3. 聊天模型--结构化输出
在 LangChain 中,聊天模型提供了额外的功能:结构化输出。一种使聊天模型以结构化格式(例如 JSON)进行响应的技术。
例如,可能希望将模型输出存储在数据库中,并确保输出符合数据库模式。 这种需求激发了结构化输出的概念,其中可以指示模型使用特定的输出结构进行响应。
核心是:从"字符串"到"对象"的范式转换。
聊天模型的 with_structured_output方法则允许我们预先定义一个期望的数据结构,并要求大 模型必须按照这个结构返回信息。
3.1 with_structured_output()
要想使用结构化输出能力,LangChain 提供了一种方法 .with_structured_output() ,该方法 需要先定义输出结构,然后执行通过 .with_structured_output() 得到的 Runnable 实例。步 骤如下(伪代码):
python
#定义输出结构
schema={"foo":"bar"}
#绑定schema,也就是生成支持结构化返回的runnable实例
model_with_structure=model.with_structured_output(schema)
#执行
structured_output = model_with_structure.invoke(user_input)这是获得结构化输出的最简单、最可靠的方法。
此方法将 输出结构 作为参数输入,返回一个类似 model 的 Runnable。输出结果,输出的不是字符串或消息 ,而是 输出与给定输出结构相对应的对象。
该 输出结构 可以指定为 TypedDict 类、JSON Schema 类, Runnable 将返回一个字典。指定为 Pydantic 类,则将返回一个 Pydantic 对 象。
3.1.1 返回 Pydantic 对象
设置执行 Runnable 后的输出结果指定为 Pydantic 类,这将返回一个 Pydantic 对象。
python
from typing import Optional, List
from langchain_deepseek import ChatDeepSeek
from pydantic import BaseModel, Field
from sqlalchemy.sql.annotation import Annotated
from typing_extensions import TypedDict
model = ChatDeepSeek(
model="deepseek-v4-flash",
extra_body={
"thinking": {
"type": "disabled"
}
}
)
#Pydantic对象
class Joke(BaseModel):
"""给用户讲的一个笑话"""
setup:str=Field(description="这个笑话的开头")
punchline:str=Field(description="这个笑话的妙语")
rating:Optional[int]=Field(default=None,description="1到10分,给这个笑话打分")
class Data(BaseModel):
"""获取关于笑话的数据列表"""
jokes:List[Joke]
model_with_structured=model.with_structured_output(Data)
print(model_with_structured.invoke("分别讲一个关于国内大殖子和台湾蛙蛙的笑话,用贴吧老哥的攻击力和语气"))3.1.2 返回 TypedDict
TypedDict ,它用于为字典对象提供精确的、结构化的类型提示。 它允许我们指定一个 字典中应该有哪些键,以及每个键对应的值的类型。它非常重要的一个能力就是捕捉键名拼写错误与类型错误。
最清晰、最常用的定义方式,就是类似于定义一个类
python
from typing import TypedDict
class User(TypedDict):
name: str
age: int
email: str
is_active: bool = True # 默认值代码示例:
python
from typing import Optional, List
from langchain_deepseek import ChatDeepSeek
from pydantic import BaseModel, Field
from sqlalchemy.sql.annotation import Annotated
from typing_extensions import TypedDict
model = ChatDeepSeek(
model="deepseek-v4-flash",
extra_body={
"thinking": {
"type": "disabled"
}
}
)
#TypedDict
class Joke(TypedDict):
steup:Annotated[str,...,"笑话的开头"]
punchline:Annotated[str,...,"这个笑话的妙语"]
rating: Annotated[int,None, "1到10分,给这个笑话打分"]
model_with_structured=model.with_structured_output(Joke)
print(model_with_structured.invoke("分别讲一个关于国内大殖子和台湾蛙蛙的笑话,用贴吧老哥的攻击力和语气"))3.1.3 返回 JSON
还可以让聊天模型直接返回 JSON,只不过为了声明 JSON,我们需要定义 JSON Schema
python
from typing import Optional, List
from langchain_deepseek import ChatDeepSeek
from pydantic import BaseModel, Field
from sqlalchemy.sql.annotation import Annotated
from typing_extensions import TypedDict
model = ChatDeepSeek(
model="deepseek-v4-flash",
extra_body={
"thinking": {
"type": "disabled"
}
}
)
#JSON Schema
