#无数据/零样本量化3------Zero-shot Adversarial Quantization
译文标题:ZAQ:一种对抗性的零样本量化方法
出处:2021 CVPR
作者:Yuang Liu等
作者单位:华东师范
论文代码地址:https://github.com/xubin1994/ZAQ-code
文章目录
- 前言
- 一、研究动机
- 二、创新点
-
- 1.对抗行量化
- [2. 两级差异建模策略](#2. 两级差异建模策略)
- [3 方法](#3 方法)
-
- [3.1 回顾](#3.1 回顾)
- [3.2 两级差异建模:](#3.2 两级差异建模:)
-
- [3.2.1 结果输出](#3.2.1 结果输出)
- [3.2.2 中间特征输出](#3.2.2 中间特征输出)
- [3.3 对抗性的知识迁移](#3.3 对抗性的知识迁移)
- [3.4 激活正则化](#3.4 激活正则化)
- [4 实验](#4 实验)
- 总结
前言
我们在前章节已经详细介绍过了神经网络模型量化的PTQ和QAT两种主流方式。以上两种均需要原始数据集进行校准或微调。然而在实际情况下,由于数据隐私以及安全问题,原始训练数据往往无法访问,例如医疗数据、金融数据、个人隐私数据和军事安全数据等。对于QAT这种量化方式 需要整个数据集来做微调,而PTQ仅需要一小部分数据对激活层做校准。从对数据集的要求来看,PTQ方法显然在零样本的情况下实现更为简单。
一、研究动机
PTQ方法的校准对于原数据的要求不高,所以对于现在的很多工作都是从PTQ方法开展。DFQ方法通过权重均衡和偏差吸收两种方式首次实现了在无样本的情况下仅通过模型权重和结果就能实现量化,但这种方法在超低精度下的量化误差进一步的增大ZeroQ和GDFQ和通过使用BNS进行样本生成,从而引导PTQ的方法的实现,但合成样本很难符合原始数据集的"特性",并且生成很耗时。
二、创新点
1.对抗行量化
在零样本的场景下提出了一个抗量化方法,能够高效的进行数据生成和知识迁移(首次引入对抗学习)。
2. 两级差异建模策略
在量化模型和全精度模型中从模型中间特征输出和模型最后的logits输出进行对齐,指导量化模型 Q Q Q和生成器 G G G的学习。
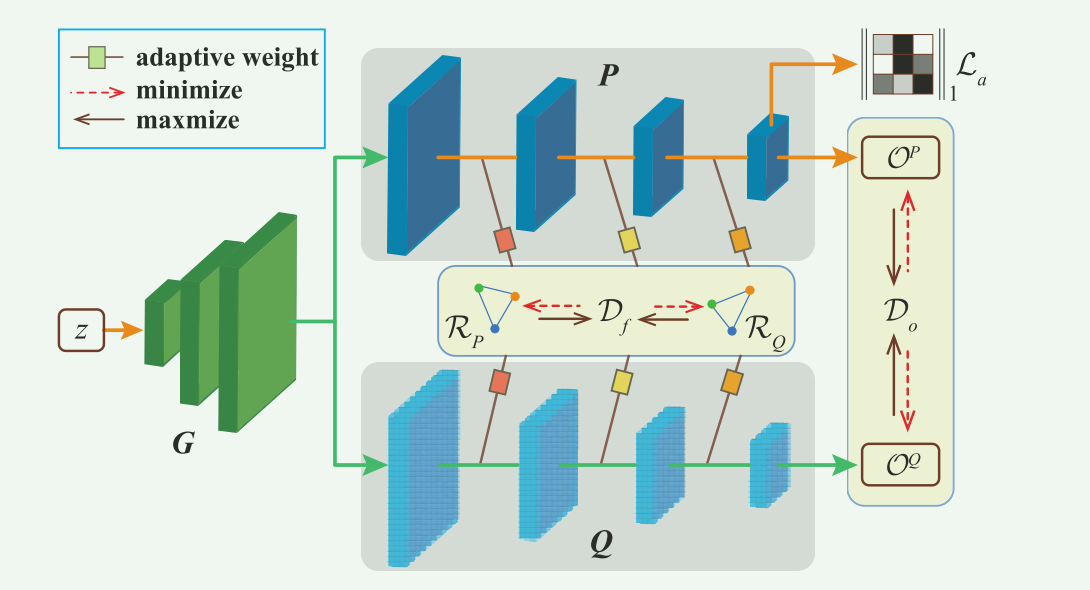
整体方法由三个部分生成器 G G G、全精度模型 P P P和 量化模型 Q Q Q三部分构成。二级差异有全精度模型 P P P和 量化模型 Q Q Q的中间部分输出 D f \mathcal {D}{\mathcal{f}} Df和结果输出 D o \mathcal {D}{\mathcal{o}} Do构成,并且由最后一层 L a \mathcal {L}_{\mathcal{a}} La正则化帮助生成信息量更大和更多样化的样本,量化模型 Q Q Q和生成器 G G G通过典型的对抗思路极大极小化进行优化。
3 方法
3.1 回顾
均匀量化公式表示:
q ( v ) = r o u n d ( S ⋅ ( v − Z ) ) , ( 1 ) q(v)=\mathrm{round}\left(S\cdot(v-Z)\right),\quad(1) q(v)=round(S⋅(v−Z)),(1)
