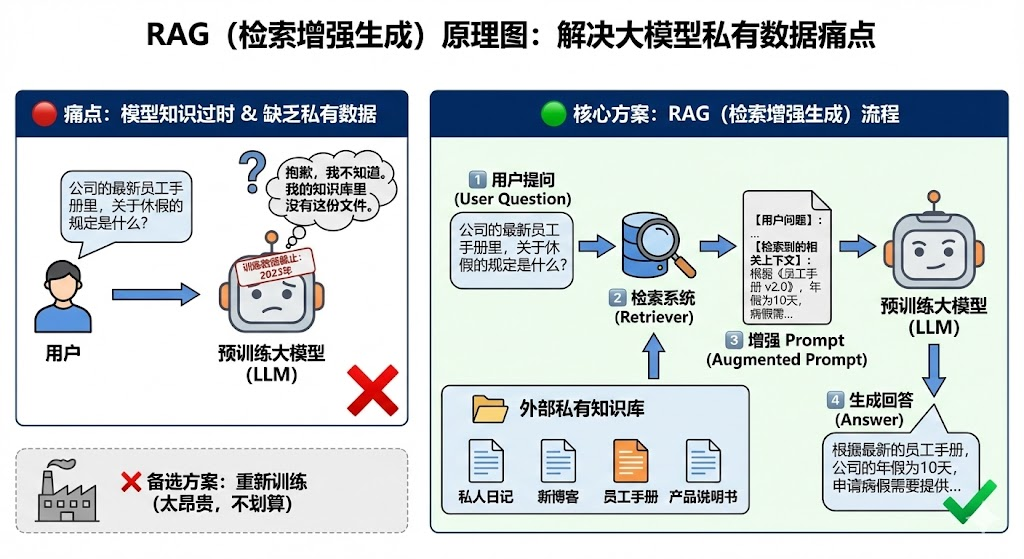
类私有数据 ,是大模型企业应用的痛点,毕竟大模型是基于在互联网上公开数据训练的。重新把这部分资料加进去,再训练一下模型?也不是不行,但是有点没有性价比,这时候就引出了大模型落地应用的核心技术-> RAG (Retrieval-Augmented Generation,检索增强生成)。
1. RAG(检索增强生成)
1.1 什么是RAG?
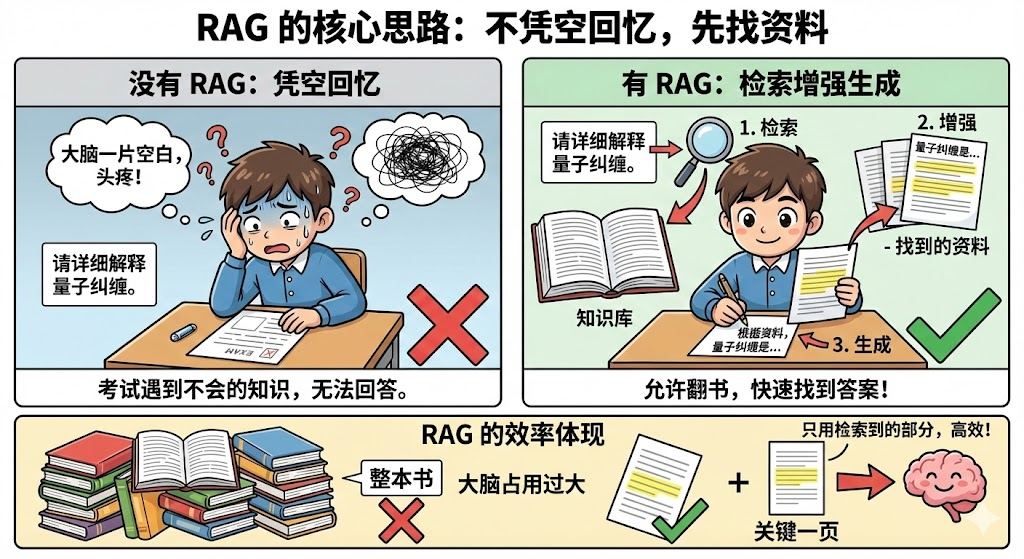
考试的时候,如果考到不会的知识,不知道各位友人们会不会头疼,如果这时候,允许我们翻书,现去书里找,我们也很有可能找得到对应的答案,哪怕我们可能完全没学过。这就是RAG 的大致思路:不让模型凭空回忆,而是先给它找资料。
RAG,检索增强生成,字面上讲,就是 拿到考题->然后去翻书,通过目录之类的索引,快速翻到(检索 )相关的内容->再根据这些内容(增强 了的内容),回答出问题(生成回答)。
对比简单地把东西一股脑全部跟大模型说一遍,我们能清楚得发现,我们只用了检索到的那一部分内容,并没有让整本书大模型的脑子将占用, 这就是RAG的效率体现。