json_schema = {
"title": "joke",
"description": "给用户讲一个笑话。",
"type": "object",
"properties": {
"setup": {
"type": "string",
"description": "这个笑话的开头",
},
"punchline": {
"type": "string",
"description": "这个笑话的妙语",
},
"rating": {
"type": "integer",
"description": "从1到10分,给这个笑话评分",
"default": None,
},
},
"required": ["setup", "punchline"],
}
model_with_structured=model.with_structured_output(json_schema)
print(model_with_structured.invoke("分别讲一个关于国内大殖子和台湾蛙蛙的笑话,用贴吧老哥的攻击力和语气"))3.1.4 选择输出格式
创建具有联合类型属性的父模式,以使用 Pydantic 为例(其他同理)
python
from typing import Optional, List, Union
from langchain_deepseek import ChatDeepSeek
from pydantic import BaseModel, Field
model = ChatDeepSeek(
model="deepseek-v4-flash",
extra_body={
"thinking": {
"type": "disabled"
}
}
)
# Pydantic对象
class Joke(BaseModel):
"""给用户讲的一个笑话"""
setup:str=Field(description="这个笑话的开头")
punchline:str=Field(description="这个笑话的妙语")
rating:Optional[int]=Field(default=None,description="1到10分,给这个笑话打分")
class Response(BaseModel):
"""用正常对话的方式来回应"""
content:str=Field(description="用于对用户查询的会话响应")
class FinalResponse(BaseModel):
"""最终回复,选择合适的输出结构"""
final_output:Union[Joke,Response]
model_with_structured=model.with_structured_output(FinalResponse)
print(model_with_structured.invoke("分别讲一个关于国内大殖子和台湾蛙蛙的笑话,用贴吧老哥的攻击力和语气"))
print(model_with_structured.invoke("你是谁"))
3.2 实用场景
3.2.1 场景1:作为信息提取器
python
from langchain_deepseek import ChatDeepSeek
from typing import Optional
from pydantic import BaseModel, Field
from langchain_core.messages import HumanMessage, SystemMessage
# 定义大模型
model =ChatDeepSeek(
model="deepseek-v4-flash",
extra_body={
"thinking":{
"type":"disabled"
}
}
)
class Person(BaseModel):
"""一个人的信息。"""
# 注意:
# 1. 每个字段都是 Optional "可选的" ------ 允许 LLM 在不知道答案时输出 None。
# 2. 每个字段都有一个 description "描述" ------ LLM使用这个描述。
# 有一个好的描述可以帮助提高提取结果。
name: Optional[str] = Field(default=None, description="这个人的名字")
hair_color: Optional[str] = Field(default=None, description="如果知道这个人头发的颜色")
skin_color: Optional[str] = Field(default=None, description="如果知道这个人的肤色")
height_in_meters: Optional[str] = Field(default=None, description="以米为单位的高度")
structured_model = model.with_structured_output(schema=Person)
messages = [
SystemMessage(content="你是一个提取信息的专家,只从文本中提取相关信息。如果您不知道要提取的属性的值,属性值返回null"),
HumanMessage(content="史密斯身高6英尺,金发。")
]
result = structured_model.invoke(messages)
print(result)3.2.2 场景2:使用"少样本提示"来增强信息提取能力
3.2.3 场景3:与工具结合使用
注意,使用聊天模型原生的工具搭配结构化输出并不好用!!!这里只是了解下其能力。更好的用法 见LangGraph Agent 能力。
拆解能力,单独依次执行
当需要同时使用结构化输出和其他工具时,需要注意顺序,不要弄反:
-
首先绑定工具
-
其次添加结构化输出

python
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from pydantic import BaseModel, Field
# 定义模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义工具
tool = TavilySearch(max_results=4)
# 绑定工具
model_with_tools = model.bind_tools([tool])
# 定义消息列表
messages = [
HumanMessage("北京今天的天气怎么样?")
