摘要 :本文在 Decoder Only Transformer 与 LLaMA 架构 的统一框架下,系统介绍 Gemma 1(2B / 7B) 的架构与每一步的矩阵维度与运算 。内容包括:Gemma 1 的定位(与 Gemini 技术同源的开源 Decoder-only 文本模型)、从文本到解码器的数据流(SentencePiece 词表、嵌入、无 在嵌入上相加的绝对位置向量)、单层 Decoder 内的 Pre-Norm + RMSNorm 、带掩码自注意力 (7B 为 MHA ,2B 为 MQA )与 RoPE 、GeGLU 前馈网络、lm_head 与自回归训练/推理;并在各环节对照 2017 年标准 Decoder 、LLaMA 说明差异与设计动机。
关键词:Gemma 1;Decoder-only;RMSNorm;Pre-Norm;GeGLU;RoPE;MQA;MHA;掩码自注意力;SentencePiece
参考与引用:
- Decoder Only Transformer
- LLaMA 架构
- Gemma explained: An overview of Gemma model family architectures(Google Developers Blog, 2024)
- Gemma:Open Models Based on Gemini Research and Technology(技术报告)
- Gemma 文档概览(Google AI for Developers)
- 权重与配置可在 Hugging Face
google/gemma-7b等仓库核对;Gemma 1 在 Kaggle 上请检索google/gemma或gemma-2b/gemma-7b(与 Gemma 4 合集 不是同一条目)。
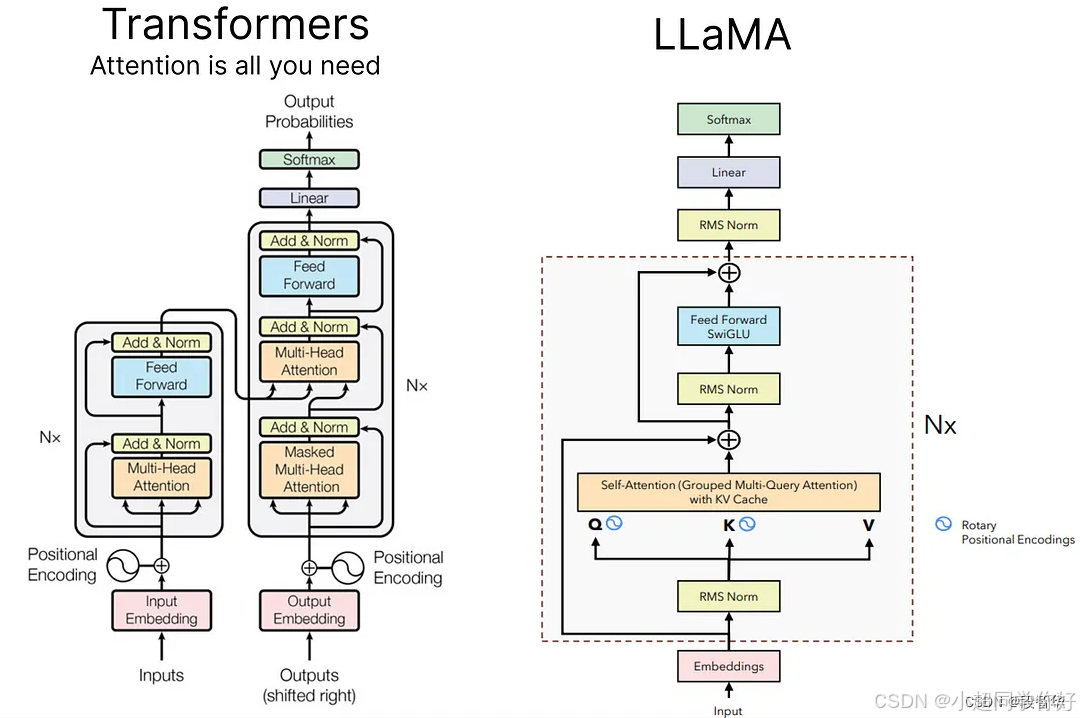
💡 理解要点 :Gemma 1 是 仅 Decoder 的因果语言模型:每层为 因果自注意力 + 前馈 + 残差 + RMSNorm ,没有 Encoder、没有交叉注意力 。与 LLaMA 同属「现代开源 LLM 配方」(RMSNorm、Pre-Norm、RoPE、门控 FFN),但 FFN 使用 GeGLU(GELU 门控) 而非 SwiGLU;7B 用标准 MHA ,2B 用 MQA 以换推理效率。与 经典 Transformer Decoder(Post-Norm、嵌入加正弦 PE、ReLU FFN)差异更大。
1. 概述:Gemma 1 在模型家族中的位置
1.1 Decoder-only 与自回归目标
与 Decoder Only Transformer 一致,Gemma 1 的任务是:给定已出现的 token 序列,预测下一个 token 。训练时对整段序列加因果掩码并行算损失;推理时逐步把预测 token 拼回输入。
Gemma 1 的范围 :公开发布的 2B、7B 权重均为文本进、文本出 的多语模型;上下文长度、GeGLU、RoPE 等细节以官方博文与 config.json 为准。来源:Gemma explained: An overview of Gemma model family architectures
1.2 核心规模对照表
下列为 Google 开发者博文中的 Gemma 1 代表性超参 (便于后文指称;实现上 embed_tokens 行数可能写作 256000,与 256128 有细微差别,以 checkpoint 为准)。
| 属性 | Gemma 1 2B | Gemma 1 7B |
|---|---|---|
| 层数 N N N | 18 | 28 |
| d model d_{\text{model}} dmodel | 2048 | 3072 |
| 注意力头数 h h h | 8 | 16 |
| 每头维度 d k d_k dk | 256 | 256 |
| KV 头数 | 1(MQA) | 16(MHA) |
| FFN 中间维(「Feedforward hidden dims」) | 32768 | 49152 |
| 词表 V V V | 256128(SentencePiece) | 同左 |
| 训练上下文长度 | 8192 tokens | 同左 |
注意,层数 N N N 指的是:堆叠的 Decoder 块(Transformer Layer)有多少个------也就是模型里有多少个 GemmaDecoderLayer(或同类的 DecoderLayer) 从输入到输出依次重复。
🔍 实际例子(7B) :若 L = 4096 L=4096 L=4096,则进入每层的张量主形状为 4096 × 3072 4096 \times 3072 4096×3072 ;自注意力中每个头的 Q ( t ) Q^{(t)} Q(t) 为 4096 × 256 4096 \times 256 4096×256 ,打分矩阵 S ( t ) S^{(t)} S(t) 为 4096 × 4096 4096 \times 4096 4096×4096(工程上常用 FlashAttention 等避免物化全矩阵)。
这里附上 Gemma 1 的架构图。第 3 节 对应单层里的 第一子层(自注意力块,含前置 RMSNorm) ;第 4 节 对应 第二子层(GeGLU 前馈块,含前置 RMSNorm) 。第 2 节 仍讲堆叠层之前的 Tokenizer / 嵌入 / RoPE 原理。
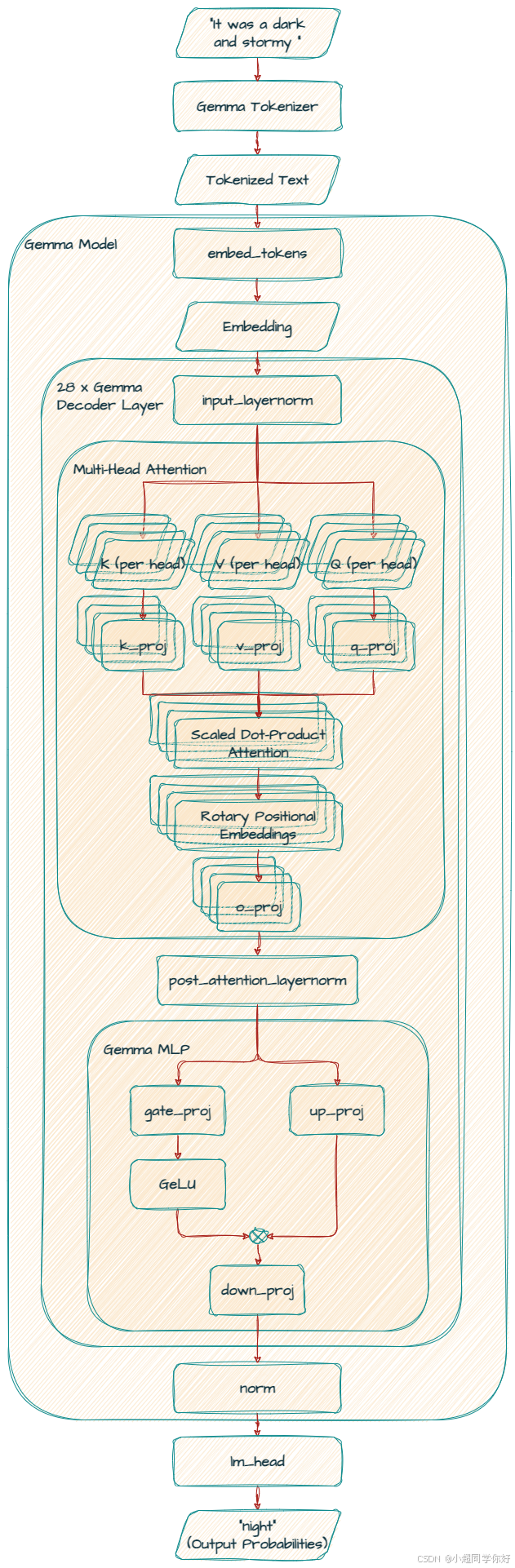
