高可用集群说明
1.项目概述
本项目旨在搭建一套基于 HAProxy + Keepalived 的 Kubernetes(K8s)高可用集群,采用"三主两worker"架构,通过负载均衡与虚拟IP(VIP)实现控制平面高可用,同时依托 K8s 自带的堆叠式 etcd 集群,自动实现数据存储层的高可用,最终构建一套稳定、可靠、可扩展的容器编排平台,满足生产级业务的部署与运行需求。
核心目标:解决单 master 节点单点故障问题,确保 K8s 控制平面、数据存储层(etcd)、业务运行层(worker)均具备高可用能力,保障集群服务不中断、数据不丢失。
2.集群架构图
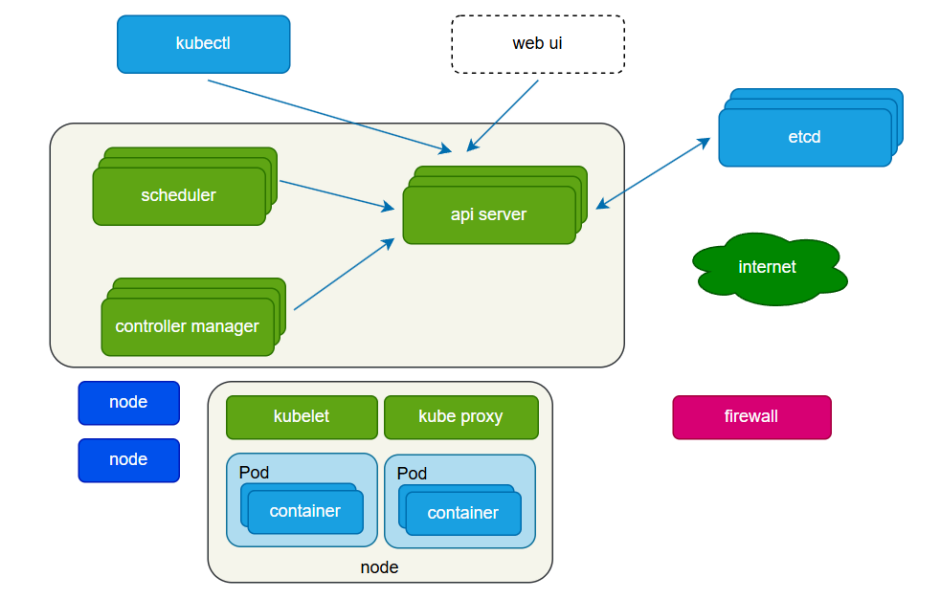
3.项目架构说明
3.1 整体架构组成
本集群由 5 个节点(3 个 master 节点、2 个 worker 节点)组成,同时部署 HAProxy 负载均衡与 Keepalived 虚拟IP服务,架构分为三层:负载均衡层、控制平面层、数据存储层、业务运行层,各层协同工作实现全链路高可用。
- 负载均衡层:所有 master 节点均部署 HAProxy + Keepalived,实现 K8s API Server 的负载分发与 VIP 漂移,对外提供统一的集群访问入口。
- 控制平面层:3 个 master 节点,每个节点部署 kube-apiserver、kube-controller-manager、kube-scheduler 核心组件,通过 HAProxy 实现负载均衡,避免单点故障。
- 数据存储层:依托 K8s 堆叠式(Stacked)etcd 架构,3 个 master 节点各部署 1 个 etcd 实例,自动组成 etcd 集群,实现数据高可用。
- 业务运行层:2 个 worker 节点,负责运行用户业务 Pod,通过 K8s 调度机制实现业务负载分发与故障转移。
3.2 核心组件说明
3.2.1 Keepalived
作用:在 3 个 master 节点之间实现虚拟IP(VIP)的高可用,通过 VRRP(虚拟路由冗余协议)机制,选举出一个主节点(Master)持有 VIP,其余节点作为备份节点(Backup)。当主节点故障时,备份节点自动接管 VIP,确保集群访问入口不中断。
核心配置:指定 VIP 地址、节点优先级(主节点优先级高于备份节点)、心跳检测频率,确保故障时快速切换(切换时间≤3秒)。
3.2.2 HAProxy
作用:作为 K8s API Server 的负载均衡器,部署在每个 master 节点,监听 VIP 和 6443 端口(API Server 默认端口),将客户端(如 kubectl、worker 节点、其他组件)的请求分发到 3 个 master 节点的 API Server,实现负载分担,同时具备健康检查能力,自动剔除故障节点的 API Server,确保请求始终分发到可用节点。
核心配置:配置 API Server 后端节点地址、健康检查规则、负载均衡算法(默认轮询),确保请求分发均匀、故障节点快速隔离。
3.2.3 K8s 核心组件
- kube-apiserver:K8s 集群的入口,处理所有请求,提供认证、授权、访问控制等功能,3 个节点通过 HAProxy 实现负载均衡。
- kube-controller-manager:负责集群资源的调度与管理(如 Pod 调度、节点管理、服务发现等),3 个节点通过选举机制实现主从切换,确保组件高可用。
- kube-scheduler:负责 Pod 的调度决策,根据节点资源、亲和性等规则,将 Pod 调度到合适的节点,3 个节点协同工作,避免单点故障。
- kubelet:部署在所有节点(master + worker),负责管理本节点的 Pod 生命周期,与 API Server 通信,执行容器的启动、停止、重启等操作。
- kube-proxy:部署在所有节点,负责 Service 的负载均衡与网络代理,本项目采用 IPVS 模式,提升网络转发性能。
3.2.4 etcd 集群
etcd 是 K8s 的分布式键值数据库,负责存储集群的所有核心数据(如 Pod 配置、Service 信息、节点状态、认证授权数据等),是 K8s 集群的"数据大脑"。本项目中,etcd 采用堆叠式架构,与 master 节点共生,即 3 个 master 节点各部署 1 个 etcd 实例,自动组成 3 节点 etcd 集群,实现数据高可用。
4.etcd 高可用实现说明
4.1 etcd 高可用原理
etcd 集群通过 Raft 一致性算法实现高可用,核心规则如下:
- 3 节点 etcd 集群中,需满足"多数派(Quorum)"决策机制,即至少 2 个节点正常运行,才能实现数据的读写与一致性同步。
- 集群中会自动选举出一个 Leader 节点,负责处理所有写请求,其余节点作为 Follower 节点,同步 Leader 的数据;当 Leader 节点故障时,剩余 Follower 节点会重新选举新的 Leader,确保集群正常运行。
- 本项目中 3 个 master 节点各部署 1 个 etcd 实例,恰好满足 etcd 高可用的最小节点数(3 节点),可容忍 1 个节点故障(即 1 个 master 节点宕机,剩余 2 个 etcd 节点仍能正常提供服务)。
4.2 etcd 高可用的自动实现(无需额外部署)
本项目中,etcd 高可用无需单独部署独立的 etcd 集群,而是依托 K8s 初始化工具 kubeadm 自动实现,核心逻辑如下:
- 初始化第一个 master 节点时,kubeadm 会自动在该节点部署 etcd 实例,并生成 etcd 集群所需的证书(自动包含所有 master 节点 IP、VIP 等信息,无需手动配置)。
- 通过 kubeadm join 命令将另外 2 个 master 节点加入集群时,kubeadm 会自动在这两个节点部署 etcd 实例,并将其加入到第一个 master 节点的 etcd 集群中,自动完成集群组建与数据同步。
- etcd 集群的通信的认证,由 kubeadm 自动生成的证书保障,无需手动配置 etcd.serverCertSANs、etcd.peerCertSANs,新版本 kubeadm(1.24+)会自动识别所有 master 节点信息,写入证书白名单,确保 etcd 节点间互相信任、正常通信。
4.3 etcd 高可用的优势
- 零额外部署成本:无需单独规划 etcd 节点,依托 master 节点共生,减少硬件资源占用与部署复杂度。
- 自动同步与故障转移:etcd 集群自动完成数据同步,Leader 节点故障时自动选举,无需人工干预。
- 与控制平面联动:etcd 与 master 节点协同部署,当 master 节点故障时,etcd 节点也随之隔离,避免数据不一致,简化运维管理。
5.集群高可用保障机制
5.1 控制平面高可用
3 个 master 节点部署全套控制平面组件,通过 HAProxy 实现 API Server 负载均衡,Keepalived 实现 VIP 漂移,确保:
- 单个 master 节点故障,API Server 请求自动分发到其他正常节点,不影响集群访问。
- 控制平面组件(controller-manager、scheduler)通过选举机制实现主从切换,避免单点故障。
5.2 数据存储高可用
依托 3 节点 etcd 集群,基于 Raft 算法,实现:
- 可容忍 1 个 etcd 节点故障,剩余 2 个节点正常提供数据读写服务,数据不丢失。
- 数据自动同步,确保所有 etcd 节点数据一致,避免数据分裂。
5.3 业务运行高可用
2 个 worker 节点负责运行业务 Pod,通过 K8s 调度机制与 Pod 多副本配置,实现:
- 单个 worker 节点故障,其上的 Pod 会自动调度到另一个正常的 worker 节点,业务不中断。
- 通过 Service 负载均衡,将客户端请求分发到不同的 Pod 实例,提升业务并发能力与可用性。
6.项目部署要点
- 节点准备:3 个 master 节点、2 个 worker 节点,确保节点间网络互通,关闭防火墙、SELinux,配置时间同步。
- 容器运行时:所有节点部署 cri-dockerd(Docker 容器运行时)或 containerd,确保与 K8s 版本兼容(本项目适配 K8s 1.35.3)。
- HAProxy + Keepalived 部署:在 3 个 master 节点部署并配置,指定 VIP、后端 API Server 地址、健康检查规则。
- K8s 集群初始化:使用 kubeadm 初始化第一个 master 节点(指定 VIP 作为 controlPlaneEndpoint),加入另外 2 个 master 节点和 2 个 worker 节点。
- 网络插件部署:导入 Calico 离线镜像,部署 Calico 网络插件,确保 Pod 间网络互通。
- 高可用验证:检查 etcd 集群状态、控制平面组件状态、VIP 漂移功能、Pod 调度功能,确保集群高可用生效。
7.项目价值与意义
本项目搭建的 HAProxy + Keepalived + K8s 三主两worker高可用集群,解决了单节点故障导致集群瘫痪的问题,同时依托堆叠式 etcd 集群,无需额外部署即可实现数据存储高可用,具备以下价值:
- 稳定性:集群各层级均具备高可用能力,可容忍单个节点故障,保障业务连续运行。
- 可扩展性:支持后续新增 master 节点、worker 节点,满足业务规模增长需求。
- 易运维:组件自动部署、自动同步、自动故障转移,减少人工干预成本。
- 生产适配:符合生产级 K8s 集群部署标准,可承载各类容器化业务,为后续业务容器化转型提供基础。
8.总结
本项目通过 HAProxy + Keepalived 实现 K8s 控制平面的负载均衡与高可用,依托 K8s 堆叠式 etcd 架构,让 3 个 master 节点的 etcd 实例自动组成高可用集群,无需额外部署独立 etcd 节点,最终构建了一套"控制平面高可用 + 数据存储高可用 + 业务运行高可用"的三主两worker K8s 集群。集群架构合理、部署简洁、运维便捷,可满足生产级业务的稳定运行需求。
9.主机规划
| 主机名 | IP地址 | 配置 | 角色 | OS |
|---|---|---|---|---|
| 172.25.254.100 | VIP | Rocky Linux9.6 mini | ||
| master01 | 172.25.254.101 | CPU:4,MEM:4GB,DISK:100G | Master | Rocky Linux9.6 mini |
| master02 | 172.25.254.102 | CPU:4,MEM:4GB,DISK:100G | Master | Rocky Linux9.6 mini |
| master03 | 172.25.254.103 | CPU:4,MEM:4GB,DISK:100G | Masrer | Rocky Linux9.6 mini |
| node01 | 172.25.254.10 | CPU:4,MEM:2GB,DISK:100G | Worker | Rocky Linux9.6 mini |
| node02 | 172.25.254.20 | CPU:4,MEM:2GB,DISK:100G | Worker | Rocky Linux9.6 mini |
| reg.harbor.org | 172.25.254.200 | CPU:4,MEM:512M,DISK:100G | 本地Harbor | Rocky Linux9.6 mini |
基础环境配置
1.网络配置
bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.101 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname master01 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.102 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname master02 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.103 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname master03 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.10 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname node01 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.20 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname node02 && bash
[root@localhost ~]# nmcli c modify eth0 ipv4.method manual ipv4.addresses 172.25.254.200 ipv4.gateway 172.25.254.2 ipv4.dns "223.5.5.5 223.6.6.6 8.8.8.8" connection.autoconnect yes && nmcli c up eth0 && hostnamectl hostname reg.harbor.org && bash2.更改软件源
全部主机
bash
sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://dl.rockylinux.org/$contentdir|baseurl=https://mirrors.aliyun.com/rockylinux|g' \
