电商物流网络包裹应急调运与结构优化问题
电商物流网络由物流场地(接货仓、分拣中心、营业部等)和物流场地之间的运输线路组成,如图1所示。受节假日和"双十一"、"618"等促销活动的影响,电商用户的下单量会发生显著波动,而疫情、地震等突发事件导致物流场地临时或永久停用时,其处理的包裹将会紧急分流到其他物流场地,这些因素均会影响到各条线路运输的包裹数量,以及各个物流场地处理的包裹数量。
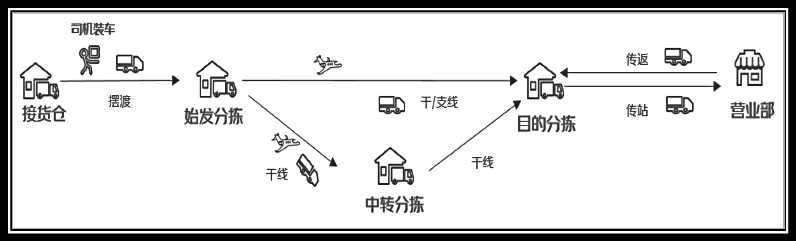
图1 电商物流网络示意图
如果能预测各物流场地及线路的包裹数量(以下简称货量),管理者将可以提前安排运输、分拣等计划,从而降低运营成本,提高运营效率。特别地,在某些场地临时或永久停用时,基于预测结果和各个物流场地的处理能力及线路的运输能力,设计物流网络调整方案,将会大大降低物流场地停用对物流网络的影响,保障物流网络的正常运行。
附件1 给出了某物流网络在2021-01-01 至2022-12-31 期间每天不同物流场地之间流转的货量数据,该物流网络有 81 个物流场地,1049 条线路。其中线路是有方向的,比如线路 DC1→DC2 和线路 DC2→DC1 被认为是两条线路。假设每个物流场地的处理能力和每条线路的运输能力上限均为其历史货量最大值。
基于以上背景,请完成以下问题:
问题1:建立线路货量的预测模型,对 2023-01-01 至 2023-01-31 期间每条线路每天的货量进行预测,并在提交的论文中给出线路 DC14→DC10、 DC20→DC35、DC25→DC62 的预测结果。
问题2:如果物流场地 DC5 于 2023-01-01 开始关停,请在问题 1 的预测基础上,建立数学模型,将 DC5 相关线路的货量分配到其他线路使所有包裹尽可能正常流转,并使得DC5关停前后货量发生变化的线路尽可能少,且保持各条线路的工作负荷尽可能均衡。如果存在部分日期部分货量没有正常流转,你们的分流方案还应使得 2023-01-01 至 2023-01-31 期间未能正常流转的包裹日累计总量尽可能少。正常流转时,请给出因 DC5 关停导致货量发生变化的线路数及网络负荷情况;不能正常流转时,请给出因 DC5关停导致货量发生变化的线路数、不能正常流转的货量及网络的负荷情况。
问题3:在问题2中,如果被关停的物流场地为 DC9,同时允许对物流网络结构进行动态调整(每日均可调整),调整措施为关闭或新开线路,不包含新增物流场地,假设新开线路的运输能力的上限为已有线路运输能力的最大值。请将 DC9 相关线路的货量分配到其他线路,使所有包裹尽可能正常流转,并使得 DC9 关停前后货量发生变化的线路数尽可能少,且保持各条线路的工作负荷尽可能均衡。如果存在部分日期没有满足要求的流转方案,你们的分流方案还应使得 2023-01-01 至 2023-01-31 期间未能正常流转的包裹日累计总量尽可能少。正常流转时,请给出因 DC9 关停导致货量发生变化的线路数及网络负荷情况;不能正常流转时,请给出因 DC9 关停导致货量发生变化的线路数、不能正常流转的货量及网络的负荷情况;同时请给出每天的线路增减情况。
问题4:根据附件1,请对该网络的不同物流场地及线路的重要性进行评价;为了改善网络性能,如果打算新增物流场地及线路,结合问题1的预测结果,探讨分析新增物流场地应与哪几个已有物流场地之间新增线路,新增物流场地的处理能力及新增线路的运输能力应如何设置?考虑到预测结果的随机性,请进一步探讨你们所建网络的鲁棒性。
附件1:物流网络历史货量数据![]() https://download.csdn.net/download/Liu_Xin233/92784631?spm=1001.2014.3001.5503
https://download.csdn.net/download/Liu_Xin233/92784631?spm=1001.2014.3001.5503
基于货量预测与调度优化的电商物流分析模型
摘 要
线路货量预测模型是一种基于历史数据和相关因素,预测未来一段时间内线路货量变化趋势和数量的模型。随着物流网络结构趋于复杂,需要处理的数据量显著增大,在运营过程中受到多种因素的影响,如促销活动、节假日等,可能会导致产生拥堵、延误等问题。因此建立可靠的物流货量预测模型对于保障物流网络的正常运行具有重要意义。
