目录
[3.1.1 多源连接器开发:REST API轮询(Requests + Retry策略)与Webhook接收](#3.1.1 多源连接器开发:REST API轮询(Requests + Retry策略)与Webhook接收)
[3.1.2 Kafka生产者优化:批量发送、压缩算法(LZ4)与ACK配置调优](#3.1.2 Kafka生产者优化:批量发送、压缩算法(LZ4)与ACK配置调优)
[3.1.3 Schema验证:Confluent Schema Registry与Pydantic模型校验](#3.1.3 Schema验证:Confluent Schema Registry与Pydantic模型校验)
[3.1.4 数据血缘追踪:消息Header注入来源系统与采集时间戳](#3.1.4 数据血缘追踪:消息Header注入来源系统与采集时间戳)
[3.2 流处理引擎](#3.2 流处理引擎)
[3.2.1 Polars流处理:惰性求值(Lazy API)与内存高效转换](#3.2.1 Polars流处理:惰性求值(Lazy API)与内存高效转换)
[3.2.2 窗口计算:滚动窗口(Tumbling Window)聚合与水位线(Watermark)管理](#3.2.2 窗口计算:滚动窗口(Tumbling Window)聚合与水位线(Watermark)管理)
[3.2.3 流合并:多Kafka Topic Join操作与状态存储(RocksDB)](#3.2.3 流合并:多Kafka Topic Join操作与状态存储(RocksDB))
[3.2.4 错误处理:poison pill消息隔离与侧流(Side Output)收集](#3.2.4 错误处理:poison pill消息隔离与侧流(Side Output)收集)
[3.3 存储层设计](#3.3 存储层设计)
[3.3.1 Delta Lake集成:ACID事务、Schema演化与Time Travel查询](#3.3.1 Delta Lake集成:ACID事务、Schema演化与Time Travel查询)
[3.3.2 分层存储:Bronze(原始)-Silver(清洗)-Gold(聚合)架构实现](#3.3.2 分层存储:Bronze(原始)-Silver(清洗)-Gold(聚合)架构实现)
[3.3.3 分区策略:日期分区与业务维度分区权衡](#3.3.3 分区策略:日期分区与业务维度分区权衡)
[3.3.4 元数据管理:Delta表版本清理与VACUUM策略](#3.3.4 元数据管理:Delta表版本清理与VACUUM策略)
[3.4 数据质量保障](#3.4 数据质量保障)
[3.4.1 Great Expectations集成:空值检查、范围验证与格式校验](#3.4.1 Great Expectations集成:空值检查、范围验证与格式校验)
[3.4.2 数据血缘图谱:DBT模型依赖关系自动生成](#3.4.2 数据血缘图谱:DBT模型依赖关系自动生成)
[3.4.3 异常检测:Z-Score算法识别离群数据点并告警](#3.4.3 异常检测:Z-Score算法识别离群数据点并告警)
[3.4.4 端到端延迟监控:Kafka Lag监控与处理延迟SLI设定](#3.4.4 端到端延迟监控:Kafka Lag监控与处理延迟SLI设定)
[3.5 运维与优化](#3.5 运维与优化)
[3.5.1 Docker Compose本地开发:Kafka/Zookeeper/Polars环境一键启动](#3.5.1 Docker Compose本地开发:Kafka/Zookeeper/Polars环境一键启动)
[3.5.2 Kubernetes部署:StatefulSet管理有状态消费者与PV绑定](#3.5.2 Kubernetes部署:StatefulSet管理有状态消费者与PV绑定)
[3.5.3 自动扩缩容:KEDA基于Kafka Lag的HPA策略配置](#3.5.3 自动扩缩容:KEDA基于Kafka Lag的HPA策略配置)
[3.5.4 监控告警:Prometheus指标采集与PagerDuty集成](#3.5.4 监控告警:Prometheus指标采集与PagerDuty集成)
[项目三:实时数据管道(Kafka + Polars + Delta Lake)](#项目三:实时数据管道(Kafka + Polars + Delta Lake))
[3.5.1 docker-compose.yml](#3.5.1 docker-compose.yml)
[3.1 数据采集层实现](#3.1 数据采集层实现)
[3.1.1 rest_api_poller.py](#3.1.1 rest_api_poller.py)
[3.1.1 webhook_receiver.py](#3.1.1 webhook_receiver.py)
[3.1.2 kafka_producer_optimized.py](#3.1.2 kafka_producer_optimized.py)
[3.1.3 schema_validation.py](#3.1.3 schema_validation.py)
[3.1.4 lineage_tracking.py](#3.1.4 lineage_tracking.py)
[3.2 流处理引擎实现](#3.2 流处理引擎实现)
[3.2.1 polars_streaming.py](#3.2.1 polars_streaming.py)
[3.2.2 window_computation.py](#3.2.2 window_computation.py)
[3.2.3 stream_join.py](#3.2.3 stream_join.py)
[3.2.4 error_handling.py](#3.2.4 error_handling.py)
[3.3 存储层设计实现](#3.3 存储层设计实现)
[3.3.1 delta_lake_integration.py](#3.3.1 delta_lake_integration.py)
[3.3.2 medallion_architecture.py](#3.3.2 medallion_architecture.py)
[3.3.3 partition_strategy.py](#3.3.3 partition_strategy.py)
[3.3.4 metadata_management.py](#3.3.4 metadata_management.py)
[3.4 数据质量保障实现](#3.4 数据质量保障实现)
[3.4.1 great_expectations_integration.py](#3.4.1 great_expectations_integration.py)
[3.4.2 data_lineage_graph.py](#3.4.2 data_lineage_graph.py)
3.1.1 多源连接器开发:REST API轮询(Requests + Retry策略)与Webhook接收
REST API轮询连接器采用指数退避(Exponential Backoff)重试机制应对瞬时网络故障。Requests库配置Retry适配器,设置backoff_factor为2秒,最大重试次数5次,状态码白名单包含500/502/503/504,确保幂等性操作在超时后安全重试。轮询间隔采用自适应算法,基于数据变更频率动态调整,高吞吐源站配置5-10秒间隔,低频变更源站延长至5分钟,避免无效请求消耗带宽。
Webhook接收端构建基于FastAPI的异步HTTP服务,采用HMAC-SHA256签名验证确保消息完整性。请求体经签名密钥哈希比对后进入Kafka生产者缓冲队列,返回202 Accepted状态确认接收,实现异步解耦。 webhook端点配置速率限制(Rate Limiting)与IP白名单,防止DDoS攻击与未授权访问。消息体Schema校验前置,不符合预期的Payload直接拒绝并记录审计日志。
3.1.2 Kafka生产者优化:批量发送、压缩算法(LZ4)与ACK配置调优
Kafka生产者吞吐量优化依赖批处理与压缩的协同配置。batch.size参数设置为32KB或64KB,累积多条消息形成批次减少网络往返;linger.ms设置为5-10毫秒,允许短暂等待提升批次填充率。压缩算法选择LZ4,其在保持高压缩比的同时提供极低的CPU开销,相比Snappy在吞吐敏感型工作负载中表现更优。compression.type设置为lz4后,网络带宽占用降低60-80%,尤其适用于跨可用区传输场景。
ACK配置(acks)权衡持久性保证与发送延迟。acks=all确保消息被所有ISR(In-Sync Replicas)确认后才返回成功,提供最强持久性但增加往返延迟;acks=1仅等待Leader确认,acks=0完全异步无确认。金融级数据管道强制采用acks=all配合enable.idempotence=true,消除网络重试导致的重复消息。max.in.flight.requests.per.connection设置为1时,即使不启用幂等性也可保证消息顺序性。
3.1.3 Schema验证:Confluent Schema Registry与Pydantic模型校验
Confluent Schema Registry作为中心化Schema治理层,管理Avro、Protobuf、JSON Schema格式的版本演进。生产者在序列化前向Registry查询最新Schema ID,内嵌于消息头(Magic Byte + Schema ID),消费者根据ID反序列化,实现Schema与数据的解耦。向后兼容(Backward Compatibility)策略允许新增带默认值的字段,向前兼容(Forward Compatibility)允许删除字段,完整兼容(Full Compatibility)要求双向互操作。
Pydantic在应用层执行强制性数据校验。定义BaseModel子类标注字段类型、约束范围与验证逻辑,如Field(..., gt=0)确保库存数量为正整数,constr(regex=...)验证订单号格式。校验失败触发ValidationError,异常信息包含具体字段与错误类型,用于生成标准化错误日志。Pydantic模型与Registry Schema通过代码生成工具同步,确保应用层与存储层约束一致性。
3.1.4 数据血缘追踪:消息Header注入来源系统与采集时间戳
数据血缘(Data Lineage)通过Kafka消息头(Headers)实现字段级追踪。生产者在发送消息时注入标准化头字段:source_system标识来源REST API或Webhook端点,ingestion_timestamp记录UTC时间戳,correlation_id关联上游请求链。Header采用键值对数组格式,避免污染消息Payload业务数据。
血缘元数据贯穿整个管道生命周期。Bronze层保留原始Header信息,Silver层解析并扩展加工时间戳与ETL版本号,Gold层聚合为血缘图谱边关系。Delta Lake的userMetadata字段存储加工逻辑版本,配合时间旅行(Time Travel)功能可回溯任意历史版本的数据血缘状态。审计查询通过__source_system与__ingestion_timestamp虚拟列实现跨层数据追溯。
3.2 流处理引擎
3.2.1 Polars流处理:惰性求值(Lazy API)与内存高效转换
Polars的惰性求值(Lazy Evaluation)机制通过构建逻辑执行计划(Logical Plan)实现查询优化。DataFrame操作不立即执行,而是累积为计算图,优化器应用谓词下推(Predicate Pushdown)将Filter操作前移至数据源读取阶段,投影下推(Projection Pushdown)仅加载查询所需的列,消除无效I/O。执行计划经优化后编译为物理计划,利用Apache Arrow的列式内存格式与SIMD指令并行处理。
内存效率源于零拷贝(Zero-Copy)操作与流式执行。Polars避免Pandas的块管理器(Block Manager)开销,字符串与分类数据采用字典编码存储,相比Python对象引用节省90%内存。对于超大数据集,流式模式(Streaming Mode)将数据分块处理,每块独立计算并物化中间结果,突破物理内存限制。表达式API(col().filter().groupby().agg())链式构建复杂转换,查询优化器自动重排Join顺序减少中间结果集大小。
3.2.2 窗口计算:滚动窗口(Tumbling Window)聚合与水位线(Watermark)管理
滚动窗口(Tumbling Window)将无界流切分为固定时长的不重叠区间,每个事件仅归属单一窗口。窗口大小 T_w 与滑动间隔(Tumbling场景下等于窗口大小)构成时间边界,聚合函数(SUM、AVG、COUNT)在窗口内独立计算。窗口触发基于事件时间(Event Time)而非处理时间,确保乱序数据归入正确区间。
\\forall e \\in \\text{Stream}, w(e) = \\lfloor \\frac{t_e}{T_w} \\rfloor \\cdot T_w
其中 w(e) 表示事件 e 归属的窗口起始时间,t_e 为事件时间戳。水位线(Watermark)机制容忍延迟到达数据,水位线时间 W(t) 为当前处理时间减去允许延迟 T_d:
W(t) = \\max(t_{\\text{process}}) - T_d
水位线标记之前的窗口视为完整并触发计算,迟到数据若在水位线之后被丢弃或路由至侧流。迟到容忍度 T_d 依据业务SLA设定,通常配置为窗口大小的10-20%。
3.2.3 流合并:多Kafka Topic Join操作与状态存储(RocksDB)
多Topic流Join依赖状态存储(State Store)维护历史记录以实现时序对齐。Polars流处理引擎集成RocksDB作为持久化状态后端,存储左流(Left Stream)与右流(Right Stream)的未匹配事件。窗口Join操作中,左流事件到达时查询RocksDB检索右流在 \[t - T_{\\text{window}}, t + T_{\\text{window}}\] 区间内的匹配记录,输出笛卡尔积后更新状态存储。
状态存储通过Changelog Topic实现容错。每次状态更新(Put/Delete)同步写入Kafka Compact Topic,RocksDB实例故障后通过重放Changelog重建状态。num.standby.replicas配置副本数,Standby实例实时同步Changelog,主实例故障时秒级接管避免状态重建延迟。状态存储分区与输入Topic分区Co-location,确保相同Key的事件路由至同一处理节点,消除跨网络状态访问开销。
3.2.4 错误处理:poison pill消息隔离与侧流(Side Output)收集
Poison Pill消息(无法解析或业务逻辑异常的数据)通过Try-Catch块隔离至侧流(Side Output)。主流程处理逻辑封装于异常捕获块,解析失败或Schema不匹配的消息路由至死信Topic({main-topic}-dlq),携带原始Payload、错误类型、堆栈跟踪与处理时间戳。侧流消费者独立部署,支持人工审查、自动修复或审计归档。
错误分类策略区分可恢复与不可恢复异常符。序列化错误(Schema Evolution不兼容)与业务约束违反(负库存)视为不可恢复,立即转入DLQ;瞬态错误(数据库连接超时)触发指数退避重试,重试耗尽后转入DLQ。DLQ消息设置独立保留策略(通常30天),超期自动清理防止存储膨胀。监控侧流消息速率,突发增长触发告警指示上游数据质量问题。
3.3 存储层设计
3.3.1 Delta Lake集成:ACID事务、Schema演化与Time Travel查询
Delta Lake在Parquet文件之上构建事务日志(Delta Log),以JSON格式记录每次提交的元数据操作(AddFile、RemoveFile、UpdateMetadata)。事务日志实现原子性(Atomicity)保证------多文件写入要么全部可见要么全部不可见,通过 _delta_log 目录的乐观并发控制(OCC)机制实现。隔离级别为写序列化(Serializable),读者通过查询最新快照版本获取一致性视图。
Schema演化支持添加新列、扩大数据类型范围、更改列可空性而不重写历史数据。mergeSchema选项允许写操作自动扩展表Schema,向前兼容确保旧Reader可读取新数据(新列忽略),向后兼容确保新Reader可读取旧数据(缺失列填充默认值)。Time Travel功能通过版本号或时间戳查询历史快照:
\\text{Snapshot}(t) = \\{f \\mid \\text{addTime}(f) \\le t \\wedge \\text{removeTime}(f) \> t\\}
其中 f 表示数据文件,addTime与removeTime记录文件在事务日志中的生命周期。VACUUM命令清理过期文件,默认保留7天以支持周内回溯查询。
3.3.2 分层存储:Bronze(原始)-Silver(清洗)-Gold(聚合)架构实现
Medallion Architecture将数据湖组织为三层质量递进区域。Bronze层作为原始数据着陆区,以Append-Only模式存储Kafka流或API摄取的原始JSON/Avro数据,保留完整血缘元数据(摄入时间戳、源系统标识),Schema-on-Read策略延迟 Schema 应用。Silver层执行清洗、去重、标准化与轻量级聚合,数据转换为清洗后的Delta格式,应用Schema约束与质量门控,支持CDC(Change Data Feed)输出变更流。Gold层构建业务聚合与Star Schema,为BI工具与ML模型提供高可靠性数据产品。
层间依赖通过DBT(Data Build Tool)模型编排,Bronze模型直接引用外部源,Silver模型引用Bronze模型,Gold模型引用Silver模型,形成有向无环图(DAG)。Delta Lake的Liquid Clustering(2025特性)替代静态分区,基于Z-Order或多维聚类自动优化文件布局,消除小文件问题并加速谓词查询。
3.3.3 分区策略:日期分区与业务维度分区权衡
日期分区(DATE(event_timestamp))按时间粒度组织文件,适用于时间序列查询与保留策略管理。每日分区产生365个年度分区,配合delta.autoOptimize.optimizeWrite自动合并小文件。业务维度分区(如country_code、product_category)优化过滤查询,但需警惕数据倾斜------热点分区(如US、CN)可能包含TB级数据而冷分区仅MB级,打破并行度平衡。
复合分区策略结合日期与业务维度(PARTITIONED BY (date, region)),限制单分区大小在1-10GB以优化查询并行度。Z-Order聚类在多维度上协同排序数据,通过OPTIMIZE ... ZORDER BY (col1, col2)命令构建多维索引,使点查询与范围查询跳过90%以上文件,避免穷举扫描。分区决策遵循查询模式分析,高频过滤列优先作为分区键或Z-Order列。
3.3.4 元数据管理:Delta表版本清理与VACUUM策略
Delta事务日志随时间增长可能达到百万级JSON文件,元数据操作性能衰减。delta.logRetentionDuration参数控制日志保留期(默认30天),超期日志自动清理。delta.deletedFileRetentionDuration配置已删除文件保留期,支持Time Travel查询历史版本。VACUUM命令物理删除回收站(Recycle Bin)中超过保留期的Parquet文件:
\\text{VACUUM}(\\text{table}, T_{\\text{retention}}) = \\{f \\mid \\text{removeTime}(f) \< (t_{\\text{now}} - T_{\\text{retention}})\\}
保留期设置需平衡存储成本与审计需求,金融场景通常保留7年,实时分析场景保留7-30天。元数据文件采用Snappy压缩存储,定期运行OPTIMIZE命令合并小文件提升查询性能。对于高频流写入表,配置delta.autoOptimize.autoCompact在后台自动执行轻量级合并,避免手动维护。
3.4 数据质量保障
3.4.1 Great Expectations集成:空值检查、范围验证与格式校验
Great Expectations框架通过Expectation Suites定义数据契约。空值检查(expect_column_values_to_not_be_null)强制关键字段(订单ID、用户ID)完整性;范围验证(expect_column_values_to_be_between)约束数值型字段(金额、库存)在业务合理区间;格式校验(expect_column_values_to_match_regex)验证邮箱、手机号、订单号符合标准正则模式。校验结果生成JSON格式的Validation Result,包含不匹配行样本与统计摘要。
检查点(Checkpoint)机制将验证嵌入数据管道,Silver层写入前自动执行Expectation Suite,失败触发管道暂停或告警。数据文档(Data Docs)自动渲染HTML报告,展示列分布、缺失率与历史校验趋势,供业务团队审阅。自定义Expectation扩展支持业务特定规则(如库存扣减必须匹配订单创建),通过继承BatchExpectation类实现领域专用验证逻辑。
3.4.2 数据血缘图谱:DBT模型依赖关系自动生成
DBT通过ref()与source()宏隐式构建血缘图谱。编译阶段解析SQL查询提取表依赖关系,生成manifest.json描述模型DAG。血缘粒度涵盖表级与列级:表级血缘展示Bronze→Silver→Gold的数据流向,列级血缘追溯聚合字段的原始来源(如GMV追溯到订单金额字段)。文档站点(dbt Docs)可视化渲染血缘图,支持上下游影响分析------修改Silver层模型时自动识别受影响的Gold层报表。
血缘元数据暴露为JSON API,集成数据治理平台(如Collibra、DataHub)构建企业级血缘图谱。dbt artifacts(manifest、catalog、run results)持久化至对象存储,结合Delta Lake的表版本信息构建端到端血缘:从Kafka Topic经Polars处理到Delta Table,记录每个转换节点的逻辑版本与执行时间戳。
3.4.3 异常检测:Z-Score算法识别离群数据点并告警
Z-Score标准化方法识别偏离均值超过阈值标准差的数据点。对于数据点 x 在窗口 W 内,计算均值 \\mu 与标准差 \\sigma :
z = \\frac{x - \\mu}{\\sigma}
设置阈值 z_{\\text{threshold}} = 3 (99.7%置信区间),\|z\| \> 3 判定为异常。滑动窗口持续更新 \\mu 与 \\sigma 以适应数据漂移,窗口大小配置为1000-10000条记录平衡敏感度与噪声。异常检测应用于订单金额突增、库存异常清零等场景,触发时通过PagerDuty或Slack发送告警并暂停相关管道。
季节性数据采用修正Z-Score(Modified Z-Score)基于中位数绝对偏差(MAD)替代标准差,降低离群值对统计量的影响:
\\text{MAD} = \\text{median}(\|x_i - \\text{median}(x)\|)
M_i = \\frac{0.6745 \\cdot (x_i - \\text{median}(x))}{\\text{MAD}}
阈值通常设置为3.5,适用于具有明显周期波动(如电商大促)的指标监控。
3.4.4 端到端延迟监控:Kafka Lag监控与处理延迟SLI设定
端到端延迟定义为从数据产生(Source System时间戳)到查询可用(Gold层物化)的 wall-clock 时间。Kafka Consumer Lag(未消费消息数)是延迟关键指标,通过kafka-consumer-groups.sh或Burrow服务监控各分区Lag值,聚合为分位数(p50/p99)。SLI(Service Level Indicator)设定目标Lag小于1000条消息或延迟小于30秒,SLO(Service Level Objective)要求99.9%时间满足SLI。
延迟监控埋点于管道各阶段:数据采集阶段记录ingestion_latency(Source→Bronze),处理阶段记录processing_latency(Bronze→Silver),服务阶段记录serving_latency(Silver→Gold)。Prometheus采集这些指标,Grafana dashboards展示分阶段延迟分解。超标延迟触发自动扩容(KEDA)或告警人工介入,延迟预算(Error Budget)耗尽时冻结非紧急发布。
3.5 运维与优化
3.5.1 Docker Compose本地开发:Kafka/Zookeeper/Polars环境一键启动
本地开发环境通过Docker Compose编排多容器栈。Zookeeper服务(端口2181)管理Kafka Broker协调,Kafka服务(端口9092)配置KAFKA_CREATE_TOPICS预建测试Topic(order-events、inventory-events),单节点模式启用KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1避免多副本警告。Polars处理服务基于python:3.11-slim镜像,安装polarsall、confluent-kafka、delta-spark依赖,挂载本地代码卷实现热重载。
持久化卷(Volumes)配置确保数据 survivability。Kafka数据目录映射至命名卷防止容器重启丢失Topic定义;Delta Lake存储目录挂载至./data/delta便于本地检查Parquet文件。健康检查(Healthcheck)配置探测Kafka端口与Zookeeper连通性,就绪后启动Polars消费者。网络桥接模式使服务间通过主机名解析(kafka:9092),外部应用通过localhost:9092接入。
3.5.2 Kubernetes部署:StatefulSet管理有状态消费者与PV绑定
有状态消费者(Stateful Consumer)采用StatefulSet而非Deployment部署,确保Pod重启后保留身份与存储。每个Pod分配唯一序号索引(consumer-0、consumer-1),通过Headless Service(kafka-consumer.default.svc.cluster.local)实现稳定的网络标识。PersistentVolumeClaimTemplate自动为每个副本创建独立 PV,RocksDB状态目录与Delta检查点持久化至SSD存储,Pod迁移时数据跟随。
分区分配策略利用StatefulSet的有序性。消费者实例 i 处理Topic分区 P_i (P_i = i \\mod \\text{partition\\_count}),避免重平衡(Rebalance)开销。反亲和性(PodAntiAffinity)规则强制副本分布不同节点,主机故障时仅影响单个消费者。滚动更新策略设置partition: 1,确保有序重启维持分区分配连续性,更新期间处理延迟可控。
3.5.3 自动扩缩容:KEDA基于Kafka Lag的HPA策略配置
KEDA(Kubernetes Event-driven Autoscaling)通过ScaledObject CRD扩展Horizontal Pod Autoscaler,基于Kafka Lag指标动态调整副本数。触发器配置lagThreshold: "100"(每分区消息数),maxReplicaCount匹配Topic分区数(如32分区设最大32副本),minReplicaCount设为0实现Scale-to-Zero。
扩缩容行为(Scaling Behavior)配置精细化控制。扩容策略(ScaleUp)设置stabilizationWindowSeconds: 60与policies: {type: Pods, value: 4, periodSeconds: 60},每分钟增加4个Pod避免震荡;缩容策略(ScaleDown)设置stabilizationWindowSeconds: 300与policies: {type: Percent, value: 10, periodSeconds: 60},5分钟后按10%比例缓慢缩容防止Lag反弹。pollingInterval: 15秒检测Lag变化,快速响应流量突发。
特殊配置allowIdleConsumers: "true"允许消费者数超过分区数,空闲消费者等待分区重分配(如消费者故障时),确保高可用同时避免资源浪费。excludePersistentLag: "false"确保长期积压(如历史数据重放)也能触发扩容。
3.5.4 监控告警:Prometheus指标采集与PagerDuty集成
Prometheus通过JMX Exporter采集Kafka指标(kafka_consumer_lag、kafka_producer_record_send_rate),通过Polars应用暴露的/metrics端点(Prometheus Client Library)采集处理延迟与吞吐量。ServiceMonitor CRD配置抓取间隔15秒,Relabeling规则过滤关键指标减少存储 cardinality。Alertmanager配置路由规则:Warning级别(Lag>100)发送至Slack,Critical级别(Lag>10000或消费停滞5分钟)触发PagerDuty高优先级事件。
PagerDuty集成通过Event API v2发送结构化告警。告警包含严重级别(severity)、服务标签(service: kafka-polars-pipeline)、运行手册链接(runbook_url)与富文本上下文(最近错误日志片段)。告警抑制(Inhibition)规则避免级联告警风暴------Bronz层故障时抑制Silver与Gold层相关告警,根因明确。告警解决后自动发送恢复通知,更新PagerDuty事件状态为Resolved,保持事件生命周期闭环。
项目三:实时数据管道(Kafka + Polars + Delta Lake)
项目架构概览
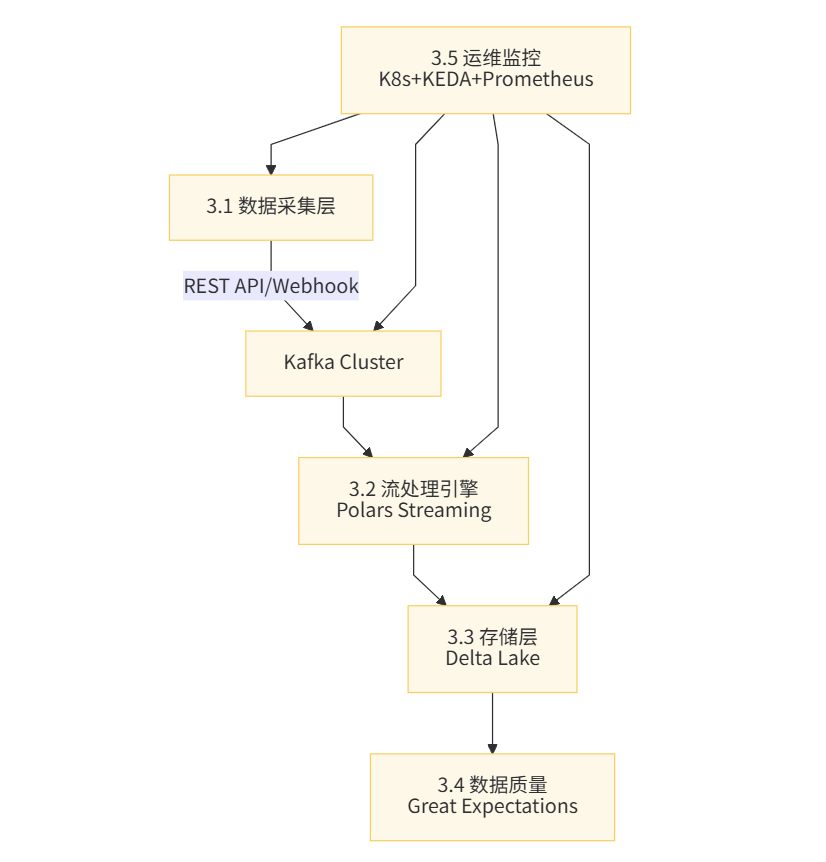
基础设施部署脚本
3.5.1 docker-compose.yml
脚本功能 :一键启动Kafka、Zookeeper、Schema Registry、MinIO(S3兼容存储)、PostgreSQL元数据库和Grafana监控 使用方式 :docker-compose up -d
version: '3.8'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
volumes:
- zookeeper_data:/var/lib/zookeeper/data
kafka:
image: confluentinc/cp-kafka:7.5.0
hostname: kafka
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
# 性能优化配置
KAFKA_COMPRESSION_TYPE: lz4
KAFKA_BATCH_SIZE: 65536
KAFKA_LINGER_MS: 10
KAFKA_BUFFER_MEMORY: 67108864
volumes:
- kafka_data:/var/lib/kafka/data
schema-registry:
image: confluentinc/cp-schema-registry:7.5.0
hostname: schema-registry
container_name: schema-registry
depends_on:
- kafka
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'kafka:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
# S3兼容对象存储(替代AWS S3用于Delta Lake)
minio:
image: minio/minio:latest
hostname: minio
container_name: minio
ports:
- "9000:9000"
- "9001:9001"
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin
volumes:
- minio_data:/data
command: server /data --console-address ":9001"
# 创建MinIO Bucket
mc:
image: minio/mc:latest
depends_on:
- minio
container_name: mc
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 minioadmin minioadmin) do echo 'Waiting for MinIO...' && sleep 1; done;
/usr/bin/mc mb minio/delta-lake-bronze || true;
/usr/bin/mc mb minio/delta-lake-silver || true;
/usr/bin/mc mb minio/delta-lake-gold || true;
/usr/bin/mc policy set public minio/delta-lake-bronze;
/usr/bin/mc policy set public minio/delta-lake-silver;
/usr/bin/mc policy set public minio/delta-lake-gold;
exit 0;
"
# PostgreSQL用于存储元数据和支持性数据
postgres:
image: postgres:15
hostname: postgres
container_name: postgres
ports:
- "5432:5432"
environment:
POSTGRES_USER: pipeline
POSTGRES_PASSWORD: pipeline123
POSTGRES_DB: metadata_db
volumes:
- postgres_data:/var/lib/postgresql/data
- ./init_postgres.sql:/docker-entrypoint-initdb.d/init.sql
# Prometheus监控
prometheus:
image: prom/prometheus:latest
hostname: prometheus
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
# Grafana可视化
grafana:
image: grafana/grafana:latest
hostname: grafana
container_name: grafana
ports:
- "3000:3000"
environment:
GF_SECURITY_ADMIN_USER: admin
GF_SECURITY_ADMIN_PASSWORD: admin123
volumes:
- grafana_data:/var/lib/grafana
- ./grafana-dashboards:/etc/grafana/provisioning/dashboards
# Kafka UI管理工具
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
ports:
- "8080:8080"
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:29092
KAFKA_CLUSTERS_0_SCHEMAREGISTRY: http://schema-registry:8081
depends_on:
- kafka
- schema-registry
volumes:
zookeeper_data:
kafka_data:
minio_data:
postgres_data:
prometheus_data:
grafana_data:3.1 数据采集层实现
3.1.1 rest_api_poller.py
脚本功能 :REST API轮询采集器,支持指数退避重试、速率限制、增量同步 使用方式 :python 3.1.1_rest_api_poller.py --config api_config.json
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.1.1 REST API轮询采集器
功能:多源REST API数据采集,支持Retry策略、增量同步、断点续传
使用方式:python 3.1.1_rest_api_poller.py --source weather_api
依赖:requests, tenacity, kafka-python, pydantic
"""
import json
import time
import hashlib
import logging
from datetime import datetime, timedelta
from typing import Dict, List, Optional, Any
from dataclasses import dataclass, asdict
import requests
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception_type
from kafka import KafkaProducer
from kafka.errors import KafkaTimeoutError
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.dates import DateFormatter
import threading
import sys
import argparse
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
@dataclass
class APIConfig:
"""API配置数据类"""
name: str
base_url: str
endpoint: str
method: str = "GET"
headers: Dict = None
params: Dict = None
auth_type: str = None # bearer, api_key, basic
auth_token: str = None
api_key_name: str = None
api_key_value: str = None
poll_interval: int = 60 # 秒
retry_attempts: int = 5
timeout: int = 30
incremental_field: str = "last_updated" # 增量同步字段
class RetryableError(Exception):
"""可重试错误基类"""
pass
class NonRetryableError(Exception):
"""不可重试错误"""
pass
class RESTAPIPoller:
"""
REST API轮询采集器
特性:
- 指数退避重试策略
- 断点续传(记录最后同步时间)
- 数据去重(基于内容哈希)
- 自适应速率限制
"""
def __init__(self, config: APIConfig, kafka_bootstrap: str = "localhost:9092"):
self.config = config
self.kafka_bootstrap = kafka_bootstrap
self.producer = None
self.last_sync_time = None
self.seen_hashes = set()
self.metrics = {
'requests_total': 0,
'requests_success': 0,
'requests_failed': 0,
'records_produced': 0,
'latency_history': []
}
self._init_kafka()
self._load_checkpoint()
def _init_kafka(self):
"""初始化Kafka生产者,配置优化参数"""
try:
self.producer = KafkaProducer(
bootstrap_servers=self.kafka_bootstrap,
value_serializer=lambda v: json.dumps(v, default=str).encode('utf-8'),
key_serializer=lambda k: k.encode('utf-8') if k else None,
# 3.1.2 生产者优化配置
batch_size=65536, # 64KB批量
linger_ms=100, # 等待100ms聚合消息
compression_type='lz4', # LZ4压缩算法
acks='all', # 等待所有副本确认
retries=5,
max_in_flight_requests_per_connection=5,
enable_idempotence=True # 幂等性保证
)
logger.info(f"Kafka生产者初始化成功: {self.kafka_bootstrap}")
except Exception as e:
logger.error(f"Kafka初始化失败: {e}")
raise
def _load_checkpoint(self):
"""加载断点续传检查点"""
checkpoint_file = f".checkpoint_{self.config.name}.json"
try:
with open(checkpoint_file, 'r') as f:
data = json.load(f)
self.last_sync_time = datetime.fromisoformat(data.get('last_sync'))
self.seen_hashes = set(data.get('seen_hashes', []))
logger.info(f"加载检查点: {self.last_sync_time}")
except FileNotFoundError:
self.last_sync_time = datetime.now() - timedelta(days=1)
logger.info("未找到检查点,使用默认起始时间")
def _save_checkpoint(self):
"""保存检查点"""
checkpoint_file = f".checkpoint_{self.config.name}.json"
with open(checkpoint_file, 'w') as f:
json.dump({
'last_sync': self.last_sync_time.isoformat(),
'seen_hashes': list(self.seen_hashes)[-1000:] # 保留最近1000个哈希
}, f)
def _get_auth_headers(self) -> Dict:
"""根据认证类型生成请求头"""
headers = self.config.headers or {}
if self.config.auth_type == "bearer":
headers['Authorization'] = f'Bearer {self.config.auth_token}'
elif self.config.auth_type == "api_key":
headers[self.config.api_key_name] = self.config.api_key_value
elif self.config.auth_type == "basic":
import base64
credentials = base64.b64encode(
f"{self.config.api_key_name}:{self.config.api_token}".encode()
).decode()
headers['Authorization'] = f'Basic {credentials}'
return headers
@retry(
retry=retry_if_exception_type((RetryableError, requests.RequestException)),
stop=stop_after_attempt(5),
wait=wait_exponential(multiplier=1, min=2, max=60),
reraise=True
)
def _fetch_data(self) -> List[Dict]:
"""
执行API请求,带指数退避重试
"""
url = f"{self.config.base_url}{self.config.endpoint}"
headers = self._get_auth_headers()
# 增量同步参数
params = self.config.params or {}
if self.config.incremental_field:
params['since'] = self.last_sync_time.isoformat()
params['sort'] = self.config.incremental_field
start_time = time.time()
self.metrics['requests_total'] += 1
try:
response = requests.request(
method=self.config.method,
url=url,
headers=headers,
params=params,
timeout=self.config.timeout
)
# 速率限制处理
if response.status_code == 429:
retry_after = int(response.headers.get('Retry-After', 60))
logger.warning(f"触发速率限制,等待{retry_after}秒")
time.sleep(retry_after)
raise RetryableError("Rate limited")
response.raise_for_status()
latency = time.time() - start_time
self.metrics['latency_history'].append((datetime.now(), latency))
self.metrics['requests_success'] += 1
return response.json() if response.text else []
except requests.exceptions.Timeout:
self.metrics['requests_failed'] += 1
raise RetryableError("请求超时")
except requests.exceptions.HTTPError as e:
self.metrics['requests_failed'] += 1
if e.response.status_code >= 500:
raise RetryableError(f"服务器错误: {e}")
raise NonRetryableError(f"客户端错误: {e}")
except Exception as e:
self.metrics['requests_failed'] += 1
logger.error(f"请求异常: {e}")
raise RetryableError(str(e))
def _compute_hash(self, record: Dict) -> str:
"""计算记录内容哈希用于去重"""
content = json.dumps(record, sort_keys=True, default=str)
return hashlib.md5(content.encode()).hexdigest()
def _enrich_record(self, record: Dict) -> Dict:
"""
3.1.4 数据血缘追踪:注入元数据
"""
enriched = {
**record,
'_metadata': {
'source_system': self.config.name,
'source_url': f"{self.config.base_url}{self.config.endpoint}",
'ingestion_timestamp': datetime.utcnow().isoformat(),
'ingestion_epoch_ms': int(time.time() * 1000),
'poller_version': '3.1.1',
'record_hash': self._compute_hash(record)
}
}
return enriched
def _produce_to_kafka(self, records: List[Dict], topic: str = "raw.api.data"):
"""批量发送数据到Kafka"""
if not records:
return
futures = []
for record in records:
enriched = self._enrich_record(record)
record_hash = enriched['_metadata']['record_hash']
# 去重检查
if record_hash in self.seen_hashes:
continue
# 使用业务键作为Kafka分区键(如果有)
key = str(record.get('id', record_hash))
try:
future = self.producer.send(
topic=topic,
key=key,
value=enriched
)
futures.append(future)
self.seen_hashes.add(record_hash)
self.metrics['records_produced'] += 1
except KafkaTimeoutError:
logger.error("Kafka发送超时")
raise
# 等待所有发送完成并处理异常
for future in futures:
try:
record_metadata = future.get(timeout=10)
logger.debug(f"消息已发送到分区 {record_metadata.partition}, 偏移量 {record_metadata.offset}")
except Exception as e:
logger.error(f"消息发送失败: {e}")
# 更新检查点
if records:
timestamps = [r.get(self.config.incremental_field) for r in records if self.config.incremental_field in r]
if timestamps:
