背景
由于产品包装设计或成分变更、不同工厂批次生产等因素,部分商品会生成新的upc,而在一些特殊场景下,需要识别定位出商品的具体UPC,通过外包装照片识别解析出upc成为了成本相对最低的一种方案。
方案
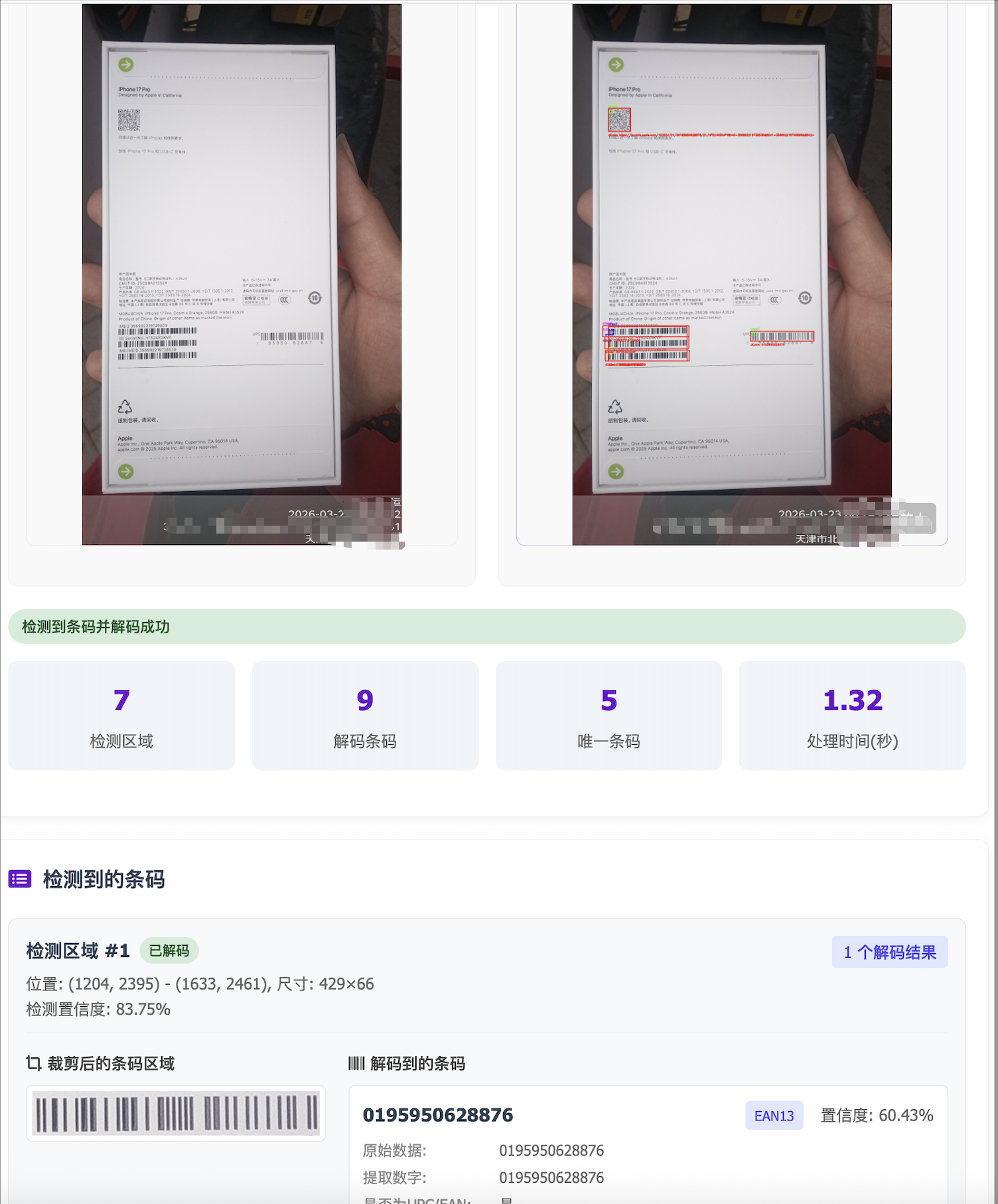
直接使用解码工具在整个照片上进行解码,解码成功率不足50%,本方案采用三步流程实现图像中的条码识别:
目标检测:使用目标检测算法模型定位图像中的条码区域,输出检测框
图像裁剪:基于检测框利用 OpenCV 提取条码子图;
解码识别:调用 zbar、zxing等解码工具 对裁剪后的条码区域进行解码,输出条码内容结果
一、目标检测算法框架对比
1.1 主流目标检测算法分类
目标检测算法经过多年发展,主要形成三大技术路线:
- 两阶段检测器:如Faster R-CNN,首先生成候选区域,再对每个区域进行分类和回归。精度高但速度慢。
- 单阶段检测器:如SSD、RetinaNet、YOLO系列,直接通过单个网络完成分类与定位,速度快但早期精度略低。
- 基于Transformer的检测器:如DETR(Detection Transformer),利用Transformer架构进行端到端检测,简化了后处理流程,但训练收敛慢、计算量大。
1.2 典型算法性能对比
以下基于COCO数据集(val2017)的公开评测结果,对比各主流算法的代表模型:
| 算法 | 骨干网络 | mAP@0.5:0.95 | 输入尺寸 | 推理速度(V100) | 参数量 | 特点 |
|---|---|---|---|---|---|---|
| YOLOv8-x | CSPDarknet | 54.2% | 640 | 11 FPS | 68.2M | 高精度实时检测 |
| YOLOv8-n | CSPDarknet | 37.3% | 640 | 120 FPS | 3.2M | 极致轻量化 |
| YOLOv12-n | Transformer | 39.5% | 640 | 130 FPS | 2.6M | 注意力机制轻量版 |
| Faster R-CNN | ResNet-101 | 42.0% | 800 | 7 FPS | 60M | 典型两阶段,精度稳但慢 |
| SSD512 | VGG16 | 31.2% | 512 | 22 FPS | 26M | 早期单阶段,小目标弱 |
| RetinaNet | ResNet-101 | 39.1% | 800 | 10 FPS | 55M | Focal Loss解决类别不平衡 |
| DETR | ResNet-50 | 42.0% | 800 | 6 FPS | 41M | 端到端,训练收敛慢 |
注:速度数据基于不同硬件和优化,仅供参考相对趋势。
兼顾工程部署易用性及精度,YOLO是当前场景的最佳选择。
1.3 YOLO的核心优势
1. 速度与精度的极致平衡
YOLO系列始终是实时检测领域的标杆。在同等精度下,YOLO的推理速度显著优于两阶段算法;在同等速度下,YOLO的精度又普遍高于SSD、RetinaNet等单阶段算法。YOLOv8-x以54.2%的mAP达到了11 FPS的推理速度,而Faster R-CNN达到相近精度时速度仅为其1/3。
2. 端到端单次推理
不同于两阶段算法需要候选区域生成和二次精修,YOLO采用网格划分+直接回归的方式,一次前向传播即可完成所有目标的定位与分类,训练和部署流程简化,延迟稳定可控。
3. 极强的工程化生态
- 易用性 :Ultralytics提供了统一的命令行接口(
yolo detect train/predict)和Python API,几行代码即可完成训练到部署。 - 多平台支持:官方原生支持导出ONNX、TensorRT、CoreML、TFLite、OpenVino等格式,无缝对接移动端、边缘端、云端。
- 持续迭代:从YOLOv5到YOLOv12,以及最新发布YOLO26,每个版本都保持向后兼容,社区活跃,文档完善。
4. 对小目标与密集场景的优化
YOLOv8及后续版本通过多尺度特征融合(PANet)、动态标签分配、注意力机制等设计,显著提升了对小目标和重叠物体的检测能力。相比之下,SSD和Faster R-CNN在小目标检测上表现较弱,DETR在密集场景下容易出现漏检。
5. 灵活的自定义能力
YOLO支持通过修改配置文件或入参直接调整学利率、批次大小等超参数,无需改动代码即可适配特定任务。配合Ultralytics提供的自动超参数搜索、数据增强组合等功能,能够快速适配工业场景。
6. 统一的多任务框架
Ultralytics将检测、分割、姿态估计、跟踪等功能集成在同一框架下,用户仅需更换任务参数即可无缝切换,降低了学习成本和开发复杂度。
二、YOLO核心原理
2.1 从YOLOv8到YOLO26的技术迭代
YOLO系列的发展历程体现了实时目标检测领域的技术革新。自Ultralytics于2023年1月发布YOLOv8以来,该框架经历了多次重要迭代,每次更新都带来了架构与性能的突破。摘选部分关键迭代版本简要介绍。
YOLOv8的核心创新:
YOLOv8作为承前启后的重要版本,引入了解耦头设计,将分类与回归任务分离为独立卷积分支。实验数据显示,这一改进使mAP提升2.3%,尤其在密集场景下效果显著。同时,动态标签分配机制采用TaskAlignedAssigner策略,通过预测框与真实框的IoU及类别置信度动态分配正负样本,有效解决了传统固定阈值导致的样本不平衡问题。