针对问题一,首先对给定的三条线路的历史货量数据进行可视化分析与预处理,获取运输货量的时间序列数据集,考虑数据集的长期趋势预测和短期波动预测,构建ARIMA模型和LSTM模型并进行组合,使用均方误差和倒数法组合进行模型赋权(ARIMA权重为0.32,LSTM权重为0.68),然后分别使用三条线路的时间序列数据进行模型训练后,预测2023年1月1日至2023年1月31日中每日货量的结果。
针对问题二,该问题属于多目标整数规划问题,建模过程采用NSGA-II算法,其选择、交叉、变异等操作与基本遗传算法一致,但在选择操作之前进行了非支配排序,增大更优解被保留的概率。考虑DC5关停前后货量发生变化的线路需要尽可能少,在目标函数中将线路货量变化量转化为01变量,考虑均衡性时,引入线路实际货量与其平均货量之比值的方差和,确定约束条件后基于NSGA-II算法进行问题求解,得出分流方案中的变化线路数为38,其负荷率的标准差为0.2397,未能正常流转的货运量为58924。
针对问题三,该问题属于动态多目标整数规划(DMOIP)问题,结合问题二的目标函数、约束条件等,额外考虑分析处理的物流场地为所有物流场地,而不是基于历史数据中出现的场地,再重新设置新开线路的最大运载能力即可,得出分流方案中的变化线路数为95,其负荷率的标准差为0.2895,未能正常流转的货运量为11160。
针对问题四,选取基于熵权法的Topsis对不同物流场地及线路进行重要性评价,其中在说明物流场地的重要性时选定的指标有发送货量总和、接收货量总和等;说明线路的重要性时选定的指标有货量上限、出现天数等。分析得出排名前四的物流场地为DC10、DC14、DC4和DC8,排名前四的线路为DC14→DC8、DC14→DC9、DC36→DC4和DC23→DC4。在考虑新增物流场地以改善物流网络性能时,应当优先对这些物流场地及对应的线路进行优化,考虑新增物流场地的处理能力及新增线路的运输能力的设置原则是最大值相近原则。为了验证模型的鲁棒性,通过引入不同数据扰动,得出预测曲线基本没有过大的波动,模型的预测区间均落在给定的置信区间内,即模型的鲁棒性较好。
1.问题重述
1.1 问题背景
20世纪90年代,随着互联网的兴起和电子商务的快速发展,越来越多的消费者选择通过互联网购买商品。这种新型的购物方式对物流产业提出了新的要求,物流企业需要为电商交易提供更加高效、便捷和低成本的物流服务。而随着电商交易规模的不断扩大,电商物流网络不断发展和完善,各大电商企业纷纷建立自己的物流中心和仓库,以提高货物的集中度和配送效率。
线路货量预测模型的主要功能是根据历史数据和相关因素,预测未来一段时间内线路货量的变化趋势和数量,以便制定合理的运营计划和资源调配方案。常用的实现方法包括时间序列分析、回归分析和机器学习等。而随着电商物流的不断发展和扩大,物流网络结构趋于复杂,需要处理的数据量也有着显著增大。这对线路货量预测模型的设计与优化带来了极大的挑战。与此同时,电商物流网络在运营过程中受到多种因素的影响。例如,电商用户的下单量会随着促销活动、节假日等因素发生显著波动,从而导致物流网络的负荷不均衡,进而产生拥堵、延误等问题。此外还可能出现不可预知的突发事件,如疫情、地震等,也会导致物流场地的临时或永久停用,进而影响到物流网络的运营。因此,建立可靠的物流货量预测模型,对于保障物流网络的正常运行具有重要意义。
1.2 问题提出
现有一个物流网络包含81个物流场地,1049条线路,其中线路是有方向的,如线路DC1→DC2和线路DC2→DC1被认为是两条线路。给出该物流网络2021年1月1日到2022年12月31日的历史货量数据,并假设每个物流场地的处理能力和每条线路的运输能力上限均为其历史货量最大值。
问题1:线路货量预测模型
建立线路货量的预测模型,根据该物流网络2021年1月1日到2022年12月31日的历史货量数据,预测2023年1月1日至2023年1月31日中线路每天的货量,包括DC14→DC10、DC20→DC35、DC25→DC62的预测结果。
问题2:物流场地关停与货量分配
在问题1的预测基础上,假设物流场地DC5于2023年1月1日开始关停,通过建立数学模型将DC5相关线路的货量分配到其他线路,使所有包裹尽可能地正常流转,且保持各条线路的工作负荷尽可能均衡。如果存在部分日期部分货量没有正常流转,分流方案还应使得2023年1月未正常流转包裹的日累计总量尽可能少。给出因DC5关停导致货量发生变化的线路数及网络负荷情况。
问题3:动态调整物流网络结构