其中 S S S是缩放因子, Z Z Z是零点。
缩放因子的计算如下:
S = 2 k − 1 − 1 max ( ∣ x f ∣ ) , ( 2 ) S=\frac{2^{k-1}-1}{\max(|x_{\mathrm{f}}|)},\quad(2) S=max(∣xf∣)2k−1−1,(2)
k k k为量化bit位宽, max ( ∣ x f ∣ ) \max(|x_\mathrm{f}|) max(∣xf∣)是同批被量化32浮点数的最大值。
量化模型和全精度模型的最大差异描述如下:
Q ∗ = min Q ( P , Q ) , ( 3 ) Q^*=\min_Q (P,Q) ,\quad(3) Q∗=Qmin(P,Q),(3)
3.2 两级差异建模:
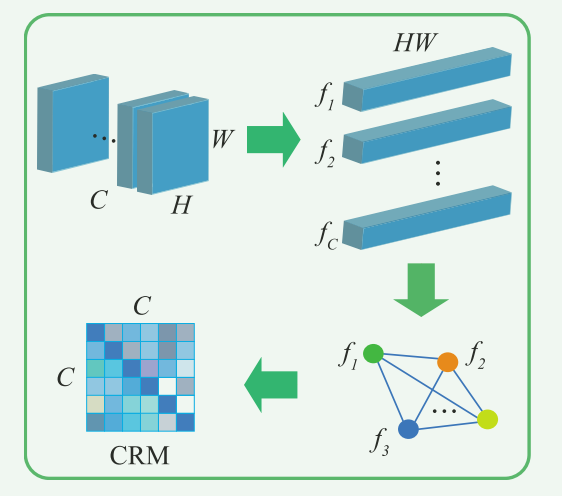
也就是中间输出和最终的结果输出都求"差异",一起算做损失函数。
3.2.1 结果输出
其中输出结果差异 D o \mathcal D_o Do被描述为:
D o ( P , Q ; G ) = E x g 1 N ∥ P ( x g ) − Q ( x g ) ∥ 1 , ( 4 ) \mathcal{D}{o}(P, Q ; G)=\mathbb{E}{x_{g}}\left\\frac{1}{N}\\left\\\|P\\left(x_{g}\\right)-Q\\left(x_{g}\\right)\\right\\\|_{1}\\right, \quad(4) Do(P,Q;G)=ExgN1∥P(xg)−Q(xg)∥1,(4)
这里选用了 L 1 L1 L1 范式的原因是因为在最大化生成器的过程中 KL散度难以捕获输出之间的微小差异。不难理解,KL散度要求平方,数字越小其平方运算结果也就越小。
3.2.2 中间特征输出
输出过程差异 D f \mathcal D_f Df被描述为:
D f ( P , Q ; G ) = E x g ∑ l L ω ( l ) C ( l ) 2 ∥ R P ( l ) ( x g ) − R Q ( l ) ( x g ) ∥ 1 , ( 5 ) \mathcal{D}{f}(P,Q;G)=\mathbb{E}{x_{g}}\left \\sum_{l}\^{L} \\frac{\\omega \^{(l)}}{{C\^{(l)}}\^2} \\left\\\| \\mathcal{R}_{P}\^{(l)}(x_{g}) -\\mathcal{R}_{Q}\^{(l)}(x_{g}) \\right\\\|_1 \\right,\quad(5) Df(P,Q;G)=Exgl∑LC(l)2ω(l) RP(l)(xg)−RQ(l)(xg) 1,(5)
作者的思路来自通道特征注意力。作者提出了一个通道关系矩阵CRM(Channal Relation Martix) 的概念, 主要是考虑不同通道级别的特征之间有相似关系的存在。首先CHW 格式的tensor 沿C通道展开成为二维的,构成像C* HW 的二维向量记为 { f 1 , f 2 , . . . , f C } {\left\{ f_1,f_2,...,f_C \right\}} {f1,f2,...,fC},然后捕获两个特征向量之间的相关性。这个和通道注意力的思路类似,只不过通过计算二者的宇轩余弦相似度来描述二者的相似关系。
