- 在矿区影像中寻找某种矿物。
- 在农田中识别某种作物。
- 在城市遥感图像中检测某种材料。
这类任务通常被称为 高光谱目标检测(Hyperspectral Target Detection)。
在之前介绍的 SAM 中,我们已经见过一种非常直观的思路:通过计算像素光谱与目标光谱之间的 夹角 来判断它们是否相似。
但我们提到了:SAM 只利用了光谱之间的几何关系,并没有考虑背景噪声或波段之间的统计特性。在复杂背景环境下,这种方法往往难以充分利用高光谱数据中包含的统计信息。
正是在这样的背景下,人们提出了一系列 基于统计模型的目标检测方法 ,其中最经典、也是最基础的一种方法便是 滤波匹配(Matched Filter,MF)。
1. 什么是 MF ?#
MF 的思想最初源自信号处理领域中的最优线性滤波理论(Matched Filter Theory),用于在已知信号形态的情况下从噪声背景中提取目标信号,而在遥感和高光谱图像分析中,这一方法被移植过来,并针对光谱数据进行了适配。
我们在上面已经提到过,SAM 有一个明显的局限:
它只考虑光谱之间的几何关系,而忽略了背景的统计特性和噪声结构。
换句话说,如果背景中存在高度相关的波段或较强的噪声,即使像素并非目标,SAM 也可能给出较高的匹配值。
这就会导致目标检测的误报率升高,特别是在高光谱数据的复杂场景下。
打个比方:假设你在嘈杂的房间里寻找某个人的声音。SAM 相当于只听声音的音色是否匹配,却完全不考虑背景噪声------空调声、回声甚至其他人的声音都会干扰判断。
于是,一个自然的想法出现了:
如果我们能够在考虑背景噪声和统计特性的基础上进行匹配,是否可以更准确地检测目标?
这正是 MF 的目标逻辑,从历史上看,MF 可以被认为是 SAM 等光谱相似性方法的统计优化版本。它不仅关注目标光谱与像素光谱的匹配程度,还同时考虑了背景的相关性和噪声结构,因此在高光谱目标检测领域迅速成为经典方法之一。
下面,我们来简单展开其核心思想:

因为高光谱遥感数据本质上是每个波段的光强叠加,而高光谱图像中的大部分像素都是背景,它们可能包含地物、植被、土壤、水体等各种光谱组合,随机性高。
所有,对于目标检测来说,我们不关心每个背景像素的具体值,而关心它们的统计特性,因为我们可以利用这一点把背景和目标区分开。
因此,MF 对于背景和像素,进行了如下假设:

由此,我们将像素区分为目标信号和非目标信号两部分,显然,目标像素的光谱中前者占比更大,而背景像素的光谱中后者占比更大。
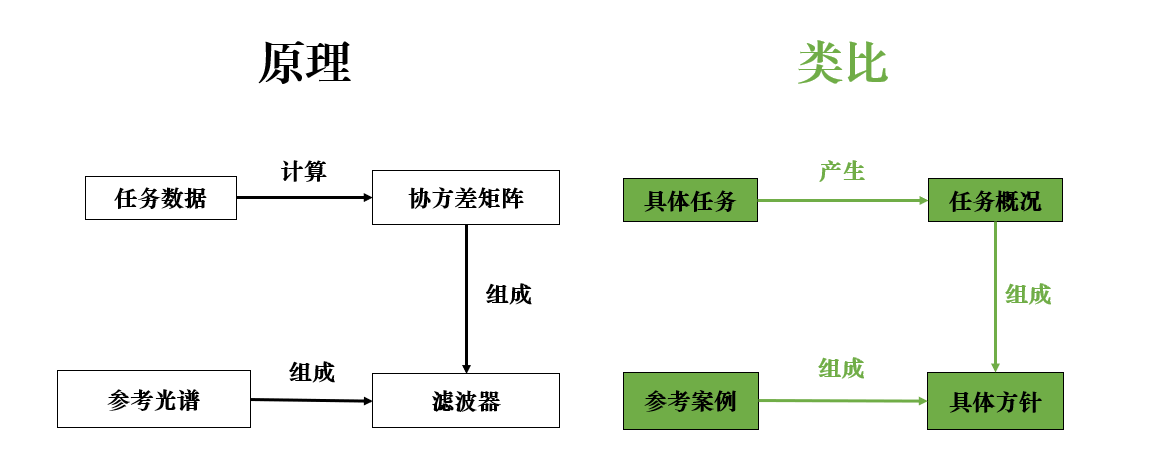
而最终,我们就可以构造出一种变换 ,形成这样的效果:

显然,MF 的核心思想就是构造出图中所示的滤波器,增强目标光谱、抑制背景噪声,来实现更好的目标检测效果。