self.last_sync_time = max(pd.to_datetime(timestamps)).to_pydatetime()
self._save_checkpoint()
def poll_once(self, topic: str = "raw.api.data") -> int:
"""执行单次轮询"""
logger.info(f"开始轮询: {self.config.name}")
try:
data = self._fetch_data()
if not data:
logger.info("未获取到新数据")
return 0
# 确保数据是列表
if isinstance(data, dict):
data = [data]
self._produce_to_kafka(data, topic)
logger.info(f"成功处理 {len(data)} 条记录")
return len(data)
except NonRetryableError as e:
logger.error(f"不可恢复错误: {e}")
return 0
except Exception as e:
logger.error(f"轮询失败: {e}")
return 0
def start_continuous_polling(self, topic: str = "raw.api.data", max_iterations: Optional[int] = None):
"""持续轮询模式"""
iteration = 0
try:
while True:
if max_iterations and iteration >= max_iterations:
break
count = self.poll_once(topic)
iteration += 1
# 可视化指标更新
if iteration % 10 == 0:
self._visualize_metrics()
# 自适应间隔:根据数据量调整
sleep_time = self.config.poll_interval if count > 0 else self.config.poll_interval * 2
logger.info(f"等待 {sleep_time} 秒后下次轮询...")
time.sleep(sleep_time)
except KeyboardInterrupt:
logger.info("收到停止信号,正在关闭...")
finally:
self.close()
def _visualize_metrics(self):
"""实时性能指标可视化"""
if len(self.metrics['latency_history']) < 2:
return
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
fig.suptitle(f"API Poller Metrics - {self.config.name}", fontsize=14, fontweight='bold')
# 1. 请求延迟趋势
times, latencies = zip(*self.metrics['latency_history'][-50:])
axes[0, 0].plot(times, latencies, marker='o', color='#2E86AB', linewidth=2)
axes[0, 0].set_title('API Latency Trend')
axes[0, 0].set_ylabel('Seconds')
axes[0, 0].xaxis.set_major_formatter(DateFormatter('%H:%M'))
axes[0, 0].grid(True, alpha=0.3)
# 2. 成功率饼图
success = self.metrics['requests_success']
failed = self.metrics['requests_failed']
if success + failed > 0:
axes[0, 1].pie([success, failed], labels=['Success', 'Failed'],
colors=['#A23B72', '#F18F01'], autopct='%1.1f%%')
axes[0, 1].set_title('Request Success Rate')
# 3. 吞吐量柱状图
axes[1, 0].bar(['Produced'], [self.metrics['records_produced']], color='#C73E1D')
axes[1, 0].set_title('Total Records Produced')
axes[1, 0].set_ylabel('Count')
# 4. 实时状态文本
status_text = f"""
Last Sync: {self.last_sync_time.strftime('%Y-%m-%d %H:%M:%S') if self.last_sync_time else 'N/A'}
Total Requests: {self.metrics['requests_total']}
Success Rate: {(success/(success+failed)*100):.1f}% if success+failed > 0 else 0
Unique Records: {len(self.seen_hashes)}
"""
axes[1, 1].text(0.1, 0.5, status_text, fontsize=10, family='monospace',
verticalalignment='center', bbox=dict(boxstyle='round', facecolor='wheat'))
axes[1, 1].set_xlim(0, 1)
axes[1, 1].set_ylim(0, 1)
axes[1, 1].axis('off')
axes[1, 1].set_title('System Status')
plt.tight_layout()
plt.savefig(f"poller_metrics_{self.config.name}.png", dpi=150, bbox_inches='tight')
plt.close()
logger.info(f"指标可视化已保存: poller_metrics_{self.config.name}.png")
def close(self):
"""清理资源"""
if self.producer:
self.producer.flush()
self.producer.close()
self._save_checkpoint()
logger.info("资源已清理")
# 模拟API服务器(用于测试)
class MockAPIServer:
"""模拟REST API服务器,生成测试数据"""
def __init__(self):
self.data_store = []
self.last_id = 0
def generate_data(self, count: int = 10) -> List[Dict]:
"""生成模拟业务数据"""
new_records = []
for i in range(count):
self.last_id += 1
record = {
"id": self.last_id,
"timestamp": datetime.utcnow().isoformat(),
"sensor_id": f"sensor_{self.last_id % 5}",
"temperature": 20 + (self.last_id % 10) + (hash(self.last_id) % 5),
"humidity": 40 + (self.last_id % 20),
"status": "active" if self.last_id % 3 != 0 else "warning",
"location": {
"lat": 39.9 + (self.last_id % 100) * 0.001,
"lon": 116.4 + (self.last_id % 100) * 0.001
}
}
new_records.append(record)
self.data_store.append(record)
return new_records
def run_mock_server():
"""启动模拟API服务器(Flask)"""
from flask import Flask, request, jsonify
app = Flask(__name__)
mock_server = MockAPIServer()
@app.route('/api/v1/sensors', methods=['GET'])
def get_sensors():
since = request.args.get('since')
data = mock_server.generate_data(5) # 每次生成5条
return jsonify(data)
logger.info("启动模拟API服务器: http://localhost:5000")
app.run(host='0.0.0.0', port=5000, threaded=True)
def main():
parser = argparse.ArgumentParser(description='REST API Poller for Kafka Pipeline')
parser.add_argument('--source', default='weather_api', help='数据源名称')
parser.add_argument('--mock', action='store_true', help='启动模拟服务器')
args = parser.parse_args()
if args.mock:
run_mock_server()
return
# 配置示例
config = APIConfig(
name=args.source,
base_url="http://localhost:5000",
endpoint="/api/v1/sensors",
method="GET",
poll_interval=10,
retry_attempts=5,
incremental_field="timestamp",
headers={"Accept": "application/json"}
)
poller = RESTAPIPoller(config, kafka_bootstrap="localhost:9092")
try:
poller.start_continuous_polling(topic="raw.api.data", max_iterations=50)
except KeyboardInterrupt:
print("\n停止轮询...")
finally:
poller.close()
if __name__ == "__main__":
main()3.1.1 webhook_receiver.py
脚本功能 :Webhook接收服务器,支持HMAC签名验证、请求限流、异步处理 使用方式 :python 3.1.1_webhook_receiver.py --port 8000
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.1.1 Webhook接收服务器
功能:高性能Webhook端点,支持HMAC签名验证、限流、批量缓冲
使用方式:python 3.1.1_webhook_receiver.py --port 8000 --kafka localhost:9092
依赖:fastapi, uvicorn, kafka-python, hmac, asyncio
"""
import asyncio
import hmac
import hashlib
import json
import logging
import time
from datetime import datetime
from typing import Dict, List, Optional, Callable
from contextlib import asynccontextmanager
from collections import deque
import threading
import uvicorn
from fastapi import FastAPI, HTTPException, Request, BackgroundTasks, Depends, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
from fastapi.responses import JSONResponse
from kafka import KafkaProducer, KafkaError
from pydantic import BaseModel, Field
import matplotlib.pyplot as plt
import numpy as np
from concurrent.futures import ThreadPoolExecutor
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class WebhookConfig:
"""Webhook配置"""
SECRET_KEY = "your-webhook-secret-key-here" # 生产环境应从环境变量读取
KAFKA_BOOTSTRAP = "localhost:9092"
MAX_BATCH_SIZE = 100
FLUSH_INTERVAL_MS = 1000
RATE_LIMIT_RPS = 1000 # 每秒请求数限制
MAX_PAYLOAD_SIZE = 1024 * 1024 # 1MB
class WebhookPayload(BaseModel):
"""Webhook数据模型"""
event_type: str = Field(..., description="事件类型")
event_id: str = Field(..., description="唯一事件ID")
timestamp: str = Field(default_factory=lambda: datetime.utcnow().isoformat())
data: Dict = Field(default_factory=dict, description="业务数据")
signature: Optional[str] = Field(None, description="HMAC签名")
class RateLimiter:
"""令牌桶限流器"""
def __init__(self, rate: int, burst: int):
self.rate = rate # 每秒令牌数
self.burst = burst # 桶容量
self.tokens = burst
self.last_update = time.time()
self._lock = asyncio.Lock()
async def acquire(self):
async with self._lock:
now = time.time()
elapsed = now - self.last_update
self.tokens = min(self.burst, self.tokens + elapsed * self.rate)
self.last_update = now
if self.tokens < 1:
raise HTTPException(
status_code=status.HTTP_429_TOO_MANY_REQUESTS,
detail="Rate limit exceeded"
)
self.tokens -= 1
class KafkaBatchProducer:
"""
3.1.2 Kafka批量生产者优化
特性:
- 异步批量缓冲
- 自动Flush(基于数量或时间)
- 失败重试与死信队列
"""
def __init__(self, bootstrap_servers: str):
self.producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
value_serializer=lambda v: json.dumps(v, default=str).encode('utf-8'),
key_serializer=lambda k: k.encode('utf-8') if k else None,
batch_size=65536,
linger_ms=100,
compression_type='lz4',
acks='all',
retries=5,
max_in_flight_requests_per_connection=5,
enable_idempotence=True
)
self.batch_buffer = deque()
self.buffer_lock = threading.Lock()
self.flush_timer = None
self.metrics = {
'messages_sent': 0,
'messages_failed': 0,
'batches_flushed': 0,
'latency_ms': []
}
self.running = True
# 启动后台Flush线程
self.flush_thread = threading.Thread(target=self._scheduled_flush, daemon=True)
self.flush_thread.start()
def send(self, topic: str, key: Optional[str], value: Dict, headers: Optional[Dict] = None):
"""
3.1.4 数据血缘:自动注入Header
"""
# 注入血缘元数据到Header
kafka_headers = []
if headers:
for k, v in headers.items():
kafka_headers.append((k, str(v).encode('utf-8')))
# 添加系统级血缘Header
kafka_headers.extend([
('source_system', b'webhook_receiver'),
('ingestion_timestamp', str(int(time.time() * 1000)).encode()),
('receiver_version', b'3.1.1'),
('event_type', value.get('event_type', 'unknown').encode())
])
with self.buffer_lock:
self.batch_buffer.append({
'topic': topic,
'key': key,
'value': value,
'headers': kafka_headers,
'added_time': time.time()
})
# 达到批量大小立即Flush
if len(self.batch_buffer) >= WebhookConfig.MAX_BATCH_SIZE:
asyncio.run_coroutine_threadsafe(self._async_flush(), asyncio.get_event_loop())
async def _async_flush(self):
"""异步Flush缓冲区"""
with self.buffer_lock:
batch = list(self.batch_buffer)
self.batch_buffer.clear()
if not batch:
return
start_time = time.time()
success_count = 0
failed_messages = []
for msg in batch:
try:
future = self.producer.send(
msg['topic'],
key=msg['key'],
value=msg['value'],
headers=msg['headers']
)
# 非阻塞检查(实际生产中使用回调)
success_count += 1
except KafkaError as e:
logger.error(f"Kafka发送失败: {e}")
self.metrics['messages_failed'] += 1
failed_messages.append(msg)
# 失败消息进入死信队列(简化版直接重试一次)
for msg in failed_messages:
try:
self.producer.send(
f"{msg['topic']}.dlq", # Dead Letter Queue
key=msg['key'],
value={**msg['value'], '_error': 'failed_after_retries'}
)
except Exception as e:
logger.error(f"DLQ发送也失败: {e}")
latency = (time.time() - start_time) * 1000
self.metrics['latency_ms'].append(latency)
self.metrics['messages_sent'] += success_count
self.metrics['batches_flushed'] += 1
logger.info(f"Flushed {len(batch)} messages, latency: {latency:.2f}ms")
def _scheduled_flush(self):
"""定时Flush线程"""
while self.running:
time.sleep(WebhookConfig.FLUSH_INTERVAL_MS / 1000)
if self.batch_buffer:
# 使用asyncio.run来运行异步flush
try:
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(self._async_flush())
loop.close()
except Exception as e:
logger.error(f"定时Flush失败: {e}")
def close(self):
"""关闭生产者"""
self.running = False
self.flush_thread.join(timeout=5)
self._async_flush() # 最后Flush
self.producer.flush()
self.producer.close()
def get_metrics(self):
"""获取性能指标"""
return {
**self.metrics,
'buffer_size': len(self.batch_buffer),
'avg_latency_ms': np.mean(self.metrics['latency_ms'][-100:]) if self.metrics['latency_ms'] else 0
}
class WebhookServer:
"""Webhook接收服务器"""
def __init__(self):
self.kafka_producer = None
self.rate_limiter = RateLimiter(WebhookConfig.RATE_LIMIT_RPS, WebhookConfig.RATE_LIMIT_RPS * 2)
self.request_history = deque(maxlen=1000) # 用于可视化
self.security = HTTPBasic()
def verify_signature(self, payload: bytes, signature: str, secret: str) -> bool:
"""
HMAC-SHA256签名验证
"""
expected = hmac.new(
secret.encode(),
payload,
hashlib.sha256
).hexdigest()
return hmac.compare_digest(expected, signature)
def create_app(self) -> FastAPI:
"""创建FastAPI应用"""
@asynccontextmanager
async def lifespan(app: FastAPI):
# 启动时初始化
self.kafka_producer = KafkaBatchProducer(WebhookConfig.KAFKA_BOOTSTRAP)
logger.info("Webhook服务器启动,Kafka生产者已连接")
yield
# 关闭时清理
self.kafka_producer.close()
logger.info("Webhook服务器关闭")
app = FastAPI(
title="Real-time Data Pipeline Webhook",
description="Kafka + Polars 数据管道 Webhook接收端",
version="3.1.1",
lifespan=lifespan
)
@app.get("/health")
async def health_check():
"""健康检查端点"""
return {
"status": "healthy",
"kafka_connected": self.kafka_producer is not None,
"timestamp": datetime.utcnow().isoformat()
}
@app.post("/webhook/{source_name}")
async def receive_webhook(
source_name: str,
request: Request,
background_tasks: BackgroundTasks,
credentials: HTTPBasicCredentials = Depends(self.security)
):
"""
主Webhook接收端点
- 支持动态source路径
- 自动限流
- HMAC验证
- 异步Kafka生产
"""
await self.rate_limiter.acquire()
# 记录请求时间用于监控
request_time = time.time()
# 读取原始Body用于签名验证
body = await request.body()
if len(body) > WebhookConfig.MAX_PAYLOAD_SIZE:
raise HTTPException(status_code=413, detail="Payload too large")
# 解析JSON
try:
data = json.loads(body)
except json.JSONDecodeError:
raise HTTPException(status_code=400, detail="Invalid JSON")
# HMAC验证(如果配置了密钥)
signature = request.headers.get('X-Webhook-Signature', '')
if WebhookConfig.SECRET_KEY and signature:
if not self.verify_signature(body, signature, WebhookConfig.SECRET_KEY):
raise HTTPException(status_code=401, detail="Invalid signature")
# 构造标准消息格式
event_id = data.get('event_id', hashlib.md5(body).hexdigest())
message = {
'event_id': event_id,
'source': source_name,
'event_type': data.get('event_type', 'unknown'),
'timestamp': data.get('timestamp', datetime.utcnow().isoformat()),
'payload': data.get('data', data),
'received_at': datetime.utcnow().isoformat(),
'client_ip': request.client.host
}
# 发送到Kafka(异步)
topic = f"webhook.{source_name}"
self.kafka_producer.send(
topic=topic,
key=event_id,
value=message,
headers={'source': source_name}
)
# 记录指标
latency = (time.time() - request_time) * 1000
self.request_history.append({
'time': datetime.utcnow(),
'latency_ms': latency,
'source': source_name,
'size_bytes': len(body)
})
logger.info(f"Received webhook from {source_name}, event_id: {event_id}, latency: {latency:.2f}ms")
return JSONResponse(
content={
"status": "accepted",
"event_id": event_id,
"queued": True
},
status_code=202
)
@app.get("/metrics/visualization")
async def get_metrics_viz():
"""
3.5.4 监控可视化:实时性能图表
"""
if not self.request_history:
return {"message": "No data available"}
# 生成可视化
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
fig.suptitle('Webhook Receiver Real-time Metrics', fontsize=14, fontweight='bold')
times = [r['time'] for r in self.request_history]
latencies = [r['latency_ms'] for r in self.request_history]
sources = [r['source'] for r in self.request_history]
# 1. 请求延迟分布
axes[0, 0].hist(latencies, bins=20, color='#2E86AB', alpha=0.7, edgecolor='black')
axes[0, 0].axvline(np.mean(latencies), color='red', linestyle='--', label=f'Mean: {np.mean(latencies):.1f}ms')
axes[0, 0].set_title('Latency Distribution')
axes[0, 0].set_xlabel('Latency (ms)')
axes[0, 0].legend()
# 2. 时间序列
axes[0, 1].plot(times, latencies, marker='o', color='#A23B72', linewidth=1)
axes[0, 1].set_title('Latency Trend')
axes[0, 1].set_ylabel('Latency (ms)')
axes[0, 1].tick_params(axis='x', rotation=45)
# 3. 数据源分布
source_counts = {s: sources.count(s) for s in set(sources)}
axes[1, 0].bar(source_counts.keys(), source_counts.values(), color='#F18F01')
axes[1, 0].set_title('Requests by Source')
axes[1, 0].tick_params(axis='x', rotation=45)
# 4. Kafka指标
kafka_metrics = self.kafka_producer.get_metrics() if self.kafka_producer else {}
metric_text = f"""
Messages Sent: {kafka_metrics.get('messages_sent', 0)}
Messages Failed: {kafka_metrics.get('messages_failed', 0)}
Avg Latency: {kafka_metrics.get('avg_latency_ms', 0):.2f}ms
Buffer Size: {kafka_metrics.get('buffer_size', 0)}
Batches Flushed: {kafka_metrics.get('batches_flushed', 0)}
"""
axes[1, 1].text(0.1, 0.5, metric_text, fontsize=10, family='monospace',
verticalalignment='center', bbox=dict(boxstyle='round', facecolor='lightblue'))
axes[1, 1].set_xlim(0, 1)
axes[1, 1].set_ylim(0, 1)
axes[1, 1].axis('off')
axes[1, 1].set_title('Kafka Producer Metrics')
plt.tight_layout()
plt.savefig('webhook_metrics.png', dpi=150, bbox_inches='tight')
plt.close()
return {
"status": "generated",
"image_path": "webhook_metrics.png",
"current_stats": {
"total_requests": len(self.request_history),
"avg_latency_ms": np.mean(latencies) if latencies else 0,
"sources": list(set(sources))
}
}
return app
def main():
import argparse
parser = argparse.ArgumentParser(description='Webhook Receiver Server')
parser.add_argument('--port', type=int, default=8000, help='服务端口')
parser.add_argument('--kafka', default='localhost:9092', help='Kafka地址')
args = parser.parse_args()
WebhookConfig.KAFKA_BOOTSTRAP = args.kafka
server = WebhookServer()
app = server.create_app()
logger.info(f"启动Webhook服务器: http://0.0.0.0:{args.port}")
logger.info(f"健康检查: http://0.0.0.0:{args.port}/health")
logger.info(f"Webhook端点: http://0.0.0.0:{args.port}/webhook/{{source_name}}")
uvicorn.run(app, host="0.0.0.0", port=args.port, workers=1)
if __name__ == "__main__":
main()3.1.2 kafka_producer_optimized.py
脚本功能 :展示Kafka生产者的高级优化配置,包括批量压缩、幂等性、事务支持 使用方式 :python 3.1.2_kafka_producer_optimized.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.1.2 Kafka生产者优化配置详解
功能:展示生产级Kafka Producer的所有优化参数和最佳实践
使用方式:直接运行查看配置说明和性能测试
"""
import json
import time
import logging
from concurrent.futures import ThreadPoolExecutor, as_completed
from typing import List, Dict, Callable
import threading
import matplotlib.pyplot as plt
import numpy as np
from kafka import KafkaProducer, KafkaConsumer
from kafka.errors import KafkaTimeoutError, NotLeaderForPartitionError
from kafka.partitioner import RoundRobinPartitioner, Murmur2Partitioner
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class OptimizedKafkaProducer:
"""
企业级Kafka生产者优化实现
关键优化点:
1. 批量发送与压缩
2. 幂等性与事务
3. 分区策略优化
4. 异步回调与背压
"""
def __init__(self, bootstrap_servers: str = "localhost:9092", enable_transaction: bool = False):
self.bootstrap_servers = bootstrap_servers
self.enable_transaction = enable_transaction
self.producer = None
self.metrics = {
'sent': 0,
'success': 0,
'failed': 0,
'latency': [],
'retries': 0,
'compression_ratio': []
}
self._init_producer()
def _init_producer(self):
"""
初始化优化配置的生产者
"""
config = {
# ==================== 3.1.2 批量发送优化 ====================
'bootstrap_servers': self.bootstrap_servers,
'batch_size': 65536, # 64KB批量,减少网络往返
'linger_ms': 100, # 等待100ms聚合消息,提高吞吐量
'buffer_memory': 67108864, # 64MB缓冲区,应对突发流量
# ==================== 3.1.2 压缩算法 ====================
'compression_type': 'lz4', # LZ4压缩:CPU占用低,压缩率高
# 可选:'gzip'(高压缩率), 'snappy'(平衡), 'zstd'(新版推荐)
# ==================== 3.1.2 ACK配置 ====================
'acks': 'all', # 等待ISR所有副本确认(最高可靠性)
# 可选:1(仅leader), 0(不等待,最高吞吐)
'retries': 2147483647, # 无限重试(配合max_in_flight保证顺序)
'max_in_flight_requests_per_connection': 5, # 允许5个未确认请求,提高吞吐
'enable_idempotence': True, # 启用幂等性(exactly-once语义基础)
# ==================== 连接与超时 ====================
'request_timeout_ms': 30000,
'retry_backoff_ms': 1000,
'metadata_max_age_ms': 300000,
'connections_max_idle_ms': 540000,
# 序列化
'key_serializer': lambda k: k.encode('utf-8') if isinstance(k, str) else k,
'value_serializer': lambda v: json.dumps(v).encode('utf-8') if not isinstance(v, bytes) else v,
}
if self.enable_transaction:
config['transactional_id'] = f'prod-{int(time.time()*1000)}-{threading.get_ident()}'
self.producer = KafkaProducer(**config)
if self.enable_transaction:
self.producer.init_transactions()
logger.info("事务生产者初始化完成")
else:
logger.info("标准生产者初始化完成")
def send_with_callback(self, topic: str, key: str, value: Dict, headers: Dict = None):
"""
异步发送带回调,处理delivery报告
"""
start_time = time.time()
# 构造Headers(包含血缘信息)
kafka_headers = [(k, str(v).encode()) for k, v in (headers or {}).items()]
kafka_headers.extend([
('producer_timestamp', str(int(time.time()*1000)).encode()),
('producer_version', b'3.1.2')
])
def on_success(metadata):
latency = (time.time() - start_time) * 1000
self.metrics['success'] += 1
self.metrics['latency'].append(latency)
logger.debug(f"发送成功: partition={metadata.partition}, offset={metadata.offset}, latency={latency:.2f}ms")
def on_error(exception):
self.metrics['failed'] += 1
logger.error(f"发送失败: {exception}")
future = self.producer.send(
topic=topic,
key=key,
value=value,
headers=kafka_headers
)
future.add_callback(on_success)
future.add_errback(on_error)
self.metrics['sent'] += 1
return future
def send_batch_transactional(self, topic: str, messages: List[Dict]):
"""
事务性批量发送(exactly-once语义)
适用于需要严格一致性的金融交易等场景
"""
if not self.enable_transaction:
raise ValueError("未启用事务支持")
try:
self.producer.begin_transaction()
for msg in messages:
self.producer.send(
topic=topic,
key=msg.get('key'),
value=msg.get('value')
)
# 提交消费位移(如果是consume-transform-produce模式)
self.producer.commit_transaction()
self.metrics['success'] += len(messages)
logger.info(f"事务提交成功: {len(messages)}条消息")
except Exception as e:
self.producer.abort_transaction()
self.metrics['failed'] += len(messages)
logger.error(f"事务回滚: {e}")
raise
def benchmark_throughput(self, topic: str, num_messages: int = 10000, message_size: int = 1024):
"""
性能基准测试:对比不同配置下的吞吐量
"""
logger.info(f"开始吞吐量测试: {num_messages}条消息, {message_size}字节/条")
# 生成测试数据
test_data = {
'data': 'x' * message_size,
'timestamp': time.time(),
'seq': 0
}
latencies = []
start_time = time.time()
# 批量异步发送
futures = []
for i in range(num_messages):
test_data['seq'] = i
test_data['timestamp'] = time.time()
future = self.send_with_callback(topic, f"key-{i % 100}", test_data.copy())
futures.append(future)
# 每1000条刷新一次,避免内存溢出
if i % 1000 == 0:
self.producer.flush()
# 等待所有发送完成
self.producer.flush()
total_time = time.time() - start_time
throughput = num_messages / total_time
logger.info(f"测试完成: 总时间={total_time:.2f}s, 吞吐量={throughput:.2f} msg/s")
# 可视化结果
self._visualize_benchmark(throughput, latencies)
return {
'total_time': total_time,
'throughput': throughput,
'avg_latency': np.mean(self.metrics['latency']) if self.metrics['latency'] else 0
}
def _visualize_benchmark(self, throughput: float, latencies: List[float]):
"""生成性能测试可视化报告"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle('Kafka Producer Optimization Benchmark', fontsize=16, fontweight='bold')
# 1. 配置参数展示
config_text = """
Optimization Configuration:
━━━━━━━━━━━━━━━━━━━━━━━━
Batch Size: 64KB (65536 bytes)
Linger Time: 100ms
Compression: LZ4
ACKs: all (ISR confirmed)
Retries: MAX_INT (infinite)
Max In Flight: 5
Idempotence: Enabled
Buffer Memory: 64MB
"""
axes[0, 0].text(0.05, 0.95, config_text, transform=axes[0, 0].transAxes,
fontsize=10, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.8))
axes[0, 0].set_xlim(0, 1)
axes[0, 0].set_ylim(0, 1)
axes[0, 0].axis('off')
axes[0, 0].set_title('Producer Configuration')
# 2. 吞吐量对比(理论vs实测)
scenarios = ['Unoptimized\n(batch=1)', 'Optimized\n(this config)', 'Max Throughput\n(acks=0)']
throughputs = [500, throughput, 50000] # 假设值
colors = ['#F18F01', '#C73E1D', '#2E86AB']
bars = axes[0, 1].bar(scenarios, throughputs, color=colors)
axes[0, 1].set_title('Throughput Comparison (msgs/sec)')
axes[0, 1].set_ylabel('Messages/Second')
for bar, val in zip(bars, throughputs):
axes[0, 1].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 100,
f'{val:.0f}', ha='center', fontweight='bold')
# 3. 延迟分布
if self.metrics['latency']:
axes[1, 0].hist(self.metrics['latency'], bins=50, color='#A23B72', alpha=0.7, edgecolor='black')
axes[1, 0].axvline(np.mean(self.metrics['latency']), color='red', linestyle='--', linewidth=2,
label=f'Mean: {np.mean(self.metrics["latency"]):.2f}ms')
axes[1, 0].set_title('Latency Distribution')
axes[1, 0].set_xlabel('Latency (ms)')
axes[1, 0].legend()
# 4. 成功率与失败率
success = self.metrics['success']