2. 从输入到 Decoder:Token、嵌入与位置信息
2.1 Tokenization:SentencePiece 与子词 ID
什么是 Tokenization?
Tokenization 是把原始字符串变成模型能吃的 离散符号序列 的过程:先切成若干 Token(词元) ,再把每个 Token 映射到词表里的整数 ID 。可以把它想成「把一句话拆成一排带编号的乐高积木」------模型里不出现原始 Unicode 字符,只出现这串 ID,后面的 Embedding 再按 ID 查表成向量。
与 Decoder Only Transformer 2.1 节 的关系 :那里已经强调「文本 → \to → ID → \to → 矩阵」的整体链路;本节在 Gemma 1 上把 SentencePiece + 256128 词表 说清楚,便于你对着官方权重或 tokenizer.json 核对。
SentencePiece 在做什么?
Gemma 1 使用 SentencePiece 作为分词后端(与早期 Gemma 技术说明一致 来源:Gemma explained 博文)。它通常在海量文本 上先学出一个固定大小的 子词词表 (含单字、多字片段、常见词根等),编码时再按所选算法(SentencePiece 支持 Unigram 语言模型 、BPE 等)把字符串切成词表内子词 的序列,使 任意新文本 几乎总能被覆盖,从而**显著减轻 OOV(词表外)**问题,对多语、符号、混写(中英夹杂、数字、标点)比较友好。
输出长什么样?
设一段 UTF-8 文本经 Tokenizer 编码后得到长度为 L L L 的序列:
w = ( w 0 , w 1 , ... , w L − 1 ) , 0 ≤ w i < V . \mathbf{w} = (w_0,\, w_1,\, \ldots,\, w_{L-1}), \quad 0 \le w_i < V. w=(w0,w1,...,wL−1),0≤wi<V.
这里 V = 256128 V=256128 V=256128 是 Gemma 1 公开配置中的词表大小。L L L 就是后续自注意力里序列维的长度:同一段文字,Token 化后 L L L 越小 ,在相同上下文窗口里能塞进的「字数」往往越多,但词表变大也会抬高 Embedding / lm_head 的参数量与显存占用。
Token 与 ID 的直观例子(示意,非你本地 tokenizer 的真实 ID):
| 文本 | 可能的子词切分(示意) | 说明 |
|---|---|---|
| 我喜欢吃苹果 | 我 | 喜欢 | 吃 | 苹果 或更细的子词组合 |
中文常被切成字/多字片,与训练语料统计有关 |
| Hello world | Hello | ▁world 或 Hel | lo | ▁world 等 |
英文常见子词;▁ 在 SentencePiece 里常表示空格边界(具体以词表为准) |
def foo() |
代码子词若干段 | 代码语料训练后会出现专门片段,利于补全 |
因此:同一句话在不同模型里会得到不同的 ID 序列,因为词表与 merge/训练目标都不同。
Gemma 1 词表规模(256128)带来什么?
- 多语与稀有词 :比很多早期 32K~50K 词表的模型更有空间容纳多语言子词与符号,同样字符数往往用更少或更稳的切分(具体仍依赖语料)。
- 特殊 Token :除普通文本子词外,词表里还会占坑 BOS/EOS/PAD/对话模板专用符号 等;实现里常见
padding_idx=0(见下文 2.2 节),说明 ID 0 往往被保留为 pad ,与「普通词的第一个 ID」要区分开------以tokenizer_config.json/ 文档为准。
与 GPT 系 BPE、LLaMA 等 tokenizer 的差异(概念层)
- 都是 子词级 :很少整词独占一词表项,而是 词根 + 后缀 等拼接,兼顾词与字符之间粒度。
- 算法细节不同 :例如 Byte-level BPE 先在字节或字符上再做合并,与 SentencePiece 的「直接训子词表 + 空白处理」在空格是否显式、词表构造流程上并不相同。
- 结论 :不要把 ChatGPT 里某句话的 token 数,原封不动套到 Gemma 1 上计费或估长;应用侧应以当前模型的
tokenizer.encode为准。
💡 理解要点 :Gemma 1 的 Tokenization = SentencePiece 子词切分 + V = 256128 V=256128 V=256128 查表 ID 。解码器看到的「序列」在数值上就是这串 ( w 0 , ... , w L − 1 ) (w_0,\ldots,w_{L-1}) (w0,...,wL−1),再往后的矩阵形状一律是 L × d model L \times d_{\text{model}} L×dmodel。
2.2 Embedding:查表得到 L × d model L \times d_{\text{model}} L×dmodel
2.2.1 数学本质
Embedding 层是一张 可学习的查找表 (lookup table)。词表大小为 V V V,模型隐藏维为 d model d_{\text{model}} dmodel,则权重矩阵为
E ∈ R V × d model . E \in \mathbb{R}^{V \times d_{\text{model}}}. E∈RV×dmodel.