-i.bak \
/etc/yum.repos.d/Rocky-*.repo
dnf makecache3.最小化安装常用工具
全部主机
bash
dnf install wget tree bash-completion vim psmisc net-tools -y
source /etc/profile.d/bash_completion.sh4.火墙与selinux设置
全部主机
bash
systemctl disable firewalld.service
systemctl mask firewalld.service
sed -i '/^SELINUX=/ c SELINUX=disabled' /etc/selinux/config
setenforce 05.配置hosts解析
集群所有主机
bash
cat > /etc/hosts <<EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.25.254.101 master01 m1
172.25.254.102 master02 m2
172.25.254.103 master03 m3
172.25.254.10 node01 n1
172.25.254.20 node02 n1
172.25.254.200 reg.harbor.org
EOF6.集群主机间配置免密
bash
[root@master01 ~]# ssh-keygen
[root@master01 ~]# for ip in 102 103 10 20 200; do ssh-copy-id root@172.25.254.$ip; done
[root@master02 ~]# ssh-keygen
[root@master02 ~]# for ip in 101 103 10 20 200; do ssh-copy-id root@172.25.254.$ip; done
[root@master03 ~]# ssh-keygen
[root@master03 ~]# for ip in 101 102 10 20 200; do ssh-copy-id root@172.25.254.$ip; done
[root@node01 ~]# ssh-keygen
[root@node01 ~]# for ip in 101 102 103 20 200; do ssh-copy-id root@172.25.254.$ip; done
[root@node02 ~]# ssh-keygen
[root@node02 ~]# for ip in 101 102 103 20 200; do ssh-copy-id root@172.25.254.$ip; done部署高可用组件
1.HAProxy
所有master节点
rpm包安装haproxy软件:
bash
dnf install haproxy -y编辑配置文件:
bash
cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
cat > /etc/haproxy/haproxy.cfg <<EOF
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
frontend k8s-master
bind 0.0.0.0:16443
bind 127.0.0.1:16443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server master01 172.25.254.101:6443 check
server master02 172.25.254.102:6443 check
server master03 172.25.254.103:6443 check
EOF启动服务:
bash
systemctl enable --now haproxy.service2.Keepalived
所有master节点
安装keepalived软件:
bash
dnf install keepalived -y创建haproxy检测脚本:
bash
mkdir /etc/keepalived/scripts/
cat > /etc/keepalived/scripts/haproxy_check.sh <<EOF
#!/bin/bash
killall -0 haproxy &> /dev/null
EOF
chmod +x /etc/keepalived/scripts/haproxy_check.sh编辑配置文件:
bash
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id masrer01 #master02 master03
}
vrrp_script check_haproxy {
script "/etc/keepalived/scripts/haproxy_check.sh"
interval 2
weight -20
fall 2
rise 2
}
vrrp_instance VI_1 {
state MASTER #除了master01都是BACKUP
interface eth0
virtual_router_id 51
priority 100 #master01为100 master02为90 master03为85
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.100
}
track_script {
check_haproxy
}
}
EOF启动服务:
bash
systemctl enable --now keepalived.service3.测试高可用组件
测试keepalived的VIP漂移
bash
#依次关闭master01,master02的keepalived查看VIP落在哪天主机上
[root@master01 ~]# systemctl stop keepalived.service #此时落在master02上
[root@master02 ~]# systemctl stop keepalived.service #此时落在master03上
#依次开启回去查看VIP的情况
[root@master01 ~]# ip a测试haproxy的宕机情况的VIP漂移
bash
#依次关闭master01,master02的haproxy查看VIP落在哪天主机上
[root@master01 ~]# systemctl stop haproxy.service #此时落在master02上
[root@master02 ~]# systemctl stop haproxy.service #此时落在master03上
#依次开启回去查看VIP的情况