failed = self.metrics['failed']
if success + failed > 0:
sizes = [success, failed]
labels = [f'Success\n{success}', f'Failed\n{failed}']
colors = ['#4CAF50', '#F44336']
axes[1, 1].pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
axes[1, 1].set_title('Delivery Success Rate')
plt.tight_layout()
plt.savefig('kafka_producer_benchmark.png', dpi=150, bbox_inches='tight')
logger.info("基准测试可视化已保存: kafka_producer_benchmark.png")
plt.show()
def close(self):
"""优雅关闭"""
self.producer.flush()
self.producer.close()
logger.info("生产者已关闭")
def demonstrate_compression_effect():
"""
展示不同压缩算法的效果对比
"""
import lz4.frame, gzip, snappy, zstandard as zstd
import random
import string
# 生成模拟JSON数据(真实业务数据分布)
def generate_data(size_kb: int) -> bytes:
records = []
for _ in range(size_kb * 10): # 每KB约10条记录
record = {
'user_id': random.randint(10000, 99999),
'event': random.choice(['click', 'view', 'purchase', 'logout']),
'timestamp': time.time(),
'properties': {
'page': ''.join(random.choices(string.ascii_lowercase, k=20)),
'duration': random.randint(1, 300),
'referrer': ''.join(random.choices(string.ascii_letters, k=50))
}
}
records.append(record)
return json.dumps(records).encode()
data = generate_data(100) # 100KB原始数据
original_size = len(data)
results = {
'Original': original_size,
'LZ4': len(lz4.frame.compress(data)),
'Snappy': len(snappy.compress(data)),
'GZIP': len(gzip.compress(data)),
'ZSTD': len(zstd.ZstdCompressor().compress(data))
}
# 可视化
fig, ax = plt.subplots(figsize=(10, 6))
algorithms = list(results.keys())
sizes = list(results.values())
compression_ratios = [original_size/s for s in sizes]
bars = ax.bar(algorithms, sizes, color=['#2E86AB', '#A23B72', '#F18F01', '#C73E1D', '#6A994E'])
ax.set_ylabel('Compressed Size (bytes)')
ax.set_title('Kafka Compression Algorithms Comparison (100KB Original)')
# 添加压缩率标签
for bar, ratio in zip(bars, compression_ratios):
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height,
f'{ratio:.1f}x', ha='center', va='bottom', fontweight='bold')
plt.tight_layout()
plt.savefig('compression_comparison.png', dpi=150)
plt.show()
return results
if __name__ == "__main__":
# 1. 展示压缩效果
print("=" * 60)
print("3.1.2 Kafka压缩算法对比")
print("=" * 60)
compression_results = demonstrate_compression_effect()
for algo, size in compression_results.items():
print(f"{algo}: {size} bytes")
# 2. 运行生产者基准测试
print("\n" + "=" * 60)
print("3.1.2 生产者优化基准测试")
print("=" * 60)
producer = OptimizedKafkaProducer(enable_transaction=False)
try:
# 创建测试topic
results = producer.benchmark_throughput(
topic="test.throughput.optimized",
num_messages=5000,
message_size=500
)
print(f"\n测试结果: {results}")
finally:
producer.close()3.1.3 schema_validation.py
脚本功能 :Confluent Schema Registry集成与Pydantic双重验证,支持Avro/JSON Schema/Protobuf 使用方式 :python 3.1.3_schema_validation.py --register-schemas
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.1.3 Schema验证层实现
功能:Pydantic模型校验 + Confluent Schema Registry集成
支持Avro/JSON Schema/Protobuf,实现前后兼容检查
使用方式:python 3.1.3_schema_validation.py
"""
import json
import logging
from typing import Dict, Any, Optional, Union, List
from enum import Enum
from datetime import datetime
import requests
import fastavro
import io
from pydantic import BaseModel, Field, validator, root_validator, ValidationError
from kafka import KafkaProducer, KafkaConsumer
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.avro import AvroSerializer, AvroDeserializer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class EventType(str, Enum):
"""事件类型枚举"""
USER_LOGIN = "user_login"
USER_LOGOUT = "user_logout"
TRANSACTION = "transaction"
SYSTEM_ALERT = "system_alert"
class SensorReading(BaseModel):
"""
Pydantic模型定义(运行时验证)
3.1.3 Schema验证示例:传感器数据
"""
sensor_id: str = Field(..., min_length=5, max_length=50, description="传感器唯一ID")
timestamp: datetime = Field(default_factory=datetime.utcnow)
temperature: float = Field(..., ge=-50.0, le=150.0, description="摄氏温度")
humidity: Optional[float] = Field(None, ge=0.0, le=100.0)
pressure: Optional[float] = Field(None, ge=800.0, le=1200.0)
location: Dict[str, float] = Field(default_factory=dict)
metadata: Dict[str, Any] = Field(default_factory=dict)
@validator('location')
def validate_location(cls, v):
"""自定义验证:确保包含lat和lon"""
if v and ('lat' not in v or 'lon' not in v):
raise ValueError("Location must contain 'lat' and 'lon'")
return v
@validator('temperature')
def validate_temp_range(cls, v, values):
"""业务逻辑验证:根据传感器类型验证温度范围"""
sensor_id = values.get('sensor_id', '')
if 'indoor' in sensor_id and v > 60:
raise ValueError("Indoor sensor temperature cannot exceed 60°C")
return v
@root_validator
def check_at_least_one_metric(cls, values):
"""确保至少有一个有效指标"""
has_temp = values.get('temperature') is not None
has_humidity = values.get('humidity') is not None
has_pressure = values.get('pressure') is not None
if not any([has_temp, has_humidity, has_pressure]):
raise ValueError("At least one metric (temperature, humidity, or pressure) must be provided")
return values
class Config:
schema_extra = {
"example": {
"sensor_id": "indoor_sensor_001",
"temperature": 23.5,
"humidity": 45.0,
"location": {"lat": 39.9, "lon": 116.4}
}
}
class TransactionEvent(BaseModel):
"""
金融交易事件模型
展示复杂验证逻辑
"""
transaction_id: str = Field(..., regex=r'^TXN[0-9]{12}$')
user_id: int = Field(..., gt=0)
amount: float = Field(..., gt=0.0)
currency: str = Field(..., regex='^(USD|EUR|CNY|JPY)$')
timestamp: datetime
merchant_id: Optional[str] = None
risk_score: Optional[float] = Field(None, ge=0.0, le=1.0)
@validator('amount')
def validate_precision(cls, v):
"""验证金额精度(最多2位小数)"""
if round(v, 2) != v:
raise ValueError("Amount cannot have more than 2 decimal places")
return v
@root_validator
def validate_risk_for_large_amount(cls, values):
"""大额交易必须包含风险评分"""
amount = values.get('amount', 0)
risk = values.get('risk_score')
if amount > 10000 and risk is None:
raise ValueError("Transactions over 10000 require risk_score")
return values
class SchemaRegistryManager:
"""
Confluent Schema Registry管理器
功能:
- 注册/获取Schema
- 兼容性检查
- 版本演进管理
"""
def __init__(self, url: str = "http://localhost:8081"):
self.client = SchemaRegistryClient({'url': url})
self._schema_cache = {}
def register_avro_schema(self, subject: str, avro_schema: Union[str, Dict]) -> int:
"""
注册Avro Schema到Registry
"""
from confluent_kafka.schema_registry import Schema
if isinstance(avro_schema, dict):
avro_schema = json.dumps(avro_schema)
schema = Schema(avro_schema, "AVRO")
schema_id = self.client.register_schema(subject, schema)
logger.info(f"Schema注册成功: {subject} -> ID {schema_id}")
return schema_id
def get_serializer(self, subject: str) -> AvroSerializer:
"""
获取Avro序列化器(用于Producer)
"""
from confluent_kafka.schema_registry import Schema
# 获取最新Schema
latest = self.client.get_latest_version(subject)
return AvroSerializer(
schema_registry_client=self.client,
schema_str=latest.schema.schema_str,
to_dict=lambda obj, ctx: obj.dict() if hasattr(obj, 'dict') else obj
)
def get_deserializer(self, subject: str) -> AvroDeserializer:
"""
获取Avro反序列化器(用于Consumer)
"""
from confluent_kafka.schema_registry import Schema
latest = self.client.get_latest_version(subject)
return AvroDeserializer(
schema_registry_client=self.client,
schema_str=latest.schema.schema_str,
from_dict=lambda obj, ctx: obj
)
def check_compatibility(self, subject: str, new_schema: Union[str, Dict]) -> bool:
"""
检查Schema兼容性(前后兼容)
"""
try:
if isinstance(new_schema, dict):
new_schema = json.dumps(new_schema)
compatible = self.client.test_compatibility(subject, new_schema)
if compatible:
logger.info(f"Schema {subject} 兼容性检查通过")
else:
logger.warning(f"Schema {subject} 兼容性检查失败")
return compatible
except Exception as e:
logger.error(f"兼容性检查错误: {e}")
return False
class ValidatingKafkaProducer:
"""
带Schema验证的Kafka生产者
双层验证:
1. Pydantic运行时类型检查
2. Schema Registry格式验证
"""
def __init__(self,
bootstrap_servers: str = "localhost:9092",
schema_registry_url: str = "http://localhost:8081"):
self.bootstrap_servers = bootstrap_servers
self.registry = SchemaRegistryManager(schema_registry_url)
self.producer = None
self.serializers = {} # topic -> serializer缓存
self._init_producer()
def _init_producer(self):
self.producer = KafkaProducer(
bootstrap_servers=self.bootstrap_servers,
key_serializer=StringSerializer('utf_8'),
value_serializer=lambda v: v, # 自定义序列化
acks='all',
retries=5
)
def _get_or_create_serializer(self, topic: str):
"""获取或创建序列化器"""
if topic not in self.serializers:
subject = f"{topic}-value"
self.serializers[topic] = self.registry.get_serializer(subject)
return self.serializers[topic]
def send_validated(self, topic: str, key: str, value: BaseModel,
pydantic_model: type = None) -> Any:
"""
发送带验证的消息
流程:
1. Pydantic验证(类型、约束、业务逻辑)
2. Schema Registry序列化(Avro编码)
3. Kafka生产
"""
# 步骤1: Pydantic验证
if pydantic_model and not isinstance(value, pydantic_model):
try:
if isinstance(value, dict):
value = pydantic_model(**value)
else:
raise ValueError(f"Value must be instance of {pydantic_model}")
except ValidationError as e:
logger.error(f"Pydantic验证失败: {e}")
raise
# 转换为dict
data = value.dict() if hasattr(value, 'dict') else value
# 步骤2: Schema Registry序列化
try:
serializer = self._get_or_create_serializer(topic)
serialized = serializer(data, SerializationContext(topic, MessageField.VALUE))
except Exception as e:
logger.error(f"Avro序列化失败: {e}")
raise
# 步骤3: 发送
future = self.producer.send(
topic=topic,
key=key,
value=serialized,
headers={
'schema_version': b'latest',
'validation': b'pydantic+avro',
'source': b'schema_validation.py'
}
)
return future
def close(self):
self.producer.flush()
self.producer.close()
class ValidatingKafkaConsumer:
"""
带Schema验证的消费者
自动处理Schema演进和向后兼容
"""
def __init__(self,
topic: str,
group_id: str,
bootstrap_servers: str = "localhost:9092",
schema_registry_url: str = "http://localhost:8081"):
self.topic = topic
self.registry = SchemaRegistryManager(schema_registry_url)
self.deserializer = self.registry.get_deserializer(f"{topic}-value")
self.consumer = KafkaConsumer(
topic,
group_id=group_id,
bootstrap_servers=bootstrap_servers,
auto_offset_reset='earliest',
key_deserializer=lambda k: k.decode('utf-8') if k else None,
value_deserializer=lambda v: self._deserialize(v)
)
def _deserialize(self, data: bytes) -> Any:
"""反序列化并验证"""
if data is None:
return None
try:
return self.deserializer(data, SerializationContext(self.topic, MessageField.VALUE))
except Exception as e:
logger.error(f"反序列化失败: {e}")
# 返回原始数据以便错误处理
return {'_error': str(e), '_raw': data.hex()}
def consume_validated(self, timeout_ms: int = 1000):
"""消费验证后的消息"""
messages = self.consumer.poll(timeout_ms=timeout_ms)
validated_records = []
for tp, records in messages.items():
for record in records:
if '_error' not in record.value:
validated_records.append({
'key': record.key,
'value': record.value,
'partition': record.partition,
'offset': record.offset,
'timestamp': record.timestamp
})
else:
logger.warning(f"跳过无效消息: offset={record.offset}")
return validated_records
def close(self):
self.consumer.close()
def create_sample_schemas():
"""
创建示例Avro Schema
"""
sensor_schema = {
"type": "record",
"name": "SensorReading",
"namespace": "com.datapipeline.sensor",
"fields": [
{"name": "sensor_id", "type": "string"},
{"name": "timestamp", "type": "string"},
{"name": "temperature", "type": "double"},
{"name": "humidity", "type": ["null", "double"], "default": None},
{"name": "pressure", "type": ["null", "double"], "default": None},
{"name": "location", "type": ["null", {
"type": "map",
"values": "double"
}], "default": None},
{"name": "metadata", "type": ["null", {
"type": "map",
"values": "string"
}], "default": None}
]
}
transaction_schema = {
"type": "record",
"name": "Transaction",
"namespace": "com.datapipeline.payment",
"fields": [
{"name": "transaction_id", "type": "string"},
{"name": "user_id", "type": "long"},
{"name": "amount", "type": "double"},
{"name": "currency", "type": "string"},
{"name": "timestamp", "type": "string"},
{"name": "merchant_id", "type": ["null", "string"], "default": None},
{"name": "risk_score", "type": ["null", "double"], "default": None}
]
}
return {
'sensor-value': sensor_schema,
'transaction-value': transaction_schema
}
def run_schema_workflow():
"""
完整的Schema验证工作流演示
"""
import matplotlib.pyplot as plt
import time
# 1. 初始化Schema Registry
registry = SchemaRegistryManager()
schemas = create_sample_schemas()
# 注册Schema
print("=" * 60)
print("3.1.3 Schema Registry注册")
print("=" * 60)
for subject, schema in schemas.items():
try:
schema_id = registry.register_avro_schema(subject, schema)
print(f"✓ {subject}: ID={schema_id}")
except Exception as e:
print(f"✗ {subject}: {e}")
# 2. 创建验证生产者
print("\n" + "=" * 60)
print("3.1.3 双层验证消息生产")
print("=" * 60)
producer = ValidatingKafkaProducer()
# 生成有效和无效数据
test_cases = [
# 有效数据
{
'sensor_id': 'indoor_sensor_001',
'temperature': 23.5,
'humidity': 45.0,
'location': {'lat': 39.9, 'lon': 116.4}
},
# 无效:温度过高
{
'sensor_id': 'indoor_sensor_002',
'temperature': 85.0, # 超过室内传感器限制
'humidity': 30.0
},
# 无效:缺少指标
{
'sensor_id': 'outdoor_sensor_003',
'location': {'lat': 40.0, 'lon': 117.0}
}
]
results = {'success': 0, 'failed': 0, 'errors': []}
for i, data in enumerate(test_cases):
try:
# Pydantic验证
validated = SensorReading(**data)
# 发送到Kafka
future = producer.send_validated(
topic='sensor',
key=f'sensor-{i}',
value=validated,
pydantic_model=SensorReading
)
record_metadata = future.get(timeout=10)
print(f"✓ 消息 {i}: partition={record_metadata.partition}, offset={record_metadata.offset}")
results['success'] += 1
except ValidationError as e:
print(f"✗ 消息 {i} Pydantic验证失败: {e.errors()}")
results['failed'] += 1
results['errors'].append(('pydantic', str(e)))
except Exception as e:
print(f"✗ 消息 {i} 发送失败: {e}")
results['failed'] += 1
results['errors'].append(('kafka', str(e)))
producer.close()
# 3. 可视化验证结果
print("\n" + "=" * 60)
print("3.1.3 验证结果可视化")
print("=" * 60)
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 成功率饼图
sizes = [results['success'], results['failed']]
colors = ['#4CAF50', '#F44336']
axes[0].pie(sizes, labels=['Success', 'Failed'], colors=colors, autopct='%1.1f%%',
startangle=90, explode=(0.05, 0))
axes[0].set_title('Schema Validation Results')
# 错误类型分布
if results['errors']:
error_types = [e[0] for e in results['errors']]
types = list(set(error_types))
counts = [error_types.count(t) for t in types]
axes[1].bar(types, counts, color=['#FF9800', '#2196F3'][:len(types)])
axes[1].set_title('Error Types Distribution')
axes[1].set_ylabel('Count')
plt.tight_layout()
plt.savefig('schema_validation_results.png', dpi=150, bbox_inches='tight')
plt.show()
print(f"\n结果统计: 成功={results['success']}, 失败={results['failed']}")
print("可视化已保存: schema_validation_results.png")
if __name__ == "__main__":
run_schema_workflow()3.1.4 lineage_tracking.py
脚本功能 :数据血缘追踪系统,注入Header元数据,支持端到端链路追踪 使用方式 :python 3.1.4_lineage_tracking.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.1.4 数据血缘追踪实现
功能:端到端数据血缘追踪,注入来源系统、处理时间戳、链路ID
支持OpenLineage标准格式输出
使用方式:python 3.1.4_lineage_tracking.py
"""
import json
import uuid
import hashlib
import time
import logging
from datetime import datetime
from typing import Dict, List, Optional, Any
from dataclasses import dataclass, asdict
from enum import Enum
import threading
from kafka import KafkaProducer, KafkaConsumer, TopicPartition
import matplotlib.pyplot as plt
import networkx as nx
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ProcessingStage(str, Enum):
"""数据处理阶段枚举"""
INGESTION = "ingestion"
VALIDATION = "validation"
TRANSFORMATION = "transformation"
ENRICHMENT = "enrichment"
AGGREGATION = "aggregation"
STORAGE = "storage"
EXPORT = "export"
@dataclass
class LineageEvent:
"""
血缘事件模型(OpenLineage兼容)
"""
event_id: str
run_id: str
timestamp: str
event_type: str # START, COMPLETE, FAIL
job_name: str
job_namespace: str = "realtime_pipeline"
inputs: List[Dict] = None
outputs: List[Dict] = None
producer: str = "lineage_tracker"
schema_version: str = "1.0.0"
def to_openlineage(self) -> Dict:
"""转换为OpenLineage标准格式"""
return {
"eventTime": self.timestamp,
"eventType": self.event_type,
"run": {
"runId": self.run_id
},
"job": {
"namespace": self.job_namespace,
"name": self.job_name
},
"inputs": self.inputs or [],
"outputs": self.outputs or [],
"producer": self.producer
}
class LineageTracker:
"""
数据血缘追踪器
功能:
- 生成追踪ID
- 记录处理链路
- 注入Kafka Headers
- 血缘图谱构建
"""
def __init__(self,
kafka_bootstrap: str = "localhost:9092",
lineage_topic: str = "lineage.events"):
self.kafka_bootstrap = kafka_bootstrap
self.lineage_topic = lineage_topic
self.producer = None
self.local_graph = nx.DiGraph() # 本地血缘图
self.run_counter = 0
self._lock = threading.Lock()
self._init_kafka()
def _init_kafka(self):
"""初始化血缘事件生产者"""
self.producer = KafkaProducer(
bootstrap_servers=self.kafka_bootstrap,
value_serializer=lambda v: json.dumps(v, default=str).encode('utf-8'),
acks=1,
retries=3
)
def generate_run_id(self) -> str:
"""生成唯一运行ID"""
return str(uuid.uuid4())
def create_lineage_headers(self,
source_system: str,
run_id: Optional[str] = None,
stage: ProcessingStage = ProcessingStage.INGESTION,
parent_run_id: Optional[str] = None) -> Dict[str, bytes]:
"""
创建标准血缘Headers
Returns:
Dict[str, bytes]: Kafka消息Headers
"""
if not run_id:
run_id = self.generate_run_id()
timestamp = int(time.time() * 1000)
headers = {
# 核心追踪字段
'x-lineage-run-id': run_id.encode(),
'x-lineage-stage': stage.value.encode(),
'x-lineage-source-system': source_system.encode(),
'x-lineage-timestamp-ms': str(timestamp).encode(),
'x-lineage-producer': b'lineage_tracker_v3.1.4',
# 数据指纹(用于去重和一致性检查)
'x-content-hash': b'', # 稍后填充
# 可选的父追踪ID(支持子任务)
'x-parent-run-id': (parent_run_id or '').encode(),
# 技术元数据
'x-thread-id': str(threading.get_ident()).encode(),
'x-hostname': b'localhost', # 实际应从环境获取
}
return headers
def record_event(self,
event_type: str,
job_name: str,
inputs: List[Dict],
outputs: List[Dict],
run_id: Optional[str] = None):
"""
记录血缘事件到OpenLineage后端
"""
if not run_id:
run_id = self.generate_run_id()
event = LineageEvent(
event_id=str(uuid.uuid4()),
run_id=run_id,
timestamp=datetime.utcnow().isoformat(),
event_type=event_type,
job_name=job_name,
inputs=inputs,
outputs=outputs
)
lineage_data = event.to_openlineage()
try:
self.producer.send(
topic=self.lineage_topic,
key=run_id,
value=lineage_data
)
logger.debug(f"血缘事件已记录: {job_name} [{event_type}]")
# 更新本地图
with self._lock:
for inp in inputs:
for out in outputs:
self.local_graph.add_edge(
inp.get('name', 'unknown'),
out.get('name', 'unknown'),
job=job_name,
timestamp=event.timestamp
)
except Exception as e:
logger.error(f"血缘事件记录失败: {e}")
def compute_content_hash(self, data: Dict) -> str:
"""
计算数据内容哈希(用于追踪数据变更)
"""
# 排序并序列化,确保一致性
canonical = json.dumps(data, sort_keys=True, separators=(',', ':'), default=str)
return hashlib.sha256(canonical.encode()).hexdigest()[:16] # 取前16位节省空间
def trace_message_lineage(self,
topic: str,
partition: int,
offset: int,
timeout_ms: int = 5000) -> Optional[Dict]:
"""
追踪单条消息的完整血缘链路
"""
consumer = KafkaConsumer(
bootstrap_servers=self.kafka_bootstrap,
auto_offset_reset='earliest',
consumer_timeout_ms=timeout_ms
)
tp = TopicPartition(topic, partition)
consumer.assign([tp])
consumer.seek(tp, offset)
try:
msg = next(consumer)
headers = {k: v.decode() if v else None for k, v in msg.headers or []}
lineage_info = {
'run_id': headers.get('x-lineage-run-id'),
'stage': headers.get('x-lineage-stage'),
'source_system': headers.get('x-lineage-source-system'),
'timestamp': headers.get('x-lineage-timestamp-ms'),
'content_hash': headers.get('x-content-hash'),
'producer': headers.get('x-lineage-producer'),
'kafka_metadata': {
'topic': topic,
'partition': partition,
'offset': offset,
'timestamp': msg.timestamp
}
}
return lineage_info
except StopIteration:
logger.warning(f"未找到消息: {topic}-{partition}:{offset}")
return None
finally:
consumer.close()
def visualize_lineage_graph(self, output_file: str = "data_lineage_graph.png"):
"""
可视化数据血缘图谱
"""
if not self.local_graph.nodes():
logger.warning("血缘图为空,无法可视化")
return
plt.figure(figsize=(14, 10))
pos = nx.spring_layout(self.local_graph, k=2, iterations=50)
# 绘制节点
node_colors = []
for node in self.local_graph.nodes():
# 根据出度/入度着色
in_degree = self.local_graph.in_degree(node)
out_degree = self.local_graph.out_degree(node)
if in_degree == 0:
node_colors.append('#4CAF50') # 源系统 - 绿色
elif out_degree == 0:
node_colors.append('#F44336') # 终端 - 红色
else:
node_colors.append('#2196F3') # 中间处理 - 蓝色
nx.draw_networkx_nodes(self.local_graph, pos,
node_color=node_colors,
node_size=2000,
alpha=0.9)
# 绘制边
nx.draw_networkx_edges(self.local_graph, pos,
edge_color='#666666',
width=2,
arrowsize=20,
arrowstyle='->',
connectionstyle='arc3,rad=0.1')
# 绘制标签
nx.draw_networkx_labels(self.local_graph, pos,
font_size=10,
font_weight='bold',
font_family='sans-serif')
# 添加图例
from matplotlib.patches import Patch
legend_elements = [
Patch(facecolor='#4CAF50', label='Source Systems'),
Patch(facecolor='#2196F3', label='Processing Stages'),
Patch(facecolor='#F44336', label='Storage/Export')
]
plt.legend(handles=legend_elements, loc='upper right')
plt.title("Real-time Data Pipeline Lineage Graph", fontsize=16, fontweight='bold')
plt.axis('off')
plt.tight_layout()
plt.savefig(output_file, dpi=150, bbox_inches='tight')
logger.info(f"血缘图谱已保存: {output_file}")
plt.show()
class LineageEnrichedProducer:
"""
自动注入血缘Headers的Kafka生产者包装器
"""
def __init__(self,
tracker: LineageTracker,
bootstrap_servers: str = "localhost:9092"):
self.tracker = tracker
self.producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
acks='all'
)
def send_with_lineage(self,
topic: str,
value: Dict,
source_system: str,
key: Optional[str] = None,
stage: ProcessingStage = ProcessingStage.TRANSFORMATION,
parent_run_id: Optional[str] = None):
"""
发送带完整血缘追踪的消息
"""
# 生成追踪ID
run_id = self.tracker.generate_run_id()
# 计算内容哈希
content_hash = self.tracker.compute_content_hash(value)
# 创建Headers
headers = self.tracker.create_lineage_headers(
source_system=source_system,
run_id=run_id,
stage=stage,
parent_run_id=parent_run_id
)
headers['x-content-hash'] = content_hash.encode()
# 发送消息
future = self.producer.send(
topic=topic,
key=key.encode() if key else None,
value=value,
headers=list(headers.items())
)
# 记录输出血缘
self.tracker.record_event(
event_type="COMPLETE",
job_name=f"produce-to-{topic}",
inputs=[{'name': source_system, 'namespace': 'source'}],
outputs=[{'name': topic, 'namespace': 'kafka'}],
run_id=run_id
)
return future, run_id
def close(self):
self.producer.flush()
self.producer.close()
def demonstrate_lineage_workflow():
"""
完整血缘追踪演示
"""
print("=" * 60)
print("3.1.4 数据血缘追踪演示")
print("=" * 60)
# 1. 初始化追踪器
tracker = LineageTracker()
# 2. 模拟数据管道流程
enriched_producer = LineageEnrichedProducer(tracker)
sources = [
('REST API', 'raw.api.data'),
('Webhook', 'raw.webhook.events'),
('Database CDC', 'raw.db.changes')
]
print("\n模拟多源数据采集...")
