
作者: 逆境不可逃
技术永无止境
希望我的内容可以帮助到你!!!!!
WARNING!
由于第一次制图,有点丑陋,请多多见谅!
如果是小白建议先到最下面查看概念补充
大家好,我是逆境不可逃,今天给大家带来文章《一篇速通互联网架构的不断升级过程:从单机到云原生》.
互联网架构不是一开始就复杂的。大多数系统最初都是从一台服务器、一个应用、一个数据库开始的。随着用户量增长、业务变复杂、团队规模扩大,原来的架构会不断暴露瓶颈,于是系统才一步步升级。
架构演进的核心逻辑可以概括为三句话:
- 没有最好的架构,只有最适合业务阶段的架构。
- 架构升级的本质,是用空间换时间,用复杂度换性能和稳定性。
- 架构永远围绕五个目标:高性能、高可用、可伸缩、可扩展、够安全。
下面按照互联网架构常见演进路径,系统讲解从单机架构到云原生架构的升级过程。
一、单机架构:从零搭建
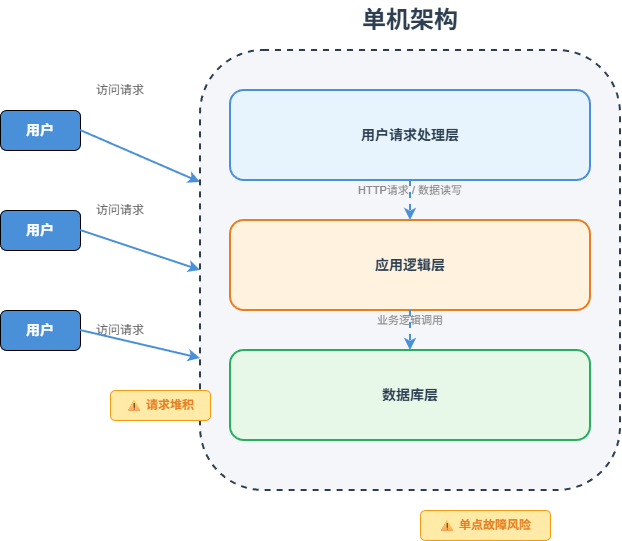
互联网系统最早期通常是单机架构。
用户 -> 应用服务器 -> 数据库这时候,Web 应用、业务代码、数据库、文件存储可能都部署在同一台机器上。
这种架构的优点非常明显:
- 开发简单
- 部署方便
- 成本低
- 适合项目早期验证
比如一个博客系统、内部管理系统、小型电商网站,初期完全可以用一台服务器完成所有功能。
但单机架构的问题也很明显:所有资源都集中在一台机器上,CPU、内存、磁盘、网络、数据库连接都会互相争抢。一旦机器宕机,整个系统就不可用。
所以单机架构解决的是:从零搭建系统的问题。 但它无法长期支撑高并发和高可用。
二、应用与数据库分离:解决资源争抢
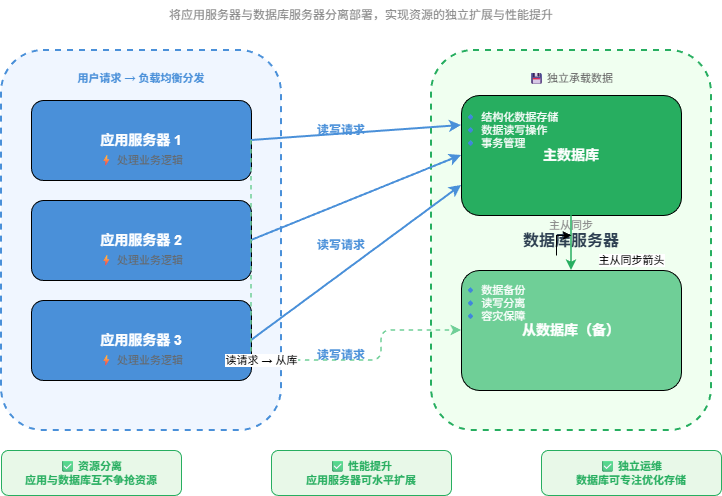
当访问量增加后,第一步通常是把应用服务器和数据库服务器拆开。
用户 -> 应用服务器 -> 数据库服务器这样做的目的,是让应用和数据库不再抢同一台机器的资源。
应用服务器主要消耗 CPU 和内存,数据库服务器主要消耗磁盘 IO、内存和连接数。拆开之后,可以分别扩容、分别优化。