在问题2的基础上,假设被关停的物流场地为DC9,同时允许对物流网络结构进行动态调整(每日均可调整),调整措施包括关闭或新开线路,但不包括新增物流场地。将DC9相关线路的货量分配到其他线路,使所有包裹尽可能正常流转,且保持各条线路的工作负荷尽可能均衡。如果存在部分日期没有满足要求的流转方案,分流方案还应使得2023年1月未能正常流转包裹的日累计总量尽可能少。给出因DC9关停导致货量发生变化的线路数及网络负荷情况,以及每天的线路增减情况。
问题4:物流网络重要性评价与改进
对该物流网络的不同物流场地及线路的重要性进行评价,并探讨如何通过新增物流场地及线路来改善网络性能,包括新增物流场地应及在哪些已有物流场地之间新增线路,新增物流场地的处理能力及新增线路的运输能力应如何设置。同时考虑预测结果的随机性,进一步探讨该网络的鲁棒性。
2.问题分析
2.1 问题1分析
分析附件给出的数据,其中包含2021年1月1日到2022年12月31日中不同场地1和场地2按时间顺序给出的物量,问题要求给出DC14→DC10、DC20→DC35、DC25→DC62共三条线路在2023年1月的预测值,因此可以考虑采用时间序列分析法来建立线路货量预测模型,如线性时间序列模型ARIMA等或非线性时间序列模型GARCH、LSTM等。对上述三条线路的时间序列数据进行可视化处理,观察到原始数据集中存在与大多数时间序列数据相差较大的数据,因此首先需要对历史货量数据进行清洗和预处理,分析特殊时间点对应的特殊事件。预测过程中需要对模型进行调参和优化,以获得更好的预测效果。最后利用构建完成的预测模型对指定时间段内每条线路每天的货量进行预测,并对预测结果进行统计、可视化和分析。
2.2 问题2分析
物流场地DC5关停于2023年1月1日,需将DC5相关线路货量分配到其他线路,使所有包裹尽可能地正常流转。该问题属于多目标整数线性规划问题,可以考虑构建合适的目标函数使得关停后货量产生变化的货量尽可能小,并且考虑部分日期部分货量可能没有正常流转的情况下,使得未正常流转包裹的日累计总量尽可能少,同时为了保证负荷均衡,需要设置合适的约束条件,在合理范围内分析极差等数据衡量负荷均衡度。
2.3 问题3分析
根据问题描述,整体方案设计与问题2相似,新增条件为允许每日对物流网络结构进行动态调整(包括关闭或新开线路,不包括新增物流场地)。同样地,首先可以构建合适的目标函数、决策变量和约束条件等,考虑到线路的运输能力存在上限,根据要求为动态调整设计限制条件,再通过选定启发式算法进行问题求解,求出DC9关停导致货量发生变化的线路数及网络负荷情况,以及每天的线路增减情况。
2.4 问题4分析
首先,问题要求对该物流网络的不同物流场地及线路的重要性进行评价,在之前的问题分析中得到了时间序列数据的可视化形式,将数据与图表结合,考虑不同物流场地处理的货量、不同线路在不同时间下的运载货量的浮动情况以及不同场地和不同线路在2021年1月1日至2022年12月31日的运载频次,通常可考虑采用Topsis、层次分析法或主成分分析等进行分析。
然后,问题要求探讨如何通过新增物流场地及线路来改善网络性能,分析可知,当线路上货运量呈现持续上升趋势时新增物流场地和线路时更为适宜,同时,运输货量变化较大的情况下,新增物流场地及线路可能也是一种有效的解决方案来改善网络性能。
其次,问题要求对新增物流场地的处理能力及新增线路的运输能力进行设置,基本的思路应当是保证新增部分应与已有部分的最大运载能力相近,以保证货量能满足分配。
最后,问题要求进一步探讨该网络的鲁棒性,可以考虑引入某些数据扰动来测试模型结果的输出,进而分析模型的鲁棒性。
3.模型假设
假设1:所有货物在正常情况下都能按时到达终点,即没有延迟或丢失的情况;
假设2:在分流方案中,新开或关闭线路的时间很短,即不影响整体的运作效率;
假设3:每个物流场地的货物流入量与货物流出量相等,即不存在货物滞留现象;
假设4:场地A→场地B是直接可达的,即该线路中不存在其他中间场地。
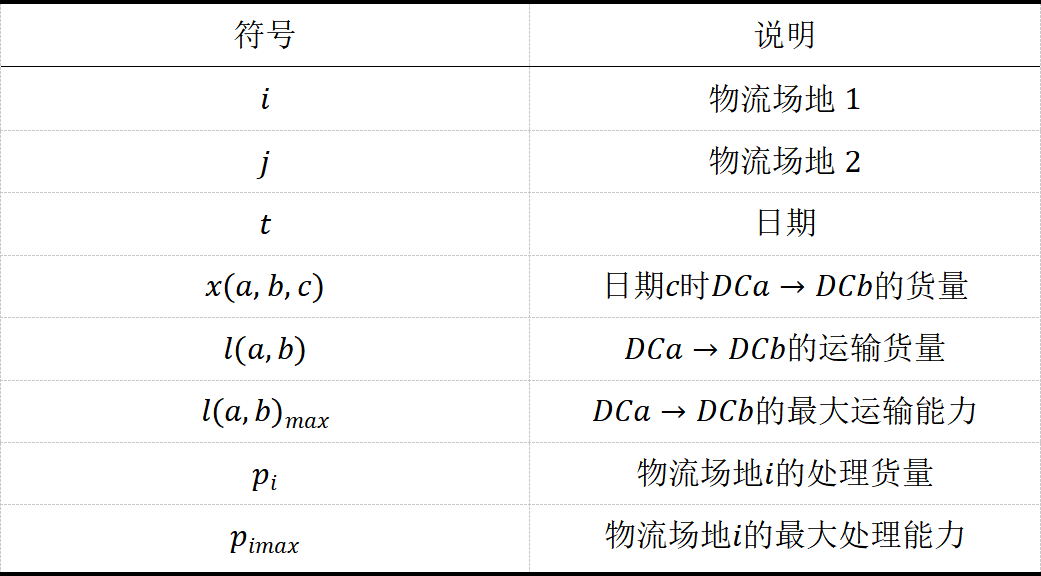
4.符号说明
5、问题一模型的建立与求解
5.1 数据分析与预处理
首先对所有物流场地之间流转的货量进行可视化处理,初步分析2021年至2022年逐月总货量的变化趋势,如图5.1所示(横坐标表示月份序号,纵坐标表示货量),按月流转的总货量整体上呈现递增的趋势。