总结来看,MF 相比 SAM,不仅衡量光谱匹配度,还充分利用背景信息和噪声结构,因此在复杂场景下具有更低的误报率和更高的鲁棒性。
下面,就来看看其具体过程:
2. MF 的具体过程#
MF 在高光谱目标检测中的具体过程,本质上就是构造一个针对目标光谱的线性变换,让目标像素的响应尽可能高,而背景像素的响应尽可能低。
2.1 像素建模和背景估计#
首先假设我们有一幅高光谱图像,每个像素的光谱向量为 �,已知目标的参考光谱为 �。
由此,我们把像素光谱建模为:
�=��+�
其中:
- ��:目标信号部分,� 表示目标在像素中的强度。
- �:背景信号(非目标部分),包含自然地物和噪声。
这部分的逻辑其实和我们之前介绍的 MNF 中噪声建模的逻辑很相似,其下一步也是相同的:我们要估计背景信号的统计特性。
在介绍估计方法前,我们先明确一点:
在高光谱目标检测中,像素仅分为两类:目标像素 与背景像素 。
即使图像中包含多种地物或可检测对象,在当前任务中,除目标外的一切均视为背景 。
这就像在超市里找苹果,无论货架上还有香蕉、牛奶还是面包,对我们而言只有两种东西:是苹果 和 不是苹果 。
因此,在目标检测场景中,目标所占像素比例极小,全图统计量主要由背景主导。目标对统计特性的污染可忽略。
基于这点,在高光谱目标检测中,最常见的背景估计方法就是全局背景统计估计 。
假设图像中共有 � 个像素,记为 {�1,�2,...,��},则:
背景均值估计为:
�^�=1�∑�=1���
背景协方差估计为:
�^�=1�−1∑�=1�(��−�^�)(��−�^�)⊤
我们将由此得到的 �^� 和 �^� 作为背景统计特性的估计,并用于后续滤波器设计。
2.2 中心化#
这部分较为简单,就不再过多赘述。
我们对数据进行中心化如下:
�~=�−�^�,�~=�−�^�
此时模型变为:
�~=��~+�~
这一步的作用是让数据的均值变为 0 ,好在下一步中应用,来确保模型一致性。
2.3 构造匹配滤波器#
在这一步,我们的目标是设计一个线性检测器 �,满足:
�=�⊤�~
其中,当 �~ 是目标像素时 � 尽可能大,而当其是背景像素时, � 则尽可能小。
而在这里,我们需要用到信号处理领域里的最优线性检测理论 ,它的内容如下:
在背景服从高斯分布 �~∼�(0,��) 的假设下,使输出信噪比最大的线性滤波器为:
�opt=��−1�~
注意,这里是 ��−1 与中心化后的参考光谱向量 �~ 的乘积 。
我们依然从语义上来理解这个公式:
首先,我们在上面已经提到,最终的滤波器可以突出目标而抑制背景,这其实就是使输出信噪比最大 。
而 ��−1 是背景协方差矩阵的逆矩阵 ,为什么要这么做?