对 Tokenization 得到的 ID 序列中第 i i i 个位置上的 w i w_i wi( 0 ≤ w i < V 0 \le w_i < V 0≤wi<V),嵌入向量是 E E E 的第 w i w_i wi 行(实现里等价于「用整数索引从第一维取值」):
x i = E w i ∈ R d model . \mathbf{x}i = Ew_i \in \mathbb{R}^{d{\text{model}}}. xi=Ewi∈Rdmodel.
把整段序列按行堆叠,得到送入第一层 Decoder 之前的 token 表示矩阵:
X = x 0 ⊤ ⋮ x L − 1 ⊤ ∈ R L × d model . X = \begin{bmatrix} \mathbf{x}0^\top \\ \vdots \\ \mathbf{x}{L-1}^\top \end{bmatrix} \in \mathbb{R}^{L \times d_{\text{model}}}. X= x0⊤⋮xL−1⊤ ∈RL×dmodel.
2.2.2 批处理时的形状
训练常为 batch 大小 B B B 条序列一起算;每条经 pad 到同一 L max L_{\max} Lmax 时,嵌入输出为 B × L max × d model B \times L_{\max} \times d_{\text{model}} B×Lmax×dmodel 。下文为简洁,多取 B = 1 B=1 B=1 ,写 L × d model L \times d_{\text{model}} L×dmodel。
Gemma 1 的矩阵形状与参数量 (取公开配置 V = 256128 V=256128 V=256128 来源:Gemma explained):
| 型号 | d model d_{\text{model}} dmodel | 嵌入矩阵 E E E | 嵌入权重个数(约) |
|---|---|---|---|
| 2B | 2048 | R 256128 × 2048 \mathbb{R}^{256128 \times 2048} R256128×2048 | 256128 × 2048 ≈ 5.24 × 10 8 256128 \times 2048 \approx 5.24\times 10^8 256128×2048≈5.24×108 |
| 7B | 3072 | R 256128 × 3072 \mathbb{R}^{256128 \times 3072} R256128×3072 | 256128 × 3072 ≈ 7.87 × 10 8 256128 \times 3072 \approx 7.87\times 10^8 256128×3072≈7.87×108 |
2.2.3 输出层 lm_head:未绑权与绑权
从 h \mathbf{h} h 到 logits(预测下一词)
设最后一层 Decoder 输出 H ∈ R L × d model H \in \mathbb{R}^{L \times d_{\text{model}}} H∈RL×dmodel,自回归预测「下一个 token」时常取最后一个有效位置的行向量,记为列向量形式
h = H L − 1 , : ⊤ ∈ R d model \mathbf{h} = HL-1,\\,:^\top \in \mathbb{R}^{d_{\text{model}}} h=HL−1,:⊤∈Rdmodel
语言模型头要把 d model d_{\text{model}} dmodel 维压到 词表维 V V V ,得到 logits s ∈ R V \mathbf{s} \in \mathbb{R}^V s∈RV,再 P = s o f t m a x ( s ) P=\mathrm{softmax}(\mathbf{s}) P=softmax(s)。
未绑权(untied) 时,单独 存放输出权重 W out ∈ R d model × V W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V} Wout∈Rdmodel×V 与(若有)偏置 b out ∈ R V \mathbf{b}_{\text{out}} \in \mathbb{R}^V bout∈RV,常用列向量写法为
s = W out ⊤ h + b out . \mathbf{s} = W_{\text{out}}^\top \mathbf{h} + \mathbf{b}_{\text{out}}. s=Wout⊤h+bout.
等价地,用行向量 h ⊤ \mathbf{h}^\top h⊤(与 PyTorch 里 hidden @ lm_head.weight.T 一致):
s ⊤ = h ⊤ W out + b out ⊤ . \mathbf{s}^\top = \mathbf{h}^\top W_{\text{out}} + \mathbf{b}_{\text{out}}^\top. s⊤=h⊤Wout+bout⊤.
此时 嵌入 E E E 与 W out W_{\text{out}} Wout 无关:输入端「词 w w w 的语义方向」与输出端「给每个词打分的方向」两套参数各自学习 。参数量上,在已有 E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel 之外,再多约 d model × V d_{\text{model}} \times V dmodel×V 个权重(bias 仅 V V V 维,相对可忽略)。
绑权(weight tying / tied embedding)
绑权在数学上即令
W out = E ⊤ ( 即 W out ∈ R d model × V 与 E ⊤ 共用同一块存储 ) . W_{\text{out}} = E^\top \quad (\text{即 } W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V} \text{ 与 } E^\top \text{ 共用同一块存储}). Wout=E⊤(即 Wout∈Rdmodel×V 与 E⊤ 共用同一块存储).
于是第 w w w 个词元的 logit(无偏置时)为
s w = h ⊤ e w , s_w = \mathbf{h}^\top \mathbf{e}_w, sw=h⊤ew,
其中 e w = E w , : ⊤ \mathbf{e}w = Ew,\\,:^\top ew=Ew,:⊤ 正是 输入端用来表示 token w w w 的那一行嵌入 (列向量)。也就是说:打分 = 上下文向量 h \mathbf{h} h 与各词嵌入方向的「内积」 ------「从向量回到词表」与「从词表进到向量」在词表维上**共用同一组 V V V 个 d model d{\text{model}} dmodel 维方向** 。若有输出偏置,则 s w = h ⊤ e w + ( b out ) w s_w = \mathbf{h}^\top \mathbf{e}w + (b{\text{out}})w sw=h⊤ew+(bout)w。用同一句式概括:省一整块 d model × V d{\text{model}} \times V dmodel×V 的 W out W_{\text{out}} Wout。
Gemma 1 上如何核对
- 配置 :
tie_word_embeddings: true→ 绑权 ;false→ 独立 lm_head。 - 实现细节 :绑权时
model.get_input_embeddings().weight与lm_head.weight往往是同一张张量 (is或data_ptr()相同);print(model)仍可能并列 打印embed_tokens与lm_head,容易被误读成「多占了一份参数」。 - 省参数量级 :当 V = 256128 V=256128 V=256128、7B 的 d model = 3072 d_{\text{model}}=3072 dmodel=3072 时,若从 untied 改为 tied,大约少存 3072 × 256128 ≈ 7.87 × 10 8 3072 \times 256128 \approx 7.87\times 10^8 3072×256128≈7.87×108 个与 W out W_{\text{out}} Wout 对应的权重(与上表「仅嵌入」那一列同量级)。
2.2.4 与 Tokenization 的衔接
多一个空格、换行或不可见字符,ID 序列可能整条变化 ,查到的 E E E 行也不同------提示词里的空白、标点同样影响分布与开销。
🔍 实际例子(7B,长度取预训练上限 8192) :单条序列若 L = 8192 L=8192 L=8192,则 Embedding 输出为 8192×3072 ;若 B = 4 B=4 B=4,则 4×8192×3072 。每一行是一个位置的 d model d_{\text{model}} dmodel 维向量,进入第一层 RMSNorm 与自注意力。
💡 理解要点 :嵌入 = 按 ID 从 E E E 取行 ,得到 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel 。行下标 只表示 token 在序列中的先后 ;相对/绝对位置信息 由后续 RoPE 写入注意力,不在此处 给 X X X 加正弦或可学习位置向量。
2.3 位置编码:RoPE,不在嵌入上「加 PE」
2.3.1 为什么需要位置信息?