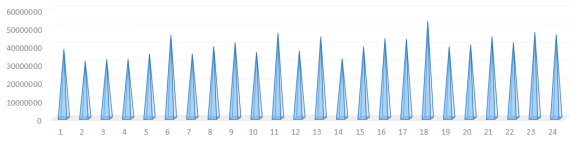
图5.1 按月流转的总货量
对问题待求解的DC14→DC10、DC20→DC35、DC25→DC62三条线路从数据集中筛选出来,通过可视化处理后,给出三条线路的历史货量,如图5.2所示:
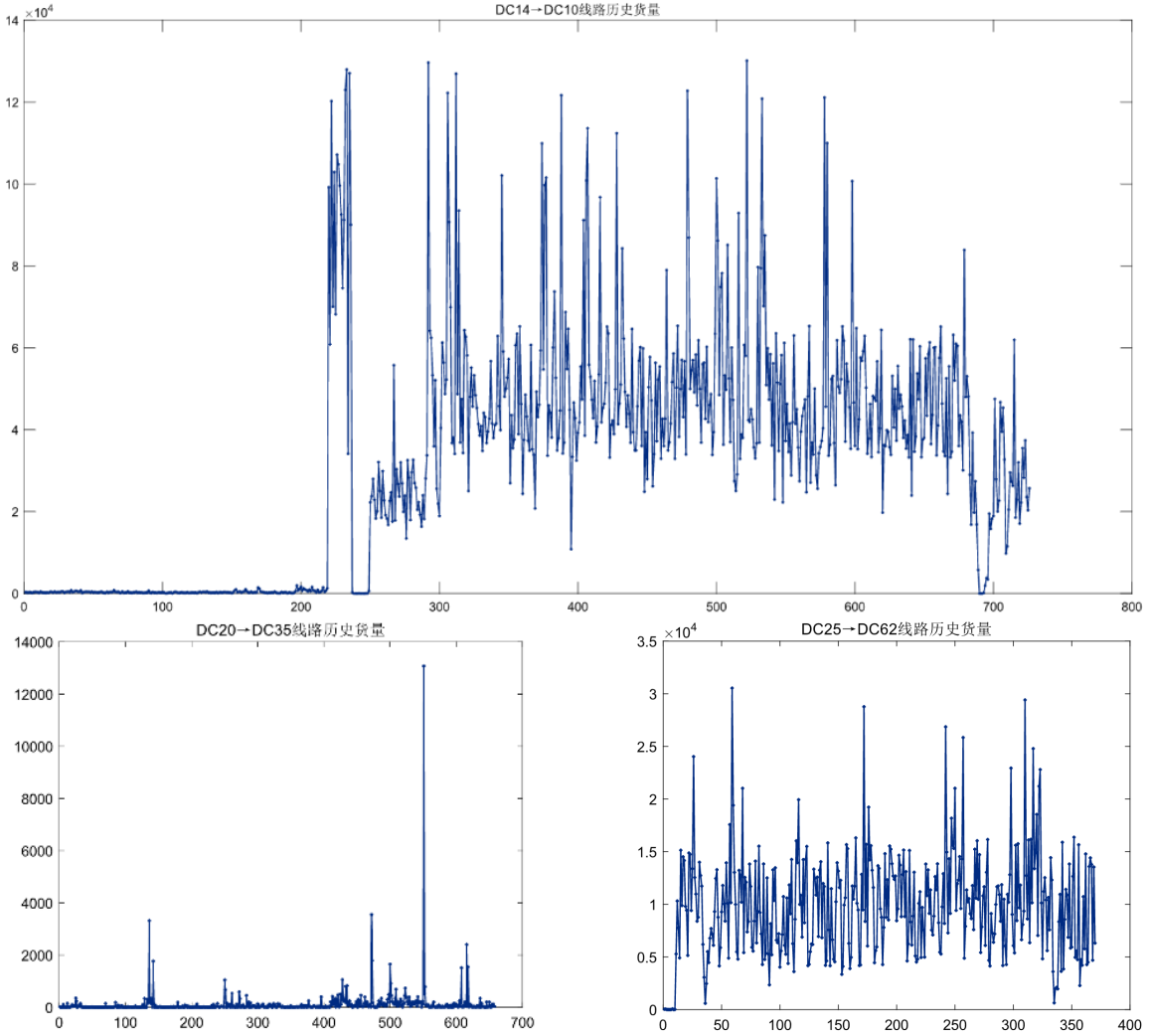
图5.2 三条线路的历史货量
5.2 构建ARIMA模型
ARIMA模型是一种常用的时间序列预测分析方法之一,它是一类在时间序列数据中捕获一组不同标准时间结构的模型。根据时间序列的性质,可以通过自相关函数(ACF)和偏自相关函数(PACF)来选择合适的阶数。ARIMA模型的预测依赖于历史观测值和模型参数,通过向前推导和预测误差的累计和来计算未来时间点的预测值。
以下给出ARIMA建模过程涉及的参数,如表5.1所示:
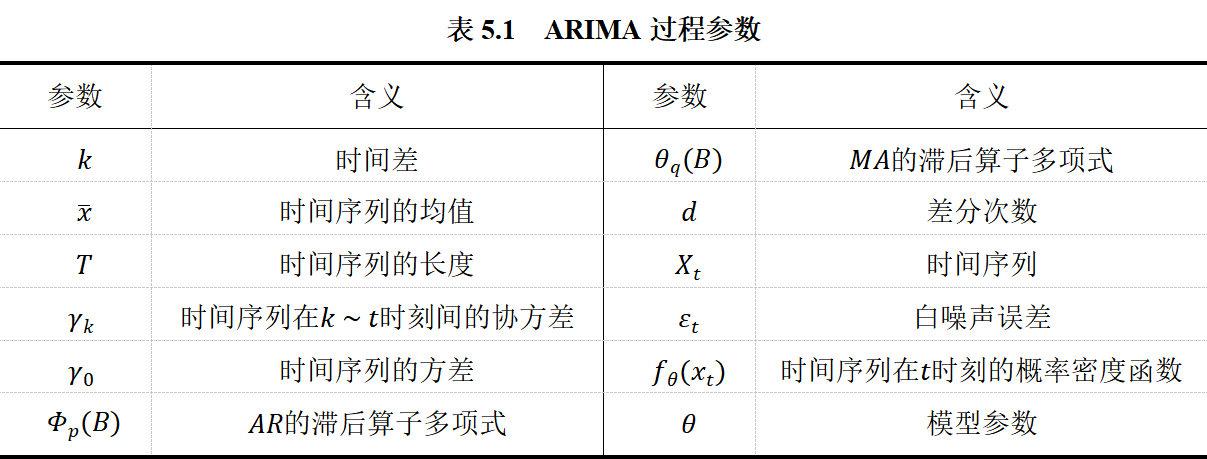
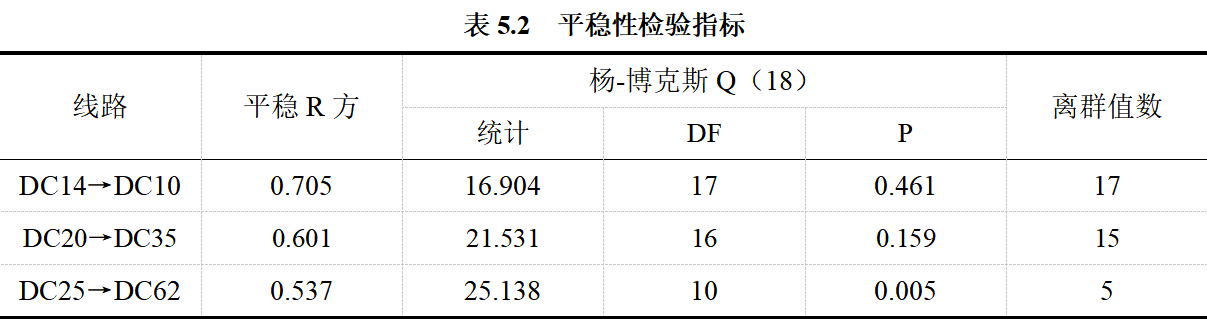
对时间序列数据进行平稳性检验,结果如表5.2所示:
对ARIMA模型的残差进行白噪声检验,结果如图5.3所示:
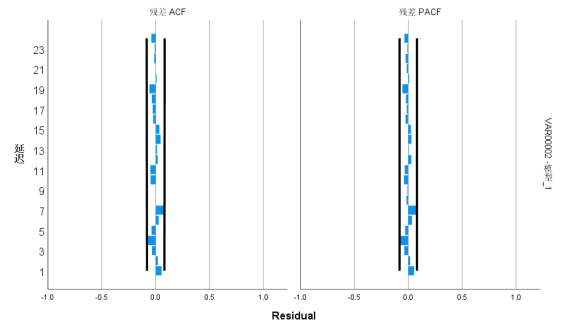
图5.3 白噪声残差检验
测试模型的拟合情况是否位于置信区间内,结果如图5.4、图5.5和图5.6所示,表明模型的拟合效果较好。
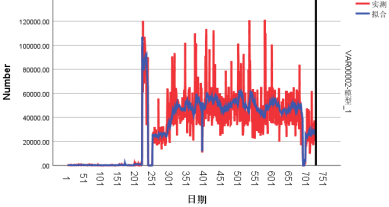
图5.4 ARIMA模型拟合效果(DC14→DC10)
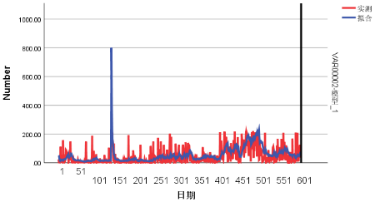
图5.5 ARIMA模型拟合效果(DC 20 →DC 35 )
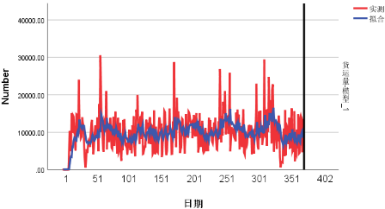
图5.6 ARIMA模型拟合效果(DC 25 →DC 62 )
5.3 构建LSTM模型
LSTM(Long Short-Term Memory)主要用于处理长序列数据,如图5.7所示。相比于传统的RNN来说,LSTM具有更好的长期记忆能力,其主要利用了门控机制,用于控制信息的流动和保存:遗忘门用于控制之前的信息及信息的哪些部分是否需要被遗忘;输入门用于控制输入信息及信息的哪些部分流入LSTM单元;输出门用于控制输出信息及当前时间步骤的隐藏状态中哪些部分流出到下一层。
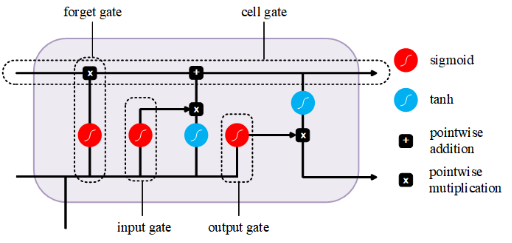
图5.7 LSTM的组成
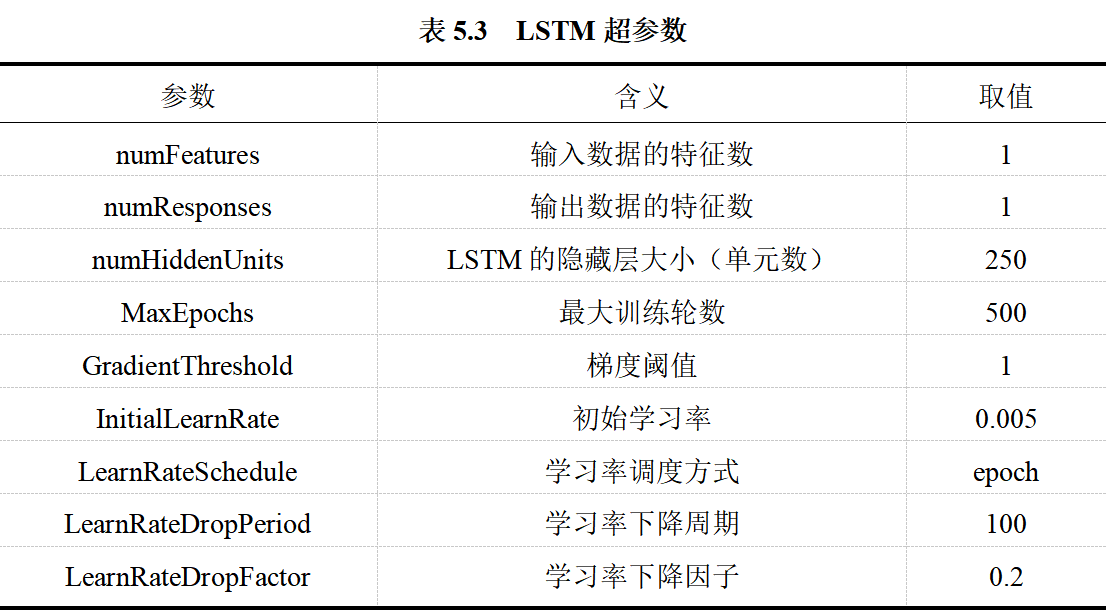
本模型中LSTM的超参数说明如表5.3所示:
5.4 模型改进------ARIMA+LSTM模型组合优化
ARIMA和LSTM在时间序列预测上各有优点和局限性: ARIMA模型通常只考虑线性关系,在非线性时间序列的处理上效果不是很好,适用于对时间序列的趋势、周期性等因素进行建模预测,而LSTM模型在时间序列中蕴含的长期依赖关系和非线性关系的处理上更有优势。考虑到问题求解给出的数据的线性相关性较低,同时具有一定的周期性,因此可以将ARIMA与LSTM结合起来,提高时间序列预测的准确性和稳定性。
这里考虑使用均方误差和倒数法组合进行模型赋权,混合模型的计算公式如下:

其中为ARIMA模型预测的均方误差,
为LSTM模型预测的均方误差,
为ARIMA模型的预测值,
为LSTM模型的预测值。
5.5 模型训练与求解
导入DC14→DC10、DC20→DC35、DC25→DC62的历史货量数据,首先对模型进行训练,训练过程如图5.8、图5.9、图5.10所示,观察到训练结束后的Loss值都趋近于0,说明模型的预测值与真实值之间的差异很小,即模型的训练效果较好。
图5.8 DC14→DC10 模型训练
图5.9 DC20→DC35 模型训练
图5.10 DC25→DC62 模型训练
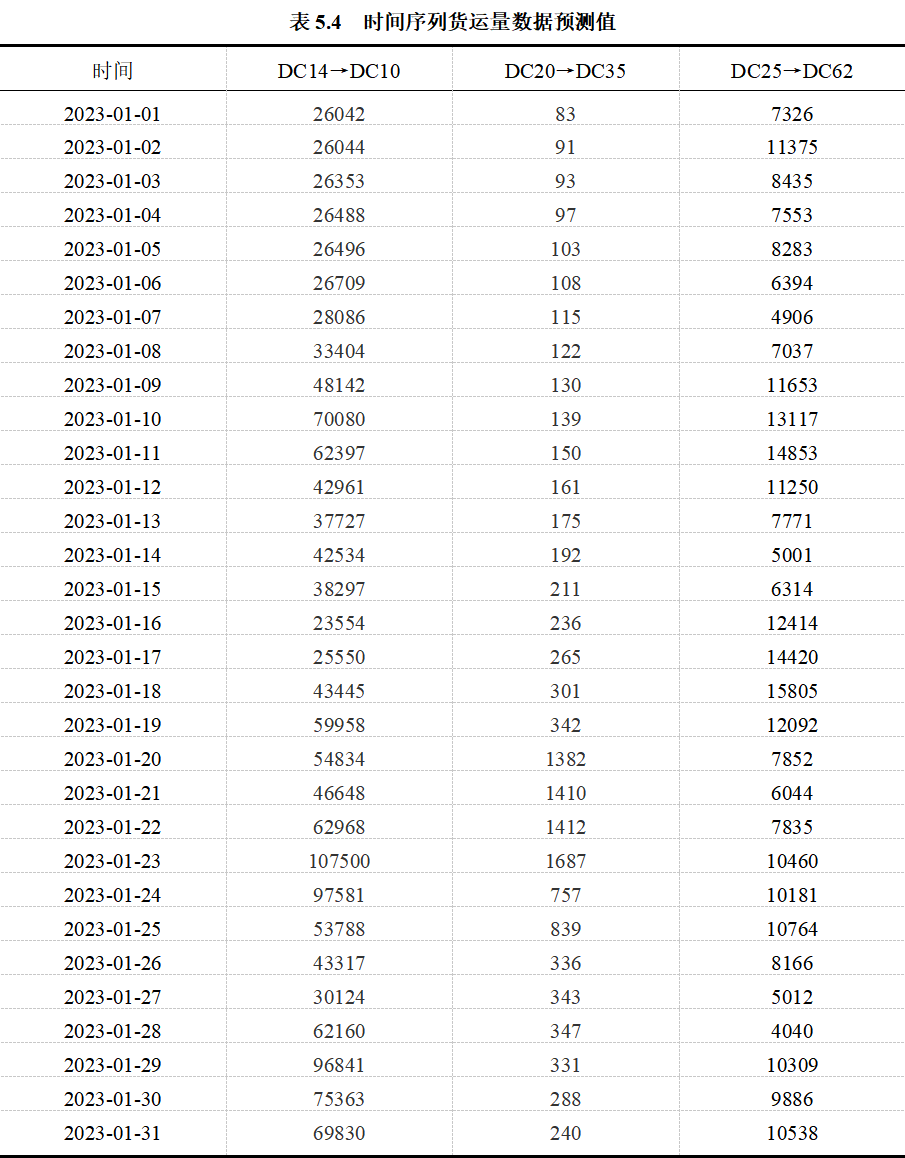
模型求解后得出的ARIMA的权重和LSTM的权重分别为0.32和0.68,最终得到的2023年1月1日至2023年1月31日的货量预测结果如图5.11、图5.12、图5.13及表5.4所示:
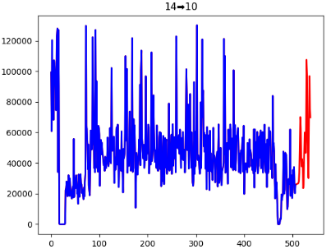
图5.11 模型预测拟合曲线
