一、引文
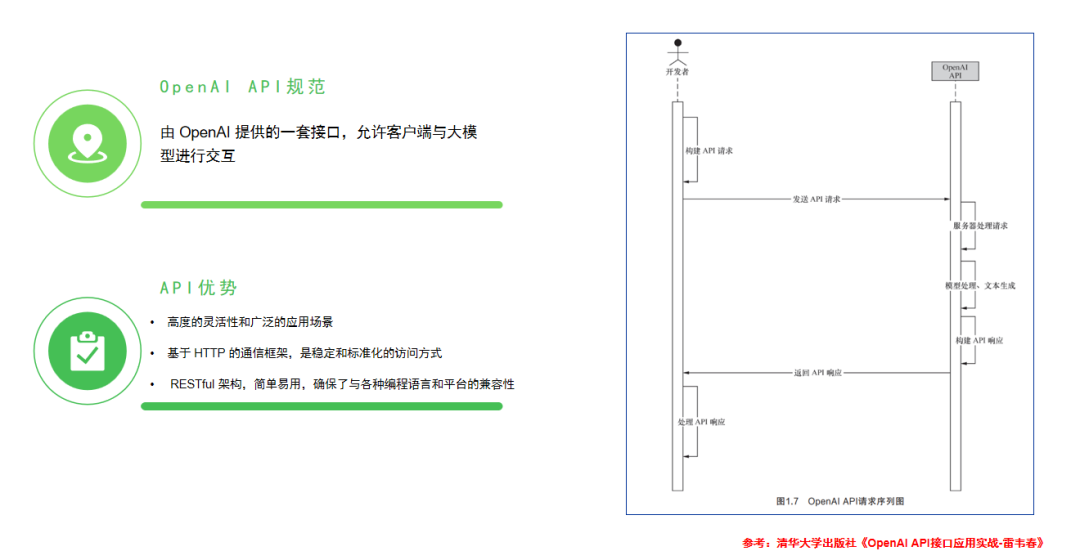
相信每一个尝试做 AI 项目,把大模型集成到自己项目中的开发者都一定听说过 OpenAI 的 API 规范。它就好比是大模型世界里面的普通话,当开发者试图通过调用 API 完成与大模型的交互时,通常都会遵循这一规范的请求格式来构建请求参数,以及根据其响应格式来解析结果,并且这一套规范在调用市面上的大部分的大模型 API 都是兼容的。那么这一规范究竟是什么呢,里面到底蕴含哪些细节,包括说在一个Java程序里面调用大模型的具体流程是什么,要想知道答案我们可以继续看下去!
注意:大模型 API 接口大致分为对话补全(Chat Completions)、嵌入(Embeddings)、微调(Fine-tuning)、图像生成(Images)、音频处理(Audio)这几种,每一种接口的内部规范略有差异,下面我们将会以最为常用的大模型 API 的事实标准------ OpenAI 的 Chat Completions API 作为示例,刨析其中的具体细节。
接口类型 适用场景 常用模型 对话补全(Chat Completions) 聊天机器人、内容生成 gpt-3.5-turbo、gpt-4、gpt-4o 嵌入(Embeddings) 语义检索、向量数据库构建 text-embedding-3-small、text-embedding-ada-002 微调(Fine-tuning) 自定义模型训练 gpt-3.5-turbo-0125 图像生成(Images) 文生图、图生图 dall-e-2、dall-e-3 音频处理(Audio) 语音转文字、文字转语音 whisper-1、tts-1
二、准备好你的BASE_URL和API_KEY
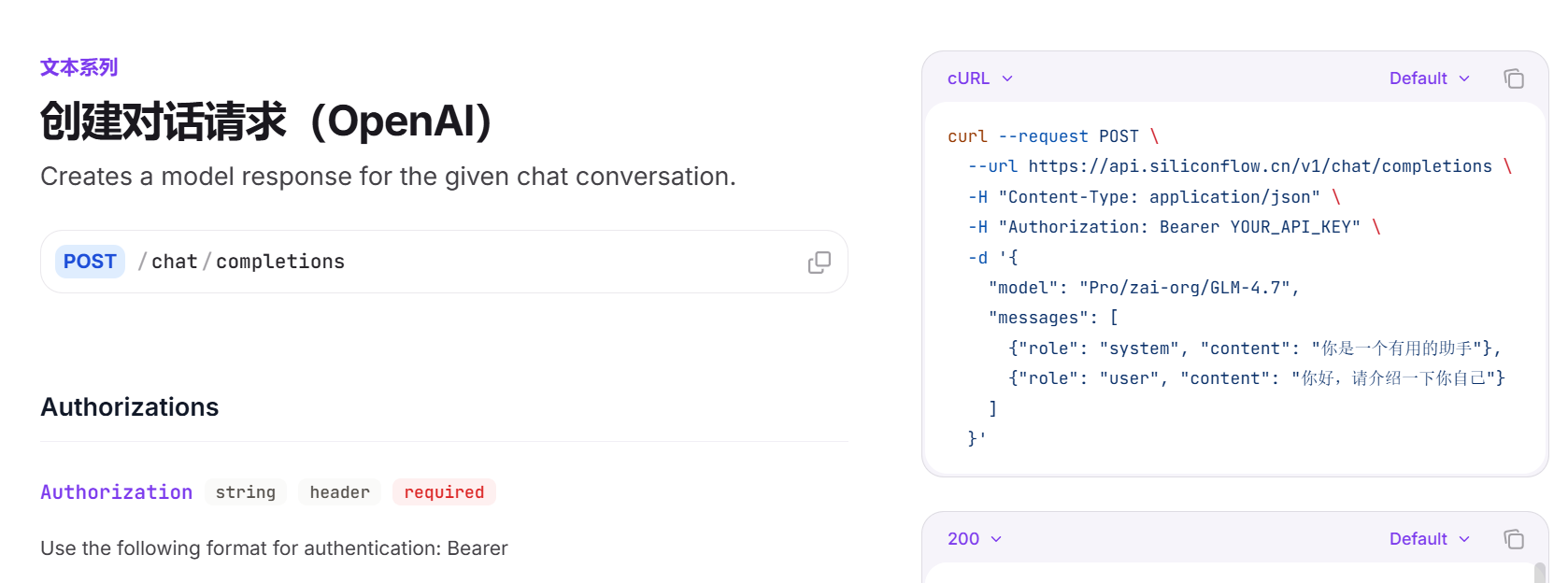
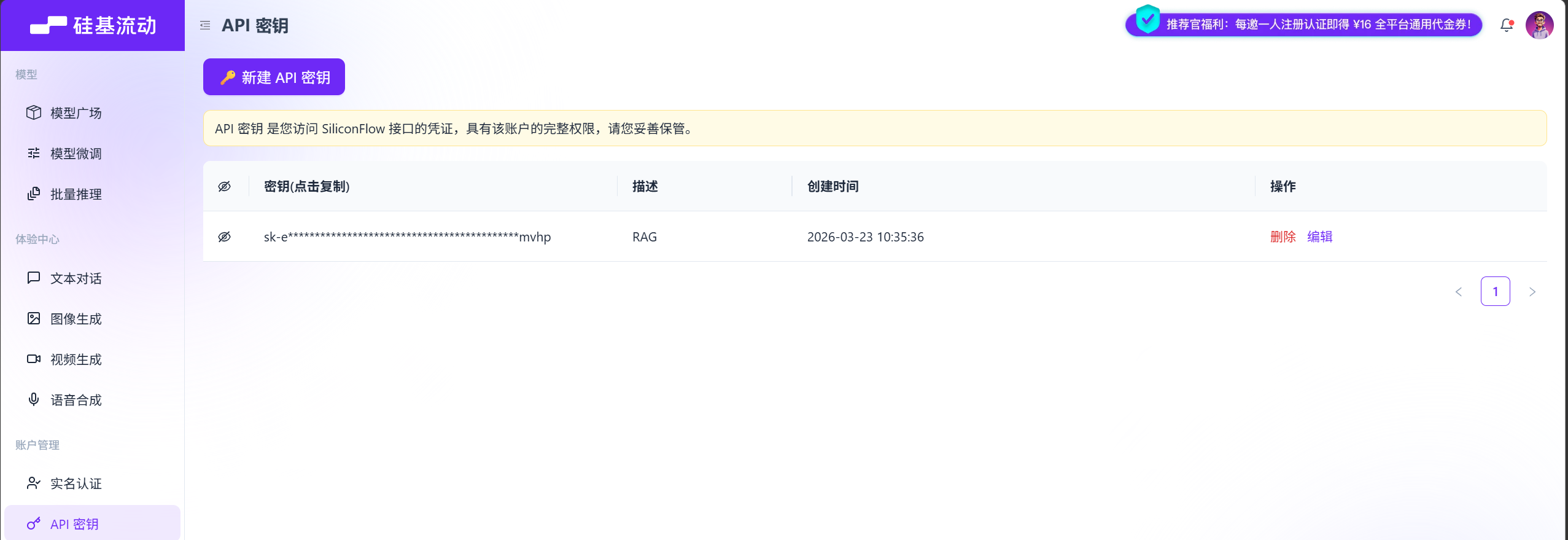
我们在 Java 程序中调用大模型的第一步就是先确定你选择注册的 AI 模型服务平台的BASE_URL 和 API_KEY。以调用硅基流动平台的智谱GLM5为例,复制 API 文档里面的POST请求就是BASE_URL,Authorization 里面的就是你的API_KEY,在 API 密钥里面可以找到。
三、构建请求体
第二步就是构建请求参数,OpenAI 的 API 规范对请求参数的格式进行了限定,在这一小节我们就具体了解一下其中各个参数的具体含义和应用场景。
1.参数总览
java
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4-turbo",
"messages": [
{
"role": "user",
"content": "What'\''s the weather like in Boston today?" <==用户的问题
}
],
"tools": [ <===用户提供工具集让模型来选择使用哪个可以解决用户的问题
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
}
],
"tool_choice": "auto"
}'观察上述 curl 命令(一个功能强大的命令行工具,可用于发送 HTTP/HTTPS 请求、下载文件、上传数据以及调试 API。它支持多种协议(HTTP、HTTPS、FTP 等),在开发、测试和运维中非常常用。),我们可以发现除却刚刚的 BASE_URL 和 API_KEY ,还有 model、messages、tools、tool_choice等等,接下来我们就来具体讲解每一种常见参数包括其属性的含义。
2.model
