
[三、60种配置实验:4代YOLO x 5个尺度 x 4个数据集](#三、60种配置实验:4代YOLO x 5个尺度 x 4个数据集)
[MS COCO 2017:加速1.43-1.68倍](#MS COCO 2017:加速1.43-1.68倍)
[PASCAL VOC 2007:加速1.60-1.69倍](#PASCAL VOC 2007:加速1.60-1.69倍)
导读
YOLO以推理速度快闻名,但训练却出乎意料地慢------YOLO11s在MS COCO上用两块RTX 4090需要43.9小时,而同条件下Faster R-CNN+ResNet50仅需6.5小时。原因在于YOLO每个epoch都要遍历全部训练图片,即使其中大量图片早已被学会。那么,YOLO真的需要每轮看完所有图片吗?
西北工业大学与重庆邮电大学的研究团队提出了Anti-Forgetting Sampling Strategy(AFSS),通过度量每张图片的学习充分性,将训练数据动态分为简单、中等、困难三级,对已学会的图片大幅减少采样,同时引入持续复习机制防止遗忘。在4个数据集、4代YOLO、5个模型尺度共60种配置(自然图像40种+遥感20种)上,AFSS实现1.43-1.70倍训练加速,且所有配置精度持平或提升。其中YOLO12x在MS COCO上从260.6小时降至154.8小时,节省105.8小时。更值得注意的是,AFSS是对比实验中唯一在加速的同时不损失精度的方法。
论文信息
-
标题:Does YOLO Really Need to See Every Training Image in Every Epoch?
-
作者:Xingxing Xie, Jiahua Dong, Junwei Han, Gong Cheng
-
机构:西北工业大学 自动化学院、重庆邮电大学 人工智能学院
-
代码:暂未开源(截至2026年3月29日)
一、每轮看所有图片真的必要吗?
YOLO系列检测器的核心卖点是推理快------"You Only Look Once"。但在训练端,这一系列却遵循一个看似矛盾的范式:每个epoch遍历全部训练图片。论文以YOLO11s为例给出了一组对比数据:在MS COCO 2017上,YOLO11s推理速度达200 FPS,但训练需要43.9小时(2块RTX 4090);而同条件下Faster R-CNN+ResNet50仅需6.5小时,训练速度反而快6.9倍。
造成这种"推理快、训练慢"反差的根源,在于YOLO不区分图片难度地进行全量遍历。训练后期,大量图片已被模型充分学会,继续处理它们产生的是冗余计算。论文的核心问题由此而来:能否在训练过程中动态跳过已学会的图片,在不损失精度的前提下加速训练?
这个问题看似简单,但朴素地丢弃图片会带来遗忘问题------模型可能"忘掉"曾经学会的样本。AFSS正是围绕"如何安全地跳过"这一核心挑战展开设计。
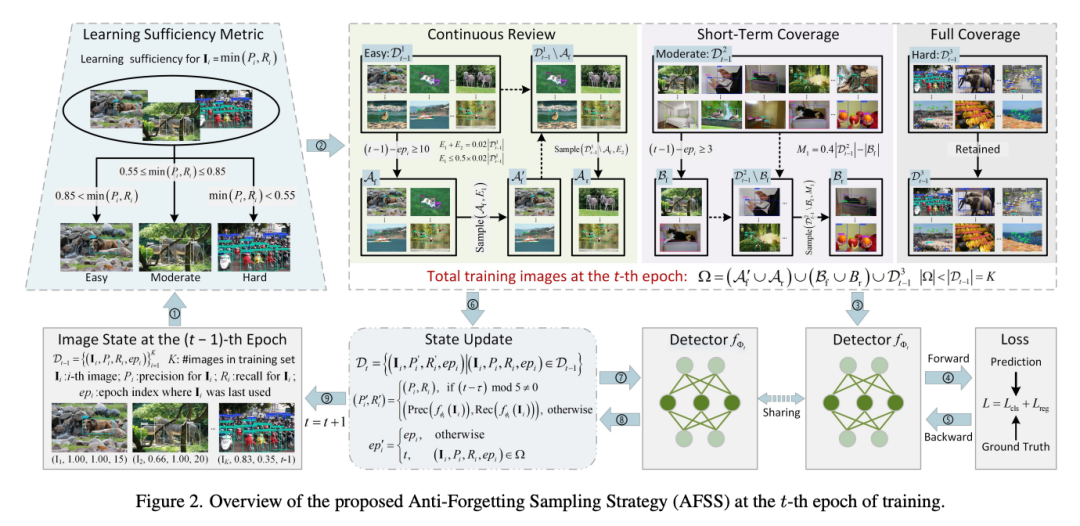
二、AFSS:学习充分性度量+三级分类+持续复习
AFSS的设计分为四个相互配合的模块:学习充分性度量(Learning Sufficiency Metric, LSM)、三级采样策略、持续复习机制、以及周期性状态更新。
学习充分性度量:取弱项而非取平均
AFSS通过一个简洁的公式衡量每张图片是否已被充分学习:
Learning Sufficiency = min(Precision, Recall)