自注意力对序列是置换敏感 的:若不加任何位置线索,调换两个位置的 token,单看注意力子层 得到的加权和可能完全不变 (因为「谁和谁相似」的关系集合没有改变)。但自然语言里 「猫咬狗」≠「狗咬猫」 ,顺序决定语义。因此必须在模型某处注入 位置信息 。Decoder Only Transformer 2.3 节 给出的经典做法是:在嵌入上再加一个只依赖位置的向量 ;Gemma 1 走的是另一条路:不把位置向量加在 X X X 上 ,而是写进 Q , K Q,K Q,K 的几何关系里(RoPE)。
2.3.2 经典绝对位置编码 vs Gemma 1(RoPE)
| 维度 | 经典 Transformer(Decoder Only Transformer 2.3 节) | Gemma 1(与 LLaMA 2.3 节 同路线) |
|---|---|---|
| 注入时机 | Embedding 之后、进第一层之前,通常 只做一次 | 每一层 、算 Q K ⊤ QK^\top QK⊤ 之前 ,对当层的 Q , K Q,K Q,K 注入 |
| 注入对象 | 整段序列的隐表示, I n p u t = E m b + P E \mathrm{Input}=\mathrm{Emb}+\mathrm{PE} Input=Emb+PE | 只对当前头的 Q , K Q,K Q,K 行向量 施旋转;V V V 一般不做 RoPE |
| 数学形态 | P E ( p o s ) \mathrm{PE}(pos) PE(pos) 与词嵌入 相加 | 块对角旋转矩阵 R p o s R_{pos} Rpos 左乘 到该位置的 Q , K Q,K Q,K 子向量上 |
| 进入第一层的 X X X | 已含绝对位置 | 仍仅 embed_tokens,形状 L × d model L \times d_{\text{model}} L×dmodel,无 PE 相加 |
| 位置语义 | 强调每个 p o s pos pos 的 绝对位置向量 | 注意力 logits 更可刻画 相对间距 i − j i-j i−j(理论动机见 RoPE 文) |
Gemma 1 实现侧 :Hugging Face 打印里每层有 rotary_emb(GemmaRotaryEmbedding),与 当前层 线性投影得到的 Q , K Q,K Q,K 结合后再算 scores 来源:Gemma explained: An overview of Gemma model family architectures。
2.3.3 RoPE 在算什么(直觉 + 形状)
直觉 :把每个头的维度 d k d_k dk(Gemma 1 里 256 ,为偶数)看成 d k / 2 d_k/2 dk/2 个互不耦合的 2D 平面 ;位置 m m m 在第 t t t 个平面上转一个角 θ m , t = m ω t \theta_{m,t}=m\omega_t θm,t=mωt。Query 在位置 m m m、Key 在位置 n n n 的两束向量各自旋转后做点积,等价于夹角里携带 m − n m-n m−n 一类信息------故叫 旋转位置编码(RoPE)。
单头矩阵形状 (本层输入经 RMSNorm、再乘 W Q , W K W_Q,W_K WQ,WK 之后):
- Q , K ∈ R L × d k Q,\, K \in \mathbb{R}^{L \times d_k} Q,K∈RL×dk。
- 对第 i i i 行(序列位置 i i i)的 d k d_k dk 维向量分别施加同一套「按位置 i i i 确定的旋转」(实现里常 fused,不显式展开整块旋转矩阵),得到 Q ′ Q' Q′、 K ′ K' K′ 的第 i i i 行;整体 Q ′ , K ′ ∈ R L × d k Q',\,K' \in \mathbb{R}^{L \times d_k} Q′,K′∈RL×dk ,形状不变,只改变数值。
注意力分数与后续(单头;多头时对每个头重复,再拼接):
S = Q ′ ( K ′ ) ⊤ d k ∈ R L × L . S = \frac{Q' (K')^\top}{\sqrt{d_k}} \in \mathbb{R}^{L \times L}. S=dk Q′(K′)⊤∈RL×L.
再 加因果掩码 M M M(同上三角 − ∞ -\infty −∞), A t t n W e i g h t s = s o f t m a x ( S + M ) \mathrm{AttnWeights}=\mathrm{softmax}(S+M) AttnWeights=softmax(S+M),与 未施 RoPE 的 V V V 相乘(标准实现里 V V V 仍用原投影输出):
h e a d = s o f t m a x ( S + M ) V ∈ R L × d k . \mathrm{head} = \mathrm{softmax}(S+M)\, V \in \mathbb{R}^{L \times d_k}. head=softmax(S+M)V∈RL×dk.