这一阶段解决的是:资源争抢问题。
但它仍然有明显缺陷:
- 应用服务器还是单点
- 数据库服务器还是单点
- 应用访问量继续上升后,单台应用服务器扛不住
于是系统需要继续升级。
三、应用集群 + 负载均衡:解决高并发
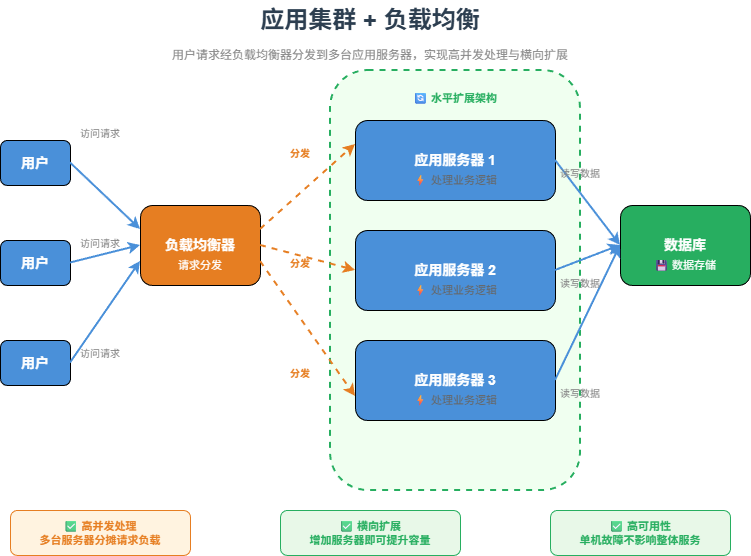
当一台应用服务器无法承载大量请求时,就需要部署多台应用服务器,并引入负载均衡。
用户 -> 负载均衡 -> 应用服务器集群 -> 数据库常见负载均衡组件包括 Nginx、LVS、HAProxy,以及云厂商提供的负载均衡服务。
负载均衡的作用是把用户请求分发到不同的应用服务器上。例如有 3 台应用服务器,请求可以按照轮询、权重、最少连接数等策略分配。
这样做带来两个好处:
- 提升并发能力:一台机器不够,就增加多台机器。
- 提升可用性:某台应用服务器故障,可以把流量切到其他服务器。
这一阶段解决的是:高并发访问问题。
但应用集群也会带来新问题,比如:
- 用户登录状态如何共享?
- 上传文件存在哪台服务器?
- 多台服务器之间配置如何保持一致?
- 会话、缓存、任务调度如何处理?
所以架构升级不是只增加机器,还要重新设计系统状态和数据存储方式。
四、多级缓存:解决查询性能和数据库压力
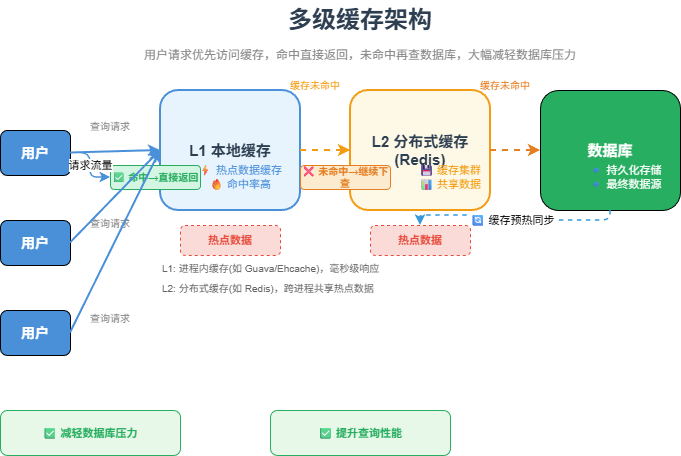
随着访问量继续上升,数据库通常会成为最核心的瓶颈。
很多请求其实是重复查询,比如首页数据、商品详情、文章详情、热门榜单。如果每次都查数据库,数据库压力会非常大。
这时就需要引入缓存。
用户 -> 应用服务器 -> 缓存 -> 数据库常见缓存包括:
- 本地缓存
- Redis
- Memcached
- 浏览器缓存
- CDN 缓存
缓存的核心思想是:能不查数据库,就不查数据库。
比如商品详情页,如果每秒有几千次访问,但商品信息并不是每秒都变化,就可以把商品信息放到 Redis 中。用户请求先查缓存,缓存没有再查数据库。
多级缓存可以显著提升系统性能,但也会带来新的复杂度:
- 缓存和数据库如何保持一致?