R i j = < f i , f j > ∥ f i ∥ 2 ∥ f j ∥ 2 \mathcal{R}{ij}=\frac{<f{i},f_{j}>}{\left\|f_{i}\right\|{2}\left\|f{j}\right\|_{2}} Rij=∥fi∥2∥fj∥2<fi,fj>
同样的我们可得到一个 R ∈ R C × C \mathcal R \in\mathbb{R}^{C\times C} R∈RC×C的CRM通道关系矩阵,一般的,扩展到L层的网络模型的CRM矩阵有如下表示:
R i j ( l ) = < f i ( l ) , f j ( l ) > ∥ f i ( l ) ∥ 2 ∥ f j ( l ) ∥ 2 , ( 6 ) \mathcal{R}{ij}^{(l)}=\frac{<\boldsymbol{f}{i}^{(l)},\boldsymbol{f}{j}^{(l)}>}{\left\|\boldsymbol{f}{i}^{(l)}\right\|{2}\left\|\boldsymbol{f}{j}^{(l)}\right\|_{2}},\quad(6) Rij(l)= fi(l) 2 fj(l) 2<fi(l),fj(l)>,(6)
回到公式(5) 其中 C ( l ) 2 {C^{(l)}}^2 C(l)2表示l层的通道个数, ω ( l ) {\omega^{(l)}} ω(l)表示第 l l l层下的自适应差异权重,这样的自定义权重表示为某一层的激活图差异输出占比,表示如下:
ω ( l ) = exp ( E M A T ( E x g ∈ B t ∥ R P ( l ) ( x g ) − R Q ( l ) ( x g ) ∥ 1 ) ) ∑ l ′ L exp ( E M A T ( E x g ∈ B t ∥ R P ( l ′ ) ( x g ) − R Q ( l ′ ) ( x g ) ∥ 1 ) ) , ( 7 ) \omega^{(l)}=\frac{\exp\left(\mathrm{EMA}T\left(\mathbb{E}{x_g\in\mathcal{B}t}\left\\left\\\|\\mathcal{R}_P\^{(l)}(x_g)-\\mathcal{R}_Q\^{(l)}(x_g)\\right\\\|_1\\right\right)\right)}{\sum{l^{\prime}}^L\exp\left(\mathrm{EMA}T\left(\mathbb{E}{x_g\in\mathcal{B}_t}\left\\left\\\|\\mathcal{R}_P\^{(l\^{\\prime})}(x_g)-\\mathcal{R}_Q\^{(l\^{\\prime})}(x_g)\\right\\\|_1\\right\right)\right)},\quad(7) ω(l)=∑l′Lexp(EMAT(Exg∈Bt RP(l′)(xg)−RQ(l′)(xg) 1))exp(EMAT(Exg∈Bt RP(l)(xg)−RQ(l)(xg) 1)),(7)
