HashMap的原理
HashMap的底层是由:数组+链表+红黑树 组成的
工作原理主要有三点
- 怎么存
HashMap的结构是kv结构,存一个kv时。
先算key的hashCode
然后用(table.length-1)&hash算出存放在数组哪一个下标 - 冲突了怎么办
两个key算出来的下标一样就叫哈希冲突。
解决方法:用链表把他们串起来,jdk8做了优化,如果同一个下标下的链表超过8个节点,就转成红黑树,速度从O(n)变为O(logn) - 扩容机制(rehash )
数组长度有限。占到数组的75%自动扩容。扩容为两倍。
总结
HashMap底层时数组+链表,在Java 8后引入红黑树。存取时通过哈希算法定位下标遇到冲突就用链表或红黑树解决。为保证性能,达到阈值会扩容。
ConcurrentHashMap
一句话定义
ConcurrentHashMap 一个支持高并发 /线程安全的hashmap实现
如何实现的
我们以JDK1.8为例:
- CAS(无锁操作)
插入空位置时,不加锁
举例:
多个线程同时往一个桶插数据
→ 用 CAS 抢
成功的写入
失败的重试
- synchronized(锁桶)
当发生冲突时(链表/红黑树)
只锁住当前桶(不是整个Map)
解释一下桶是什么:
可以理解为:
下表 +这个位置上存储的数据结构(链表/红黑树)
ConcurrentHashMap的put流程
插入流程:
- 计算 hash → 找桶
- 如果桶为空 → CAS 插入(无锁)
- 如果桶不为空 → 加锁(synchronized)
- 插入链表 / 红黑树
HashMap与ConcurrentHashMap区别
一句话:
HashMap 是非线程安全的,
ConcurrentHashMap 是线程安全的高并发 Map 实现。
| 对比点 | HashMap | ConcurrentHashMap |
|---|---|---|
| 线程安全 | 不安全 | 线程安全 |
| 锁机制 | 无锁 | 分段锁 / CAS |
| 并发性能 | 差 | 高 |
| 使用场景 | 单线程 | 多线程 |
什么是CAS
CAS(Compare And Swap)是一种无锁的原子操作,通过比较内存中的值是否等于预期值,如果相等就更新,否则重试。
例子
在多线程下进行:count++分为三个步骤
- 读count
- +1
- 写回
问题 :
如果两个线程同时执行
线程A读到 0
线程B读到 0
A 写 1
B 写 1
本来应该是 2,结果变成:1
CAS怎么解决的
操作原理:
更新前先"检查一下
举个例子:
如果count=0
线程A:
期望值 A = 0
新值 B = 1
CAS:发现 count == 0 → 成功更新为 1
线程B(慢一步):
期望值 A = 0
新值 B = 1
CAS:发现 count 已经是 1
→ 更新失败 → 重新读取再试
CAS的本质
CAS = 乐观锁思想
先不加锁,如果出现问题,再重试
CAS的优缺点
优点:
- 无锁并发
- 线程不会阻塞
- 不会出现死锁问题
- 吞吐量高
Java中的原子类/ConcurrentHashMap/AQS底层都大量使用了CAS
缺点:
- ABA问题
- 自旋开销,高并发是大量线程反复重试,cpu空转浪费资源
- 只能保证单个变量的原子性
ABA问题
变量从A变为B再变为A时,CAS操作无法检测出这种变化。
解决方法:引入版本号。每次更新时更新版本号。通过版本号的改变判断是否出现问题
java
private AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(0, 0);
public void updateValue(int expected, int newValue) {
int[] stampHolder = new int[1];
Integer currentValue = atomicStampedReference.get(stampHolder);
int currentStamp = stampHolder[0];
boolean updated = atomicStampedReference.compareAndSet(expected, newValue, currentStamp, currentStamp + 1);
if (updated) {
System.out.println("Value updated to " + newValue);
} else {
System.out.println("Update failed");
}
}在Java中ConcurrentHashMap1.7和1.8有什么区别
JDK1.7中,采用分段锁设计。
底层把整个数组分成16个segment。每一个segment之间不会产生锁竞争,并发度最高位16.