这是因为背景由多种地物和噪声组成,在不同波段表现出不同的波动强度:某些波段背景变化剧烈(方差大),某些波段则相对平稳(方差小),且波段之间常存在光谱相关性。
而 �~ 作为参考光谱,是"统一的参考答案",�� 则是能反映出本任务数据中方差、协方差特点。
因此,我们可以让参考光谱根据本任务数据的特定进行一点"本地化 "。
所以, ��−1�~ 使用 �� 的逆矩阵,就像是给参考光谱加了一个更适合本任务的自适应权重:
-
在背景方差大的波段,��−1 对应的权重变小(抑制噪声)。
-
在背景方差小的波段,权重变大(信任信号)。
-
同时自动解耦相关波段 (协方差特性)。

在这里,就来到下一个问题:为什么 MF 要更信任方差小的波段?
来举一个例子:
如果某个纯背景像素在波段 1 出现一个偶然的高反射 (比如云、亮石块),简单内积会误判为"像目标"(因为目标也在波段 1 强),但 MF 知道"波段 1 容易乱跳 ",所以不会轻易相信它,从而降低虚警 。
反之,如果目标出现在波段 2(即使信号弱),MF 会更确信这是"真信号",因为背景很少在那里波动。就像"狼来了"一样。
于是,我们将 �opt 代入,得到 MF 响应:
�=�opt⊤�~=�~⊤��−1�~
这就是我们在高光谱目标检测中使用的匹配滤波器。
此外,实践中经常会再加入归一化分母,让响应标准差变为1,即服从标准正态分布,利于阈值设定:
�=�~⊤��−1�~�~⊤��−1�~
最终,当对整幅高光谱图像的每个像素计算 MF 响应 �,就得到一幅MF 响应图 。
其中:
- 响应高的区域,很可能是目标。
- 响应低的区域,多为背景。
最后,根据实际任务设定一个阈值 �,将响应大于 � 的像素标记为目标,即可实现目标检测。
2.4 一个完整实例#
现在,假设我们使用高光谱传感器在矿区探测一种含铁矿物,为简化说明,我们仅考虑 3 个关键波段 。
首先,已知目标参考光谱为:
�=0.750.200.60
这表示:波段 2 反射率低,波段 1 和 3 反射较强。
继续,假定我们计算得到的全图背景均值估计为:
�^�=0.500.500.50
于是,计算中心化后的参考光谱如下:
�~=�−�^�=0.25−0.300.10
继续下一部分,进行背景协方差矩阵估计如下:
�^�=0.090.060.030.060.040.020.030.020.01
可以发现:
- 波段 1 方差最大(0.09),受大气和地形影响大。
- 波段 3 方差最小(0.01),最稳定。
- 波段间存在正相关。
于是,我们计算协方差逆矩阵:
�^�−1≈50−750−75150−500−50100
紧接着,构造匹配滤波器权重如下:
�opt=�^�−1�~≈50−750−75150−500−501000.25−0.300.10=35.0−68.525.0
现在,参考光谱就同时考虑了矿物的标准反射率和在任务数据中的方差大小。
我们用以下三种检测方式进行对比:
| 方法 | 检测器权重 � | 说明 |
|---|---|---|
| 简单内积 | �1=�~=0.25, −0.30, 0.10⊤ | 忽略背景统计,仅做光谱匹配 |
| 匹配滤波器(未归一化) | �2=�^�−1�~≈35.0, −68.5, 25.0⊤ | 考虑背景协方差,自适应加权 |
| 归一化 MF | 同上权重,但输出除以 �=�~⊤�^�−1�~≈5.64 | 使响应具有统计可比性 |
输入两个像素如下:
| 像素类型 | 观测光谱 � | 中心化后光谱 �~=�−�^� | 说明 |
|---|---|---|---|