- 缓存过期时间如何设置?
- 热点 key 被大量访问怎么办?
- 缓存击穿、缓存穿透、缓存雪崩如何处理?
这一阶段解决的是:查询性能和数据库压力问题。
五、数据库读写分离:解决读写阻塞
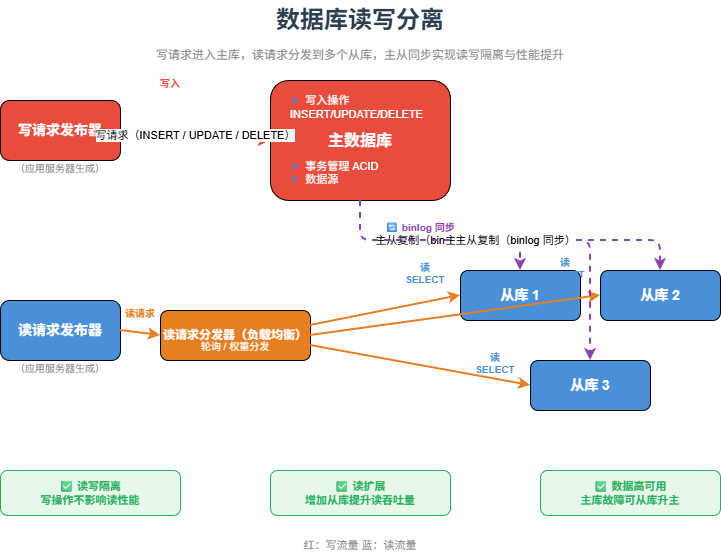
在很多互联网业务中,读请求远远多于写请求。
比如电商系统中,用户浏览商品是读操作,下单支付是写操作。新闻系统中,用户看文章是读操作,发布文章是写操作。
为了提升数据库读能力,可以做读写分离。
写请求 -> 主库
读请求 -> 从库主库负责写入数据,从库通过主从复制同步主库数据。应用层根据请求类型,把写操作发到主库,把读操作发到从库。
读写分离可以缓解数据库压力,提升查询能力。
但它也会带来一个关键问题:主从延迟。
比如用户刚修改了个人资料,下一秒查询时,请求被路由到从库,但从库还没有同步最新数据,用户看到的可能还是旧数据。
所以读写分离不仅是技术问题,也要结合业务场景判断哪些数据必须强一致,哪些数据可以接受短暂延迟。
这一阶段解决的是:数据库读写阻塞问题。
六、分库分表 + 分布式数据库:解决海量数据存储
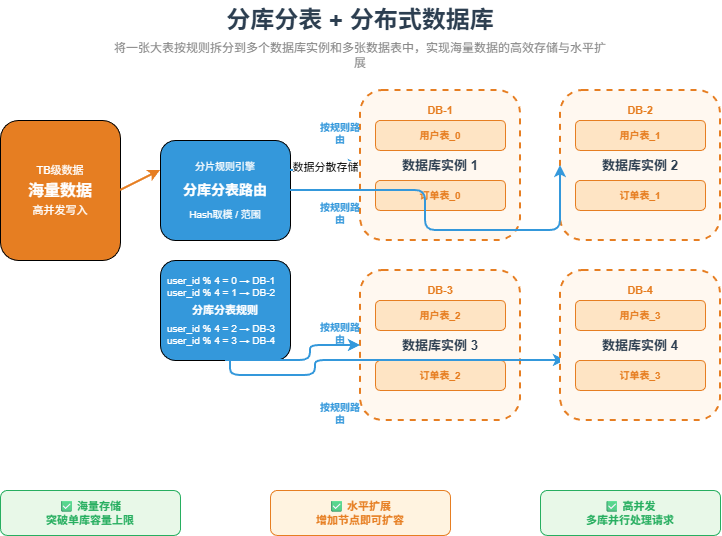
当数据量继续增长,单库单表会遇到更严重的问题。
例如订单表达到几千万、上亿数据后,查询、索引、备份、迁移都会变得困难。此时就需要分库分表。
常见方式包括:
- 按用户 ID 分库
- 按订单 ID 分表
- 按时间分表
- 按地区或业务线拆分数据库
例如订单表可以按照用户 ID 取模拆分:
order_0
order_1
order_2
