ElasticSearch
此文档根据B站"编程不良人"博主的视频学习后总结而成,发布此平台的目的主要是为个人笔记所用。
一、什么是RestFul
**rest:**资源的表现层状态转化(Representational State Tranfer)是一种设计原则,设计约束,设计思路。
**restFul:**是一种软件架构风格。一个架构的设计如果遵循Rest设计原则,那么这个架构为RestFul架构风格
**资源:**网络中的一切事物统称为资源,一首歌,一张图片,一条数据。每一个资源都存在一个唯一的资源标识符URL
**表现层:**我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)
状态转化:如果客户端想要操作服务器,必须通过某种手段,让服务器发生"状态转化"(state transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
Rest原则就是指一个URL代表一个唯一资源,并且可以通过HTTP协议里面四个动词:GET、POST、PUT、DELETE对应四种服务器端的基本操作:GET用来获取资源,POST用来添加资源(也可以用来更新资源),PUT用来更新资源,DELETE用来删除资源。
基于restFul风格编码
二、什么是全文检索
全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程
检索:索(建立索引)检(检索索引)
栈内检索和栈外检索
全文检索(Full-Text Retrieval)以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。
关于全文检索,我们要知道:
1. 只处理文本
2.不处理语义
3.搜索时英文不区分大小写
4.结果列表有相关度排序。
三、什么是ElasticSearch
ElasticSearch 简称ES ,**是基于Apach lucene构建的开源搜索引擎,是当前流行的企业级搜索引擎。**Lucene本身就可以被认为迄今为止性能最好的一款开源搜索引擎工具包,但是Lucene的API相对复杂,需要深厚的搜索理论。很难集成到实际的应用中去。但是ES是采用Java语言编写,提供了简单易用的RestFul API,开发者可以使用其简单的搜索功能,从而避免Lucene的复杂性。
四、ES的诞生
伦敦的公寓内,Shay Banon 正在忙着寻找工作,而他的妻子正在蓝带 (Le Cordon Bleu) 烹饪学校学习厨艺。在空闲时间,他开始编写搜索引擎来帮助妻子管理越来越丰富的菜谱。
他的首个迭代版本叫做 Compass。第二个迭代版本就是 Elasticsearch(基于 Apache Lucene 开发)。他将 Elasticsearch 作为开源产品发布给公众,并创建了 #elasticsearch IRC 通道,剩下来就是静待用户出现了。
公众反响十分强烈。用户自然而然地就喜欢上了这一软件。由于使用量急速攀升,此软件开始有了自己的社区,并引起了人们的高度关注,尤其引发了 Steven Schuurman、Uri Boness 和 Simon Willnauer 的浓厚兴趣。他们四人最终共同组建了一家搜索公司。
五、ES的应用场景
ES主要以轻量级JSON作为数据存储格式,这点与MongoDB有点类似,但它在读写性能上优于MongoDB。同时也支持地理位置查询,还方便地理位置和文本混合查询,以及在统计、日志类数据存储和分析、可视化这方面是引领者。
-
国外:
-
Wikipedia(维基百科)使用ES提供全文搜索并高亮关键字
-
stackOverflow (IT问答网站)结合全文与地理位置查询,GitHub使用Elasticsearch检索1300亿行的代码
-
-
国内
- 百度(在云分析、网盟、预测、文库、钱包、风控等业务上都应用了ES,单集群每天导入30TB+数据,总共每天60TB+)
- 新浪、阿里巴巴、腾讯等公司均有对ES的使用
使用比较广泛的平台ELK(Elasticsearch、Logstash、Kibana)。
六、ES的安装
-
安装准备
-
centos7
-
java 8
-
elastic 6.8.0+
-
-
配置环境变量
properties# 配置path vi ect/profile/ export JAVA_HOME=/JDK/jdkTar/jdk1.8.0_171 export PATH=$PATH:$JAVA_HOME/bin # 重新加载资源 source /etc/profile -
重新加载资源 source /etc/profile
-
es只能在普通用户状态下可以使用,所以要先创建一个用户
properties#1.创建用户组 groupadd es #2.创建用户 useradd es -g es #3.更新密码 passwd es #4.切换用户 su 用户名 #5.检测当前用户是否是普通用户 who am i -
上传安装
properties#1.上传 rz #2.解压 tar -zxvf elasticsearch-6.2.4.tar.gz #3.进入bin目录启动es ./elasticsearch #4.模拟浏览器(curl) 测试es服务是否开启 curl http://localhost:9200 #5.注意,es和redis默认只允许本地连接 -
分布式搜索引擎服务(端口)
- web端口 9200 (浏览器使用)
- tcp端口:9300 (Java连接使用)
-
开启远程连接权限
properties#1.前往conf文件夹中修改 elasticsearch.yml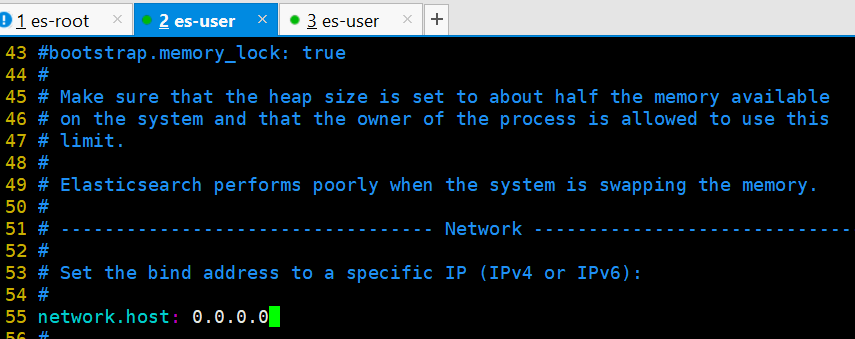 properties
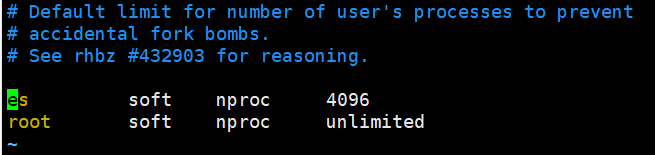
properties#2.重新启动es服务 #3.出现错误 -ERROR: [3] bootstrap checks failed [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] [2]: max number of threads [3872] for user [es] is too low, increase to at least [4096] [3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] #4.解决错误,通过root用户修改配置文件 - vim /etc/security/limits.conf 追加内容 * soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 #5.重新登陆(切换用户 su 用户名) 检查配置是否生效 ulimit -Hn ulimit -Sn ulimit -Hu ulimit -Su #6.解决错误【2】 使用root用户修改系统配置 vim /etc/security/limits.d/20-nproc.conf #修改如图所示
properties
#7.解决错误【3】 使用root用户修改系统配置
vim /etc/sysctl.conf