EMA 是一个典型的指数移动平均算法,炼丹时候也经常使用; T T T是一个epoch的训练步数(1,2,3,...,收敛);其中 ω ( l ) {\omega^{(l)}} ω(l)在每一个epoch都被初始化定义为 1 L \frac {1}{L} L1,即每层都相等。
这里也好理解,使用softmax函数将其做归一化,表示同一epoch的第 T T T步下, ω ( l ) {\omega^{(l)}} ω(l)在 l l l层的CRM 自适应差异权重。
3.3 对抗性的知识迁移
将已经收敛的预训练全精度模型的知识迁移到量化模型,采用对抗学习中经典的最大最小算法。分为差异估计和知识迁移两个部分。这个思想很简单,再差异估计部分让生成器 G G G生成最难的样本, Q Q Q和 P P P的输出差异最大,差异估计loss最大化;第二步知识迁移部分,拿着这批样本进行 Q Q Q和 P P P的进行二段差异对齐,知识迁移loss最大化。
差异估计部分的loss如下:
L D E = − D o ( P , Q ; G ) − α D ( P , Q ; G ) , ( 8 ) \mathcal L_{DE}=-\mathcal D_o(P,Q;G)-\alpha \mathcal D(P,Q;G), \quad(8) LDE=−Do(P,Q;G)−αD(P,Q;G),(8)
知识迁移的部分如下:
L K T = D o ( P , Q ; G ) + α D ( P , Q ; G ) , ( 9 ) \mathcal L_{KT}=\mathcal D_o(P,Q;G)+\alpha \mathcal D(P,Q;G),\quad(9) LKT=Do(P,Q;G)+αD(P,Q;G),(9)
3.4 激活正则化
这里引用了一神经网络的可解释性相关研究------激活层可以反映DNN对于输入数据的敏感性。将其解释为激活输出越高,合成样本越与原始输入样本的相关性就越高。因此为使得合成样本尽可能落在训练样本集输入域中,对最后一层进行正则约束如下:
L a = − 1 M ∑ i M ∥ h i P ∥ 1 , ( 10 ) \mathcal{L}_a=-\frac{1}{M}\sum_i^M\left\|h_i^P\right\|_1,\quad(10) La=−M1i∑M hiP 1,(10)
其中,M是最后一层的通道个数,将最后一层激活图 P P P表示为 h i P , i ∈ { 1 , 2 , . . . , M } h_i^P,i \in\{1,2,...,M\} hiP,i∈{1,2,...,M},将差异估计阶段的loss函数定义如下,将其最小化。(因为前边定义了 − - −,所以采用常用的最小化,也符合最大化的对抗定义)
L D E = − D o ( P , Q ; G ) − α D f ( P , Q ; G ) + β L a , ( 11 ) \mathcal{L}_{DE}=-\mathcal{D}_o(P,Q;G)-\alpha\mathcal{D}_f(P,Q;G)+\beta\mathcal{L}_a,\quad(11) LDE=−Do(P,Q;G)−αDf(P,Q;G)+βLa,(11)