]
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
for tool_call in ai_message.tool_calls:
tool_message = tool.invoke(tool_call)
messages.append(tool_message)
class SearchResult(BaseModel):
"""结构化搜索对象"""
query: str = Field(description="搜索查询")
findings: str = Field(description="查询结果摘要")
model_with_structured = model_with_tools.with_structured_output(SearchResult)
print(model_with_structured.invoke(messages))4. 聊天模型--流式传输
流式处理对于使基于 LLM 的应用程序能够响应最终用户至关重要。其通过逐步显示输出,甚至在完整的响应准备就绪之前,流式传输可以显着改善用户体验。
之前直接使用invoke 的调用方式属于非流式传输 ,看到的现象是聊天模型直接返回全量内容 ,若
模型思考时间较长,则我们等待的时间就越长。
我们使用的deepseek客户端就是属于流式输出。可以看到输出时间快了很多

对于 LangChain 的聊天模型来说,它同样支持流式返回。
4.1 stream() 同步传输
LangChain 聊天模型中的**.stream() 方法** ,来同步生成流式响应的效果,.stream() 方法返回一个迭代器,该迭代器在生成输出时同步产生输出 消息块 。可以 使用 for 循环实时处理每个块。
python
from langchain_deepseek import ChatDeepSeek
model=ChatDeepSeek(model="deepseek-v4-flash")
#流式输出,返回一个迭代器,产生的消息块
chunks=[]
for chunk in model.stream("写一段关于龟兔赛跑的故事,20字左右"):
chunks.append(chunk)
#chunks:AIMessage
print(chunk.content,end="|",flush=True)
#我们得到了一个叫做 AIMessageChunk 的东西,它代表 AIMessage 的一部分,也就是消息块。
#消息块还可以直接相加
print("\n")
temp_chunks=chunks[0]+chunks[1]+chunks[2]+chunks[3]+chunks[4]+chunks[5]
print(temp_chunks)
4.2 astream() 异步传输
想象一个场景:你需要煮一壶水,同时还要给朋友发一条短信。我们分别用同步(传统)和异步两种 方式来完成,以此对比并引入 协程 和 事件循环 的概念
• 同步(阻塞)方式:这就像是一个"死心眼"的人,做事必须一件一件来:
python
import time
#同步io
def boil_water():
print("开始烧水...")
time.sleep(5)#模拟烧水5s,cpu完全空闲
print("烧水完成...")
def send_message():
print("开始发消息...")
time.sleep(2)
print("发消息完成...")
def main():
boil_water()
send_message()
#耗时七秒
main()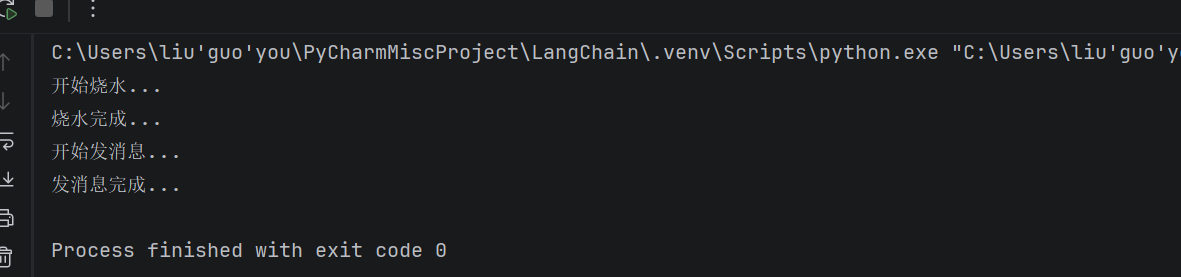
问题: 在 boil_water 函数等待的5秒里,CPU 完全空闲,但却不能去做 send_message 任务, 效率低下。
• 异步方式:我们请出 asyncio 、 协程 和 事件循环 。
什么是协程?
