一、为什么你一定要搞清楚 QPS / Session / Tokens
很多团队在做大模型落地时,会出现一个非常典型的问题:
把"并发"当成一个单一指标在说
比如:
-
"我们能支持 40 并发"
-
"这套资源能跑 100 用户"
听起来很合理,但在工程上这是不成立的。
因为:
👉 并发不是一个维度,而是三个不同层级的指标
二、三层模型:从用户到算力
可以用一条链路理解整个系统:
用户规模(Session)
↓
请求压力(QPS)
↓
计算消耗(Tokens)这三层分别对应三种完全不同的能力。
三、Session:你在服务多少"人"

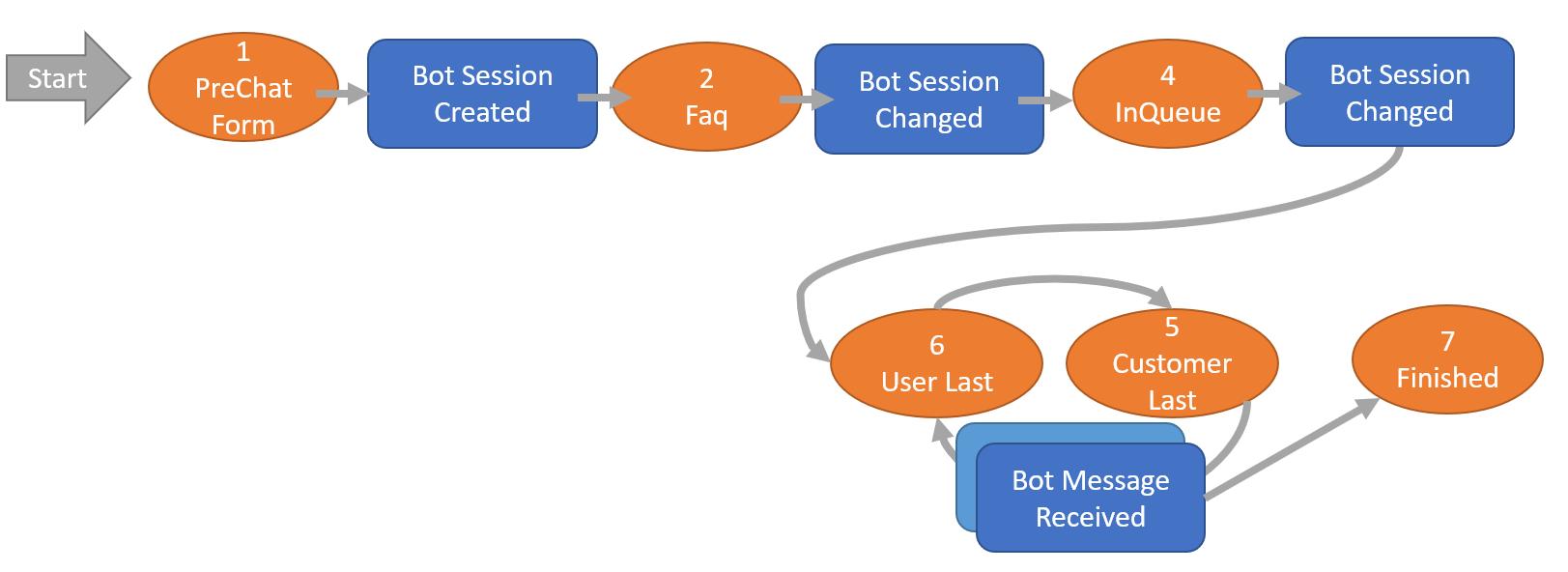
核心定义
同时有多少用户在使用系统
工程理解
-
一个 Session = 一个用户的一段对话上下文
-
可以持续几秒,也可以持续几分钟
-
包含多轮交互
举个真实场景
你的"个人通信智能体":
-
1000个用户在线聊天
→ Session = 1000
关键特点
-
面向业务(用户规模)
-
不直接等于系统压力
-
决定"你服务了多少人"
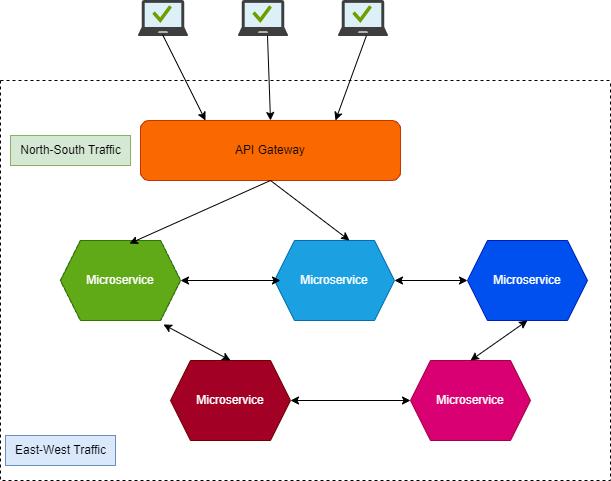
四、QPS:系统每秒被打多少次
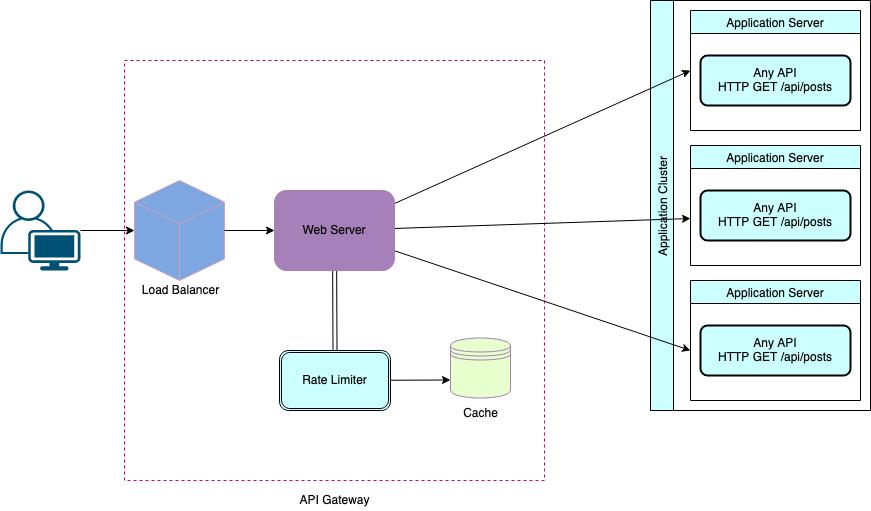
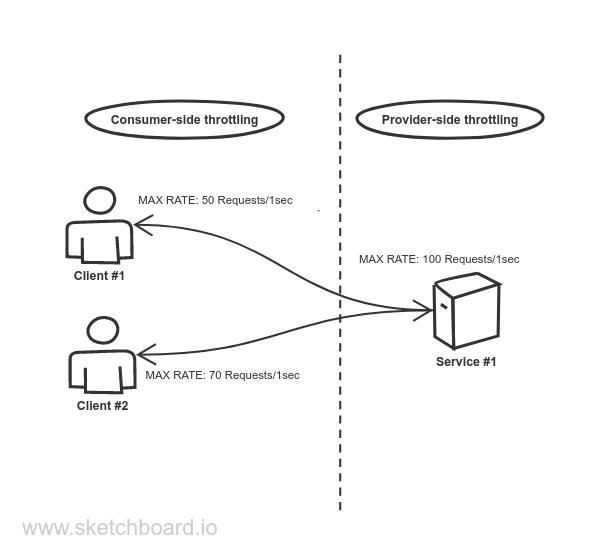
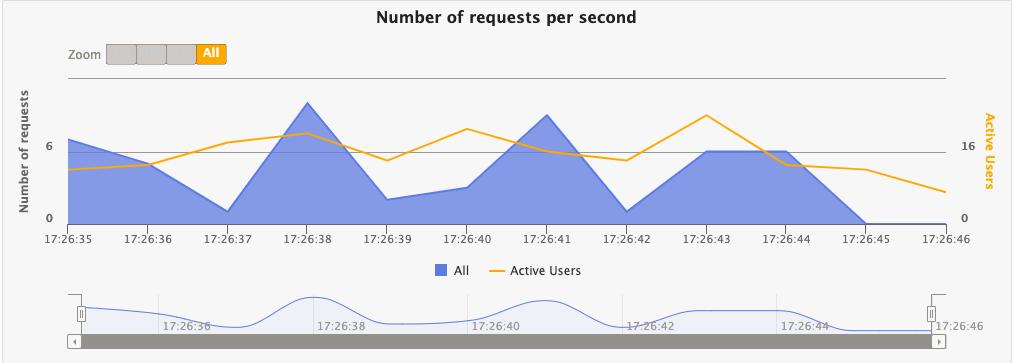