model 都是 string 类型,且是必须具备的参数,它代表调用的模型ID,例如
gpt-3.5-turbo、gpt-4o、gpt-4-turbo,必须使用当前账号有权限的模型,否则会返回404错误
3.messages
message 细分的话可以分为四类 System message、User message、Assistant message、Tool message,每种 message 的属性有所差别,接下来分开进行讲解。
(1)System message
System message 又称系统消息,系统消息是用来定义模型的行为规则,相当于给模型一份工作手册。模型会始终遵守系统消息中的指令。通常大家在借用 AI 背八股或者模拟面试时,如果对大模型的回答效果不是很满意,其实就可以上牛客或者直接找 AI 帮你写出一段对应场景下适合的 System message,这样大模型就会严格按照这套行为规则回答你的问题,效果通常都会比默认的 System message 要好出很多。
一个完整的system message要是一个json对象,包含以下字段:
content *:*必须提供的string类型,表示系统消息内容
**role:**必须提供的string类型,表示该消息的角色,对于system message应该是"system"
**name:**可选的string类型,表示对话参与者的名称。
(2)User message
用户消息就是用户的输入,也就是用户问的问题。
一个完整的User message是一个json对象,包含以下字段:
content *:*必须提供的string或array类型,二选一,表示user的消息内容
为string类型时,表示消息的文本内容
为array类型时 ,一般用于调用多模态模型,用来包含多个内容部分的数组,一般是一个文本内容的json对象和一个或多个图片内容的json对象。仅当使用 gpt-4-visual-preview 这样的多模态模型时才支持图像输入。具体字段如下:
文本内容部分,是一个json对象:
type:必须提供的string类型,表示内容部分的类型,一般是"text"
text:必须提供的string类型,文字内容
图片内容部分,是一个json对象:
type:必须提供的string类型,表示内容部分的类型,一般是"image_url"
image_url:必须提供的json对象类型,字段有:
url:必须提供的string类型,图像的 URL 或Base64 编码的图像数据
detail:可选的string类型,一般默认是"auto"
**role:**必须提供的string类型,表示消息的角色,对于user message应该是"user"
**name:**可选的string类型,表示对话参与者的名称
(3)Assistant message
助手消息是模型之前的回答。它的作用是构建多轮对话的上下文。
一个完整的Assistant message是一个json对象,包含以下字段:
content :必须提供(指定 tool_ call时除外)的string类型,表示大模型的回答
**role:**必须提供的string类型,表示消息的角色,对于assistant message应该是"assistant"
**name:**可选的string类型,表示对话参与者的名称
**tool_calls:**可选的array类型,大模型生成的工具调用,例如函数调用。tool_calls数组的每个元素是一个json对象,代表一个函数调用,包含的字段有:
id:必须提供的string类型,表示函数调用的id
type:必须提供的string类型,表示工具调用的类型。目前仅支持"function"类型