对每张训练图片分别计算检测精确率(Precision)和召回率(Recall),取两者中的最小值 作为该图片的学习充分性指标。这样做的核心思路是聚焦弱项:只要分类或定位中任何一项不可靠,就认为这张图片尚未被充分学习。
论文也对比了其他度量方式的效果。基于Loss的度量过早饱和,最终精度仅46.0 AP;基于梯度的度量虽然精度尚可(46.9 AP)但增加了计算开销;F1 Score同样存在饱和问题(46.6 AP)。而min(Precision, Recall)在精度(47.2 AP)和加速(1.54倍)上均取得最优结果。
值得注意的是,现代YOLO训练流程本身就会计算Precision和Recall,因此这一度量几乎不增加额外计算开销。
三级分类与差异化采样
根据学习充分性的数值,AFSS将所有训练图片动态分为三个级别:
| 级别 | 判定条件 | 每epoch采样策略 |
|---|---|---|
| Easy(简单) | min(P, R) > 0.85 | 仅采样2% |
| Moderate(中等) | 0.55 ≤ min(P, R) ≤ 0.85 | 采样40%,保证每3个epoch至少出现一次 |
| Hard(困难) | min(P, R) < 0.55 | 全部参与训练 |
这三级策略的核心逻辑是:简单图片大幅削减、中等图片适度保留、困难图片充分学习。
持续复习:防止"学会又忘"
对Easy图片仅采样2%,如何防止遗忘?AFSS引入了**持续复习(Continuous Review)**机制:
-
强制复习:超过10个epoch未被使用的Easy图片优先被召回参与训练
-
随机多样性:剩余配额从Easy图片中随机抽取,维持曝光多样性
-
总量约束:强制复习部分不超过Easy采样总量的一半(即不超过1%)
对Moderate图片也有类似的**短期覆盖(Short-Term Coverage)**机制:连续2个epoch未使用的Moderate图片会被强制选入下一轮训练,确保每张Moderate图片至少每3个epoch出现一次。剩余配额随机补齐到40%。
周期性状态更新
每张图片的Precision、Recall和上次使用时间构成一个状态字典,每5个epoch更新一次。这个频率是精心平衡的结果:每epoch更新(间隔=1)计算开销太大,加速仅1.26倍;每10个epoch更新则状态过时,精度降至45.8 AP。每5个epoch更新在精度(47.2 AP)和加速(1.54倍)之间取得最优平衡。
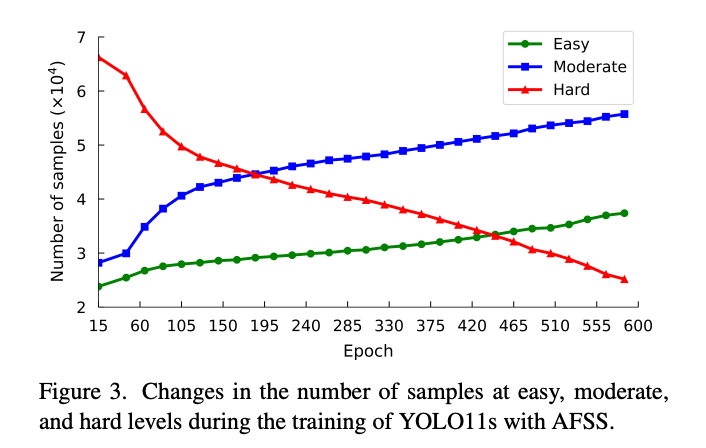
随着训练推进,越来越多图片从Hard迁移到Moderate再到Easy,模型自动将注意力集中在剩余的困难样本上。以YOLO11s在MS COCO上的训练为例:Epoch 100时仍使用78.8%的图片(约93k/118k),Epoch 300时降至69.5%(约82k/118k),到Epoch 600时仅使用36.4%(约43k/118k)。
图片来源于原论文
三、60种配置实验:4代YOLO x 5个尺度 x 4个数据集
AFSS的实验覆盖面在YOLO相关研究中相当罕见:4个数据集(MS COCO 2017、PASCAL VOC 2007、DOTA-v1.0、DIOR-R)、4代YOLO(YOLOv8、YOLOv10、YOLO11、YOLO12)、5个模型尺度(n/s/m/l/x),共计60种模型-数据集配置(自然图像4代YOLO×5尺度×2数据集=40种,遥感2代YOLO-OBB×5尺度×2数据集=20种)。所有实验基于2块RTX 4090完成。