复杂度 :与不做 RoPE 的全长自注意力相同,主项仍是 O ( L 2 ) O(L^2) O(L2) (相对 L L L);RoPE 本身是 按维、按位置的轻量三角函数/旋转 ,相对 Q K ⊤ QK^\top QK⊤ 开销通常较小。
2.3.4 Gemma 1 语境下的小结
- 预训练长度 公开为 8192 :RoPE 的 基频、缩放 等在该长度附近最优;更长序列是否外推、是否改配置,以 checkpoint 与
config.json(如max_position_embeddings、rope_theta等字段)为准。 - 7B:16 头 × 256 维 ,2B:8 头 × 256 维 :每个头各自有一组 Q ′ , K ′ Q',K' Q′,K′,RoPE 按头维 d k = 256 d_k=256 dk=256 作用 ,与 d model d_{\text{model}} dmodel 是否为 2048/3072 无矛盾(投影矩阵把 d model d_{\text{model}} dmodel 映到 h ⋅ d k = d model h\cdot d_k=d_{\text{model}} h⋅dk=dmodel)。
🔍 实际例子(7B, L = 4096 L=4096 L=4096) :某头内 Q ′ , K ′ Q',K' Q′,K′ 均为 4096×256 , S S S 为 4096×4096 ;28 层 每层都重新对当层 Q , K Q,K Q,K 套 RoPE,不是只在第一层做一次。
💡 理解要点 :Gemma 1 的「位置」不进 X X X ,不进 V V V 的 RoPE (常见实现);只扭转 Q , K Q,K Q,K 再点积 ,从而在 logits 层之前 就让人头看见顺序。与 LLaMA 在 RoPE 套路上同族;差异主要在 层数、头数、 d model d_{\text{model}} dmodel、FFN(GeGLU vs SwiGLU)、2B 的 MQA ,以及 RoPE 超参 以各自config为准。
更深推导 (相对位置为何出现在点积里、YaRN 等长文外推):见 33_ROPE.md。
2.4 小结:进入 Decoder 堆叠层之前的矩阵
- 输入 : X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel,仅 来自
embed_tokens(无正弦 PE 相加)。 - L L L 与上下文 :预训练序列长度 8192;推理/微调时可按实现与位置编码外推策略截断或扩展。
自本节之后,第 3、4 节 按 GemmaDecoderLayer 内部顺序 拆开:先写 第一子层(自注意力块) ,再写 第二子层(前馈块) ;两者都是 Pre-Norm :归一化发生在子层内部最前端 ,再进 self_attn 或 mlp。
3. Decoder 单层 · 第一子层:带掩码的多头自注意力(含 Pre-Norm)
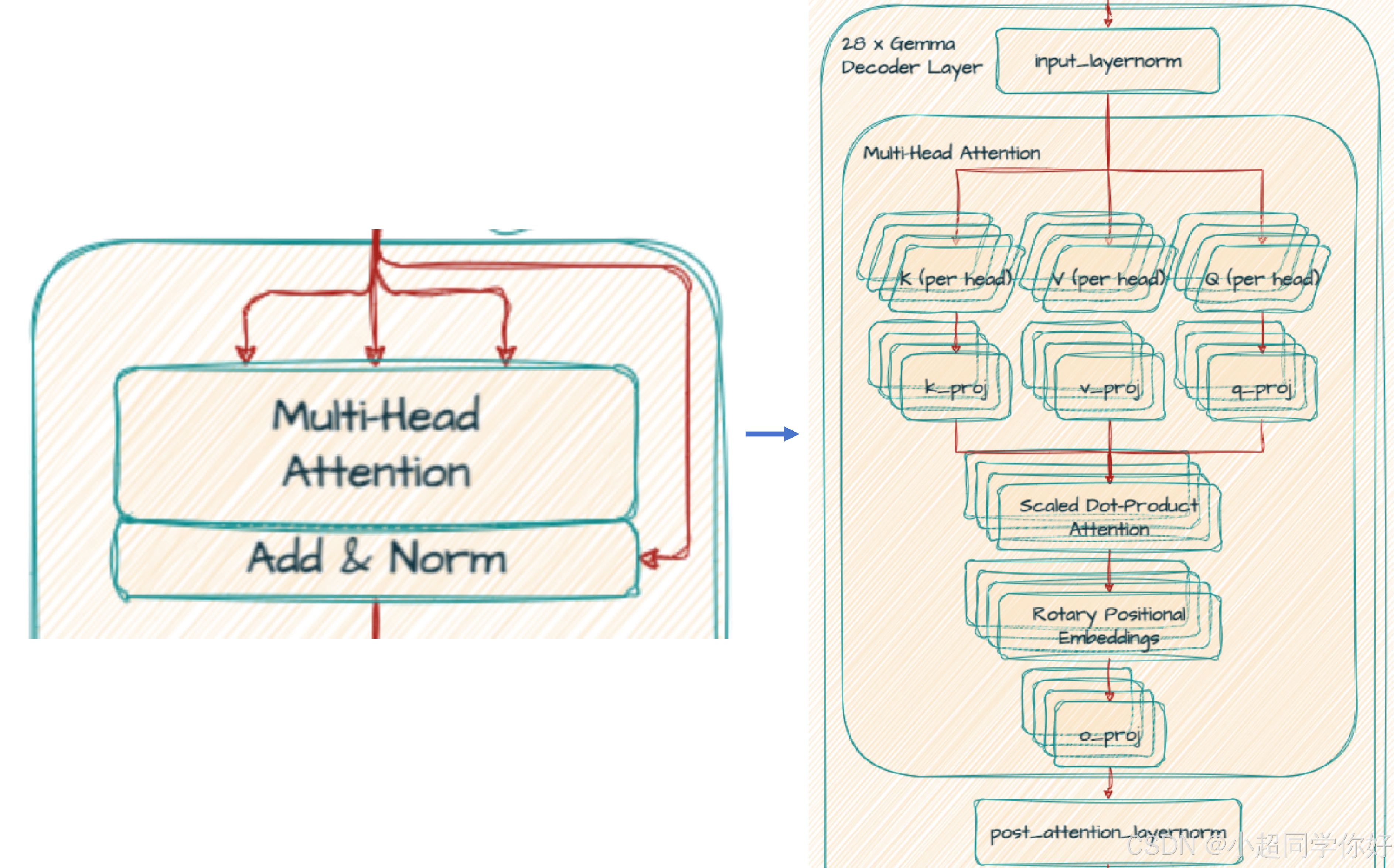
GemmaDecoderLayer 的第一子层 在模块顺序上对应:input_layernorm → self_attn → 与本子层输入的残差 。不要把 RMSNorm 想成与注意力「无关的另一章」------在 Pre-Norm 里,它是 进入 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV 与 RoPE 之前 的必要第一步。
整层骨架(预习):
X mid = X + A t t n B l o c k ( X ) ⏟ 第一子层(本节) , X out = X mid + F F N B l o c k ( X mid ) ( 第二子层,见第 4 节 ) . \underbrace{X_{\text{mid}} = X + \mathrm{AttnBlock}(X)}{\text{第一子层(本节)}}, \qquad X{\text{out}} = X_{\text{mid}} + \mathrm{FFNBlock}(X_{\text{mid}}) \quad (\text{第二子层,见第 4 节}). 第一子层(本节) Xmid=X+AttnBlock(X),Xout=Xmid+FFNBlock(Xmid)(第二子层,见第 4 节).