在骨干网络方面,YOLOv8融合了CSPNet与ELAN(Efficient Layer Aggregation Network)架构,通过跨阶段特征融合减少计算冗余。以YOLOv8-s为例,参数量较YOLOv5-s减少23%,推理速度提升18%。
YOLOv12的注意力架构革新:
YOLOv12引入了一种以注意力为中心的架构,与以往YOLO模型中基于CNN的传统方法形成鲜明对比。该版本通过对注意力机制和整体网络架构的创新,在保持实时推理速度的同时,实现了最先进的物体检测精度。值得注意的是,YOLOv12本质上延续了YOLOv8的核心设计理念,在训练和部署流程上保持了高度兼容性。
YOLO26原生的端到端模型
YOLO26是一个原生的端到端模型,直接生成预测结果,无需非极大值抑制(NMS)。通过消除这一后处理步骤,推理变得更快、更轻量,并且更容易部署到实际系统中。引入了MuSGD 优化器,它是 SGD 和 Muon 的混合体------灵感来源于 Moonshot AI 在 LLM 训练中 Kimi K2 的突破。该优化器带来了增强的稳定性和更快的收敛,将语言模型中的优化进展转移到计算机视觉领域。该模型在小对象上实现了更高的精度,提供了无缝部署,并且在 CPU 上的运行速度提高了 43%
通过netron生成yolo26模型结构截取部分如下所示:
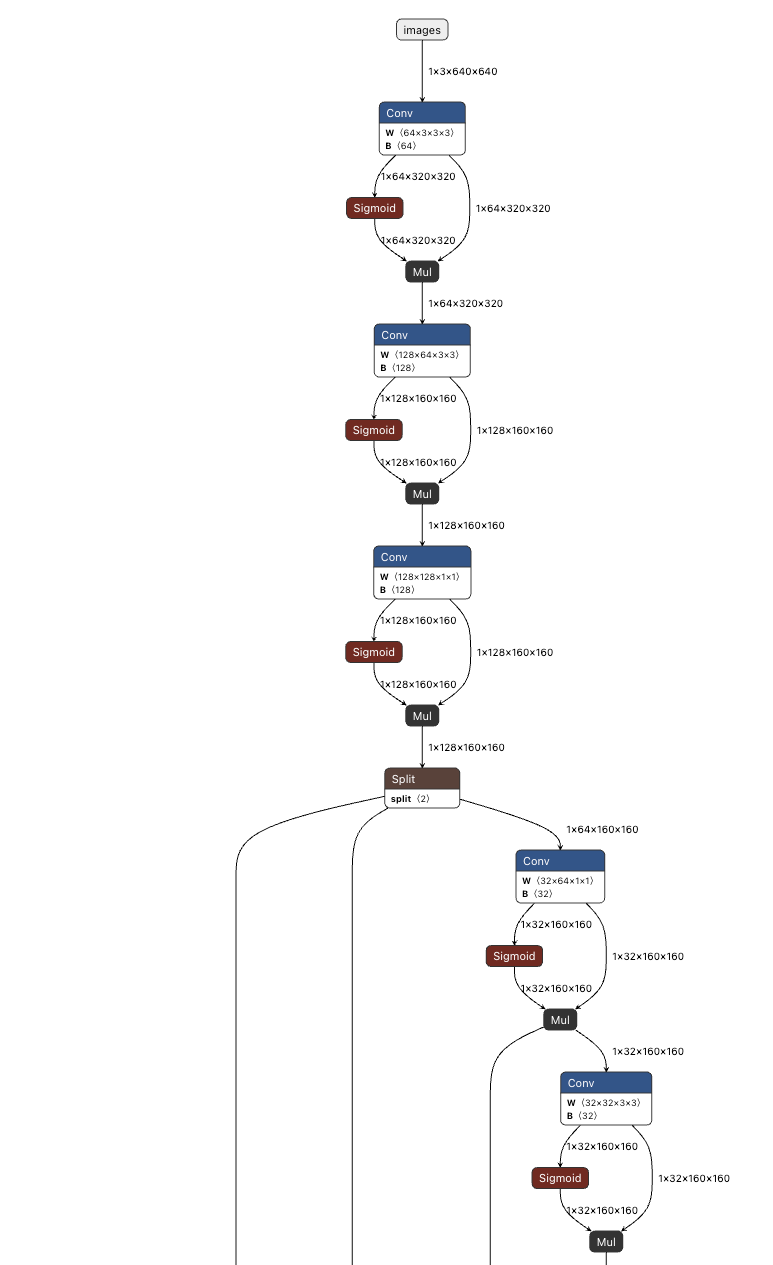
该网络的核心是卷积提取特征+注意力增强的循环模块,通过多次卷积逐层提取从低级(边缘)到高级(语义)的特征,同时用Sigmoid+Mul动态调整特征的重要性,提升模型对关键信息的捕捉能力。
网络遵循经典的 主干 -> 颈部 -> 头部 三段式架构:
- 主干网络 - 特征提取, 大量门控卷积模块,动态地筛选重要特征
- 颈部网络 - 特征融合,结构图的中下部,结构变得非常复杂,出现了大量的分支汇聚,将深层的语义信息(知道"是什么")与浅层的细节信息(知道"在哪里")融合
- 头部网络 - 预测输出, 最底部的节点通常是最终的检测头,输出边界框坐标(Box)、物体置信度(Conf)和类别概率(Class)
2.2 YOLO各版本性能指标对比
根据官方公布的COCO数据集测试结果,各版本模型的性能表现如下:
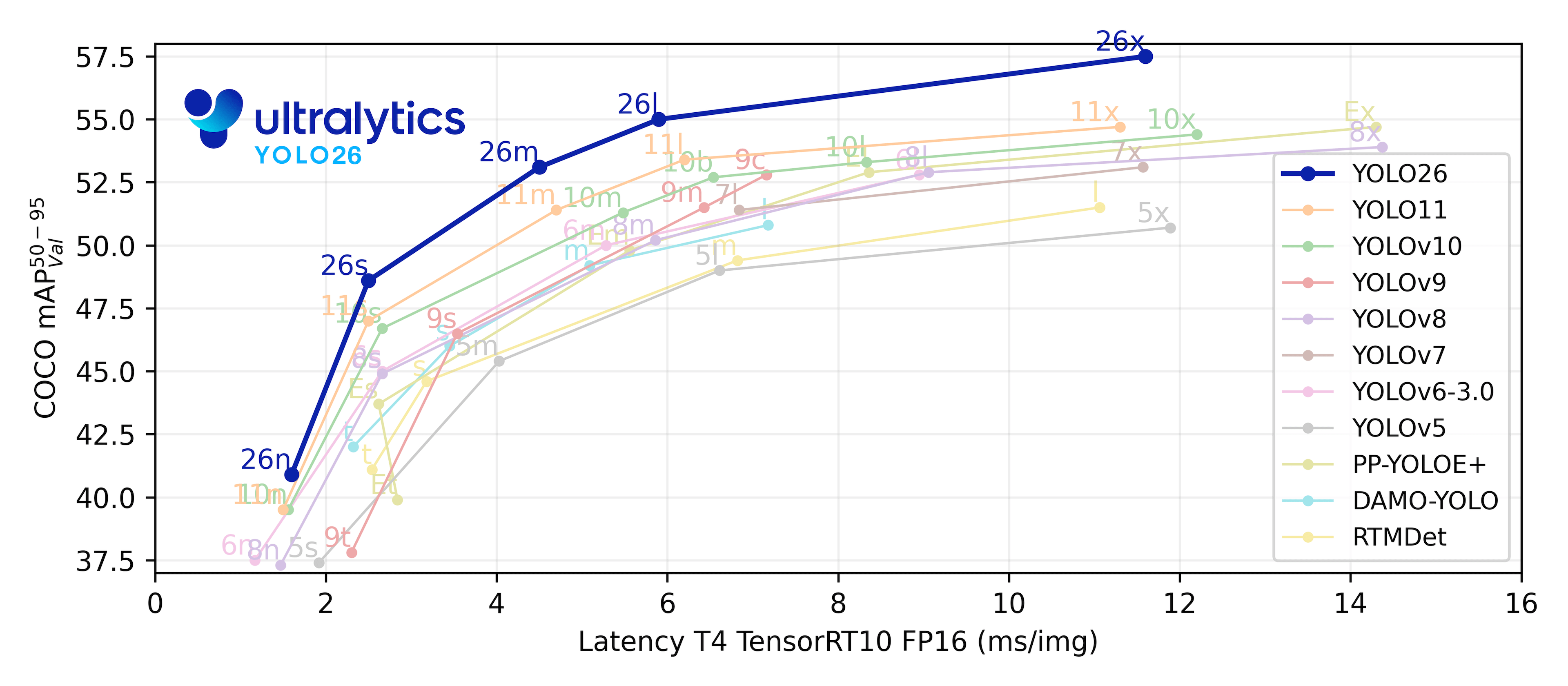
数据来源:Ultralytics官方文档及公开测试报告
新发布的YOLO26版本在各项性能上均优于前代。
三、实践-数据准备与模型训练
3.1 环境配置与数据集构建
环境配置:
使用conda管理Python环境,通过以下命令快速构建标注数据所需环境:
bash
conda env create yoloenv python=3.10
conda activate yoloenv标注工具安装 :
标注工具使用ai辅助的x-anylabel:
安装命令如下:
bash
pip install x-anylabeling-cvhub启动后界面如下:
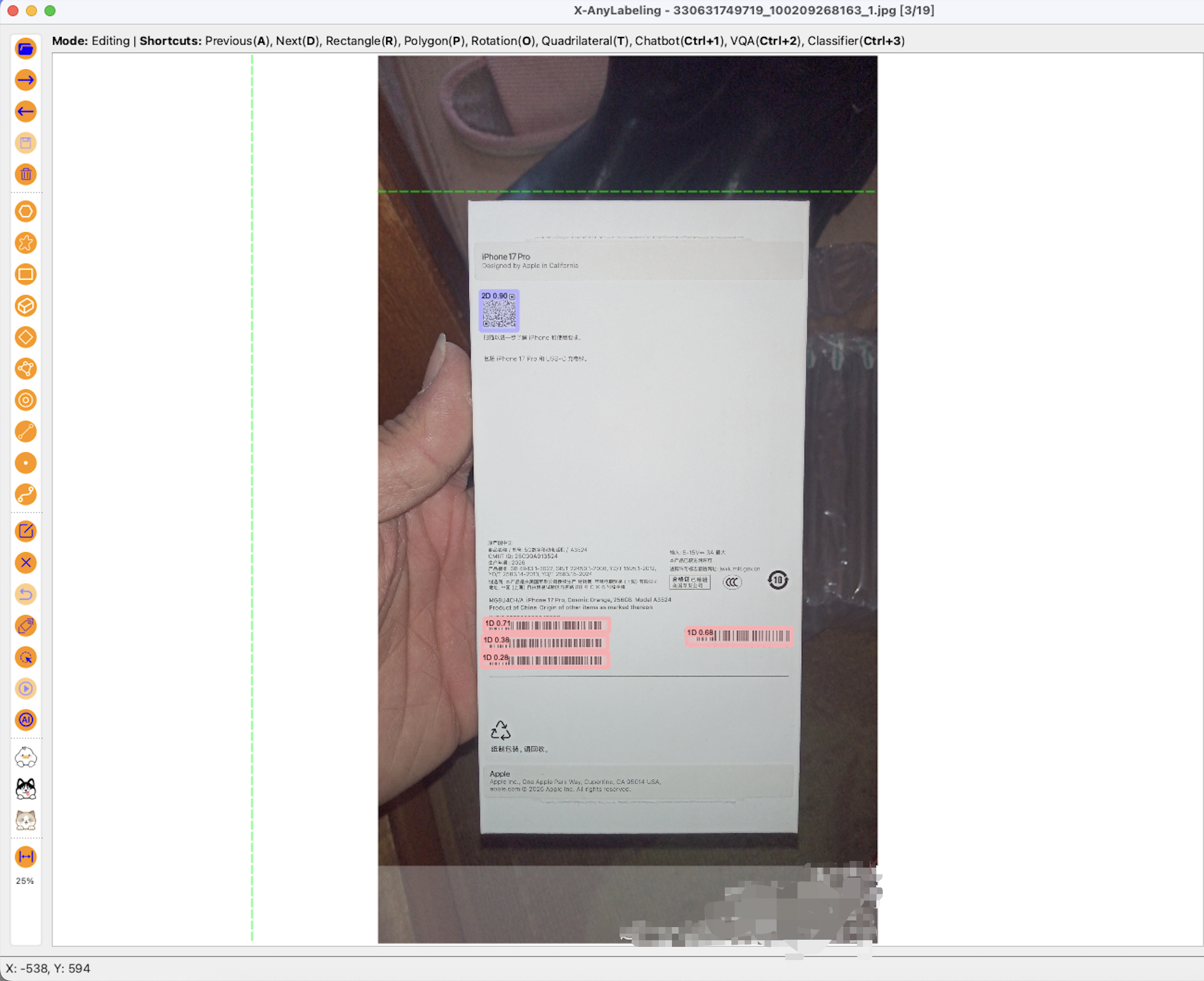
示例中标注了一个二维码、四个一维条码。标注完成的数据,可以直接导出为yolo格式的数据集。
数据集标准结构:
YOLO系列模型要求数据集遵循统一的目录规范:
dataset/
├── images/
│ ├── train/ # 训练集图片
│ └── val/ # 验证集图片
└── labels/
├── train/ # 训练集标注
└── val/ # 验证集标注标注文件格式规范:
针对目标检测,每个图片对应同名的txt文件,内容格式为:
txt
<class_id> <x_center> <y_center> <width> <height>所有坐标需归一化到0,1区间。例如:
0 0.445964 0.579346 0.179253 0.017090 # 类别0,中心点(0.445964, 0.579346),宽高比例3.2 模型训练
模型训练通过平台提供的镜像,可省去大部分环境搭建、配置工作,在docker镜像中已包含了所需依赖例如cuda、torch、torchvision、torchaudio等。
搭建完环境后,上传导入训练数据,具体检测数据集配置如下:
数据集配置文件:
yaml
# data.yaml
path: ${网盘挂载路径}/yolo/train/yolo_barcode_dataset
train: images/train
val: images/val
nc: 2
names: ['1D', '2D']执行训练数据根目录,训练、评估数据集的图片地址,类别数量nc及类别名称。
训练命令:
bash
yolo train data=dataset.yaml model=yolo26m.pt epochs=300 device=cuda workers=8 patience=30其中patience=30 为早停参数,若持续30轮指标无提升则停止训练。
训练过程中自动生成以下文件:
-
best.pt: 最佳权重文件。在验证集上表现最优(通常指 mAP@0.5 或 mAP@0.5:0.95 最高)的模型权重。这是用于部署或进一步推理的推荐文件
-
last.pt: 最后权重文件
-
args.yaml: 训练参数配置文件
-
训练结果汇总 (results.png 与 results.csv)
-
