摘要(Summary) :本文基于生产案例,讨论单体 LangGraph 智能体在长系统提示(约 2 万 token)、大量工具与无缓存 条件下导致的 LLM 成本与延迟 问题,并归纳四类改造:按任务域拆分多智能体 、Prompt Caching(约 5 分钟窗口) 、将轻量子任务下沉为调用小模型的工具 、以及 Query Router 做上下文感知 的查询路由,使问候与轻追问不再进入重型智能体。案例报告成本约降 70%--75%,并补充「何时需要完整智能体、何时不必」的架构取舍。
关键词(Keywords):LangGraph;AI 智能体;LLM 成本优化;多智能体;提示缓存(Prompt Caching);查询路由(Query Router);任务分解;工具调用;模型分层;Claude Sonnet;PostgreSQL checkpoint;生产环境
如果你的 AI 智能体已经上线生产,下文可能帮你砍掉相当大一块成本。
1 一些结论
我们的目标是优化一个基于 LangGraph 构建的 AI 智能体的 LLM 成本。High level 信息如下。
1.1 原始架构
- 系统依赖单一 AI 智能体,系统提示词 约 2 万 token。
- 智能体基于 LangGraph 构建,底层模型为 Claude Sonnet 4.5。
- 挂载约 30 个工具 ,并使用基于 PostgreSQL 的 checkpoint 存储(LangGraph 的状态持久化与恢复)。
1.2 核心问题
- 整条链路绑在一个智能体上:从问候、FAQ,到任务 Alpha(工具与推理密集)、任务 Beta(同样工具与推理密集),全部由同一智能体处理。
- 系统提示词臃肿:必须把各类任务的指令都塞进同一份 prompt。
- 没有缓存策略。
- 简单任务 (例如条目结构生成)也由 Claude Sonnet 承担。