vm.max_map_count=655360
#8.检测以上命令是否生效
sysctl -p
properties
#9.使用root身份关闭防火墙
systemctl disable firewalld.service
#10.重新登录,开启服务,使用浏览器访问 -- ./elasticsearch -d 守护进程(后台运行)
http://192.168.75.131:9200/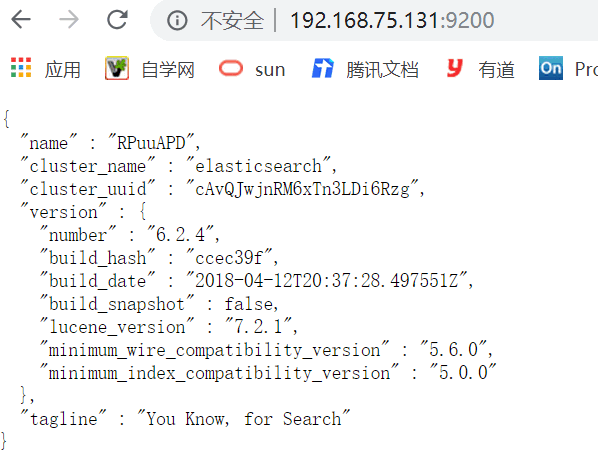
七、ES中基本概念
1.接近实时(NRT Near Real Time)
**Elasticsearch是一个接近实时的搜索平台。**这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒内)
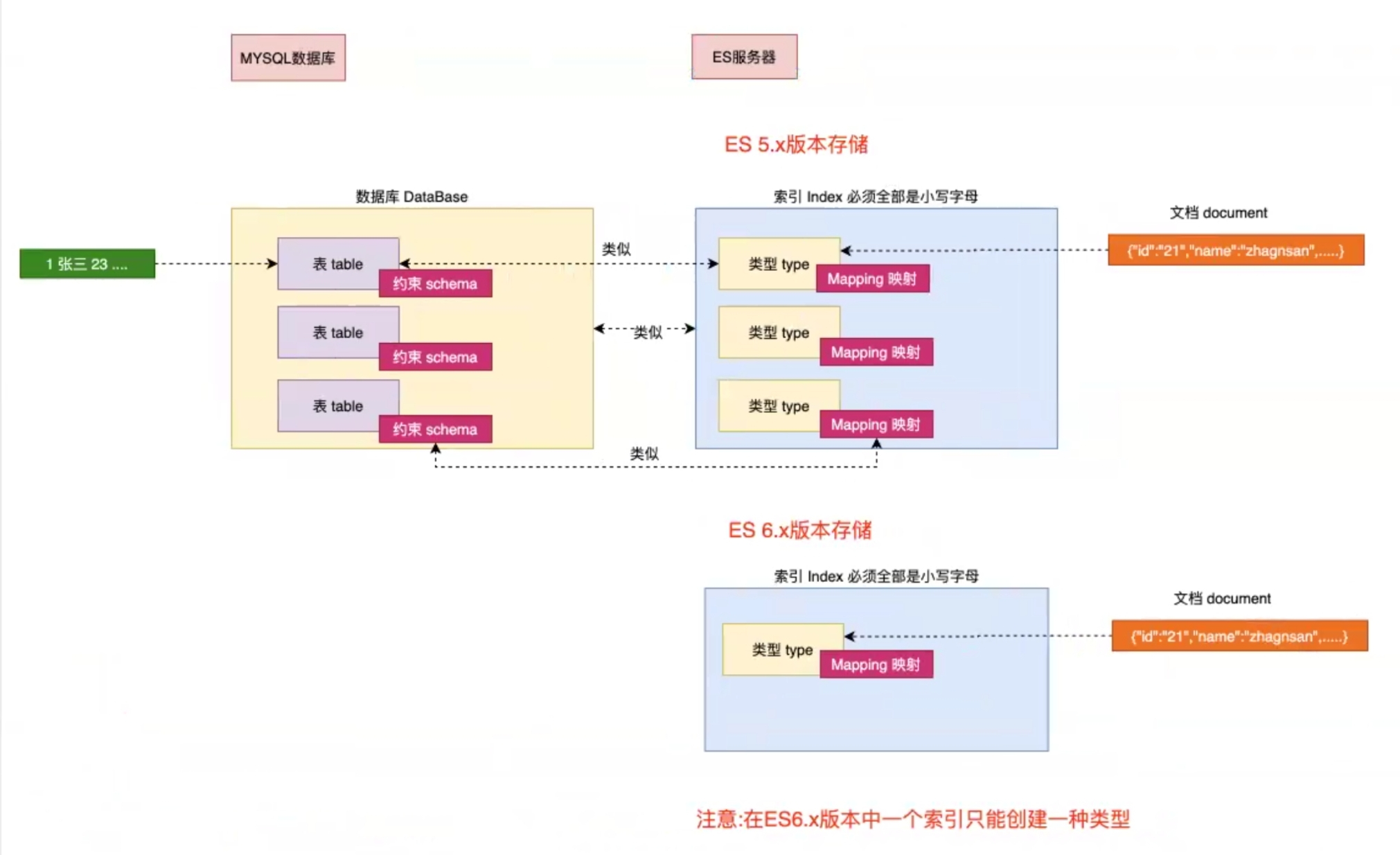
2.索引(index)
**一个索引就是一个拥有几分相似特征的文档的集合。**比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。**一个索引由一个名字来标识(必须全部是小写字母的),当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。索引类似于关系型数据库中的Database的概念。**在一个集群中,如果你想,可以定义多个任意多的索引。
3.类型(type)
**在一个索引中,你可以定义一种或多种类型。**一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营了一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。类型类似于关系型数据库中Table的概念
备注:在5.x版本以前可以在一个索引中定义多个类型,6.x之后版本也可以实用,但是不推荐,在7~8.x版本中彻底移除了一个索引中创建多个类型
4.映射(Mapping)
Mapping 是ES中一个很重要的内容,它类似于传统关系型数据库中table中的schema(约束),用于定义一个索引(index)中的类型(type)的数据的结构 。在ES中,我们可以手动创建type(相当于table)和mapping(相当于schema),也可以采用默认创建方式。在默认配置下,ES可以根据插入的数据自动地创建type及其mapping。mapping中主要包括字段名、字段数据类型和字段索引类型
5.文档(document)
**一个文档是一个可被索引的基础信息单元,类似于表中的一条记录。**比如,你可以拥有一个员工的文档,也可以拥有某个商品的一个文档,文档采用了轻量级的数据交换格式Json(Javascript Object Notation)来表示
6.概念关系图
八、Kibana(对es中的数据进行可视化的一个工具)
Kibana是一个针对elasticsearch的开源分析及可视化平台,实用kibana可以查询、查看并与存储在ES索引中的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据
Kibana版本必须和elasticsearch严格保持一致
properties
# 1.下载Kibana
https://www.elastic.co/cn/downloads/past-releases#kibana
# 2.安装下载的Kibana
rpm -ivh kibana-6.2.4-x86_64.rpm
# 3.查找Kibana安装位置
find / -name kibana
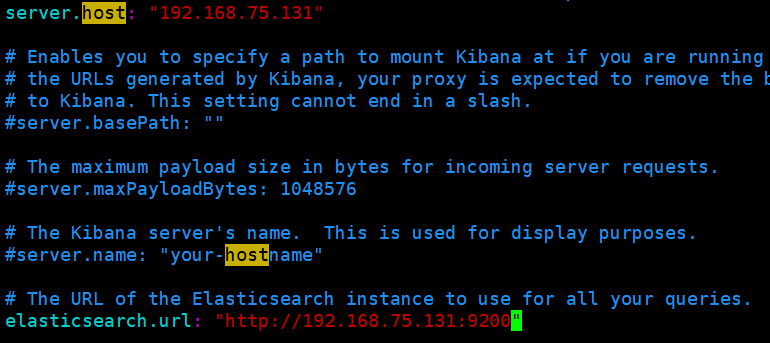
# 4.root用户下编辑kibana配置文件
vim /etc/kibana/kibana.yml
# 5.修改如下配置
server.host: "192.168.75.131" #ES主机名
elasticsearch.url: "http://192.168.75.142:9200" #ES服务器地址名文件属主更改为es用户:
chown -R es /home/es/kibana-6.8.0-linux-x86_64
chown -R es /home/es/elasticsearch-6.8.0
properties
#6.查看Kibana服务
systemctl status kibana
#7.启动kibana服务
systemctl start kibana
#注意6.8开启方式为 ./bin/kibana
#8.通过浏览器进入Kibana服务
http://192.168.75.142:5601
九、Kibana的基本操作
1.索引(index的基本操作)
PUT /dangdang/ #创建一个dangdang索引
DELETE /dangdang #删除
DELETE /* #删除
GET /dangdang #获取
GET /_cat/indices?v #获取索引详细信息2.类型(type)的基本操作
创建类型
json
#1.创建/ems索引并创建emp类型
PUT ems
{
"mappings":{
"emp":{
"properties":{
"id":{
"type":"keyword"
},
"name":{
"type": "text"
},
"age":{
"type": "integer"
},
"bir":{
"type": "date"
}
}
}
}
}
//注意:这种方式创建类型要求索引不能存在
#2.查看索引中索引的映射
GET /dangdang/_mappingMapping Type:text、keyword、date、integer 、long 、double 、boolean or ip
3.文档操作
添加文档
json
#文档操作:插入一条文档 Put/索引/类型/1
#method1
PUT /ems/emp/2
{
"id":"1",
"name":"刘备",
"age":18,
"bir":"2000-02-28"
}
#method2 先生成_id,再更新数据
POST /ems/emp/
{
"id":"1",
"name":"刘备",
"age":18,
"bir":"2000-02-28"
}查看文档
json
#查看一条文档 GET /索引/类型/_id
GET /xiaozhi/problem/4
#结果
{
"_index": "xiaozhi",
"_type": "problem",
"_id": "4",
"_version": 1,
"found": true, #找到
"_source": {
"id": 1,
"title": "xiaohaimian",
"answer": "wozhunbeihaolewozhunbeihaole"
}
}更新文档
json
#方法一:不保留原始数据(先删除再插入)
POST /xiaozhi/problem/NzN3FXcBuz237NSSPdiq
{
"title":"daxingxing"
}
#原有
"_source": {
"id": 1,
"title": "xiaohaimian",
"answer": "wozhunbeihaolewozhunbeihaole"