[root@master01 ~]# ip a至此高可用组件已经配置完毕
安装Docker
全部主机都要安装Docker
添加仓库源并安装:
bash
yum install -y yum-utils
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
dnf install docker-ce -y
systemctl enable --now docker设置镜像仓库源:
配置镜像加速
模拟生产环境中从内网拉取镜像来部署而不是从外网拉取镜像,安全性欠缺
bash
cat >> /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://reg.harbor.org",
"https://docker.1ms.run"
]
}
EOF
systemctl restart docker查看是否添加成功
docker info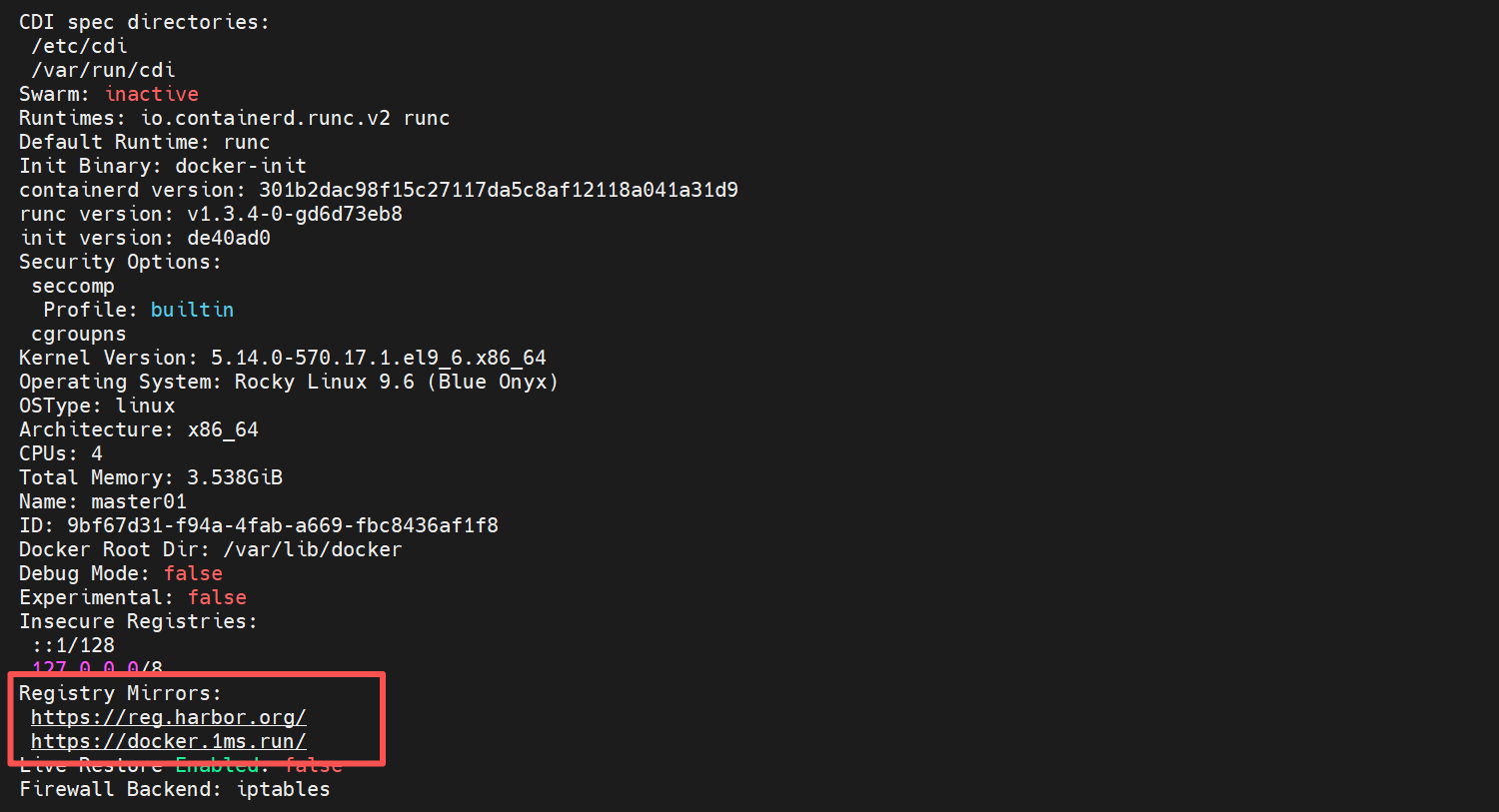
Harbor仓库部署
harbor获取地址:https://github.com/goharbor/harbor/
1.配置ssl生成证书与公钥
bash
[root@reg ~]# mkdir /data/certs/ -p
[root@reg ~]# openssl req -newkey rsa:4096 \
-nodes -sha256 -keyout /data/certs/harbor.org.key \
-addext "subjectAltName = DNS:reg.harbor.org" \
-x509 -days 365 -out /data/certs/harbor.org.crt2.安装harbor与运行
bash
[root@reg ~]# wget https://github.com/goharbor/harbor/releases/download/v2.13.5/harbor-offline-installer-v2.13.5.tgz
[root@reg ~]# tar zxf harbor-offline-installer-v2.13.5.tgz
[root@reg ~]# cd harbor/
[root@reg harbor]# cp harbor.yml.tmpl harbor.yml
[root@reg harbor]# vim harbor.yml
hostname: reg.harbor.org #habor的访问域名
......
certificate: /data/certs/harbor.org.crt #https证书
private_key: /data/certs/harbor.org.key #https私钥
......
harbor_admin_password: password #设置登录密码
[root@reg harbor]# ./install.sh
[root@reg harbor]# docker compose up -d3.拷贝证书给docker让其信任并验证
bash
[root@reg ~]# mkdir /etc/docker/certs.d/reg.harbor.org -p
[root@reg ~]# cp /data/certs/harbor.org.crt /etc/docker/certs.d/reg.harbor.org/ca.crt
[root@reg ~]# systemctl restart docker
[root@reg ~]# docker login reg.harbor.org -u admin
Password:
Login Succeeded #显示登录成功即可完成4.将harbor证书拷贝给k8s集群所有主机让其信任
bash
[root@reg harbor]# for i in {101,102,103,10,20}; do scp -r /etc/docker/certs.d/ root@172.25.254.$i:/etc/docker/; done
#k8s集群主机重启docker并登录
systemctl restart docker
docker login reg.harbor.orgk8s高可用集群部署准备
关闭swap分区
k8s集群主机
bash
systemctl disable --now swap.target
systemctl mask swap.target
sed -i 's/.*swap.*/#&/' /etc/fstab
swapoff -a
free -h
#查看是否关闭配置时间同步
全部主机
bash
dnf install chrony -y
sed -i '/^pool/ c server ntp.aliyun.com iburst' /etc/chrony.conf
systemctl enable --now chronyd
systemctl restart chronyd
chronyc sources -v修改linux最大连接数
k8s集群主机
bash
cat >> /etc/security/limits.conf <<EOF
* soft nofile 655350
* hard nofile 655350
* soft nproc 655350
* hard nproc 655350
* soft memlock unlimited
* hard memlock unlimited
EOF
ulimit -SHn 655350优化内核参数与安装ipvs
k8s集群主机
bash
modprobe br_netfilter
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
dnf install ipvsadm -y安装cri-docker
所有k8s集群主机
安装cri-docker让docker作为k8s集群的容器运行时
下载地址: https://github.com/Mirantis/cri-dockerd/releases/
1.安装软件与依赖
bash
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.24/cri-dockerd-0.3.24-3.fc36.x86_64.rpm
wget https://rpmfind.net/linux/almalinux/8.10/BaseOS/x86_64/os/Packages/libcgroup-0.41-19.el8.x86_64.rpm
dnf install libcgroup-0.41-19.el8.x86_64.rpm -y
dnf install cri-dockerd-0.3.24-3.fc36.x86_64.rpm -y2.编辑系统服务文件
bash
vim /lib/systemd/system/cri-docker.service
......