1.2 RAG的步骤
RAG技术的思路很简单,但是实现并非只是一个单一的技术能实现的,它有一套流水线(流水线) 。 把这头"大象"放进冰箱,总共需要两步:准备好数据 和让模型拿到数据。
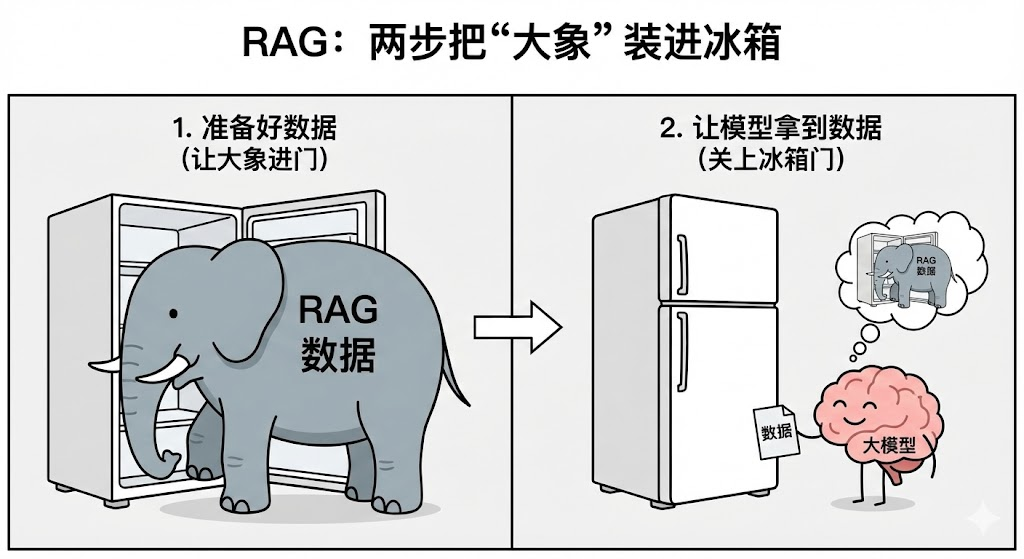
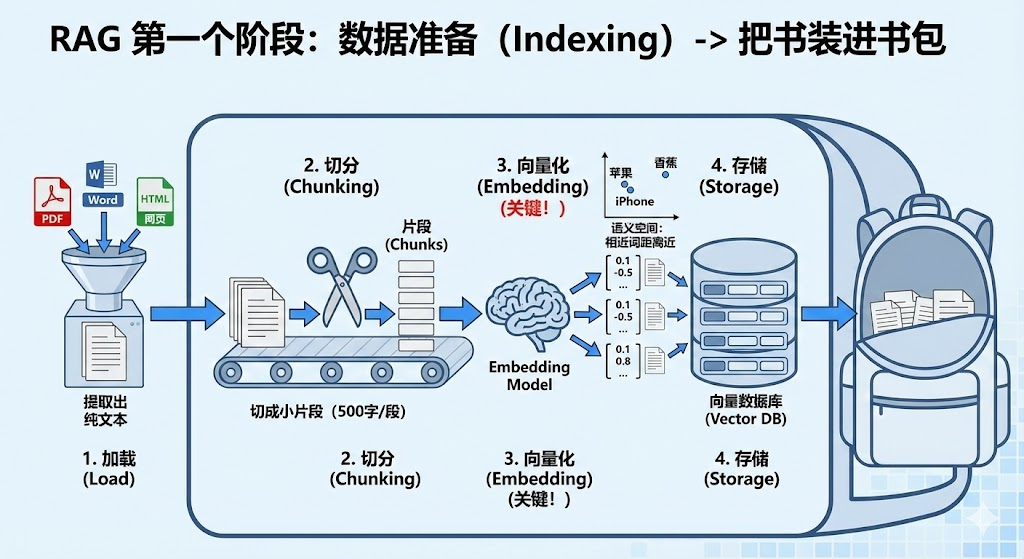
第一个阶段:数据准备(Indexing) -> 把书装进书包
在大模型能够翻书 之前,咱们得先把我们想给它看的书 整理好,放进书包里。
-
加载 (Load):咱们的资料可能是各种各样的格式,一般大模型是不认识这么些格式的,所以我们就需要把 PDF、Word、网页等各种格式的文件读进来,统一提取出纯文本。
-
切分 (Chunking) :大模型一次吃不下整本书,就和我们一眼看不完整本《三国演义》一样,它有上下文长度限制 。我们需要把长文本切成一个个小的片段 (Chunks),比如每 500 个字切一段。
-
向量化 (Embedding) :这是最关键的一步!