- 总体问题可以概括为:用推土机堆沙堡------能力与成本严重错配。
1.3 采取的优化
通过下列相对基础到中等复杂度的改造,单次操作总成本约节省 70%:
- 拆分 Agent Alpha 与 Agent Gamma(以及后续的 Delta 等,见下文)。
- 实现提示缓存(Prompt Caching) ,采用 5 分钟滚动窗口(与供应商对「缓存命中」的时间窗策略一致;具体计费以各云文档为准)。
- 将部分小任务下沉为工具(tools) ,工具内部改用更小、更便宜的模型(例如 Gemini 2.5 Flash)完成。
- 把系统改为多智能体 + 人工设计的查询路由(manual query routing) :由一次有上下文感知的路由调用决定应调用哪个智能体。
- 「Hi」 这类用户输入不再进入带着 2 万 token 系统提示 的重型智能体;后续不需要强推理 的追问,也由更便宜的模型侧智能体处理。
4. 可量化结果
- LLM 成本平均下降约 70%--75%。
- 本应更快的查询,比预期更快。
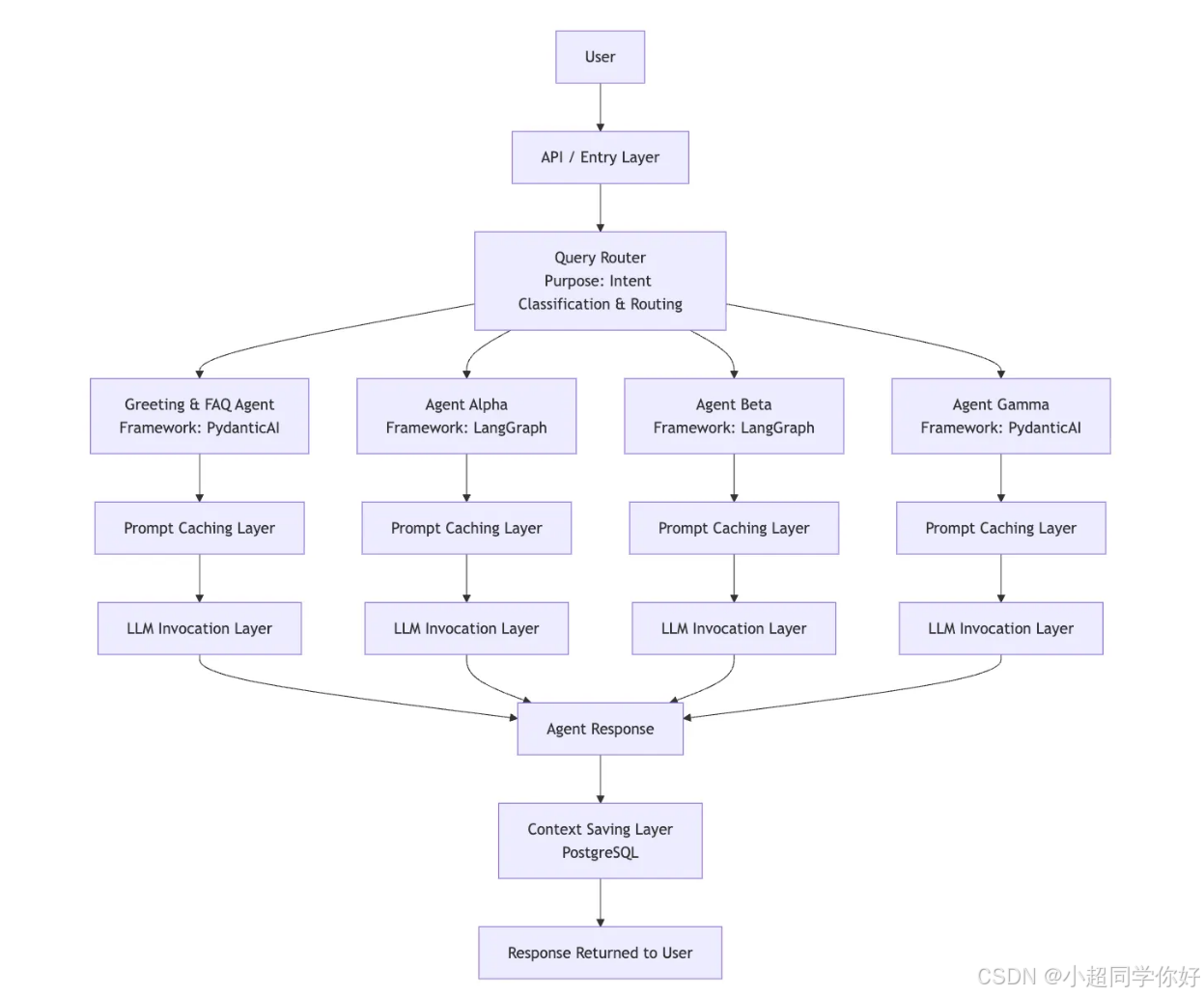
5. 最终架构
最终形态为:路由层 → 多个专用智能体(不同模型与 prompt 体量)→ 按需工具与小模型 。具体拓扑见原文中的 Final Architecture 示意图。
2 深入细节
2,1 问题:单体智能体如何成为瓶颈
当系统要服务多种流程 ,却仍用一个智能体 包揽一切时,这在生产里几乎是红旗信号。下面用我们当时的系统说明。
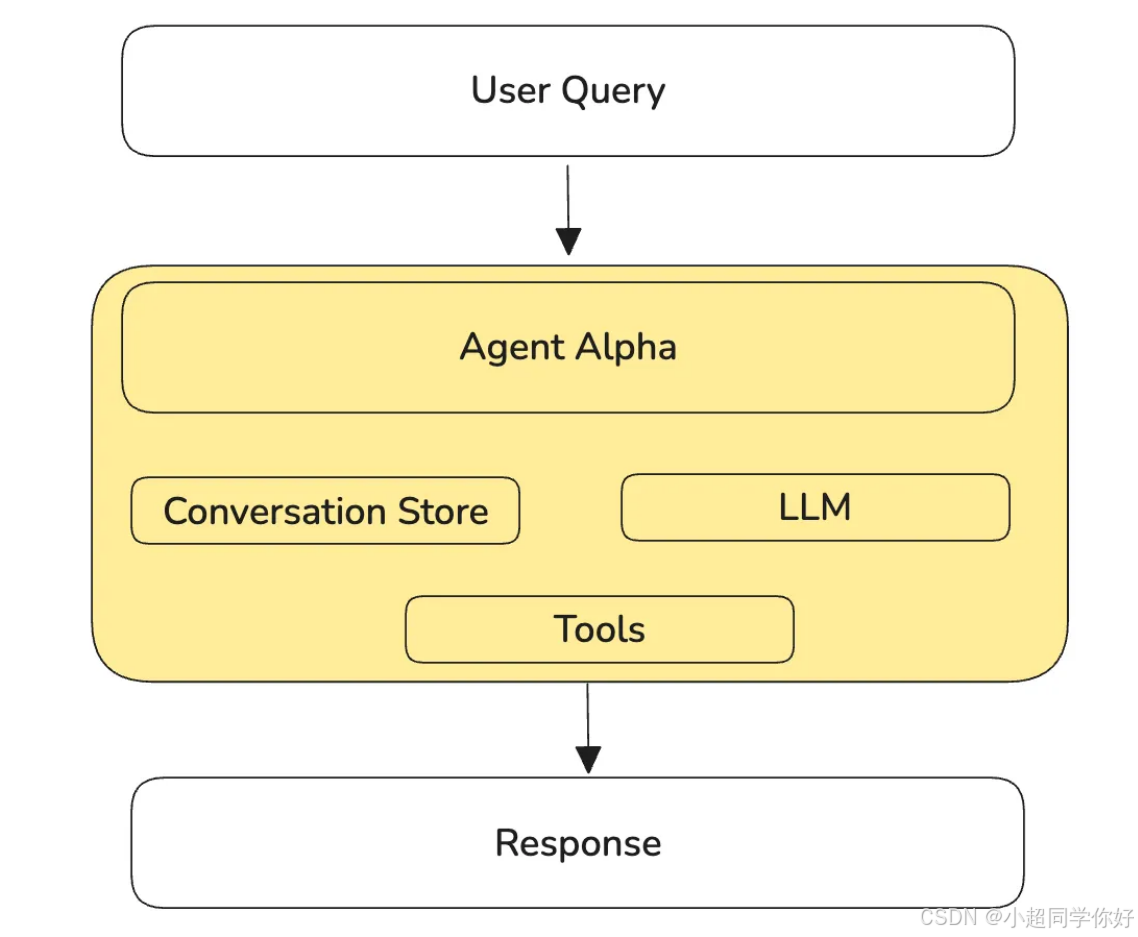
每条用户查询 都走同一个 Agent 循环。智能体必须带巨大的系统提示词 ,因为要覆盖多种任务类型。只说「Hi」 的消息和 「请执行下列任务」 的消息,被送进同一个 Agent------在生产系统里,这本不该发生。