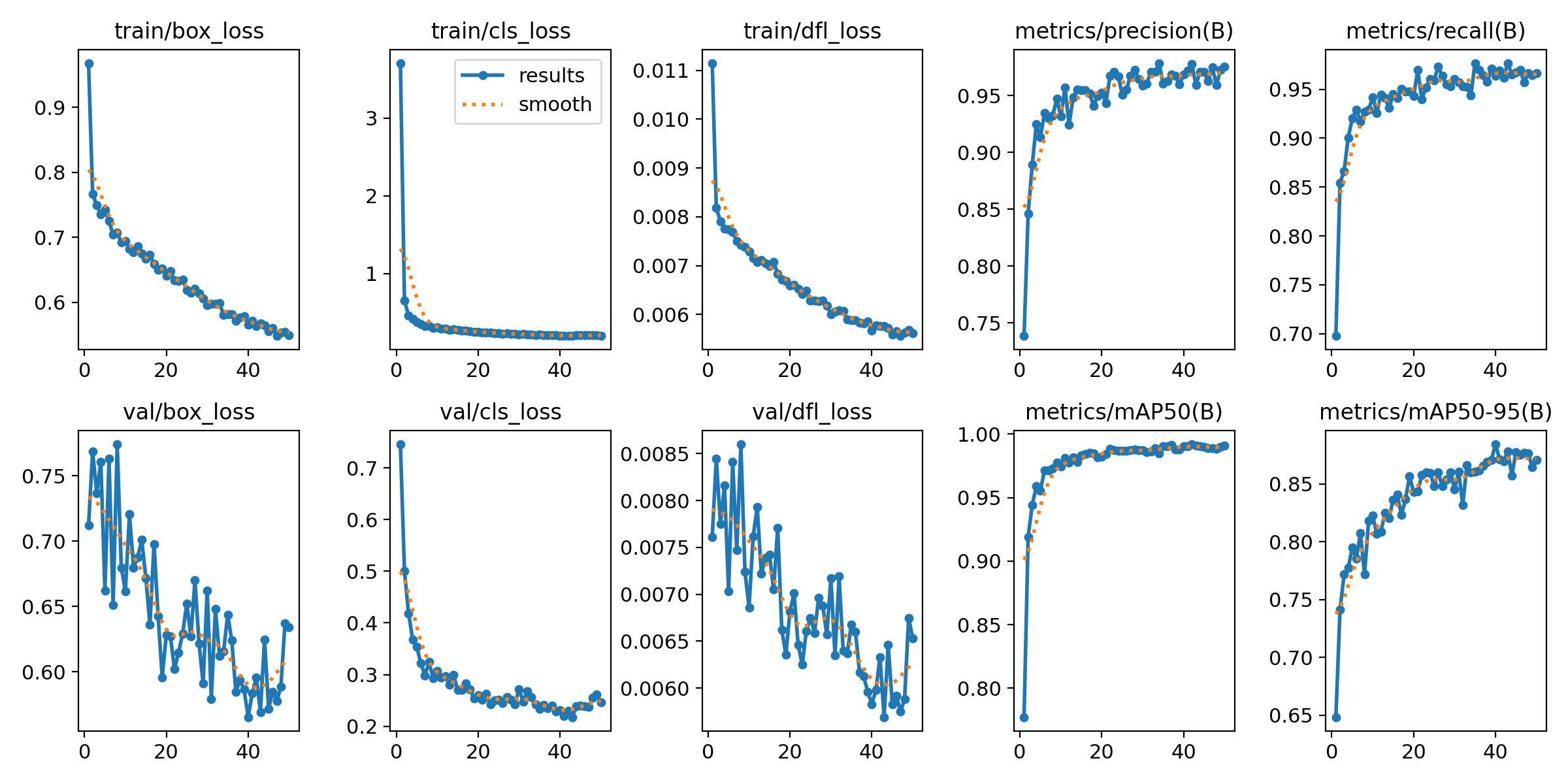
results.png: 训练指标趋势图。一张综合图表,通常包含以下指标随训练轮次(Epoch)的变化曲线:
-
results.csv: 训练指标数据表。以 CSV 格式存储了 results.png 中所有曲线的原始数值数据。
-
-
数据可视化样本
- labels.jpg: 训练集标签可视化。展示一个训练批次中,真实边界框和类别标签在图像上的标注情况,用于验证数据标注是否正确加载。
- train_batch0.jpg, train_batch1.jpg, train_batch2.jpg: 训练批次增强可视化。展示训练初期几个批次的图像,包含了应用的所有数据增强(如翻转、色彩抖动、马赛克等)后的效果,用于检查数据增强策略是否合理。
- val_batch0_labels.jpg: 验证集标签可视化。展示一个验证批次的真实标签。
- val_batch0_pred.jpg: 验证集预测可视化。展示同一个验证批次上,模型(通常是 best.pt)的预测结果,包括预测框、类别和置信度。
3.3 训练结果评估
损失函数分析 :
YOLO训练过程中跟踪三种核心损失:
- box_loss:边界框回归损失(CIoU Loss)
- cls_loss:分类损失(BCE Loss)
- dfl_loss :动态特征损失
损失函数:train/box_loss, train/cls_loss, train/dfl_loss(训练集损失);val/box_loss, val/cls_loss(验证集损失)。损失下降并趋于平稳表明训练有效。
评估指标
-
metrics/mAP@0.5 这是最常用、最宽松的指标,衡量模型在"大致框对位置"时的检测能力。值越高,表示模型在宽松定位要求下性能越好。
-
metrics/mAP@0.5:0.95, 这是更严格、更全面的综合性指标,同时评估模型的定位精度(IoU高)和分类准确性。值越高,表明模型在精确框定目标方面的综合能力越强
-
metrics/precision, 衡量模型的可靠性,高精确率意味着模型"说某个地方有目标时,通常是对的",误报较少
-
metrics/recall, 衡量模型的覆盖能力。高召回率意味着模型"能找出大部分真实目标",漏检较少。
训练过程监控 :
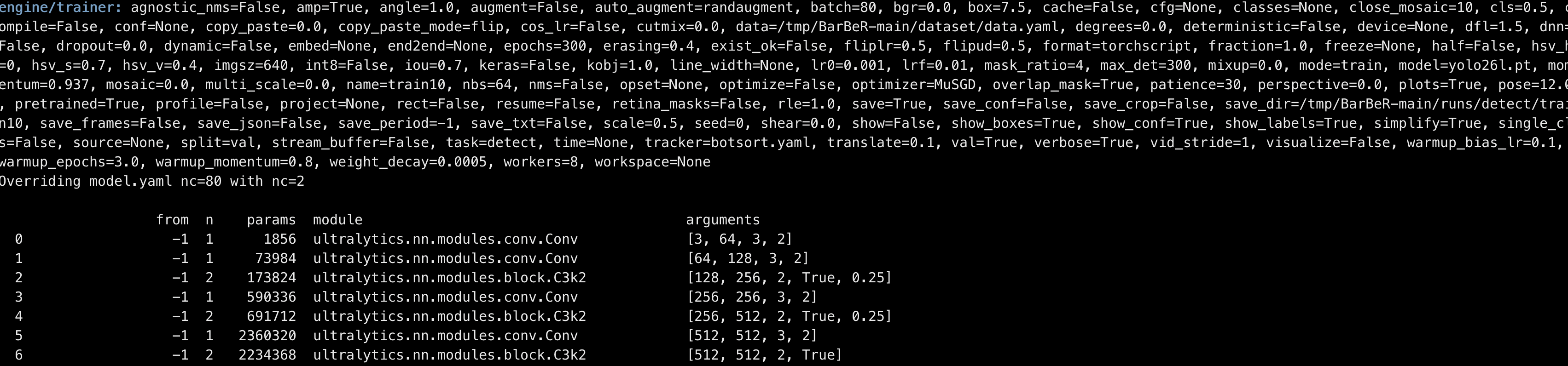
启动训练后,会打印输入的参数及每轮训练的评价指标到控制台:
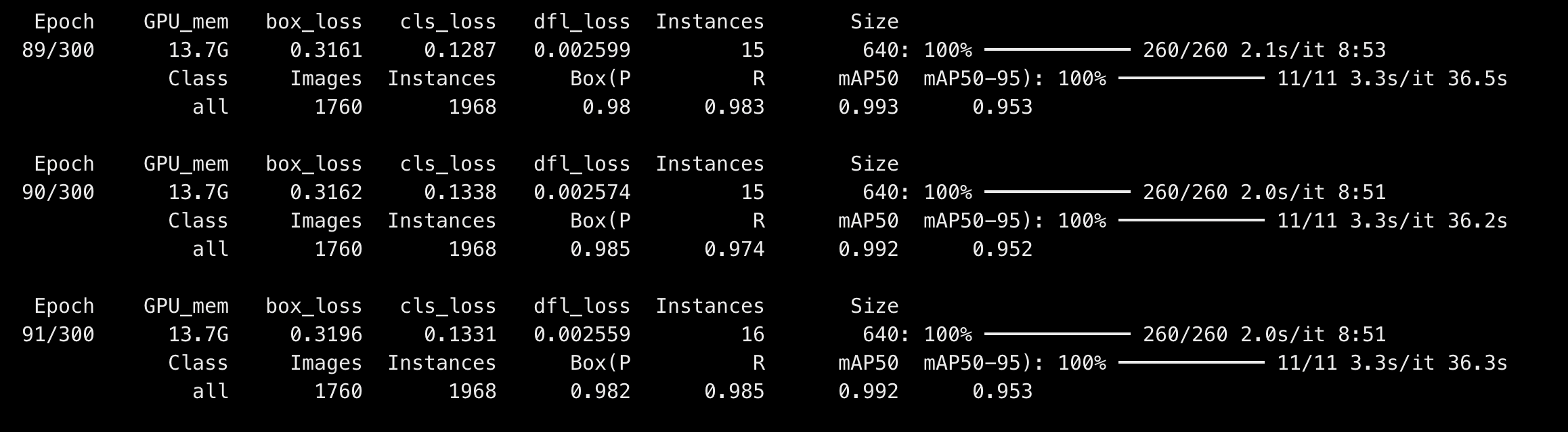
训练完成后,在评估集上运行的指标打印如下:

四、部署-模型转换与推理实践
针对条码识别检测、识别场景,需要同时考虑模型推理性能与图像预处理(二值化、高斯模糊等)、解码能力的集成。以下是ONNX Runtime、DL4j和Python原生方案的对比:
| 维度 | Python原生方案 | ONNX Runtime (Python) | ONNX Runtime (Java) | DL4j (Java) |
|---|---|---|---|---|
| 技术栈 | PyTorch/TF + OpenCV | ONNX Runtime + OpenCV | ONNX Runtime + JavaCV | DL4j + JavaCV |
| 预处理库 | OpenCV/Pillow | OpenCV/Pillow | JavaCV/OpenCV Java版 | JavaCV/DL4j原生 |
| 部署依赖框架 | FastAPI/Flask | FastAPI/Flask | Spring Boot | Spring Boot |
| 预处理性能 | 优秀 | 优秀 | 良好 | 良好 |
| 推理性能 | 中等 | 优秀 | 优秀 | 中等 |
| 开发效率 | 极高 | 高 | 中等 | 中等 |
4.1 多格式模型导出
导出ONNX格式 :
命令行方式
bash
yolo export model=best.pt format=onnx opset=12参数说明:
opset=12:ONNX算子集版本,具体ONNX Runtime 版本与opset适配关系见ONNX Runtime 兼容性
导出OPNEVINO格式 :
脚本方式
python
from ultralytics import YOLO
model = YOLO('YOLO26_Barcode_Detection.pt')
model.export(format='openvino', imgsz=640) 4.2 推理部署&服务化实现
模型加载
在支持openvino时,优先加载openvino格式的,否则退化到pytorch格式的,节选部分代码如下:
python
def __init__(self, model_path: str, conf: float = 0.1, iou: float = 0.2):
self.model_path = model_path
self.default_conf = conf
self.default_iou = iou
self.device = self.get_best_device()
# 检查是否为OpenVINO模型文件
self.use_openvino = False
if OPENVINO_AVAILABLE and (model_path.endswith('openvino_model/')):