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.10.1
......
[root@master01 ~]# for i in 102 103 10 20 ; do scp /lib/systemd/system/cri-docker.service root@172.25.254.$i:/lib/systemd/system/; done3.依次启动服务
bash
systemctl daemon-reload
systemctl enable --now cri-docker.service
systemctl enable --now cri-docker.socket安装k8s相关软件
1.添加仓库源并安装,启动服务
k8s集群所有主机
这里node直接可以不安装kubectl,由于写者是批量安装所以方便就全部安装了
bash
#添加仓库源
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.35/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.35/rpm/repodata/repomd.xml.key
EOF
dnf makecache
dnf install -y kubelet kubeadm kubectl
systemctl enable --now kubelet.service2.master节点中 kubectl 和kubeadm 补齐
kubectl与kubeadm补齐
bash
echo "source <(kubectl completion bash)" >> ~/.bashrc
echo "source <(kubeadm completion bash)" >> ~/.bashrc
source ~/.bashrc3.查看版本与所需镜像
bash
#查看版本
kubeadm version
#查看所需的镜像
kubeadm config images list 
4.提前拉取镜像下来并上传到本地harbor仓库
只在一个master上拉取即可
拉取镜像:
bash
[root@master01 ~]# kubeadm config images pull \
> --image-repository registry.aliyuncs.com/google_containers \
> --kubernetes-version v1.35.3 \
> --cri-socket=unix:///var/run/cri-dockerd.sock上传镜像到本地harbor:
bash
#确保已经登录本地仓库
[root@master01 ~]# docker login reg.harbor.org -u admin
Password:
[root@master01 ~]# docker images --format "{{.Repository}}:{{.Tag}}" | awk -F "/" '/google/{system("docker tag "$0" reg.harbor.org/k8s/"$3)}'
[root@master01 ~]# docker images --format "{{.Repository}}:{{.Tag}}" | awk -F "/" '/harbor/{system("docker push "$0)}'查看是否推送到了本地harbor仓库
kubeadm高可用集群初始化与节点扩容
1.初始化集群
master01配置
初始化文件
bash
#生成初始化模板
[root@master01 ~]# kubeadm config print init-defaults > kubeadm-init.yaml
[root@master01 ~]# vim kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta4
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
#localAPIEndpoint: #注释后可以自动识别
# advertiseAddress: 1.2.3.4
# bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock #指定使用的容器运行时的套接字
imagePullPolicy: IfNotPresent
imagePullSerial: true
# name: node #主动识别主机名
taints: null
timeouts:
controlPlaneComponentHealthCheck: 4m0s
discovery: 5m0s
etcdAPICall: 2m0s
kubeletHealthCheck: 4m0s
kubernetesAPICall: 1m0s
tlsBootstrap: 5m0s
upgradeManifests: 5m0s
---
apiServer: {}
apiVersion: kubeadm.k8s.io/v1beta4
caCertificateValidityPeriod: 87600h0m0s
certificateValidityPeriod: 8760h0m0s
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
encryptionAlgorithm: RSA-2048
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: reg.harbor.org/k8s #使用本地harbor仓库镜像
kind: ClusterConfiguration