核心定义
每秒处理多少个请求
工程理解
-
每一次用户输入 → 一次请求
-
每一次模型回复 → 一次推理请求
举个例子
-
1000个用户
-
每人每秒发 0.2 条消息
→ QPS = 200
关键特点
-
面向系统(接口压力)
-
是传统后端最常用指标
-
忽略了请求"重不重"
五、Tokens:真正烧 GPU 的东西

核心定义
模型处理的文本量(输入 + 输出)
工程理解
一次请求的成本:
总tokens = 输入tokens + 输出tokens举个例子
一次对话:
-
输入:1000 tokens
-
输出:500 tokens
→ 总消耗:1500 tokens
关键特点
-
决定 GPU 负载
-
决定延迟
-
决定成本
👉 这是最底层、最真实的瓶颈
六、三者之间怎么换算
这是最关键的一步,也是大多数方案缺失的地方。
1️⃣ 基本关系
QPS = Session × 人均请求频率
Tokens/s = QPS × 单请求tokens2️⃣ 带入一个真实业务
假设:
-
1000 用户在线(Session = 1000)
-
每人每秒 0.2 次请求
→ QPS = 200
-
每次请求 2000 tokens
→ Tokens/s = 200 × 2000 = 40万 tokens/s
3️⃣ 这意味着什么?
你真正需要关心的是:
👉 你的 64 卡,能不能扛住 40万 tokens/s
而不是:
-
能不能支持"43并发"
-
能不能服务"100用户"
七、为什么很多算力方案会失真