- 计算机无法直接比较"苹果"和"iphone"是不是相关的。
- 我们需要用一个专门的模型(Embedding Model),把每一段文字变成一串数字向量 (比如
[0.1, -0.5, 0.8, ...]),是不是有点耳熟,对这和大模型训练的Embedding是一个思路,但是我们一般会使用特制 的嵌入模型来做这个专业的事情。 - 在这个数学空间里,语义相近的词,距离就越近, 这样我们就能知道,这本书中的所有向量,哪些是和我们的问题相关的了。
-
存储 (Storage) :把这些向量和对应的文字,存入向量数据库 (Vector DB) 中。
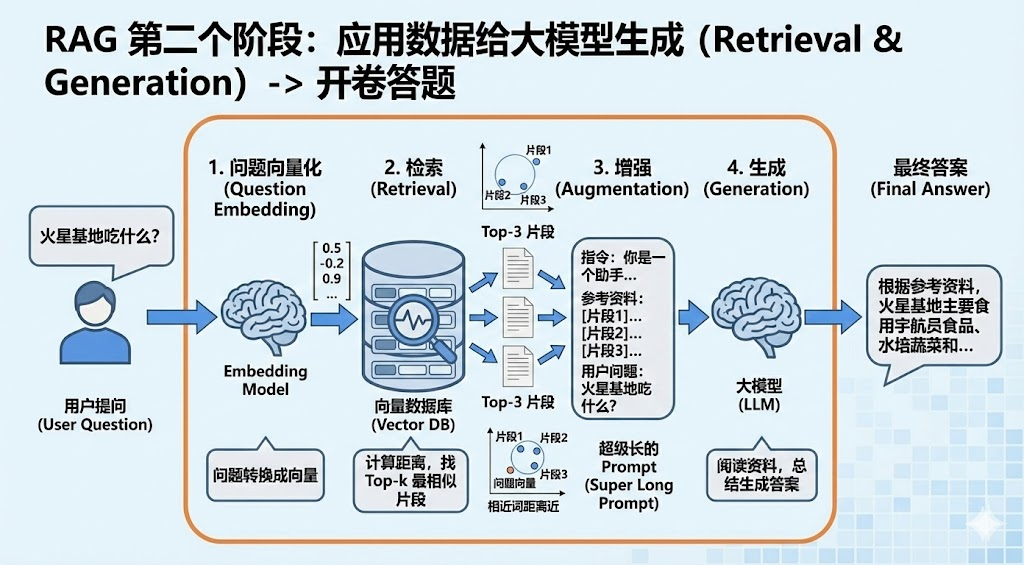
第二个阶段:应用数据给大模型生成(Retrieval & Generation)-> 开卷答题
拿到书了之后,我们想要翻书 ,就得找到和问题有关系 的内容,然后再将这些内容和我们自己的常识结合起来,对提出的问题进行答题。
-
问题向量化(Embedding):要想知道用户的提问(例如"火星基地吃什么?")和内容的相关性,我们就需要像对准备的数据一样,用同一个 Embedding 模型将问题变成向量。
-
检索 (Retrieval) :拿着这个"问题向量",去向量数据库里搜, 去找到关系性高的内容。
- 系统会计算:"哪个文档片段的向量,和问题向量的距离最近?"
