AI的记忆困局:为什么需要"时序"和"知识图谱"?
用过ChatGPT或任何AI助手的人大概都有过这样的体验:昨天告诉AI自己住在北京,今天问它"我住哪儿",它可能还能答对;但是过了两周,你又告诉它你搬到了上海,再问"我之前住哪儿",它可能就一脸茫然,或者开始自己的幻想回答。
这并不是AI"笨",而是它的记忆系统结构上的缺陷造成的。
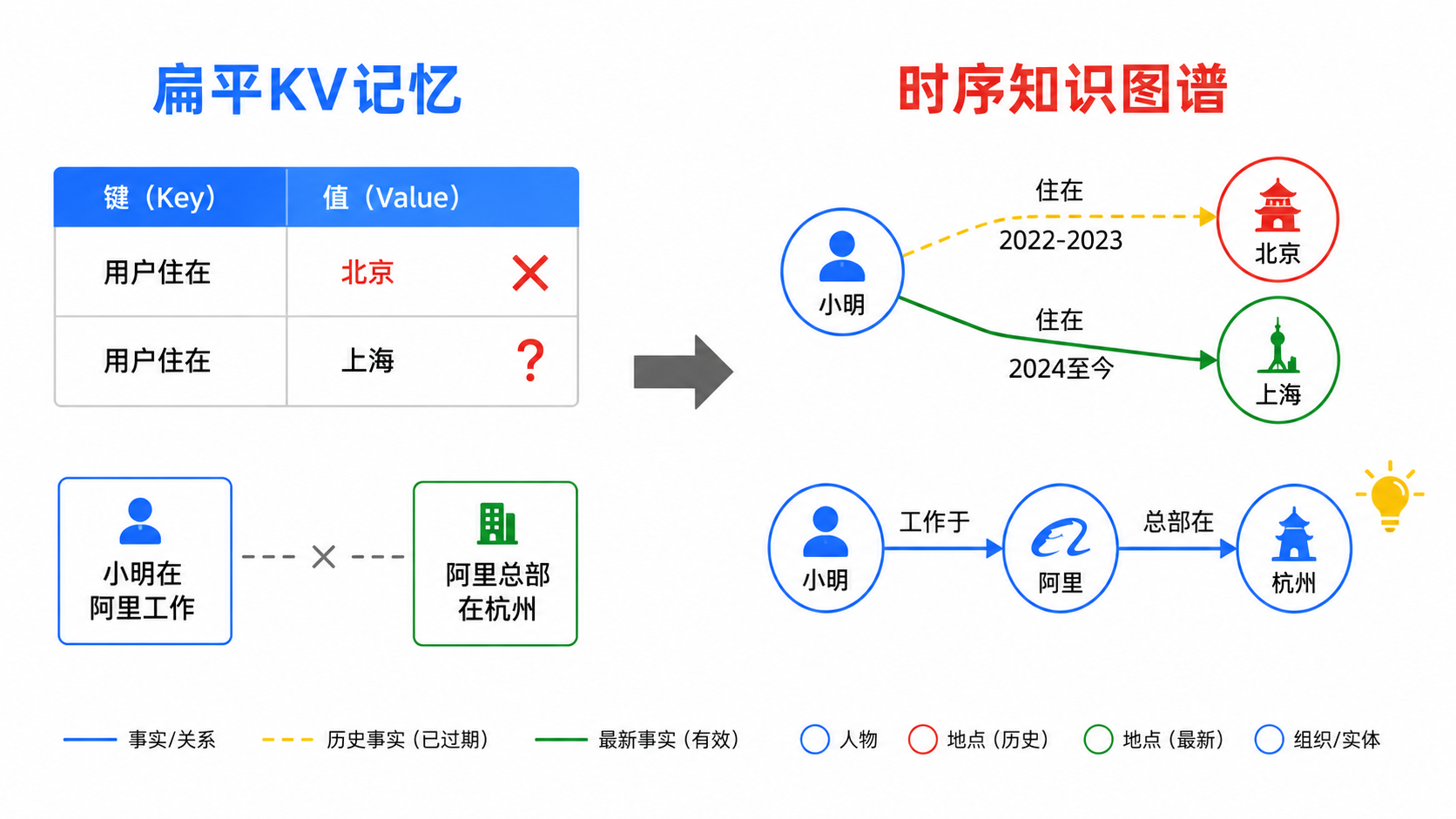
当前主流的AI记忆系统架构,本质上是一种"扁平存储",即把用户说过的话提取成关键词和值的配对,存进向量数据库,检索时靠语义相似度进行匹配。这套逻辑在"记住一个静态事实"时还算好用,但是在面对真实世界中的以下两大场景时就会显得力不从心:
场景一:事实会变。 用户的工作、住址、偏好都在动态的更新,而扁平记忆系统只能存储"当前状态",旧信息要么被覆盖,要么和新信息并存造成矛盾。
场景二:事实之间有关联。 "小明在阿里工作"和"阿里的总部在杭州"是两条独立的事实,人类是能够自然的推理出"小明可能在杭州",但是扁平化的KV存储是做不到这一点的。
而能够解决这两个问题的,正是"时序能力"和"知识图谱"。
时序+知识图谱 vs 普通记忆系统
时序:事实会变,历史不能丢
普通记忆系统存储的是快照:"用户住在北京"。它只有一个状态,没有时间维度。
时序记忆系统存储的是时间线:"用户2022年住在北京,2024年搬到了上海"。每条事实都带有生效时间点或时间段,旧的事实不会被删除,而是被标记为"在某个时间点或时间段之后不再成立"。
时序记忆的优势可以概括为一句话:事实会变,历史不能丢。 你可能需要知道用户现在住哪里,也可能需要知道用户两年前住哪里------这正是时序记忆的价值所在。
知识图谱:从"存事实"到"做推理"
普通记忆系统的存储结构是扁平的KV对(关键词-值),类似于字典:
小明 → 在阿里工作
阿里 → 总部在杭州这种结构只能逐条检索,无法发现两条记录之间的关联。
知识图谱的存储结构是"实体-关系-实体"的三元组网络:
(小明) --[工作于]--> (阿里) --[总部位于]--> (杭州)这种网络结构天然支持推理:当你问出"小明可能在哪个城市"时,系统会沿着图谱的路径"小明→阿里→杭州"推导出答案。而这恰好是扁平存储根本做不到的------它甚至不知道"阿里"和"杭州"之间有关系。
时序+知识图谱:MemoryOS的核心差异化
当"时序"叠加上"知识图谱",产生的化学反应远不止1+1=2:
- 知识图谱告诉你"谁和谁有什么关系"
- 时序标注告诉你"这个关系什么时候成立、什么时候失效"
- 组合起来,系统既能推理实体间的关系,又能精准回答"A和B的关系在2023年是什么"这类时序查询
比如用户2022年在阿里的杭州总部工作,2024年跳槽到了深圳的腾讯。在时序知识图谱中,这两条信息共存不冲突:
(小明)-[工作于]->(阿里) tvalid: 2022~2024
(小明)-[工作于]->(腾讯) tvalid: 2024~现在
(阿里)-[总部位于]->(杭州) tvalid: 一直
(腾讯)-[总部位于]->(深圳) tvalid: 一直当问"小明现在在哪工作"时,沿当前有效的边遍历即可;当问"小明2023年在哪工作"时,沿2023年有效的边遍历即可。这就是MemoryOS的核心差异化所在。
MemoryOS简介
说了优势之后,再把MemoryOS详细介绍一下。MemoryOS是一个开源的AI Agent记忆平台(GitHub: Per0x1de-1337/MemoryOS),采用MIT开源许可证,核心引擎和SDK完全免费,支持自托管部署。
它的核心架构由以下几个关键模块构成:
1. Append-only时序知识图谱
这是整个系统的基础。每条知识都以边(edge)的形式存储,其结构为`(subject, predicate, object, tvalidstart, tvalidend)`。当事实发生变化时,旧边的`tvalid_end`被设置为变更时间,新边追加到图谱中------永不执行UPDATE或DELETE操作。
这种设计带来了两个好处:一是完整的保留了事实变迁的历史,支持任意时间点的快照查询("2022年Alice住哪里?");二是避免了并发写入时的数据冲突,新的事实只是追加,不会修改已有的数据。
2. 三重向量表示
每个新的记忆块会获得三种向量表示:
- vcontent:原始文本的密集向量,用于捕捉字面语义
- vlatent:LLM增强文本的密集向量,解析代词和引用(比如把"他不喜欢那个框架"解析为"小明不喜欢React"),用于捕捉深层语义
- BM25稀疏权重:基于词频的稀疏表示,用于弥补语义向量在关键词精确匹配上的不足
三种向量表示各有侧重,在检索时并行评分、融合排序,兼顾语义理解和关键词命中。
3. 混合检索:三路评分+图遍历融合
查询时的检索流程:
-
查询文本经过本地嵌入(14ms)→ pgvector HNSW近似最近邻检索(20ms)→ 获取Top-50候选
-