• 多进程通常利用的是多核 CPU 的优势,同时执行多个计算任务。每个进程有自己独立的内存管 理,所以不同进程之间要进行数据通信比较麻烦。
• 多线程是在一个 cpu 上创建多个子任务,当某一个子任务休息的时候其他任务接着执行。多线程 的控制是由 python 自己控制的。线程存在数据同步问题,所以要有锁机制。
• 协程的实现是在一个线程内实现的,相当于流水线作业。由于线程切换的消耗比较大,所以对于 并发编程,可以优先使用协程。
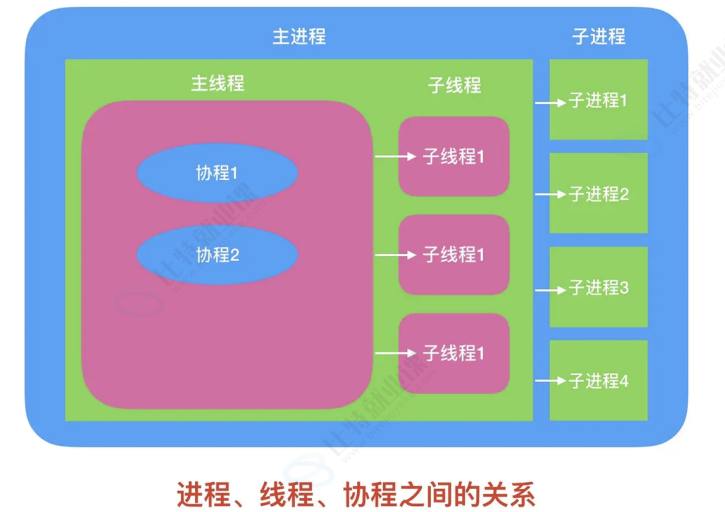
协程,作为一种轻量级的并发编程模型,可以被视为用户态的"轻量级线程"。
其核心优势在于**其调度完全由用户空间掌控,**避免了操作系统内核的频繁介入,从而显著降低了上 下文切换的开销。
在诸如网络数据刷新、资源加载、用户界面更新、以及 I/O 读写等场景下,如果并 发任务的计算量相对较小、对系统资源占用较低,则不必动用操作系统级别的线程。
协程的切换则由程序员和编程语言控制 ,程序员决定在何时暂停或恢复协程。协程是一个特殊的函 数,它可以在执行过程中暂停,并在稍后恢复执行 。它用 async def 定义,并在需要暂停的地方使 用 await。
python
#异步IO
import asyncio
#协程
async def boil_water():
print("开始烧水...")
await asyncio.sleep(5) #await表示等待这个操作完成,但期间可以做别的事
print("烧水完成...")
#协程
async def send_message():
print("开始发消息...")
await asyncio.sleep(2)
print("发消息完毕...")
#协程调度
#事件循环
async def main():
#创建两个任务,并交给事件循环去调度
#1、烧水,任务1
task1=asyncio.create_task(boil_water())
#2、发消息。任务2
task2=asyncio.create_task(send_message())
#等待两个任务完成
await task1
await task2
#run会创建一个事件循环
#5s
asyncio.run(main())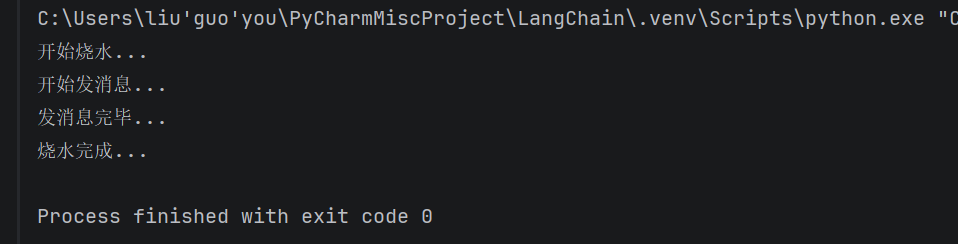
事件循环
事件循环是asyncio(python标准库中的模块,用于编写异步I/O操作的代码)的核心,可以把它当作一个总调度员
工作流程:
1、他维护一个任务列表
2、不断循环检查每个任务
若任务处于"等待I/O状态"(比如等水烧开..)就暂停他,立即去执行下一个已经就绪的任务;
若任务等待时间到了或者I.O操作完成了,事件循环就恢复执行该任务
python
# 主程序(也是一个协程)
async def main():
# 创建两个任务,并交给事件循环去调度
task1 = asyncio.create_task(boil_water_async())
task2 = asyncio.create_task(send_message_async())
# 等待两个任务都完成
await task1
await task2
# 它负责创建事件循环,并将第一个协程(主程序)放入其中运行。
asyncio.run(main())通过asyncio,可以在单线程中同时处理多个任务。**一个在单线程内调度和管理所有协程 的核心机制,就是事件循环。**它不停地检查哪些协程可以执行,哪些在等待。
总结
• 协程是 asyncio 的核心概念之一。他是一个特殊函数,可以在执行过程中暂停,稍后可以恢复
协程通过async def关键字定义。通过await关键字暂停执行,等待异步操作完成
使用asyncio.run()函数运行一个协程。他会创建一个事件循环,并运行指定的协程。事件循环是 asyncio 的核心组件,负责调度和执行协程。它不断地检查是否有任务需要执 行,并在任务完成后调用相应的回调函数。
