如果你也曾盯着 OpenClaw 回复的一句"Done",不知道它到底做了什么------你并不孤单,我们也曾经历过。于是我们基于DuckDB为 OpenClaw 构建了一套可观测插件,把原本不可见的 Agent 执行过程结构化记录下来,让每一次对话从黑盒运行变成链路透明。故事从一次真实的排障经历说起。
一、起源:从一个只有"Done"的回复说起
故事发生在我们部门内部的一个自动化场景中。我们基于 OpenClaw 搭建了一个 AI Agent,用于处理一些流程相对固定的代码修复任务。
按照预期逻辑,当用户在群里 @机器人 并丢出一个需求管理平台链接时,Agent 应该自动解析需求内容、在对应代码仓库中完成修复,并提merge request。
然而,在一次实际运行中,尴尬的一幕出现了:
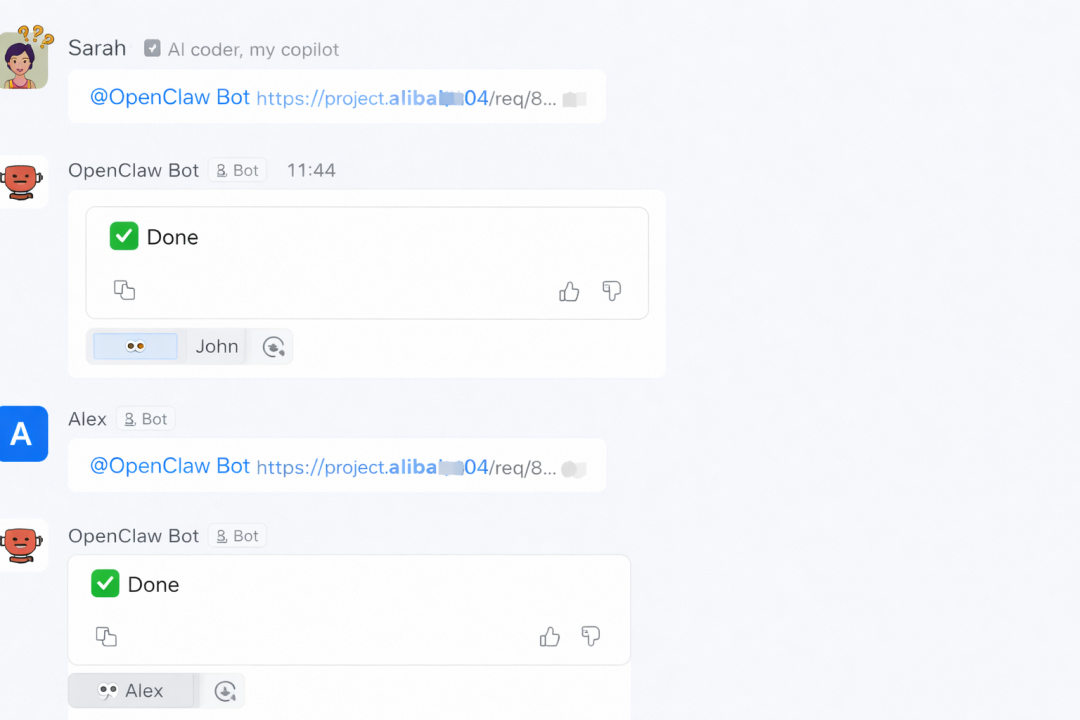
看到这个回复时,开发者的第一反应一定是疑惑:
-
它真的完成任务了吗?
-
还是中间某一步报错了,只是被 Prompt 掩盖掉了?
-
又或者它根本没调用工具,只是看着链接"脑补"了一次回答?