order_3用户 ID 对 4 取模,决定数据落在哪张表中。
分库分表可以提升数据存储和查询能力,但复杂度也明显上升:
- 跨库查询变难
- 分布式事务变复杂
- 数据迁移成本变高
- 全局唯一 ID 需要单独设计
- 分页、排序、聚合查询不再简单
所以分库分表通常不是一开始就做,而是在数据库容量和性能接近瓶颈时再做。
这一阶段解决的是:海量数据存储问题。
七、CDN + 反向代理:解决访问速度和系统安全
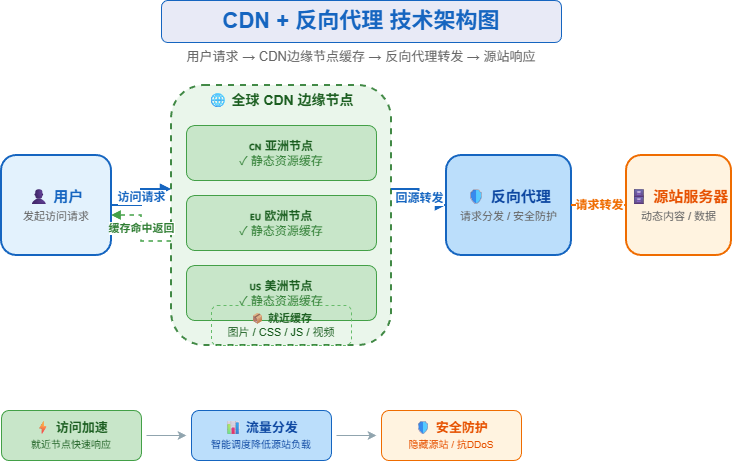
当用户分布在不同地区时,如果所有请求都访问同一个机房,远距离用户访问速度会变慢。
这时需要引入 CDN。
用户 -> CDN -> 静态资源CDN 主要用于加速静态资源,比如:
- 图片
- 视频
- CSS
- JavaScript
- 文件下载
CDN 会把资源缓存到离用户更近的节点上,用户访问时不必每次都回源站。
反向代理通常部署在应用服务器前面,例如 Nginx。
用户 -> Nginx -> 应用服务器反向代理可以做:
- 请求转发
- 负载均衡
- HTTPS 终止
- 限流
- 黑白名单
- 静态资源处理
- 简单安全防护
这一阶段解决的是:访问速度和系统安全问题。
八、搜索引擎 + NoSQL:解决复杂查询
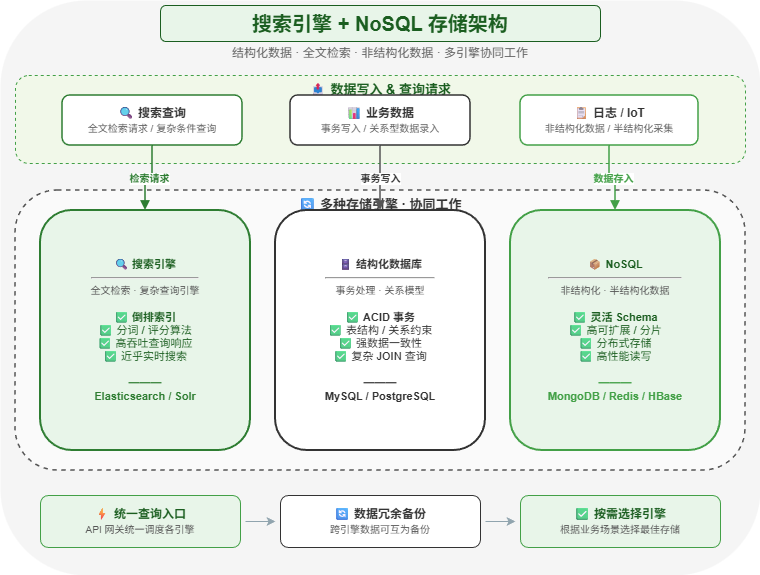
传统关系型数据库适合事务和结构化数据,但不适合所有查询场景。
比如:
- 商品搜索
- 文章全文检索
- 日志查询
- 推荐系统
- 用户行为数据分析
- 海量非结构化数据存储
这时会引入搜索引擎和 NoSQL。