使用.astream(),异步生成流式响应
使用 .astream() 方法,来异步生成流式响应的效果,这专为非阻塞工作流程而设计。可以在 异步代码中使用它来实现相同的实时流式处理行为。
python
import asyncio
from langchain_deepseek import ChatDeepSeek
model=ChatDeepSeek(model="deepseek-v4-flash")
#异步流式输出
async def async_stream():
print("====异步调用====")
async for chunk in model.astream("写一段关于春天的故事。100字"):
print(chunk.content,end="|",flush=True)
asyncio.run(async_stream())
4.3 使用 StrOutputParser 解析模型的输出
StrOutputParser 是 LangChain 中最基础的输出解析器。
它的核心作用,是将聊天模型返回的复杂**AIMessage 对象,解析并提取为最纯净的字符串文本。**
LLM 返回的原始结果是一个包含大量元数据的对象(如令牌用量、模型名称、响应ID等)。在大多数应用场景下,我们只关心回复的文本内容。StrOutputParser 就是专门负责完成这个"过滤与提取"工作的组件。
python
from langchain_core.output_parsers import StrOutputParser
from langchain_deepseek import ChatDeepSeek
#组件1:聊天模型
model=ChatDeepSeek(model="deepseek-v4-flash")
#2、初始化解析器
parser=StrOutputParser()
chain=model | parser
result=chain.invoke("简单介绍deepseek-v4")
print(result)
流式输出的兼容由于构建出的链本身也是标准的 Runnable 对象,它完美地继承了流式处理能力。在流式场景下,解析器会自动将每一个流式消息块转换为对应的字符串片段。
python
from langchain_core.output_parsers import StrOutputParser
from langchain_deepseek import ChatDeepSeek
#组件1:聊天模型
model=ChatDeepSeek(model="deepseek-v4-flash")
#2、初始化解析器
parser=StrOutputParser()
chain=model | parser
for chunk in chain.stream("简单介绍Claude"):
print(chunk,end="")
注意:
流式传输不是聊天模型的专属特性,而是所有遵循 Runnable 接口标准的组件所共有的"标准能力"。
可以借助"USB接口标准"这个类比来理解:
-
聊天模型、输出解析器、处理链等,都像是按照"Runnable"(USB标准)设计的不同设备(U盘、鼠标、键盘)。
-
流式传输
.stream(),就像"即插即用"一样,是这个标准本身定义好的一项通用功能。 -
因此,只要是
Runnable的实例,原则上都可以调用.stream()方法,这是一种基于接口规范的、而不是具体类别的能力。
实践中需要注意的三点
-
"流出"的数据类型各不相同
虽然都能流式输出,但不同组件流出的"数据块"类型完全不同。例如:
-
聊天模型 直接
.stream(),产出的是AIMessageChunk对象。 -
"模型 + 解析器"构成的链 对流式输出的每个
AIMessageChunk做了处理,再.stream(),产出的就是纯净的str字符串。
-
-
并非所有组件都支持流式
即便实现了
