前面我们学完了 Collection单列集合:List、Set。
今天正式进入Java集合最重要、面试问得最多、工作用得最频繁 的集合:Map双列集合。
如果说 List 是一排柜子 、Set 是独立储物柜 ; 那 Map 就是身份证 :一个编号(Key)对应一个人(Value)。
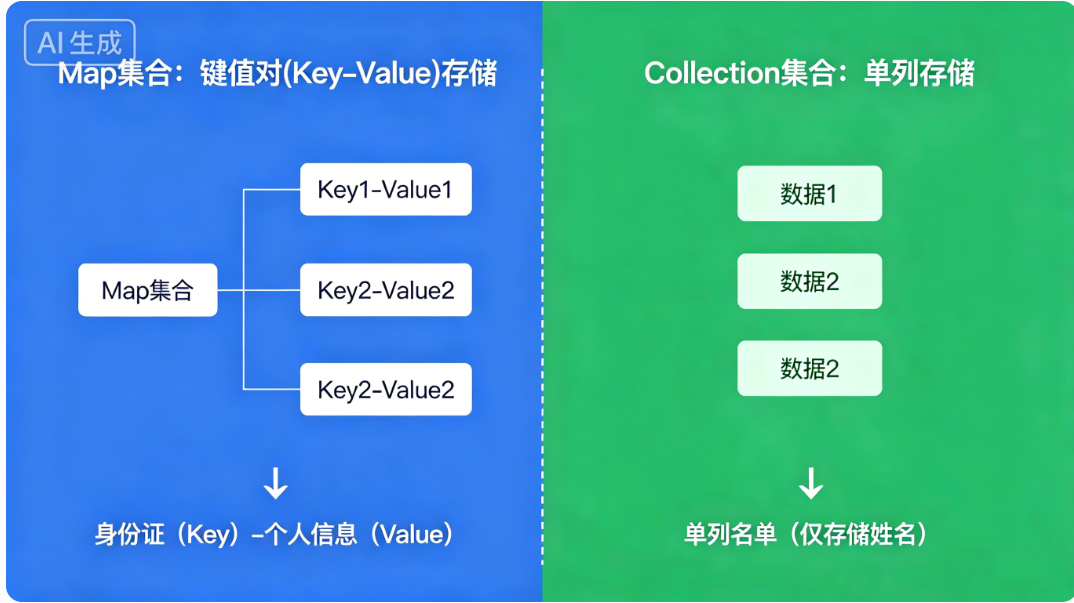
Map 全部以 键值对(Key-Value) 方式存储数据,这是和之前所有集合最大的区别。
本篇重点讲解 HashMap(重中之重),通俗拆解底层哈希表、哈希冲突、JDK1.7与JDK1.8区别、扩容机制、红黑树转换、遍历方式。全篇没有难懂源码,新手一次性看懂。
本篇核心学习目标:
-
理解Map集合特点、键值对存储结构
-
精通HashMap底层结构、存储流程
-
弄懂哈希冲突、怎么解决冲突
-
吃透JDK1.8优化(链表转红黑树)
-
掌握HashMap四种遍历方式
-
分清HashMap、TreeMap、HashTable区别
-
背熟高频Map面试题
一、Map集合是什么?能干什么?
1.1 Map存储结构
Map = 键(Key) + 值(Value)
生活举例:
-
手机号(Key) = 联系人姓名(Value)
-
学号(Key) = 学生信息(Value)
-
IP地址(Key) = 地理位置(Value)
1.2 Map核心特点(必背)
-
键(Key)唯一、不可重复
-
值(Value)可重复
-
一个键只能对应一个值
-
无序、无索引
-
键重复会覆盖旧值
1.3 Map常用实现类
| 实现类 | 底层结构 | 顺序 | 线程安全 | 使用场景 |
|---|---|---|---|---|
| HashMap | 哈希表 | 无序 | 不安全 | 日常开发首选 |
| TreeMap | 红黑树 | 按键排序 | 不安全 | 需要排序 |
| HashTable | 哈希表 | 无序 | 安全 | 老旧、已淘汰 |
二、Map常用方法(工作天天写)
2.1 通用基础方法
java
put(key,value) // 添加/覆盖元素
get(key) // 根据键取值
remove(key) // 根据键删除
containsKey(key) // 判断键是否存在
containsValue(value) // 判断值是否存在
size() // 获取键值对个数
clear() // 清空集合
keySet() // 获取所有键
values() // 获取所有值
entrySet() // 获取键值对对象2.2 代码基础演示
java
import java.util.HashMap;
import java.util.Map;
public class MapDemo {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
// 添加数据
map.put("001","张三");
map.put("002","李四");
map.put("001","张三三"); // 键重复,覆盖旧值
// 查询
System.out.println(map.get("001")); // 输出:张三三
// 删除
map.remove("002");
System.out.println(map);
}
}重点:键重复不会报错,直接覆盖旧数据!