- 找出最相似的前 3-5 个片段 (Top-k)。
-
增强 (Augmentation) :把这 3-5 个片段拼在一起,和用户的问题组合成一个超级长的 Prompt。
- Prompt 模板示例: 你是一个助手。请根据以下参考资料回答问题。
参考资料:片段1... 片段2...
用户问题:火星基地吃什么?
- Prompt 模板示例: 你是一个助手。请根据以下参考资料回答问题。
-
生成 (Generation) :把这个 Prompt 喂给大模型(LLM)。大模型阅读资料,总结并生成最终答案。
2. RAG技术选型
好了,理论我们已经懂了,现在我们撸起袖子,准备来实操一下子吧。我们打算从零开始 快速搭建一个工程级 的RAG系统: 私有API助手, 在我直接告诉各位友人们我们要用到的工具前,我觉得也有必要大概让各位友人们知道还有哪些别的选择,我们为什么选择了这几个。
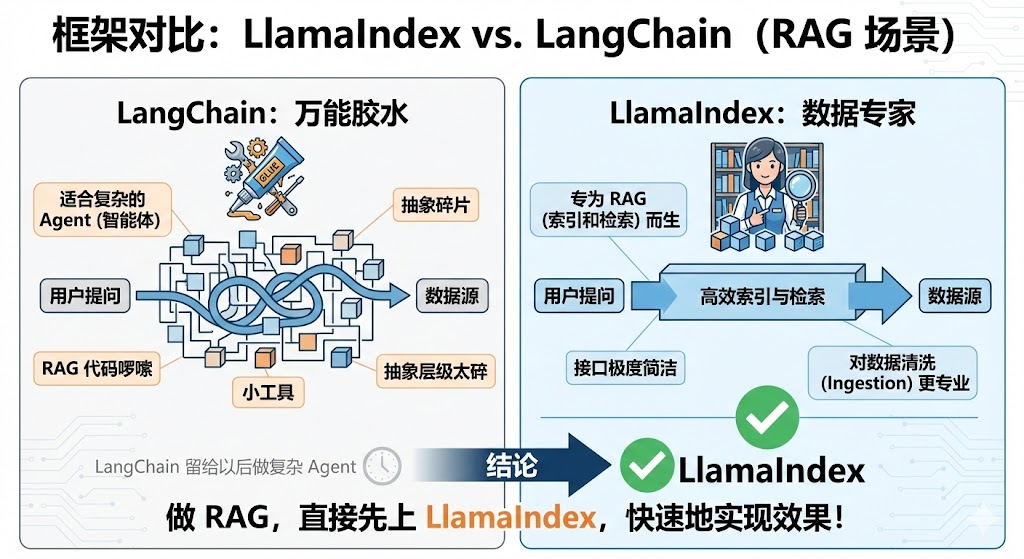
2.1 框架: LlamaIndex vs. LangChain
-
LangChain:万能胶水,适合做复杂的 Agent(智能体),但写 RAG 代码比较啰嗦,抽象层级太碎,我们后面写智能体的时候(如果有精力做智能体的教程的话)再来使用它。
-
LlamaIndex :数据专家。专门为 RAG 也就是"索引和检索"而生。接口极度简洁,且对数据清洗(Ingestion)的处理更专业。
-
结论 :我们做RAG,直接先上LlamaIndex , 快速地实现效果。
2.2 嵌入模型 (Embedding):BGE vs. OpenAI
-
OpenAI (text-embedding-3):效果好,但要钱,且数据要传给 OpenAI(隐私风险)。
-
BAAI/bge-small-zh-v1.5 :国货之光。中文效果霸榜,体积极小(几百 MB),完全可以在 Kaggle 本地跑。
-
结论 :为了免费和隐私,首选 BGE-Small。
-
PS : 如果是英文资料的话,建议换成