try:
logger.info(f"[TOOL] 检测到OpenVINO模型文件: {model_path}")
self.use_openvino = True
self._init_openvino_model(model_path)
except Exception as e:
logger.error(f"[FAILURE] OpenVINO模型初始化失败: {e}")
logger.info("[TOOL] 回退到原始YOLO模型")
self.use_openvino = False
# 获取父目录
parent_dir = os.path.dirname(model_path.rstrip('/')) # 移除末尾斜杠
# 拼接 .pt 文件
pt_filename = "YOLOV26_Barcode_Detection.pt"
torch_model_path = os.path.join(parent_dir, pt_filename)
self.model = YOLO(torch_model_path)
self.model.to(self.device)
else:
logger.info(f"[TOOL] 检测到pt模型文件: {model_path}")
self.model = YOLO(model_path)
self.model.to(self.device)
logger.info(f"[TOOL] 使用设备: {self.device}, 图例模型use_openvino: {self.use_openvino}")
logger.info(f"[TOOL] 模型推理参数 - conf: {self.default_conf}, iou: {self.default_iou}")
@staticmethod
def get_best_device() -> str:
# 获取最佳可用设备
if hasattr(torch.backends, 'mps') and torch.backends.mps.is_available():
return "mps"
elif torch.cuda.is_available():
return "cuda"
else:
return "cpu"
def _init_openvino_model(self, model_path: str):
# 初始化OpenVINO模型
logger.info("[TOOL] 初始化OpenVINO模型...")
# 保存编译后的模型
self.model = YOLO(model_path, task='detect')
logger.info("[SUCCESS] OpenVINO模型初始化完成")图像推理 :
OpenVINO格式模型推理如下,输入Numpy的ndarray格式图片数据、置信度阈值、IOU阈值,返回多个检查框(坐标、类别、置信度),节选关键代码如下:
python
def _detect_barcodes_openvino(self, image: np.ndarray, conf_threshold: float, iou_threshold: float) -> List[Dict[str, Any]]:
# 建YOLO模型实例,封装OpenVINO运行
results = self.model(image, conf=conf_threshold, iou=iou_threshold, verbose=False)
barcode_boxes = []
for result in results:
if result.boxes is not None and len(result.boxes) > 0:
boxes = result.boxes.xyxy.cpu().numpy()
confidences = result.boxes.conf.cpu().numpy()
for box, conf in zip(boxes, confidences):
x1, y1, x2, y2 = map(int, box[:4])
x1, y1 = max(0, x1), max(0, y1)
x2, y2 = min(image.shape[1], x2), min(image.shape[0], y2)
if x2 > x1 and y2 > y1:
barcode_boxes.append({
'bbox': (x1, y1, x2, y2),
'confidence': float(conf)
})
return barcode_boxes条码解码 :
核心通过pyzbar的decode方法实现条码内容的解码,解码成功返回条码内容、格式、位置坐标;
python
def decode_barcode_with_rotation(self, image: np.ndarray, bbox_info: Dict[str, Any],
enable_rotation: bool = False,
pre_process_mothed_bitmap: int = 0) -> List[Dict[str, Any]]:
"""使用旋转和多种预处理方法解码条码"""
x1, y1, x2, y2 = bbox_info['bbox']
if x1 >= x2 or y1 >= y2:
return []
roi = image[y1:y2, x1:x2]