}
#结果
"_source": {
"title": "daxingxing"
}
#方法二:保留原有数据更新(先查找原始数据,在原始数据的基础上进行更新)
POST xiaozhi/problem/ODN-FXcBuz237NSSrtgw/_update #_update
{
"doc":{ #doc
"title":"daxingxing"
}
}
#原有
"_source": {
"id": 1,
"title": "xiaohaimian",
"answer": "wozhunbeihaolewozhunbeihaole"
}
#结果
"_source": {
"id": 1,
"title": "daxingxing",
"answer": "wozhunbeihaolewozhunbeihaole"
}
#方法二补充 自动添加未有的类型【不推荐、自动具有未知性】
POST xiaozhi/problem/ODN-FXcBuz237NSSrtgw/_update #_update
{
"doc":{ #doc
"title":"daxingxing",
"dept":"yanfa"
}
}
#方法三 脚本更新script【了解即可】
POST /ems/emp/2/_update
{
"script": "ctx._source.age+=3"
}
#原来
"_source": {
"id": "1",
"name": "刘备",
"age": 18, #年龄修改成功
"bir": "2000-02-28"
}
#现在
"_source": {
"id": "1",
"name": "刘备",
"age": 21, #年龄修改成功
"bir": "2000-02-28"
}批量操作 _bulk
json
# _bulk(批量操作) 添加(index) 删除(delete) 修改(update)
PUT /ems/emp/_bulk
{"index":{"_id":"5"}}
{"name":"张飞","age":"35","id":"5","bir":"1999-02-15"}
{"delete":{"_id":"2"}}
{"update":{"_id":"3"}}
{"doc":{"age":100}}
#注意 一条文档只能占用一行删除文档
json
#删除一条文档
DELETE xiaozhi/problem/3
#结果
{
"_index": "xiaozhi",
"_type": "problem",
"_id": "3",
"_version": 2,
"result": "deleted", #删除成功
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}十、ES中的高级检索(Query)
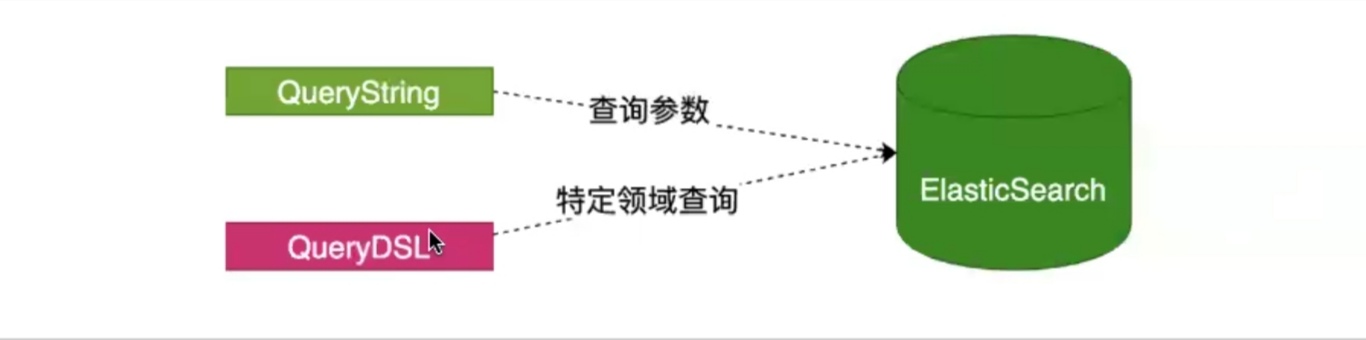
1.检索方式_search
ES官方提供了两种检索方式:一种是通过URL参数进行搜索,另一是通过DSL(Domain Specified Language)进行搜索。官方更推荐使用第二种方式,第二种方式是基于传递JSON作为请求体(request body)格式与ES进行交互,这种方式更强大,更简洁。
-
使用语法
URL:查询:GET /索引/类型/_search?参数
DSL查询:GET /索引/类型/_search{}
http
#_search 查询索引下的所有数据
GET /xiaozhi/problem/_search?q=*
#sort 对查出来的数据进行年龄字段排序 默认升序 此例:降序 默认10条
GET /ems/emp/_search?q=*&sort=age:desc
#size 限制查询出的数据条数
GET /ems/emp/_search?q=*&sort=age:desc&size=2
#from 等同于start 开始记录条数
GET /ems/emp/_search?q=*&sort=age:desc&size=2&from=1
#_source 查询出的结果,筛选字段
GET /ems/emp/_search?q=*&sort=age:desc&size=2&from=1&_source=name
//多个字段
GET /ems/emp/_search?q=*&sort=age:desc&size=2&from=1&_source=name,age2.Query DSL 方式查询 DSL 复杂查询
2.1 查询所有(match_all)
**math_all关键字:**返回索引中的全部文档
http
GET /ems/emp/_search
{
"query": {
"match_all": {}
}
}2.2 查询所有并排序 sort 默认asc
**sort关键字:**指定查询结果中排序。 默认asc text 类型无法排序
json
#单字段排序
GET /ems/emp/_search
{
"query": {
"match_all": {}
}
, "sort": [
{
"age": {
"order": "desc"
}
}
]
}
#多字段排序
GET /ems/emp/_search
{
"query": {
"match_all": {}
}
, "sort": [
{
"age": {
"order": "desc"
}
},
{
"bir": {
"order": "desc"
}
}
]
}2.3 查询结果中返回指定条数(size)
**size关键字:**指定查询结果中返回指定条数。 默认返回10条
http
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"size":2
}2.4 查询结果分页 limit start(from) size
from关键字:指定查询结果中的开始记录条数
http
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"size":2,
"from":1
}2.5指定查询结果中 返回指定字段 _source
json
#单个字段
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"size":2,
"from":1,
"_source": "name"
}
#多个字段
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"size":2,
"from":1,
"_source": ["name","age"]
}响应结果解释:
json
{
"took": 7, #毫秒数
"timed_out": false, #是否超时
"_shards": {
"total": 5, #集群分片
"successful": 5, #5个完整分片
"skipped": 0,
"failed": 0
},
"hits": { #基重对象
"total": 4, #最大记录数
"max_score": 1, #最大得分
"hits": [ #返回的符合条件的文档对象
{
"_index": "ems",
"_type": "emp",
"_id": "2",
"_score": 1,