kubernetesVersion: 1.35.3 #指定集群版本
controlPlaneEndpoint: 172.25.254.100:16443 #新增添加高可用VIP与端口
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 #新增添加pod的网段
proxy: {}
scheduler: {}
---
apiVersion: kubelet.config.k8s.io/v1beta1 #新增
kind: KubeletConfiguration
cgroupDriver: systemd #使用Docker/contained作为容器运行时都要加systemd驱动
imageGCHighThresholdPercent: 95 #磁盘使用率达到95%时自动清理无用镜像
imageGCLowThresholdPercent: 90 #清理降到90%为止
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1 #新增
kind: KubeProxyConfiguration
mode: ipvs #ipvs性能比iptables强生成必开
#检测语法是否ok
kubeadm config validate --config=kubeadm-init.yaml
#开始初始化集群并自动分发证书
kubeadm init --config=kubeadm-init.yaml --upload-certs
#以下为控制节点才需要做的配置
#设置kubectl命令访问权限让其能够管理集群
mkdir -p $HOME/.kube #在当前用户的家目录创建 .kube 隐藏目录(用于存放 kubectl 配置文件)
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config #将集群的管理员配置文件复制到用户专属的 kubectl 配置路径
chown $(id -u):$(id -g) $HOME/.kube/config #修正配置文件的所有权,确保当前用户有权限读取该文件
#设置配置文件的环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bashrc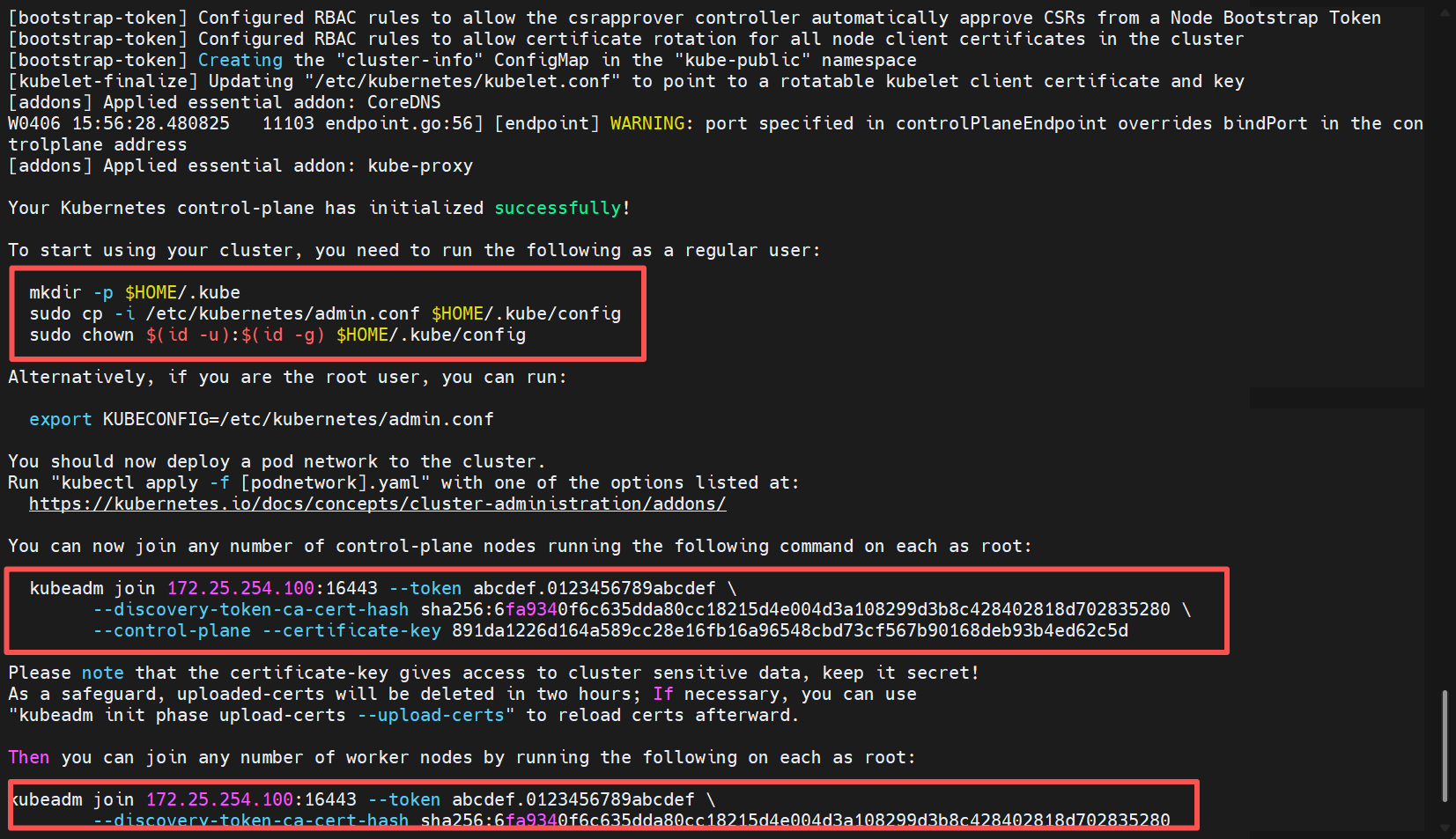
以上为初始化完成的图片
2.加入集群
bash
#让另外两个master节点加入集群
[root@master02 ~]# kubeadm join 172.25.254.100:16443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6fa9340f6c635dda80cc18215d4e004d3a108299d3b8c428402818d702835280 --control-plane --certificate-key 891da1226d164a589cc28e16fb16a96548cbd73cf567b90168deb93b4ed62c5d --cri-socket=unix:///var/run/cri-dockerd.sock
[root@master02 ~]# mkdir -p $HOME/.kube
[root@master02 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master02 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
[root@master02 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master02 ~]# source ~/.bashrc
[root@master03 ~]# kubeadm join 172.25.254.100:16443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6fa9340f6c635dda80cc18215d4e004d3a108299d3b8c428402818d702835280 --control-plane --certificate-key 891da1226d164a589cc28e16fb16a96548cbd73cf567b90168deb93b4ed62c5d --cri-socket=unix:///var/run/cri-dockerd.sock
[root@master03 ~]# mkdir -p $HOME/.kube
[root@master03 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master03 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
[root@master03 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master03 ~]# source ~/.bashrc
#让node节点加入集群
[root@node01 ~]# kubeadm join 172.25.254.100:16443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6fa9340f6c635dda80cc18215d4e004d3a108299d3b8c428402818d702835280 --cri-socket=unix:///var/run/cri-dockerd.sock
