在 MySQL 中,主键 ID 的选择是一个经典问题。自增 ID 和 雪花 ID 的核心区别在于:生成机制 (集中式 vs 分布式)、是否有序 、以及在分库分表场景下的表现。
一 核心原理

二 详细对比
1. 有序性与索引性能
-
自增 ID:
-
严格有序。新插入的数据 ID 总是大于之前的数据。
-
索引效率高。InnoDB 引擎的主键是聚簇索引,数据按照主键顺序存储。自增 ID 保证了新数据只往"最后面"写,页分裂(Page Split)发生的概率极低,写入性能非常好。
-
-
雪花 ID:
-
趋势递增,但非严格连续。
-
由于高位是时间戳,整体上写入是有序的,不会像 UUID 那样导致随机写入。但在高并发下,同一毫秒内的 ID 顺序取决于序列号。
-
相比自增,对 B+Tree 索引的影响很小(远优于 UUID),但在极端海量写入下,理论上可能比纯自增产生稍多的页分裂。
-
2. 安全性(防泄露)
-
自增 ID :极不安全。
-
在 API 接口中如果暴露了自增 ID(如
/user/1001),竞争对手或恶意用户可以:-
通过 ID 差值推算业务量(昨天 1000,今天 2000,就知道新增了 1000 用户)。
-
通过遍历 ID 爬取所有数据(
/user/1001,/user/1002)。
-
-
-
雪花 ID :较安全。
-
ID 通常是 19 位的长整型数字(如
6892001845624832)。 -
由于不是连续的,外界无法通过一个 ID 推测出总数,也无法通过简单加减进行遍历爬取(虽然理论上可以通过时间戳推测大致顺序,但成本高很多)。
-
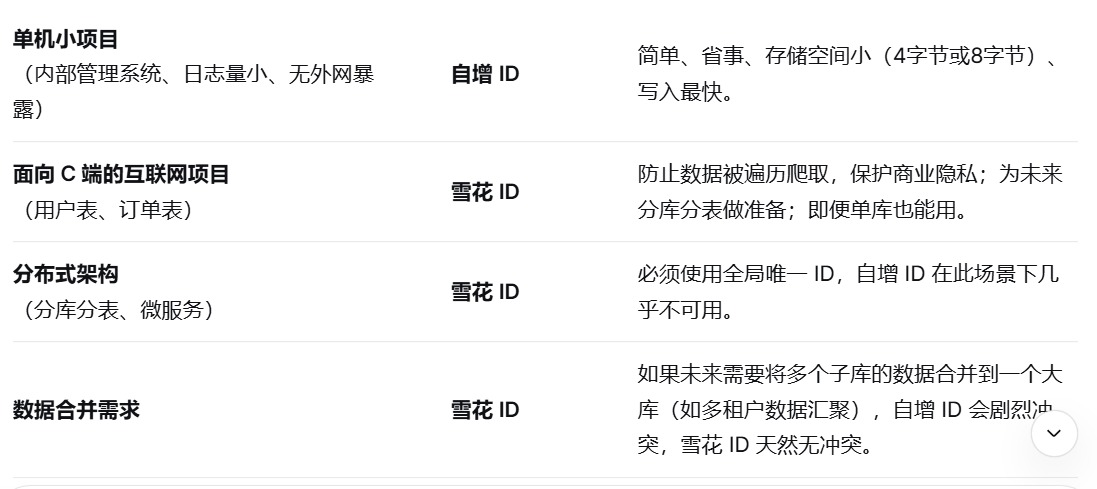
3. 分库分表
-
自增 ID :痛点。
-
在分库分表(Sharding)场景下,如果每个分表依然使用自己的自增,会导致 全局 ID 重复。
-
解决方案通常依赖设置
auto_increment_offset和auto_increment_increment(步长),但运维复杂,扩容困难,或者依赖中间件(如Sequence表)生成,这又引入了单点性能瓶颈。
-
-
雪花 ID :最佳拍档。
-
天生就是为了分布式系统设计的。应用层在插入数据前,直接生成一个全局唯一的 ID。
-
分库分表时,无需任何中心化协调,可以直接将雪花 ID 作为逻辑主键写入不同的分表,绝对保证全局唯一。
-
4. 性能
-
自增 ID:
-
性能极高。数据库自身维护,无需额外计算。
-
但在高并发下,如果使用
REPLACE INTO或者某些特殊锁模式下,AUTO_INCREMENT锁可能会有轻微竞争(不过 MySQL 8.0+ 已优化为轻量级锁)。
-
-
雪花 ID:
-
性能极高 。在应用内存中生成,不依赖数据库网络 IO,没有锁竞争。
-
缺点是依赖系统时钟。如果系统时钟回拨(NTP 校准),可能导致 ID 重复或产生异常(虽然成熟的算法如百度 UidGenerator、美团 Leaf 都解决了时钟回拨问题)
-
三 如何选择