"_source": {
"name": "刘备",
"age": 55
}
},............以下基于query
2.6 term查询 基于关键词查询【字典中已有的】
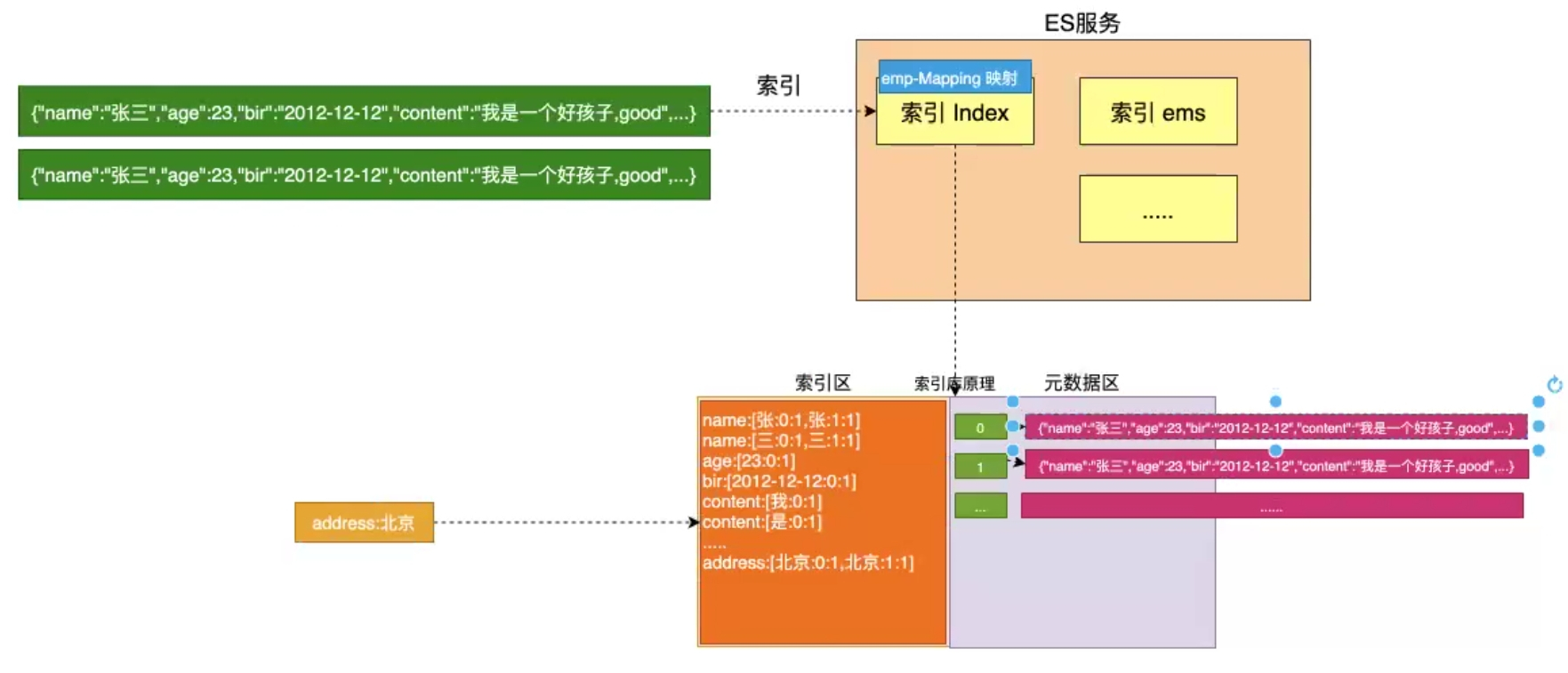
**注意:**type 中只有 text 类型会进行分词。ES中默认使用分词器是标准分词 standard
中文为单字分词 **例:**贾 宇 超
英文为单词分词 例:spring boot
http
GET /ems/emp/_search
{
"query": {
"term": {
"age": {
"value": 100
}
}
}
}2.6.1 标准分词器演示
http
GET _analyze
{
"text": "java 是一个"
}
#响应结果
{
"tokens": [
{
"token": "java",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "是",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "一",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "个",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}2.6.2 ES索引底层存储原理
2.7 范围查询(range)
range 关键字:用来指定查询范围内的数据
http
GET ems/emp/_search
{
"query": {
"range": {
"age": {
"gte": 20, #大于等于
"lte": 50 #小于等于
}
}
}
}2.8 前缀查询(prefix)
**prefix关键字:**基于指定字段的前缀查询
http
GET ems/emp/_search
{
"query": {
"prefix": {
"name": {
"value": "张"
}
}
}
}
#注意:无法使用integer类型来进行前缀查询
"reason":"Can only use prefix queries on keyword and text fields - not on [age] which is of type [integer"2.9 通配符查询(wildcard)
**wildcart关键字:**通配符查询,可以使用?和*作为通配符来使用,?只可以匹配一个任意字符 *匹配0-n个
http
GET ems/emp/_search
{
"query": {
"wildcard": {
"name": {
"value": "张*" # ? 匹配一个
}
}
}
}2.10 多id查询(ids)
**ids关键字:**值为数组类型,用来根据一组id获取多个对应的文档
http
GET ems/emp/_search
{
"query": {
"ids": {
"values": ["2","5","1"]
}
}
}2.11 fuzzy 模糊查询
**fuzzy关键字:**模糊查询 ,
最大模糊错误距离 必须在 0-2之间 例:0个错误 2两个错误
#搜索关键词长度为2 不允许存在模糊
#搜索关键词长度为3-5 允许0-1个模糊
#搜索关键词长度大于5 允许0-2个模糊
http
GET xiaozhi/problem/_search
{
"query": {
"fuzzy": {
"title": "daxixing"
}
}
}2.12 布尔查询(bool)
bool 关键字:用来组合多个条件实现复杂查询
must :相当于 && 同时成立
should :相当于 || 成立一个即可
must_not :相当于 ! 不能满足任何一个
json
GET ems/emp/_search
{
"query": {
"bool": {
"should": [ #should must_not must
{
"term": {
"age": {
"value": "35"
}
}
},
{
"range": { #其他关键字均可 ids wildcard fuzzy prefix
"age": {
"gte": 10,
"lte": 50
}
}
}
]
}
}
}2.12 高亮查询
**highlight关键字:**查询结果做二次渲染【高亮】 可以在highlight中使用
pre_tags和post_tags
json
GET /ems/emp/_search
{
"query": {
"term": {
"name": {
"value": "关"
}
}
}
, "highlight": {
"pre_tags": ["<span style='color:red'>"],
"post_tags": ["</span>"],
"fields": {
"name": {}
}
}
}2.13 多字段查询(multi_match)
**multi_match关键词:**搜索比较只能
1.如果搜索的字段分词,他会对query先进行分词 然后再拿分词之后的结果进行搜索
2.如果搜索的字段不分词,那么他会直接使用query整体进行该字段搜索
3.建议query中存放可被分词的对象。
http
GET /ems/emp/_search
{
"query": {
"multi_match": {
"query": "子",
"fields": ["name","content"]
}
}
}2.14 多字段分词查询(query_string)
json
#默认分词,先对query中的字段进行分词,然后在 default_field 字段中进行查询
GET /ems/emp/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "es is open framework"
}
}
}
#功能和 multi_match 区别不大 但是 它可以加自己的分词器 analyzer
GET /ems/emp/_search
{
"query": {
"query_string": {
"query": "子",
"fields": ["name","content"]
#,"analyzer": "ik_max_word"
}
}
}十一、IK分词器
NOTE(备注):默认ES中采用标准分词其进行分词,这种方式并不适合中文网站,因此需要修改该ES对中文友好分词,从而达到更佳的搜索效果
1.在线安装IK
在线安装IK(v5.5.1版本之后支持在线安装)
shell
# 1.在es安装目录中执行命令
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip
# 2.清空es中的数据(ik和原有的数据会产生冲突) 删除根目录下的data文件夹即可
rm -rf data/
# 3.开启es服务
./elasticsearch
# 4.重启Kibana服务
systemctl restart kibana
# 5.在线安装IK 配置文件 在conf/analysis-ikp 【千万注意】2.ik_max_word 和 ik_smart
ik_max_word 和 ik_smart 什么区别?