常见技术包括:
- Elasticsearch
- Solr
- MongoDB
- HBase
- Cassandra
- ClickHouse
例如电商搜索场景中,如果用户搜索 "黑色运动鞋",直接查 MySQL 效率很低,而且很难支持分词、排序、相关性计算。使用 Elasticsearch 会更适合。
NoSQL 和搜索引擎的价值在于:把不同类型的数据交给更适合的存储系统处理。
这一阶段解决的是:复杂查询问题。
但也要注意,系统中引入的数据存储越多,数据同步和一致性问题就越复杂。
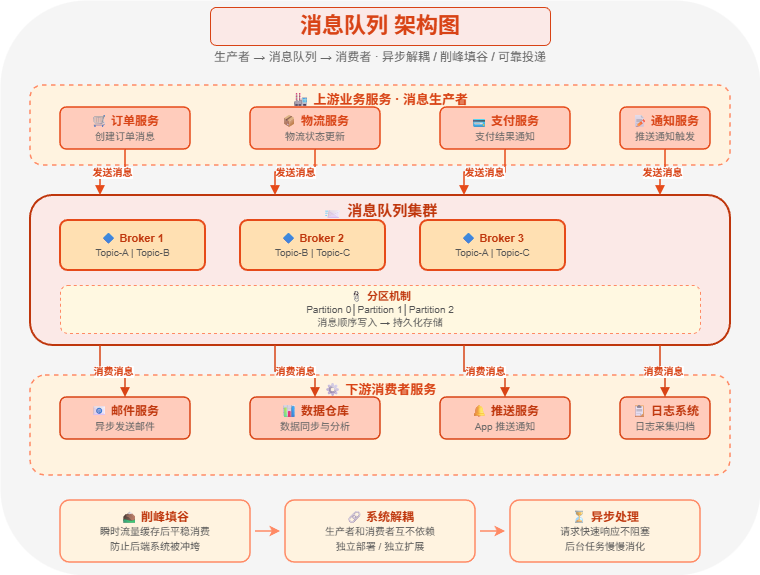
九、消息队列:解决削峰填谷和系统解耦
高并发系统中,不是所有操作都必须同步完成。
比如用户下单后,核心流程是创建订单和扣减库存,而发送短信、增加积分、推送通知、更新报表等操作可以异步执行。
这时可以引入消息队列。
订单服务 -> 消息队列 -> 库存服务 / 通知服务 / 积分服务常见消息队列包括:
- Kafka
- RabbitMQ
- RocketMQ
- Pulsar
消息队列主要解决三个问题:
- 削峰填谷:高峰请求先进入队列,后端服务按能力消费。
- 系统解耦:订单服务不需要直接依赖短信、积分、通知等服务。
- 异步处理:缩短主流程响应时间。
例如秒杀活动中,一瞬间可能有几十万请求进来。如果全部直接打到数据库,系统很容易崩溃。使用消息队列后,可以先接收请求,再按系统承载能力逐步处理。
但消息队列也会带来问题:
- 消息是否会丢失?
- 消息是否会重复消费?
- 消费失败如何重试?
- 消息顺序如何保证?
- 最终一致性如何设计?
