 3, 1), # 15 (P5/32-large)
Conv(512, 256, 1, 1), # 16
nn.Upsample(scale_factor=2, mode="nearest"), # 17
Concat(dim=1), # 18
Bottleneck(768, 512, shortcut=False, g=1, e=0.5), # 19
Bottleneck(512, 512, shortcut=False, g=1, e=0.5), # 20
Conv(512, 256, 1, 1), # 21
Conv(256, 512, 3, 1), # 22 (P4/16-medium)
Conv(256, 128, 1, 1), # 23
nn.Upsample(scale_factor=2, mode="nearest"), # 24
Concat(dim=1), # 25
Bottleneck(384, 256, shortcut=False, g=1, e=0.5), # 26
nn.Sequential( # 27 (P3/8-small)
Bottleneck(256, 256, shortcut=False, g=1, e=0.5),
Bottleneck(256, 256, shortcut=False, g=1, e=0.5)
),
Detect( # 28
nc=80,
anchors=[
[10, 13, 16, 30, 33, 23],
[30, 61, 62, 45, 59, 119],
[116, 90, 156, 198, 373, 326]
],
ch=[256, 512, 1024],
inplace=True
)
]而返回的sorted(save)列表如下:
python
sorted(save) = [6, 8, 15, 22, 27]然后在推理是调用forward就会调用上述sequential中各个模块的forward给出结果。
2.9 注意点
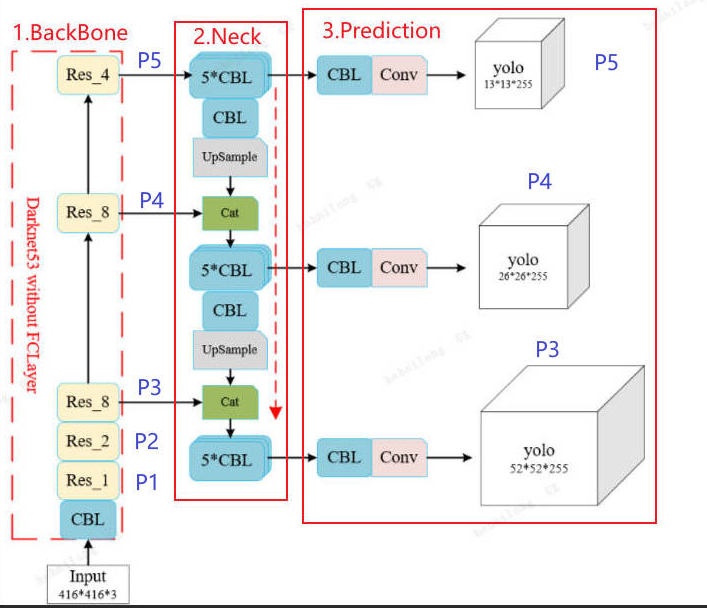
就是有一点要说下就是yolov3.yaml中主干标注的P1-P5,和head里标注的P1-P5。
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# darknet53 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Bottleneck, [64]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 2, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 5-P3/8
[-1, 8, Bottleneck, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 8, Bottleneck, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
[-1, 4, Bottleneck, [1024]], # 10
]
# YOLOv3 head
head: [
[-1, 1, Bottleneck, [1024, False]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [1024, 3, 1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 8], 1, Concat, [1]], # cat backbone P4
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 1, Bottleneck, [256, False]],
[-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
[[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]注意啊,在 Backbone 部分,虽然注释里写了 5-P3/8、7-P4/16、9-P5/32,但这只是标记下采样位置。真正被 Neck 引用的"干货"是每个 Stage 最后的Bottleneck 输出。
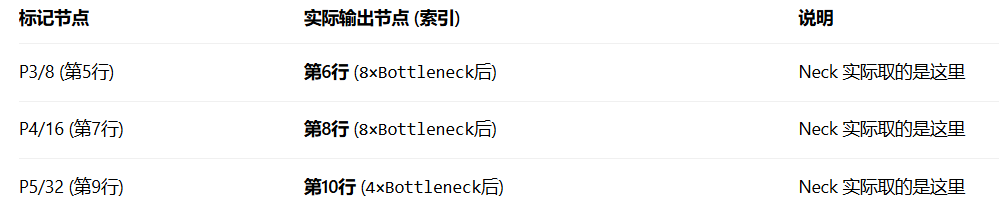
关键证据:在 Neck 的 Concat操作中,from字段指向的是 8和 6,而不是 7和 5。如下
python
[[-1, 8], 1, Concat, [1]] # 取索引8(第8行,即P4 stage最后的输出)
[[-1, 6], 1, Concat, [1]] # 取索引6(第6行,即P3 stage最后的输出)3 后处理代码
推理后,需要进行处理。
阶段一:模型预测与原始输出
模型前向传播 (detect.py)
代码:pred = model(im, augment=augment, visualize=visualize)
输出:prediction张量,其形状通常为 batch, num_boxes, 85。其中 85 = 4(坐标) + 1(置信度) + 80(COCO类别概率)。如果使用多尺度预测,这个张量是三个尺度预测结果的合并。
阶段二:非极大值抑制 (NMS) - 核心后处理
调用 NMS 函数 (detect.py)
代码:pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
作用:从成千上万个重叠的预测框中,筛选出最可靠、不重复的检测结果。
NMS 核心算法实现 (general.py中的 non_max_suppression函数)
该函数是后处理的引擎,其内部执行以下关键步骤,与你之前理解的流程一一对应:
a. 置信度过滤:舍弃置信度低于阈值 (conf_thres) 的框。
b. 计算综合得分:conf = obj_conf * cls_conf,得到每个框的最终得分。
c. 坐标转换:调用 xywh2xyxy函数,将框的格式从 (中心x, 中心y, 宽, 高)转换为 (左上x, 左上y, 右下x, 右下y),以便计算 IoU。
d. 按类别/全局进行NMS:
如果不是 agnostic模式,会为不同类别的框加上一个大的偏移量,实现按类别分别进行NMS,防止不同类别的框因位置接近而被误删。
调用 torchvision.ops.nms(boxes, scores, iou_thres),这是执行筛选的核心操作。
e. 返回结果:返回一个列表,其中每个元素是一个张量,代表一张图片中最终保留的检测框,格式为 n, 6,即 x1, y1, x2, y2, conf, class_id。
4 叠框处理代码
阶段三:结果可视化与保存
准备可视化工具 (detect.py)
代码:annotator = Annotator(im0, line_width=line_thickness, example=str(names))
作用:创建一个 Annotator对象,它封装了在图片上画框、写文字的功能。
遍历并绘制每一个检测框 (detect.py)
代码 (在循环内):
c
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = names[c] if hide_conf else f'{names[c]} {conf:.2f}'
annotator.box_label(xyxy, label, color=colors(c, True))作用:
*xyxy, conf, cls:解包 NMS 输出的一个检测框。
label:生成要在框旁显示的文本(类别名 + 置信度)。
annotator.box_label(...):这是"叠框"动作的核心调用。它内部会做两件事:1) 用指定颜色在 (x1, y1, x2, y2)坐标画矩形框;2) 在框的左上角画一个填充色块并写上 label文字。
保存或显示结果图片 (detect.py)
保存图片:cv2.imwrite(save_path, im0)
显示图片:cv2.imshow(str§, im0)(如果 view_img=True)
作用:将已经画好所有检测框的图片 (im0) 保存到硬盘或显示在屏幕上。