- ik_max_word: 会将文本做最细粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌",会穷尽各种可能的组合,适合 Term Query;
- ik_smart: 会做最粗粒度的拆分,比如会将"中华人民共和国国歌"拆分为"中华人民共和国,国歌",适合 Phrase 查询。
http
# ik_smart
GET /_analyze
{
"text": "中华人人民共和国国歌"
, "analyzer": "ik_smart"
}
# ik_max_word
GET /_analyze
{
"text": "中华人人民共和国国歌"
, "analyzer": "ik_max_word"
}3.测试
json
PUT /dangdang
{
"mappings": {
"book":{
"properties": {
"id":{
"type": "integer"
},
"name":{
"type": "keyword"
},
"price":{
"type": "double"
},
"author":{
"type": "keyword"
},
"des":{
"type": "text"
, "analyzer": "ik_max_word"
,"search_analyzer": "ik_max_word" #默认和上面的分词器一致
},
"pubdate":{
"type": "date"
}
}
}
}
}4.本地安装【建议使用】
6.2.4 链接
shell
# 1.安装unzip工具 可以解压zip文件
yum install -y unzip
# 2.上传zip压缩包
unzip elast......
# 3.移动到es安装目录的plugins目录中
# 4.重启es生效
# 5.本地安装ik配置目录为 es安装目录中 /plugins/analysis-ik/config测试数据: 批量添加 保持一行
json
POST /dangdang/book/_bulk
{"index":{}}
{"id":"3","name":"spring快速","price":"49.5","pudate":"2001-05-13","author":"apring 资源丰富","des":"Spring每天为数百万的最终用户提供令人愉悦的体验-不管是串流电视, 联网汽车, 网上购物或无数其他创新解决方案"}
{"index":{}}
{"id":"4","name":"spring快产","price":"29.5","pudate":"2001-05-13","author":"apring 资源丰富","des":"Spring还得到了包括阿里巴巴,亚马逊,谷歌,微软等在内的所有科技巨头的贡献。"}
{"index":{}}
{"id":"5","name":"spring多产","price":"19.5","pudate":"2001-05-13","author":"apring 资源丰富","des":"Spring灵活而全面的扩展集和第三方库使开发人员可以构建几乎可以想象的任何应用程序。"}
{"index":{}}
{"id":"7","name":"spring弹簧灵活","price":"9.5","pudate":"2001-05-13","author":"apring 资源丰富","des":"Spring Framework的核心控制反转(IoC) 和 依赖注入(DI)功能为广泛的功能集提供了基础"}5.自定义扩词器+配置IK远程控制词典:
shell
# 1.把zip中的config文件夹放入到plugins中
cp -r test/elasticsearch/config /home/es/elasticsearch-6.2.4/plugins/analysis-ik/
# 2.创建ext_dict.dic 和 ext_stopword.dic 自定义 扩展词典/停用词典
touch ext_dict.dic
touch ext_stopword.dic
# 3.编辑配置文件
vim ../plugins/analysis-ik/config/IKAnalyzer.cfg.xml
# 注意:
1.文件必须UTF-8,否则无效
2.线上安装和本地安装的config目录位置不一致!!!
3.dic 词典文件中,一行只能写一个关键字
4.加入新的词典关键字配置,只会对新的索引生效!!!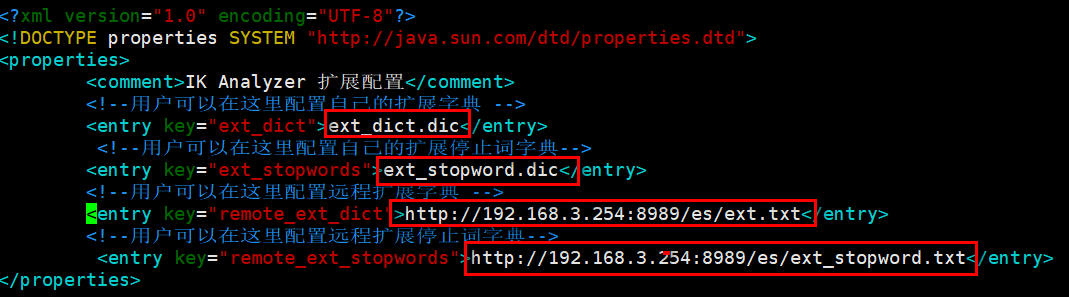
成功日志:

十二、 (过滤查询) Filter Query
1.过滤查询
其实准确来说,ES中的查询操作分为2种: 查询(query)和过滤(filter) 。查询即是之前提到的query查询,它 (查询)默认会计算每个返回文档的得分,然后根据得分排序。而过滤(filter)只会筛选出符合的文档,并不计算 得分,且它可以缓存文档 。所以,单从性能考虑,过滤比查询更快。
换句话说,过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时, 应先使用过滤操作过滤数据, 然后使用查询匹配数据。
2.过滤语法
NOTE(注意):在执行filter和query时。先执行filter再执行query
NOTE(注意):ES会自动缓存经常使用的过滤器。以加快性能
2.1 range过滤
http
GET /dangdang/book/_search
{
"query": {
"bool": {
"must": [ #再查询并计算得分
{
"term": {
"des": {
"value": "spring"
}
}
}
],
"filter": { #先过滤
"range": { #term 也可以过滤
"price": {
"gte": 20,
"lte": 50
}
}
}
}
}
}2.2 term过滤
http
GET /dangdang/book/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"des": {
"value": "spring"
}
}
}
],
"filter": {
"terms": {
"des": [
"程序",
"阿里巴巴"
]
}
}
}
}
}
}2.3 exist filter
过滤存在指定字段,获取字段不为空的索引记录使用
http
GET /dangdang/book/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value": "springTest"
}
}
}
],
"filter": {
"exists": {
"field": "des"
}
}
}
}
}2.4 ids filter
http
GET /dangdang/book/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"ids": {
"values": [
"pGiMGHcB9rNQvDxxVoOb",
"pWiNGHcB9rNQvDxxUoMG"
]
}
}
}
}
}十三、Java操作
1. ES和DB配合架构**【ES无法替代DB,ES的事务处理功能极差】**
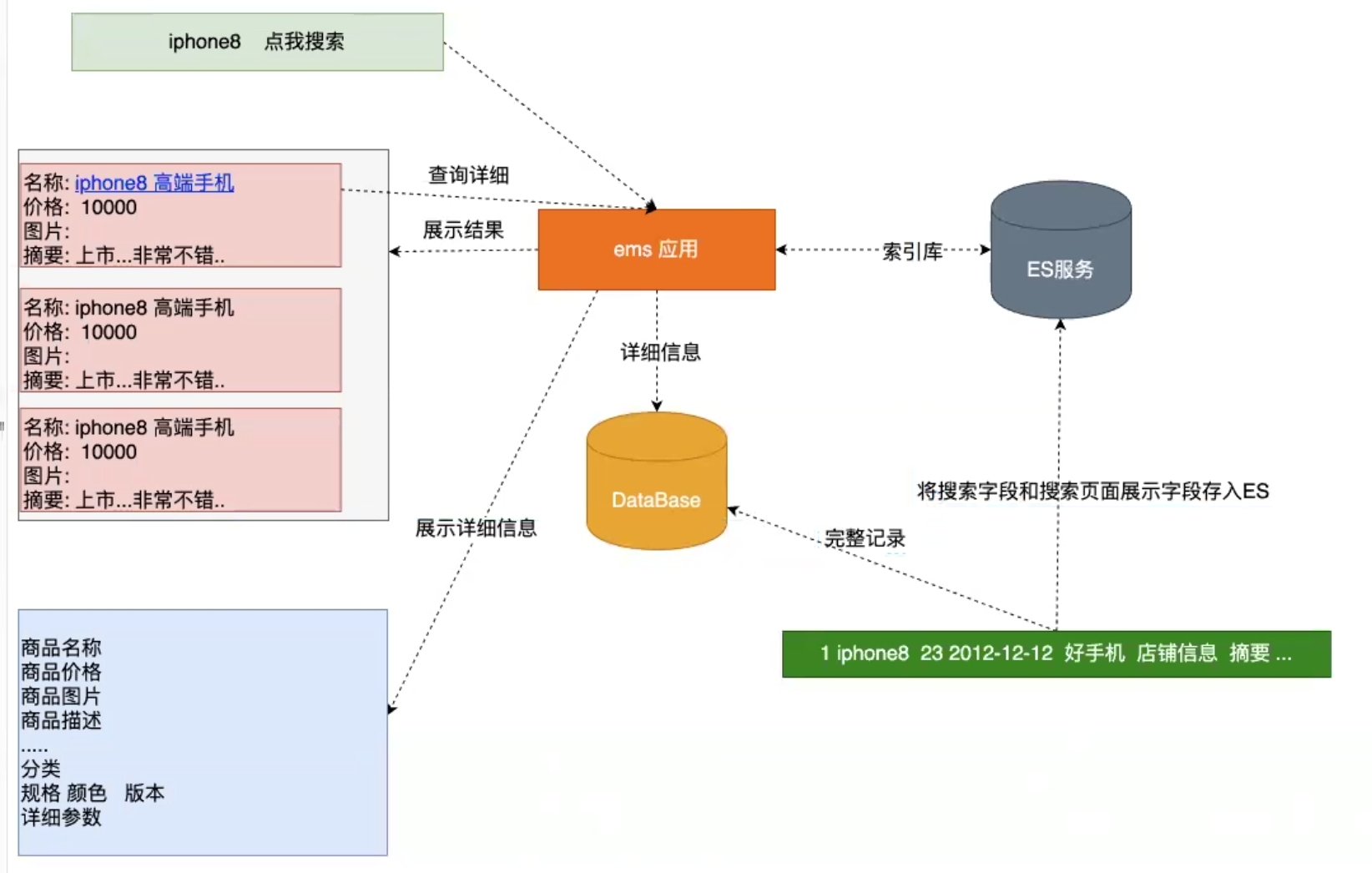
数据强一致性 :保证DB中数据和ES中的数据实时一致 【淘宝、京东】
数据最终一致性 : 在过了某一个时间段后,DB和ES中的数据保持一致 【哔哩哔哩】
2.引入依赖
xml
<!-- ES服务 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.2.4</version>
</dependency>
<!-- ES客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.2.4</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>transport-netty4-client</artifactId>
<version>6.2.4</version>
</dependency>
<!-- json -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>3.小源码剖析
java
//Settings.EMPTY 解释
public static final Settings EMPTY = (new Settings.Builder()).build();4.复杂查询案例
java
public class TestFilterQuery {
private TransportClient transportClient;
@Before
public void before() throws UnknownHostException {
transportClient = new PreBuiltTransportClient(Settings.EMPTY);
transportClient.addTransportAddress(new TransportAddress(InetAddress.getByName("192.168.75.131"), 9300));
}
@After
public void after(){
transportClient.close();
}
/**
* 用于测试复杂查询
*
* 多字段关键字查询
* 分页
* 排序
* 过滤
* 字段返回
* 高亮处理
*
*/
@Test
public void testSearch(){
String[] inclus= {"name","price","des"};
String[] excludes = {"id"};
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<span style='color:red;'>");
highlightBuilder.postTags("</span>");
highlightBuilder.field("des");
//顺序设置不能乱 先设置限制性约束 再进行过滤查询 然后query查询,最后显示高亮字段
SearchResponse searchResponse = transportClient.prepareSearch("dangdang")
.setTypes("book")
.setFrom(0)
.setSize(2)
.setSource(SearchSourceBuilder.searchSource().fetchSource(inclus, excludes))
.setPostFilter(QueryBuilders.rangeQuery("price").gte(0).lte(30))
.setQuery(QueryBuilders.multiMatchQuery("spring", "des", "name"))
.highlighter(highlightBuilder)
.get();
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
System.out.println("totalHits = " + totalHits);
float maxScore = hits.getMaxScore();
System.out.println("maxScore = " + maxScore);
SearchHit[] hits1 = hits.getHits();
