用LangGraph搭一个自动化研究助手:从设计到部署全流程
AI Agent实战手册 · 第四章 框架篇
前面几篇我们讲了Agent架构、框架选型和Dify低代码平台。但很多开发者更想亲自动手,用代码实现一个完整的Agent系统。本篇就带你从零开始,用LangGraph构建一个自动化研究助手------它能自动搜索资料、分析内容、生成报告,完全不用人工干预。
一、为什么选研究助手作为实战项目?
研究助手是Agent最经典的落地场景之一:
- 流程清晰:搜索→分析→总结,天然适合状态机建模
- 需要多Agent协作:研究员、审查员、撰稿人各司其职
- 工具调用密集:搜索API、内容提取、数据处理
- 实用性强:可用于竞品分析、市场调研、学术研究
最终效果:你输入一个研究主题(如"2026年AI编程工具市场分析"),系统自动完成:
- 生成研究大纲和关键子问题
- 并行搜索多个资料来源
- 审查信息准确性和完整性
- 生成结构化的研究报告
二、系统架构设计
2.1 总体架构
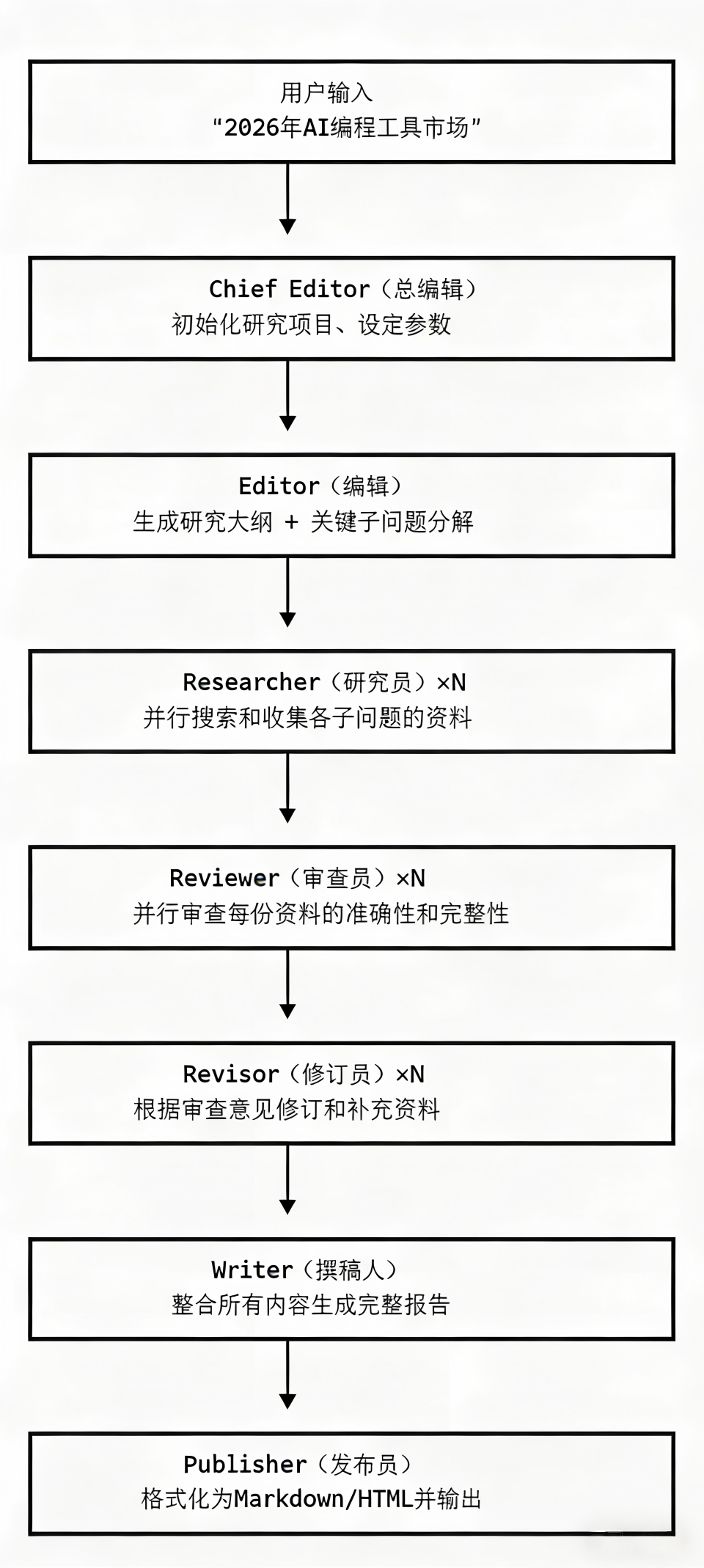
2.2 技术栈
LangGraph → 多智能体工作流编排
LangChain → LLM调用和工具管理
Tavily → 网络搜索API
Python → 核心逻辑
dotenv → 环境变量管理
Streamlit → Web界面(可选)2.3 为什么用LangGraph而不是CrewAI?