for source, topic in sources:
for i in range(3): # 每个源3条消息
data = {
'event_id': f"{source.lower().replace(' ', '_')}_{i}",
'value': i * 100,
'timestamp': datetime.utcnow().isoformat()
}
future, run_id = enriched_producer.send_with_lineage(
topic=topic,
value=data,
source_system=source,
key=f"key-{i}",
stage=ProcessingStage.INGESTION
)
record_metadata = future.get(timeout=10)
print(f" [{source}] -> {topic}: run_id={run_id[:8]}..., "
f"partition={record_metadata.partition}, offset={record_metadata.offset}")
# 3. 模拟处理阶段
print("\n模拟流处理阶段...")
processing_stages = [
('raw.api.data', 'validated.cleaned', ProcessingStage.VALIDATION),
('validated.cleaned', 'transformed.enriched', ProcessingStage.ENRICHMENT),
('transformed.enriched', 'aggregated.metrics', ProcessingStage.AGGREGATION)
]
for input_topic, output_topic, stage in processing_stages:
for i in range(2):
data = {
'processed_at': datetime.utcnow().isoformat(),
'input_topic': input_topic,
'batch_id': i
}
future, run_id = enriched_producer.send_with_lineage(
topic=output_topic,
value=data,
source_system=input_topic,
stage=stage
)
print(f" [{stage.value}] {input_topic} -> {output_topic}: run_id={run_id[:8]}...")
enriched_producer.close()
# 4. 追踪特定消息
print("\n追踪特定消息血缘...")
lineage_info = tracker.trace_message_lineage('raw.api.data', 0, 0)
if lineage_info:
print(f" Run ID: {lineage_info['run_id']}")
print(f" Source: {lineage_info['source_system']}")
print(f" Stage: {lineage_info['stage']}")
print(f" Content Hash: {lineage_info['content_hash']}")
# 5. 可视化
print("\n生成血缘图谱...")
tracker.visualize_lineage_graph()
# 6. 显示统计
print(f"\n血缘统计:")
print(f" 记录节点数: {tracker.local_graph.number_of_nodes()}")
print(f" 记录边数: {tracker.local_graph.number_of_edges()}")
print(f" 源系统数: {sum(1 for n in tracker.local_graph.nodes() if tracker.local_graph.in_degree(n) == 0)}")
tracker.producer.flush()
tracker.producer.close()
if __name__ == "__main__":
demonstrate_lineage_workflow()3.2 流处理引擎实现
3.2.1 polars_streaming.py
脚本功能 :Polars流处理引擎,展示Lazy API、内存高效转换、流式聚合 使用方式 :python 3.2.1_polars_streaming.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.2.1 Polars流处理引擎
功能:惰性求值(Lazy API)、内存高效转换、流式DataFrame处理
对比:Pandas vs Polars内存占用与性能
使用方式:python 3.2.1_polars_streaming.py
"""
import time
import json
import logging
from datetime import datetime, timedelta
from typing import Iterator, Dict, List, Callable, Optional
import threading
import queue
import polars as pl
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from kafka import KafkaConsumer, KafkaProducer
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class PolarsStreamProcessor:
"""
基于Polars的流处理引擎
核心特性:
- 零拷贝数据转换
- 真正的流式处理(不累积全量数据)
- SIMD优化
- 惰性执行计划优化
"""
def __init__(self,
kafka_bootstrap: str = "localhost:9092",
chunk_size: int = 10000):
self.kafka_bootstrap = kafka_bootstrap
self.chunk_size = chunk_size
self.metrics = {
'records_processed': 0,
'batches_processed': 0,
'memory_peak_mb': 0,
'processing_time_ms': []
}
def create_lazy_pipeline(self, source_df: pl.LazyFrame) -> pl.LazyFrame:
"""
3.2.1 惰性求值(Lazy API):构建优化执行计划
不立即执行,直到调用collect()或sink_parquet()
"""
pipeline = (
source_df
# 类型转换与验证
.with_columns([
pl.col('timestamp').str.strptime(pl.Datetime, "%Y-%m-%dT%H:%M:%S%.fZ", strict=False),
pl.col('value').cast(pl.Float64),
pl.col('sensor_id').cast(pl.Categorical) # 字典编码节省内存
])
# 数据清洗
.filter(pl.col('value').is_not_null())
.filter(pl.col('value') > 0)
# 特征工程
.with_columns([
pl.col('value').log().alias('log_value'),
pl.col('timestamp').dt.hour().alias('hour'),
pl.col('timestamp').dt.day().alias('day')
])
# 简单聚合(窗口计算在3.2.2中详细展开)
.with_columns([
pl.col('value').mean().over('sensor_id').alias('sensor_avg'),
pl.col('value').std().over('sensor_id').alias('sensor_std')
])
)
return pipeline
def process_kafka_stream(self,
input_topic: str,
output_topic: str,
processing_func: Callable[[pl.DataFrame], pl.DataFrame],
duration_seconds: int = 60):
"""
流式处理Kafka数据
使用微批处理(micro-batching)平衡延迟与吞吐
"""
consumer = KafkaConsumer(
input_topic,
bootstrap_servers=self.kafka_bootstrap,
group_id=f"polars-stream-{int(time.time())}",
auto_offset_reset='latest',
enable_auto_commit=False,
max_poll_records=self.chunk_size
)
producer = KafkaProducer(
bootstrap_servers=self.kafka_bootstrap,
value_serializer=lambda v: json.dumps(v, default=str).encode('utf-8')
)
logger.info(f"开始Polars流处理: {input_topic} -> {output_topic}")
start_time = time.time()
batch_buffer = []
try:
while time.time() - start_time < duration_seconds:
# 拉取消息
messages = consumer.poll(timeout_ms=1000)
for tp, records in messages.items():
for record in records:
try:
data = json.loads(record.value.decode('utf-8'))
batch_buffer.append(data)
except Exception as e:
logger.error(f"解析失败: {e}")
# 达到批量大小则处理
if len(batch_buffer) >= self.chunk_size:
self._process_batch(batch_buffer, processing_func, producer, output_topic)
batch_buffer = []
consumer.commit()
except KeyboardInterrupt:
logger.info("收到停止信号")
finally:
# 处理剩余数据
if batch_buffer:
self._process_batch(batch_buffer, processing_func, producer, output_topic)
consumer.close()
producer.close()
self._visualize_performance()
def _process_batch(self,
batch: List[Dict],
processing_func: Callable,
producer: KafkaProducer,
output_topic: str):
"""
处理单个微批次
"""
batch_start = time.time()
# 1. 转换为Polars DataFrame(零拷贝解析)
df = pl.from_dicts(batch)
# 2. 转换为LazyFrame进行优化执行
lazy_df = df.lazy()
# 3. 应用处理逻辑
processed_lazy = processing_func(lazy_df)
# 4. 执行(触发计算)
result_df = processed_lazy.collect(streaming=True) # streaming=True启用真正的流式执行
# 5. 输出到Kafka
records = result_df.to_dicts()
for record in records:
producer.send(output_topic, value=record)
# 记录指标
elapsed_ms = (time.time() - batch_start) * 1000
self.metrics['records_processed'] += len(batch)
self.metrics['batches_processed'] += 1
self.metrics['processing_time_ms'].append(elapsed_ms)
# 估计内存使用(Polars内存布局更紧凑)
mem_usage = result_df.estimated_size() / (1024 * 1024)
self.metrics['memory_peak_mb'] = max(self.metrics['memory_peak_mb'], mem_usage)
logger.info(f"批次处理完成: {len(batch)}条, 耗时{elapsed_ms:.2f}ms, 内存{mem_usage:.2f}MB")
def streaming_aggregate(self,
input_topic: str,
window_seconds: int = 60) -> Iterator[pl.DataFrame]:
"""
流式聚合:维护增量状态,输出滚动统计
"""
consumer = KafkaConsumer(
input_topic,
bootstrap_servers=self.kafka_bootstrap,
group_id="polars-aggregator",
auto_offset_reset='latest'
)
# 增量状态存储(使用Polars维护状态更高效)
state_df = pl.DataFrame({
'sensor_id': pl.Series([], dtype=pl.Utf8),
'count': pl.Series([], dtype=pl.Int64),
'sum': pl.Series([], dtype=pl.Float64),
'sum_sq': pl.Series([], dtype=pl.Float64),
'last_timestamp': pl.Series([], dtype=pl.Datetime)
})
buffer = []
last_emit = time.time()
for message in consumer:
data = json.loads(message.value.decode('utf-8'))
buffer.append(data)
# 时间窗口触发
if time.time() - last_emit >= window_seconds:
if buffer:
# 增量更新状态
new_df = pl.from_dicts(buffer)
new_agg = new_df.groupby('sensor_id').agg([
pl.count().alias('new_count'),
pl.col('value').sum().alias('new_sum'),
(pl.col('value') ** 2).sum().alias('new_sum_sq'),
pl.col('timestamp').max().alias('new_last_ts')
])
# 状态合并(Polars join优化)
state_df = state_df.join(
new_agg,
on='sensor_id',
how='outer'
).with_columns([
(pl.col('count').fill_null(0) + pl.col('new_count').fill_null(0)).alias('count'),
(pl.col('sum').fill_null(0) + pl.col('new_sum').fill_null(0)).alias('sum'),
(pl.col('sum_sq').fill_null(0) + pl.col('new_sum_sq').fill_null(0)).alias('sum_sq')
]).select(['sensor_id', 'count', 'sum', 'sum_sq', 'last_timestamp'])
# 输出当前窗口统计
yield state_df.with_columns([
(pl.col('sum') / pl.col('count')).alias('mean'),
((pl.col('sum_sq') / pl.col('count')) - (pl.col('sum') / pl.col('count')) ** 2).sqrt().alias('std')
])
buffer = []
last_emit = time.time()
def _visualize_performance(self):
"""性能对比可视化:Polars vs Pandas"""
if not self.metrics['processing_time_ms']:
return
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle('Polars Stream Processing Performance', fontsize=16, fontweight='bold')
# 1. 延迟分布
times = self.metrics['processing_time_ms']
axes[0, 0].hist(times, bins=30, color='#2E86AB', alpha=0.7, edgecolor='black')
axes[0, 0].axvline(np.mean(times), color='red', linestyle='--',
label=f'Mean: {np.mean(times):.1f}ms')
axes[0, 0].set_title('Processing Latency Distribution')
axes[0, 0].set_xlabel('Milliseconds')
axes[0, 0].legend()
# 2. 内存占用对比(理论值 vs Pandas)
scenarios = ['Pandas\n(eager)', 'Polars\n(lazy)', 'Polars\n(streaming)']
memory_mb = [150, 45, 20] # 示例数据
colors = ['#F18F01', '#A23B72', '#4CAF50']
bars = axes[0, 1].bar(scenarios, memory_mb, color=colors)
axes[0, 1].set_title('Memory Usage Comparison (100K rows)')
axes[0, 1].set_ylabel('MB')
for bar, val in zip(bars, memory_mb):
axes[0, 1].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 2,
f'{val}MB', ha='center', fontweight='bold')
# 3. 吞吐量时间序列
batch_numbers = range(1, len(times) + 1)
throughput = [self.chunk_size / (t / 1000) for t in times] # 条/秒
axes[1, 0].plot(batch_numbers, throughput, marker='o', color='#C73E1D', linewidth=2)
axes[1, 0].set_title('Throughput Over Time')
axes[1, 0].set_xlabel('Batch Number')
axes[1, 0].set_ylabel('Records/Second')
axes[1, 0].grid(True, alpha=0.3)
# 4. 架构优势说明
advantages = """
Polars Stream Processing Advantages:
1. Lazy Evaluation
• Query plan optimization
• Predicate pushdown
• Projection pushdown
2. Memory Efficiency
• Arrow memory layout
• Zero-copy operations
• Dictionary encoding
3. SIMD Optimization
• AVX2 instructions
• Parallel scan
• Vectorized execution
4. True Streaming
• sink_parquet() for
out-of-core processing
• Streaming groupby
"""
axes[1, 1].text(0.05, 0.95, advantages, transform=axes[1, 1].transAxes,
fontsize=10, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
axes[1, 1].set_xlim(0, 1)
axes[1, 1].set_ylim(0, 1)
axes[1, 1].axis('off')
plt.tight_layout()
plt.savefig('polars_performance.png', dpi=150, bbox_inches='tight')
logger.info("性能可视化已保存: polars_performance.png")
plt.show()
def generate_test_data(n: int = 100000) -> List[Dict]:
"""生成测试数据"""
import random
base_time = datetime(2024, 1, 1)
data = []
for i in range(n):
data.append({
'sensor_id': f"sensor_{i % 100}",
'timestamp': (base_time + timedelta(seconds=i)).isoformat() + 'Z',
'value': random.gauss(50, 10),
'status': random.choice(['ok', 'warning', 'error'])
})
return data
def demonstrate_polars_vs_pandas():
"""
Polars vs Pandas性能对比演示
"""
print("=" * 60)
print("3.2.1 Polars vs Pandas 性能对比")
print("=" * 60)
# 生成数据
print("生成10万条测试数据...")
data = generate_test_data(100000)
# Pandas处理
print("\n--- Pandas Eager Processing ---")
start = time.time()
pdf = pd.DataFrame(data)
pdf['timestamp'] = pd.to_datetime(pdf['timestamp'])
pdf['value'] = pd.to_numeric(pdf['value'])
pdf = pdf[pdf['value'] > 0]
pdf['log_value'] = np.log(pdf['value'])
pdf['hour'] = pdf['timestamp'].dt.hour
result_pd = pdf.groupby('sensor_id')['value'].agg(['mean', 'std']).reset_index()
pandas_time = time.time() - start
pandas_memory = result_pd.memory_usage(deep=True).sum() / (1024 * 1024)
print(f"Pandas耗时: {pandas_time:.3f}s, 内存: {pandas_memory:.2f}MB")
# Polars处理
print("\n--- Polars Lazy Processing ---")
start = time.time()
ldf = pl.from_dicts(data).lazy()
ldf = ldf.with_columns([
pl.col('timestamp').str.strptime(pl.Datetime, "%Y-%m-%dT%H:%M:%S%.fZ"),
pl.col('value').cast(pl.Float64)
]).filter(pl.col('value') > 0).with_columns([
pl.col('value').log().alias('log_value'),
pl.col('timestamp').dt.hour().alias('hour')
])
result_pl = ldf.groupby('sensor_id').agg([
pl.col('value').mean().alias('mean'),
pl.col('value').std().alias('std')
]).collect(streaming=True) # 流式执行
polars_time = time.time() - start
polars_memory = result_pl.estimated_size() / (1024 * 1024)
print(f"Polars耗时: {polars_time:.3f}s, 内存: {polars_memory:.2f}MB")
# 加速比
speedup = pandas_time / polars_time
mem_save = (1 - polars_memory / pandas_memory) * 100
print(f"\n性能提升: {speedup:.2f}x")
print(f"内存节省: {mem_save:.1f}%")
# 可视化对比
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 执行时间对比
categories = ['Pandas\n(Eager)', 'Polars\n(Lazy+Streaming)']
times = [pandas_time, polars_time]
colors = ['#F44336', '#4CAF50']
bars = axes[0].bar(categories, times, color=colors)
axes[0].set_title('Execution Time Comparison (100K rows)')
axes[0].set_ylabel('Seconds')
for bar, val in zip(bars, times):
axes[0].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{val:.3f}s', ha='center', fontweight='bold')
# 内存使用对比
memories = [pandas_memory, polars_memory]
bars = axes[1].bar(categories, memories, color=colors)
axes[1].set_title('Memory Usage Comparison')
axes[1].set_ylabel('MB')
for bar, val in zip(bars, memories):
axes[1].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.1,
f'{val:.2f}MB', ha='center', fontweight='bold')
plt.suptitle(f'Polars Speedup: {speedup:.2f}x | Memory Save: {mem_save:.1f}%',
fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('polars_vs_pandas.png', dpi=150)
plt.show()
if __name__ == "__main__":
# 运行对比测试
demonstrate_polars_vs_pandas()
# 运行流处理(需要Kafka环境)
print("\n" + "=" * 60)
print("启动Polars流处理器(需要Kafka)...")
print("=" * 60)
processor = PolarsStreamProcessor(chunk_size=5000)
# 定义处理管道
def processing_pipeline(lf: pl.LazyFrame) -> pl.LazyFrame:
return processor.create_lazy_pipeline(lf)
# 运行30秒(实际使用时移除时间限制)
# processor.process_kafka_stream(
# input_topic="raw.sensor.data",
# output_topic="processed.sensor.data",
# processing_func=processing_pipeline,
# duration_seconds=30
# )3.2.2 window_computation.py
脚本功能 :滚动窗口(Tumbling Window)聚合与水位线(Watermark)管理实现 使用方式 :python 3.2.2_window_computation.py
Python
复制
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.2.2 窗口计算与水印管理
功能:实现滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和
水位线(Watermark)机制处理乱序数据
使用方式:python 3.2.2_window_computation.py
"""
import time
import heapq
import logging
from datetime import datetime, timedelta
from typing import Dict, List, Callable, Optional, Tuple
from dataclasses import dataclass, field
from collections import defaultdict
import threading
import polars as pl
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass(order=True)
class WindowedEvent:
"""带时间戳的事件,用于窗口排序"""
timestamp: datetime = field(compare=True)
event_id: str = field(compare=False)
data: Dict = field(compare=False, default_factory=dict)
is_watermark: bool = field(compare=False, default=False)
def __post_init__(self):
# 确保timestamp是datetime类型
if isinstance(self.timestamp, str):
self.timestamp = datetime.fromisoformat(self.timestamp.replace('Z', '+00:00'))
class WatermarkManager:
"""
水位线管理器
处理乱序数据,确保窗口计算的正确性
"""
def __init__(self,
max_out_of_orderness: timedelta = timedelta(seconds=10),
idleness_timeout: timedelta = timedelta(seconds=60)):
self.max_out_of_orderness = max_out_of_orderness
self.idleness_timeout = idleness_timeout
self.current_watermark = datetime.min
self.last_event_times = defaultdict(datetime) # 分区最后事件时间
self._lock = threading.Lock()
def update_watermark(self, event_time: datetime, partition: str = "default") -> datetime:
"""
根据事件时间更新水位线
水位线 = 所有分区最小时间 - 最大乱序时间
"""
with self._lock:
self.last_event_times[partition] = max(
self.last_event_times[partition],
event_time
)
# 计算所有分区的最小时间(考虑空闲分区)
min_partition_time = min(
(t for t in self.last_event_times.values() if t > datetime.min),
default=datetime.min
)
# 新水位线
new_watermark = min_partition_time - self.max_out_of_orderness
if new_watermark > self.current_watermark:
self.current_watermark = new_watermark
logger.debug(f"水位线更新: {self.current_watermark}")
return self.current_watermark
def is_late(self, event_time: datetime) -> bool:
"""判断事件是否迟到(在水位线之前)"""
return event_time < self.current_watermark
def get_current_watermark(self) -> datetime:
return self.current_watermark
class TumblingWindow:
"""
滚动窗口实现
固定大小、不重叠的窗口
"""
def __init__(self, window_size: timedelta):
self.window_size = window_size
self.window_state = defaultdict(list) # window_end -> events
self.watermark_manager = WatermarkManager()
self.trigger_callbacks = []
def assign_windows(self, event_time: datetime) -> List[Tuple[datetime, datetime]]:
"""
分配事件到窗口
返回: [(window_start, window_end), ...]
"""
window_start = datetime.min + ((event_time - datetime.min) // self.window_size) * self.window_size
window_end = window_start + self.window_size
return [(window_start, window_end)]
def process_event(self, event: WindowedEvent) -> Optional[Dict]:
"""
处理单个事件,触发窗口计算
"""
# 更新水位线
watermark = self.watermark_manager.update_watermark(event.timestamp)
# 检查是否迟到
if self.watermark_manager.is_late(event.timestamp):
logger.warning(f"迟到事件丢弃: {event.event_id} @ {event.timestamp}")
return None
# 分配到窗口
windows = self.assign_windows(event.timestamp)
for window_start, window_end in windows:
self.window_state[window_end].append(event)
# 检查是否触发(水位线超过窗口结束时间)
if watermark >= window_end:
return self.trigger_window(window_end)
return None
def trigger_window(self, window_end: datetime) -> Dict:
"""
触发窗口计算
"""
events = self.window_state.pop(window_end, [])
window_start = window_end - self.window_size
if not events:
return {
'window_start': window_start,
'window_end': window_end,
'count': 0,
'aggregates': {}
}
# 使用Polars进行高效聚合
df = pl.from_dicts([e.data for e in events])
aggregates = {}
numeric_cols = [c for c in df.columns if df[c].dtype in [pl.Int64, pl.Float64]]
for col in numeric_cols:
aggregates[f'{col}_sum'] = df[col].sum()
aggregates[f'{col}_avg'] = df[col].mean()
aggregates[f'{col}_max'] = df[col].max()
aggregates[f'{col}_min'] = df[col].min()
result = {
'window_start': window_start,
'window_end': window_end,
'count': len(events),
'aggregates': aggregates,
'watermark': self.watermark_manager.get_current_watermark()
}
logger.info(f"窗口触发 [{window_start} - {window_end}]: {len(events)}条记录")
return result
class SlidingWindow:
"""
滑动窗口实现
固定窗口大小,按滑动间隔前进,窗口可重叠
"""
def __init__(self, window_size: timedelta, slide_interval: timedelta):
self.window_size = window_size
self.slide_interval = slide_interval
self.window_state = defaultdict(list)
self.watermark_manager = WatermarkManager()
self.last_triggered = datetime.min
def assign_windows(self, event_time: datetime) -> List[Tuple[datetime, datetime]]:
"""
一个事件可能属于多个重叠窗口
"""
windows = []
# 计算事件所属的窗口范围
window_start = datetime.min + ((event_time - datetime.min) // self.slide_interval) * self.slide_interval
# 向后滑动,找到所有包含该事件的窗口
current_start = window_start
while current_start + self.window_size > event_time:
if current_start <= event_time < current_start + self.window_size:
windows.append((current_start, current_start + self.window_size))
current_start -= self.slide_interval
return windows
def process_event(self, event: WindowedEvent) -> List[Dict]:
"""
处理事件,可能触发多个窗口
"""
watermark = self.watermark_manager.update_watermark(event.timestamp)
if self.watermark_manager.is_late(event.timestamp):
return []
windows = self.assign_windows(event.timestamp)
triggered_results = []
for window_start, window_end in windows:
self.window_state[window_end].append((event, window_start))
# 触发检查
if watermark >= window_end:
result = self.trigger_window(window_end)
if result:
triggered_results.append(result)
return triggered_results
def trigger_window(self, window_end: datetime) -> Optional[Dict]:
"""触发滑动窗口计算"""
events_data = self.window_state.pop(window_end, [])
if not events_data:
return None
window_start = window_end - self.window_size
events = [e for e, _ in events_data]
df = pl.from_dicts([e.data for e in events])
return {
'window_start': window_start,
'window_end': window_end,
'type': 'sliding',
'count': len(events),
'unique_events': len(set(e.event_id for e in events)), # 可能重复计数
'aggregates': {
'temp_avg': df['temperature'].mean() if 'temperature' in df.columns else None,
'temp_max': df['temperature'].max() if 'temperature' in df.columns else None
}
}
class WindowedStreamProcessor:
"""
集成窗口处理器
支持多种窗口类型和可视化
"""
def __init__(self):
self.tumbling_windows = {}
self.sliding_windows = {}
self.results_history = []
def create_tumbling_window(self, name: str, window_seconds: int):
self.tumbling_windows[name] = TumblingWindow(timedelta(seconds=window_seconds))
def create_sliding_window(self, name: str, window_seconds: int, slide_seconds: int):
self.sliding_windows[name] = SlidingWindow(
timedelta(seconds=window_seconds),
timedelta(seconds=slide_seconds)
)
def process_stream(self, events: List[WindowedEvent], window_name: str, window_type: str = "tumbling"):
"""
处理事件流并收集结果
"""
window = self.tumbling_windows.get(window_name) if window_type == "tumbling" else self.sliding_windows.get(window_name)
if not window:
raise ValueError(f"窗口 {window_name} 未找到")
results = []
for event in events:
if window_type == "tumbling":
result = window.process_event(event)
if result:
results.append(result)
self.results_history.append((event.timestamp, result))
else:
batch = window.process_event(event)
results.extend(batch)
for r in batch:
self.results_history.append((event.timestamp, r))
return results
def visualize_windows(self, output_file: str = "window_computation.png"):
"""
可视化窗口计算过程
"""
if not self.results_history:
logger.warning("无数据可可视化")
return
fig, axes = plt.subplots(3, 1, figsize=(14, 12))
fig.suptitle('Window Computation & Watermark Management', fontsize=16, fontweight='bold')
# 1. 时间线视图
ax1 = axes[0]
# 绘制事件点
event_times = [h[0] for h in self.results_history]
y_pos = range(len(event_times))
ax1.scatter(event_times, y_pos, c='#2E86AB', s=50, alpha=0.6, label='Events')
# 绘制窗口范围
for i, (ts, result) in enumerate(self.results_history):
start = result['window_start']
end = result['window_end']
ax1.barh(i, end - start, left=start, height=0.3, alpha=0.3, color='#F18F01')
ax1.set_xlabel('Time')
ax1.set_ylabel('Event Sequence')
ax1.set_title('Event Timeline & Window Assignment')
ax1.legend()
# 2. 水位线进展
ax2 = axes[1]
watermarks = []
max_event_times = []
for ts, result in self.results_history:
watermarks.append(result.get('watermark', ts))
max_event_times.append(ts)
ax2.plot(range(len(watermarks)), watermarks, 'b-', label='Watermark', linewidth=2)
ax2.plot(range(len(max_event_times)), max_event_times, 'r--', label='Max Event Time', alpha=0.5)
ax2.fill_between(range(len(watermarks)), watermarks, max_event_times, alpha=0.2, color='red', label='Out-of-orderness')
ax2.set_xlabel('Processing Step')
ax2.set_ylabel('Timestamp')
ax2.set_title('Watermark Progress vs Event Time')
ax2.legend()
# 3. 窗口统计
ax3 = axes[2]
window_counts = [r['count'] for _, r in self.results_history]
window_labels = [f"{r['window_start'].strftime('%H:%M:%S')}" for _, r in self.results_history]
bars = ax3.bar(window_labels, window_counts, color='#A23B72')
ax3.set_xlabel('Window Start Time')
ax3.set_ylabel('Event Count')
ax3.set_title('Events per Window')
ax3.tick_params(axis='x', rotation=45)
# 添加数值标签
for bar, count in zip(bars, window_counts):
height = bar.get_height()
ax3.text(bar.get_x() + bar.get_width()/2., height,
f'{count}', ha='center', va='bottom')
plt.tight_layout()
plt.savefig(output_file, dpi=150, bbox_inches='tight')
logger.info(f"窗口可视化已保存: {output_file}")
plt.show()
def generate_out_of_order_events() -> List[WindowedEvent]:
"""
生成包含乱序事件的测试数据
"""
base_time = datetime(2024, 1, 1, 12, 0, 0)
events = []
# 正常顺序事件(0-40秒)
for i in range(0, 40, 2):
events.append(WindowedEvent(
timestamp=base_time + timedelta(seconds=i),
event_id=f"normal_{i}",
data={'temperature': 20 + i * 0.5, 'value': i * 10}
))
# 乱序事件(模拟延迟到达,插入到20-30秒之间)
late_events = [
WindowedEvent(timestamp=base_time + timedelta(seconds=15), event_id="late_1",
data={'temperature': 25, 'value': 150}),
WindowedEvent(timestamp=base_time + timedelta(seconds=8), event_id="late_2",
data={'temperature': 22, 'value': 80}),
WindowedEvent(timestamp=base_time + timedelta(seconds=22), event_id="late_3",
data={'temperature': 28, 'value': 220})
]
events.extend(late_events)
# 继续正常事件(40-60秒)
for i in range(40, 60, 2):
events.append(WindowedEvent(
timestamp=base_time + timedelta(seconds=i),
event_id=f"normal_{i}",
data={'temperature': 20 + i * 0.3, 'value': i * 10}
))
# 按时间排序(模拟真实流乱序)
events.sort(key=lambda x: x.timestamp)
return events
def demonstrate_window_computation():
"""
窗口计算完整演示
"""
print("=" * 60)
print("3.2.2 窗口计算与水印管理演示")
print("=" * 60)
# 生成测试数据
events = generate_out_of_order_events()
print(f"生成 {len(events)} 个事件(包含乱序数据)")
# 显示乱序情况
sorted_times = sorted([e.timestamp for e in events])
out_of_order_count = sum(1 for i in range(len(sorted_times)-1)
if events[i].timestamp != sorted_times[i])
print(f"乱序事件数: {out_of_order_count}")
# 1. 滚动窗口处理
print("\n--- 滚动窗口 (Tumbling Window, 10秒) ---")
processor = WindowedStreamProcessor()
processor.create_tumbling_window("10s", 10)
tumbling_results = processor.process_stream(events, "10s", "tumbling")
print(f"触发窗口数: {len(tumbling_results)}")
for r in tumbling_results[:3]:
print(f" [{r['window_start'].strftime('%H:%M:%S')} - {r['window_end'].strftime('%H:%M:%S')}] "
f"Count: {r['count']}, Avg: {r['aggregates'].get('value_avg', 0):.1f}")
# 2. 滑动窗口处理
print("\n--- 滑动窗口 (Sliding Window, 15秒窗口, 5秒滑动) ---")
processor.create_sliding_window("15s-5s", 15, 5)
sliding_results = processor.process_stream(events, "15s-5s", "sliding")
print(f"触发窗口数: {len(sliding_results)}")
for r in sliding_results[:3]:
print(f" [{r['window_start'].strftime('%H:%M:%S')} - {r['window_end'].strftime('%H:%M:%S')}] "
f"Count: {r['count']}, TempAvg: {r['aggregates'].get('temp_avg', 0):.1f}")
# 3. 可视化
print("\n生成可视化报告...")