三路评分(vcontent相似度 + vlatent相似度 + BM25权重)融合为初始混合分
-
图遍历评分:沿知识图谱路径计算与查询实体相关的图距离分
-
混合分 × 图分 × 衰减分 = 最终排序分
-
可选:Cohere Reranker精排(增加约450ms,但会显著提升模糊查询的精度)
整个检索热路径完全本地化,不依赖外部API调用。
4. 艾宾浩斯衰减引擎
人的记忆不是越多越好,过时的、不再被访问的记忆需要被"归档"。MemoryOS采用了艾宾浩斯遗忘曲线的数学模型:
R = e^(-t/S)
其中R是记忆保留率,t是距上次访问的时间,S是记忆稳定性。关键在于:S不是固定值,它会随着每次检索而增长------频繁被访问的记忆更难被遗忘,长期无人问津的记忆则逐渐衰减,低于阈值后自动归档。
这套机制确保了记忆库的"新陈代谢":重要的记忆会长期保留,过时的记忆则慢慢的被清理归档。
5. 性能数据
在Azure D48ads-v5(48 vCPU,无GPU)环境下的实测数据:
| 指标 | 数值 |
| 批量写入吞吐 | 9ms/msg |
| 快速查询(warm p50) | ~78ms |
| 精确查询(warm p50) | ~470ms |
| 精确查询(warm p95) | ~640ms |
|---|
评测数据
LongMemEval-s(ICLR 2025)对比
LongMemEval是ICLR 2025发表的长期记忆评测基准,包含500道人工编写的问题,覆盖信息提取、多会话推理、时序推理、知识更新和弃权五大核心能力。其中LongMemEval-s为小规模版本,每个问题约115K tokens的对话历史。
| 系统 | 准确率 | 延迟 | 开源 | 价格 |
| HydraDB | 90.79% | <200ms | 闭源 | $249/mo |
| MemoryOS | 86.2% | 78ms | 开源 | 免费,自托管 |
| Supermemory | 85.4% | <300ms | 开源 | $19/mo |
|---|
数据来源:Hacker News帖子(2026-05-12)
从上面的对比中可以看到三个关键信息:
- 速度最快:MemoryOS的78ms检索延迟是三者中最低的,比HydraDB快2.5倍以上
- 准确率第二:86.2%仅次于闭源的HydraDB,但超过了同样开源的Supermemory
- 成本为零:HydraDB每月249,Supermemory每月19,MemoryOS完全免费自托管