[root@node02 ~]# kubeadm join 172.25.254.100:16443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6fa9340f6c635dda80cc18215d4e004d3a108299d3b8c428402818d702835280 --cri-socket=unix:///var/run/cri-dockerd.sock如果集群初始化错误或者加入错误
bash
#集群初始化错误
[root@master01 ~]# kubeadm reset -f kkubeadm-init.yaml && rm -rf
$HOME/.kube /etc/cni/ /etc/kubernetes/ && ipvsadm --clear
#集群加入错误
kubeadm reset如果忘记token,可以重新生成
bash
[root@master01 ~]# kubeadm token create --print-join-command集群加入完成后可以查看节点状态
bash
[root@master01 ~]# kubectl get nodes
!NOTE
STATUS显示为NotReady是因为没有布置网络插件
3.工作节点扩容
bash
[root@node01 ~]# mkdir /root/.kube
[root@node02 ~]# mkdir /root/.kube
[root@master01 ~]# scp .kube/config n1:/root/.kube/
[root@master01 ~]# scp .kube/config n2:/root/.kube/部署calico网络插件
获取calico部署的自定义资源:
打开后点击下载超过50节点yaml文件
只在master01节点操作
1.获取yaml文件
bash
[root@master01 ~]# curl https://raw.githubusercontent.com/projectcalico/calico/v3.31.4/manifests/calico-typha.yaml -o calico.yaml
[root@master01 ~]# kubectl apply -f calico.yaml
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane 32m v1.34.6
master02 Ready control-plane 26m v1.34.6
master03 Ready control-plane 23m v1.34.6
node01 Ready <none> 26m v1.34.6
node2 Ready <none> 24m v1.34.62.上传要使用的镜像到harbor仓库
harbor仓库添加项目
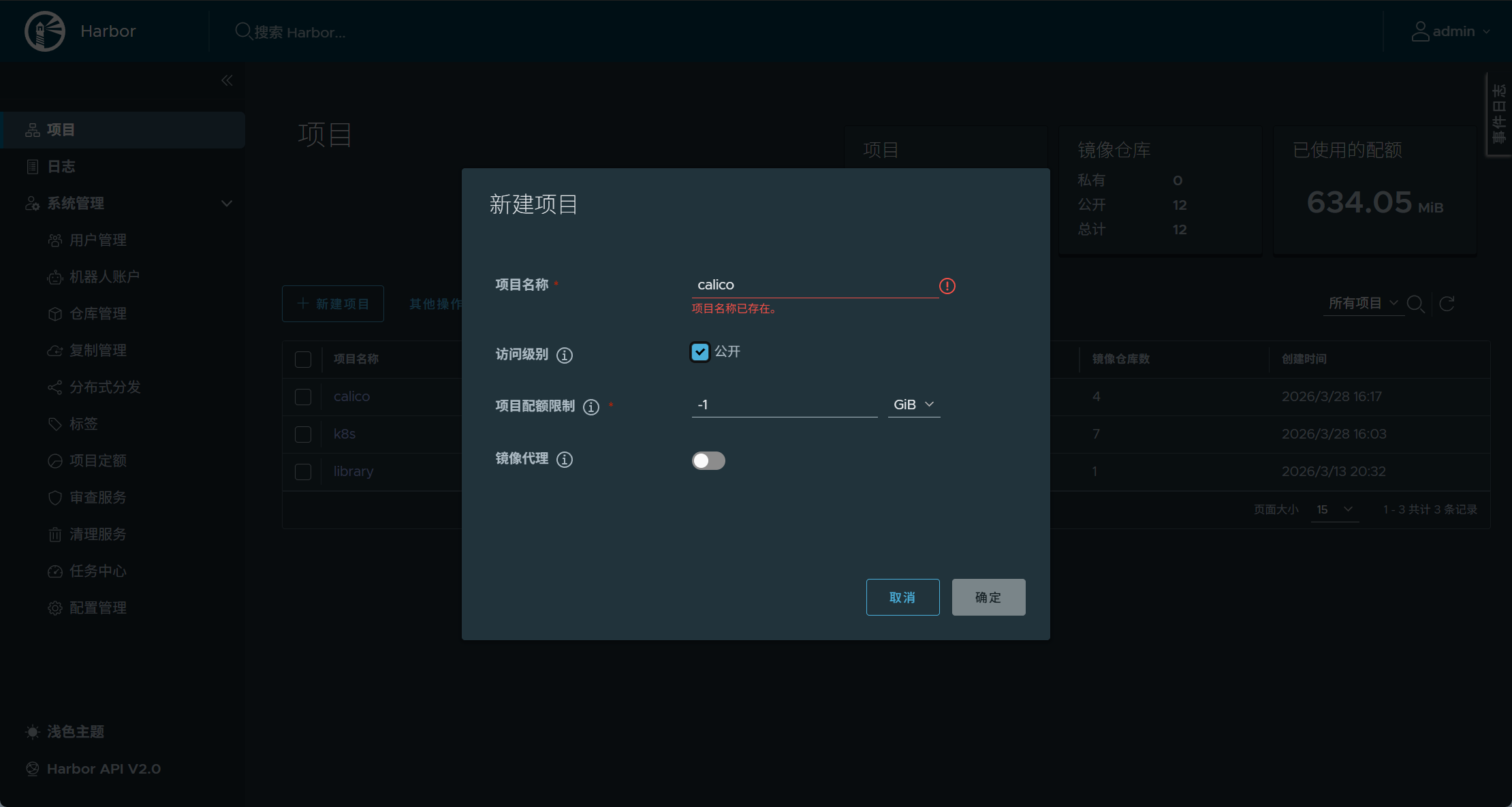
bash
[root@master01 ~]# docker load -i calico-images.tar
[root@master01 ~]# docker images --format "{{.Repository}}:{{.Tag}}" | awk -F "/" '/calico/{system("docker tag "$0" reg.harbor.org/calico/"$3)}'
[root@master01 ~]# docker images --format "{{.Repository}}:{{.Tag}}" | awk -F "/" '/harbor/{system("docker push "$0)}'3.更改网络模式与镜像地址
bash
[root@master01 ~]# vim calico.yaml
......
image: reg.harbor.org/calico/cni:v3.31.4 #把所有镜像地址改为本地harbor仓库地址
......
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Off" #设置为Off即为BGP模式
# Enable or Disable VXLAN on the default IP pool.
- name: CALICO_IPV4POOL_VXLAN
value: "Never"
# Enable or Disable VXLAN on the default IPv6 IP pool.
- name: CALICO_IPV6POOL_VXLAN
value: "Never"
......
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16" #修改为初始化集群pod的网段
......4.应用yaml文件部署
bash
#部署后等待即可全部ready
[root@master01 ~]# kubectl apply -f calico.yaml
#查看集群状态
[root@master01 ~]# kubectl get nodes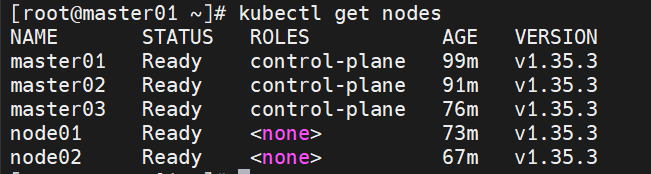
集群测试与etcd备份
1.测试集群创建的资源是否可以正常访问网络和coredns
bash
[root@master01 ~]# kubectl run --image library/busybox --image-pull-policy IfNotPresent --restart Never --rm -it busybox -- /bin/sh
/ # ping www.baidu.com
PING www.baidu.com (183.2.172.177): 56 data bytes
64 bytes from 183.2.172.177: seq=0 ttl=127 time=9.832 ms