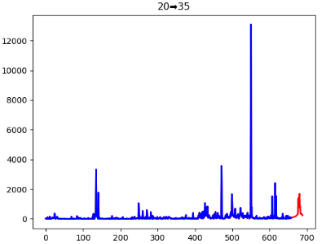
图5.12 模型预测拟合曲线
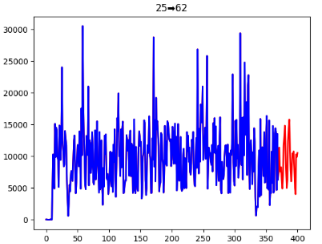
图5.13 模型预测拟合曲线
6、问题二模型的建立与求解
6.1 问题与数据分析
物流场地DC5关停于2023年1月1日,需将DC5相关线路货量分配到其他线路,使所有包裹尽可能地正常流转,该问题属于多目标整数规划(MOIP)问题,分析在整个物流网络上,存在一定货量运入和运出物流场地DC5,将该部分货量进行可视化处理,如图6.1所示:
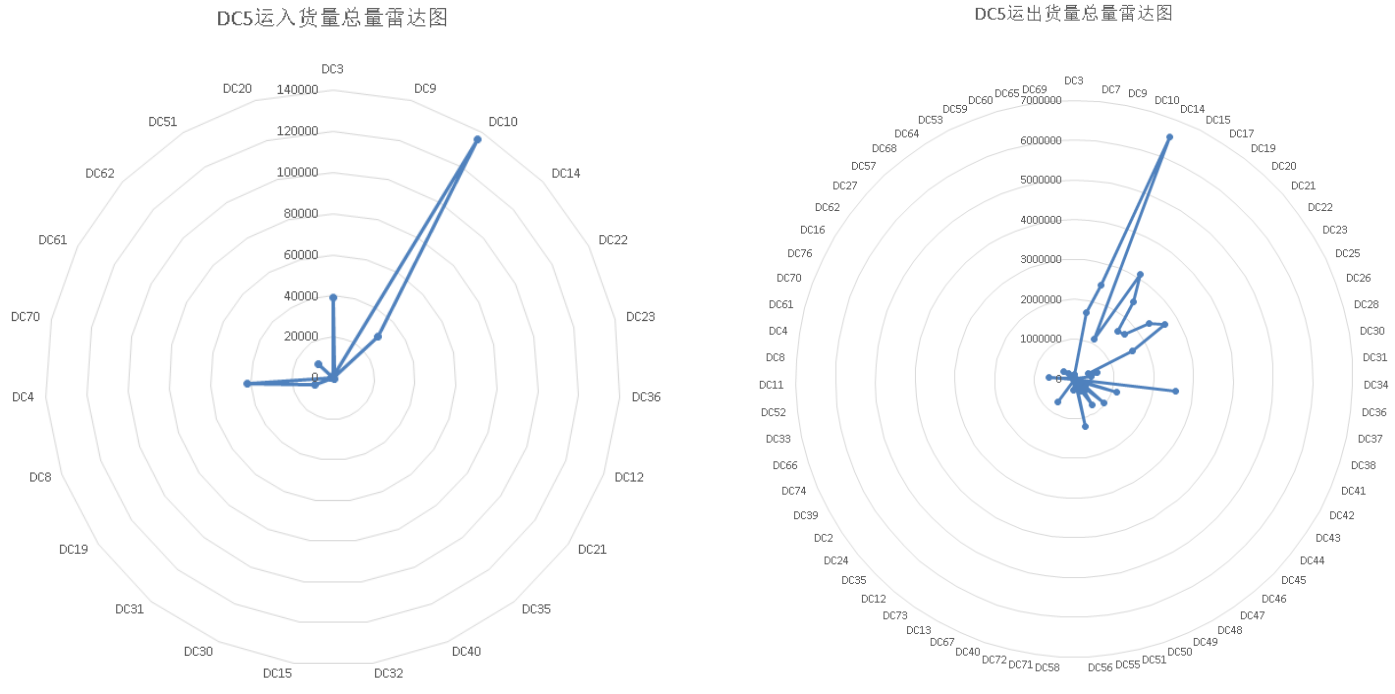
图6.1 运入和运出DC5的总货量雷达图
考虑当DC5关停时,如果与之直接可达的物流场地的当前运输货量低于或远低于其最大处理能力,并且与这些场地直接可达的其他场地的物流场地及线路的最大运载能力高于或远高于当前运输货量的情况下,受到的影响就会相对较小,甚至可能不会受到影响;而如果与之直接可达的物流场地的当前运输货量比较接近或已经达到其最大处理能力,并且与之直接可达的其他场地及线路的最大运载能力不高于当前运输货量的情况下,甚至不存在直接可达的物流场地时,受到的影响就会相对较大,甚至可能导致线路工作满负荷或超负荷。
6.2 基于NSGA-II算法的原理分析
NSGA算法是以遗传算法为基础并基于Pareto最优概念得到的。NSGA算法在进行选择操作之前对个体进行了非支配排序,增大了优秀个体被保留的概率,而选择、交叉、变异等操作与基本遗传算法无异,而NSGA算法比传统的多目标遗传算法效果更好。
针对NSGA算法存在的不足,NSGA-II进行了一系列的优化改进:通过使用快速非支配排序法,大大降低了算法的时间复杂度;通过应用精英策略,将父代个体与子代个体合并后进行非支配排序,使得搜索空间变大,生成下一代父代种群时按顺序将优先级较高的个体选入,并在同级个体中采用拥挤度进行选择,保证了优秀个体能够有更大的概率被保留;用求解拥挤距离的方法代替了需指定共享半径的适应度共享策略,并作为在同级个体中选择优秀个体的标准,保证了种群中个体的多样性,有利于个体能够在整个区间内进行选择、交叉和变异。
(1)选择、交叉与变异
选择操作模仿了自然界中的"优胜劣汰"法则,当个体适应度高时,其有更大概率被遗传到下一代,反之则概率较小。进行选择操作的方法有许多,比如轮盘赌选择、排序选择、最优个体保存、随机联赛选择等。
交叉操作模拟自然界中染色体的交叉换位现象,用于生成新个体,决定了算法的全局搜索能力。标准的NSGA-II算法使用模拟二进制交叉算子,计算公式如下:
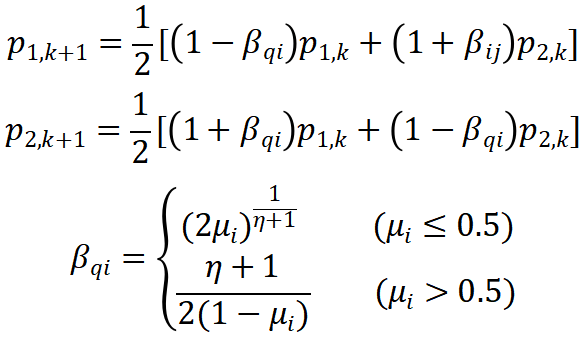
变异操作是模拟生物的基因变异,与交叉操作的目的一样,都能用于产生新个体。标准NSGA-II算法的变异算子为多项式变异算子,计算公式如下:
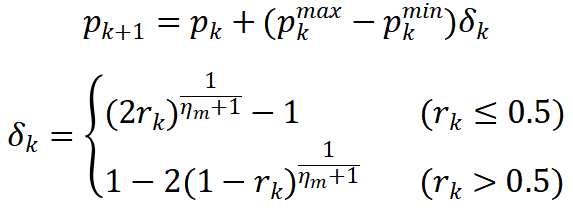
(2)快速非支配排序
快速非支配排序的基本思想为:对每个解p,计算其支配集合Sp和支配次数np,然后将支配次数为0的解标记为第一层,将其从种群中移除。接着,对第一层解的支配集合进行更新,将支配次数减1。重复执行这个过程,直到所有解都被标记为某一层。这样就可以将种群中的解分成不同的Pareto前沿,如图6.2所示:
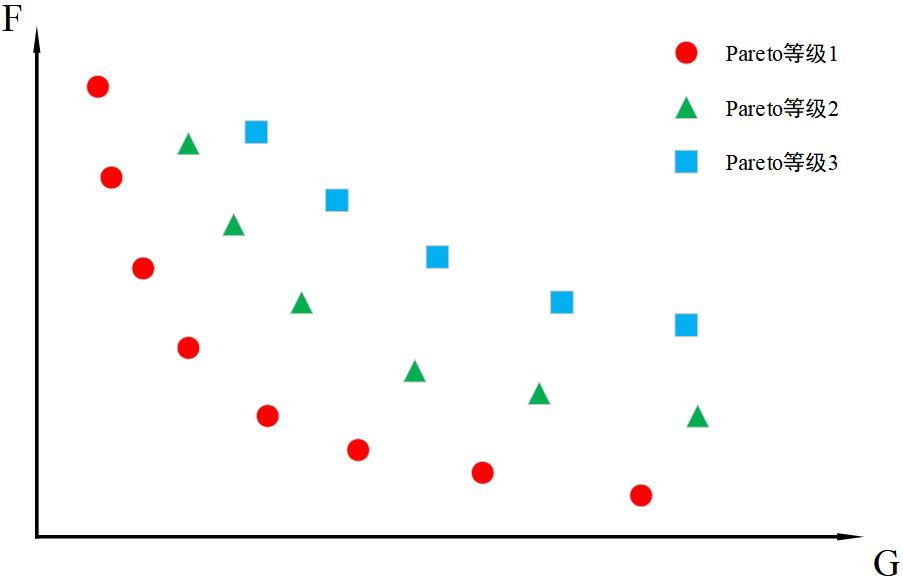
图6.2 Pareto前沿 曲线
(3)拥挤距离计算
在NSGA算法中需要指定共享半径,这对经验要求较高,为了克服这一缺点,NSGA-II引用了拥挤度的概念,即表示空间中个体的密度值,直观上可以用个体周围不包括其他个体的长方形表示,如图6.3所示:
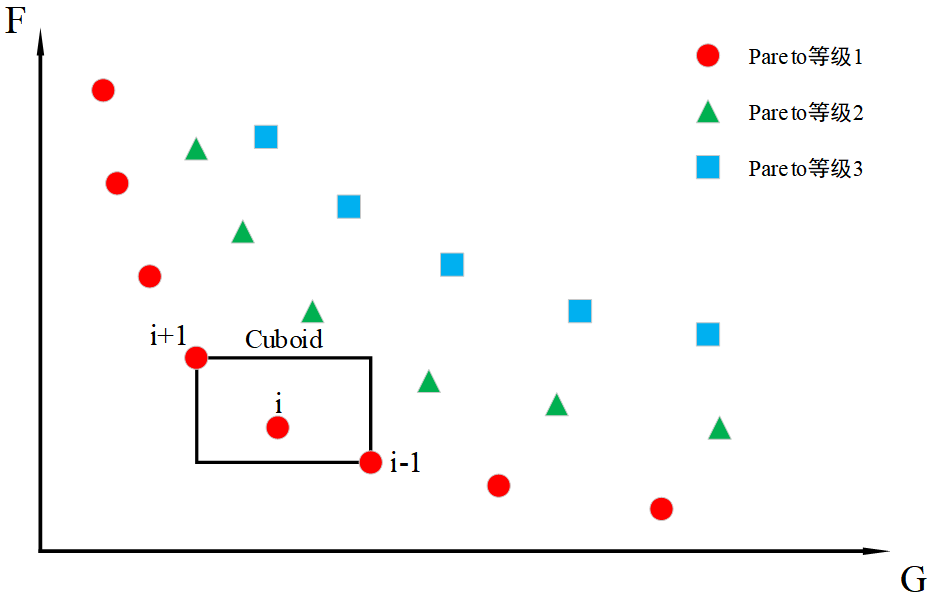
图6.3 拥挤距离计算
(4)精英策略
NSGA-II算法引入精英策略,达到保留优秀个体淘汰劣等个体的目的。通过将父代与子代个体混合形成新的群体,扩大产生下一代个体时的筛选范围,过程如图6.4所示:
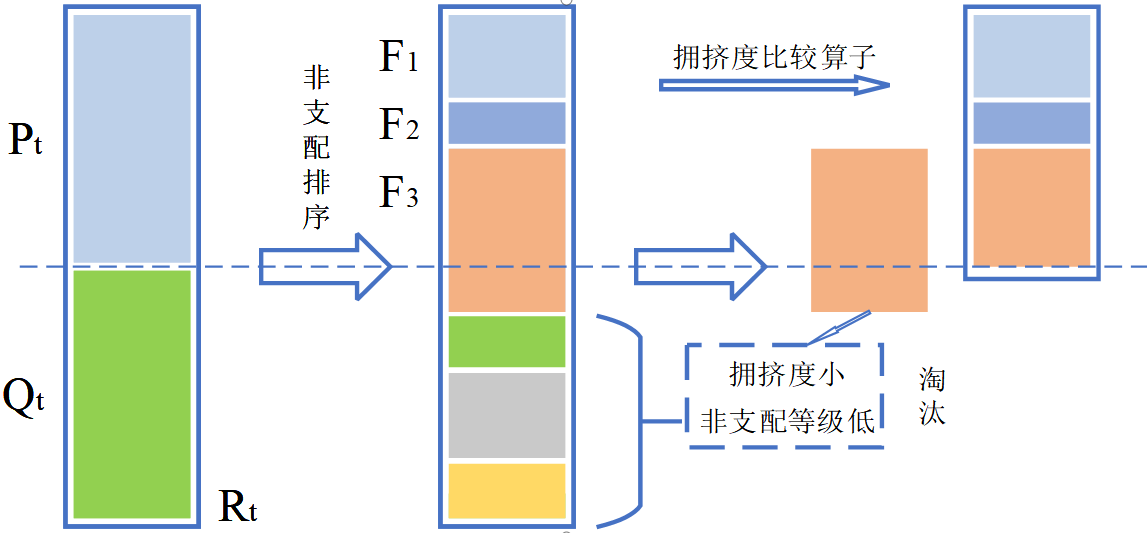
图6.4 精英策略执行过程
6.3 基于NSGA-II算法的问题求解
基于NSGA-II算法的求解过程如图6.5所示:
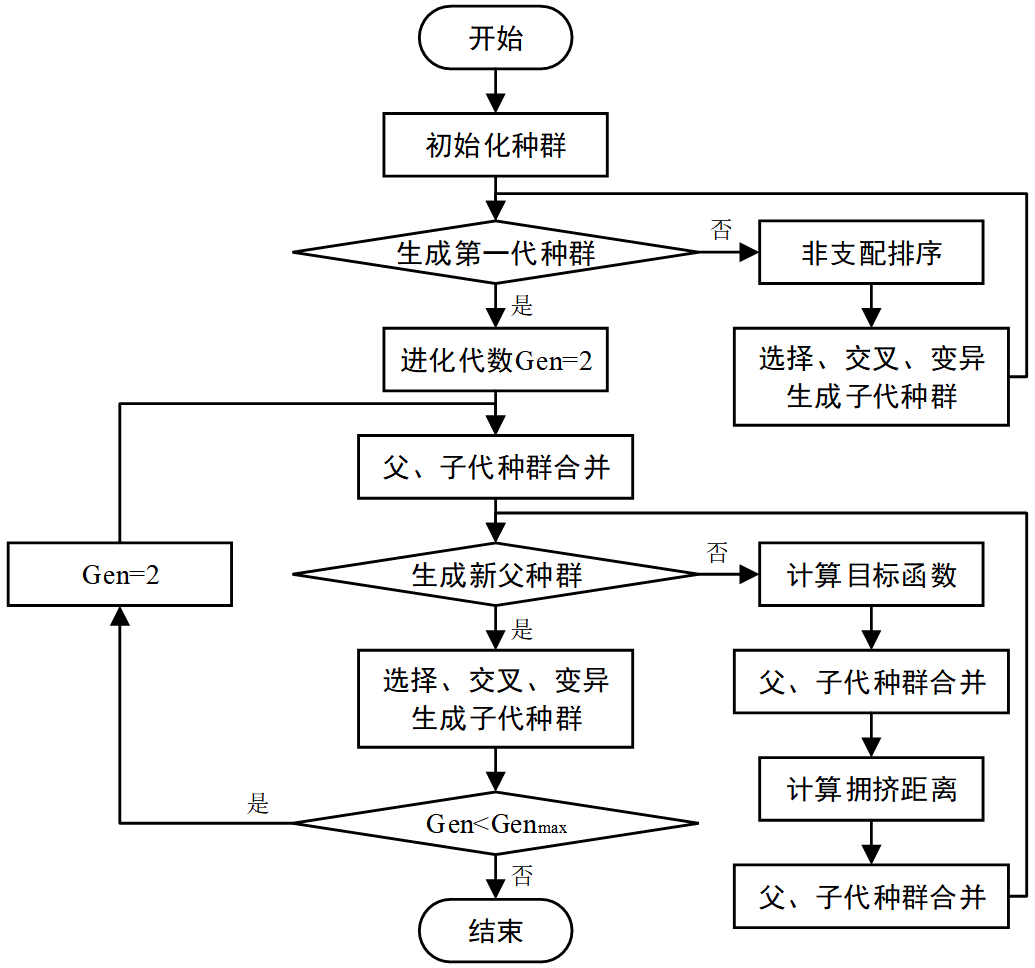