这一阶段解决的是:流量高峰和系统耦合问题。
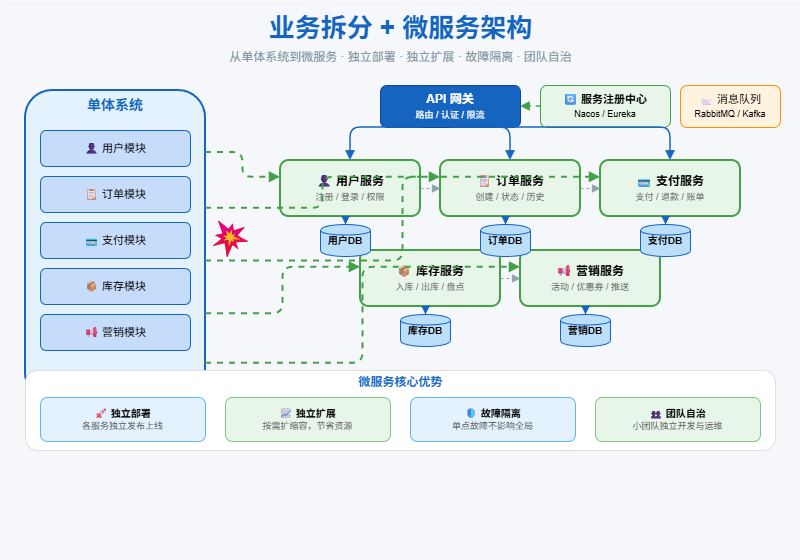
十、业务拆分 + 分布式:解决业务膨胀和代码维护
随着业务越来越复杂,单体应用会变得越来越难维护。
一个系统里可能同时包含:
- 用户模块
- 商品模块
- 订单模块
- 支付模块
- 库存模块
- 营销模块
- 后台管理模块
所有代码都在一个项目中,会导致:
- 项目启动慢
- 发布风险高
- 模块边界混乱
- 团队协作困难
- 一个模块故障影响整个系统
于是系统开始按照业务领域拆分。
用户系统
商品系统
订单系统
支付系统
库存系统
营销系统这就是服务化和分布式架构的基础。
拆分后,每个系统可以独立开发、独立部署、独立扩容。例如订单系统压力大,就只扩容订单系统;商品系统改版,也不需要发布整个系统。
这一阶段解决的是:业务膨胀和代码维护问题。
但分布式架构也会引入新问题:
- 服务之间如何通信?
- 服务地址如何发现?
- 接口超时怎么办?
- 调用链路如何排查?
- 分布式事务如何处理?
- 某个服务故障如何降级?
所以从单体到分布式,不只是拆代码,而是整个研发、部署、监控、运维体系都要升级。
十一、微服务架构:解决团队协作和极致弹性
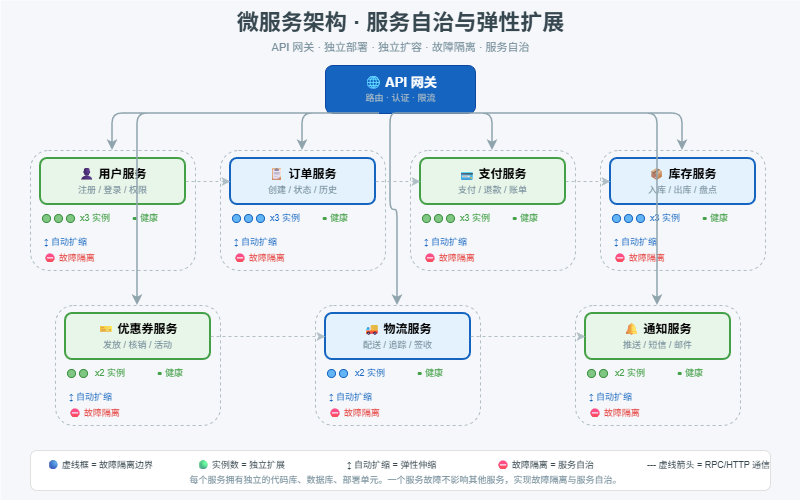
微服务可以看作服务化的进一步细化。
每个微服务围绕一个明确的业务能力构建,比如:
用户服务
订单服务
支付服务
库存服务
优惠券服务
物流服务
通知服务微服务之间通常通过 RPC 或 HTTP API 通信。常见技术包括:
- Spring Cloud
- Dubbo
- gRPC
- Kubernetes Service
- 服务注册与发现组件
微服务架构的核心价值是:
- 服务独立部署
- 服务独立扩容
- 团队独立负责
- 故障隔离更清晰
- 技术选型更灵活
例如支付服务对稳定性要求极高,可以单独做限流、熔断、监控和扩容;推荐服务需要大量计算资源,也可以独立部署和优化。
但微服务并不是越细越好。拆得太细,会导致调用链路复杂、排查困难、接口治理成本上升。
所以微服务的重点不是 "微",而是合理的业务边界。
这一阶段解决的是:团队协作和系统弹性问题。
十二、容器化 + 云平台:解决运维、成本和自动化
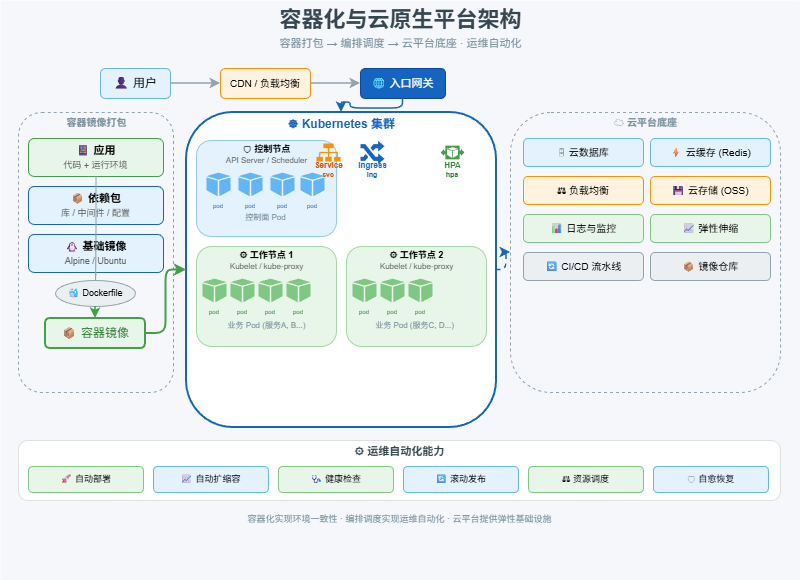
当服务数量越来越多,部署和运维会成为巨大挑战。
过去部署一个应用,可能需要手动安装 JDK、配置环境变量、上传包、启动进程。几十个服务、几百个实例之后,这种方式很难管理。
容器化解决了环境一致性问题。