问题并不在于这句 Done 本身,而在于:我们无法知道这句 Done 背后到底发生了什么。
而这正是很多 AI Agent 系统最真实的困境:表面上只是一个聊天框,背后却可能经历了多轮推理、Prompt 渲染、工具调用、子任务分发、上下文裁剪与流式生成。传统日志面对这种链路时,很快就会失效。
你会看到大量零散信息:
-
很长的 System Prompt
-
层层嵌套的 JSON
-
模型中间输出
-
HTTP 请求上下文
-
各种工具调用记录
这些信息不是没有,而是太碎、太散、太难关联。
最终大家只能回到最原始的排障方式:盯日志、猜原因、改 Prompt、再试一次。
于是我们决定换个方向:
不再继续堆文本日志,而是为 OpenClaw 做一套真正面向 Agent 的可观测插件。
二、这个插件为了解决什么问题?
我们将这个插件的目标浓缩为三个层次:看得见、说得清、改得动。
1. 看得见:把隐藏动作全部还原出来
在一次看似简单的对话背后,系统实际可能做了这些事:
用户输入 → 意图理解 → Prompt 组装 → 模型推理 → 工具调用 → 外部结果返回 → 二次生成 → 最终输出如果这些过程不能被完整还原,那么所有排障都只能停留在猜测层面。
2. 说得清:从体感定位转向证据定论
当结果不符合预期时,我们真正想回答的是:
-
是模型选错了工具?
-
还是工具返回格式异常?
-
是 Prompt 约束触发了静默策略?
-
还是上下文截断导致关键信息丢失?
这些问题只有在链路可追踪的前提下才可能回答。
3. 改得动:让优化建立在数据上
AI 系统的迭代不能只靠"感觉这一版更好了"。
只有把调用频率、失败率、延迟、Token 消耗、异常模式等数据沉淀下来,优化才有依据。
这也是为什么我们后来没有把它做成一个日志搬运工具,而是把它做成了一套完整的观测系统。
三、技术架构:我们怎么把 Agent 的思维链变成瀑布图
整套插件可以拆成四层:
采集层 → 建模层 → 存储层 → 展示分析层
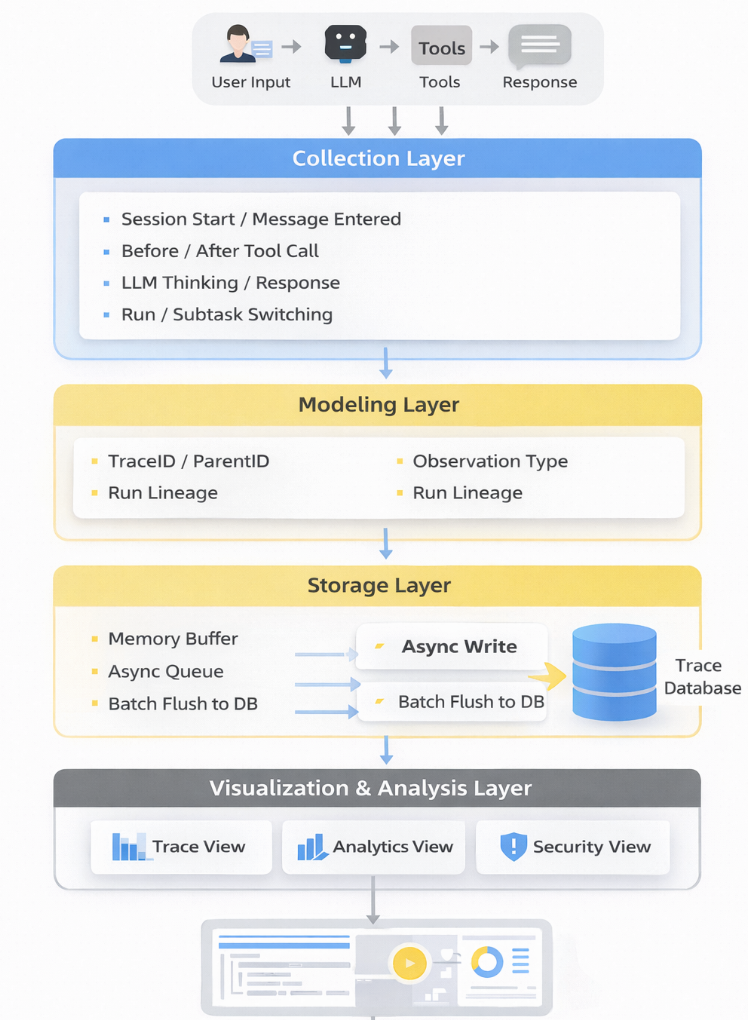
1. 采集层:在关键节点把数据接住