| 像素 A(真实目标) | 0.74, 0.21, 0.61⊤ | 0.24, −0.29, 0.11⊤ | 包含目标矿物,光谱特征与参考光谱 � 高度一致。 |
| 像素 B(纯背景) | 0.78, 0.52, 0.51⊤ | 0.28, 0.02, 0.01⊤ | 背景中偶然出现高反射,仅波段 1 异常偏高,其余波段接近背景均值。 |
最终,我们分别计算每种方法对两个像素的响应:
| 方法 | 像素 A(目标)响应 | 像素 B(背景)响应 |
|---|---|---|
| 简单内积 | �1(�)=0.25⋅0.24+(−0.30)⋅(−0.29)+0.10⋅0.11=0.158 | �1(�)=0.25⋅0.28+(−0.30)⋅0.02+0.10⋅0.01=0.065 |
| 匹配滤波器(未归一化) | �2(�)=35.0⋅0.24+(−68.5)⋅(−0.29)+25.0⋅0.11≈31.02 | �2(�)=35.0⋅0.28+(−68.5)⋅0.02+25.0⋅0.01≈8.68 |
| 归一化匹配滤波器 | �3(�)=31.02/5.64≈5.50 | �3(�)=8.68/5.64≈1.54 |
我们进行如下总结:
- 若直接使用简单内积:目标和背景相应差距更小,易虚警。
- 若不归一化:响应分别为 31.4 和 8.6,范围较大,难以设定阈值。
- 若归一化 : 目标响应 ≈ 5.57,背景响应 ≈ 1.52 ,此时响应服从标准正态分布的统一阈值�=3 。
最后,对整幅图像计算归一化 MF 响应,得到响应图。 设定阈值 �=3,标记所有 �>3 的像素为预测目标区域,即可完成目标检测。
3. MF 的优缺#
MF 作为一种基于最优线性检测理论的目标探测方法,广泛应用于高光谱图像中的已知目标检测任务。
它通过利用目标参考光谱和背景统计特性,构造一个最大化输出信噪比的线性检测器。尽管 MF 在许多场景下表现优异,但它也依赖特定假设并存在局限性。
3.1 MF 的优势#
| 优点 | 说明 |
|---|---|
| 理论最优性 | 在背景服从高斯分布的假设下,MF 是使输出信噪比最大的线性检测器,具有坚实的信号处理理论基础。 |
| 能自适应抑制背景干扰 | 通过引入背景协方差矩阵的逆 ��−1,MF 能自动降低高噪声或高相关波段的权重,增强对稳定波段的依赖,从而有效抑制虚警。 |
| 适用于弱小目标检测 | 即使目标在像素中占比很小(�≪1),只要其光谱特征与参考光谱一致,MF 仍能通过信噪比最大化机制将其从复杂背景中凸显出来。 |
| 归一化后支持统一阈值 | 归一化 MF 响应近似服从标准正态分布,使得不同目标、不同场景可使用统一的检测阈值(如 �=3),便于工程部署。 |
3.2 MF 的不足#
| 缺点 | 说明 |
|---|---|
| 依赖准确的背景统计估计 | MF 性能高度依赖对背景均值 �^� 和协方差 �^� 的准确估计;若图像中目标占比过高或背景非均匀,估计偏差会导致检测性能下降。 |
| 需要已知参考光谱 | MF 只能检测已知光谱特征的目标,无法用于未知目标或异常检测;若参考光谱与真实目标存在较大偏差(如光照、大气校正不一致),检测效果会显著退化。 |
| 对非高斯背景敏感 | MF 的最优性基于背景高斯假设;当背景包含大量异常值、强非高斯分布(如城市区域、云层)时,其虚警率可能升高。 |
| 仍是单像素检测器,忽略空间信息 | MF 仅利用光谱信息,未考虑目标的空间连续性或形状特征,在纹理复杂或光谱混淆区域易产生孤立虚警,通常需结合后处理(如形态学滤波)提升结果。 |