for (SearchHit documentFields : hits1) {
System.out.println("getSourceAsString = " + documentFields.getSourceAsString());
System.out.println("getHighlightFields = " + documentFields.getHighlightFields());
}
}
}
}5.term bulk
java
/**
* 用于测试term
*/
@Test
public void testTerm(){
SearchResponse searchResponse = transportClient.prepareSearch("ems")
.setTypes("emp")
.setQuery(QueryBuilders.termQuery("name", "女孩")) //查询条件
.get();
long totalHits = searchResponse.getHits().getTotalHits();
float maxScore = searchResponse.getHits().getMaxScore();
System.out.println("totalHits = " + totalHits);
System.out.println("maxScore = " + maxScore);
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("hit = " + hit.getSourceAsString());
}
}
/**
* 用于测试bulk
*/
@Test
public void testBulk(){
//创建
Book book = new Book("18", "水浒传", 78.0, new Date(), "施耐庵", "天罡地煞水泊梁山");
IndexRequest indexRequest = new IndexRequest("dangdang", "book", book.getId()).source(JSONObject.toJSONStringWithDateFormat(book, "yyyy-MM-dd"), XContentType.JSON);
//更新
Book book1 = new Book();
book1.setDes("一群男人和一群女人的故事2");
UpdateRequest updateRequest = new UpdateRequest("dangdang", "book", "m8A8GXcBfhjxlQPVPTFa").doc(
JSONObject.toJSONString(book1), XContentType.JSON
);
//删除
DeleteRequest deleteRequest = new DeleteRequest("dangdang", "book", "ncBZGXcBfhjxlQPVeTEp");
BulkResponse bulkItemResponses = transportClient.prepareBulk()
// .add(indexRequest)
// .add(deleteRequest)
.add(updateRequest).get();
BulkItemResponse[] items = bulkItemResponses.getItems();
for (BulkItemResponse item : items) {
System.out.println("item.status() = " + item.status());
}
}十四、整合springboot
1.引入依赖
xml
<!--通过spring data 操作Es-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- 注意6.8版本的ES需要配合 2.2.5版本的springboot来使用 -->2.编写yml配置
yml
spring:
data:
elasticsearch:
cluster-nodes: 172.16.251.142:9300 3.客户端对象配置类 -->替换了transportClient对象 替换了yml配置6.2.4不可用
java
@Configuration
public class RestClientConfig extends AbstractElasticsearchConfiguration {
//@Value("${elasticsearch.rest.uri}")
//private String uri;
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}4.RestHighLevelClient rest客户端 【高级:自定义复杂查询使用】
4.1 基本操作
java
//案例 一 term查询
public void testQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("dangdang");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder
.query(QueryBuilders.termQuery("des","spring"))
.from(0)
.size(2)
.sort("price", SortOrder.DESC)
;
searchRequest.types("book").source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("hit = " + hit.getSourceAsString());
}
}
//案例二 批量查询
@Test
public void testBulk() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
IndexRequest indexRequest = new IndexRequest("dangdang", "book");
Book book = new Book();
book.setId("22");
book.setName("一千零一夜");
book.setPrice(64.5);
String bookJson = JSONObject.toJSONString(book);
indexRequest.source(bookJson,XContentType.JSON);
DeleteRequest deleteRequest = new DeleteRequest("dangdang", "book", "21");
bulkRequest.add(deleteRequest).add(indexRequest);
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
BulkItemResponse[] items = bulkResponse.getItems();
for (BulkItemResponse item : items) {
System.out.println("item = " + item);
System.out.println("item.status() = " + item.status());
}
}
//案例三 更新
//修改es中的数据
String videoJson = JSONObject.toJSONString(video);
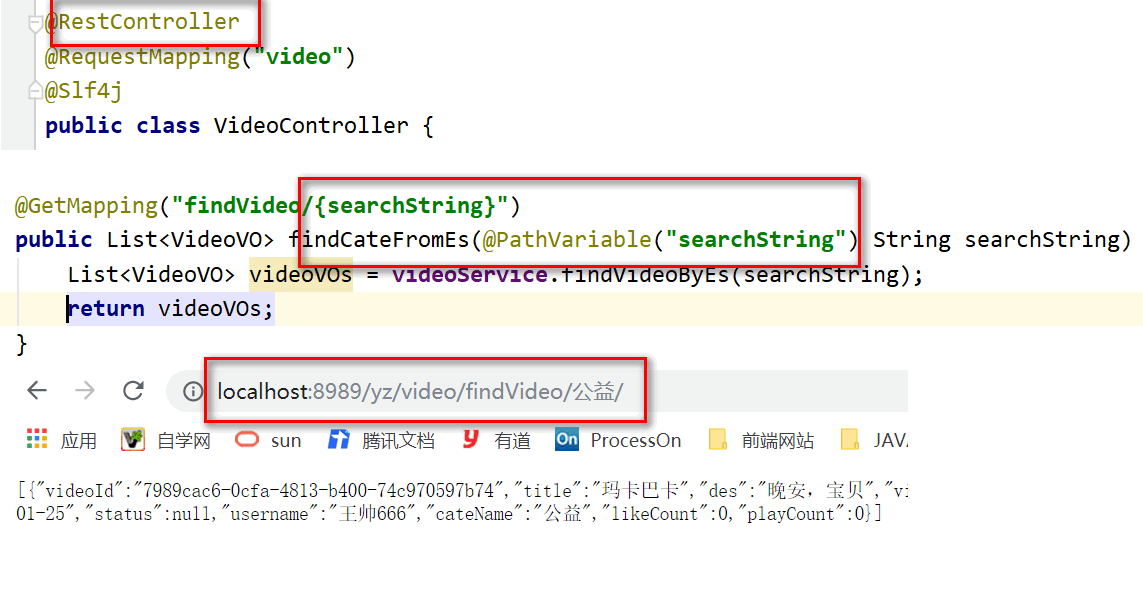
UpdateRequest updateRequest = new UpdateRequest("video","videovo",video.getVideoId());
updateRequest.doc(videoJson, XContentType.JSON);
restHighLevelClient.update(updateRequest,RequestOptions.DEFAULT);4.2 高亮复杂查询 RestHightLevelClient
java
@Test
public void testRestHighLevelClient() throws IOException, ParseException {
//设置高亮对象
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder
.field("*")
.requireFieldMatch(false)
.preTags("<span style='color:red;'>")
.postTags("</span>")
;
//创建请求对象
SearchRequest searchRequest = new SearchRequest("ems");
//创建搜索对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//设置参数
sourceBuilder
.query(QueryBuilders.termQuery("content","武当"))
.from(0)
.size(5)
.sort("age",SortOrder.DESC)
.highlighter(highlightBuilder);
//添加查询源
searchRequest.types("emp").source(sourceBuilder);
//开始查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//输出查询总记录条数
System.out.println(searchResponse.getHits().getTotalHits());
SearchHit[] hits = searchResponse.getHits().getHits();
ArrayList<Emp> emps = new ArrayList<>();
for (SearchHit hit : hits) {
Emp emp = new Emp();
//获取原始数据
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
Date bir = new SimpleDateFormat("yyyy-MM-dd").parse(sourceAsMap.get("bir").toString());
//添加原始数据
emp
.setId(sourceAsMap.get("id").toString())
.setAge(Integer.parseInt(sourceAsMap.get("age").toString()))
.setBir(bir)
.setName(sourceAsMap.get("name").toString())
.setAddress(sourceAsMap.get("address").toString())
.setContent(sourceAsMap.get("content").toString())
;
//高亮部分
Map<String, HighlightField> highMap = hit.getHighlightFields();
//替换有高亮的字段