应用 + 依赖 + 运行环境 -> Docker 镜像Docker 可以把应用和依赖打包成镜像,做到一次构建,到处运行。
Kubernetes,也就是 K8S,进一步解决了容器编排问题:
- 自动部署
- 自动扩缩容
- 服务发现
- 健康检查
- 故障恢复
- 滚动发布
- 资源调度
云平台则提供更完整的基础设施能力,例如:
- 云服务器
- 云数据库
- 云缓存
- 云负载均衡
- 云存储
- 日志服务
- 监控告警
- 弹性伸缩
这一阶段解决的是:运维、成本和自动化问题。
架构也逐渐进入云原生阶段。
用户 -> CDN/网关 -> K8S 集群 -> 微服务 -> 数据库/缓存/消息队列十三、互联网架构升级路线总结
互联网架构的升级过程,可以按照下面这条路线理解:
单机架构
-> 应用与数据库分离
-> 应用集群 + 负载均衡
-> 多级缓存
-> 数据库读写分离
-> 分库分表 + 分布式数据库
-> CDN + 反向代理
-> 搜索引擎 + NoSQL
-> 消息队列
-> 业务拆分 + 分布式
-> 微服务架构
-> 容器化 + 云平台每一步升级,本质上都在解决一个具体问题:
| 架构阶段 | 主要解决的问题 |
|---|---|
| 单机架构 | 从零搭建 |
| 应用与数据库分离 | 资源争抢 |
| 应用集群 + 负载均衡 | 高并发 |
| 多级缓存 | 查询性能、数据库压力 |
| 数据库读写分离 | 数据库读写阻塞 |
| 分库分表 + 分布式数据库 | 海量数据存储 |
| CDN + 反向代理 | 访问速度、系统安全 |
| 搜索引擎 + NoSQL | 复杂查询 |
| 消息队列 | 削峰填谷、系统解耦 |
| 业务拆分 + 分布式 | 业务膨胀、代码维护 |
| 微服务架构 | 团队协作、极致弹性 |
| 容器化 + 云平台 | 运维、成本、自动化 |
结语
架构升级不是为了堆技术名词,而是为了解决业务发展过程中真实出现的问题。
小系统过早使用微服务、K8S、分库分表,可能会让开发和运维成本大幅增加;大系统长期停留在单体和单库架构,又会被性能、稳定性和协作效率拖垮。
真正成熟的架构思维,是知道每种架构适合什么阶段、解决什么问题、又会带来什么代价。
互联网架构演进的本质,就是在业务增长、性能要求、稳定性要求和研发效率之间不断做平衡。没有一套架构适合所有系统,只有在当前业务阶段下最合适的架构。
附:小白概念补充
🔵 基础阶段(单机 → 云平台)
- 单机:互联网系统最早期形态,所有代码、应用、数据库都部署在同一台服务器上,开发部署简单,但性能、可用性都受限于这一台机器。
- 服务注册与发现:微服务架构的核心组件,服务启动时向注册中心登记,其他服务通过注册中心动态获取服务地址,解决了服务实例变化后的寻址问题。