| 维度 | LangGraph | CrewAI |
|---|---|---|
| 流程控制 | 精确的状态机,每一步都可控 | 角色驱动,流程较隐式 |
| 并行处理 | 原生支持,Send API | 需要额外配置 |
| 调试 | LangGraph Studio可视化调试 | 日志为主 |
| 复杂路由 | 条件边、循环边原生支持 | 简单场景够用 |
| 学习曲线 | 较陡,但上限高 | 较平,快速上手 |
研究助手的流程有严格的先后顺序,还有并行处理需求,LangGraph的状态机模型更合适。
三、核心代码实现
3.1 项目结构
research_agent/
├── main.py # 核心程序入口
├── agents/
│ ├── editor.py # 编辑智能体
│ ├── researcher.py # 研究员智能体
│ ├── reviewer.py # 审查员智能体
│ ├── revisor.py # 修订员智能体
│ ├── writer.py # 撰稿人智能体
│ └── publisher.py # 发布员智能体
├── tools/
│ ├── search.py # 搜索工具
│ └── extract.py # 内容提取工具
├── state.py # 状态定义
├── config.py # 配置管理
├── .env # 环境变量
└── webui.py # Web界面(可选)3.2 状态定义------整个系统的"数据库"
LangGraph的核心是状态(State)。所有Agent通过共享状态传递信息:
python
# state.py
from typing import TypedDict, Annotated, List, Dict, Optional
from langgraph.graph.message import add_messages
import operator
class ResearchState(TypedDict):
"""研究助手的全局状态"""
# 研究主题和配置
topic: str # 研究主题
language: str # 输出语言(zh/en)
format: str # 输出格式(markdown/html)
# 编辑阶段
outline: Optional[List[str]] # 研究大纲
sub_questions: Optional[List[str]] # 子问题列表
# 研究阶段(按子问题组织)
research_findings: Annotated[
Dict[str, List[str]], operator.add # {子问题: [搜索结果]}
]
# 审查阶段
review_results: Annotated[
Dict[str, str], operator.add # {子问题: 审查意见}
]
# 修订阶段
revised_findings: Annotated[
Dict[str, List[str]], operator.add # {子问题: [修订后内容]}
]
# 最终输出
final_report: Optional[str] # 最终报告
# 控制流
messages: Annotated[list, add_messages] # 对话消息记录
current_step: str # 当前执行步骤
error_count: int # 错误计数(用于重试控制)关键设计决策 :使用 Annotated[..., operator.add] 确保并行Agent写入同一字段时内容不会覆盖,而是合并。
3.3 编辑Agent------生成研究大纲
python
# agents/editor.py
from langchain_core.messages import SystemMessage, HumanMessage
def editor_agent(state: ResearchState) -> dict:
"""编辑智能体:生成研究大纲和子问题"""
system_prompt = """你是一位资深研究编辑。你的任务是:
1. 将研究主题分解为3-5个关键子问题
2. 生成研究大纲
3. 确保子问题之间不重叠,覆盖主题的各个维度
输出格式:
## 大纲
- 子问题1
- 子问题2
- 子问题3
## 子问题
1. 具体的子问题1
2. 具体的子问题2
3. 具体的子问题3"""
messages = [
SystemMessage(content=system_prompt),
HumanMessage(content=f"研究主题:{state['topic']}")
]
response = llm.invoke(messages)
# 解析大纲和子问题
outline, sub_questions = parse_outline(response.content)
return {
"outline": outline,
"sub_questions": sub_questions,
"current_step": "research",
"messages": [response]
}
def parse_outline(text: str) -> tuple:
"""解析LLM返回的大纲和子问题"""
outline = []
questions = []
in_outline = False
in_questions = False
for line in text.split("\n"):
if "## 大纲" in line:
in_outline = True
in_questions = False
continue
elif "## 子问题" in line:
in_outline = False
in_questions = True
continue
line = line.strip()
if not line:
continue
if in_outline and line.startswith("-"):
outline.append(line[1:].strip())
elif in_questions and (line[0].isdigit()):
questions.append(line.split(".", 1)[1].strip())
return outline, questions3.4 研究员Agent------并行搜索
这是最核心的步骤。每个子问题对应一个研究员,并行执行搜索任务:
python
# agents/researcher.py
from langgraph.constants import Send
def research_orchestrator(state: ResearchState) -> list:
"""研究调度器:为每个子问题分配研究员(并行)"""
return [
Send(
"researcher_worker",
{
"sub_question": q,
"topic": state["topic"],
}
)
for q in state["sub_questions"]
]
def researcher_worker(state: dict) -> dict:
"""研究员工作节点:搜索特定子问题的资料"""
sub_question = state["sub_question"]
# 调用搜索工具
search_results = tavily_search(
query=f"{state['topic']}: {sub_question}",
max_results=5
)
# 提取网页内容
contents = []
for result in search_results:
content = extract_web_content(result["url"])
if content:
contents.append(content)
# 用LLM总结搜索结果
summary = llm.invoke([
SystemMessage(content="你是研究员。请从搜索结果中提取关键信息,每条不超过100字。"),
HumanMessage(content=f"子问题:{sub_question}\n\n搜索结果:\n" +
"\n---\n".join(contents))
]).content
# 返回格式:{sub_question: [findings]}
key = sub_question
return {
"research_findings": {key: [summary]},
"messages": [HumanMessage(content=f"完成研究:{sub_question}")]
}3.5 审查Agent------质量控制
python
# agents/reviewer.py
def review_orchestrator(state: ResearchState) -> list:
"""审查调度器:为每份研究发现分配审查员"""
return [
Send("reviewer_worker", {
"sub_question": q,
"findings": state["research_findings"].get(q, []),
})
for q in state["sub_questions"]
]
def reviewer_worker(state: dict) -> dict:
"""审查员工作节点:评估研究质量"""
sub_question = state["sub_question"]
findings = state["findings"]
review_prompt = f"""你是研究审查员。请评估以下研究内容的质量。
子问题:{sub_question}
研究内容:
{chr(10).join(findings)}
请从以下维度评估:
1. 准确性:信息是否准确可靠?
2. 完整性:是否覆盖了关键方面?
3. 时效性:信息是否最新?
4. 建议:需要补充什么?
输出格式:
评分:X/10
审查意见:...
需要补充:..."""
review = llm.invoke([
HumanMessage(content=review_prompt)
]).content
key = sub_question
return {
"review_results": {key: review},
"messages": [HumanMessage(content=f"完成审查:{sub_question}")]
}3.6 组装完整工作流
python
# main.py
from langgraph.graph import StateGraph, START, END
def build_research_workflow() -> StateGraph:
"""构建完整的研究助手工作流"""
workflow = StateGraph(ResearchState)
# ===== 添加节点 =====
workflow.add_node("editor", editor_agent)
workflow.add_node("research_orchestrator", research_orchestrator)
workflow.add_node("researcher_worker", researcher_worker)
workflow.add_node("review_orchestrator", review_orchestrator)
workflow.add_node("reviewer_worker", reviewer_worker)
workflow.add_node("reviser", reviser_agent)
workflow.add_node("writer", writer_agent)
workflow.add_node("publisher", publisher_agent)
# ===== 添加边 =====
# 线性流程
workflow.add_edge(START, "editor")
workflow.add_edge("editor", "research_orchestrator")
workflow.add_edge("research_orchestrator", "researcher_worker")
workflow.add_edge("researcher_worker", "review_orchestrator")
workflow.add_edge("review_orchestrator", "reviewer_worker")
workflow.add_edge("reviewer_worker", "reviser")
workflow.add_edge("reviser", "writer")
workflow.add_edge("writer", "publisher")
workflow.add_edge("publisher", END)
return workflow.compile()
# ===== 运行 =====
if __name__ == "__main__":
workflow = build_research_workflow()
result = workflow.invoke({
"topic": "2026年AI编程工具市场分析",
"language": "zh",
"format": "markdown",
"research_findings": {},