if(highMap.containsKey("content")) emp.setContent(highMap.get("content").fragments()[0].toString());
if(highMap.containsKey("address")) emp.setAddress(highMap.get("address").fragments()[0].toString());
if(highMap.containsKey("name")) emp.setName(highMap.get("name").fragments()[0].toString());
emps.add(emp);
//原数据
System.out.println("hit = " + hit.getSourceAsString());
//高亮数据
System.out.println("getHighlightFields = " + hit.getHighlightFields().toString());
}
System.out.println("---------------------------------------");
//展示
System.out.println("emps = " + emps);
}5.ElasticSearchRepositoty接口
5.1简单基本查询
java
//添加 | 更新
/**
* 用于测试save
*/
@Test
public void testSave() {
Emp emp = new Emp();
emp.setId("dc4c1d23-f9c2-4837-aa2a-ff733ab84583")
// emp
.setBir(new Date())
.setName("张无忌")
.setAge(22)
.setAddress("武当派创始人,太极拳,武当剑法就是其所创建")
.setContent("武侠败类");
empRepository.save(emp);
}
//根据id删除一条
/**
* 用于测试del
*/
@Test
public void testDel() {
empRepository.deleteById("dc4c1d23-f9c2-4837-aa2a-ff733ab84583");
}
//删除所有
/**
* 用于测试delAll
*/
@Test
public void testDelAll(){
empRepository.deleteAll();
}
//检索一条 option
/**
* 用于测试find
*/
@Test
public void testFindOne(){
Optional<Emp> byId = empRepository.findById("dc4c1d23-f9c2-4837-aa2a-ff733ab84583");
System.out.println("byId = " + byId.get());
}
//查询所有
/**
* 用于测试All
*/
@Test
public void testFindAll(){
Iterable<Emp> all = empRepository.findAll();
all.forEach(emp -> System.out.println("emp = " + emp));
}
//查询所有排序
/**
* 用于测试findAllOrder
*/
@Test
public void testFindAllOrder(){
Iterable<Emp> age = empRepository.findAll(Sort.by(Sort.Order.asc("age")));
age.forEach(emp -> System.out.println("emp = " + emp));
}
//分页
/**
* 用于测试Page
*/
@Test
public void testFindByPage(){
Page<Emp> search = empRepository.search(QueryBuilders.matchAllQuery(), PageRequest.of(0, 3));
search.forEach(emp -> System.out.println("emp = " + emp));
}5.2自定义基本查询 ElasticsearchRepository
5.2.1.实体类
java
@Data
@ToString
@AllArgsConstructor
@NoArgsConstructor
/**
* //将这个对象转化为一个json文档
* @indexName 指定 index名字
* 要求,es服务器中不能存在此索引名
* @type 指定这个索引下的文档类型
* @Field 用在字段,代表mapping中的一个字段
* @Id 将id值为_id相匹配
*/
@Document(indexName = "ems")
@Accessors(chain = true)
public class Emp {
@Id
private String id;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String name;
@Field(type = FieldType.Integer)
private Integer age;
@Field(type = FieldType.Date)
@JsonFormat( pattern = "yyyy-MM-dd")
private Date bir;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String content;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String address;
}
@Document: 代表一个文档记录
indexName: 用来指定索引名称
type: 用来指定索引类型
@Id: 用来将对象中id和ES中_id映射
@Field: 用来指定ES中的字段对应Mapping
type: 用来指定ES中存储类型
analyzer: 用来指定使用哪种分词器
5.2.2.接口Repository
java
public interface EmpRepository extends ElasticsearchRepository<Emp,String> {
//根据姓名查询
List<Emp> findByName(String name);
//根据年龄查询
List<Emp> findByAge(Integer age);
//根据姓名和地址
List<Emp> findByNameAndAge(String name,Integer age);
//根据姓名或者年龄
List<Emp> findByNameOrAge(String name,Integer age);
//大于等于
List<Emp> findByAgeGreaterThanEqual(Integer age);
}5.2.3.测试
java
//基础查询 //根据名字 年龄 等
/**
* 用于测试ByName
*/
@Test
public void testByName(){
List<Emp> ems = empRepository.findByName("无忌");
ems.forEach(emp -> System.out.println("emp = " + emp));
}
/**
* 用于测试Age
*/
@Test
public void testAge(){
List<Emp> byAge = empRepository.findByAge(22);
byAge.forEach(emp -> System.out.println("emp = " + emp));
}
/**
* 用于测试or
*/
@Test
public void testNameOrAge(){
List<Emp> emps = empRepository.findByNameOrAge("无忌", 19);
emps.forEach(emp-> System.out.println("emp = " + emp));
}
/**
* 用于测试greteAndThan
*
*/
@Test
public void testGreaterTranEquals(){
List<Emp> byAgeGreaterThanEqual = empRepository.findByAgeGreaterThanEqual(19);
byAgeGreaterThanEqual.forEach(emp -> System.out.println("emp = " + emp));
}5.2.4 自定义基本查询语法:
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And |
findByNameAndPrice |
{"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or |
findByNameOrPrice |
{"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is |
findByName |
{"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not |
findByNameNot |
{"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between |
findByPriceBetween |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
LessThanEqual |
findByPriceLessThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
GreaterThanEqual |
findByPriceGreaterThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Before |
findByPriceBefore |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After |
findByPriceAfter |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like |
findByNameLike |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith |
findByNameStartingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith |
findByNameEndingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
Contains/Containing |
findByNameContaining |
{"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
In |
findByNameIn (Collection<String>names) |
{"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn |
findByNameNotIn (Collection<String>names) |
{"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
Near |
findByStoreNear |
Not Supported Yet ! |
True |
findByAvailableTrue |
{"bool" : {"must" : {"field" : {"available" : true}}}} |
False |
findByAvailableFalse |
{"bool" : {"must" : {"field" : {"available" : false}}}} |
OrderBy |
findByAvailable TrueOrderByNameDesc |
{"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
十五、Es中集群
15.1 相关概念
解决:单节点并发压力,物理存储上限
集群(cluster)
一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群 由一个唯一的名字标识,这个名字默认就是
elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定名字是一个好习惯【不要使用默认名字】,但是使用默认值来进行测试/开发也是不错的。
节点(node)
一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫 做"elasticsearch"的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做"elasticsearch"的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点, 这时启动一个节点,会默认创建并加入一个叫做"elasticsearch"的集群。
分片和复制(shards & replicas)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的"索引",这个"索引"可以被放置 到集群中的任何节点上。 分片之所以重要,主要有两方面的原因:
允许你水平分割/扩展你的内容容量允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的,用户无需多做操作。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。复制之所以重要,主要有两方面的原因:
在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要 (original/primary)分片置于同一节点上是非常重要的。 扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个 索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,这取决于你的集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的。
15.2 快速搭建集群
markdown
1. 将原有ES安装包复制三份
cp -r elasticsearch-6.2.4/ master/
cp -r elasticsearch-6.2.4/ slave1/
cp -r elasticsearch-6.2.4/ slave2/
2. 删除复制目录中data目录
#注意:由于复制目录之前使用过因此需要在创建集群时将原来数据删除
rm -rf master/data
rm -rf slave1/data
rm -rf slave2/data
3. 编辑没有文件夹中config目录中jvm.options文件跳转启动内存
vim master/config/jvm.options
vim slave1/config/jvm.options
vim slave2/config/jvm.options
#分别加入: -Xms300m -Xmx300m
4. 【核心】分别修改三个文件夹中config目录中elasticsearch.yml文件
vim master/config/elasticsearch.yml
vim salve1/config/elasticsearch.yml
vim slave2/config/elasticsearch.yml
#分别修改如下配置:【彼此发现】
cluster.name: my-es #集群名称(集群名称必须一致)
node.name: es-03 #节点名称(节点名称不能一致)
network.host: 0.0.0.0 #监听地址(必须开启远程权限,并关闭防火墙)
http.port: 9200 #监听端口(在一台机器时服务端口不能一)9201,9202,9203
discovery.zen.ping.unicast.hosts: ["172.30.2.175:9301", "172.30.2.201:9302"] #另外两个节点的ip
gateway.recover_after_nodes: 3 #集群可做master的最小节点数
transport.tcp.port: 9300 #集群TCP端口(在一台机器搭建必须修改)【自己写】9301
5. 启动多个es
./master/bin/elasticsearch
./slave1/bin/elasticsearch
./slave2/bin/elasticsearch
6. 查看节点状态
curl http://10.102.115.3:9200
curl http://10.102.115.3:8200
curl http://10.102.115.3:7200
7. 查看集群健康
http://10.102.115.3:9200/_cat/health?v15.3 安装head插件
markdown
1. 访问github网站
搜索: elasticsearch-head 插件
2. 安装git
yum install git
3. 将elasticsearch-head下载到本地
git clone git://github.com/mobz/elasticsearch-head.git
4. 安装nodejs
#注意: 没有wget的请先安装yum install -y wget
wget http://cdn.npm.taobao.org/dist/node/latest-v8.x/node-v8.1.2-linux-x64.tar.xz
5. 解压缩nodejs
xz -d node-v10.15.3-linux-arm64.tar.xz
tar -xvf node-v10.15.3-linux-arm64.tar
6. 配置环境变量
mv node-v10.15.3-linux-arm64 nodejs
mv nodejs /usr/nodejs
vim /etc/profile
export NODE_HOME=/usr/nodejs
export PATH=$PATH:$JAVA_HOME/bin:$NODE_HOME/bin
source /etc/profile
7. 进入elasticsearch-head的目录
npm config set registry https://registry.npm.taobao.org
npm install
npm run start
8. 编写elastsearch.yml配置文件开启head插件的访问【跨域访问】
http.cors.enabled: true
http.cors.allow-origin: "*"
9. 启动访问head插件 默认端口9100
http://ip:9100 查看集群状态
加入: -Xms300m -Xmx300m
4. 【核心】分别修改三个文件夹中config目录中elasticsearch.yml文件
vim master/config/elasticsearch.yml
vim salve1/config/elasticsearch.yml
vim slave2/config/elasticsearch.yml
#分别修改如下配置:【彼此发现】
cluster.name: my-es #集群名称(集群名称必须一致)
node.name: es-03 #节点名称(节点名称不能一致)
network.host: 0.0.0.0 #监听地址(必须开启远程权限,并关闭防火墙)
http.port: 9200 #监听端口(在一台机器时服务端口不能一)9201,9202,9203
discovery.zen.ping.unicast.hosts: ["172.30.2.175:9301", "172.30.2.201:9302"] #另外两个节点的ip
gateway.recover_after_nodes: 3 #集群可做master的最小节点数
transport.tcp.port: 9300 #集群TCP端口(在一台机器搭建必须修改)【自己写】9301
5. 启动多个es
./master/bin/elasticsearch
./slave1/bin/elasticsearch
./slave2/bin/elasticsearch
6. 查看节点状态
curl http://10.102.115.3:9200
curl http://10.102.115.3:8200
curl http://10.102.115.3:7200
7. 查看集群健康
http://10.102.115.3:9200/_cat/health?v15.3 安装head插件
markdown
1. 访问github网站
搜索: elasticsearch-head 插件
2. 安装git
yum install git
3. 将elasticsearch-head下载到本地
git clone git://github.com/mobz/elasticsearch-head.git
4. 安装nodejs
#注意: 没有wget的请先安装yum install -y wget
wget http://cdn.npm.taobao.org/dist/node/latest-v8.x/node-v8.1.2-linux-x64.tar.xz
5. 解压缩nodejs
xz -d node-v10.15.3-linux-arm64.tar.xz
tar -xvf node-v10.15.3-linux-arm64.tar
6. 配置环境变量
mv node-v10.15.3-linux-arm64 nodejs
mv nodejs /usr/nodejs
vim /etc/profile
export NODE_HOME=/usr/nodejs
export PATH=$PATH:$JAVA_HOME/bin:$NODE_HOME/bin
source /etc/profile
7. 进入elasticsearch-head的目录
npm config set registry https://registry.npm.taobao.org
npm install
npm run start
8. 编写elastsearch.yml配置文件开启head插件的访问【跨域访问】
http.cors.enabled: true
http.cors.allow-origin: "*"
9. 启动访问head插件 默认端口9100
http://ip:9100 查看集群状态