64 bytes from 183.2.172.177: seq=1 ttl=127 time=7.549 ms
64 bytes from 183.2.172.177: seq=2 ttl=127 time=8.918 ms
64 bytes from 183.2.172.177: seq=3 ttl=127 time=6.159 ms2.排查 etcd 集群健康状况的标准操作
1.列出 etcd 集群当前所有成员(节点)的信息
bash
[root@master01 ~]# docker run --rm -it --net host -v /etc/kubernetes:/etc/kubernetes registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.4-0 etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --cacert /etc/kubernetes/pki/etcd/ca.crt member list2.检查 etcd 集群中所有指定端点的健康状态
bash
[root@master01 ~]# docker run --rm -it --net host -v /etc/kubernetes:/etc/kubernetes registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.4-0 etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --cacert /etc/kubernetes/pki/etcd/ca.crt --endpoints=https://172.25.254.101:2379,https://172.25.254.102:2379,https://172.25.254.103:2379 endpoint health --cluster3.以表格格式显示 etcd 集群中所有端点的详细状态信息(包括 leader、raft term、存储大小、版本等)
bash
[root@master01 ~]# docker run --rm -it --net host \
-v /etc/kubernetes:/etc/kubernetes \
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.4-0 \
etcdctl \
-w table \
--cert /etc/kubernetes/pki/etcd/peer.crt \
--key /etc/kubernetes/pki/etcd/peer.key \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--endpoints=https://172.25.254.101:2379,https://172.25.254.102:2379,https://172.25.254.103:2379 endpoint status ---cluster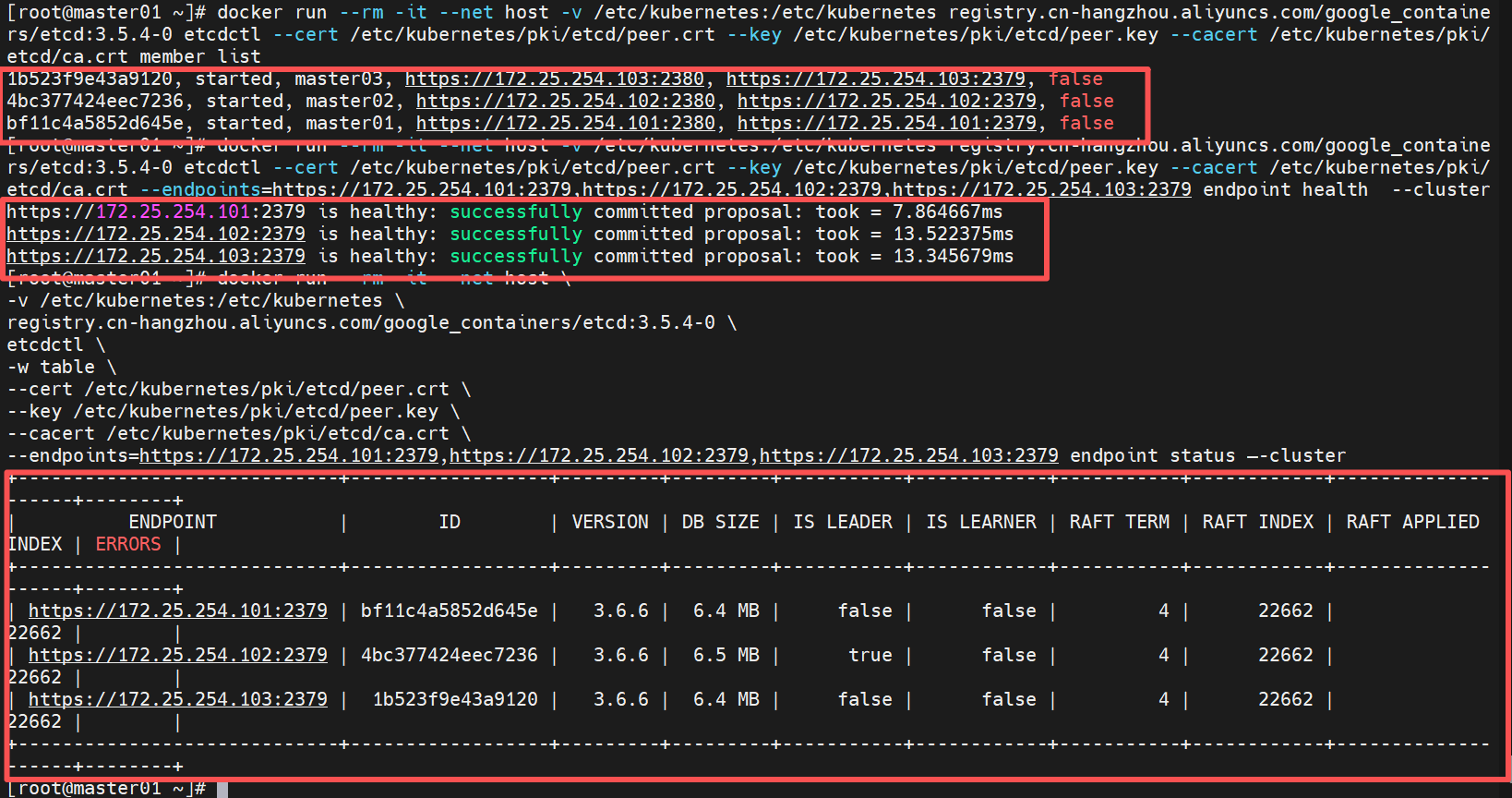
3.etcd备份
- 只需要备份任意一个节点的数据就行,不需要三个节点都备份!
- 因为 etcd 是一个强一致性集群,所有节点的数据内容是一样的(同步的),
- 所以备份任何一个健康节点的数据就可以恢复整个集群!
bash
[root@master01 ~]# docker run --rm -it --net host -v /etc/kubernetes:/etc/kubernetes -v /backup:/backup registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.4-0 etcdctl --cert /etc/kubernetes/pki/etcd/peer.crt --key /etc/kubernetes/pki/etcd/peer.key --cacert /etc/kubernetes/pki/etcd/ca.crt --endpoints=https://172.25.254.101:2379 snapshot save /backup/etcd-snapshot.db
# 将备份发送至另一台专门做存储的主机(奈何资源不足,发送至Harbor主机进行保存)
[root@reg ~]# mkdir /backup_k8s
[root@master01 ~]# scp /backup/etcd-snapshot.db reg.harbor.org:/backup_k8s/!CAUTION
etcd备份一定要定时做!比如用 crontab 每天备一份。
最好把快照文件备份到远程,比如 NAS、对象存储,不要只存在本机。
恢复操作尽量在测试环境演练过一次,不要第一次就在生产上操作。
etcd非常重要,它是Kubernetes的心脏,千万不能轻视备份。
bash
#如果要进行测试可以执行以下命令
rm -rf /var/lib/etcd/*备份文件进行还原(集群宕机)及集群内etcd重启
bash
docker run --rm -it --net host \
-v /etc/kubernetes:/etc/kubernetes \
-v /backup:/backup \
-v /var/lib/etcd:/var/lib/etcd \
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.4-0 \
etcdctl snapshot restore /backup/etcd-snapshot.db \
--data-dir /var/lib/etcd