MS COCO 2017:加速1.43-1.68倍
下表展示AFSS在MS COCO 2017上各模型的精度和训练时间对比(部分代表性配置):
| 模型 | 原始AP | +AFSS AP | 原始时间(h) | +AFSS时间(h) | 加速 |
|---|---|---|---|---|---|
| YOLOv8n | 37.3 | 37.4 | 30.4 | 21.2 | 1.43x |
| YOLO11s | 47.0 | 47.2 | 43.9 | 28.4 | 1.54x |
| YOLO12m | 52.5 | 52.6 | 111.3 | 68.7 | 1.62x |
| YOLO11x | 54.7 | 54.9 | 161.6 | 96.1 | 1.68x |
| YOLO12x | 55.2 | 55.4 | 260.6 | 154.8 | 1.68x |
两个重要规律浮现:模型越大,加速越明显 ------n尺度加速约1.43-1.48倍,x尺度达到1.67-1.68倍。这是因为大模型学习能力更强,能更快将图片"学会"并归入Easy类别。此外,在已测试的全部60种配置中,精度均持平或提升,没有任何一个配置出现精度下降。
PASCAL VOC 2007:加速1.60-1.69倍
VOC数据集规模较小,冗余更集中,加速比COCO更明显。代表性结果:
| 模型 | 原始mAP | +AFSS mAP | 原始时间(h) | +AFSS时间(h) | 加速 |
|---|---|---|---|---|---|
| YOLOv8n | 75.9 | 76.0 | 4.5 | 2.8 | 1.60x |
| YOLO11s | 81.7 | 81.8 | 6.9 | 4.2 | 1.64x |
| YOLO12x | 86.2 | 86.4 | 40.3 | 23.8 | 1.69x |
遥感数据集:加速1.63-1.70倍
在DOTA-v1.0和DIOR-R两个旋转目标检测数据集上,AFSS展现了更大的加速潜力。遥感图像分辨率更高(DOTA使用1024x1024,DIOR-R使用800x800),冗余计算占比更大,加速效果更显著。
| 模型 | 数据集 | 原始mAP | +AFSS mAP | 加速 |
|---|---|---|---|---|
| YOLOv8n-OBB | DOTA-v1.0 | 78.0 | 78.1 | 1.63x |
| YOLO11x-OBB | DOTA-v1.0 | 81.3 | 81.4 | 1.69x |
| YOLOv8x-OBB | DIOR-R | 83.6 | 83.6 | 1.70x |
| YOLO11x-OBB | DIOR-R | 83.6 | 83.7 | 1.70x |
与现有训练加速策略对比
论文以YOLO11s+MS COCO为基准,对比了四种常见的训练加速策略:
| 方法 | AP | 加速 | AP变化 |
|---|---|---|---|
| Baseline | 47.0 | --- | --- |
| Curriculum Learning | 43.7 | 1.35x | -3.3 |
| Self-Paced Learning | 44.5 | 1.30x | -2.5 |
| Data Pruning | 40.5 | 1.38x | -6.5 |
| Dataset Distillation | 35.6 | 1.50x | -11.4 |
| AFSS | 47.2 | 1.54x | +0.2 |