BAAI/bge-small-en-v1.5或者 OpenAI 的text-embedding-3-small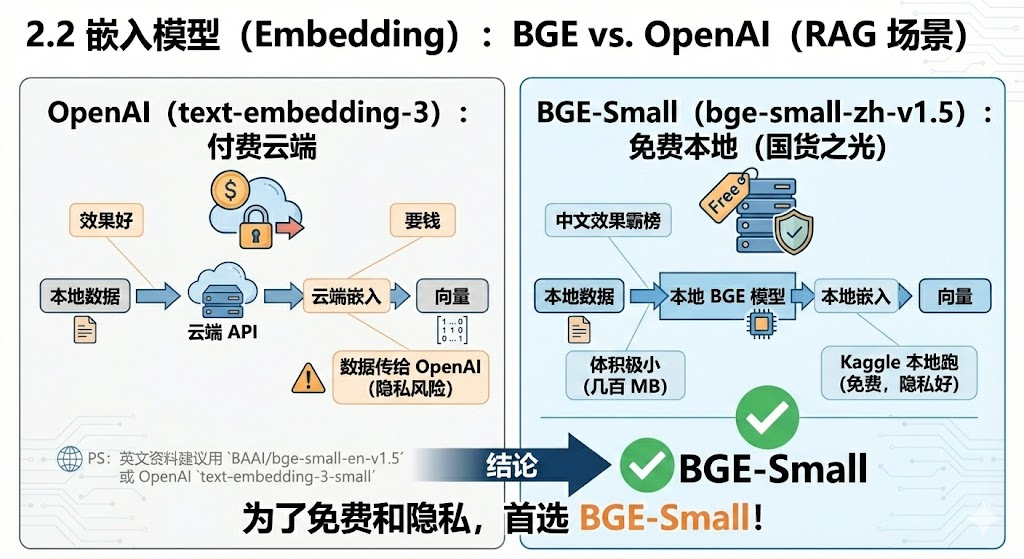
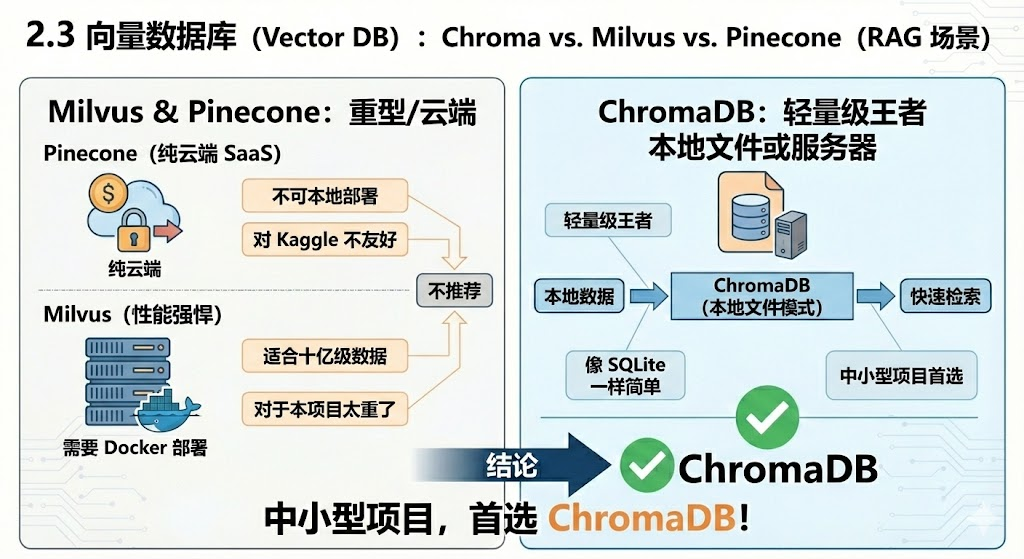
2.3 向量数据库:Chroma vs. Milvus vs. Pinecone
-
Pinecone:纯云端 SaaS,不可本地部署,对 Kaggle 不友好。
-
Milvus:性能强悍,适合十亿级数据,需要 Docker 部署,适合数据量大的时候使用,但是对于咱们的这个项目来说,太重了。
-
ChromaDB :轻量级王者。可以像 SQLite 一样以"本地文件"形式存在,也可以部署成服务器。
-
结论 :中小型项目,首选 ChromaDB 。
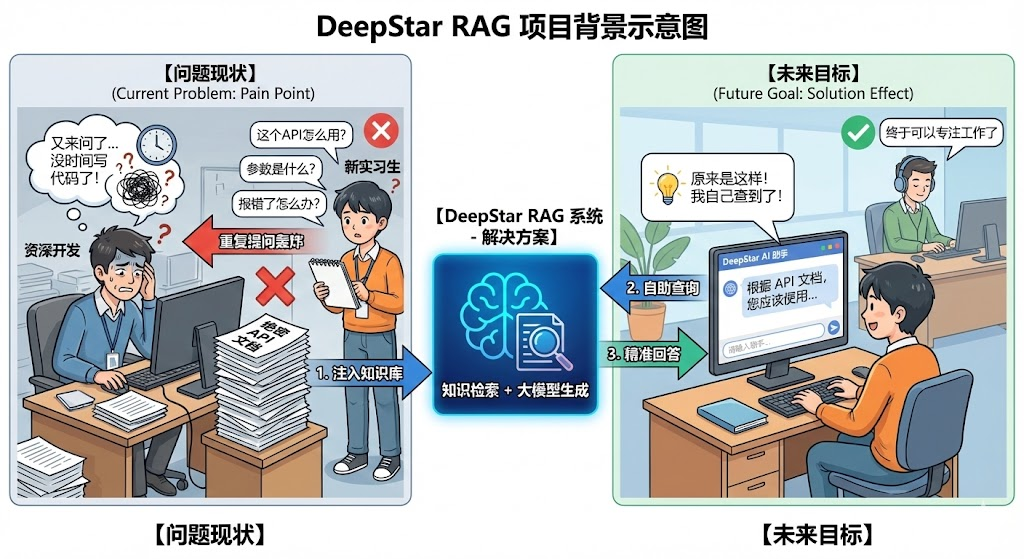
3. 上手实操
项目背景:假设我们是一家名叫 "DeepStar" 的初创公司,我们有一套内部绝密的 API 文档,新来的实习生总是问重复的问题。我们要用 RAG 让他自己查。
3.1 环境配置 (Kaggle)
启动 Kaggle Notebook,确保 Internet: On ,Accelerator: GPU T4 x2。
# 1. 更新transformers及其相关库
!pip install -U transformers peft accelerate bitsandbytes sentence-transformers
# 2. 安装 LlamaIndex 核心及相关插件
!pip install llama-index-core llama-index-llms-huggingface llama-index-embeddings-huggingface
# 3. 安装 ChromaDB 向量库支持
!pip install llama-index-vector-stores-chroma chromadb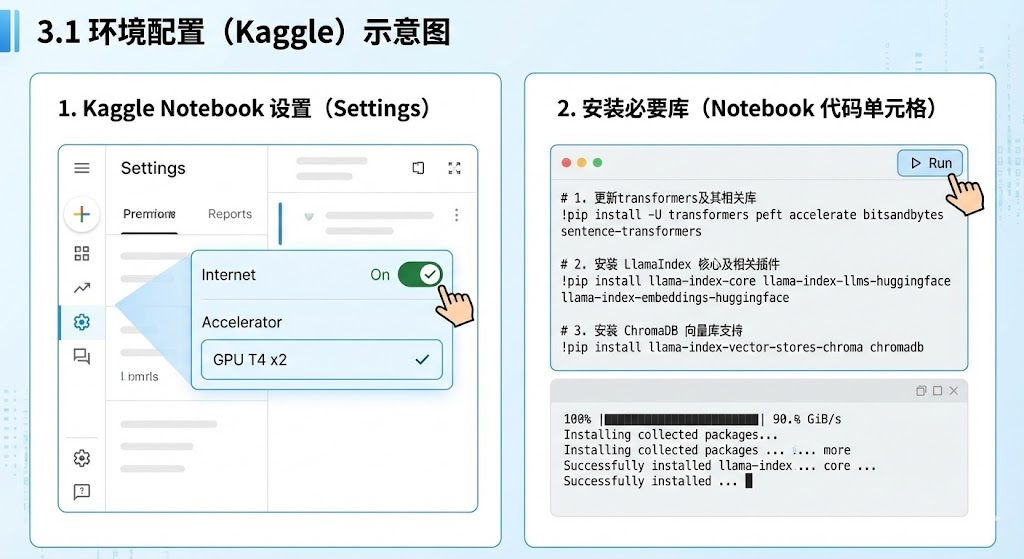