function:必须提供的string类型,表示模型针对工具调用为用户生成的函数说明,即模型在特定任务和场景下下,在用户提供的函数中,会推断出应该使用哪一个函数,以及函数的参数应该是什么。所以包括的字段有:
name:必须提供的string类型,要调用的函数的名称
arguments:必须提供的string类型,表示调用函数所用的参数,由模型以 JSON 格式生成(如:"{\n\"location\": \"Boston, MA\"\n}")。但是请注意,模型并不总是生成有效的参数,并且可能会产生未由函数定义的参数。在调用函数之前最好验证参数的准确性。
(4)Tool message
在讲最后一种消息类型前,先给大家介绍下 Function Calling,它可以让大模型通过调用工具扩展能力边界。一种常见的误解是,所谓的 Function Calling 就是大模型自己调用工具,这种想法是错误的,大模型本身不会自己调用工具,它只会告诉你的后端代码需要执行哪个工具,然后由你的后端代码去执行这一工具,再把返回结果传递给大模型拼凑上下文回答你的问题。具体过程如下:
Step 1:
用户询问天气案例------> messages 里面的User message携带用户问题,tools 里面则是开发者事先给大模型准备好的工具,它是一个列表,里面存着各种各样的工具,具体属性及含义后面在讲解 tools 这个参数时会再次讲解。
javacurl https://api.openai.com/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -d '{ "model": "gpt-4-turbo", "messages": [ { "role": "user", "content": "What'\''s the weather like in Boston today?" <==用户的问题 } ], "tools": [ <===用户提供工具集让模型来选择使用哪个可以解决用户的问题 { "type": "function", "function": { "name": "get_current_weather", "description": "Get the current weather in a given location", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city and state, e.g. San Francisco, CA" }, "unit": { "type": "string", "enum": ["celsius", "fahrenheit"] } }, "required": ["location"] } } } ], "tool_choice": "auto" }'Step 2:
大模型回答Step 1中的用户请求 ------> 这是一个 OpenAI 的Chat Completions API的标准响应体格式,在第四大节会讲到。关键看它 tool_calls 属性,里面就是大模型根据用户问题还有事先准备的工具列表判断出来的你的后端代码需要调用的工具以及它的各种属性,比如名字就是"get_current_weather",这就是一个标准的 JSON 格式字符串,然后你的后端代码先把这个响应体解析,再去调用这个函数。