图6.5 基于 NSGA-II算法 的求解流程
设定MOIP约束条件如下:
(1)每个时间段每个线路的货量为非负整数
(2)流入每个物流场地的货量等于流出每个物流场地的货量
(3)各条线路的运输能力不大于最大运输能力
(4)各个物流场地的处理能力不大于最大运输能力
(5)将DC5相关线路货量分配到其他线路,使所有包裹尽可能地正常流转的同时,考虑部分日期部分货量可能没有正常流转的情况下,使得未正常流转包裹的日累计总量尽可能少。
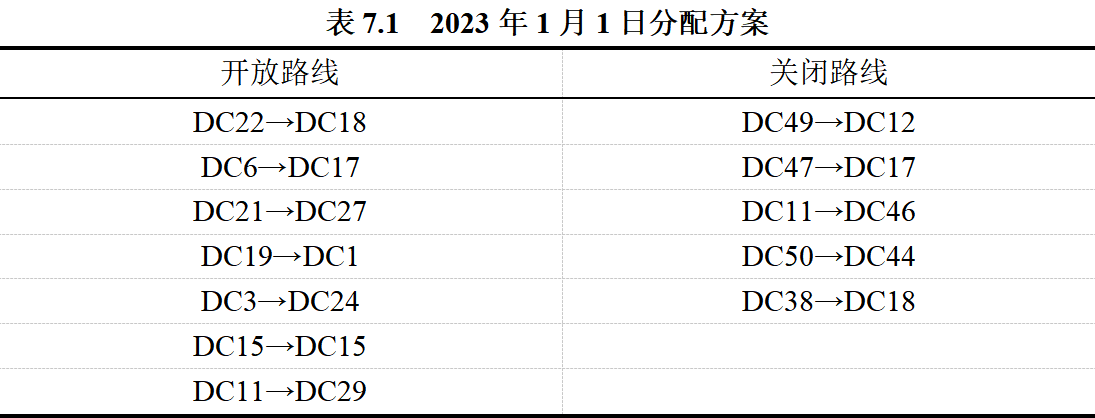
首先对DC5关停当日进行模型求解,得出分配方案如表6.1所示:
分析得出,分流方案中的变化线路数为38,其负荷率的标准差为0.2397,未能正常流转的货运量为58924。
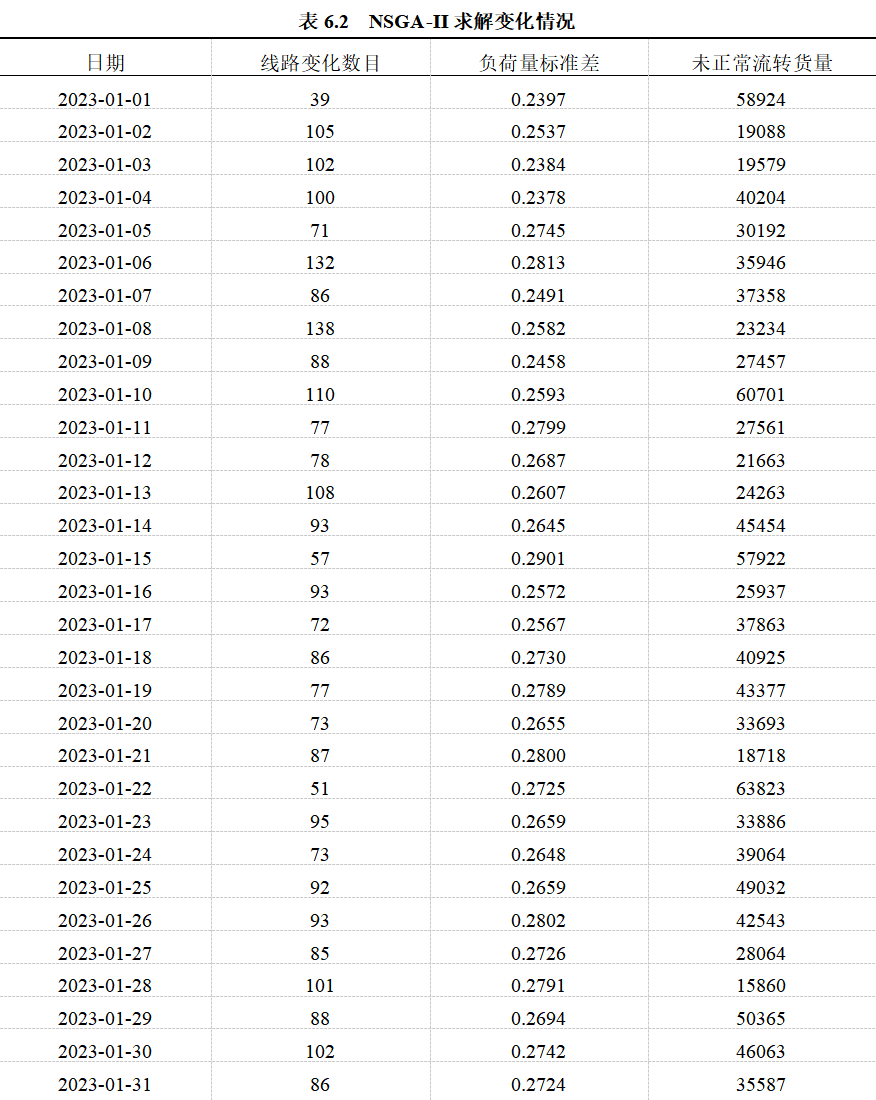
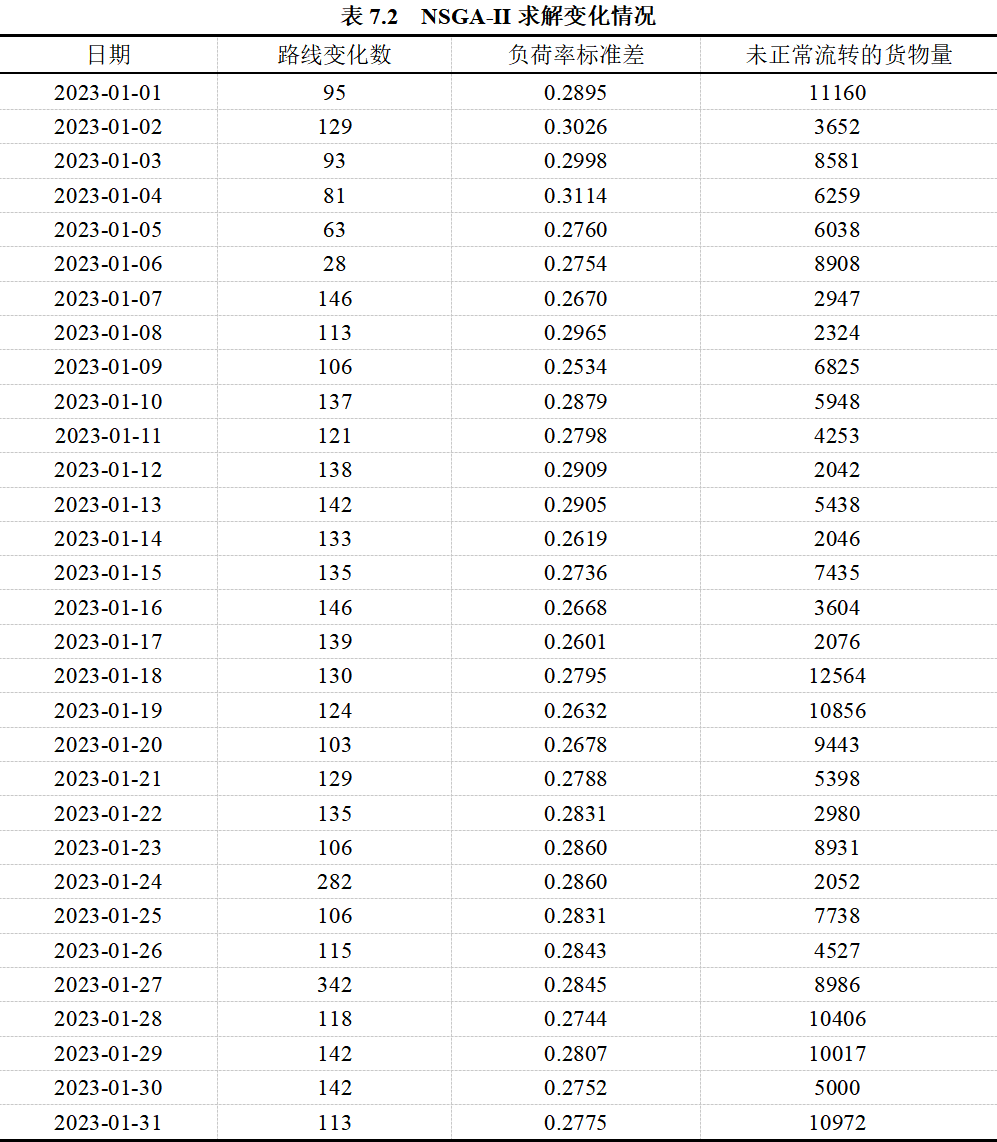
对2023年1月的每天都使用NSGA-II算法进行求解,线路增减情况及其他指标说明如表6.2所示:
7、问题三模型的建立与求解
7.1 问题与数据分析
问题指出被关停的物流场地为DC9,同时允许对当前物流网络结构进行动态调整(每日均可调整),调整措施包括关闭或新开线路,但不包括新增物流场地。该问题与问题二思路上相似,但属于动态多目标整数规划(DMOIP)问题,与传统的MOIP问题不同的是,DMOIP问题中的目标函数和约束条件是随着时间变化而变化的,因此需要动态求解最优解。分析在整个物流网络上,存在一定货量运入和运出物流场地DC9,将该部分货量进行可视化处理,如图7.1所示:
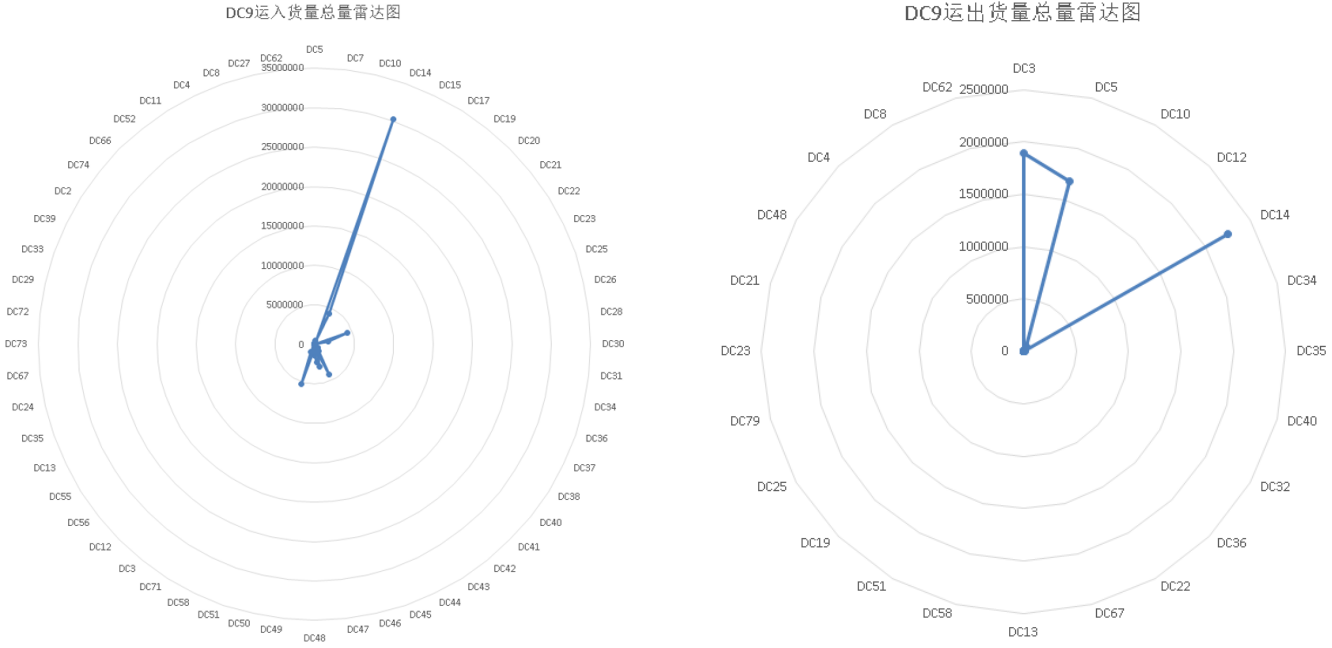
图7.1 运入和运出DC 9 的总货量雷达图
采用问题二的NSGA-II算法进行求解,根据问题要求,模型需要每日进行一次分析求解,给出最佳的决策方案,在整个电商物流网络上关闭一定的物流节点和线路,以及新开一定的物流节点和线路。在DC9被关停后,需要将原本运入和运出DC9的总货量进行重新分配,分配原则与问题二基本一致。
7.2 基于NSGA-II算法的问题求解
设定MOIP约束条件如下:
(1)每个时间段每个线路的货量为非负整数
(2)流入每个物流场地的货量等于流出每个物流场地的货量
(3)各条线路的运输能力不大于最大运输能力
(4)各个物流场地的处理能力不大于最大运输能力
首先对DC9关停当日进行模型求解,得出分配方案如表7.1所示,同时解出分流方案中的变化线路数为95,其负荷率的标准差为0.2895,未能正常流转的货运量为11160。
对2023年1月的每天都使用NSGA-II算法进行求解,线路增减情况及其他指标说明如表7.2所示:
8、问题四模型的建立与求解
8.1 基于熵权法的Topsis对不同物流场地及线路的重要性评价
Topsis是一种多属性决策分析方法,用于确定一组备选方案中最佳的方案。该方法通过对备选方案进行评分,将其转化为一个数学模型,从而帮助决策者确定最佳方案。首先Topsis将评价对象转化为决策矩阵,然后依次通过标准化决策矩阵、确定权重、确定理想解和负理想解、计算距离、计算综合得分和排序确定最佳方案。
基于熵权法的Topsis通过计算属性之间的信息熵来自动确定每个属性的权重,避免权重可能存在的主观性和不确定性,能够更准确地评估备选方案的综合得分。基于熵权法的Topsis的处理流程如图8.1所示:
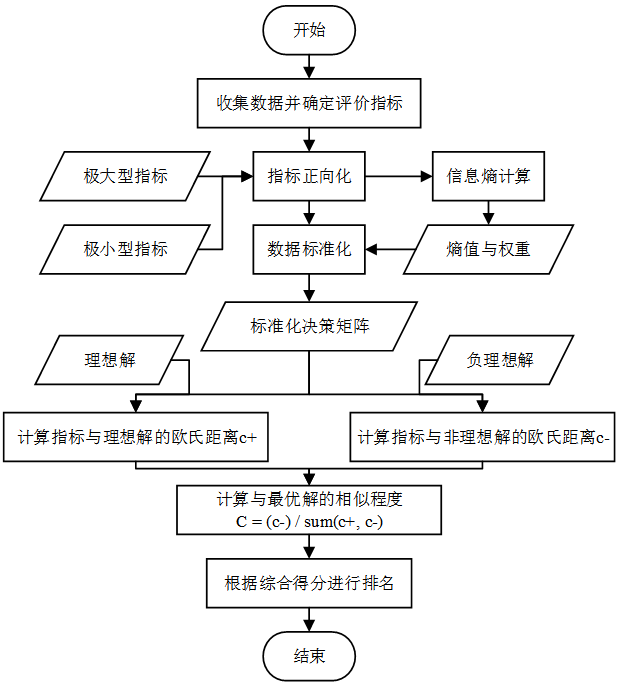
图8.1 基于熵权法的Topsis流程图
(1)指标正向化
常用的指标一般分为极大型指标(又称效益型指标)和极小型指标(又称成本型指标)。针对附件给出的数据与问题分析,主要考虑的指标如下:
①现有运输货量:反映电商物流网络的运输能力和规模;
②货物运输次数:反映电商物流网络的运输效率和运输能力;
③最大运输货量:反映电商物流网络的最大运输能力和规模;
④货物运输均衡度:反映电商物流网络的运输均衡性;
⑤场地发送总货量、场地接受总货量:反映电商物流网络的场地利用率;
⑥场地发送货物次数、场地接收货物次数:反映电商物流网络的场地利用效率;
⑦场地发送货物均值、场地接收货物均值:反映电商物流网络收发货物的均衡性。
极大型指标的正向化:
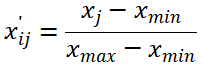