Runnable接口,部分组件因其工作性质,不提供流式处理(或流式无意义)。例如,检索器 (Retrievers) 是一次性返回全量检索结果的,过程无法拆分,因此对它调用.stream()也只会获得一次性返回的结果,没有逐令牌生成的过程。 -
链式调用是常态
在实际开发中,几乎不会单独使用模型的原生流,绝大多数情况下,都是通过构建链(Chain)的方式,利用解析器将流式消息处理为最终想要的格式(如字符串)再进行流式输出。
4.4 自定义流式输出解析器
一个思维模式的转变 :从这一节开始,我们要明白,自定义流式解析器的任务,就是对流经的数据进行任意的加工和重组。它不再局限于提取内容,而是可以改变数据的形态。
StrOutputParser,它能帮我们把大模型返回的复杂消息块,变成纯净的字符串,并且在流式输出时,也是一个字一个字地往外蹦。
但这带来了一个新问题:如果我们不想看一个字一个字地蹦,而是想等模型"说"完一句话,再把这句完整的话显示出来,该怎么办?
这就引出了这一节的核心:自定义流式输出解析器 。它允许我们通过写一个生成器函数 ,来任意地改变流式输出的"节奏"和"样式"。在链中使用 生成器函数,即可完成自定义流式输出的能力。
聊天模型的 .stream() 方法返回的是一个迭代器,该迭代器在生成输出时同步产 生输出 消息块 。那么我们的将实现的这些生成器的签名应该是IteratorInput -> IteratorOutput 。它规定了我们写的生成器函数,必须接收一个"流"(迭代器)作为输入,并且也返回一个"流"(迭代器)作为输出。这样就能完美地嵌入到 model | parser 这个管道里。或者对于异步生成器:AsyncIteratorInput -> AsyncIteratorOutput 。
python
from typing import Iterator, List
from langchain_core.output_parsers import StrOutputParser
from langchain_deepseek import ChatDeepSeek
#组件1:聊天模型
model=ChatDeepSeek(model="deepseek-v4-flash")
#组件2:输出解析器(str)
parser=StrOutputParser()
#自定义生成器
def split_into_list(input:Iterator[str])->Iterator[List[str]]:
#创建一个空字符串变量buffer
buffer=""
for chunk in input:
buffer += chunk
#遇到句号需要刷新buffer
while"。" in buffer:
#找到句号的位置
stop_index=buffer.index("。")
#yield用于创造生成器
#buffer[:stop_index]是切片,取开头到句号位置(stop_index)之前的所有字符
#.strip() 去掉字符串前后的空白字符(空格、换行等)。
yield [buffer[:stop_index].strip()]#外面套上 [ ... ] 表示把这个字符串放进一个列表里。
#yield [buffer[:stop_index].strip()] ------ 这是生成器的关键。
# yield 有点像 return,但不会结束函数,而是"返回一个值,然后暂停函数,下次调用时继续"。
# 这里返回的是一个列表,列表中只有一个元素:buffer[:stop_index].strip()。
buffer=buffer[stop_index+1:]
#处理buffer最后几个字
yield [buffer.strip()]
#定义链。
# 构建处理链:模型 -> 字符串解析器 -> 我们自定义的句子分割器
chain=model | parser | split_into_list
#流式输出,返回一个迭代器,产生的消息块
for chunk in chain.stream("写一段关于爱情的歌词,需要5句话,每句话中文句号隔开"):