java{ "id": "chatcmpl-abc123", "object": "chat.completion", "created": 1699896916, "model": "gpt-3.5-turbo-0125", "choices": [ { "index": 0, "message": { "role": "assistant", "content": null, "tool_calls": [===>大模型根据用户的问题和用户提供的工具集返回了可能有用的函数 { "id": "call_abc123", "type": "function", "function": { "name": "get_current_weather", ===>用户可以在调用了该函数后在下一轮对话把该函数调用结果反馈给大模型 ,然后就可以得到一个最终的答复 "arguments": "{\n\"location\": \"Boston, MA\"\n}" } } ] }, "logprobs": null, "finish_reason": "tool_calls" } ], "usage": { "prompt_tokens": 82, "completion_tokens": 17, "total_tokens": 99 } }Step 3:
生成我们的 Tool message返回给大模型,拼凑上下文 ------>
一个完整的Tool message是一个json对象。他的用处是:在用户根据assistant的tool_calls内容调用了某个函数后,用户可能还需要再把函数调用结果反馈给大模型,让大模型根据函数调用结果给出最终的总结性的答复。tool message消息字段有:
content:必须提供的string类型,表示工具消息的内容,一般是把函数调用的结果描述在这里
**role:**必须提供的string类型,表示消息的角色,对于tool message应该是"tool"
tool_call_id:必须提供的string类型,表示本次消息是对哪个函数调用的结果反馈,应该与 assistant message->tool_calls->id 对应
4.tools
可用工具列表,定义模型可以调用的函数/工具规范,每个工具包含
type(固定为function)和function(函数定义,包含name、description、parameters)列表中每个tool包含的字段有:
**type:**必须提供的string类型,工具的类型。目前仅支持函数"function"
**function:**必须提供的json对象类型,表示函数的一些描述信息,包括:
**description:**可选的string类型,是函数功能的描述,模型使用它来选择何时以及如何调用该函数
**name:**必须提供的string类型,是函数的名称。必须是 a-z、A-Z、0-9,或包含下划线和破折号,最大长度为 64
**parameters:**可选的json对象类型,表示函数接受的参数,描述为 JSON Schema 对象。不包含parameters字段是,代表定义了一个带有空参数列表的函数
5.tool_choice
控制工具调用行为:
**-
none:**强制不调用工具**-
auto:**让模型自动选择是否调用工具 - 指定具体工具对象:强制调用该工具
6.stream
是否启用流式响应,默认false。设置为true时会通过SSE协议逐块返回结果,适合需要打字机效果的场景
7.top_p
核采样参数,取值范围0~1,默认1。例如设置为0.1时,只会从概率总和前10%的Token中采样,和temperature建议只修改其中一个
8.temperature
采样温度,取值范围0~2,默认1。值越低输出越确定,值越高输出越随机有创造性,0表示完全确定性输出
四、解析响应体
1.参数总览
java
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-3.5-turbo-0125",