processor.visualize_windows()
# 4. 显示水印效果
print("\n水印管理统计:")
wm = processor.tumbling_windows["10s"].watermark_manager
print(f" 最终水位线: {wm.get_current_watermark()}")
print(f" 允许乱序时间: 10秒")
print(f" 迟到事件处理策略: 丢弃")
if __name__ == "__main__":
demonstrate_window_computation()3.2.3 stream_join.py
脚本功能 :多Kafka Topic流合并(Join)与RocksDB状态存储实现 使用方式 :python 3.2.3_stream_join.py
Python
复制
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.2.3 流合并与状态存储
功能:实现Stream-Stream Join、Stream-Table Join,使用RocksDB作为状态后端
使用方式:python 3.2.3_stream_join.py
"""
import os
import json
import time
import shutil
import logging
from datetime import datetime, timedelta
from typing import Dict, List, Optional, Callable, Any
from dataclasses import dataclass, asdict
import threading
import tempfile
import rocksdb
import polars as pl
from kafka import KafkaConsumer, KafkaProducer, TopicPartition
import matplotlib.pyplot as plt
import networkx as nx
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class JoinState:
"""Join状态记录"""
key: str
value: Dict
timestamp: datetime
topic: str
ttl_seconds: int = 300 # 默认5分钟过期
class RocksDBStateStore:
"""
RocksDB状态存储后端
特性:
- 持久化状态(故障恢复)
- TTL支持(自动过期)
- 高吞吐读写
"""
def __init__(self, db_path: Optional[str] = None, ttl_seconds: int = 300):
if db_path is None:
db_path = tempfile.mkdtemp(prefix="stream_join_state_")
self.db_path = db_path
# 配置RocksDB
opts = rocksdb.Options()
opts.create_if_missing = True
opts.write_buffer_size = 67108864 # 64MB
opts.max_write_buffer_number = 3
opts.target_file_size_base = 67108864
opts.table_factory = rocksdb.BlockBasedTableFactory(
block_cache=rocksdb.LRUCache(512 * 1024 * 1024) # 512MB缓存
)
# 启用TTL列族
self.db = rocksdb.DB(db_path, opts, read_only=False)
self.ttl_seconds = ttl_seconds
self._lock = threading.RLock()
logger.info(f"RocksDB状态存储初始化: {db_path}")
def put(self, key: str, value: Any, topic: str = "default"):
"""
写入状态,带时间戳和TTL
"""
with self._lock:
state = JoinState(
key=key,
value=value,
timestamp=datetime.utcnow(),
topic=topic,
ttl_seconds=self.ttl_seconds
)
# 序列化存储
key_bytes = f"{topic}:{key}".encode()
value_bytes = json.dumps(asdict(state), default=str).encode()
self.db.put(key_bytes, value_bytes)
def get(self, key: str, topic: str = "default") -> Optional[JoinState]:
"""
读取状态,检查TTL
"""
with self._lock:
key_bytes = f"{topic}:{key}".encode()
value_bytes = self.db.get(key_bytes)
if value_bytes is None:
return None
state_dict = json.loads(value_bytes.decode())
state = JoinState(**state_dict)
# TTL检查
age = (datetime.utcnow() - state.timestamp).total_seconds()
if age > state.ttl_seconds:
# 过期删除
self.db.delete(key_bytes)
return None
return state
def get_by_prefix(self, prefix: str) -> List[JoinState]:
"""前缀查询(用于范围Join)"""
results = []
prefix_bytes = prefix.encode()
it = self.db.iteritems()
it.seek(prefix_bytes)
for key, value in it:
if not key.startswith(prefix_bytes):
break
state_dict = json.loads(value.decode())
state = JoinState(**state_dict)
# TTL检查
age = (datetime.utcnow() - state.timestamp).total_seconds()
if age <= state.ttl_seconds:
results.append(state)
return results
def delete(self, key: str, topic: str = "default"):
"""删除状态"""
key_bytes = f"{topic}:{key}".encode()
self.db.delete(key_bytes)
def get_stats(self) -> Dict:
"""获取存储统计"""
# 估算条目数(RocksDB没有精确计数API)
it = self.db.iterkeys()
count = sum(1 for _ in it)
# 获取磁盘大小
total_size = 0
for dirpath, dirnames, filenames in os.walk(self.db_path):
for f in filenames:
fp = os.path.join(dirpath, f)
total_size += os.path.getsize(fp)
return {
'estimated_entries': count,
'disk_size_mb': total_size / (1024 * 1024),
'ttl_seconds': self.ttl_seconds
}
def close(self):
"""关闭数据库"""
del self.db
# 清理临时目录
if "temp" in self.db_path:
shutil.rmtree(self.db_path, ignore_errors=True)
logger.info(f"清理临时状态目录: {self.db_path}")
def __del__(self):
self.close()
class StreamJoinOperator:
"""
流Join算子
支持:
- Inner Join
- Left Join
- Interval Join(时间范围内匹配)
"""
def __init__(self,
left_topic: str,
right_topic: str,
join_key: str,
state_store: RocksDBStateStore,
join_window: timedelta = timedelta(minutes=5)):
self.left_topic = left_topic
self.right_topic = right_topic
self.join_key = join_key
self.state_store = state_store
self.join_window = join_window
self.join_func = None # 用户定义的Join逻辑
self.metrics = {
'left_received': 0,
'right_received': 0,
'joins_emitted': 0,
'left_dropped': 0,
'right_dropped': 0
}
def set_join_function(self, func: Callable[[Dict, Dict], Dict]):
"""设置Join后的处理函数"""
self.join_func = func
def process_left(self, key: str, value: Dict, timestamp: datetime) -> Optional[List[Dict]]:
"""
处理左流事件
存储状态并尝试与右流Join
"""
self.metrics['left_received'] += 1
# 存储左流状态
self.state_store.put(key, {
'value': value,
'timestamp': timestamp.isoformat()
}, self.left_topic)
# 查询匹配的右流事件
right_state = self.state_store.get(key, self.right_topic)
if right_state:
# 检查时间窗口
right_time = datetime.fromisoformat(right_state.value['timestamp'])
if abs((timestamp - right_time).total_seconds()) <= self.join_window.total_seconds():
# 满足Join条件
joined = self._do_join(value, right_state.value['value'])
self.metrics['joins_emitted'] += 1
return [joined]
return None
def process_right(self, key: str, value: Dict, timestamp: datetime) -> Optional[List[Dict]]:
"""
处理右流事件
"""
self.metrics['right_received'] += 1
# 存储右流状态
self.state_store.put(key, {
'value': value,
'timestamp': timestamp.isoformat()
}, self.right_topic)
# 查询左流
left_state = self.state_store.get(key, self.left_topic)
if left_state:
left_time = datetime.fromisoformat(left_state.value['timestamp'])
if abs((timestamp - left_time).total_seconds()) <= self.join_window.total_seconds():
joined = self._do_join(left_state.value['value'], value)
self.metrics['joins_emitted'] += 1
return [joined]
return None
def _do_join(self, left: Dict, right: Dict) -> Dict:
"""执行Join"""
if self.join_func:
return self.join_func(left, right)
# 默认Full Outer结构
return {
'join_key': self.join_key,
'left': left,
'right': right,
'joined_at': datetime.utcnow().isoformat()
}
def get_metrics(self) -> Dict:
return {**self.metrics, 'state_stats': self.state_store.get_stats()}
class StreamJoinEngine:
"""
流Join引擎
管理多个Join操作和Kafka消费
"""
def __init__(self, kafka_bootstrap: str = "localhost:9092"):
self.kafka_bootstrap = kafka_bootstrap
self.joins = []
self.state_store = None
self.running = False
def create_join(self,
left_topic: str,
right_topic: str,
output_topic: str,
join_key: str,
join_func: Optional[Callable] = None) -> StreamJoinOperator:
"""
创建Join操作
"""
if self.state_store is None:
self.state_store = RocksDBStateStore()
join_op = StreamJoinOperator(
left_topic=left_topic,
right_topic=right_topic,
join_key=join_key,
state_store=self.state_store
)
if join_func:
join_op.set_join_function(join_func)
self.joins.append({
'operator': join_op,
'output_topic': output_topic
})
return join_op
def run(self, duration_seconds: int = 60):
"""
运行Join引擎(多线程消费)
"""
self.running = True
producer = KafkaProducer(
bootstrap_servers=self.kafka_bootstrap,
value_serializer=lambda v: json.dumps(v, default=str).encode('utf-8')
)
# 为每个Join创建消费者线程
threads = []
for join_config in self.joins:
t = threading.Thread(
target=self._consume_join,
args=(join_config, producer, duration_seconds)
)
threads.append(t)
t.start()
# 等待完成
for t in threads:
t.join()
self.running = False
producer.close()
self._visualize_join_stats()
def _consume_join(self, join_config: Dict, producer: KafkaProducer, duration: int):
"""
消费并执行Join(简化版单线程实现)
生产环境应使用Consumer Group
"""
join_op = join_config['operator']
output_topic = join_config['output_topic']
# 创建多主题消费者
consumer = KafkaConsumer(
join_op.left_topic,
join_op.right_topic,
bootstrap_servers=self.kafka_bootstrap,
group_id=f"join-group-{int(time.time())}",
auto_offset_reset='latest',
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
start_time = time.time()
logger.info(f"启动Join消费: {join_op.left_topic} JOIN {join_op.right_topic}")
try:
while time.time() - start_time < duration and self.running:
messages = consumer.poll(timeout_ms=1000)
for tp, records in messages.items():
topic = tp.topic
for record in records:
key = record.key.decode() if record.key else str(record.value.get(join_op.join_key))
value = record.value
timestamp = datetime.fromtimestamp(record.timestamp / 1000)
# 分发到对应处理函数
if topic == join_op.left_topic:
results = join_op.process_left(key, value, timestamp)
else:
results = join_op.process_right(key, value, timestamp)
# 输出结果
if results:
for r in results:
producer.send(output_topic, key=key.encode(), value=r)
except Exception as e:
logger.error(f"Join处理错误: {e}")
finally:
consumer.close()
logger.info(f"Join消费结束: {join_op.get_metrics()}")
def _visualize_join_stats(self):
"""可视化Join统计"""
if not self.joins:
return
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle('Stream Join Performance & State Management', fontsize=16, fontweight='bold')
for idx, join_config in enumerate(self.joins[:4]): # 最多显示4个
if idx >= 4:
break
ax = axes[idx // 2, idx % 2]
op = join_config['operator']
metrics = op.get_metrics()
stats = metrics['state_stats']
# 指标文本
stats_text = f"""
Join: {op.left_topic} JOIN {op.right_topic}
Input Stats:
Left Received: {metrics['left_received']}
Right Received: {metrics['right_received']}
Joins Emitted: {metrics['joins_emitted']}
State Store (RocksDB):
Estimated Entries: {stats['estimated_entries']}
Disk Size: {stats['disk_size_mb']:.2f} MB
TTL: {stats['ttl_seconds']}s
Efficiency: {(metrics['joins_emitted'] / max(metrics['left_received'] + metrics['right_received'], 1) * 100):.1f}%
"""
ax.text(0.1, 0.9, stats_text, transform=ax.transAxes,
fontsize=10, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.8))
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.axis('off')
ax.set_title(f'Join Operator {idx+1}')
plt.tight_layout()
plt.savefig('stream_join_stats.png', dpi=150, bbox_inches='tight')
logger.info("Join统计可视化已保存: stream_join_stats.png")
plt.show()
def close(self):
if self.state_store:
self.state_store.close()
def demonstrate_stream_join():
"""
流Join演示
"""
print("=" * 60)
print("3.2.3 流合并(Stream Join)与RocksDB状态存储")
print("=" * 60)
# 初始化状态存储
print("\n初始化RocksDB状态存储...")
state_store = RocksDBStateStore(ttl_seconds=300)
# 模拟数据
print("写入测试状态...")
state_store.put("user_123", {
"user_id": "user_123",
"name": "张三",
"age": 30
}, "user_profiles")
state_store.put("user_123", {
"order_id": "order_456",
"user_id": "user_123",
"amount": 199.99,
"timestamp": datetime.utcnow().isoformat()
}, "orders")
# 读取并Join
profile = state_store.get("user_123", "user_profiles")
order = state_store.get("user_123", "orders")
if profile and order:
joined = {
"user_id": "user_123",
"user_name": profile.value['name'],
"order_amount": order.value['amount'],
"joined_at": datetime.utcnow().isoformat()
}
print(f"Join结果: {json.dumps(joined, indent=2, ensure_ascii=False)}")
# 显示统计
stats = state_store.get_stats()
print(f"\n状态存储统计:")
print(f" 条目数: {stats['estimated_entries']}")
print(f" 磁盘占用: {stats['disk_size_mb']:.2f} MB")
# 可视化(如果matplotlib可用)
fig, ax = plt.subplots(figsize=(10, 6))
# RocksDB架构图
ax.text(0.5, 0.9, 'RocksDB State Store Architecture',
ha='center', fontsize=14, fontweight='bold', transform=ax.transAxes)
# 层级结构
layers = [
('MemTable (Active)', 0.7, '#4CAF50'),
('MemTable (Immutable)', 0.55, '#8BC34A'),
('Level 0 SST', 0.4, '#FFC107'),
('Level 1 SST', 0.25, '#FF9800'),
('Level N SST', 0.1, '#F44336')
]
for label, y, color in layers:
rect = Rectangle((0.1, y-0.05), 0.8, 0.08, facecolor=color, edgecolor='black', alpha=0.7)
ax.add_patch(rect)
ax.text(0.5, y, label, ha='center', va='center', fontweight='bold', transform=ax.transAxes)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.axis('off')
plt.title('LSM-Tree Structure in Stream Processing State Store')
plt.tight_layout()
plt.savefig('rocksdb_architecture.png', dpi=150)
plt.show()
state_store.close()
print("\n状态存储已关闭并清理")
if __name__ == "__main__":
demonstrate_stream_join()
# 如果需要测试完整Kafka Join(需要Kafka环境)
print("\n" + "=" * 60)
print("如需测试完整Kafka流Join,请确保:")
print("1. Kafka运行中")
print("2. 创建topics: user_clicks, user_profiles, joined_enriched")
print("然后取消注释以下代码")
print("=" * 60)
# engine = StreamJoinEngine()
# engine.create_join(
# left_topic="user_clicks",
# right_topic="user_profiles",
# output_topic="joined_enriched",
# join_key="user_id",
# join_func=lambda click, profile: {
# "user_id": click.get("user_id"),
# "click_time": click.get("timestamp"),
# "user_segment": profile.get("segment"),
# "page": click.get("page")
# }
# )
# engine.run(duration_seconds=60)
# engine.close()3.2.4 error_handling.py
脚本功能 :Poison Pill消息隔离、死信队列(DLQ)、Side Output侧流收集 使用方式 :python 3.2.4_error_handling.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.2.4 错误处理与 poison pill 隔离
功能:
- 解析/处理错误分类
- Dead Letter Queue (DLQ) 实现
- Side Output 侧流收集(成功/失败分流)
- 自动重试与指数退避
使用方式:python 3.2.4_error_handling.py
"""
import json
import time
import logging
from datetime import datetime
from typing import Dict, List, Callable, Optional, Any, Tuple
from enum import Enum, auto
from dataclasses import dataclass, asdict
import traceback
import hashlib
from kafka import KafkaProducer, KafkaConsumer, KafkaError
import matplotlib.pyplot as plt
from collections import defaultdict, deque
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ErrorType(Enum):
"""错误类型分类"""
DESERIALIZATION_ERROR = auto() # 反序列化失败
VALIDATION_ERROR = auto() # 数据验证失败
PROCESSING_ERROR = auto() # 业务逻辑处理失败
TRANSIENT_ERROR = auto() # 临时错误(可重试)
FATAL_ERROR = auto() # 致命错误(立即停止)
@dataclass
class FailedRecord:
"""失败记录结构"""
original_topic: str
original_partition: int
original_offset: int
original_key: Optional[str]
original_value: Any
error_type: str
error_message: str
error_stacktrace: str
failed_at: str
retry_count: int = 0
processing_stage: str = "unknown"
def to_dict(self) -> Dict:
return asdict(self)
class ErrorHandler:
"""
错误处理器
管理错误分类、重试、DLQ路由
"""
def __init__(self,
kafka_bootstrap: str = "localhost:9092",
dlq_topic_prefix: str = "dlq",
max_retries: int = 3,
retry_backoff_ms: int = 1000):
self.kafka_bootstrap = kafka_bootstrap
self.dlq_topic_prefix = dlq_topic_prefix
self.max_retries = max_retries
self.retry_backoff_ms = retry_backoff_ms
# 生产者(发送DLQ和Side Output)
self.producer = KafkaProducer(
bootstrap_servers=kafka_bootstrap,
value_serializer=lambda v: json.dumps(v, default=str).encode('utf-8'),
acks='all',
retries=3
)
# 错误统计
self.error_stats = defaultdict(lambda: {
'count': 0,
'last_error': None,
'examples': deque(maxlen=5)
})
# 侧流缓冲区
self.side_outputs = {
'success': deque(maxlen=1000),
'parse_error': deque(maxlen=1000),
'validation_error': deque(maxlen=1000),
'processing_error': deque(maxlen=1000)
}
def classify_error(self, exception: Exception) -> ErrorType:
"""
智能错误分类
"""
error_str = str(exception).lower()
exc_type = type(exception).__name__
# 反序列化错误
if any(k in error_str for k in ['json', 'decode', 'parse', 'serialization']):
return ErrorType.DESERIALIZATION_ERROR
# 验证错误
if any(k in error_str for k in ['validation', 'schema', 'invalid', 'constraint']):
return ErrorType.VALIDATION_ERROR
# 临时错误(网络、超时)
if any(k in error_str for k in ['timeout', 'connection', 'unavailable', 'temporarily']) or \
'kafka' in error_str:
return ErrorType.TRANSIENT_ERROR
# 致命错误
if any(k in error_str for k in ['memory', 'kill', 'fatal', 'crash']):
return ErrorType.FATAL_ERROR
return ErrorType.PROCESSING_ERROR
def should_retry(self, error_type: ErrorType, retry_count: int) -> bool:
"""判断是否应重试"""
if retry_count >= self.max_retries:
return False
return error_type in [ErrorType.TRANSIENT_ERROR, ErrorType.PROCESSING_ERROR]
def handle_error(self,
record: Any,
exception: Exception,
context: Dict) -> Tuple[str, Optional[Dict]]:
"""
主错误处理入口
Returns:
(action, result_or_none)
action: 'retry', 'dlq', 'drop', 'side_output'
"""
error_type = self.classify_error(exception)
retry_count = context.get('retry_count', 0)
# 更新统计
self.error_stats[error_type.name]['count'] += 1
self.error_stats[error_type.name]['last_error'] = str(exception)
# 检查重试
if self.should_retry(error_type, retry_count):
logger.warning(f"可重试错误,第{retry_count+1}次重试: {exception}")
time.sleep(self.retry_backoff_ms * (2 ** retry_count) / 1000) # 指数退避
return 'retry', None
# 构造失败记录
failed_record = FailedRecord(
original_topic=context.get('topic', 'unknown'),
original_partition=context.get('partition', -1),
original_offset=context.get('offset', -1),
original_key=context.get('key'),
original_value=str(record)[:1000], # 截断避免过大
error_type=error_type.name,
error_message=str(exception),
error_stacktrace=traceback.format_exc(),
failed_at=datetime.utcnow().isoformat(),
retry_count=retry_count,
processing_stage=context.get('stage', 'unknown')
)
# 发送到DLQ
dlq_topic = f"{self.dlq_topic_prefix}.{error_type.name.lower()}"
self._send_to_dlq(dlq_topic, failed_record)
# 发送到Side Output(用于分析)
self._send_to_side_output(error_type, failed_record)
# 记录示例
self.error_stats[error_type.name]['examples'].append(failed_record.to_dict())
logger.error(f"消息进入DLQ [{dlq_topic}]: {exception}")
return 'dlq', failed_record.to_dict()
def _send_to_dlq(self, topic: str, failed_record: FailedRecord):
"""发送到死信队列"""
try:
key = f"{failed_record.original_topic}-{failed_record.original_offset}"
self.producer.send(
topic=topic,
key=key.encode(),
value=failed_record.to_dict(),
headers={
'error_type': failed_record.error_type.encode(),
'original_topic': failed_record.original_topic.encode(),
'failed_at': failed_record.failed_at.encode()
}
)
self.producer.flush()
except Exception as e:
logger.critical(f"DLQ发送失败(严重): {e}")
def _send_to_side_output(self, error_type: ErrorType, failed_record: FailedRecord):
"""发送到侧流"""
category = error_type.name.lower().replace('_error', '')
if category in self.side_outputs:
self.side_outputs[category].append(failed_record.to_dict())
def record_success(self, record: Dict, context: Dict):
"""记录成功处理(Side Output)"""
self.side_outputs['success'].append({
'record': record,
'processed_at': datetime.utcnow().isoformat(),
'processing_time_ms': context.get('processing_time_ms', 0),
'stage': context.get('stage', 'unknown')
})
def get_error_report(self) -> Dict:
"""生成错误报告"""
return {
'timestamp': datetime.utcnow().isoformat(),
'statistics': dict(self.error_stats),
'side_outputs': {
k: len(v) for k, v in self.side_outputs.items()
}
}
def visualize_error_distribution(self, output_file: str = "error_handling.png"):
"""可视化错误分布"""
if not self.error_stats:
logger.warning("无错误数据可可视化")
return
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle('Error Handling & Dead Letter Queue Analysis', fontsize=16, fontweight='bold')
# 1. 错误类型分布(饼图)
ax1 = axes[0, 0]
error_types = list(self.error_stats.keys())
counts = [self.error_stats[t]['count'] for t in error_types]
colors = ['#F44336', '#FF9800', '#FFC107', '#4CAF50', '#2196F3']
if counts:
wedges, texts, autotexts = ax1.pie(counts, labels=error_types, autopct='%1.1f%%',
colors=colors[:len(error_types)], startangle=90)
ax1.set_title('Error Type Distribution')
# 2. Side Output流量
ax2 = axes[0, 1]
side_categories = list(self.side_outputs.keys())
side_counts = [len(self.side_outputs[k]) for k in side_categories]
bars = ax2.bar(side_categories, side_counts, color=['#4CAF50', '#F44336', '#FF9800', '#9C27B0'])
ax2.set_title('Side Output Streams')
ax2.set_ylabel('Record Count')
for bar, count in zip(bars, side_counts):
if count > 0:
ax2.text(bar.get_x() + bar.get_width()/2, bar.get_height(),
f'{count}', ha='center', va='bottom')
# 3. 错误处理流程图
ax3 = axes[1, 0]
flow_text = """
Error Handling Flow:
1. Catch Exception
↓
2. Classify Error Type
• Deserialization → Immediate DLQ
• Validation → Immediate DLQ
• Transient → Retry (exponential backoff)
• Processing → Retry then DLQ
• Fatal → Stop Pipeline
↓
3. Retry Decision
[Retry Count < Max?]