极小型指标的正向化:
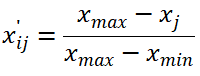
(2)数据标准化
将评价对象转化为决策矩阵,对决策矩阵的每一列标准化,消除量纲影响:
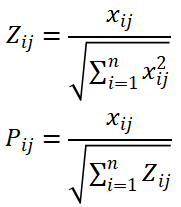
(3)熵权法求解信息熵与权重
对每个指标计算信息熵,根据信息熵求解权重,然后进行归一化处理求出权重:
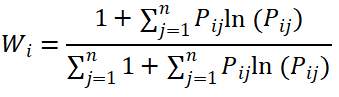
根据熵权法求解的结果如表8.1、表8.2所示:
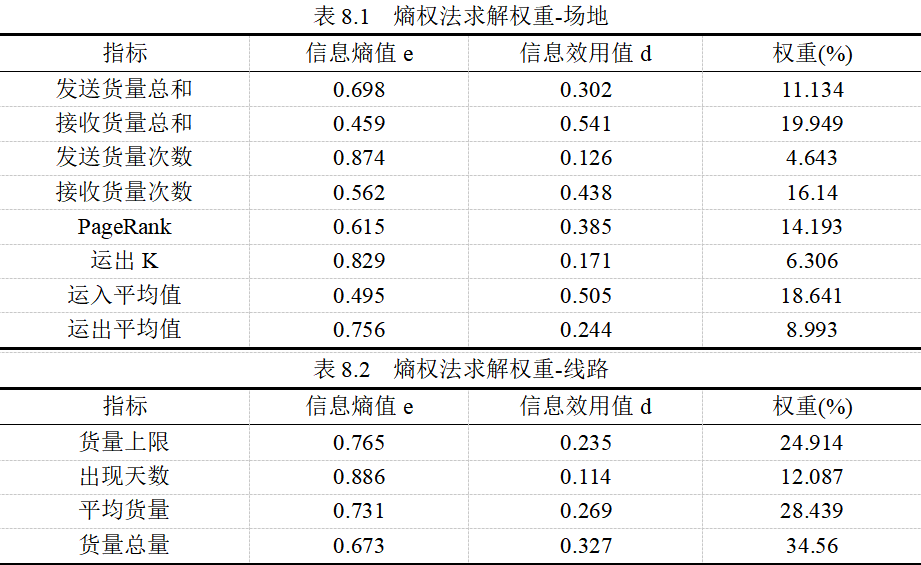
(4)计算指标与理想解和负理想解的欧氏距离
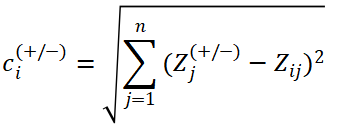
(5)计算综合得分并排序
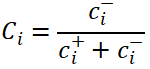
最终排序后的综合得分如表8.3、表8.4所示:
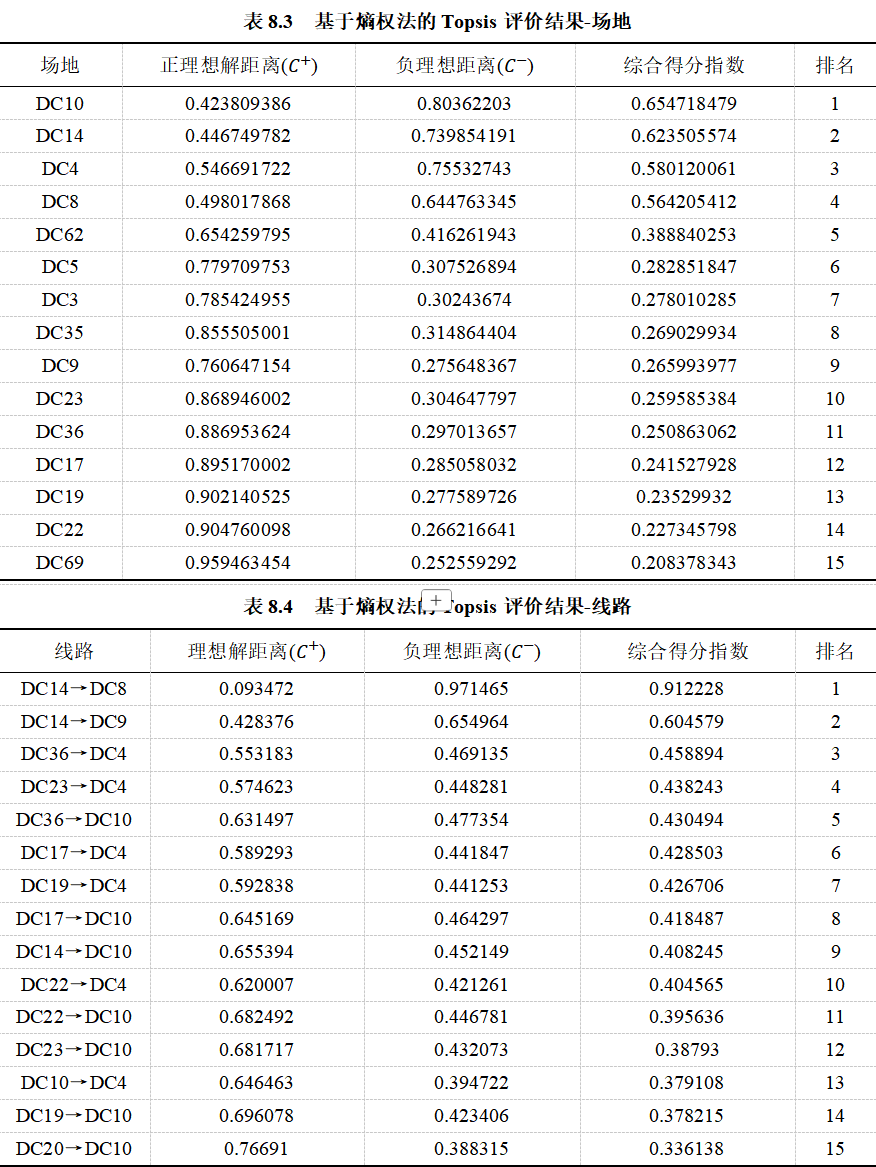
表8.3、表8.4分别给出了排名前15的场地及线路,根据给出的综合得分指数和排名,可以说明表中给出的物流场地及线路的重要性比较高。同时观察到排名靠前的场地DC14、DC10、DC8、DC9等也均是排名靠前的线路DC14->DC8、DC14->DC9、DC14->DC10等的相关场地,评价结果之间相互印证,从而可以进一步说明评价结果的合理性。
8.2 新增物流场地及处理能力设置和新增线路的运载能力设置
根据表8.3给出的评价结果,结合问题一中模型的预测结果,可知排名前四的物流场地DC10、DC14、DC4和DC8的综合得分指数较高,相对而言在本题给出的物流网络中更加重要,因此在考虑新增物流场地以改善物流网络性能时,应当优先对这些物流场地及对应的线路进行优化,使线路的工作负荷尽量均衡,同时缓解当这些物流场地出现突发情况被迫关停时造成的网络负荷调度问题。
问题还要求对新增物流场地的处理能力及新增线路的运输能力进行设置,求解的基本的思路是令新增物流场地的处理能力与线路上已有场地的最大处理能力相近,同时新增线路的运输能力也需要和当前线路的最大运输能力相近,以保证货量能满足分配需求。
8.3 模型鲁棒性验证
由于模型的预测结果具有一定的随机性,同时在建模过程中可能会假设前提条件或参数值,通常是基于某些假设或者历史数据得出的,而现实情况可能会与这些假设或者历史数据存在差异,因此在构建物流网络的过程中必须考虑模型的鲁棒性,通过调参优化或增设备选方案来提升模型的预测效果。
为了验证模型的鲁棒性,通过观察与分析附件给出的时间序列数据中的不同时间引入不同程度的数据扰动后模型的训练情况以及评估模型的预测结果,说明模型的鲁棒性。
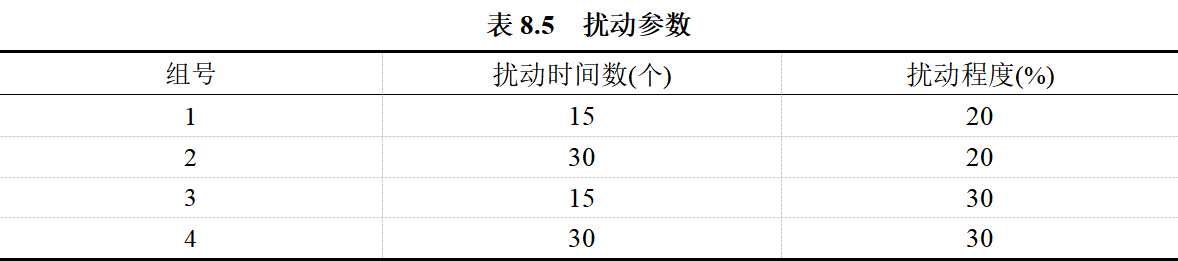
设置不同时间及引入不同程度的数据扰动的参数如表8.5所示:
根据扰动参数表,选取DC14→DC10、DC20→DC35、DC25→DC62共三条线路的历史货量数据,分别按照表中给出的分组进行数据扰动,重新训练模型并预测2023年1月1日至2023年1月31日的货量,模型预测的结果如图8.2、图8.3和图8.4所示:
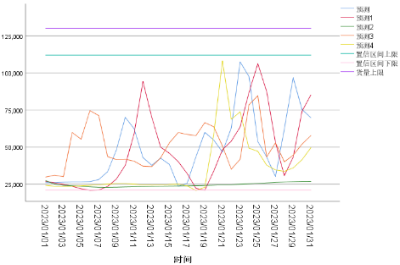
图8.2 模型预测拟合曲线( DC14→DC10)****
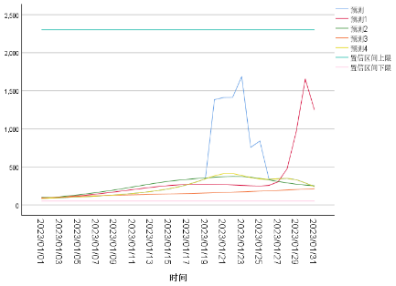
图8.3 模型预测拟合曲线( DC20→DC35)****
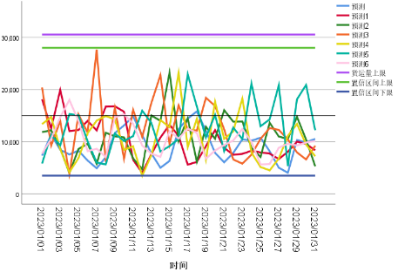
图8.4 模型预测拟合曲线( DC25→DC62)****
这里给出模型的置信区间边界和历史货运量上限,观察到引入不同的数据扰动后,给出的预测曲线基本没有过大的波动,部分预测曲线的最高货运量有升高,表明物流网络的负荷量出现增长,但模型的预测区间均落在给定的置信区间内,说明模型在引入一定的数据扰动后依旧保持良好的预测效果,即模型的鲁棒性较好。
9、模型的优缺点
9.1 模型的优点
(1)模型采用ARIMA+LSTM模型组合的方式,其中ARIMA能够捕捉时间序列的长期趋势,而LSTM能够捕捉时间序列的短期波动。二者结合可以更好地捕捉时间序列的长期趋势和短期波动;