下载依赖库可能会需要一点时间,之后我看看能不能在kaggle上用uv去做包管理。
3.2 造数据:模拟企业内部文档
我们创建两份文档:一份是核心接口定义,一份是错误码说明。
import os
data_path = "/kaggle/working/data"
# 创建数据目录
os.makedirs(data_path, exist_ok=True)
# 文档 1: 核心 API 定义
api_doc = """
[机密] DeepStar 核心交易接口 v2.0
1. 创建订单 API: POST /api/v2/order/create
- 必填参数: 'user_id' (String), 'amount' (Decimal), 'token' (X-Auth-Token)
- 特殊逻辑: 如果 amount > 10000, 必须额外传递 'audit_code' (审计码)。
- 频率限制: 单用户每秒最多 5 次调用。
2. 查询余额 API: GET /api/v2/balance
- 缓存策略: 默认缓存 5 秒。传递 'no-cache=true' 可强制刷新。
"""
# 文档 2: 错误码字典
error_doc = """
[机密] DeepStar 全局错误码字典
- E1001: 签名验证失败。请检查 X-Auth-Token 是否过期。
- E2009: 余额不足。注意:冻结金额不计入可用余额。
- E5003: 审计风控拦截。大额交易未通过自动审计,请联系人工客服。
"""
with open(f"{/data_path}/api_specs.txt", "w") as f:
f.write(api_doc)
with open(f"/{data_path}/error_codes.txt", "w") as f:
f.write(error_doc)
print("[Success] 企业文档库已就绪!")