与其他开源框架对比
根据CSDN横评(2026-05-12),各框架在主流基准上的表现:
| 框架 | LoCoMo | LongMemEval-S | 架构特点 |
| Mem0 | ~64% | ~65% | 扁平KV+语义向量 |
| Zep | ~78% | --- | 时序知识图谱(Graphiti) |
| MemOS(MemTensor) | 69.24% | 68.68% | 图谱+多模型+MCP |
| MemoryOS(Per0x1de-1337) | --- | 86.2% | 时序KG+三重向量+衰减 |
|---|
数据来源:CSDN横评(2026-05-12)
特别注意:MemoryOS(Per0x1de-1337)和MemOS(MemTensor)是两个完全不同的项目。前者是轻量级的时序知识图谱记忆引擎,后者是MemTensor团队开发的记忆操作系统,采用段页式分层+热度驱动淘汰的架构。两者名字相似但设计思路和技术路线却完全不同,请勿混淆。
MemoryOS在LongMemEval-S上的86.2%,比同属开源阵营的Mem0(~65%)高出约21个百分点,比MemOS(MemTensor,68.68%)高出约17.5个百分点。这种差距主要来自时序知识图谱结构对时序推理和知识更新类问题的天然优势。
总结:从"能记住"到"能理解变化"
第一代记忆系统解决了"能记住"的问题------通过向量数据库把对话中的事实持久化下来,让AI在跨会话时不再"失忆"。
第二代记忆系统解决的是"能理解变化"的问题------事实不是静态的,关系不是孤立的,时间不是无关紧要的维度。用户会换工作、会搬家、会改变偏好,一个优秀的记忆系统需要像人类一样,既能记得过去发生了什么,又能知道现在是什么状态,还能预测未来可能的变化。
时序知识图谱正是实现这一升级的关键技术路径。它让AI的记忆从一本扁平的"通讯录"进化为一部立体的"编年史"------不仅记录了"谁是谁",更记录了"什么时候、因为什么、变成了什么"。
写在最后
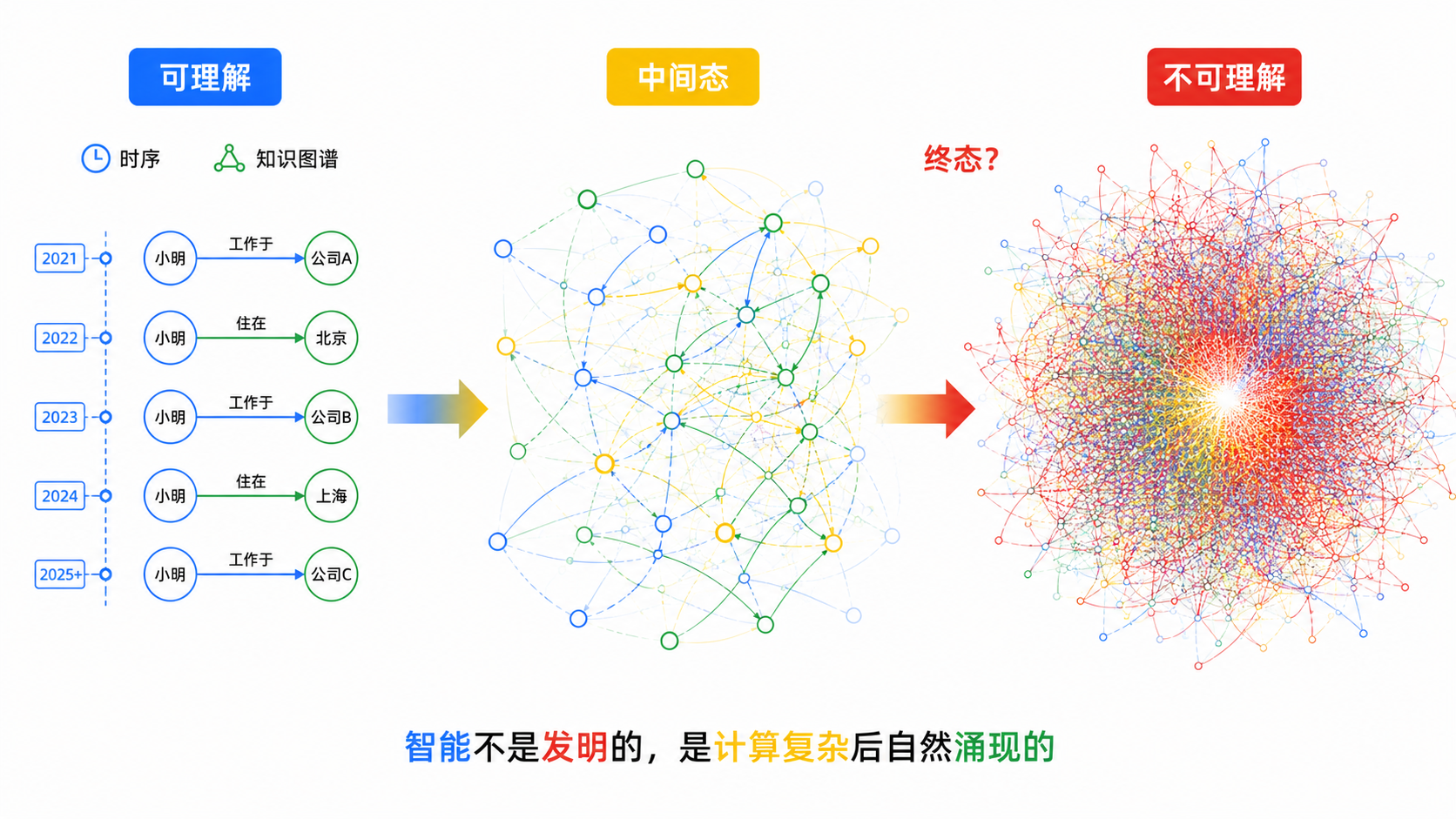
智能是计算高度复杂后的自然产物,我们并不是发明了智能,而是像发现数学公式一样在当前达到了这样的计算复杂度后自然而然发现的。时序+知识图谱一定不是最后的结构,而最后的结构一定是一种随着计算和存储复杂后自然而然产生的人类无法理解的算法结构。但是时序+知识图谱可以很好的给我们一个理解AI记忆的中间态。