下面把 AttnBlock 从内到外拆成 五步。
3.1 第一步:input_layernorm(RMSNorm)
对子层入口 的矩阵 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel 逐行 做 RMSNorm,与 LLaMA 3.1 节 相同:对 x ∈ R d model \mathbf{x} \in \mathbb{R}^{d_{\text{model}}} x∈Rdmodel( X X X 的某一行),
R M S ( x ) = ε + 1 d model ∑ j = 1 d model x j 2 , R M S N o r m ( x ) = x R M S ( x ) ⊙ γ . \mathrm{RMS}(\mathbf{x}) = \sqrt{\varepsilon + \frac{1}{d_{\text{model}}} \sum_{j=1}^{d_{\text{model}}} x_j^2}, \qquad \mathrm{RMSNorm}(\mathbf{x}) = \frac{\mathbf{x}}{\mathrm{RMS}(\mathbf{x})} \odot \boldsymbol{\gamma}. RMS(x)=ε+dmodel1j=1∑dmodelxj2 ,RMSNorm(x)=RMS(x)x⊙γ.
记整表输出为 X ~ = R M S N o r m in ( X ) ∈ R L × d model \tilde{X} = \mathrm{RMSNorm}{\text{in}}(X) \in \mathbb{R}^{L \times d{\text{model}}} X~=RMSNormin(X)∈RL×dmodel。形状不变 ;可学习参数只有缩放 γ ∈ R d model \boldsymbol{\gamma} \in \mathbb{R}^{d_{\text{model}}} γ∈Rdmodel,无 LayerNorm 常见的平移 β \boldsymbol{\beta} β。
与 Post-Norm 对比 :Decoder Only Transformer 3.3 节 常见写法是先子层再加残差再 LN;Pre-Norm 是 先 LN/RMSNorm 再进子层,深层堆叠往往更稳。
💡 理解要点 :在 Gemma 1 里,第一子层的第一算子 就是
input_layernorm;它不属于第二子层 (FFN)。Hugging Face 打印里名字带post_attention的 RMSNorm 在 下一节(第 4 节) 才出现。
3.2 第二步:线性投影得到 Q、K、V
在 X ~ \tilde{X} X~ 上施加 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV(7B 可做成三块大矩阵再按头切分;数学上等价于每头一组矩阵)。以 7B 为例, h = 16 h=16 h=16, d k = 256 d_k=256 dk=256,第 t t t 个头:
Q ( t ) = X ~ W Q ( t ) , K ( t ) = X ~ W K ( t ) , V ( t ) = X ~ W V ( t ) , Q^{(t)} = \tilde{X}\, W_Q^{(t)}, \quad K^{(t)} = \tilde{X}\, W_K^{(t)}, \quad V^{(t)} = \tilde{X}\, W_V^{(t)}, Q(t)=X~WQ(t),K(t)=X~WK(t),V(t)=X~WV(t),
W Q ( t ) , W K ( t ) , W V ( t ) ∈ R d model × d k W_Q^{(t)}, W_K^{(t)}, W_V^{(t)} \in \mathbb{R}^{d_{\text{model}} \times d_k} WQ(t),WK(t),WV(t)∈Rdmodel×dk,故 Q ( t ) , K ( t ) , V ( t ) ∈ R L × d k Q^{(t)}, K^{(t)}, V^{(t)} \in \mathbb{R}^{L \times d_k} Q(t),K(t),V(t)∈RL×dk。
Gemma 1 2B(MQA) : Q Q Q 仍为多路头;K , V K,V K,V 只有一组 共享,详情参考 章节3.5。
3.3 第三步:RoPE 作用于 Q、K,再算缩放点积与因果掩码
对 每个头 的 Q ( t ) , K ( t ) Q^{(t)}, K^{(t)} Q(t),K(t) 在算分数前施加 RoPE ,得到 Q ′ ( t ) , K ′ ( t ) Q'^{(t)}, K'^{(t)} Q′(t),K′(t)(形状仍为 L × d k L \times d_k L×dk)。原理与几何直觉见上文第 2.3 节。
S ( t ) = Q ′ ( t ) ( K ′ ( t ) ) ⊤ d k + M , M i j = { 0 j ≤ i − ∞ j > i . S^{(t)} = \frac{Q'^{(t)} (K'^{(t)})^\top}{\sqrt{d_k}} + M, \quad M_{ij}=\begin{cases}0 & j\le i \\ -\infty & j>i\end{cases}. S(t)=dk Q′(t)(K′(t))⊤+M,Mij={0−∞j≤ij>i.
h e a d ( t ) = s o f t m a x ( S ( t ) ) V ( t ) ∈ R L × d k . \mathrm{head}^{(t)} = \mathrm{softmax}(S^{(t)})\, V^{(t)} \in \mathbb{R}^{L \times d_k}. head(t)=softmax(S(t))V(t)∈RL×dk.
V ( t ) V^{(t)} V(t) 使用 未乘 RoPE 的投影输出(标准实现),只是 Q , K Q,K Q,K 在进入点积前多了旋转。
形状 (7B): S ( t ) ∈ R L × L S^{(t)} \in \mathbb{R}^{L \times L} S(t)∈RL×L;若 L = 4096 L=4096 L=4096,单头注意力矩阵为 4096×4096。
3.4 第四步:多头拼接与输出投影 W O W_O WO
C o n c a t = C o n c a t ( h e a d ( 1 ) , ... , h e a d ( h ) ) ∈ R L × d model , A t t n O u t = C o n c a t W O , W O ∈ R d model × d model . \mathrm{Concat} = \mathrm{Concat}(\mathrm{head}^{(1)},\ldots,\mathrm{head}^{(h)}) \in \mathbb{R}^{L \times d_{\text{model}}}, \quad \mathrm{AttnOut} = \mathrm{Concat}\, W_O,\; W_O \in \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}}. Concat=Concat(head(1),...,head(h))∈RL×dmodel,AttnOut=ConcatWO,WO∈Rdmodel×dmodel.
博文 7B 的 q_proj / k_proj / v_proj 的 out_features 均为 4096 = 16 × 256 16 \times 256 16×256 ;o_proj 映回 3072 。来源:Gemma explained 博文
3.5 Gemma 1:7B(MHA) 与 2B(MQA)
MHA = Multi-Head Attention(多头注意力) ;MQA = Multi-Query Attention(多查询注意力,多组 Q 共享少量 KV)。
7B:MHA --- 每个头自有 一套 K、V 投影;推理 KV cache 随头数 h h h 增长。与 LLaMA-2 7B 同属 MHA 家族(维度不同);不是 GQA(Grouped-Query Attention,分组查询注意力)。
2B:MQA --- 多个 Query 头共享 一组 K、V(博文:k_proj/v_proj out_features=256 ,q_proj 2048=8×256 )。省参、省 KV cache;表达上让多个 Q「看同一套记忆」。
| 项目 | 标准描述(10 号文) | Gemma 1 7B | Gemma 1 2B |
|---|---|---|---|
| 头与 KV | 常设 MHA | MHA(多头注意力) | MQA(多查询注意力),单组 KV |
| 位置 | 嵌入 + PE 或变体 | RoPE(Q,K) | 同左 |
| 掩码 | 因果 | 因果 | 因果 |
3.6 第五步:残差 --- 第一子层输出
残差连回的是「进入 input_layernorm 之前」的 X X X (不是 X ~ \tilde{X} X~):
X mid = X + A t t n O u t ∈ R L × d model . X_{\text{mid}} = X + \mathrm{AttnOut} \in \mathbb{R}^{L \times d_{\text{model}}}. Xmid=X+AttnOut∈RL×dmodel.