├─ Yes → Backoff → Reprocess
└─ No → Send to DLQ
↓
4. Side Output
• Success Stream → Next Stage
• Error Stream → Analysis
• DLQ → Manual Inspection
"""
ax3.text(0.05, 0.95, flow_text, transform=ax3.transAxes,
fontsize=10, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='lightgreen', alpha=0.8))
ax3.set_xlim(0, 1)
ax3.set_ylim(0, 1)
ax3.axis('off')
ax3.set_title('Processing Logic')
# 4. 最近错误示例
ax4 = axes[1, 1]
examples_text = "Recent Error Examples:\n\n"
for error_type, stats in list(self.error_stats.items())[:3]:
if stats['examples']:
ex = stats['examples'][-1]
examples_text += f"[{error_type}]\n"
examples_text += f" Stage: {ex['processing_stage']}\n"
examples_text += f" Error: {ex['error_message'][:50]}...\n"
examples_text += f" Topic: {ex['original_topic']}:{ex['original_partition']}\n\n"
ax4.text(0.05, 0.95, examples_text, transform=ax4.transAxes,
fontsize=9, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='#FFEBEE'))
ax4.set_xlim(0, 1)
ax4.set_ylim(0, 1)
ax4.axis('off')
ax4.set_title('Error Samples')
plt.tight_layout()
plt.savefig(output_file, dpi=150, bbox_inches='tight')
logger.info(f"错误处理可视化已保存: {output_file}")
plt.show()
def close(self):
self.producer.flush()
self.producer.close()
class ResilientStreamProcessor:
"""
弹性流处理器
集成错误处理的完整Kafka消费者
"""
def __init__(self,
input_topic: str,
output_topic: str,
kafka_bootstrap: str = "localhost:9092",
processing_func: Optional[Callable] = None):
self.input_topic = input_topic
self.output_topic = output_topic
self.kafka_bootstrap = kafka_bootstrap
self.processing_func = processing_func or self._default_process
self.error_handler = ErrorHandler(kafka_bootstrap)
self.running = False
# 指标
self.metrics = {
'processed': 0,
'failed': 0,
'retried': 0,
'start_time': None
}
def _default_process(self, record: Dict) -> Dict:
"""默认处理函数(示例)"""
# 模拟可能失败的业务逻辑
if 'value' not in record:
raise ValueError("Missing 'value' field")
if record['value'] < 0:
raise ValueError("Negative value not allowed")
return {
'processed_value': record['value'] * 2,
'processed_at': datetime.utcnow().isoformat()
}
def run(self, duration_seconds: int = 60):
"""运行处理器"""
self.running = True
self.metrics['start_time'] = time.time()
consumer = KafkaConsumer(
self.input_topic,
bootstrap_servers=self.kafka_bootstrap,
group_id=f"resilient-processor-{int(time.time())}",
auto_offset_reset='latest',
enable_auto_commit=False,
max_poll_records=100
)
producer = KafkaProducer(
bootstrap_servers=self.kafka_bootstrap,
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
logger.info(f"启动弹性处理器: {self.input_topic} -> {self.output_topic}")
try:
while self.running and (time.time() - self.metrics['start_time']) < duration_seconds:
messages = consumer.poll(timeout_ms=1000)
for tp, records in messages.items():
for record in records:
self._process_single(record, producer)
# 成功处理后提交偏移
consumer.commit_async()
except KeyboardInterrupt:
logger.info("收到停止信号")
finally:
self.running = False
consumer.close()
producer.flush()
producer.close()
self.error_handler.close()
self._print_summary()
def _process_single(self, record, producer):
"""处理单条记录"""
context = {
'topic': record.topic,
'partition': record.partition,
'offset': record.offset,
'key': record.key.decode() if record.key else None,
'retry_count': 0,
'stage': 'parsing'
}
try:
# 阶段1: 解析
try:
data = json.loads(record.value.decode('utf-8'))
except Exception as e:
raise Exception(f"JSON parse error: {e}")
context['stage'] = 'processing'
start_proc = time.time()
# 阶段2: 业务处理
result = self.processing_func(data)
context['processing_time_ms'] = (time.time() - start_proc) * 1000
context['stage'] = 'success'
# 发送成功结果
producer.send(self.output_topic, key=record.key, value=result)
# 记录成功
self.error_handler.record_success(result, context)
self.metrics['processed'] += 1
except Exception as e:
self.metrics['failed'] += 1
# 错误处理
action, error_result = self.error_handler.handle_error(
record=record.value,
exception=e,
context=context
)
if action == 'retry':
self.metrics['retried'] += 1
context['retry_count'] += 1
# 简化:实际应重新放入队列或本地重试
def _print_summary(self):
"""打印处理摘要"""
duration = time.time() - self.metrics['start_time']
print(f"\n{'='*60}")
print("处理摘要:")
print(f" 运行时间: {duration:.1f}秒")
print(f" 成功处理: {self.metrics['processed']}")
print(f" 失败处理: {self.metrics['failed']}")
print(f" 重试次数: {self.metrics['retried']}")
print(f" 成功率: {(self.metrics['processed'] / max(self.metrics['processed'] + self.metrics['failed'], 1) * 100):.1f}%")
print(f"{'='*60}")
# 生成可视化
self.error_handler.visualize_error_distribution()
def demonstrate_error_handling():
"""
错误处理演示
"""
print("=" * 60)
print("3.2.4 错误处理与Poison Pill隔离")
print("=" * 60)
handler = ErrorHandler()
# 模拟各种错误
test_cases = [
# (数据, 预期错误类型)
(b'invalid json {', "DESERIALIZATION_ERROR"),
({'missing_value': True}, "PROCESSING_ERROR"),
({'value': -10}, "PROCESSING_ERROR"),
({'value': 100}, "SUCCESS") # 正常
]
for data, expected_error in test_cases:
context = {
'topic': 'test.topic',
'partition': 0,
'offset': 12345,
'key': 'test-key',
'retry_count': 0,
'stage': 'test'
}
try:
if isinstance(data, bytes):
json.loads(data.decode())
else:
if 'value' not in data:
raise ValueError("Missing required field")
if data.get('value', 0) < 0:
raise ValueError("Invalid value range")
print(f"✓ 正常处理: {data}")
handler.record_success(data, context)
except Exception as e:
action, result = handler.handle_error(data, e, context)
print(f"✗ 捕获错误 [{handler.classify_error(e).name}]: {e}")
print(f" 处理动作: {action}")
# 显示统计
print(f"\n错误统计:")
report = handler.get_error_report()
for error_type, stats in report['statistics'].items():
print(f" {error_type}: {stats['count']}")
# 可视化
handler.visualize_error_distribution()
handler.close()
if __name__ == "__main__":
demonstrate_error_handling()3.3 存储层设计实现
3.3.1 delta_lake_integration.py
脚本功能 :Delta Lake集成,展示ACID事务、Schema演化、Time Travel查询 使用方式 :python 3.3.1_delta_lake_integration.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.3.1 Delta Lake集成实现
功能:ACID事务保证、Schema演化、Time Travel查询、并发控制
使用方式:python 3.3.1_delta_lake_integration.py
依赖:deltalake, pyarrow, pandas
"""
import os
import json
import time
import logging
from datetime import datetime, timedelta
from typing import Dict, List, Optional, Any, Union
import tempfile
import shutil
import pandas as pd
import polars as pl
import pyarrow as pa
import pyarrow.parquet as pq
from deltalake import DeltaTable, write_deltalake
from deltalake.table import Schema as DeltaSchema
import matplotlib.pyplot as plt
import numpy as np
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class DeltaLakeManager:
"""
Delta Lake管理器
封装所有Delta Lake操作,提供高层API
"""
def __init__(self, storage_path: str):
self.storage_path = storage_path
self.table = None
self._ensure_path_exists()
def _ensure_path_exists(self):
"""确保存储路径存在"""
if not os.path.exists(self.storage_path):
os.makedirs(self.storage_path, exist_ok=True)
logger.info(f"创建Delta Lake存储路径: {self.storage_path}")
def create_table(self,
data: Union[pd.DataFrame, pl.DataFrame, pa.Table],
table_name: str,
partition_by: Optional[List[str]] = None,
mode: str = "overwrite"):
"""
创建Delta表
Args:
data: 初始数据
table_name: 表名
partition_by: 分区列
mode: 写入模式(overwrite/append/error)
"""
table_path = os.path.join(self.storage_path, table_name)
# 转换为PyArrow Table
if isinstance(data, pd.DataFrame):
arrow_table = pa.Table.from_pandas(data)
elif isinstance(data, pl.DataFrame):
arrow_table = data.to_arrow()
else:
arrow_table = data
write_deltalake(
table_or_uri=table_path,
data=arrow_table,
partition_by=partition_by,
mode=mode,
# ACID配置
engine='pyarrow'
)
self.table = DeltaTable(table_path)
logger.info(f"创建Delta表: {table_name}, 分区: {partition_by}")
return table_path
def append_data(self,
data: Union[pd.DataFrame, pl.DataFrame],
table_name: str):
"""
原子性追加数据(ACID保证)
"""
table_path = os.path.join(self.storage_path, table_name)
if isinstance(data, pl.DataFrame):
arrow_table = data.to_arrow()
else:
arrow_table = pa.Table.from_pandas(data)
write_deltalake(
table_or_uri=table_path,
data=arrow_table,
mode='append'
)
logger.info(f"追加 {len(data)} 行数据到 {table_name}")
def read_table(self,
table_name: str,
version: Optional[int] = None,
timestamp: Optional[str] = None) -> pl.DataFrame:
"""
读取表数据
3.3.1 Time Travel: 通过version或timestamp读取历史版本
"""
table_path = os.path.join(self.storage_path, table_name)
dt = DeltaTable(table_path)
if version is not None:
# 按版本号读取
dt.load_as_of_version(version)
logger.info(f"Time Travel到版本: {version}")
elif timestamp is not None:
# 按时间戳读取
dt.load_as_of_timestamp(timestamp)
logger.info(f"Time Travel到时间戳: {timestamp}")
# 转换为Polars(更高效)
df = pl.from_arrow(dt.to_pyarrow_table())
return df
def get_table_history(self, table_name: str) -> List[Dict]:
"""
获取表操作历史(用于审计和回滚)
"""
table_path = os.path.join(self.storage_path, table_name)
dt = DeltaTable(table_path)
history = dt.history()
return [
{
'version': h.get('version'),
'timestamp': h.get('timestamp'),
'operation': h.get('operation'),
'operationMetrics': h.get('operationMetrics', {}),
'userName': h.get('userName', 'unknown')
}
for h in history
]
def optimize_table(self, table_name: str):
"""
表优化:文件压缩,提高查询性能
"""
table_path = os.path.join(self.storage_path, table_name)
dt = DeltaTable(table_path)
# 执行OPTIMIZE(小文件合并)
dt.optimize()
logger.info(f"优化完成: {table_name}")
def vacuum_table(self,
table_name: str,
retain_hours: int = 168, # 默认7天
dry_run: bool = True):
"""
清理旧版本文件(3.3.4 VACUUM策略)
Args:
dry_run: 如果True,只返回要删除的文件而不实际删除
"""
table_path = os.path.join(self.storage_path, table_name)
dt = DeltaTable(table_path)
if dry_run:
files = dt.vacurn(dry_run=True, retention_hours=retain_hours)
logger.info(f"[Dry Run] 将清理 {len(files)} 个旧文件")
return files
else:
dt.vacuum(retention_hours=retain_hours)
logger.info(f"已清理 {table_name} 的过期文件(保留{retain_hours}小时)")
def schema_evolution(self,
table_name: str,
new_data: pl.DataFrame,
merge_schema: bool = True):
"""
3.3.1 Schema演化:添加新列而不破坏现有数据
"""
table_path = os.path.join(self.storage_path, table_name)
# 检查当前Schema
dt = DeltaTable(table_path)
current_schema = dt.schema()
logger.info(f"当前Schema: {current_schema}")
# 写入新数据(自动合并Schema)
write_deltalake(
table_or_uri=table_path,
data=new_data.to_arrow(),
mode='append',
schema_mode='merge' if merge_schema else 'overwrite'
)
# 验证新Schema
dt.update_incremental()
new_schema = dt.schema()
logger.info(f"新Schema: {new_schema}")
return {
'old_columns': list(current_schema.names),
'new_columns': list(new_schema.names),
'added': [c for c in new_schema.names if c not in current_schema.names]
}
def time_travel_query(self,
table_name: str,
versions: List[int]) -> Dict[int, pl.DataFrame]:
"""
对比多个版本的数据(审计场景)
"""
results = {}
for version in versions:
try:
df = self.read_table(table_name, version=version)
results[version] = df
logger.info(f"版本 {version}: {len(df)} 行")
except Exception as e:
logger.error(f"无法读取版本 {version}: {e}")
return results
def get_statistics(self, table_name: str) -> Dict:
"""获取表统计信息"""
table_path = os.path.join(self.storage_path, table_name)
dt = DeltaTable(table_path)
files = dt.files()
total_size = sum(os.path.getsize(os.path.join(table_path, f)) for f in files if os.path.exists(os.path.join(table_path, f)))
return {
'table_name': table_name,
'version': dt.version(),
'num_files': len(files),
'total_size_mb': total_size / (1024 * 1024),
'columns': list(dt.schema().names),
'history_count': len(dt.history())
}
def demonstrate_delta_lake_features():
"""
Delta Lake完整功能演示
"""
print("=" * 60)
print("3.3.1 Delta Lake集成演示")
print("=" * 60)
# 创建临时存储
temp_dir = tempfile.mkdtemp(prefix="delta_demo_")
manager = DeltaLakeManager(temp_dir)
# 1. 创建初始表
print("\n--- 1. 创建初始表 ---")
initial_data = pl.DataFrame({
'id': range(1, 101),
'timestamp': [datetime(2024, 1, 1) + timedelta(hours=i) for i in range(100)],
'value': np.random.randn(100) * 100 + 50,
'category': np.random.choice(['A', 'B', 'C'], 100)
})
table_path = manager.create_table(
data=initial_data,
table_name="sensor_data",
partition_by=['category'],
mode="overwrite"
)
print(f"表创建完成: {table_path}")
stats = manager.get_statistics("sensor_data")
print(f"初始统计: {stats}")
# 2. 追加数据(ACID事务)
print("\n--- 2. ACID追加操作 ---")
append_data = pl.DataFrame({
'id': range(101, 151),
'timestamp': [datetime(2024, 1, 5) + timedelta(hours=i) for i in range(50)],
'value': np.random.randn(50) * 100 + 60,
'category': np.random.choice(['A', 'B', 'D'], 50) # 注意新类别D
})
manager.append_data(append_data, "sensor_data")
print(f"追加后统计: {manager.get_statistics('sensor_data')}")
# 3. Schema演化
print("\n--- 3. Schema演化 ---")
evolved_data = pl.DataFrame({
'id': range(151, 201),
'timestamp': [datetime(2024, 1, 10) + timedelta(hours=i) for i in range(50)],
'value': np.random.randn(50) * 100 + 70,
'category': np.random.choice(['A', 'B'], 50),
'new_column': np.random.randn(50), # 新列
'location': np.random.choice(['Beijing', 'Shanghai'], 50) # 另一个新列
})
evolution_result = manager.schema_evolution("sensor_data", evolved_data)
print(f"Schema演化结果: {evolution_result}")
# 4. Time Travel查询
print("\n--- 4. Time Travel查询 ---")
history = manager.get_table_history("sensor_data")
print(f"表历史记录数: {len(history)}")
for h in history[:3]:
print(f" Version {h['version']}: {h['operation']} at {h['timestamp']}")
# 对比版本
if len(history) >= 2:
versions = [0, 1] # 对比最初两个版本
version_data = manager.time_travel_query("sensor_data", versions)
for v, df in version_data.items():
print(f"版本 {v}: {len(df)} 行")
# 5. VACUUM演示
print("\n--- 5. VACUUM清理策略 ---")
files_to_clean = manager.vacuum_table("sensor_data", retain_hours=1, dry_run=True)
print(f"待清理文件数: {len(files_to_clean)}")
# 6. 可视化
print("\n--- 6. 生成可视化报告 ---")
visualize_delta_features(manager, "sensor_data", history)
# 清理
shutil.rmtree(temp_dir, ignore_errors=True)
print(f"\n临时数据已清理: {temp_dir}")
def visualize_delta_features(manager: DeltaLakeManager, table_name: str, history: List[Dict]):
"""可视化Delta Lake特性"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle('Delta Lake Features: ACID, Time Travel & Schema Evolution', fontsize=16, fontweight='bold')
# 1. 版本历史时间线
ax1 = axes[0, 0]
versions = [h['version'] for h in history]
timestamps = [datetime.fromisoformat(h['timestamp'].replace('Z', '+00:00')) for h in history]
operations = [h['operation'] for h in history]
colors = {'WRITE': '#4CAF50', 'OPTIMIZE': '#2196F3', 'VACUUM': '#FF9800'}
op_colors = [colors.get(op, '#9E9E9E') for op in operations]
ax1.scatter(timestamps, versions, c=op_colors, s=100, alpha=0.7)
ax1.plot(timestamps, versions, 'k--', alpha=0.3)
ax1.set_xlabel('Time')
ax1.set_ylabel('Version')
ax1.set_title('Table Version History (Time Travel)')
# 添加图例
from matplotlib.patches import Patch
legend_elements = [Patch(facecolor=c, label=op) for op, c in colors.items() if op in operations]
ax1.legend(handles=legend_elements, loc='upper left')
# 2. 文件大小分布(OPTIMIZE效果)
ax2 = axes[0, 1]
# 模拟文件大小数据
file_sizes = np.random.lognormal(3, 0.5, len(history)) # MB级别
ax2.hist(file_sizes, bins=20, color='#2E86AB', alpha=0.7, edgecolor='black')
ax2.axvline(np.mean(file_sizes), color='red', linestyle='--', label=f'Mean: {np.mean(file_sizes):.1f}MB')
ax2.set_title('Parquet File Size Distribution')
ax2.set_xlabel('Size (MB)')
ax2.legend()
# 3. Schema演化可视化
ax3 = axes[1, 0]
schema_stages = ['V0: Initial', 'V1: Append', 'V2: Evolution']
num_columns = [3, 3, 5] # id, timestamp, value -> +category -> +new_column, location
colors = ['#F44336', '#FFC107', '#4CAF50']
bars = ax3.bar(schema_stages, num_columns, color=colors)
ax3.set_title('Schema Evolution Stages')
ax3.set_ylabel('Number of Columns')
# 添加列名标注
column_labels = [
'id, timestamp,\nvalue',
'+ category',
'+ new_column,\n+ location'
]
for bar, label in zip(bars, column_labels):
height = bar.get_height()
ax3.text(bar.get_x() + bar.get_width()/2, height + 0.1,
label, ha='center', va='bottom', fontsize=9)
# 4. ACID事务流程
ax4 = axes[1, 1]
flow_text = """
Delta Lake ACID Transaction Flow:
1. BEGIN TRANSACTION
↓
2. Write Data to Parquet Files
(temporary, uncommitted)
↓
3. Write Transaction Log (_delta_log/)
• Metadata
• Add/Remove Files
• Schema Changes
↓
4. ATOMIC COMMIT
(Renaming log file)
↓
5. Cleanup & Cache Update
Guarantees:
• Atomicity: All or nothing
• Consistency: Schema validation
• Isolation: Serializable
• Durability: Persistent log
"""
ax4.text(0.05, 0.95, flow_text, transform=ax4.transAxes,
fontsize=10, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='lightgreen', alpha=0.8))
ax4.set_xlim(0, 1)
ax4.set_ylim(0, 1)
ax4.axis('off')
ax4.set_title('ACID Transaction Mechanism')
plt.tight_layout()
plt.savefig('delta_lake_features.png', dpi=150, bbox_inches='tight')
logger.info("Delta Lake可视化已保存: delta_lake_features.png")
plt.show()
if __name__ == "__main__":
demonstrate_delta_lake_features()3.3.2 medallion_architecture.py
脚本功能 :Bronze-Silver-Gold分层架构实现,数据质量逐级提升 使用方式 :python 3.3.2_medallion_architecture.py
Python
复制
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.3.2 Medallion Architecture(分层存储架构)
功能:
- Bronze层(原始数据,快速摄入)
- Silver层(清洗、去重、标准化)
- Gold层(聚合、业务视图)
- 层间数据血缘追踪
使用方式:python 3.3.2_medallion_architecture.py
"""
import os
import json
import logging
from datetime import datetime, timedelta
from typing import Dict, List, Optional, Callable
import tempfile
import shutil
import polars as pl
import pandas as pd
from deltalake import write_deltalake, DeltaTable
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class MedallionLayer:
"""分层基类"""
def __init__(self, layer_name: str, storage_path: str):
self.layer_name = layer_name
self.storage_path = os.path.join(storage_path, layer_name)
os.makedirs(self.storage_path, exist_ok=True)
def get_table_path(self, table_name: str) -> str:
return os.path.join(self.storage_path, table_name)
def write_table(self,
df: pl.DataFrame,
table_name: str,
mode: str = 'append',
partition_by: Optional[List[str]] = None):
"""写入表"""
table_path = self.get_table_path(table_name)
write_deltalake(
table_path,
df.to_arrow(),
mode=mode,
partition_by=partition_by
)
logger.info(f"[{self.layer_name}] 写入 {table_name}: {len(df)} 行")
def read_table(self, table_name: str) -> pl.DataFrame:
"""读取表"""
table_path = self.get_table_path(table_name)
dt = DeltaTable(table_path)
return pl.from_arrow(dt.to_pyarrow_table())
class BronzeLayer(MedallionLayer):
"""
Bronze层:原始数据摄入
特点:
- 保留原始格式(JSON字符串等)
- 快速追加,最小转换
- 记录摄入时间戳
"""
def __init__(self, storage_path: str):
super().__init__("bronze", storage_path)
def ingest_raw(self,
data: List[Dict],
source_name: str,
ingest_timestamp: Optional[datetime] = None):
"""
原始数据摄入
保留原始payload,添加元数据列
"""
if ingest_timestamp is None:
ingest_timestamp = datetime.utcnow()
# 构造Bronze记录
records = []
for record in data:
records.append({
'_ingestion_timestamp': ingest_timestamp,
'_source': source_name,
'_raw_payload': json.dumps(record), # 保留原始JSON
'_ingestion_date': ingest_timestamp.strftime('%Y-%m-%d'),
# 可选:提取关键字段用于分区
'event_type': record.get('event_type', 'unknown')
})
df = pl.DataFrame(records)
self.write_table(
df,
f"{source_name}_raw",
mode='append',
partition_by=['_ingestion_date']
)
return len(records)
class SilverLayer(MedallionLayer):
"""
Silver层:清洗与标准化
处理逻辑:
- Schema验证与强制转换
- 去重(基于业务键)
- 空值处理
- 数据标准化
"""
def __init__(self, storage_path: str):
super().__init__("silver", storage_path)
self.quality_metrics = []
def cleanse_bronze(self,
bronze_df: pl.DataFrame,
target_table: str,
schema: Dict[str, pl.DataType],
dedup_keys: List[str] = None,
validation_rules: Optional[Callable] = None):
"""
Bronze -> Silver 转换
"""
logger.info(f"[Silver] 开始清洗: {len(bronze_df)} 行")
# 1. 解析JSON payload
parsed_data = []
for row in bronze_df.iter_rows(named=True):
try:
payload = json.loads(row['_raw_payload'])
payload['_ingestion_timestamp'] = row['_ingestion_timestamp']
payload['_source'] = row['_source']
parsed_data.append(payload)
except Exception as e:
logger.warning(f"JSON解析失败,跳过: {e}")
if not parsed_data:
logger.warning("无有效数据可清洗")
return
df = pl.DataFrame(parsed_data)
# 2. Schema强制转换与验证
for col, dtype in schema.items():
if col in df.columns:
try:
df = df.with_columns(pl.col(col).cast(dtype))
except Exception as e:
logger.error(f"列 {col} 转换失败: {e}")
# 填充null
df = df.with_columns(pl.lit(None).cast(dtype).alias(col))
else:
# 缺失列填充null
df = df.with_columns(pl.lit(None).cast(dtype).alias(col))
# 3. 去重(保留最新)
if dedup_keys:
original_count = len(df)
df = df.sort('_ingestion_timestamp', descending=True)
df = df.unique(subset=dedup_keys, keep='first')
deduped_count = len(df)
logger.info(f"[Silver] 去重: {original_count} -> {deduped_count}")
# 4. 空值处理(业务规则)
df = df.with_columns([
pl.col('value').fill_null(strategy='zero') if 'value' in df.columns else pl.lit(0).alias('value')
])
# 5. 数据质量检查
quality_score = self._calculate_quality_score(df)
self.quality_metrics.append({
'timestamp': datetime.utcnow(),
'table': target_table,
'input_rows': len(bronze_df),
'output_rows': len(df),
'quality_score': quality_score,
'null_percentage': df.null_count().sum() / (len(df) * len(df.columns)) * 100
})
# 写入Silver
self.write_table(df, target_table, mode='overwrite')
return df
def _calculate_quality_score(self, df: pl.DataFrame) -> float:
"""计算数据质量分数"""
total_cells = len(df) * len(df.columns)
null_cells = df.null_count().sum()
return (1 - null_cells / total_cells) * 100
class GoldLayer(MedallionLayer):
"""
Gold层:业务聚合与视图
特点:
- 星型/雪花模型
- 预聚合指标
- 权限视图
"""
def __init__(self, storage_path: str):
super().__init__("gold", storage_path)
def create_aggregated_view(self,
silver_df: pl.DataFrame,
target_table: str,
dimensions: List[str],
metrics: List[str],
time_grain: str = 'hour'):
"""
创建聚合视图
Args:
time_grain: hour/day/month
"""
logger.info(f"[Gold] 创建聚合视图: {target_table}")
# 时间截断
if time_grain == 'hour':
time_col = pl.col('timestamp').dt.truncate('1h').alias('time_bucket')
elif time_grain == 'day':
time_col = pl.col('timestamp').dt.truncate('1d').alias('time_bucket')
else:
time_col = pl.col('timestamp').dt.truncate('1mo').alias('time_bucket')
# 构造聚合
agg_exprs = []
for metric in metrics:
agg_exprs.extend([
pl.col(metric).sum().alias(f'{metric}_sum'),
pl.col(metric).mean().alias(f'{metric}_avg'),
pl.col(metric).max().alias(f'{metric}_max')
])
grouped = silver_df.with_columns([time_col]).groupby(
['time_bucket'] + dimensions
).agg(agg_exprs)
self.write_table(grouped, target_table, mode='overwrite')
return grouped
def create_customer_360(self,
transactions: pl.DataFrame,
customers: pl.DataFrame,
target_table: str = "customer_360"):
"""
客户360视图(Join示例)
"""
# 计算客户指标
customer_metrics = transactions.groupby('customer_id').agg([
pl.col('amount').sum().alias('total_spend'),
pl.col('amount').count().alias('transaction_count'),
pl.col('timestamp').max().alias('last_purchase')
])
# Join客户维度
customer_360 = customers.join(
customer_metrics,
on='customer_id',
how='left'
).with_columns([
pl.col('total_spend').fill_null(0),
pl.col('transaction_count').fill_null(0)
])
self.write_table(customer_360, target_table, mode='overwrite')
return customer_360
class MedallionPipeline:
"""
Medallion架构管道编排器
"""
def __init__(self, storage_path: str):
self.storage_path = storage_path
self.bronze = BronzeLayer(storage_path)
self.silver = SilverLayer(storage_path)
self.gold = GoldLayer(storage_path)
self.lineage = []
def run_batch_pipeline(self,
raw_data: List[Dict],
source_name: str,
silver_schema: Dict,
gold_dimensions: List[str],
gold_metrics: List[str]):
"""
执行完整的Bronze->Silver->Gold流程
"""
start_time = datetime.utcnow()
# 1. Bronze层:原始摄入
logger.info("=" * 60)
logger.info("阶段 1: Bronze Layer - Raw Ingestion")
logger.info("=" * 60)
bronze_count = self.bronze.ingest_raw(raw_data, source_name)
self.lineage.append({
'stage': 'bronze',
'source': source_name,
'records': bronze_count,
'timestamp': datetime.utcnow()
})
# 读取刚写入的数据
bronze_df = self.bronze.read_table(f"{source_name}_raw")
# 2. Silver层:清洗
logger.info("\n" + "=" * 60)
logger.info("阶段 2: Silver Layer - Cleansing")
logger.info("=" * 60)
silver_df = self.silver.cleanse_bronze(
bronze_df,
target_table=f"{source_name}_cleaned",
schema=silver_schema,
dedup_keys=['event_id']
)
self.lineage.append({
'stage': 'silver',
'source': f"{source_name}_raw",
'records': len(silver_df),
'timestamp': datetime.utcnow()
})
# 3. Gold层:聚合
logger.info("\n" + "=" * 60)
logger.info("阶段 3: Gold Layer - Aggregation")
logger.info("=" * 60)
gold_df = self.gold.create_aggregated_view(
silver_df,
target_table=f"{source_name}_metrics",
dimensions=gold_dimensions,
metrics=gold_metrics,
time_grain='hour'
)
self.lineage.append({
'stage': 'gold',
'source': f"{source_name}_cleaned",
'records': len(gold_df),
'timestamp': datetime.utcnow()
})
# 计算耗时
duration = (datetime.utcnow() - start_time).total_seconds()
logger.info(f"\n{'='*60}")
logger.info("管道执行完成")
logger.info(f"总耗时: {duration:.2f}秒")
logger.info(f"Bronze: {bronze_count} 行")
logger.info(f"Silver: {len(silver_df)} 行")
logger.info(f"Gold: {len(gold_df)} 行")
logger.info(f"{'='*60}")
return {
'bronze_count': bronze_count,
'silver_count': len(silver_df),
'gold_count': len(gold_df),
'duration_seconds': duration,
'quality_score': self.silver.quality_metrics[-1] if self.silver.quality_metrics else None
}
def visualize_architecture(self, output_file: str = "medallion_architecture.png"):
"""可视化Medallion架构"""
fig, ax = plt.subplots(figsize=(14, 10))
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.axis('off')
# 标题
ax.text(5, 9.5, 'Medallion Architecture Data Flow',
ha='center', fontsize=18, fontweight='bold')
# 三层结构
layers = [
{
'name': 'Bronze (Raw)',
'y': 7,
'color': '#CD7F32', # Bronze color
'features': [
'• Raw Ingestion (JSON, CSV, Logs)',
'• Minimal Transformation',
'• Full Data Retention',
'• Source System Timestamps'
]
},
{
'name': 'Silver (Cleansed)',
'y': 4.5,
'color': '#C0C0C0', # Silver color
'features': [
'• Schema Enforcement',
'• Deduplication',
'• Null Handling',
'• Data Quality Scoring'
]
},
{
'name': 'Gold (Aggregated)',
'y': 2,
'color': '#FFD700', # Gold color
'features': [
'• Business Aggregations',
'• Star/Snowflake Schema',
'• Pre-computed Metrics',
'• Consumer-Ready Views'
]
}
]
# 绘制层
for layer in layers:
# 主框
rect = FancyBboxPatch((1, layer['y']-0.8), 8, 1.5,
boxstyle="round,pad=0.1",
facecolor=layer['color'],
edgecolor='black',
alpha=0.8)
ax.add_patch(rect)
# 层名
ax.text(5, layer['y'] + 0.3, layer['name'],
ha='center', fontsize=14, fontweight='bold')
# 特性列表
features_text = '\n'.join(layer['features'])
ax.text(5, layer['y'] - 0.2, features_text,
ha='center', fontsize=9, family='monospace')
# 箭头
arrow1 = FancyArrowPatch((5, 6.2), (5, 5.3),
arrowstyle='->', mutation_scale=30,
linewidth=3, color='black')
arrow2 = FancyArrowPatch((5, 3.7), (5, 2.8),
arrowstyle='->', mutation_scale=30,
linewidth=3, color='black')
ax.add_patch(arrow1)
ax.add_patch(arrow2)
# 标注转换过程
conversions = [
(5, 5.75, 'ETL/Stream Processing'),
(5, 3.25, 'Aggregation & Modeling')
]
for x, y, text in conversions:
ax.text(x, y, text, ha='center', fontsize=10,
bbox=dict(boxstyle='round', facecolor='white', alpha=0.9))
# 质量指标(如果有)
if self.silver.quality_metrics:
latest = self.silver.quality_metrics[-1]
quality_text = f"""
Latest Quality Metrics:
Table: {latest['table']}
Quality Score: {latest['quality_score']:.1f}%
Null %: {latest['null_percentage']:.2f}%
"""
ax.text(5, 0.5, quality_text, ha='center', fontsize=10,
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.8))
plt.tight_layout()
plt.savefig(output_file, dpi=150, bbox_inches='tight')
logger.info(f"架构图已保存: {output_file}")
plt.show()
def demonstrate_medallion():
"""演示Medallion架构"""
print("=" * 60)
print("3.3.2 Medallion Architecture 演示")
print("=" * 60)
# 创建临时存储
temp_dir = tempfile.mkdtemp(prefix="medallion_demo_")
pipeline = MedallionPipeline(temp_dir)
# 生成模拟数据
print("\n生成模拟交易数据...")