JDK1.8中移除了Segment,锁粒度细致到数组每一个槽位 。数据结构和HashMap同步(数组+链表+红黑树)。
进行插入操作时,先尝试CAS插入到数组位置,发生冲突时才使用synchronized(只锁链表或树的头节点),其他线程可以操作别的桶
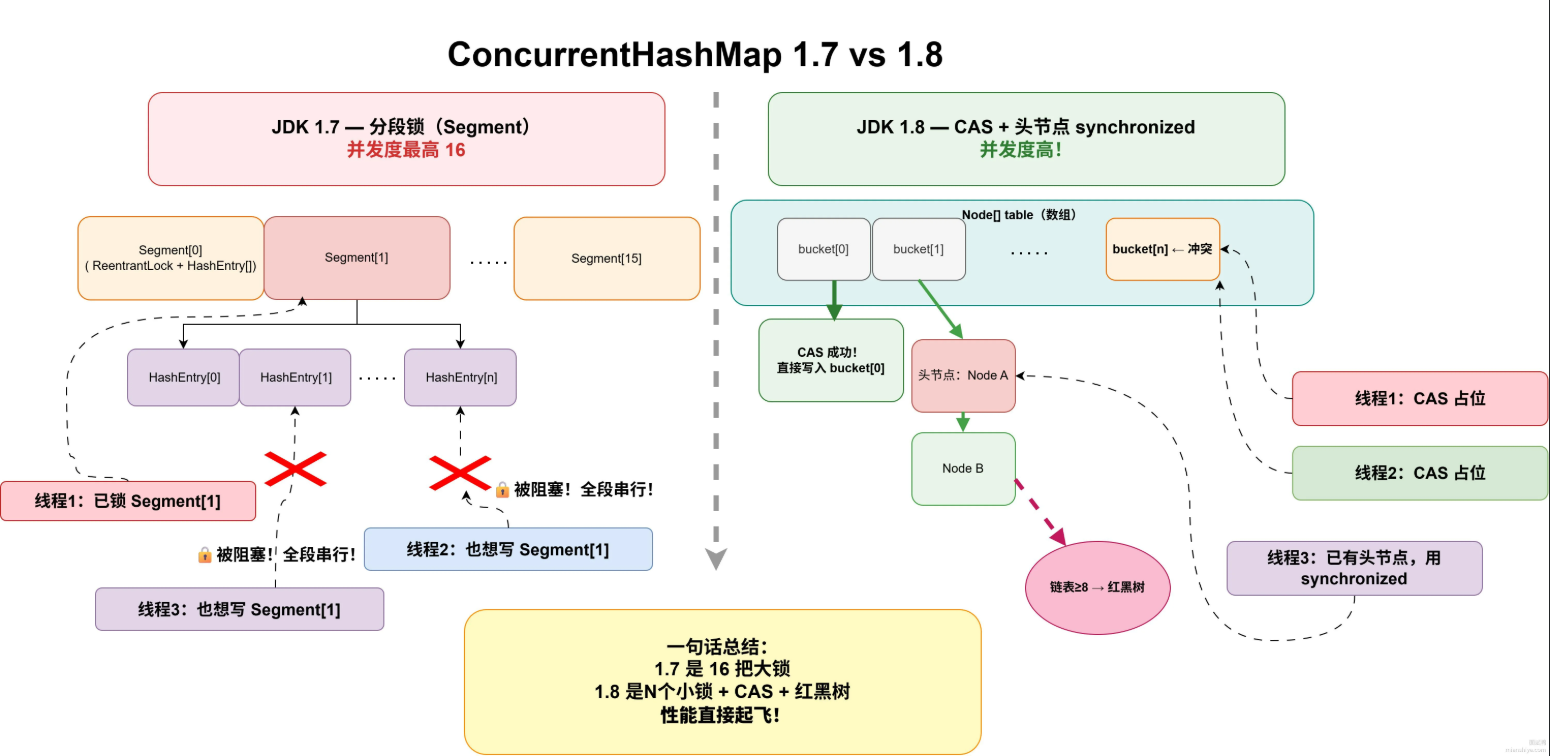
总结
我们发现1.8并发能够大大加强就是因为锁粒度的设计。1.8之间去掉了segment,锁粒度位每一个。数量接近于数组长度。
总结
这一篇主要讲解:
-
HashMap底层(数组+链表+红黑树)
怎么存(用hashcode计算key存放的下标)
冲突怎么办(链表或者红黑树)
扩容机制(75%时扩成两倍)
-
ConcurrentHashMap是什么(线程安全/支持高并发的map)
如何实现(CAS,synchronized)
put操作流程
-
1.8版本如何改进,实现并发能力的加强
(优化锁粒度)