至此,第一子层 结束; X mid X_{\text{mid}} Xmid 作为 第二子层(第 4 节) 的输入。
4. Decoder 单层 · 第二子层:前馈网络 GeGLU(含 Pre-Norm)
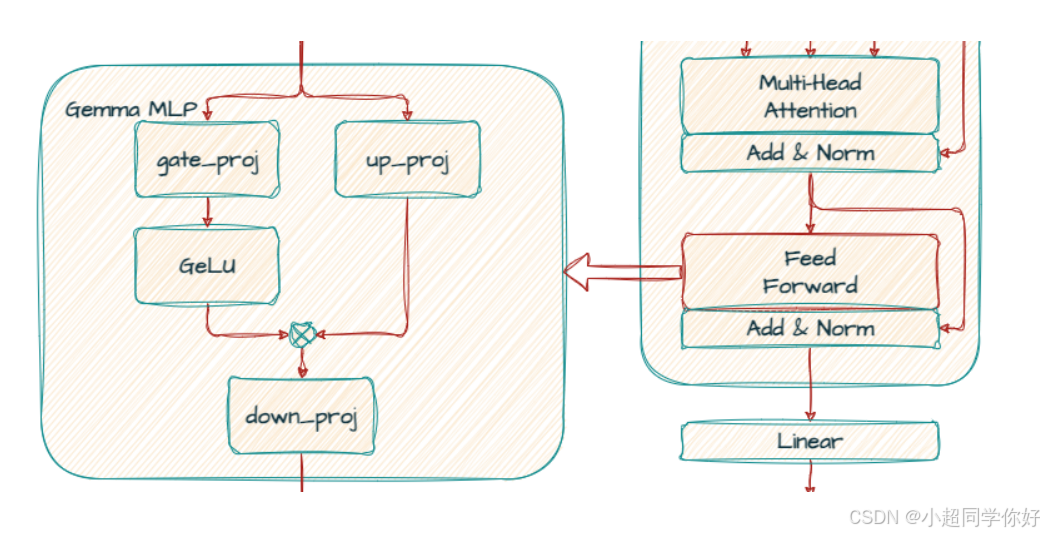
第二子层 对应:post_attention_layernorm → mlp(GeGLU)→ 与 X mid X_{\text{mid}} Xmid 的残差 。顺序上紧接 3.6 节 的输出。
4.1 第一步:post_attention_layernorm(RMSNorm)
对 X mid ∈ R L × d model X_{\text{mid}} \in \mathbb{R}^{L \times d_{\text{model}}} Xmid∈RL×dmodel 再做一次 RMSNorm (另一组 γ \boldsymbol{\gamma} γ 参数,与 input_layernorm 不共享):
X ~ ff = R M S N o r m post ( X mid ) ∈ R L × d model . \tilde{X}{\text{ff}} = \mathrm{RMSNorm}{\text{post}}(X_{\text{mid}}) \in \mathbb{R}^{L \times d_{\text{model}}}. X~ff=RMSNormpost(Xmid)∈RL×dmodel.
(下文公式里简记输入为 X ~ ff \tilde{X}_{\text{ff}} X~ff。)
💡 理解要点 :两个 RMSNorm 各司其职:一个 只服务自注意力 ,一个 只服务 FFN ;这是 Pre-Norm Transformer 块的标准拆分,避免把「归一化」写成脱离子层的孤立章节。
4.2 第二步:GeGLU(门控 + 上投影 + 下投影)
GLU 与「门控」在指什么?
GLU(Gated Linear Unit,门控线性单元) 把前馈拆成 两路并行投影 ,再 逐元素相乘 合成一路,形如「一路决定开多大的门 、一路是要通过的内容 」。记号上常写作 G L U ( a , b ) = a ⊙ σ ( b ) \mathrm{GLU}(a,b)=a\odot\sigma(b) GLU(a,b)=a⊙σ(b) 一类变体;哪一路过激活、哪一路当"门" 依具体变体(GEGLU、SwiGLU 等)而定。
在 GeGLU 里(Gemma 博文与实现命名):
up_proj:把 X ~ ff \tilde{X}_{\text{ff}} X~ff 投到中间维,得到 U U U ,可理解为 "候选内容 / 值支路"(value branch)。gate_proj:同样从 X ~ ff \tilde{X}_{\text{ff}} X~ff 投到 同宽 中间维,得到 G G G ,再经 G E L U ( ⋅ ) \mathrm{GELU}(\cdot) GELU(⋅) 。GELU 是光滑、可导的非线性,输出可看作每个维度的 连续"门限"或增益 :绝对值大的分量更容易被保留,小的被压小 ,从而 按位置、按维度 决定 U U U 里哪些成分参与后续计算------这就是常说的 门控(gating) :不是标量 0/1,而是 与 U U U 同形状的逐元素权重幕布。- 合成 H = G E L U ( G ) ⊙ U H = \mathrm{GELU}(G) \odot U H=GELU(G)⊙U 后,再
down_proj压回 d model d_{\text{model}} dmodel,相当于在「已被门控筛选过的」宽特征上做读出。
🔍 直觉类比 :可以把 G E L U ( G ) \mathrm{GELU}(G) GELU(G) 想成一排 连续可调的百叶窗 :每个维度一扇;U U U 是窗外进来的光,逐元素乘 之后,有的缝开大一点(信息通过多),有的小一点。比单层 ReLU MLP 多了一条 专门学"怎么开闭"的支路 ,表达能力更强。来源:GLU Variants Improve Transformer;Gemma explained 博文对 GeGLU 的说明
全称 :GeGLU = GELU-Gated Linear Unit(用 GELU 作门控非线性的门控线性单元)。
7B 模型:
gate_proj: Linear(3072, 24576)up_proj: Linear(3072, 24576)down_proj: Linear(24576, 3072)
批量矩阵形式 ( X ~ ff ∈ R L × d model \tilde{X}{\text{ff}} \in \mathbb{R}^{L \times d{\text{model}}} X~ff∈RL×dmodel,intermediate_size 记为 d ff d_{\text{ff}} dff):
U = X ~ ff W up , G = X ~ ff W gate , H = G E L U ( G ) ⊙ U , F F N O u t = H W down . U = \tilde{X}{\text{ff}}\, W{\text{up}}, \quad G = \tilde{X}{\text{ff}}\, W{\text{gate}}, \quad H = \mathrm{GELU}(G) \odot U, \quad \mathrm{FFNOut} = H\, W_{\text{down}}. U=X~ffWup,G=X~ffWgate,H=GELU(G)⊙U,FFNOut=HWdown.