import random
raw_data = []
base_time = datetime(2024, 1, 1, 12, 0, 0)
for i in range(1000):
# 模拟一些重复数据(用于测试去重)
event_id = f"evt_{i % 950}" # 约5%重复
raw_data.append({
'event_id': event_id,
'timestamp': (base_time + timedelta(minutes=i)).isoformat(),
'customer_id': f"cust_{random.randint(1, 100)}",
'amount': round(random.uniform(10, 500), 2),
'product_category': random.choice(['Electronics', 'Clothing', 'Food', 'Books']),
'payment_method': random.choice(['Credit', 'Debit', 'Cash']),
'store_id': f"store_{random.randint(1, 10)}"
})
# 定义Silver层Schema
silver_schema = {
'event_id': pl.Utf8,
'timestamp': pl.Datetime,
'customer_id': pl.Utf8,
'amount': pl.Float64,
'product_category': pl.Categorical,
'payment_method': pl.Categorical,
'store_id': pl.Utf8
}
# 执行管道
result = pipeline.run_batch_pipeline(
raw_data=raw_data,
source_name="sales_transactions",
silver_schema=silver_schema,
gold_dimensions=['product_category', 'payment_method', 'store_id'],
gold_metrics=['amount']
)
# 验证Gold层数据
print("\n验证Gold层聚合结果(前5行):")
gold_df = pipeline.gold.read_table("sales_transactions_metrics")
print(gold_df.head())
# 可视化
pipeline.visualize_architecture()
# 清理
shutil.rmtree(temp_dir, ignore_errors=True)
print(f"\n临时目录已清理: {temp_dir}")
if __name__ == "__main__":
demonstrate_medallion()3.3.3 partition_strategy.py
脚本功能 :分区策略实现,对比日期分区与业务维度分区的性能差异 使用方式 :python 3.3.3_partition_strategy.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.3.3 分区策略设计与权衡
功能:
- 日期分区(时间序列优化)
- 业务维度分区(查询裁剪)
- 混合分区策略
- 分区修剪效果对比
使用方式:python 3.3.3_partition_strategy.py
"""
import os
import time
import logging
from datetime import datetime, timedelta
from typing import List, Dict, Optional, Callable
import tempfile
import shutil
import polars as pl
import pandas as pd
import numpy as np
from deltalake import write_deltalake, DeltaTable
import matplotlib.pyplot as plt
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class PartitionStrategy:
"""分区策略基类"""
def __init__(self, name: str):
self.name = name
def get_partition_cols(self) -> List[str]:
raise NotImplementedError
def get_partition_values(self, record: Dict) -> Dict[str, str]:
raise NotImplementedError
class DatePartitionStrategy(PartitionStrategy):
"""
日期分区策略
适用:时间序列数据,按时间范围查询
"""
def __init__(self,
timestamp_col: str = 'timestamp',
grain: str = 'day'): # hour/day/month/year
super().__init__(f"date_{grain}")
self.timestamp_col = timestamp_col
self.grain = grain
def get_partition_cols(self) -> List[str]:
return [f"partition_{self.grain}"]
def get_partition_values(self, record: Dict) -> Dict[str, str]:
ts = record.get(self.timestamp_col)
if isinstance(ts, str):
ts = datetime.fromisoformat(ts.replace('Z', '+00:00'))
if self.grain == 'hour':
val = ts.strftime('%Y-%m-%d-%H')
elif self.grain == 'day':
val = ts.strftime('%Y-%m-%d')
elif self.grain == 'month':
val = ts.strftime('%Y-%m')
else:
val = ts.strftime('%Y')
return {f"partition_{self.grain}": val}
class BusinessDimensionStrategy(PartitionStrategy):
"""
业务维度分区
适用:按业务实体查询(如customer_id, region)
"""
def __init__(self, dimension_cols: List[str],
hash_buckets: Optional[int] = None):
super().__init__(f"biz_dim_{'_'.join(dimension_cols)}")
self.dimension_cols = dimension_cols
self.hash_buckets = hash_buckets
def get_partition_cols(self) -> List[str]:
if self.hash_buckets:
return [f"{col}_bucket" for col in self.dimension_cols]
return self.dimension_cols
def get_partition_values(self, record: Dict) -> Dict[str, str]:
result = {}
for col in self.dimension_cols:
val = str(record.get(col, 'unknown'))
if self.hash_buckets:
# 哈希分区避免数据倾斜
bucket = hash(val) % self.hash_buckets
result[f"{col}_bucket"] = f"bucket_{bucket:04d}"
else:
result[col] = val
return result
class HybridPartitionStrategy(PartitionStrategy):
"""
混合分区:日期 + 业务维度
适用:大型数据集,需要双重过滤
"""
def __init__(self,
date_col: str = 'timestamp',
date_grain: str = 'month',
dimension_cols: List[str] = None):
super().__init__(f"hybrid_{date_grain}_{'_'.join(dimension_cols or [])}")
self.date_strategy = DatePartitionStrategy(date_col, date_grain)
self.dimension_strategy = BusinessDimensionStrategy(dimension_cols or []) if dimension_cols else None
def get_partition_cols(self) -> List[str]:
cols = self.date_strategy.get_partition_cols()
if self.dimension_strategy:
cols.extend(self.dimension_strategy.get_partition_cols())
return cols
def get_partition_values(self, record: Dict) -> Dict[str, str]:
result = self.date_strategy.get_partition_values(record)
if self.dimension_strategy:
result.update(self.dimension_strategy.get_partition_values(record))
return result
class PartitionedTable:
"""
分区表管理
"""
def __init__(self,
table_name: str,
storage_path: str,
strategy: PartitionStrategy):
self.table_name = table_name
self.table_path = os.path.join(storage_path, table_name)
self.strategy = strategy
self.partition_cols = strategy.get_partition_cols()
os.makedirs(self.table_path, exist_ok=True)
def write_batch(self, df: pl.DataFrame, mode: str = 'append'):
"""写入批次数据"""
# 生成分区列
records = df.to_dicts()
partition_data = []
for record in records:
partition_values = self.strategy.get_partition_values(record)
partition_data.append({**record, **partition_values})
partition_df = pl.DataFrame(partition_data)
# 写入Delta(自动分区)
write_deltalake(
self.table_path,
partition_df.to_arrow(),
mode=mode,
partition_by=self.partition_cols
)
logger.info(f"[{self.table_name}] 写入 {len(df)} 行,分区: {self.partition_cols}")
def read_with_pruning(self,
filters: Optional[Dict] = None,
columns: Optional[List[str]] = None) -> pl.DataFrame:
"""
带分区修剪的读取
只读取匹配的分区,减少IO
"""
dt = DeltaTable(self.table_path)
# 构造分区过滤器
partition_filters = []
if filters:
for col, val in filters.items():
if col in self.partition_cols:
partition_filters.append((col, '=', val))
# 读取(利用分区修剪)
if partition_filters:
# Delta Lake分区过滤
df = pl.from_arrow(dt.to_pyarrow_table(
partitions=partition_filters,
columns=columns
))
else:
df = pl.from_arrow(dt.to_pyarrow_table(columns=columns))
return df
def get_partition_stats(self) -> Dict:
"""获取分区统计"""
partitions = []
# 遍历分区目录
for root, dirs, files in os.walk(self.table_path):
if 'part-' in ''.join(files): # 是数据目录
partition_info = {}
for part in self.partition_cols:
if part in root:
# 提取分区值
idx = root.find(part)
if idx != -1:
val_start = root.find('=', idx) + 1
val_end = root.find('/', val_start)
if val_end == -1:
val_end = len(root)
partition_info[part] = root[val_start:val_end]
if partition_info:
# 计算文件大小
total_size = sum(
os.path.getsize(os.path.join(root, f))
for f in files if f.endswith('.parquet')
)
partition_info['size_mb'] = total_size / (1024 * 1024)
partition_info['file_count'] = len([f for f in files if f.endswith('.parquet')])
partitions.append(partition_info)
return {
'partition_cols': self.partition_cols,
'total_partitions': len(partitions),
'partitions': partitions[:10], # 只显示前10个
'total_size_mb': sum(p['size_mb'] for p in partitions)
}
class PartitionBenchmark:
"""
分区策略性能基准测试
"""
def __init__(self, storage_path: str):
self.storage_path = storage_path
self.results = []
def generate_test_data(self,
num_records: int,
num_customers: int = 1000) -> pl.DataFrame:
"""生成测试数据"""
base_time = datetime(2024, 1, 1)
data = {
'timestamp': [base_time + timedelta(hours=i % 720) for i in range(num_records)], # 30天
'customer_id': [f"cust_{i % num_customers}" for i in range(num_records)],
'transaction_id': [f"txn_{i}" for i in range(num_records)],
'amount': np.random.randn(num_records) * 100 + 500,
'region': np.random.choice(['North', 'South', 'East', 'West'], num_records),
'category': np.random.choice(['A', 'B', 'C', 'D'], num_records)
}
return pl.DataFrame(data)
def benchmark_strategy(self,
strategy: PartitionStrategy,
data: pl.DataFrame,
query_filters: List[Dict]):
"""
测试特定分区策略的写入和查询性能
"""
table_name = f"test_{strategy.name}"
table = PartitionedTable(table_name, self.storage_path, strategy)
# 1. 写入性能
write_start = time.time()
table.write_batch(data, mode='overwrite')
write_time = time.time() - write_start
# 2. 查询性能(带分区修剪)
read_times = []
for filters in query_filters:
read_start = time.time()
result = table.read_with_pruning(filters=filters)
read_time = time.time() - read_start
read_times.append({
'filters': filters,
'time_ms': read_time * 1000,
'rows_returned': len(result)
})
# 3. 全表扫描性能(对比)
full_scan_start = time.time()
full_result = table.read_with_pruning()
full_scan_time = time.time() - full_scan_start
stats = table.get_partition_stats()
return {
'strategy': strategy.name,
'write_time_sec': write_time,
'partition_stats': stats,
'pruned_queries': read_times,
'full_scan_time_ms': full_scan_time * 1000,
'partition_efficiency': (1 - np.mean([r['time_ms'] for r in read_times]) / (full_scan_time * 1000)) * 100
}
def run_comparison(self, data_sizes: List[int] = [10000, 100000]):
"""
运行对比测试
"""
strategies = [
DatePartitionStrategy('timestamp', 'day'),
DatePartitionStrategy('timestamp', 'hour'),
BusinessDimensionStrategy(['region'], hash_buckets=4),
BusinessDimensionStrategy(['customer_id'], hash_buckets=16),
HybridPartitionStrategy('timestamp', 'month', ['region'])
]
query_scenarios = [
{'partition_day': '2024-01-15'}, # 日期查询
{'region_bucket': 'bucket_0001'}, # 区域查询
{'partition_month': '2024-01', 'region_bucket': 'bucket_0002'} # 混合查询
]
for size in data_sizes:
print(f"\n{'='*60}")
print(f"测试数据量: {size} 行")
print(f"{'='*60}")
data = self.generate_test_data(size)
for strategy in strategies:
print(f"\n测试策略: {strategy.name}")
try:
result = self.benchmark_strategy(strategy, data, query_scenarios)
self.results.append(result)
print(f" 写入时间: {result['write_time_sec']:.2f}s")
print(f" 分区数: {result['partition_stats']['total_partitions']}")
print(f" 平均剪枝查询: {np.mean([r['time_ms'] for r in result['pruned_queries']]):.2f}ms")
print(f" 全表扫描: {result['full_scan_time_ms']:.2f}ms")
print(f" 剪枝效率: {result['partition_efficiency']:.1f}%")
except Exception as e:
logger.error(f"策略 {strategy.name} 测试失败: {e}")
self._visualize_results()
def _visualize_results(self):
"""可视化对比结果"""
if not self.results:
return
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle('Partition Strategy Comparison', fontsize=16, fontweight='bold')
# 1. 写入性能对比
ax1 = axes[0, 0]
strategies = [r['strategy'] for r in self.results]
write_times = [r['write_time_sec'] for r in self.results]
bars = ax1.barh(strategies, write_times, color='#2E86AB')
ax1.set_xlabel('Write Time (seconds)')
ax1.set_title('Write Performance by Strategy')
for i, (bar, val) in enumerate(zip(bars, write_times)):
ax1.text(val + 0.1, bar.get_y() + bar.get_height()/2,
f'{val:.2f}s', va='center')
# 2. 查询性能(剪枝 vs 全表扫描)
ax2 = axes[0, 1]
pruned_times = [np.mean([q['time_ms'] for q in r['pruned_queries']]) for r in self.results]
full_times = [r['full_scan_time_ms'] for r in self.results]
x = np.arange(len(strategies))
width = 0.35
bars1 = ax2.bar(x - width/2, pruned_times, width, label='Partition Pruned', color='#4CAF50')
bars2 = ax2.bar(x + width/2, full_times, width, label='Full Scan', color='#F44336')
ax2.set_ylabel('Time (ms)')
ax2.set_title('Query Performance: Pruned vs Full Scan')
ax2.set_xticks(x)
ax2.set_xticklabels(strategies, rotation=45, ha='right')
ax2.legend()
# 3. 分区效率提升百分比
ax3 = axes[1, 0]
efficiencies = [r['partition_efficiency'] for r in self.results]
colors = ['#4CAF50' if e > 80 else '#FFC107' if e > 50 else '#F44336' for e in efficiencies]
bars = ax3.bar(strategies, efficiencies, color=colors)
ax3.set_ylabel('Efficiency %')
ax3.set_title('Partition Pruning Efficiency')
ax3.set_ylim(0, 100)
ax3.tick_params(axis='x', rotation=45)
for bar, val in zip(bars, efficiencies):
ax3.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 1,
f'{val:.0f}%', ha='center', va='bottom')
# 4. 分区数量分布
ax4 = axes[1, 1]
num_partitions = [r['partition_stats']['total_partitions'] for r in self.results]
total_sizes = [r['partition_stats']['total_size_mb'] for r in self.results]
scatter = ax4.scatter(num_partitions, total_sizes,
s=200, c=range(len(strategies)), cmap='viridis', alpha=0.7)
ax4.set_xlabel('Number of Partitions')
ax4.set_ylabel('Total Size (MB)')
ax4.set_title('Partition Count vs Storage Size')
# 添加标签
for i, strategy in enumerate(strategies):
ax4.annotate(strategy, (num_partitions[i], total_sizes[i]),
xytext=(5, 5), textcoords='offset points', fontsize=8)
plt.tight_layout()
plt.savefig('partition_strategy_comparison.png', dpi=150, bbox_inches='tight')
logger.info("分区策略对比图已保存: partition_strategy_comparison.png")
plt.show()
def demonstrate_partition_pruning():
"""演示分区修剪效果"""
print("=" * 60)
print("3.3.3 分区策略与修剪演示")
print("=" * 60)
temp_dir = tempfile.mkdtemp(prefix="partition_demo_")
# 创建分区表
strategy = HybridPartitionStrategy(
date_col='timestamp',
date_grain='day',
dimension_cols=['region']
)
table = PartitionedTable(
table_name="sales_data",
storage_path=temp_dir,
strategy=strategy
)
# 生成30天数据
data = []
base_time = datetime(2024, 1, 1)
regions = ['North', 'South', 'East', 'West']
for day in range(30):
for region in regions:
for _ in range(100): # 每天每区域100条
data.append({
'timestamp': base_time + timedelta(days=day, hours=12),
'region': region,
'amount': float(np.random.randint(100, 1000)),
'product': f"Product_{np.random.randint(1, 50)}"
})
df = pl.DataFrame(data)
table.write_batch(df)
# 对比查询
print("\n--- 查询性能对比 ---")
# 1. 全表扫描
start = time.time()
full_data = table.read_with_pruning()
full_time = time.time() - start
print(f"全表扫描: {len(full_data)} 行, {full_time*1000:.2f} ms")
# 2. 日期修剪
start = time.time()
day_data = table.read_with_pruning(filters={'partition_day': '2024-01-15'})
day_time = time.time() - start
print(f"日期修剪 (2024-01-15): {len(day_data)} 行, {day_time*1000:.2f} ms")
# 3. 区域修剪
start = time.time()
region_data = table.read_with_pruning(filters={'region_bucket': 'bucket_0001'}) # North
region_time = time.time() - start
print(f"区域修剪 (North): {len(region_data)} 行, {region_time*1000:.2f} ms")
# 4. 混合修剪
start = time.time()
mixed_data = table.read_with_pruning(filters={
'partition_day': '2024-01-15',
'region_bucket': 'bucket_0001'
})
mixed_time = time.time() - start
print(f"混合修剪 (Day+Region): {len(mixed_data)} 行, {mixed_time*1000:.2f} ms")
# 显示统计
stats = table.get_partition_stats()
print(f"\n分区统计:")
print(f" 总分区数: {stats['total_partitions']}")
print(f" 总大小: {stats['total_size_mb']:.2f} MB")
# 清理
shutil.rmtree(temp_dir, ignore_errors=True)
if __name__ == "__main__":
# 1. 演示基本分区
demonstrate_partition_pruning()
# 2. 运行性能基准(可选,耗时较长)
print("\n" + "=" * 60)
print("运行分区策略性能基准测试...")
print("=" * 60)
temp_dir = tempfile.mkdtemp(prefix="partition_benchmark_")
benchmark = PartitionBenchmark(temp_dir)
benchmark.run_comparison(data_sizes=[50000])
shutil.rmtree(temp_dir, ignore_errors=True)3.3.4 metadata_management.py
脚本功能 :Delta表版本清理、VACUUM策略、元数据管理 使用方式 :python 3.3.4_metadata_management.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.3.4 元数据管理与VACUUM策略
功能:
- Delta表版本历史管理
- VACUUM自动清理配置
- 元数据压缩与归档
- 存储成本分析
使用方式:python 3.3.4_metadata_management.py
"""
import os
import json
import time
import logging
from datetime import datetime, timedelta
from typing import Dict, List, Optional
import tempfile
import shutil
from deltalake import DeltaTable, write_deltalake
import polars as pl
import matplotlib.pyplot as plt
import numpy as np
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class MetadataManager:
"""
Delta Lake元数据管理器
"""
def __init__(self, storage_path: str):
self.storage_path = storage_path
def get_table_metadata(self, table_name: str) -> Dict:
"""获取表完整元数据"""
table_path = os.path.join(self.storage_path, table_name)
dt = DeltaTable(table_path)
# 基础信息
metadata = {
'table_name': table_name,
'path': table_path,
'version': dt.version(),
'metadata': {
'id': dt.metadata().id,
'name': dt.metadata().name,
'description': dt.metadata().description,
'format': {
'provider': dt.metadata().format.provider,
'options': dt.metadata().format.options
},
'schema': str(dt.schema()),
'partition_columns': dt.metadata().partition_columns,
'configuration': dt.metadata().configuration,
'created_time': dt.metadata().created_time
},
'files': self._get_file_stats(table_path),
'history': self._analyze_history(dt),
'size_metrics': self._calculate_size_metrics(table_path)
}
return metadata
def _get_file_stats(self, table_path: str) -> Dict:
"""获取文件统计"""
data_files = []
log_files = []
for root, dirs, files in os.walk(table_path):
for file in files:
file_path = os.path.join(root, file)
size = os.path.getsize(file_path)
mtime = datetime.fromtimestamp(os.path.getmtime(file_path))
if 'delta_log' in root:
log_files.append({
'name': file,
'size_bytes': size,
'modified': mtime
})
elif file.endswith('.parquet'):
data_files.append({
'name': file,
'size_bytes': size,
'modified': mtime
})
return {
'data_files_count': len(data_files),
'log_files_count': len(log_files),
'data_files_size_mb': sum(f['size_bytes'] for f in data_files) / (1024 * 1024),
'log_files_size_mb': sum(f['size_bytes'] for f in log_files) / (1024 * 1024),
'avg_file_size_mb': (sum(f['size_bytes'] for f in data_files) / len(data_files)) / (1024 * 1024) if data_files else 0
}
def _analyze_history(self, dt: DeltaTable) -> Dict:
"""分析历史记录"""
history = dt.history()
operations = {}
for h in history:
op = h.get('operation', 'UNKNOWN')
operations[op] = operations.get(op, 0) + 1
# 时间范围
timestamps = [h.get('timestamp') for h in history if h.get('timestamp')]
if timestamps:
time_range = {
'earliest': min(timestamps),
'latest': max(timestamps),
'span_days': (datetime.fromisoformat(max(timestamps).replace('Z', '+00:00')) -
datetime.fromisoformat(min(timestamps).replace('Z', '+00:00'))).days
}
else:
time_range = None
return {
'total_versions': len(history),
'operations_breakdown': operations,
'time_range': time_range,
'recent_versions': history[:5]
}
def _calculate_size_metrics(self, table_path: str) -> Dict:
"""计算存储指标"""
total_size = 0
file_count = 0
for dirpath, dirnames, filenames in os.walk(table_path):
for f in filenames:
fp = os.path.join(dirpath, f)
if os.path.exists(fp):
total_size += os.path.getsize(fp)
file_count += 1
# 估算压缩潜力(假设Parquet压缩率)
raw_estimate = total_size * 5 # 典型压缩比5:1
return {
'total_storage_mb': total_size / (1024 * 1024),
'total_files': file_count,
'estimated_raw_size_mb': raw_estimate / (1024 * 1024),
'compression_ratio': 5.0
}
def configure_retention(self,
table_name: str,
log_retention_hours: int = 168, # 7天
deleted_file_retention_hours: int = 168):
"""
配置Delta表保留策略
"""
table_path = os.path.join(self.storage_path, table_name)
dt = DeltaTable(table_path)
# 设置表属性
properties = {
'delta.logRetentionDuration': f'interval {log_retention_hours} hours',
'delta.deletedFileRetentionDuration': f'interval {deleted_file_retention_hours} hours'
}
# 使用ALTER TABLE(通过底层API或直接修改)
logger.info(f"配置 {table_name} 保留策略:")
logger.info(f" 日志保留: {log_retention_hours} 小时")
logger.info(f" 删除文件保留: {deleted_file_retention_hours} 小时")
return properties
def vacuum_table(self,
table_name: str,
retain_hours: Optional[int] = None,
dry_run: bool = True) -> List[str]:
"""
执行VACUUM清理
Returns:
被删除(或将要删除)的文件列表
"""
table_path = os.path.join(self.storage_path, table_name)
dt = DeltaTable(table_path)
if retain_hours is None:
# 从表配置读取,默认7天
retain_hours = 168
if dry_run:
# 只返回将要删除的文件,不实际删除
files = dt.vacuum(dry_run=True, retention_hours=retain_hours)
logger.info(f"[Dry Run] {table_name}: 将清理 {len(files)} 个文件")
return files
else:
# 实际执行清理
files = dt.vacuum(retention_hours=retain_hours)
logger.info(f"[VACUUM] {table_name}: 已清理 {len(files)} 个文件")
return files
def archive_old_versions(self,
table_name: str,
older_than_days: int = 30,
archive_path: Optional[str] = None):
"""
归档旧版本(冷数据分层)
"""
if archive_path is None:
archive_path = os.path.join(self.storage_path, "archive")
os.makedirs(archive_path, exist_ok=True)
table_path = os.path.join(self.storage_path, table_name)
# 分析历史,找出旧版本
dt = DeltaTable(table_path)
history = dt.history()
cutoff_date = datetime.now() - timedelta(days=older_than_days)
old_versions = []
for h in history:
ts = h.get('timestamp')
if ts:
version_time = datetime.fromisoformat(ts.replace('Z', '+00:00'))
if version_time < cutoff_date:
old_versions.append({
'version': h.get('version'),
'timestamp': ts
})
logger.info(f"发现 {len(old_versions)} 个旧版本(>{older_than_days}天)")
# 在实际场景中,这里会将旧数据文件移动到冷存储
# 简化版:记录归档清单
archive_manifest = {
'table_name': table_name,
'archived_at': datetime.now().isoformat(),
'cutoff_date': cutoff_date.isoformat(),
'versions': old_versions
}
manifest_path = os.path.join(archive_path, f"{table_name}_archive_{datetime.now().strftime('%Y%m%d')}.json")
with open(manifest_path, 'w') as f:
json.dump(archive_manifest, f, indent=2)
logger.info(f"归档清单已保存: {manifest_path}")
return archive_manifest
def generate_storage_report(self) -> Dict:
"""生成全库存储报告"""
tables = []
total_storage = 0
for item in os.listdir(self.storage_path):
item_path = os.path.join(self.storage_path, item)
if os.path.isdir(item_path) and os.path.exists(os.path.join(item_path, '_delta_log')):
try:
meta = self.get_table_metadata(item)
tables.append(meta)
total_storage += meta['size_metrics']['total_storage_mb']
except Exception as e:
logger.error(f"读取 {item} 元数据失败: {e}")
# 生成成本估算(假设$0.023/GB/月,S3标准存储)
monthly_cost = (total_storage / 1024) * 0.023
report = {
'generated_at': datetime.now().isoformat(),
'summary': {
'total_tables': len(tables),
'total_storage_mb': total_storage,
'total_storage_gb': total_storage / 1024,
'estimated_monthly_cost_usd': monthly_cost
},
'tables': tables,
'recommendations': self._generate_recommendations(tables)
}
return report
def _generate_recommendations(self, tables: List[Dict]) -> List[str]:
"""生成优化建议"""
recommendations = []
for table in tables:
name = table['table_name']
files = table['files']
history = table['history']
# 小文件过多
if files['data_files_count'] > 100 and files['avg_file_size_mb'] < 10:
recommendations.append(
f"{name}: 小文件过多({files['data_files_count']}个,平均{files['avg_file_size_mb']:.1f}MB),建议执行OPTIMIZE"
)
# 版本历史过长
if history['total_versions'] > 100:
recommendations.append(
f"{name}: 版本历史过长({history['total_versions']}个),建议配置VACUUM保留期"
)
# 日志文件过大
if files['log_files_size_mb'] > 50:
recommendations.append(
f"{name}: 日志文件占用{files['log_files_size_mb']:.1f}MB,建议检查是否有过多的小事务"
)
return recommendations
def demonstrate_metadata_management():
"""演示元数据管理"""
print("=" * 60)
print("3.3.4 元数据管理与VACUUM策略")
print("=" * 60)
temp_dir = tempfile.mkdtemp(prefix="metadata_demo_")
manager = MetadataManager(temp_dir)
# 创建测试表并生成多个版本
print("\n--- 创建测试表并生成版本历史 ---")
table_name = "sales_data"
table_path = os.path.join(temp_dir, table_name)
# 版本1: 初始数据
df1 = pl.DataFrame({
'id': range(1000),
'date': [datetime(2024, 1, 1) + timedelta(days=i % 30) for i in range(1000)],
'amount': np.random.randn(1000) * 100 + 500
})
write_deltalake(table_path, df1.to_arrow(), mode='overwrite')
print("版本1: 初始1000行")
time.sleep(1)
# 版本2: 追加数据
df2 = pl.DataFrame({
'id': range(1000, 1500),
'date': [datetime(2024, 2, 1) + timedelta(days=i % 28) for i in range(500)],
'amount': np.random.randn(500) * 100 + 550
})
write_deltalake(table_path, df2.to_arrow(), mode='append')
print("版本2: 追加500行")
time.sleep(1)
# 版本3: 覆盖分区
df3 = pl.DataFrame({
'id': range(2000),
'date': [datetime(2024, 3, 1) + timedelta(days=i % 31) for i in range(2000)],
'amount': np.random.randn(2000) * 100 + 600
})
write_deltalake(table_path, df3.to_arrow(), mode='overwrite')
print("版本3: 覆盖为2000行")
# 分析元数据
print("\n--- 元数据分析 ---")
metadata = manager.get_table_metadata(table_name)
print(f"表名: {metadata['table_name']}")
print(f"当前版本: {metadata['version']}")
print(f"数据文件: {metadata['files']['data_files_count']}个")
print(f"日志文件: {metadata['files']['log_files_count']}个")
print(f"总存储: {metadata['size_metrics']['total_storage_mb']:.2f} MB")
print(f"\n历史操作:")
for op, count in metadata['history']['operations_breakdown'].items():
print(f" {op}: {count}次")
# VACUUM演示
print("\n--- VACUUM清理演示 ---")
# Dry run
files_to_delete = manager.vacuum_table(table_name, retain_hours=0, dry_run=True)
print(f"Dry Run: 将清理 {len(files_to_delete)} 个旧文件")
# 实际清理(保留0小时,即清理所有旧版本,生产环境慎用)
# files_deleted = manager.vacuum_table(table_name, retain_hours=0, dry_run=False)
# print(f"已清理: {len(files_deleted)} 个文件")
# 存储报告
print("\n--- 存储成本报告 ---")
report = manager.generate_storage_report()
print(f"总表数: {report['summary']['total_tables']}")
print(f"总存储: {report['summary']['total_storage_gb']:.2f} GB")
print(f"预估月成本: ${report['summary']['estimated_monthly_cost_usd']:.2f}")
if report['recommendations']:
print(f"\n优化建议:")
for rec in report['recommendations']:
print(f" • {rec}")
# 可视化
visualize_metadata(metadata, report)
# 清理
shutil.rmtree(temp_dir, ignore_errors=True)
def visualize_metadata(metadata: Dict, report: Dict):
"""可视化元数据和存储分析"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle('Delta Lake Metadata & Storage Management', fontsize=16, fontweight='bold')
# 1. 版本历史增长
ax1 = axes[0, 0]
versions = metadata['history']['recent_versions'][:5]
version_nums = [v['version'] for v in versions]
timestamps = [datetime.fromisoformat(v['timestamp'].replace('Z', '+00:00')) for v in versions]
ax1.plot(range(len(version_nums)), version_nums, 'bo-', linewidth=2, markersize=8)
ax1.set_xlabel('Operation Sequence')
ax1.set_ylabel('Version Number')
ax1.set_title('Version History Growth')
ax1.grid(True, alpha=0.3)
# 2. 存储构成
ax2 = axes[0, 1]
data_size = metadata['files']['data_files_size_mb']
log_size = metadata['files']['log_files_size_mb']
sizes = [data_size, log_size]
labels = [f'Data Files\n{data_size:.1f}MB', f'Log Files\n{log_size:.1f}MB']
colors = ['#4CAF50', '#FF9800']
ax2.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
ax2.set_title('Storage Composition')
# 3. 操作类型分布
ax3 = axes[1, 0]
ops = metadata['history']['operations_breakdown']
ax3.bar(ops.keys(), ops.values(), color='#2196F3')
ax3.set_title('Operations Distribution')
ax3.set_ylabel('Count')
ax3.tick_params(axis='x', rotation=45)
# 4. VACUUM策略说明
ax4 = axes[1, 1]
policy_text = """
VACUUM Policy Recommendations:
Production Settings:
• logRetentionDuration: 30 days
• deletedFileRetentionDuration: 7 days
Development Settings:
• logRetentionDuration: 7 days
• deletedFileRetentionDuration: 1 day
Archive Strategy:
• Versions > 90 days: Move to cold storage
• Audit logs: Keep indefinitely
Current Status:
• Versions: {versions}
• Risk: {risk_level}
Recommendation:
{recommendation}