整体算法描述如下:

不难理解,每个epoch训练步骤如下:
-
均匀初始化自适应层级差异权重 ω = 1 L \omega = \frac{1}{L} ω=L1;
-
生成样本 x g x_g xg,固定量化模型 Q Q Q参数,计算 L D E \mathcal L_{DE} LDE,更新生成器 G G G参数;
-
然后更新下每层的自适应差异权重 ω ( l ) \omega ^{(l)} ω(l);
-
固定生成器 G G G参数, 生成样本 x g x_g xg,计算 L K T \mathcal L_{KT} LKT,更新 量化模型Q的参数;
4 实验
作者分别在分类 分割和目标检测三类图像任务中都进行了 实验。
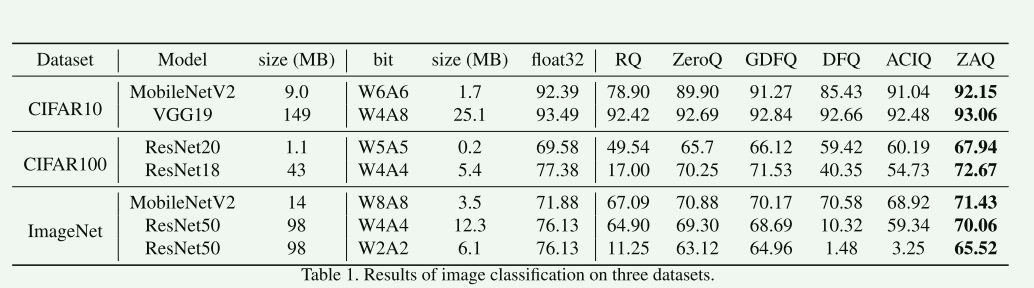
4.1 分类
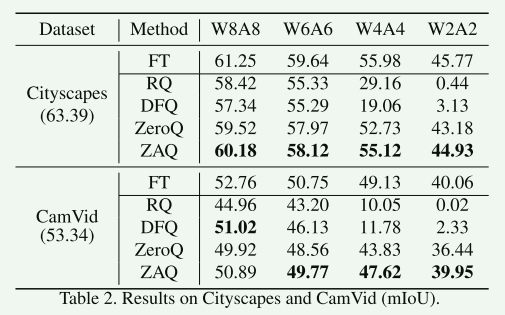
4.2 分割
4.3 目标检测
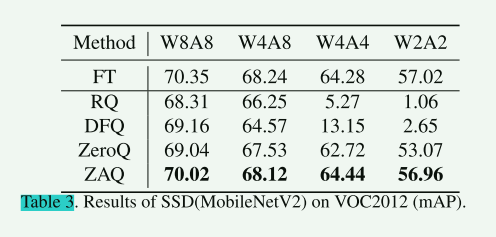
作者分别在分类 分割和目标检测三类图像任务中做了量化比特精度与实验指标折线图,实验表明ZAQ在低比特梁欢精度下 比现有方法更好。
4.4 消融实验
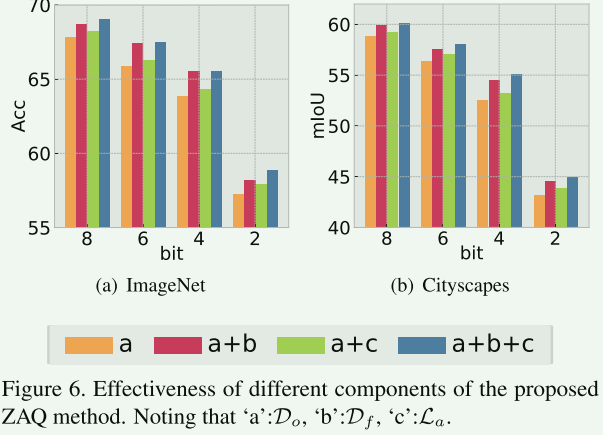
在这里发现中间特征输出(red)和激活正则化(green)都是有正向作用的。
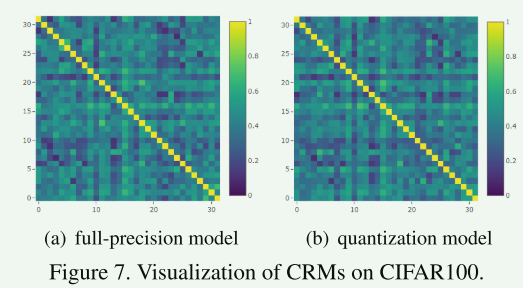
4.5 CRM通道关系映射矩阵法
作者也证实了 本文针对中间输出差异建模的提出的CRM通道关系映射矩阵法,结果表明CRM是优于gram法和AT法。
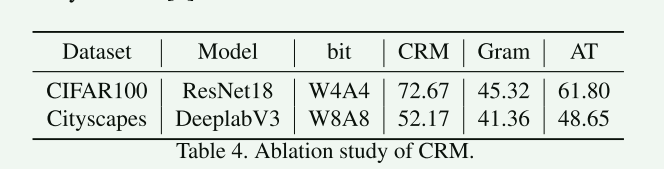
全精度模型和4bit的resnet-18的第二层激活的CRM,观察其值是相似的。
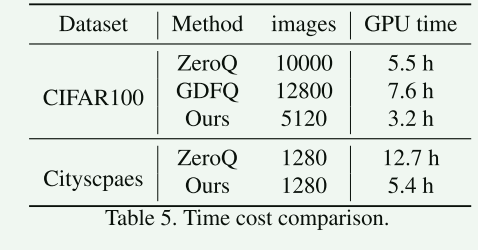
4.6 样本合成的效率分析
GTX2080TI设备.
这样本合成的数量取决于ZeroQ和GDFQ方法的收敛状态,说明如下:
(1) 由于ZeroQ和GDFQ样本多样性较差,所以需要更多的样本;
(2) 分割任务ZeroQ太慢了(cityscapes分辨率太高了),所以使用了原始训练的epoch的样本1280数量进行对比;
结果如下:
发现ZAQ方法效率较GDFQ和ZeroQ是最优的。
4.7 样本合成的可视化分析
CIFAR
针对CIFAR10(行1组)和 CIFAR100(行2)进行合成,前三列组模型使用mobileNet,最后前三列组模型使用resnet-20。

以上三种方法合成的样本都不被人类识别(当然CNN的能力是捕获局部特征),但是ZAQ样本更多样化。(这个结论好像也不太好被看出来吧?)
CamVid
可以看出来,合成图用于分割的样本具有更丰富的局部特征。

总结
提出了对抗性的二阶段零样本量化方法,通过中间和结果输出交替的进行差异估计和知识迁移;并且在三类经典任务上均有效。
- 首次对抗学习引入零样本量化;
- 首次在分类 分割和目标检测上都做实验;