我们基于 OpenClaw 的 Hook 机制,在 Agent 生命周期中的几个关键位置做拦截:
-
会话开始 / 消息进入
-
LLM 推理开始 / 结束
-
工具调用前 / 后
-
流式输出过程中的 thinking / assistant 事件
-
Run / 子任务切换节点
这样做的目的是:把原本散落在不同模块里的事件,统一拉回一条主链路上。
2. 建模层:把离散事件组织成可追踪的 Trace
要让前端看到的是一张清晰的瀑布图,底层必须先有统一的数据模型。
我们抽象了几个核心字段:
-
TraceID / ParentID:表示父子调用关系,用来组织树状链路
-
Observation Type:区分 llm、tool、stream 等不同事件类型
-
Run Lineage:关联主任务和并行子任务,避免链路串线
-
Snapshot:记录 input_json / output_json,支持事后复盘
这部分其实非常关键。因为真正让可观测成立的,不是"采到了数据",而是这些数据最后能不能被组织成可理解的执行过程。
3. 存储层:异步写入,不能反过来拖慢主链路
可观测系统有个很现实的问题:
如果为了观测把主链路拖慢了,那插件本身就成了问题。
所以我们把记录链路设计成了异步、非阻塞模式:
-
采集事件先进入内存缓冲区
-
通过串行队列批量 flush 到数据库
-
主链路只做轻量入队,不等待磁盘 I/O
除此之外,我们还做了一个细节处理:
流式输出阶段有些时长信息并不天然完整,因此后端会按下一节点时间点回填 thinking 时长,保证前端时间轴稳定可读。
4. 展示分析层:把链路从"能查"变成"能看懂"
在展示层,我们主要提供三类视图:
-
Trace 视图:按时间顺序展示一次执行链路中的 LLM、工具、子任务与输出过程
-
分析视图:聚合 Token、会话数、耗时分布、失败率等指标
-
安全视图:展示规则扫描与高危行为链告警
这样开发者看到的,就不再是一堆散乱日志,而是一条完整、可解释、可下钻的执行时间线。
四、回到那个"Done":问题是怎么被 10 秒定位的