激活在实现中常标 PytorchGELUTanh() 。形状 : F F N O u t ∈ R L × d model \mathrm{FFNOut} \in \mathbb{R}^{L \times d_{\text{model}}} FFNOut∈RL×dmodel。
博文表 49152 与两路 24576 的对照、2B 的中间维 d ff d_{\text{ff}} dff 等,以 config.json / print(model) 为准。
4.3 与 LLaMA(SwiGLU)的差异
| 项目 | LLaMA(常见) | Gemma 1 |
|---|---|---|
| 门控非线性 | Swish / SiLU | GELU(GeGLU) |
| 结构 | gate+up+down | gate_proj + up_proj + down_proj |
二者均属 GLU 族;差异在门函数与具体中间维。
4.4 第三步:残差 --- 整层输出
X out = X mid + F F N O u t ∈ R L × d model . X_{\text{out}} = X_{\text{mid}} + \mathrm{FFNOut} \in \mathbb{R}^{L \times d_{\text{model}}}. Xout=Xmid+FFNOut∈RL×dmodel.
X out X_{\text{out}} Xout 作为 下一 Decoder 层 的输入;N N N 层 (2B 为 18,7B 为 28)重复 第 3--4 节 所述块。
5. 输出层:lm_head 与 Softmax
最后一层堆叠输出 H ∈ R L × d model H \in \mathbb{R}^{L \times d_{\text{model}}} H∈RL×dmodel。自回归训练/推理常针对「下一个 token」位置取对应行向量 h ∈ R d model \mathbf{h} \in \mathbb{R}^{d_{\text{model}}} h∈Rdmodel(或对所有位置并行算 logits),与 Decoder Only Transformer 第 4 节 一致:
z = h W lm , W lm ∈ R d model × V , P = s o f t m a x ( z ) . \mathbf{z} = \mathbf{h}\, W_{\text{lm}}, \quad W_{\text{lm}} \in \mathbb{R}^{d_{\text{model}} \times V}, \quad P = \mathrm{softmax}(\mathbf{z}). z=hWlm,Wlm∈Rdmodel×V,P=softmax(z).
博文摘录中 7B 的 lm_head 为 Linear(3072, 256000);实际词表常为 256128 ,以权重为准。是否 tie(与 E E E 共享) 以实现与训练配置为准。
💡 与技术报告 / 实现 :若启用 attention logits soft-capping 等稳定技巧,以对应版本
modeling_gemma代码为准(非本入门篇展开重点)。
6. 训练与推理流程(简叙)
与 Decoder Only Transformer 第5节 一致:
- 训练 :Teacher Forcing + 因果掩码,一次前向可算所有位置的下一词损失。
- 推理 :自回归循环, L L L 随步数增加;2B(MQA) 在 KV cache 上相对 7B(MHA) 更省。
7. 参数量量级(便于与 LLaMA 文对照)
以下给出常用公式 (Gemma 注意力实现中常 bias=False )。设 d = d model d=d_{\text{model}} d=dmodel, d ff d_{\text{ff}} dff 为 intermediate_size(单路隐藏维,GeGLU 两路同宽再逐元素乘)。
7.1 单层(7B 量级,MHA)
- 注意力 : W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV 各约 d × d d \times d d×d, W O W_O WO 为 d × d d \times d d×d → 约 4 d 2 4d^2 4d2(与多头切分方式等价)。
- FFN(GeGLU) : W gate , W up W_{\text{gate}}, W_{\text{up}} Wgate,Wup 各 d × d ff d \times d_{\text{ff}} d×dff, W down W_{\text{down}} Wdown 为 d ff × d d_{\text{ff}} \times d dff×d → 2 d d ff + d ff d 2 d\, d_{\text{ff}} + d_{\text{ff}}\, d 2ddff+dffd (与 LLaMA 8 节 SwiGLU 计数同型)。
- RMSNorm :两处各 γ \boldsymbol{\gamma} γ 维 d d d → 2 d 2d 2d。
7.2 单层(2B,MQA)
- Q :仍可到 d × d d \times d d×d(或等价分头拼接)。
- K/V :投影到 单组 KV(宽度远小于 2 d 2 2d^2 2d2 的 MHA 情形),显著减少 K/V 侧参数与缓存。
嵌入与 lm_head 各约 V ⋅ d V \cdot d V⋅d 量级(若 tie 则只计一次)。
🔍 实际例子 : d = 3072 d=3072 d=3072,单层 注意力 约 4 d 2 ≈ 3.77 × 10 7 4d^2 \approx 3.77 \times 10^7 4d2≈3.77×107;28 层 堆叠后,主参数体量仍集中在 FFN 与嵌入/输出层。
8. 总览对照表:Gemma 1 vs 经典 Decoder vs LLaMA
| 维度 | 经典 Decoder-only | LLaMA | Gemma 1 |
|---|---|---|---|
| 位置 | 嵌入 + 正弦/可学习 PE | RoPE(Q,K),无嵌入 PE | 同 LLaMA |
| 归一化 | LayerNorm(Post-Norm 常见) | RMSNorm + Pre-Norm | 同 LLaMA |
| FFN | ReLU 两段 | SwiGLU | GeGLU |
| 7B 注意力 | 多为 MHA | MHA(7B) | MHA |
| 2B 注意力 | --- | 依系列而定 | MQA |
| 词表 | 因模型而异 | 如 32K | 256K + SentencePiece |
| 上下文(公开训练) | 因模型而异 | 如 4K/8K+ | 8192 |
9. 小结
- Gemma 1 = Decoder-only + Pre-Norm RMSNorm + RoPE + GeGLU FFN + 因果掩码自注意力 ;7B 用 MHA ,2B 用 MQA。
- 每一层 (第 3--4 节):第一子层 =
input_layernorm+ 掩码多头注意力 + 残差;第二子层 =post_attention_layernorm+ GeGLU + 残差。 - 数据流:SentencePiece ID → 嵌入 L × d L \times d L×d → 重复 N N N 层上述两块 → lm_head → Softmax。
- 与 LLaMA 最近的差别在 GeGLU vs SwiGLU 与 2B 的 MQA ;与 原版 Transformer Decoder 的差别在 无嵌入绝对 PE、RMSNorm、门控 FFN。
结合 Decoder Only Transformer 的矩阵推演与 LLaMA 架构 的 RoPE/RMSNorm 表述阅读本文,可将 Gemma 1 完全纳入同一套「可算、可对表」的知识框架。后续代际(如更长上下文、混合注意力、多模态)见 Gemma 4 架构。
💡 总结 :读 Gemma 1 时抓住三条------RoPE 不进嵌入 、FFN 用 GeGLU 、小模型用 MQA 省 KV。其余仍是标准自回归 Transformer 的「缩放点积 + 因果掩码 + 残差」故事。