Curriculum Learning和Self-Paced Learning虽然加速训练,但都以明显的精度损失为代价(分别-3.3和-2.5 AP)。Data Pruning和Dataset Distillation的精度下降更为严重(-6.5和-11.4 AP)。AFSS是唯一在获得最高加速的同时还提升了精度的方法。

图片来源于原论文
四、消融实验:四个模块和超参数敏感性
模块贡献分析
论文以YOLO11s+MS COCO为基准,逐步叠加各模块观察效果(LSM=学习充分性度量,CR=持续复习,STC=短期覆盖,SU=状态更新):
| LSM | CR | STC | SU | AP | 加速 |
|---|---|---|---|---|---|
| --- | --- | --- | --- | 47.0 | --- |
| ✓ | --- | --- | --- | 44.8 | 1.45x |
| ✓ | ✓ | --- | --- | 45.5 | 1.34x |
| ✓ | ✓ | ✓ | --- | 46.6 | 1.31x |
| ✓ | ✓ | --- | ✓ | 47.2 | 1.26x |
| ✓ | ✓ | ✓ | ✓ | 47.2 | 1.54x |
仅使用LSM进行难度过滤可获得1.45倍加速,但精度下降至44.8 AP(-2.2)。逐步加入CR和STC后精度逐渐恢复(45.5、46.6),但加速也相应下降。加入SU后精度恢复至47.2 AP,但加速降至1.26倍。只有四个模块全部配合,才能同时实现47.2 AP和1.54倍加速------各模块缺一不可。
超参数敏感性
论文系统测试了三个关键超参数的影响:
持续复习间隔(Easy图片强制复习的epoch间隔):
| 间隔 | AP | 加速 |
|---|---|---|
| 5 | 47.2 | 1.49x |
| 10 | 47.2 | 1.54x |
| 15 | 45.7 | 1.58x |
| 20 | 44.8 | 1.63x |
间隔10为最优选择。间隔太短(5)复习过于频繁,间隔太长(15、20)则引起遗忘,精度分别降至45.7和44.8 AP。
短期覆盖间隔(Moderate图片强制出现的最大epoch间隔):
| 间隔 | AP | 加速 |
|---|---|---|
| 2 | 47.2 | 1.53x |
| 3 | 47.2 | 1.54x |
| 4 | 46.0 | 1.55x |
| 5 | 44.2 | 1.56x |
间隔3为最优。间隔2过于频繁,间隔4和5则导致Moderate图片覆盖不足,精度明显下降。
状态更新间隔:
| 间隔 | AP | 加速 |
|---|---|---|
| 1 | 47.2 | 1.26x |
| 5 | 47.2 | 1.54x |
| 10 | 45.8 | 1.72x |
| 15 | 43.7 | 1.93x |
这组实验揭示了一个有趣的权衡:更新越频繁,状态越准确,但计算开销越大。间隔1虽然精度最优但加速仅1.26倍;间隔10和15加速虽大但状态过时导致精度下降。间隔5是精度和效率的最优平衡点。
图片来源于原论文
五、总结与思考
AFSS提出了一个简洁而有效的训练加速思路:通过min(Precision, Recall)度量每张图片的学习充分性,将训练数据动态分为三级并差异化采样,同时用持续复习和短期覆盖机制防止遗忘。在60种YOLO配置上实现1.43-1.70倍加速且精度不降,作为即插即用的训练策略,不修改模型架构,不增加推理开销。