if roi.size == 0:
return []
preprocessing_methods = []
base_methods = [
("原始灰度", lambda img: cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)),
("二值化", lambda img: cv2.threshold(
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY), 0, 255,
cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]),
("高斯模糊", lambda img: cv2.GaussianBlur(
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY), (3, 3), 0)),
("CLAHE", lambda img: cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8)).apply(
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY))),
("直方图均衡化", lambda img: cv2.equalizeHist(
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY))),
]
# 预处理方法集合
preprocessing_methods.extend(base_methods)
for method_name, preprocess_func in preprocessing_methods:
try:
processed = preprocess_func(roi)
decoded_with_current_method = False
for angle in angles_to_try:
try:
if angle != 0:
rotated = self._rotate_image(processed, angle)
else:
rotated = processed
decoded_objs = pyzbar.decode(rotated)
if not decoded_objs:
continue
decoded_with_current_method = True
logger.info(f"启用位{pre_process_mothed_bitmap}的预处理方法,成功解码的预处理方法: method_name={method_name}, angle={angle}")
for obj in decoded_objs:
try:
data = obj.data.decode('utf-8')
confidence = bbox_info['confidence'] * 100
if hasattr(obj, 'quality'):
confidence = confidence * 0.7 + obj.quality * 0.3
if angle != 0:
confidence *= 0.95
# 处理多边形坐标
obj_polygon = []
if hasattr(obj, 'polygon') and obj.polygon:
for point in obj.polygon:
obj_polygon.append((point.x, point.y))
# 旋转角度修正多边形
if obj_polygon and angle != 0:
obj_polygon = self._correct_polygon_for_rotation(obj_polygon, angle, rotated.shape)
# 全局坐标转换
global_polygon = []
for point in obj_polygon:
global_x = x1 + point[0]
global_y = y1 + point[1]
global_polygon.append((global_x, global_y))
# 处理矩形区域
global_rect = None
if hasattr(obj, 'rect') and obj.rect:
rect_left, rect_top, rect_width, rect_height = obj.rect
global_rect = {
'left': x1 + rect_left,
'top': y1 + rect_top,
'width': rect_width,
'height': rect_height,
'right': x1 + rect_left + rect_width,
'bottom': y1 + rect_top + rect_height
}
barcode_info = {
'data': data,
'original_data': data,
'digits': self._extract_digits_from_barcode(data),
'is_upc_ean': self._is_valid_upc_ean(data),
'type': obj.type,
'preprocess_method': method_name,
'rotation_angle': angle,