#使用parser,结果就是str
print(chunk,flush=True)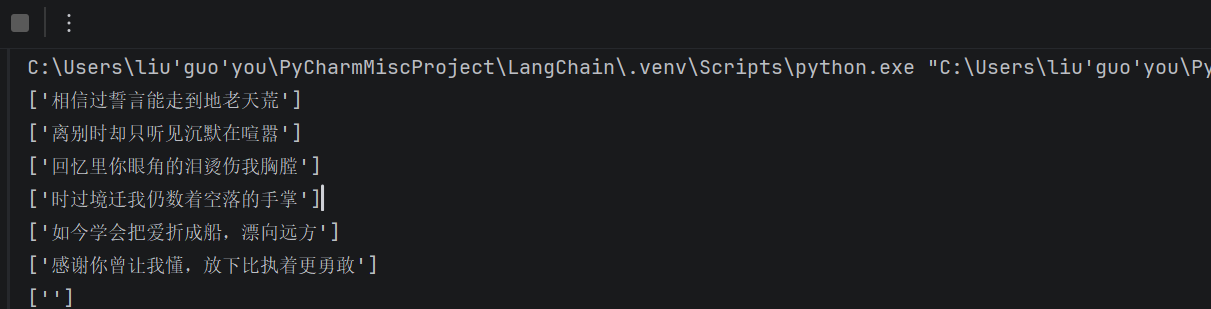
4.5 深度探索流式传输
我们需要从源码层面回答三个根本性问题:
-
LangChain 请求 OpenAI 时,底层使用什么网络协议?
-
LangChain 如何实现并支持流式传输?
-
OpenAI 返回的原始数据块是何格式? LangChain 如何将其转换为标准的
AIMessageChunk对象?
SSE 协议介绍
流式传输并非 LangChain 自身创造,其根基在于大模型服务商(如 OpenAI)提供的 SSE(Server-Sent Events,服务器发送事件) 支持。
可以将其理解为一种基于 HTTP 的"长连接热线" 。相比传统"一问一答"即关闭的短连接,SSE 建立连接后,服务器可持续向客户端单向推送数据流,直到传输结束。这为流式输出提供了底层物理通道。
HTTP 协议本身设计为无状态的请求-响应模式,严格来说,是无法做到服务器主动推送消息到客户端,但通过Server-Sent Events (服务器发送事件,简称 SSE)技术可实现流式传输,允许服
务器主动向浏览器推送数据流。
SSE(Server-Sent Events)是一种基于 HTTP 的轻量级实时通信协议,浏览器可以通过内置的
EventSource API 接收并处理这些实时事件。
核心特点
• 基于 HTTP 协议:复用标准 HTTP/HTTPS 协议,无需额外端口或协议,兼容性好且易于部署。
• 单向通信机制:SSE 仅支持服务器向客户端的单向数据推送,客户端通过普通 HTTP 请求建立连接后,服务器可持续发送数据流,但客户端无法通过同一连接向服务器发送数据。
• 自动重连机制:支持断线重连,连接中断时,浏览器会自动尝试重新连接(支持 retry 字段指定重连间隔)。
• 自定义消息类型:
客户端发起请求后,服务器保持连接开放。响应头设置Content-Type: text/eventstream,标识为事件流格式,持续推送事件流。
数据格式
服务端向浏览器发送 SSE 数据,需要设置必要的 HTTP 头信息:
python
Content-Type: text/event-stream;charset=utf-8
Connection: keep-aliveLangChain 的流式处理流程(源码层面)
通过分析 BaseChatOpenAI 类中的 _stream 方法,可梳理出以下核心生命周期:
1. 发起请求(建立热线)
LangChain 本身并不"创造"或"规定"一个底层的网络传输协议,而是依赖于其底层的大模型供应商(如 OpenAI)的协议。因此当我们发起请求时,会在请求中设置 stream=True ( _stream() 源码中的第一步),表示OpenAI 服务器将在生成 Response 时向客户端发出数据(server-sent events,SSE)。此时 API会保持 HTTP 连接打开,并以特定格式发送数据。在构建 HTTP 请求时,LangChain 将参数 stream 强制设置为 True。此标志告知 OpenAI 服务器:本次对话需采用 SSE 模式,持续推送生成结果。
# 源码逻辑
kwargs["stream"] = True
payload = self._get_request_payload(messages, stop=stop, **kwargs)2. 接入与接收(监听数据流)
LangChain 使用 openai 官方 SDK 构建的 HTTP 客户端(具体为 _SyncHttpxClientWrapper 类)发起调用,并持续监听来自 https://api.openai.com/v1 的 SSE 事件流。
3. 核心转换(数据"本土化")
这是最关键的一步。OpenAI 通过 SSE 推送的原始数据,是一系列包含 delta 字段的 JSON 对象(例如 "delta":{"content":"你"}),而非 LangChain 可直接使用的消息对象。