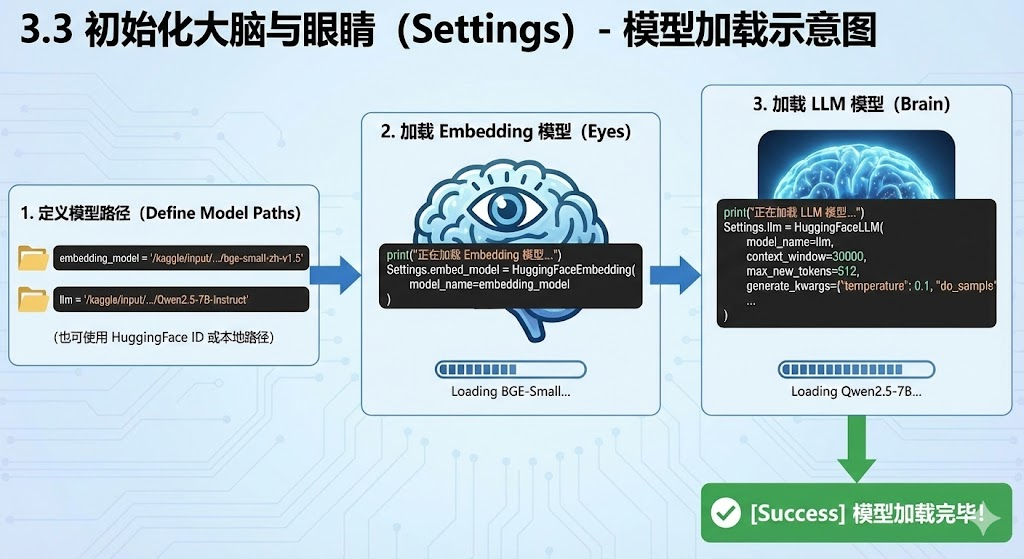
3.3 初始化大脑与眼睛 (Settings)
提前根据自己的情况来配置待会儿用的词嵌入模型 和推理模型。
embedding_model ="BAAI/bge-small-zh-v1.5"
llm = "Qwen/Qwen2.5-7B-Instruct"
# 在本地服务器,可以用modelscope下载下来, 把路径配置在这儿利用 Settings 全局配置,将默认的 OpenAI 替换为本地模型。
import torch
from llama_index.core import Settings
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 1. 设置 Embedding (眼睛)
# 使用 BGE-Small,显存占用极低,检索中文效果极佳
print("正在加载 Embedding 模型...")
Settings.embed_model = HuggingFaceEmbedding(
model_name=embedding_model
)
# 2. 设置 LLM (大脑)
# 使用 Qwen2.5-7B-Instruct
print("正在加载 LLM 模型...")
Settings.llm = HuggingFaceLLM(
model_name=llm,
tokenizer_name=llm,
context_window=30000,
max_new_tokens=512,
generate_kwargs={"temperature": 0.1, "do_sample": True}, # 技术文档要求严谨,温度调低
device_map="auto",
model_kwargs={"dtype": torch.float16, "trust_remote_code": True}
)
print("[Success] 模型加载完毕!")