"review_results": {},
"revised_findings": {},
"messages": [],
"error_count": 0,
})
print(result["final_report"])3.7 撰稿人Agent------生成最终报告
python
# agents/writer.py
def writer_agent(state: ResearchState) -> dict:
"""撰稿人:整合所有内容生成报告"""
# 组织所有研究内容
content = ""
for i, q in enumerate(state["sub_questions"]):
findings = state["revised_findings"].get(q, [])
review = state["review_results"].get(q, "")
content += f"""
### {q}
{chr(10).join(findings)}
> 审查备注:{review}
---
"""
writer_prompt = f"""你是资深研究报告撰稿人。请根据以下研究材料撰写完整报告。
研究主题:{state['topic']}
研究材料:
{content}
要求:
1. 结构清晰,有引言、主体、结论
2. 每个观点标注来源
3. 语言专业但易懂
4. 包含数据支撑
5. 最终给出趋势判断和建议"""
report = llm.invoke([
SystemMessage(content=writer_prompt)
]).content
return {
"final_report": report,
"messages": [HumanMessage(content="报告生成完成")]
}四、关键技术点解析
4.1 并行处理的实现
LangGraph的 Send API 是实现并行处理的关键:
python
# 串行处理(慢)
for q in sub_questions:
result = research(q) # 每个耗时10秒,3个问题=30秒
# 并行处理(快)
results = [Send("researcher_worker", {"sub_question": q})
for q in sub_questions] # 3个问题同时执行≈10秒Send 的原理是:它不是一个普通的边,而是一个动态生成的任务列表 。LangGraph会同时启动多个工作节点处理这些任务,结果通过 operator.add 合并到共享状态中。
4.2 状态合并策略
当多个Agent并行写入同一个状态字段时,需要一个合并策略:
python
# 默认行为:后写覆盖(错误!)
research_findings: Dict[str, List[str]] # ❌ 会被覆盖
# 正确行为:追加合并
research_findings: Annotated[
Dict[str, List[str]],
operator.add # ✅ 新数据追加到已有数据
]这是初学者最容易踩的坑之一。忘记设置合并策略会导致并行Agent的结果互相覆盖。
4.3 错误处理与重试
python
def researcher_worker_with_retry(state: dict) -> dict:
"""带重试的研究员工作节点"""
max_retries = 3
for attempt in range(max_retries):
try:
result = do_research(state)
return result
except SearchAPIError as e:
if attempt == max_retries - 1:
# 最后一次重试失败,返回空结果而不是崩溃
return {
"research_findings": {
state["sub_question"]: [f"搜索失败:{str(e)}"]
}
}
time.sleep(2 ** attempt) # 指数退避关键原则:Agent系统不应该因为单个节点的失败而整体崩溃。用优雅降级代替硬中断。
4.4 工具调用的封装
python
# tools/search.py
from langchain_core.tools import tool
@tool
def web_search(query: str, max_results: int = 5) -> list:
"""搜索网络获取最新信息"""
from tavily import TavilyClient
client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
return client.search(query=query, max_results=max_results)
@tool
def extract_content(url: str) -> str:
"""提取网页正文内容"""
import requests
from bs4 import BeautifulSoup
response = requests.get(url, timeout=10)
soup = BeautifulSoup(response.text, 'html.parser')
# 移除脚本和样式
for tag in soup(["script", "style", "nav", "footer"]):
tag.decompose()
return soup.get_text(strip=True)[:3000] # 限制长度五、调试与优化
5.1 LangGraph Studio可视化调试
LangGraph提供了官方的可视化调试工具------LangGraph Studio:
- 安装:
pip install langgraph-cli - 在项目目录运行:
langgraph dev - 打开浏览器访问
http://localhost:8123 - 你可以看到:
- 状态机的完整图形化展示
- 每个节点的实时执行状态
- 状态的当前值和变化
- 执行轨迹回放
5.2 性能优化清单
| 优化点 | 方法 | 效果 |
|---|---|---|
| LLM调用次数 | 合并多个小任务为一个大任务 | 减少50%+API调用 |
| 搜索结果缓存 | 相同查询缓存24小时 | 重复主题效率提升5倍 |
| Token控制 | 每个Agent的输入截断到必要内容 | 降低30%Token消耗 |
| 并行度 | 根据API限流调整并行数 | 避免被限流 |
| 模型选择 | 简单总结用小模型,分析用大模型 | 成本降低40% |
5.3 质量提升技巧
python
# 技巧1:Few-shot示例提升输出质量
editor_prompt = """...