回到你那份方案:
64卡 → 43.5路并发
问题在于:
❌ 没说清楚"并发是什么"
-
是 43.5 QPS?
-
还是 43.5 Session?
-
还是推导出来的容量?
❌ 没有 tokens 维度
不同请求:
-
简单问答:500 tokens
-
长上下文:5000 tokens
差 10 倍算力消耗
❌ 没有用户行为模型
-
用户发消息频率是多少?
-
是否有高频用户?
👉 结果就是:
这个"43.5并发"没有工程意义,也无法验收
八、工程上正确的做法
一个可落地的模型,至少要包含三层:
① 用户层(Session)
-
DAU / 并发用户数
-
用户活跃度(请求频率)
② 请求层(QPS)
-
峰值 QPS
-
平均 QPS
③ 计算层(Tokens)
-
单请求 tokens
-
tokens/s 上限
-
GPU吞吐能力
④ 最终你能得到
-
最大可承载用户数
-
每月成本
-
扩容节点
九、给你一个可以直接用的表达方式
以后写方案,可以直接用这一段:
系统容量需从三个维度评估:
用户并发规模(Session)、请求吞吐能力(QPS)以及模型计算负载(Tokens)。
其中,Session 决定业务规模,QPS 决定系统压力,Tokens 决定算力瓶颈。
三者需通过"用户行为模型 + 单请求Token消耗"进行统一换算,最终以 tokens/s 作为资源规划的核心指标。
十、一句话收尾
QPS 只是"有多少请求",Session 只是"有多少人在用",真正决定系统能不能跑起来的,是 tokens。