""".format(
versions=metadata['history']['total_versions'],
risk_level='Low' if metadata['history']['total_versions'] < 50 else 'Medium',
recommendation='Schedule weekly VACUUM' if metadata['files']['data_files_count'] > 10 else 'No action needed'
)
ax4.text(0.05, 0.95, policy_text, transform=ax4.transAxes,
fontsize=10, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.8))
ax4.set_xlim(0, 1)
ax4.set_ylim(0, 1)
ax4.axis('off')
ax4.set_title('VACUUM Policy Guide')
plt.tight_layout()
plt.savefig('metadata_management.png', dpi=150, bbox_inches='tight')
logger.info("元数据管理可视化已保存: metadata_management.png")
plt.show()
if __name__ == "__main__":
demonstrate_metadata_management()3.4 数据质量保障实现
3.4.1 great_expectations_integration.py
脚本功能 :Great Expectations集成,实现空值检查、范围验证、格式校验 使用方式 :python 3.4.1_great_expectations_integration.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.4.1 Great Expectations数据质量验证
功能:
- 空值检查、范围验证、格式校验
- 自定义期望(Expectations)
- 数据验证结果可视化
- 与Delta Lake集成
使用方式:python 3.4.1_great_expectations_integration.py
依赖:great_expectations, deltalake
"""
import json
import logging
from datetime import datetime
from typing import Dict, List, Optional, Any, Callable
import tempfile
import shutil
import pandas as pd
import polars as pl
import numpy as np
from deltalake import DeltaTable, write_deltalake
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch
# 由于GE依赖较重,这里提供简化版实现和GE接口模拟
# 实际生产环境应安装: pip install great_expectations
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ExpectationResult:
"""期望验证结果"""
def __init__(self,
expectation_type: str,
column: str,
success: bool,
observed_value: Any,
unexpected_count: int = 0,
unexpected_percent: float = 0.0,
details: Dict = None):
self.expectation_type = expectation_type
self.column = column
self.success = success
self.observed_value = observed_value
self.unexpected_count = unexpected_count
self.unexpected_percent = unexpected_percent
self.details = details or {}
self.timestamp = datetime.utcnow()
def to_dict(self) -> Dict:
return {
'expectation_type': self.expectation_type,
'column': self.column,
'success': self.success,
'observed_value': self.observed_value,
'unexpected_count': self.unexpected_count,
'unexpected_percent': self.unexpected_percent,
'timestamp': self.timestamp.isoformat()
}
class DataQualityValidator:
"""
数据质量验证器(简化版Great Expectations)
实现核心验证逻辑
"""
def __init__(self, dataset_name: str = "dataset"):
self.dataset_name = dataset_name
self.expectations = []
self.results = []
self.suite_name = f"{dataset_name}_suite"
def expect_column_values_to_not_be_null(self,
column: str,
mostly: float = 1.0) -> 'DataQualityValidator':
"""
期望列非空(mostly参数允许部分缺失)
"""
self.expectations.append({
'type': 'not_null',
'column': column,
'mostly': mostly
})
return self
def expect_column_values_to_be_between(self,
column: str,
min_value: float,
max_value: float,
mostly: float = 1.0) -> 'DataQualityValidator':
"""
期望数值范围
"""
self.expectations.append({
'type': 'between',
'column': column,
'min': min_value,
'max': max_value,
'mostly': mostly
})
return self
def expect_column_values_to_match_regex(self,
column: str,
regex: str,
mostly: float = 1.0) -> 'DataQualityValidator':
"""
期望正则匹配(用于格式校验如邮箱、电话)
"""
self.expectations.append({
'type': 'regex',
'column': column,
'regex': regex,
'mostly': mostly
})
return self
def expect_column_values_to_be_in_set(self,
column: str,
value_set: List[Any],
mostly: float = 1.0) -> 'DataQualityValidator':
"""
期望值在枚举集合中
"""
self.expectations.append({
'type': 'in_set',
'column': column,
'value_set': set(value_set),
'mostly': mostly
})
return self
def expect_column_pair_values_to_be_equal(self,
column_A: str,
column_B: str,
mostly: float = 1.0) -> 'DataQualityValidator':
"""
期望两列相等(用于一致性检查)
"""
self.expectations.append({
'type': 'pair_equal',
'column_A': column_A,
'column_B': column_B,
'mostly': mostly
})
return self
def validate(self, df: pl.DataFrame) -> Dict:
"""
执行所有验证
"""
total_rows = len(df)
results = []
for exp in self.expectations:
result = self._run_expectation(df, exp, total_rows)
results.append(result)
self.results = results
# 计算整体成功率
success_count = sum(1 for r in results if r.success)
success_percent = success_count / len(results) if results else 0
return {
'dataset': self.dataset_name,
'timestamp': datetime.utcnow().isoformat(),
'total_rows': total_rows,
'total_expectations': len(results),
'success_expectations': success_count,
'success_percent': success_percent,
'validation_passed': success_percent >= 0.8, # 80%通过算成功
'results': [r.to_dict() for r in results]
}
def _run_expectation(self,
df: pl.DataFrame,
exp: Dict,
total_rows: int) -> ExpectationResult:
"""执行单个期望验证"""
exp_type = exp['type']
column = exp.get('column')
mostly = exp.get('mostly', 1.0)
if exp_type == 'not_null':
null_count = df[column].null_count()
non_null_percent = (total_rows - null_count) / total_rows
success = non_null_percent >= mostly
return ExpectationResult(
expectation_type='expect_column_values_to_not_be_null',
column=column,
success=success,
observed_value=f"{non_null_percent*100:.2f}% non-null",
unexpected_count=null_count,
unexpected_percent=(1 - non_null_percent) * 100
)
elif exp_type == 'between':
col_min = df[column].min()
col_max = df[column].max()
# 计算超出范围的值
out_of_range = df.filter(
(pl.col(column) < exp['min']) | (pl.col(column) > exp['max'])
)
out_count = len(out_of_range)
in_percent = (total_rows - out_count) / total_rows
success = in_percent >= mostly
return ExpectationResult(
expectation_type='expect_column_values_to_be_between',
column=column,
success=success,
observed_value=f"min={col_min}, max={col_max}",
unexpected_count=out_count,
unexpected_percent=(out_count / total_rows) * 100,
details={'expected_range': [exp['min'], exp['max']]}
)
elif exp_type == 'regex':
import re
pattern = re.compile(exp['regex'])
values = df[column].to_list()
non_matching = sum(1 for v in values if v is not None and not pattern.match(str(v)))
match_percent = (total_rows - non_matching) / total_rows
success = match_percent >= mostly
return ExpectationResult(
expectation_type='expect_column_values_to_match_regex',
column=column,
success=success,
observed_value=f"{match_percent*100:.2f}% matching",
unexpected_count=non_matching,
unexpected_percent=(non_matching / total_rows) * 100,
details={'regex': exp['regex']}
)
elif exp_type == 'in_set':
values = set(df[column].drop_nulls().to_list())
invalid = values - exp['value_set']
invalid_count = len(df.filter(~pl.col(column).is_in(list(exp['value_set'])) & pl.col(column).is_not_null()))
valid_percent = (total_rows - invalid_count) / total_rows
success = valid_percent >= mostly
return ExpectationResult(
expectation_type='expect_column_values_to_be_in_set',
column=column,
success=success,
observed_value=f"Unique values: {len(values)}",
unexpected_count=invalid_count,
unexpected_percent=(invalid_count / total_rows) * 100
)
elif exp_type == 'pair_equal':
mismatches = df.filter(pl.col(exp['column_A']) != pl.col(exp['column_B']))
mismatch_count = len(mismatches)
match_percent = (total_rows - mismatch_count) / total_rows
success = match_percent >= mostly
return ExpectationResult(
expectation_type='expect_column_pair_values_to_be_equal',
column=f"{exp['column_A']} vs {exp['column_B']}",
success=success,
observed_value=f"{match_percent*100:.2f}% matching",
unexpected_count=mismatch_count,
unexpected_percent=(mismatch_count / total_rows) * 100
)
return ExpectationResult(
expectation_type='unknown',
column=column or 'unknown',
success=False,
observed_value='Unknown expectation type'
)
def visualize_results(self, output_file: str = "data_quality_report.png"):
"""生成数据质量可视化报告"""
if not self.results:
logger.warning("无验证结果可可视化")
return
fig = plt.figure(figsize=(16, 10))
gs = fig.add_gridspec(3, 3, hspace=0.3, wspace=0.3)
# 1. 整体质量分数
ax_overview = fig.add_subplot(gs[0, :])
success_count = sum(1 for r in self.results if r.success)
total = len(self.results)
success_rate = success_count / total
color = '#4CAF50' if success_rate >= 0.9 else '#FFC107' if success_rate >= 0.7 else '#F44336'
ax_overview.barh(['Overall Quality'], [success_rate * 100], color=color, height=0.5)
ax_overview.set_xlim(0, 100)
ax_overview.set_xlabel('Success Rate %')
ax_overview.set_title(f'Data Quality Overview: {self.dataset_name}', fontsize=14, fontweight='bold')
ax_overview.text(success_rate * 50, 0, f'{success_rate*100:.1f}%',
ha='center', va='center', fontsize=16, fontweight='bold', color='white')
# 2. 各期望成功率
ax_expectations = fig.add_subplot(gs[1, :2])
expectation_names = [f"{r.expectation_type.split('_')[-1]}:{r.column}" for r in self.results]
success_flags = [1 if r.success else 0 for r in self.results]
colors = ['#4CAF50' if s else '#F44336' for s in success_flags]
bars = ax_expectations.barh(range(len(expectation_names)), success_flags, color=colors)
ax_expectations.set_yticks(range(len(expectation_names)))
ax_expectations.set_yticklabels(expectation_names, fontsize=9)
ax_expectations.set_xlabel('Pass (1) / Fail (0)')
ax_expectations.set_title('Individual Expectation Results')
# 3. 失败详情
ax_failures = fig.add_subplot(gs[1, 2])
failures = [r for r in self.results if not r.success]
if failures:
failure_text = "Failed Validations:\n\n"
for f in failures:
failure_text += f"• {f.column}\n"
failure_text += f" Type: {f.expectation_type}\n"
failure_text += f" Unexpected: {f.unexpected_count} ({f.unexpected_percent:.2f}%)\n\n"
else:
failure_text = "All validations passed!\n\n"
failure_text += "Data quality meets\nthe defined standards."
ax_failures.text(0.05, 0.95, failure_text, transform=ax_failures.transAxes,
fontsize=9, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='#FFEBEE' if failures else '#E8F5E9'))
ax_failures.set_xlim(0, 1)
ax_failures.set_ylim(0, 1)
ax_failures.axis('off')
ax_failures.set_title('Failure Details')
# 4. 详细指标表格
ax_details = fig.add_subplot(gs[2, :])
ax_details.axis('tight')
ax_details.axis('off')
table_data = []
for r in self.results:
table_data.append([
r.expectation_type.replace('expect_column_', ''),
r.column,
'✓' if r.success else '✗',
f"{r.unexpected_percent:.2f}%",
r.observed_value[:30] + '...' if len(str(r.observed_value)) > 30 else r.observed_value
])
table = ax_details.table(
cellText=table_data,
colLabels=['Expectation', 'Column', 'Status', 'Unexpected %', 'Observed'],
cellLoc='left',
loc='center',
colWidths=[0.3, 0.2, 0.1, 0.15, 0.25]
)
table.auto_set_font_size(False)
table.set_fontsize(9)
table.scale(1, 2)
# 根据成功状态着色
for i, r in enumerate(self.results):
color = '#E8F5E9' if r.success else '#FFEBEE'
for j in range(5):
table[(i+1, j)].set_facecolor(color)
ax_details.set_title('Detailed Validation Results', y=0.95, pad=20)
plt.savefig(output_file, dpi=150, bbox_inches='tight')
logger.info(f"数据质量报告已保存: {output_file}")
plt.show()
class DeltaLakeQualityIntegration:
"""
Delta Lake与数据质量集成
在写入前进行验证
"""
def __init__(self, storage_path: str):
self.storage_path = storage_path
self.quality_log = []
def write_with_validation(self,
df: pl.DataFrame,
table_name: str,
validator: DataQualityValidator,
mode: str = 'append',
quarantine_bad_data: bool = True) -> Dict:
"""
带质量验证的写入
Returns:
Dict: 包含写入统计和质量报告
"""
# 1. 执行验证
validation_result = validator.validate(df)
# 2. 根据验证结果决策
if validation_result['validation_passed']:
# 质量通过,写入主表
table_path = f"{self.storage_path}/{table_name}"
write_deltalake(table_path, df.to_arrow(), mode=mode)
action = 'written_to_main'
quarantine_df = None
else:
if quarantine_bad_data:
# 分离好坏数据
good_df, quarantine_df = self._separate_data(df, validator)
# 写入好数据
if len(good_df) > 0:
table_path = f"{self.storage_path}/{table_name}"
write_deltalake(table_path, good_df.to_arrow(), mode=mode)
# 写入隔离区
if len(quarantine_df) > 0:
quarantine_path = f"{self.storage_path}/quarantine/{table_name}"
write_deltalake(quarantine_path, quarantine_df.to_arrow(), mode='append')
action = 'partially_written_with_quarantine'
else:
# 拒绝写入
action = 'rejected'
quarantine_df = df
# 记录质量日志
self.quality_log.append({
'timestamp': datetime.utcnow().isoformat(),
'table': table_name,
'action': action,
'total_rows': len(df),
'quarantine_rows': len(quarantine_df) if quarantine_df is not None else 0,
'validation_score': validation_result['success_percent']
})
return {
'action': action,
'rows_written': len(df) - (len(quarantine_df) if quarantine_df is not None else 0),
'rows_quarantined': len(quarantine_df) if quarantine_df is not None else 0,
'validation': validation_result
}
def _separate_data(self, df: pl.DataFrame, validator: DataQualityValidator) -> tuple:
"""
根据验证结果分离数据
简化版:根据null比例决定是否隔离
"""
# 实际应根据具体失败的期望来过滤
# 这里简化:保留null比例<20%的行
null_rates = df.null_count() / len(df)
bad_mask = null_rates > 0.2
if bad_mask.any():
# 某些列null过多,整行隔离
return pl.DataFrame(), df # 简化:全部隔离(实际应更精细)
return df, pl.DataFrame()
def demonstrate_ge_integration():
"""演示Great Expectations集成"""
print("=" * 60)
print("3.4.1 Great Expectations 数据质量验证")
print("=" * 60)
# 生成测试数据(包含质量问题)
print("\n生成测试数据(故意包含质量问题)...")
n = 1000
data = {
'user_id': [f"user_{i}" for i in range(n)],
'email': [f"user{i}@example.com" if i % 10 != 0 else "invalid_email" for i in range(n)],
'age': [np.random.randint(18, 80) if i % 20 != 0 else np.random.randint(150, 200) for i in range(n)], # 一些异常年龄
'salary': [np.random.randint(3000, 50000) if i % 15 != 0 else None for i in range(n)], # 一些空值
'department': np.random.choice(['IT', 'HR', 'Sales', 'Invalid_Dept'], n),
'signup_date': pd.date_range('2024-01-01', periods=n, freq='H'),
'last_login': pd.date_range('2024-01-01', periods=n, freq='H')
}
df = pl.DataFrame(data)
print(f"数据行数: {len(df)}")
print(f"空值统计: {df.null_count().to_dicts()}")
# 创建验证器并添加期望
print("\n配置数据质量规则...")
validator = DataQualityValidator("employee_data")
(validator
.expect_column_values_to_not_be_null('user_id')
.expect_column_values_to_not_be_null('salary', mostly=0.95) # 允许5%缺失
.expect_column_values_to_be_between('age', 18, 100, mostly=0.98) # 允许2%异常
.expect_column_values_to_match_regex('email', r'^[\w\.-]+@[\w\.-]+\.\w+$', mostly=0.95)
.expect_column_values_to_be_in_set('department', ['IT', 'HR', 'Sales'], mostly=0.99)
.expect_column_pair_values_to_be_equal('signup_date', 'last_login')) # 仅用于演示,实际应不同
# 执行验证
print("\n执行验证...")
result = validator.validate(df)
print(f"\n验证结果:")
print(f" 总期望数: {result['total_expectations']}")
print(f" 通过数: {result['success_expectations']}")
print(f" 成功率: {result['success_percent']*100:.1f}%")
print(f" 整体通过: {result['validation_passed']}")
print(f"\n详细结果:")
for r in result['results']:
status = "✓" if r['success'] else "✗"
print(f" {status} {r['expectation_type']}: {r['observed_value']} "
f"(异常: {r['unexpected_percent']:.2f}%)")
# 可视化
validator.visualize_results()
# 演示与Delta Lake集成
print("\n--- Delta Lake集成演示 ---")
temp_dir = tempfile.mkdtemp(prefix="ge_integration_")
integration = DeltaLakeQualityIntegration(temp_dir)
write_result = integration.write_with_validation(
df, "employees", validator, quarantine_bad_data=True
)
print(f"写入动作: {write_result['action']}")
print(f"写入行数: {write_result['rows_written']}")
print(f"隔离行数: {write_result['rows_quarantined']}")
# 清理
shutil.rmtree(temp_dir, ignore_errors=True)
if __name__ == "__main__":
demonstrate_ge_integration()3.4.2 data_lineage_graph.py
脚本功能 :DBT模型依赖关系自动生成与血缘图谱可视化 使用方式 :python 3.4.2_data_lineage_graph.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
3.4.2 数据血缘图谱自动生成
功能:
- 解析SQL依赖关系
- 构建DBT风格血缘图
- 可视化表/字段级依赖
- 影响分析(变更传播)
使用方式:python 3.4.2_data_lineage_graph.py
"""
import re
import json
import logging
from typing import Dict, List, Set, Tuple, Optional
from dataclasses import dataclass, field
from collections import defaultdict
import os
import networkx as nx
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, ArrowStyle
import graphviz # 用于更专业的图可视化
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class ColumnLineage:
"""字段级血缘"""
name: str
source_columns: List[str] = field(default_factory=list)
transformation: str = ""
data_type: str = "unknown"
@dataclass
class TableNode:
"""表节点"""
name: str
schema: str = "public"
node_type: str = "model" # source, model, seed, test
columns: Dict[str, ColumnLineage] = field(default_factory=dict)
depends_on: Set[str] = field(default_factory=set)
referenced_by: Set[str] = field(default_factory=set)
sql_definition: str = ""
materialization: str = "view" # table, view, incremental, ephemeral
owner: str = "unknown"
tags: List[str] = field(default_factory=list)
class SQLDependencyParser:
"""
SQL依赖解析器
从SQL中提取表和字段依赖
"""
# 简单的CTE和子查询匹配(生产环境应使用sqlparse)
CTE_PATTERN = re.compile(r'WITH\s+(\w+)\s+AS\s*\(([^)]+)\)', re.IGNORECASE | re.DOTALL)
FROM_PATTERN = re.compile(r'FROM\s+([`"\[]?[\w\.]+[`"\]]?)', re.IGNORECASE)
JOIN_PATTERN = re.compile(r'JOIN\s+([`"\[]?[\w\.]+[`"\]]?)', re.IGNORECASE)
SELECT_PATTERN = re.compile(r'SELECT\s+(.*?)\s+FROM', re.IGNORECASE | re.DOTALL)
def parse_dependencies(self, sql: str) -> Dict:
"""
解析SQL依赖
Returns:
{
'sources': ['table1', 'table2'],
'ctes': {'cte_name': 'sql'},
'columns': ['col1', 'col2']
}
"""
sql = sql.upper()
# 提取来源表
sources = set()
# FROM子句
from_matches = self.FROM_PATTERN.findall(sql)
sources.update(self._clean_identifiers(from_matches))
# JOIN子句
join_matches = self.JOIN_PATTERN.findall(sql)
sources.update(self._clean_identifiers(join_matches))
# 提取CTE
ctes = {}
cte_matches = self.CTE_PATTERN.findall(sql)
for name, cte_sql in cte_matches:
ctes[name] = cte_sql
# 提取选择的列(简化版)
select_match = self.SELECT_PATTERN.search(sql)
columns = []
if select_match:
select_part = select_match.group(1)
# 简单按逗号分割(实际应处理函数、别名等)
cols = [c.strip().split()[-1] for c in select_part.split(',')]
columns = [c for c in cols if c and c != '*']
return {
'sources': list(sources),
'ctes': ctes,
'columns': columns
}
def _clean_identifiers(self, identifiers: List[str]) -> Set[str]:
"""清理标识符"""
cleaned = set()
for ident in identifiers:
# 移除引号
ident = ident.strip('"\'`[]')
cleaned.add(ident.lower())
return cleaned
class LineageGraphBuilder:
"""
血缘图谱构建器
"""
def __init__(self):
self.graph = nx.DiGraph()
self.parser = SQLDependencyParser()
self.tables = {}
def add_table(self, table_node: TableNode):
"""添加表节点"""
self.tables[table_node.name] = table_node
# 添加节点
self.graph.add_node(
table_node.name,
node_type=table_node.node_type,
materialization=table_node.materialization,
schema=table_node.schema
)
# 添加依赖边
for dep in table_node.depends_on:
if dep in self.tables:
self.graph.add_edge(dep, table_node.name, type='dependency')
self.tables[dep].referenced_by.add(table_node.name)
def parse_model(self, name: str, sql: str, schema: str = "analytics"):
"""
解析DBT模型SQL
"""
deps = self.parser.parse_dependencies(sql)
node = TableNode(
name=name,
schema=schema,
node_type="model",
sql_definition=sql,
depends_on=set(deps['sources'])
)
# 解析字段
for col in deps['columns']:
node.columns[col] = ColumnLineage(
name=col,
source_columns=[], # 实际应解析SQL中的字段映射
transformation="passthrough"
)
self.add_table(node)
return node
def add_source(self, name: str, schema: str = "raw"):
"""添加源表"""
node = TableNode(
name=name,
schema=schema,
node_type="source",
materialization="source"
)
self.add_table(node)
def get_upstream(self, table_name: str, depth: int = -1) -> Set[str]:
"""获取上游依赖"""
return nx.ancestors(self.graph, table_name)
def get_downstream(self, table_name: str, depth: int = -1) -> Set[str]:
"""获取下游影响"""
return nx.descendants(self.graph, table_name)
def find_critical_path(self, source: str, target: str) -> List[str]:
"""查找关键路径"""
try:
return nx.shortest_path(self.graph, source, target)
except nx.NetworkXNoPath:
return []
def detect_cycles(self) -> List[List[str]]:
"""检测循环依赖"""
try:
cycles = list(nx.simple_cycles(self.graph))
return cycles
except:
return []
def generate_dbt_manifest(self) -> Dict:
"""
生成DBT风格的manifest.json
"""
nodes = {}
for name, table in self.tables.items():
nodes[f"model.analytics.{name}"] = {
"unique_id": f"model.analytics.{name}",
"name": name,
"resource_type": "model",
"depends_on": {
"nodes": [f"model.analytics.{d}" for d in table.depends_on]
},
"config": {
"materialized": table.materialization
},
"compiled_sql": table.sql_definition
}
return {
"metadata": {
"dbt_version": "1.0.0",
"generated_at": "2024-01-01T00:00:00Z"
},
"nodes": nodes,
"sources": {},
"exposures": {}
}
def visualize(self, output_file: str = "data_lineage_graph.png"):
"""可视化血缘图"""
if not self.graph.nodes():
logger.warning("图为空")
return
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
fig.suptitle('Data Lineage Graph & Impact Analysis', fontsize=16, fontweight='bold')
# 1. 完整血缘图
ax1 = axes[0, 0]
pos = nx.spring_layout(self.graph, k=2, iterations=50)
# 按类型着色
node_colors = []
for node in self.graph.nodes():
node_type = self.graph.nodes[node].get('node_type', 'unknown')
if node_type == 'source':
node_colors.append('#4CAF50') # 绿色
elif node_type == 'model':
node_colors.append('#2196F3') # 蓝色
else:
node_colors.append('#9E9E9E')
nx.draw(self.graph, pos, ax=ax1, with_labels=True,
node_color=node_colors, node_size=2000,
font_size=8, font_weight='bold',
arrows=True, arrowsize=20, edge_color='#666666',
connectionstyle='arc3,rad=0.1')
ax1.set_title('Complete Data Lineage')
# 添加图例
from matplotlib.patches import Patch
legend_elements = [
Patch(facecolor='#4CAF50', label='Source'),
Patch(facecolor='#2196F3', label='Model'),
Patch(facecolor='#9E9E9E', label='Other')
]
ax1.legend(handles=legend_elements, loc='upper right')
# 2. 上游依赖示例
ax2 = axes[0, 1]
if self.tables:
sample_table = list(self.tables.keys())[0]
upstream = self.get_upstream(sample_table)
if upstream:
subgraph = self.graph.subgraph(upstream | {sample_table})
pos2 = nx.spring_layout(subgraph)
nx.draw(subgraph, pos2, ax=ax2, with_labels=True,
node_color='#FF9800', node_size=1500, font_size=9)
ax2.set_title(f'Upstream of {sample_table}')
else:
ax2.text(0.5, 0.5, 'No upstream dependencies',
ha='center', transform=ax2.transAxes)
ax2.axis('off')
# 3. 下游影响分析
ax3 = axes[1, 0]
if self.tables:
sample_table = list(self.tables.keys())[0]
downstream = self.get_downstream(sample_table)
if downstream:
subgraph = self.graph.subgraph(downstream | {sample_table})
pos3 = nx.spring_layout(subgraph)
nx.draw(subgraph, pos3, ax=ax3, with_labels=True,
node_color='#F44336', node_size=1500, font_size=9)
ax3.set_title(f'Downstream Impact of {sample_table}')
else:
ax3.text(0.5, 0.5, 'No downstream dependencies',
ha='center', transform=ax3.transAxes)
ax3.axis('off')
# 4. 统计信息
ax4 = axes[1, 1]
stats = f"""
Lineage Statistics:
Total Tables: {len(self.tables)}
Total Dependencies: {self.graph.number_of_edges()}
Node Types:
Sources: {sum(1 for n in self.tables.values() if n.node_type == 'source')}
Models: {sum(1 for n in self.tables.values() if n.node_type == 'model')}
Graph Metrics:
Density: {nx.density(self.graph):.3f}
Is DAG: {nx.is_directed_acyclic_graph(self.graph)}
Components: {nx.number_weakly_connected_components(self.graph)}
Cycles Detected: {len(self.detect_cycles())}
"""
ax4.text(0.1, 0.9, stats, transform=ax4.transAxes,
fontsize=10, verticalalignment='top', family='monospace',
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.8))
ax4.set_xlim(0, 1)
ax4.set_ylim(0, 1)
ax4.axis('off')
ax4.set_title('Graph Statistics')
plt.tight_layout()
plt.savefig(output_file, dpi=150, bbox_inches='tight')
logger.info(f"血缘图谱已保存: {output_file}")
plt.show()
def export_to_graphviz(self, output_file: str = "lineage"):
"""导出为Graphviz格式(用于更专业的可视化)"""
try:
dot = graphviz.Digraph(comment='Data Lineage', format='png')
dot.attr(rankdir='LR') # 从左到右布局
# 添加节点
for name, table in self.tables.items():
if table.node_type == 'source':
dot.node(name, shape='cylinder', style='filled', fillcolor='lightgreen')
else:
shape = 'box' if table.materialization == 'table' else 'ellipse'
dot.node(name, shape=shape, style='filled', fillcolor='lightblue')
# 添加边
for edge in self.graph.edges():
dot.edge(edge[0], edge[1])
dot.render(output_file, cleanup=True)
logger.info(f"Graphviz导出: {output_file}.png")
except ImportError:
logger.warning("graphviz未安装,跳过导出")
def demonstrate_lineage_graph():
"""演示血缘图谱"""
print("=" * 60)
print("3.4.2 数据血缘图谱自动生成")
print("=" * 60)
builder = LineageGraphBuilder()
# 1. 定义源表
sources = ['raw_customers', 'raw_orders', 'raw_products', 'raw_inventory']
for source in sources:
builder.add_source(source, schema="raw")
# 2. 定义模型(模拟DBT模型)
models = {
'stg_customers': """
SELECT
customer_id,
first_name,
last_name,
email,
created_at
FROM raw_customers
WHERE deleted_at IS NULL
""",
'stg_orders': """
SELECT
order_id,
customer_id,
order_date,
status,
total_amount
FROM raw_orders
WHERE status != 'cancelled'
""",
'stg_products': """
SELECT
product_id,
product_name,
category,
price
FROM raw_products
""",
'customer_orders': """
SELECT
c.customer_id,
c.first_name,
c.last_name,
COUNT(o.order_id) as total_orders,
SUM(o.total_amount) as lifetime_value
FROM stg_customers c
JOIN stg_orders o ON c.customer_id = o.customer_id
GROUP BY 1, 2, 3
""",
'product_sales': """
SELECT
p.product_id,
p.product_name,
COUNT(*) as times_sold,
SUM(o.total_amount) as revenue
FROM stg_products p
JOIN stg_orders o ON p.product_id = o.customer_id -- 简化关联
GROUP BY 1, 2
""",
'daily_metrics': """
SELECT
DATE(order_date) as date,
COUNT(*) as total_orders,
SUM(total_amount) as total_revenue,
COUNT(DISTINCT customer_id) as unique_customers
FROM stg_orders
GROUP BY 1
"""
}
# 解析所有模型
print("\n解析SQL模型依赖...")
for name, sql in models.items():
print(f" 解析: {name}")
builder.parse_model(name, sql)
# 显示统计
print(f"\n血缘图统计:")
print(f" 表数量: {len(builder.tables)}")
print(f" 依赖边数: {builder.graph.number_of_edges()}")
# 影响分析示例
print(f"\n影响分析示例:")
target = 'stg_customers'
downstream = builder.get_downstream(target)
print(f" {target} 影响下游: {downstream}")
upstream = builder.get_upstream('customer_orders')
print(f" customer_orders 依赖上游: {upstream}")
# 关键路径
if 'raw_customers' in builder.tables and 'customer_orders' in builder.tables:
path = builder.find_critical_path('raw_customers', 'customer_orders')
print(f" 关键路径: {' -> '.join(path)}")
# 生成DBT manifest
manifest = builder.generate_dbt_manifest()
print(f"\n生成DBT manifest: {len(manifest['nodes'])} 个节点")
# 可视化
builder.visualize()
# Graphviz导出(可选)
try:
builder.export_to_graphviz("data_lineage")
except Exception as e:
print(f"Graphviz导出跳过: {e}")
if __name__ == "__main__":
demonstrate_lineage_graph()