三、HashMap底层原理(面试必考核心)
3.1 底层结构演变
JDK1.7:数组 + 单向链表
JDK1.8:数组 + 单向链表 + 红黑树(重点)
3.2 初始化参数(必须记住)
-
默认初始容量:16
-
加载因子:0.75
-
扩容阈值:16 * 0.75 = 12
-
链表转红黑树条件:链表长度>8 && 数组长度>=64
-
红黑树退化成链表:节点小于6
3.3 HashMap存储流程(通俗大白话)
-
首次put,创建长度为16的数组
-
通过key计算hash值,定位数组下标
-
下标位置为空:直接存入
-
下标位置有数据:发生哈希冲突
-
冲突后:挂在链表尾部(JDK1.8尾插法)
-
链表过长:长度超过8,数组达标64,转为红黑树
-
达到阈值12,自动扩容为原来2倍
3.4 什么是哈希冲突?
不同的Key,经过哈希算法算出相同数组下标,就叫哈希冲突。
HashMap三种解决冲突方式:
-
哈希算法(尽量分散)
-
链表法(冲突后挂链表)
-
红黑树(超长链表优化查询)
3.5 JDK1.8重大优化(面试高频)
-
由头插法 改为尾插法(避免循环链表死链)
-
新增红黑树,查询速度大幅提升
-
优化hash算法,减少冲突概率
四、HashMap四种遍历方式(工作必写)
4.1 方式一:遍历键(keySet)
java
for (String key : map.keySet()) {
System.out.println(key + "=" + map.get(key));
}4.2 方式二:遍历值(values)
java
for (String value : map.values()) {
System.out.println(value);
}4.3 方式三:键值对遍历(entrySet,推荐最快)
java
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey()+"="+entry.getValue());
}4.4 方式四:Lambda遍历(简洁)
java
map.forEach((k,v)-> System.out.println(k+"="+v));开发最优遍历:entrySet 效率最高,没有重复查询。
五、HashMap、HashTable、ConcurrentHashMap区别
这是面试必问三连,直接背下表:
| 集合 | 线程安全 | 效率 | key、value是否允许null | 底层 |
|---|---|---|---|---|
| HashMap | 不安全 | 最快 | key最多一个null,value任意null | 哈希表 |
| HashTable | 安全 | 慢 | 都不允许null | 哈希表 |
| ConcurrentHashMap | 安全 | 较快 | 不允许null | 分段锁哈希表 |
口诀:单线程HashMap,多线程ConcurrentHashMap,HashTable彻底不用。
六、新手高频易错坑(避坑指南)
-
HashMap键重复直接覆盖,不会报错
-
HashMap允许一个key为null,多个value为null
-
JDK1.8链表是尾插法,不是头插
-
链表转红黑树必须同时满足两个条件,不是到8就转
-
HashMap线程不安全:多线程put可能数据丢失
-
不要在循环中频繁keySet遍历取值,效率低,优先entrySet
七、本篇总结
本篇是集合框架最难、最重要的一篇,你必须牢牢记住:
-
Map是双列集合,键唯一、值重复、无序无索引
-
HashMap底层:数组+链表+红黑树
-
默认容量16、加载因子0.75、阈值12
-
哈希冲突:链表挂载,过长转红黑树
-
四种遍历,优先entrySet
-
单线程HashMap,多线程ConcurrentHashMap