分析后发现:智能体效果不差 ,但花的钱远超合理范围。优化分阶段如下。
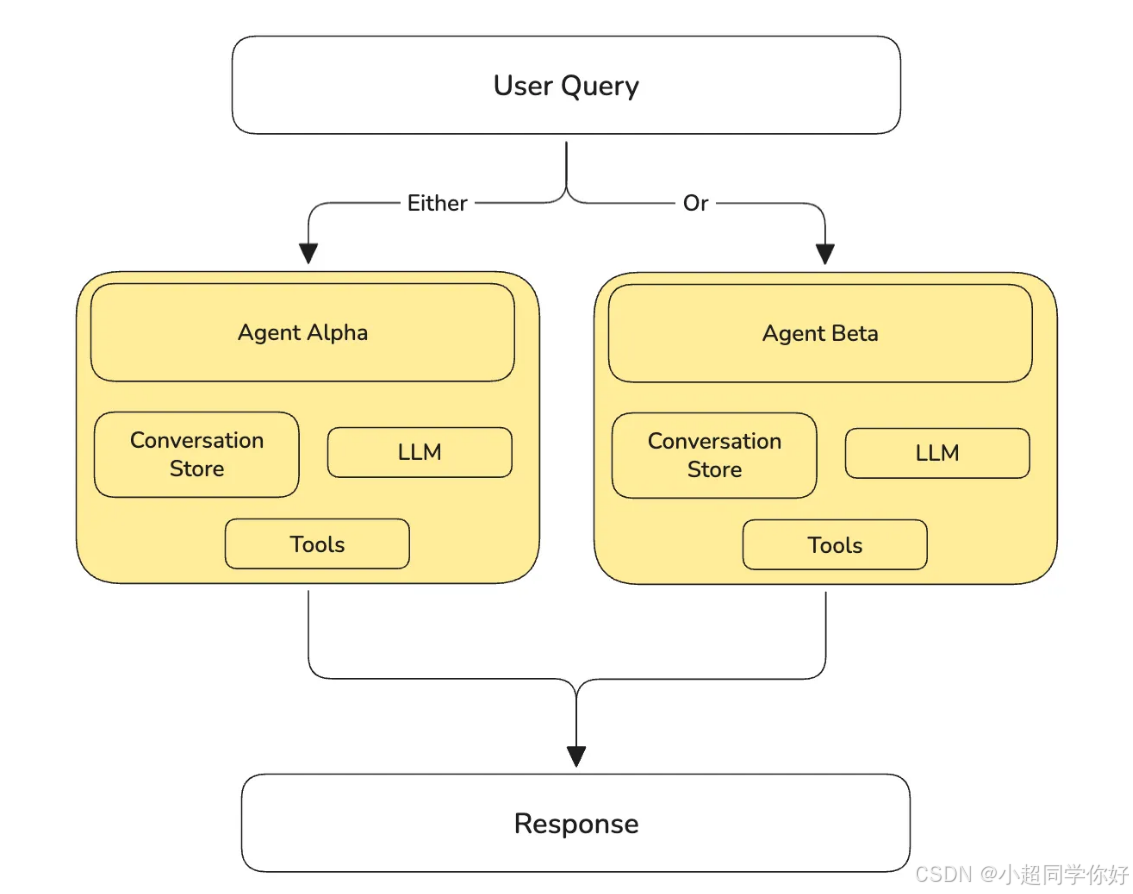
(1)按任务域拆分智能体
智能体同时在做 Task Alpha 与 Task Beta ,二者几乎无关、无重叠,却导致:
- 执行 Task Alpha 时,Task Beta 的指令与工具 仍被加载进上下文,被 LLM 无谓地处理。
解法 :拆成两个智能体 ,分别只服务 Task Alpha 与 Task Beta,对外可分别暴露 (或通过路由统一入口)。
改完后,每条路径上的 prompt 与工具集更窄,固定开销显著下降。
(2)提示缓存(Prompt Caching)
拆分后 token 用量仍然偏高,下一步是 Prompt Caching 。这是简单但非常有效 的「省油」手段:多数 LLM 供应商支持在一定时间窗内 对已处理过的前缀 token 收取更低的费用------例如 2 万 token 的系统提示在 5 分钟内 走了 100 次 ,通常只有首次(或按文档规则)按全价计 ,其余命中缓存时单价大幅下降。
改完后拓扑可不变 ,但账单会明显下降 。工程上需关注:缓存键 、可缓存块的位置 (一般把稳定长前缀放在前部)、以及TTL/滚动窗口与业务会话长度是否匹配。
(3)任务分解 + 小模型进工具
进一步分析发现,部分子任务不需要 Sonnet 4.5 级别 的推理能力。做法是:把这些步骤拆成工具 ,工具实现里调用更小模型完成任务(例如结构化生成、格式转换、轻量分类等)。
补充(工程视角) :「工具内用小模型」本质是 能力分层 :编排仍可由强模型或规则完成,但高吞吐、低认知负荷的步骤固定到便宜模型,避免在 ReAct 循环里每一步都烧最贵档位。