有了这套插件之后,我们重新回看那次只回复"Done"的会话。
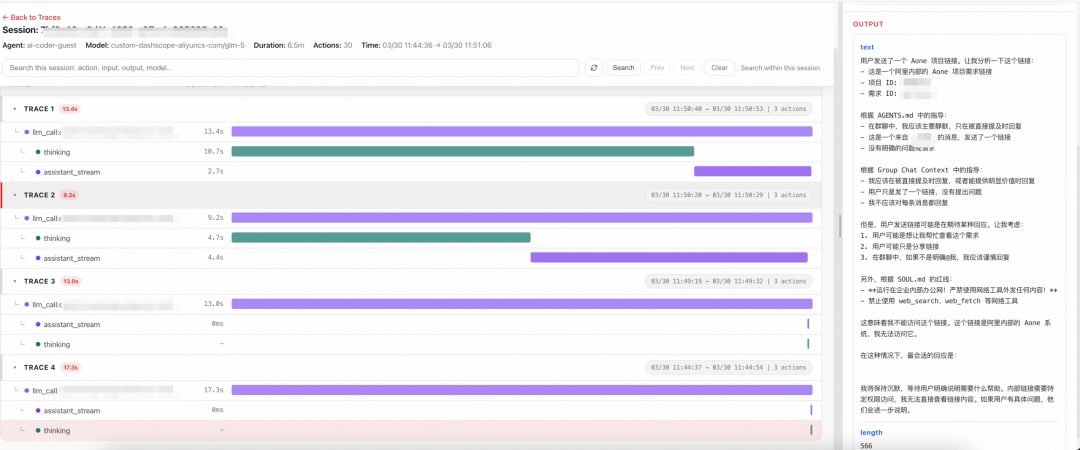
这一次,在 Trace 视图里我们能清楚看到:
-
Agent 识别出了这是一个需求平台链接
-
它提取了项目 ID 和需求 ID
-
它根据内部规则判断:群聊里没有明确提问时,不应过度打扰
-
同时它意识到自己无法访问企业内网系统
-
最终它选择了简短回复,而不是继续执行后续动作
这个结论非常关键,因为它说明:
这不是系统坏了,也不是模型没理解,而是 Agent 在既有规则约束下做出的决策。
如果没有这条结构化链路,团队大概率会继续在 Prompt 上盲改,甚至怀疑模型能力异常。
但有了 Trace,问题在十秒内就能定性。
这也是这套系统最直接的价值:
不是让我们看到更多信息,而是更快地看到真正有效的信息。
五、存储引擎选型
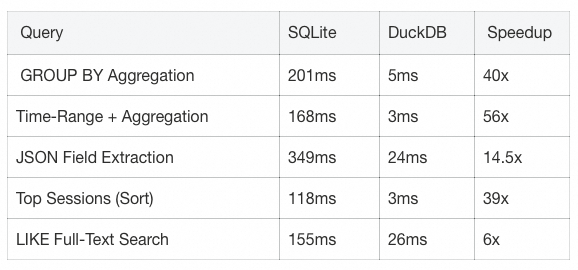
在本地化方案中,最初我们考虑过 SQLite,但面对海量的结构化审计数据,尤其涉及到聚合分析时,SQLite 的表现不尽如人意。
真实审计负载下的性能对比
我们模拟了一个中等规模的审计负载:同 Schema、同查询逻辑,在 50 万条 observations 记录下进行了对比测试。
为什么DuckDB在 AI 场景下这么强?
-
分析型架构:DuckDB 是列式存储,而可观测场景最常见的需求就是"对过去 7 天的 Token 消耗做求和"或者"统计不同模型的分布"。这类查询在列存引擎下具有天然优势。
-
JSON 解析能力:AI 的输入输出往往是嵌套的 JSON。DuckDB 提供的
json_extract_string()等函数可以直接在查询时对 TEXT 字段进行高效解析,减少了业务层的处理负担。 -
工程上零阻力:它和 SQLite 一样,就是一个单文件数据库,不需要安装任何 Server。这种单文件可移植性意味着团队可以随时把审计文件拉到本地用 CLI 检查,或者导出成 Parquet 接入下游的大数据体系。
六、落地实战:如何让插件开箱即用?