"system_fingerprint": "fp_44709d6fcb",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "你好,有什么可以帮你的?",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}2.id
本次请求的唯一ID,用于问题排查
3.object
固定为
chat.completion,标识响应类型
4.created
请求处理的时间戳(秒级)
5.model
实际使用的模型ID
6.system_fingerprint
模型后端版本标识,相同值表示后端环境一致
7.choice
回复结果数组,长度等于请求中设置的
n值:**-
index:**结果序号**-
message:**AI回复的消息对象,结构和请求中的message一致-
finish_reason: 回复结束原因:stop(正常结束)、length(达到max_tokens限制)、tool_calls(调用工具)、content_filter(内容审核拦截)
8.usage
Token消耗统计:
**-
prompt_tokens:**输入消息的Token数**-
completion_tokens:**输出回复的Token数**-
total_tokens:**总消耗Token数,用于计费
9.流式响应
流式响应会返回多个SSE块,每个块是一个JSON对象,结构和非流式类似,但
choices[0].delta字段增量返回内容,最后一块的finish_reason不为空表示结束,最后会返回一个data: [DONE]标记。
javadata: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"role":"assistant","content":""},"finish_reason":null}]} data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"可以"},"finish_reason":null}]} data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"的。"},"finish_reason":null}]} data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"根据"},"finish_reason":null}]} data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"退货"},"finish_reason":null}]} data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{"content":"政策"},"finish_reason":null}]} data: {"id":"chatcmpl-abc123","choices":[{"index":0,"delta":{},"finish_reason":"stop"}]} data: [DONE]
五、总结
这篇文章我们主要围绕OpenAI API接口展开讲解,先梳理对话补全、嵌入、微调、图像生成、音频处理五类接口的适用场景与常用模型;接着说明调用前需准备BASE_URL与API_KEY,重点解析Chat Completions请求体核心参数,包括model、messages各类角色消息、工具调用相关配置及stream、top_p、temperature等参数;再介绍响应体字段含义与流式响应格式,清晰展示从发起带工具的对话请求、模型返回函数调用指令,到完成结果交互的完整流程。整体为开发者提供了OpenAI API从接口选型、请求构建到响应解析的实用入门指引。