'rotation_enabled': enable_rotation,
'confidence': round(confidence, 2),
'bbox': bbox_info['bbox'],
'bbox_details': {
'x': int(x1),
'y': int(y1),
'width': int(x2 - x1),
'height': int(y2 - y1)
},
'pyzbar_details': {
'polygon': global_polygon if global_polygon else None,
'rect': global_rect,
'quality': getattr(obj, 'quality', None),
'orientation': getattr(obj, 'orientation', None),
'multiple_codes_found': len(decoded_objs) > 1
}
}
all_decoded_barcodes.append(barcode_info)
except Exception:
continue
except Exception:
continue
if decoded_with_current_method:
break
except Exception:
continue服务接口 :
通过fastapi框架,提供相关的http接口
python
@app.post("/api/analyzeImage", summary="分析图片接口")
async def analyze_image(request: AnalyzeImageRequest):
data = request.dict()
has_image = data.get('imageUrl')
if not has_image:
return create_response({'error': '请提供图片数据(URL或base64)'}, 400, False)
enable_rotation = data.get('enableRotation', app_config.enable_rotation_by_default)
detect_conf = data.get('modelConf', detector.default_conf)
detect_iou = data.get('modelIou', detector.default_iou)
debug_mode = data.get('debug', False)
image_url = data.get('image_url', '')
logger.info(f"分析图片{image_url}, debug模式: {debug_mode}")
image = None
# 下载图片
image, status = detector.download_image(data['imageUrl'])
if image is None:
return create_response({'error': f'图片加载失败: {status}'}, 400, False)
# 检测 + 解码
barcodes = detector.detect_barcodes(image, conf=detect_conf, iou=detect_iou)
return create_response(barcodes)4.3 推理性能优化
IntelCPU推理加速处理
使用CPU推理部署时,选择近5年内的CPU型号, cpu flag 包含avx(高级矢量扩展) 指令集的,支持,例如 avx512f avx512dq,实测对比pytorch cpu推理的,平均耗时降低58%
并行推理优化 :
每个处理订单有3张左右照片,通过asyncio 调度实现并行异步处理,由于
python
for args in process_args:
task = process_single_image_by_semaphore(args)
tasks.append(task)
completed = await asyncio.gather(*tasks, return_exceptions=True)
for i, result in enumerate(completed):
if isinstance(result, Exception):
logger.error(f"处理图片 {i+1} 时发生错误: {result}")
results.append(self._create_error_result(process_args[i], download_results, str(result)))
else:
results.append(result)
每个图片的推理分发到推理进程池内的一个推理进程处理:
python
async def process_single_image_by_semaphore(args):
async with self.task_semaphore:
try:
loop = asyncio.get_event_loop()
return await asyncio.wait_for(
loop.run_in_executor(self.process_executor, self._process_single_image_worker, *args),
timeout=30.0
)