- 云平台:提供服务器、数据库、缓存、存储等基础设施服务的平台,让开发者不用自己管理物理硬件,能快速、弹性地搭建和扩容系统。
🟠 性能优化阶段(负载均衡、反向代理、读写分离)
- 负载均衡:把用户请求均匀分发到多台应用服务器上,既提升了系统的并发处理能力,也能在某台服务器故障时自动转移流量,提升可用性。
- 反向代理:部署在应用服务器前面,接收用户请求并转发给后端服务,可实现请求转发、负载均衡、HTTPS 处理、限流和安全防护等功能。
- 读写分离:数据库优化方案,主库负责写操作,从库通过主从复制同步数据,读请求分发到从库,缓解主库压力,提升整体读性能。
⚫ 扩展存储与加速阶段(NoSQL、CDN、K8S、RPC)
- NoSQL:非关系型数据库,适合存储海量、非结构化或半结构化数据,如用户行为日志、商品评论等,能提供比传统关系型数据库更高的读写性能和扩展性。
- CDN:内容分发网络,把静态资源(图片、视频、JS/CSS)缓存到离用户更近的节点,用户访问时直接从就近节点获取,大幅提升访问速度,减轻源站压力。
- K8S(Kubernetes):容器编排平台,负责容器的部署、调度、扩缩容、健康检查和故障恢复,是实现容器化和云原生架构的核心工具。
- RPC:远程过程调用协议,让不同服务之间可以像调用本地方法一样互相通信,是微服务架构中服务间调用的主流方式之一。
🟢 分布式架构阶段(分布式、容器、缓存、微服务)
- 分布式:把原本单体的系统拆分成多个独立的子系统,部署在不同机器上协同工作,解决了单体架构难以扩展、维护成本高的问题。
- 容器:一种轻量级的虚拟化技术,能把应用和依赖打包成独立的镜像,实现 "一次构建,到处运行",保证不同环境下的运行一致性。
- 缓存:把热点数据存储在读取速度更快的介质中(如内存),用户请求优先访问缓存,命中则直接返回,大幅减少对数据库的访问压力,提升响应速度。
- 微服务:分布式架构的细化形态,把业务拆分成多个独立的、职责单一的小服务,每个服务可独立开发、部署、扩容,降低耦合度,提升开发和运维效率。
🔴 进阶架构阶段(消息队列、云原生、分库分表)
- 消息队列:系统间异步通信的中间件,能实现流量削峰、系统解耦和异步处理,比如用户下单后,订单服务发消息给队列,通知库存、短信等服务异步执行后续操作。
- 云原生:基于云平台构建和运行应用的架构理念,以容器、微服务、DevOps 为核心,强调弹性伸缩、自动化运维和持续交付,让应用更适配云环境。
- 分库分表:当单库单表数据量过大时,把数据拆分到多个数据库和表中存储,提升查询性能和存储容量,常见拆分方式包括按用户 ID、时间、业务线等维度拆分。
