谷歌TurboQuant技术突破:高效压缩AI内存需求
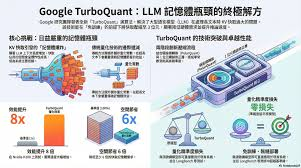
谷歌TurboQuant技术通过创新的免训练压缩方法,有效解决了大语言模型面临的内存瓶颈问题。该技术采用两阶段压缩方案:PolarQuant极坐标量化和QJL误差修正,在不损失精度的前提下实现显著优化。实验数据显示,TurboQuant可将KVCache内存需求降低6倍以上,注意力计算速度提升8倍,并支持3-bit量化。这项突破使AI系统能在现有硬件上处理更长上下文,降低推理成本,标志着AI发展从规模竞赛转向效率优化的重要转变。
谷歌 TurboQuant 详解:打破 AI 内存瓶颈的新利器
引言:AI 规模化道路上的"隐形墙"
在过去几个月中,Google TurboQuant 的出现被视为 AI 效率领域的重大突破。它直击当前大语言模型(LLM)在实际生产中的核心痛点:内存容量与带宽。
随着 AI 模型处理的文档越来越长、上下文窗口不断扩大、向量数据库规模激增,内存消耗已成为制约性能的"隐形墙"。谷歌研究院推出的 TurboQuant,正是为了在不牺牲精度的前提下,极速压缩这些庞大的数据。
什么是 TurboQuant?
简单来说,TurboQuant 是一种针对高维向量的**免训练(Training-free)**压缩技术。它主要应用于两个核心场景:
-
大模型的 KV Cache(键值缓存)压缩:减少模型在对话过程中的记忆负担。
-
语义检索系统中的高维向量搜索:提升从海量数据中捞取信息的效率。
核心战绩:
-
内存占用: 将 KV Cache 内存需求降低了 6 倍以上。
-
计算速度: 在特定环境下,注意力分数的计算速度提升了 8 倍。
-
精度保持: 在主流基准测试中,几乎实现了"零精度损失"。
技术深挖:它是如何运作的?
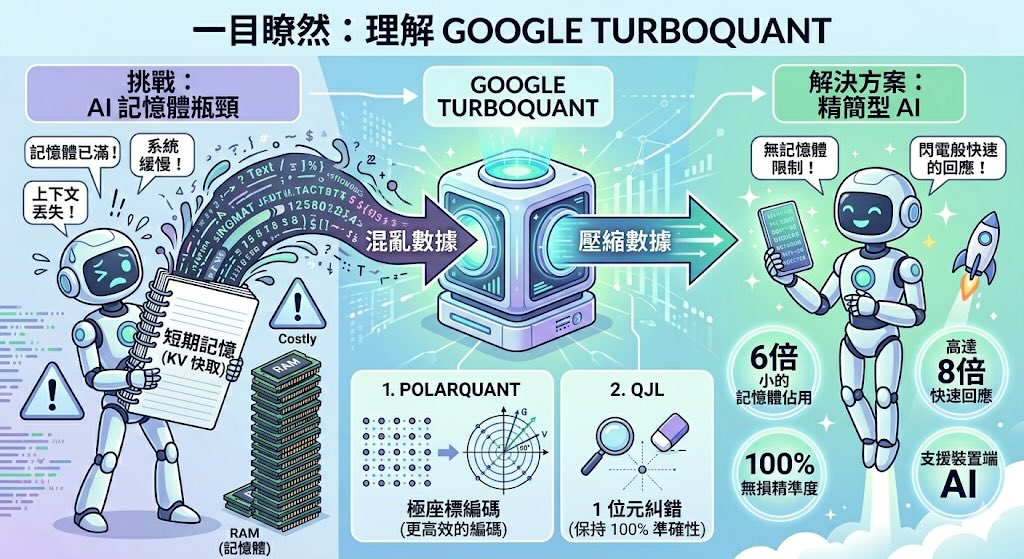
传统量化技术(如将 16 位浮点数转为 4 位整数)虽然能省空间,但往往需要存储额外的"缩放因子"或"元数据",这在处理数十亿个向量时会产生巨大的隐藏开销。
TurboQuant 通过两阶段的数学创新巧妙地避开了这个问题:
第一阶段:PolarQuant(极坐标量化)
这是压缩的主力引擎。传统的量化是在笛卡尔坐标系(直角坐标)下进行的,而 PolarQuant 将向量转换为极坐标形式(即"长度+角度")。
形象比喻: 传统的坐标像是在地图上说"向东走 3 公里,向北走 4 公里";而 PolarQuant 则是说"朝 53 度方向走 5 公里"。
通过随机旋转变换,数据的分布变得更有规律。这种表示法允许系统在不存储昂贵的"块归一化常数"的情况下进行压缩,从而彻底消除元数据带来的额外内存占用。
第二阶段:QJL(量化约翰逊-林登施特劳斯)
即使第一阶段很强,也会留下微小的残留误差。TurboQuant 引入了 QJL 方案进行误差修正。
它利用数学上的降维原理,仅使用 1 bit(正号或负号) 信号来捕获并抵消误差。这种"零开销"的微调机制,确保了模型在极高压缩比下依然能保持原有的智力水平。
为什么 KV Cache 压缩如此重要?
在大模型推理时,为了避免重复计算之前的对话内容,系统会将中间结果存入 KV Cache。随着对话变长,这个缓存会像滚雪球一样迅速吃光显存(VRAM)。
这直接影响了以下场景:
-
长文档分析: 处理法律合同或整本代码库时,内存极易溢出。
-
AI Agent(智能体): 复杂的任务规划需要极长的推理链路。
-
端侧 AI: 手机、电脑等本地设备的内存资源极其有限。
TurboQuant 让企业无需购买更昂贵的显卡,就能在现有硬件上跑更长的上下文。
惊人的实验结果
谷歌在 Gemma、Mistral 和 Llama 等主流模型上进行了测试,数据非常抢眼:
| 指标 | 表现结果 |
|---|---|
| 内存节省 | KV Cache 占用至少降低 6x |
| 计算加速 | 在 H100 GPU 上,注意力逻辑计算快了 8x |
| 极致压缩 | 成功实现 3-bit 量化且无需重新训练 |
| 大海捞针测试 | 在长文本检索测试(Needle In A Haystack)中表现近乎完美 |
这意味着,TurboQuant 不仅能省钱,还能让 AI 反应更快,且不会变笨。
总结:从"规模竞赛"转向"效率革命"
TurboQuant 的意义远超谷歌自家产品的提升,它预示着 AI 行业的一个重要转变:未来的竞争力不仅在于模型有多大,更在于数据表示有多精简。
为什么它值得关注?
-
降低成本: 显存占用低了,推理成本自然下降。
-
即插即用: 无需重新训练模型,现有模型可以直接套用。
-
强化搜索: 语义搜索和 RAG(检索增强生成)系统将变得更加高效。
TurboQuant 证明了:通过深厚的数学底蕴对数据表示进行优化,我们可以在不堆砌硬件的情况下,释放出 AI 巨大的潜能。