except asyncio.TimeoutError:
logger.warning(f"处理图片超时: 参数 {args[:3]}")
self.statistics['task_timeouts'] += 1
return self._create_timeout_result(args, download_results)
except Exception as e:
logger.error(f"处理图片时发生错误: {e}")
error_type = type(e).__name__
self.statistics['task_failures_by_type'][error_type] = \
self.statistics['task_failures_by_type'].get(error_type, 0) + 1
return self._create_error_result(args, download_results, str(e))五、优化篇:指标调优与问题解决
5.1 解码成功率优化策略
图像预处理 :
常用预处理方法的opencv算子示例如下:
python
("原始灰度", lambda img: cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)),
("二值化", lambda img: cv2.threshold(
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY), 0, 255,
cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]),
("高斯模糊", lambda img: cv2.GaussianBlur(
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY), (3, 3), 0)),
("CLAHE", lambda img: cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8)).apply(
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY))),
("直方图均衡化", lambda img: cv2.equalizeHist(
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY))),对于条码解析场景,经过原始灰度、二值化预处理方法解码成功的比例占绝大部分90%以上。
| 方法组 | 算子名称 | 核心作用 | 原理简述 | 典型应用场景 |
|---|---|---|---|---|
| 基础方法 | 原始灰度 | 颜色空间转换,保留亮度信息。 | 将BGR图像转换为灰度图,丢弃颜色信息,简化后续处理。 | 所有灰度图像处理的初始步骤。 |
| 二值化 (Otsu) | 图像分割,将前景与背景分离。 | 自动计算全局阈值,将灰度图转为黑白二值图。 | 文档扫描、目标分割、OCR预处理。 | |
| 高斯模糊 | 降噪与平滑,抑制高频噪声。 | 使用高斯核对图像进行卷积,实现平滑效果。 | 消除细小噪声,为边缘检测等操作做准备。 | |
| CLAHE | 增强局部对比度,改善光照不均。 | 对图像分块进行自适应直方图均衡,防止过度增强。 | 医学影像、低光照或高对比度场景的增强。 | |
| 直方图均衡化 | 增强全局对比度。 | 拉伸图像灰度直方图,使其分布更均匀。 | 整体偏暗或偏亮图像的对比度提升。 | |
| 组1: 自适应阈值 | 自适应高斯阈值 | 局部二值化,适应光照变化。 | 根据像素邻域的高斯加权平均计算局部阈值。 | 光照不均的文档、自然场景文本提取。 |
| 自适应均值阈值 | 局部二值化,计算更高效。 | 根据像素邻域的算术平均计算局部阈值。 | 同上,计算速度略快于高斯方法。 | |
| 组2: 边缘检测 | Sobel边缘 | 检测图像在水平或垂直方向的边缘。 | 使用Sobel算子计算图像的一阶梯度近似值。 | 强调水平和垂直边缘,用于方向性分析。 |
| Canny边缘 | 检测精确、连续的边缘。 | 多阶段算法(高斯滤波、梯度计算、非极大值抑制、双阈值滞后)。 | 标准的边缘检测方法,用于物体轮廓提取。 | |
| 拉普拉斯锐化 | 增强边缘和细节,或检测二阶过零点边缘。 | 使用拉普拉斯算子计算图像的二阶导数。 | 图像锐化、边缘检测(对噪声敏感)。 | |
| 组3: 形态学操作 | 开运算 | 消除细小噪声,分离微小连接。 | 先腐蚀后膨胀,可消除小物体。 | 去除椒盐噪声,断开细小连接。 |
| 闭运算 | 填充细小孔洞,连接邻近物体。 | 先膨胀后腐蚀,可填充小孔。 | 填充前景物体中的小洞,连接断点。 | |
| 顶帽变换 | 提取比背景亮的细小区域或细节。 | 原图与开运算结果的差值。 | 提取背景上的亮细节(如文本、细胞)。 | |
| 组4: 滤波降噪 | 中值滤波 | 去除椒盐噪声,同时较好保留边缘。 | 用邻域内像素的中值代替中心像素值。 | 去除椒盐噪声的首选方法。 |
| 双边滤波 | 平滑图像同时保留强边缘。 | 同时考虑空间邻近度和像素值相似度进行加权平均。 | 人像美颜、高保真度的降噪。 | |