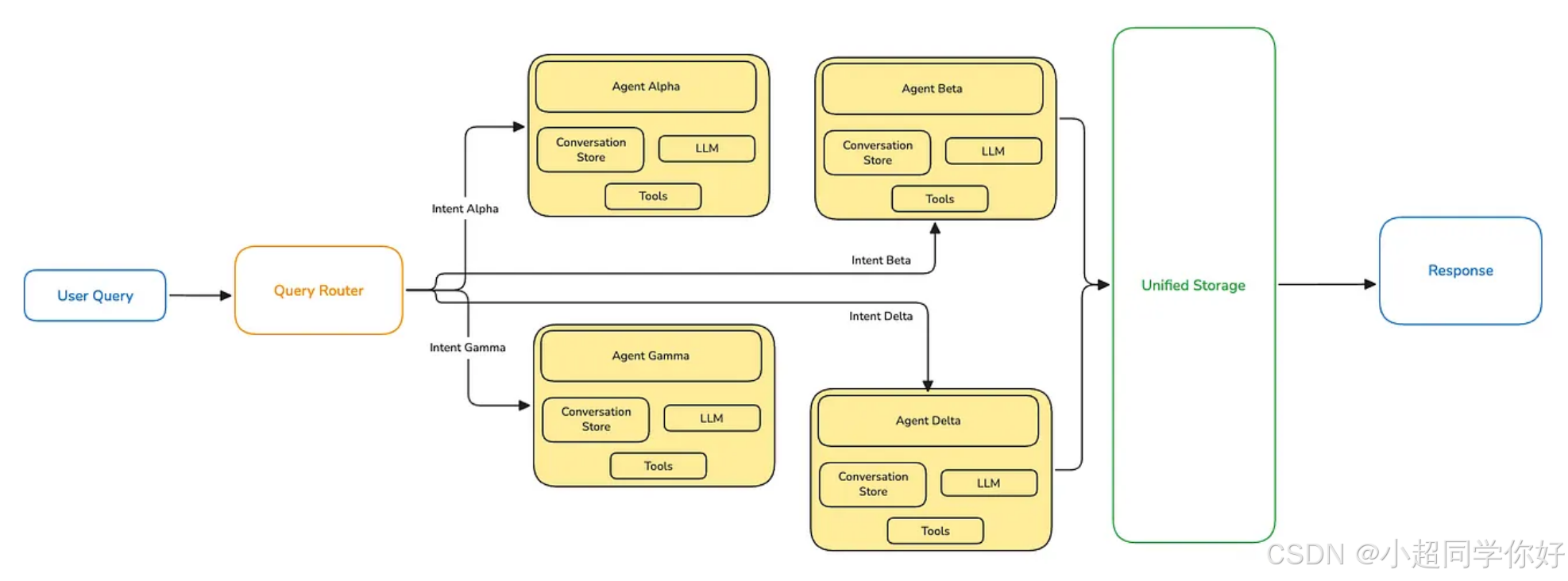
(4)再拆:问候 / FAQ / 支持与「任务后追问」
仍有问题:问候、用户支持、或 Alpha/Beta 完成后的简单追问 ,若仍进入 Agent Alpha 或 Beta,token 与单价依然偏高。
进一步拆分:
- Agent Gamma :专门处理 问候、FAQ、用户支持。
- Agent Delta :专门处理 Task Alpha 完成后的后续追问(轻量、跟随型对话)。
拆智能体本身不难,难在:由谁决定在何时调用哪一个智能体------不可能给每个智能体各做一个独立用户界面。
解法 :实现 Query Router(查询路由器) ------一次单轮(single-shot)、有上下文感知 的 LLM 调用,唯一职责 是:理解当前请求意图,并决定应路由到哪个下游智能体。
Gamma 与 Delta 不需要 复杂图编排,可以选择用类似 Pydantic AI 搭建这类轻量智能体。
将单体改为手工编排的多智能体系统 后,单次请求成本 约再降 75%--80%(相对优化前;与全文「约 70%」为不同口径下的表述,均以原文为准),整体是可观的改进。
补充(与 LangGraph 的关系) :LangGraph 适合有环、有状态、多步工具调用 的复杂工作流;对单轮分类/路由 + 少量结构化输出 ,轻量框架往往更省事。生产上常见做法是 「图编排(重任务)+ 轻量 handler(轻任务)」 混合架构,而不是「所有盒子都用同一种图引擎」。
3 什么时候该用 AI 智能体,什么时候不该
智能体很强,但也贵、复杂、且常被滥用 。最大的架构误区之一,是把每一个 AI 需求都当成「智能体问题」。
在动手前,要先想清楚:智能体到底是什么。
3.1 智能体 ≠ 单次 LLM 调用