(2)ARIMA和LSTM都是经典的时间序列预测方法,具有较好的鲁棒性,二者结合可以进一步提高时间序列预测的鲁棒性;
(3)MOIP问题采用NSGA-II算法,相较于传统MOIP问题求解的算法,NSGA-II算法具有高效性、多样性、可扩展性和稳健性;
9.2 模型的缺点
(1)ARIMA和LSTM都需要较长的时间序列数据来训练模型,并且需要进行大量的参数调整。二者结合会使得计算复杂度增加;
(2)LSTM是一种黑盒模型,ARIMA和LSTM结合会造成预测结果的可解释性出现一定程度的降低;
(3)NSGA-II算法通过限制解集大小来控制Pareto前沿的质量,可能会导致一些高质量的解被忽略,同时随着问题维度的增加,算法的性能会下降,而且算法对Pareto前沿的刻画不够准确。
参考文献
1 Fattah J, Ezzine L, Aman Z, et al. Forecasting of demand using ARIMA modelJ. International Journal of Engineering Business Management, 10: 1-9, 2018.
2 Gonzalez J, Yu W. Non-linear system modeling using LSTM neural networksJ. IFAC-PapersOnLine, 51(13): 485-489, 2018.
3 Siami-Namini S, Tavakoli N, Namin A S. A comparison of ARIMA and LSTM in forecasting time seriesC, IEEE international conference on machine learning and applications. IEEE, 1394-1401, 2018.
4 Zhou K, Wang W Y, Hu T, et al. Comparison of time series forecasting based on statistical ARIMA model and LSTM with attention mechanismC, Journal of physics: conference series. IOP Publishing, 1631(1): 012141, 2020.
5 Deb K, Pratap A, Agarwal S, et al. A fast and elitist multiobjective genetic algorithm: NSGA-IIJ. IEEE transactions on evolutionary computation, 6(2): 182-197, 2002.
6 Hamdani T M, Won J M, Alimi A M, et al. Multi-objective feature selection with NSGA IIC, Adaptive and Natural Computing Algorithms: 8th International Conference, ICANNGA 2007, Warsaw, Poland, Proceedings, Part I 8. Springer Berlin Heidelberg, 2007: 240-247, April 11-14, 2007.
7 魏唯, 欧阳丹彤, 吕帅, 等. 动态不确定环境下多目标路径规划方法J. 计算机学报, 34(5): 836-846, 2011.
8 Behzadian M, Otaghsara S K, Yazdani M, et al. A state-of the-art survey of TOPSIS applicationsJ. Expert Systems with applications, 39(17): 13051-13069, 2012.
9 陈雷, 王延章. 基于熵权系数与 TOPSIS 集成评价决策方法的研究J. 控制与决策, 18(4): 456-459, 2003.
10 Shih H S, Shyur H J, Lee E S. An extension of TOPSIS for group decision makingJ. Mathematical & Computer Modelling, 45(7):801-813, 2007.