| 组5: 组合增强 | CLAHE+高斯 | 先增强对比度再平滑,平衡细节与噪声。 | CLAHE提升细节对比度,高斯模糊抑制可能引入的噪声。 | 需要增强细节但又要控制噪声的医学或工业图像。 |
| 均衡化+二值化 | 全局增强对比度后进行分割。 | 直方图均衡化拉伸对比度后,再用Otsu法二值化。 | 整体对比度低且需要二值化的图像。 | |
| 组6: 色彩空间利用 | LAB亮度通道 | 提取与颜色信息解耦的亮度信息。 | 转换到LAB色彩空间,取L通道(感知亮度)。 | 受颜色干扰小的亮度分析。 |
| HSV值通道 | 提取图像的明度信息。 | 转换到HSV色彩空间,取V通道(亮度值)。 | 对光照变化更鲁棒的亮度分析。 | |
| 红色增强 | 突出或抑制图像中的红色区域。 | 从灰度图中减去一部分红色通道过亮的区域。 | 增强红色目标(如火焰、特定标记)或抑制红色干扰。 | |
| 组7: 梯度特征 | 梯度幅值 | 综合计算图像的整体边缘强度。 | 结合Sobel算子在X和Y方向的梯度,计算总梯度幅值。 | 强调所有方向的边缘,用于纹理分析或显著区域检测。 |
| 组8: 高级处理 | 非局部均值 | 高级降噪,能更好保留纹理。 | 利用图像中所有像素的相似性进行加权平均去噪。 | 去除高斯噪声等复杂噪声,且需保留细节。 |
| 透视校正 | 校正图像的几何透视畸变。 | 通过检测角点或标记,计算透视变换矩阵进行校正。 | 文档、标牌等平面物体的正面化校正。 |
角度旋转 :
在-45° ~ +45°之间,每隔15°进行旋转后,尝试解码。具体图像旋转实现如下所示:
python
def _rotate_image(image: np.ndarray, angle: float) -> np.ndarray:
"""旋转图像"""
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
rotated = cv2.warpAffine(image, M, (w, h), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
return rotated检测框扩大:
python
# 解码失败,尝试扩大bbox边框10%后再次解码
img_h, img_w = image.shape[:2]
x1, y1, x2, y2 = bbox_info['bbox']
# 计算扩大后的bbox
bbox_width = x2 - x1
bbox_height = y2 - y1
# 计算扩展量(10%)
expand_w = int(bbox_width * 0.1)
expand_h = int(bbox_height * 0.1)
# 扩大bbox,确保不超出图片边界
new_x1 = max(0, x1 - expand_w)
new_y1 = max(0, y1 - expand_h)
new_x2 = min(img_w, x2 + expand_w)
new_y2 = min(img_h, y2 + expand_h)
# 创建扩大后的bbox_info
expanded_bbox_info = bbox_info.copy()
expanded_bbox_info['bbox'] = (new_x1, new_y1, new_x2, new_y2)5.2 常见问题解决
每轮训练较慢:
解决方案:
- 在内存、显存允许情况下,加大batch大小:
batch=48 - 图片预处理速度跟不上GPU计算能力,增加worker个数到CPU核数,:
workers=8 - 数据集从网盘复制到本地磁盘或启用cache,预先将图片处理为Python内的图片数据结构
- 使用混合精度训练:
--amp
缺少opencv、zbar库
解决方案:
定制镜像,基础环境中安装相关依赖库
Dockerfile
RUN yum install -y opencv opencv-devel opencv-python libffi-devel zbar-devel mesa-libGL六、总结与规划
本方案成功构建了一个基于YOLO的条码识别系统,通过 YOLO精准定位 与 多层次预处理/解码策略的结合,解决了商品外包装条码定位、解码问题。并通过并行化与cpu硬件加速,在仅CPU推理下满足了生产的吞吐要求。
仍存在5%左右的复杂案例图片(如极度模糊、严重形变、强反光等)无法正确识别出upc,排除拍摄物品完全没条码的场景外,尚有部分靠人工仍勉强可识别出文字的upc,未来算法、预处理、系统架构仍有一些改进空间:
- 预处理策略智能化:当前预处理方法为顺序尝试,未来可探索基于强化学习或轻量级分类网络,根据图像特征(模糊度、对比度、噪声类型)智能选择最优预处理流水线。
- 引入视觉语言模型(VLM)进行理解:对于传统算法完全失效的极端案例,可尝试调用多模态大模型,利用其强大的场景理解和推理能力,对图像进行描述或直接输出条码信息,作为最终保障。
- 为了并行推理,引入的推理进程池,在Python多进程通信中,直接序列化图片(如通过pickle)会存在处理延迟,可通过共享内存+内存池技术,实现内存复用,消除此部分处理延迟。
参考
《State-of-the-art review and benchmarking of barcode localization methods》
https://runtime.onnx.org.cn/docs/
https://docs.ultralytics.com/