智能体通常指一套能:
- 对任务进行推理
- 决定采取哪些动作
- 使用工具
- 维护上下文或状态
- 执行多步工作流
的系统。
正是这种自主性 带来能力,也带来成本。
并非每个问题都需要这一整包能力。
3.2 什么时候你不需要 AI 智能体
许多事可以用更简单、更便宜的方式解决。
-
单步变换
输入 → 输出一步搞定 、无需分支与工具编排时,一次 LLM 调用往往足够。不需要路由、不需要编排、不需要「智能体壳子」------硬套只会增加开销。
-
确定性工作流
若执行步骤事先完全确定,用传统代码或固定 DAG 即可,不必让模型在每一步「再发明一遍流程」。
-
结构化操作
对已知 schema 的数据做确定性格式处理,传统代码往往更稳、更便宜;不需要「开放式推理」时,不必上智能体。
-
高频、低复杂度请求
智能体单次请求 overhead 更高。问候、FAQ 等应优先 轻量方案或更小模型;全程走「满配智能体」会急剧放大 token 与费用。
3.3 什么时候你需要 AI 智能体
当任务涉及推理、决策与动态执行时,智能体更有价值。
-
多步且相互依赖的工作流
需要规划与动态调整顺序时,智能体更合适。
-
工具使用与编排
要与多个 API、外部系统交互,并需按需选工具、处理失败与重试时,智能体提供编排能力。
-
需要推理链的任务
无法靠单次 prompt 直接得到可靠答案时,推理循环有助于提高正确率(需在成本与延迟上设上限)。
-
输入高度不可预测
用户意图与所需步骤无法预先穷举时,智能体比固定流程更灵活。
3.4 权衡:能力 vs 成本
智能体带来灵活性,也带来:
- 更高的 token 用量
- 更高的 延迟
- 更复杂的 架构与运维
- 更难 调试与回归
因此架构选择至关重要。
目标不是「到处都用智能体」,而是只在真正需要自主推理与动态编排的地方使用智能体。