好的研究大纲示例:
主题:"大模型在金融领域的应用"
大纲:
1. 大模型在风险评估中的应用
2. 大模型在智能投顾中的应用
3. 大模型在反欺诈中的应用
4. 监管政策与合规挑战
现在请为以下主题生成大纲:{topic}"""
# 技巧2:Chain-of-Thought引导复杂推理
review_prompt = """请按以下步骤审查:
步骤1:列出研究发现中的关键论点
步骤2:逐个验证论点的可信度
步骤3:检查是否有遗漏的重要方面
步骤4:给出总体评分和改进建议"""
# 技巧3:结构化输出
from pydantic import BaseModel
class ReviewResult(BaseModel):
score: int # 1-10分
accuracy: str # 准确性评估
completeness: str # 完整性评估
suggestions: list # 改进建议六、部署方案
6.1 方案一:命令行工具
最简单的部署方式,适合个人使用:
bash
# 安装依赖
pip install langgraph langchain tavily-python python-dotenv
# 配置环境变量
echo 'OPENAI_API_KEY=sk-xxx' > .env
echo 'TAVILY_API_KEY=tvly-xxx' >> .env
# 运行
python main.py --topic "2026年AI编程工具市场分析" --lang zh --format markdown6.2 方案二:Web界面
使用Streamlit快速搭建Web界面:
python
# webui.py
import streamlit as st
from main import build_research_workflow
st.title("🔍 AI研究助手")
st.caption("输入研究主题,自动生成研究报告")
topic = st.text_input("研究主题", placeholder="例如:2026年AI编程工具市场分析")
language = st.selectbox("输出语言", ["中文", "English"])
report_format = st.selectbox("输出格式", ["Markdown", "HTML"])
if st.button("开始研究", type="primary"):
with st.spinner("正在进行研究,请稍候..."):
workflow = build_research_workflow()
result = workflow.invoke({
"topic": topic,
"language": "zh" if language == "中文" else "en",
"format": report_format.lower(),
"research_findings": {},
"review_results": {},
"revised_findings": {},
"messages": [],
"error_count": 0,
})
st.markdown(result["final_report"])6.3 方案三:API服务
生产环境推荐用FastAPI封装:
python
# api.py
from fastapi import FastAPI
from pydantic import BaseModel
from main import build_research_workflow
app = FastAPI(title="AI研究助手API")
workflow = build_research_workflow()
class ResearchRequest(BaseModel):
topic: str
language: str = "zh"
format: str = "markdown"
class ResearchResponse(BaseModel):
report: str
outline: list
sub_questions: list
@app.post("/research", response_model=ResearchResponse)
async def research(request: ResearchRequest):
result = await workflow.ainvoke({
"topic": request.topic,
"language": request.language,
"format": request.format,
"research_findings": {},
"review_results": {},
"revised_findings": {},
"messages": [],
"error_count": 0,
})
return ResearchResponse(
report=result["final_report"],
outline=result["outline"],
sub_questions=result["sub_questions"],
)七、扩展方向
基础版本搭建完成后,可以考虑这些扩展:
| 方向 | 具体内容 |
|---|---|
| 更多工具 | 接入学术论文搜索(Google Scholar)、专利数据库、新闻API |
| 多轮对话 | 支持用户对报告提出追问,Agent针对性补充 |
| 定时研究 | 定期自动执行研究任务,推送报告变更 |
| 多语言 | 自动翻译为多语言版本 |
| 可视化 | 自动生成图表(市场趋势图、对比矩阵) |
| 人机协作 | 在关键节点暂停,等待用户确认后继续 |
八、完整项目成本估算
| 项目 | 明细 |
|---|---|
| LLM调用 | 每次研究约$0.5-2(取决于子问题数量和内容量) |
| 搜索API | Tavily每月1000次免费,超出$0.01/次 |
| 部署 | 本地免费,云服务器≈$10-50/月 |
| 开发时间 | 熟悉LangGraph后约4-8小时完成基础版 |
九、总结
本篇用一个完整的研究助手项目,展示了LangGraph的核心能力:
- 状态机建模 :通过
TypedDict定义清晰的状态结构 - 多Agent编排:7个专业Agent各司其职,协作完成复杂任务
- 并行处理 :
SendAPI实现子问题级别的并行搜索 - 质量控制:审查→修订→再确认的多重保障
- 灵活部署:命令行、Web界面、API服务三种方案
LangGraph的学习曲线确实比CrewAI和Dify更陡,但它给予你的控制力和可扩展性是无可替代的。如果你要做真正生产级的Agent系统,LangGraph是最值得投入的选择。
相关阅读