这一步的转换工作,由 _convert_chunk_to_generation_chunk 方法完成。它的职责是:
-
输入 :OpenAI 推送的原始 JSON 数据块(
chunk)。 -
处理 :提取
choices[0].delta中的内容。 -
输出 :一个标准的
ChatGenerationChunk对象,其核心属性message就是我们所熟悉的AIMessageChunk实例。
至此,每一块原始的流式数据便被封装成了包含 content、response_metadata 等完整信息的 AIMessageChunk 对象,可供下游组件统一处理。
数据转换结构对比
| 阶段 | 数据格式 | 示例内容 |
|---|---|---|
| OpenAI 原始 SSE 数据块 | JSON 对象 | {"choices":[{"delta":{"content":"你"}}]} |
| LangChain 转换后 | AIMessageChunk |
content='你', additional_kwargs={...} |
总结
-
技术基石:流式传输能力由模型服务商基于 SSE 协议提供,LangChain 是这一能力的使用者和封装者。
-
核心机制 :LangChain 通过在请求中开启
stream=True启用 SSE,并在客户端内部实现了一套从"原始 JSON 事件流"到"AIMessageChunk对象序列"的完整转换逻辑。 -
深入价值:掌握此流程,有助于开发者理解流式处理的全链路,便于日后进行定制化开发或排查相关问题。至此,我们从底层的网络协议,到上层的对象封装,完成了对流式传输的深度剖析。
LangChain流式传输的完整流程与底层协议。总结一下:
-
langchain-openai 包通过集成 OpenAI Python SDK,提供了一个 HTTP 客户端。
-
因此,支持 LangChain 向 OpenAI 的 API 发起调用请求。
-
若希望发起流式传输请求,则需在请求中加入 stream=True ,向 OpenAI 说明以 SSE 协议进行
流式返回。
- LangChain 接收 OpenAI 的 SSE 格式的响应,并将其转换为 LangChain 自封装的消息格式,如
AIMessageChunk 消息。这样就可以以统一的方式处理来自不同模型提供商(OpenAI,
Anthropic等)的流式响应。
5. 使用 LangSmith 跟踪 LLM 应用
使用 LangSmith 时没有代码介入,只需要配置下环境,就可以直接监控我们的应用。
使用 LangChain 构建的许多应用程序,可能会包含多个步骤和多次的 LLM 调用。随着这些应用程序变得越来越复杂,作为开发者,我们能够检查链或代理内部到底发生了什么变得至关重要。最好的方法是使用 LangSmith。
LangSmith 与框架无关,它可以与 langchain 和 langgraph 一起使用,也可以不使用。LangSmith 是一个用于帮助我们构建生产级 LLM 应用程序的平台,它将密切监控和评估我们的应用。
LangSmith 平台地址:https://smith.langchain.com/ (新用户需要注册)
要想让 LangSmith 跟踪 LLM 应用,第一步申请 LangSmith API Key,点击 Settings,就会跳转
到"API Keys"设置页面,若没有跳转,可以在左侧 tab 栏中找到进入。
创建完成后,保存好你的 API Key。
接下来配置两个环境变量:
LANGSMITH_TRACING="true"
LANGSMITH_API_KEY="你的 LangSmith API Key"
配置完成后,我们任意执行代码,查看 LangSmith 平台,这将在 LangSmith 的默认跟踪项目中生成调用的跟踪。跟踪会以瀑布流形式展示调用的完整步骤,以及每个步骤的详细信息和耗时。让我们能够检查内部到底发生了什么!