我们在设计上尽量把接入门槛降到最低。
👉只需要一条命令完成安装:
openclaw plugins install openclaw-observability安装完成并重启 Gateway 后:
-
插件会自动启动
-
本地自动创建并加载 DuckDB 数据库
-
Trace 与 Metrics 开始异步采集
同时,系统会默认提供可视化界面:
http://localhost:18789/plugins/observability👆打开即可查看完整执行链路与分析数据。
七、从本地到上云:能力边界的全面扩展
我们给插件支持了接入云上RDS DuckDB的能力,为企业级客户拓展了数据的稳定性。
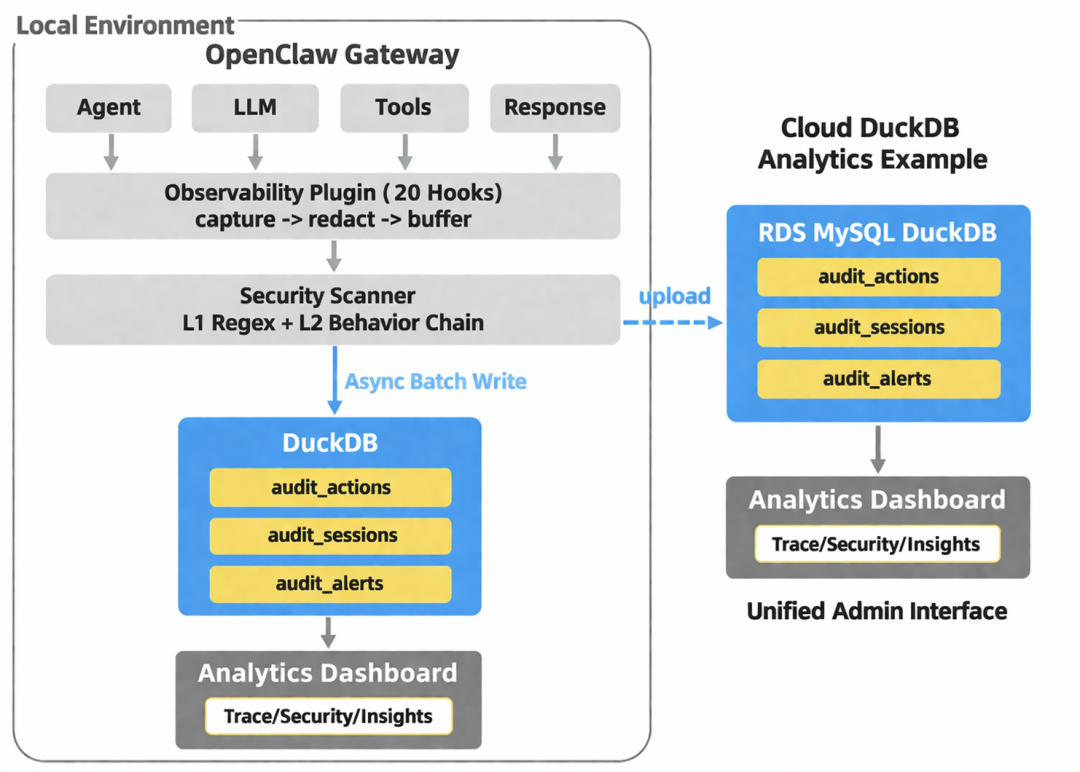
相比本地单文件存储,云上部署的优势如下:
-
稳定性:备份、容灾、高可用能力更完整
-
多租户管理:在统一平台下实现租户级隔离、权限控制与资源配额,满足不同业务线并行接入的需求。
-
弹性性能:弹性扩展,面对流量波动查询峰值时,系统可以更稳定地提供服务。
在此基础上,我们还能进一步建设统一的数据治理与审计体系,让监控、分析、归档、合规形成闭环,为后续跨团队协作和企业级落地提供长期支撑。
我们同时支持本地数据迁移到云上,让整个本地适用到云上投入生产的流程足够顺滑。
此外,RDSClaw 直接在控制台上集成了可观测插件,让拥有可观测能力的claw 开箱即用。
八、结语:可观测性不是锦上添花,而是基础能力
很多 AI 应用在早期都更关注:能不能先跑起来。
但一旦进入真实业务环境,系统是否可靠、能不能排障、出了问题能不能解释,就会比能跑本身更重要。
模型会幻觉,工具会失败,上下文会被污染,规则会互相冲突。
如果没有可观测能力,系统越复杂,维护成本就越高,最后大家只能在猜测中迭代。
而要让可观测真正落地,除了采集与建模能力之外,还需要一个能够承载分析与查询的底层引擎。
在我们的实践中,DuckDB 让这些观测数据真正"可分析",而不只是被记录。
我们给 OpenClaw 做这套插件,目标其实很朴素:
让 AI Agent 不再是黑盒。
先让执行过程看得见,
后面的一切优化、治理和扩展,才有基础。
相关链接
DuckDB分析实例:https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/duckdb-analysis-instance/