Java、Python、JavaScript、C++ 等所有语言,只讲底层结构与逻辑,不讲语法差异,核心是理解"数据如何组织",而非"用某语言如何写"。
数据结构是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合。常见的数据结构包括数组、链表、栈、队列、树、图等。
一、数据结构通用基础认知
核心定义
比喻:数据结构就像"数据的仓库布局"------仓库里的货物(数据)怎么摆放、怎么分类、怎么存取,决定了后续找货、放货、改货的效率。 本质:数据在内存中的组织与存储方式,核心是"组织"和"存储",直接决定数据如何存放、如何访问、如何修改。
核心作用
类比:仓库布局合理(好的数据结构),找货(查询)、放货(新增)、改货(修改)更快,还能节省仓库空间(内存);布局不合理,再多人手(代码优化)也没用。 核心:优化增删改查效率、节省内存空间、适配不同业务场景(比如"频繁找货"和"频繁放货"需要不同布局)。

通用操作(所有结构都具备)
类比:不管仓库布局如何,都离不开4个基础操作,对应数据的核心需求:
-
增:往仓库里新增货物(添加数据)
-
删:从仓库里移除货物(删除数据)
-
改:把仓库里的某件货物换成另一件(修改数据)
-
查:在仓库里找到某件货物(查找 / 遍历数据)
通用评价维度

新手重点:这是判断"哪种数据结构适合场景"的核心标准,不用死记公式,理解本质即可:
-
时间复杂度:做某件操作(比如查数据)的"快慢",数字越小越快(比如O(1)比O(n)快),类比"找货花多久"。
-
空间复杂度:存储数据占用的"内存大小",类比"仓库占多大地方",不是越小越好,要平衡快慢和空间。
-
是否有序:数据是否按固定顺序排列(比如数组的1、2、3,哈希表的无序存储),类比"货物是否按编号排队"。
-
是否可重复:是否允许存储相同的数据(比如数组可以存两个5,哈希表的key不能重复),类比"仓库是否允许放两件一模一样的货物"。
-
是否支持随机访问:能否直接定位到某条数据(比如数组通过下标直接取,链表不能),类比"能否直接走到某件货物面前,不用从头找"。
二、线性结构(数据排成一条线)
核心类比:线性结构就像"排队的人",所有人排成一条直线,只有前后两个方向,没有分支,数据之间是"一对一"的关系。
2.1 数组 / 列表

特点
比喻:数组是"一排连续的储物柜",每个储物柜有唯一编号(下标),储物柜之间紧紧挨着,没有空隙;数据就放在储物柜里,通过编号(下标)能直接找到。 本质:连续内存存储、支持随机访问(通过下标直接取,时间复杂度O(1))。
优点
查询快:直接按编号找,不用从头遍历;遍历简单:从第一个储物柜到最后一个,顺着走就行,类比"按编号查货物,一眼找到"。
缺点
插入/删除需移动元素,效率低:比如在第2个储物柜插一件货物,第2、3、4...所有后面的储物柜都要往后挪一个位置;静态数组长度固定,比如买了10个储物柜,就只能放10件货物,多了放不下。
通用场景
大量查询、少量修改、有序列表(比如成绩排名、商品编号列表,主要需求是"查",很少新增/删除)。
新手误区
把"数组"和"列表"搞混:数组(静态)长度固定,列表(动态)是数组的"升级版",自动扩容,但底层还是连续内存,插入/删除依然要移动元素(只是不用手动处理扩容);误以为"列表插入删除很快",其实和数组一样,效率低。
2.2 链表

特点
比喻:链表是"一串糖葫芦",每个山楂(节点)都有两部分:山楂肉(数据)和一根小棍子(指针,指向 next 山楂的位置);山楂之间不挨着,靠小棍子连接,不用连续的空间。 本质:分散存储,每个节点存数据 + 指向下一节点的地址,不支持随机访问(不能直接找第3个山楂,必须从第一个开始数)。
优点
插入/删除只需改指针,效率高:比如在两个山楂之间插一个新山楂,只需把前一个山楂的小棍子指向新山楂,新山楂的小棍子指向后一个山楂,不用移动其他山楂;长度动态,想加多少山楂(节点)都可以,只要有内存。
缺点
查询慢:必须从头遍历(从第一个山楂开始,顺着小棍子一个个找),找第n个节点要走n步,时间复杂度O(n);类比"找一串糖葫芦里的第5个山楂,必须从第一个开始数"。
通用场景
频繁增删、数据量动态变化(比如消息列表、聊天记录,经常新增/删除消息,很少一次性查询所有消息)。
常见类型
-
单链表:只有一个指针,只能从前往后走(糖葫芦只能从第一个吃到最后一个)。
-
双向链表:每个节点有两个指针,既能往前找,也能往后找(糖葫芦能来回吃),删除效率比单链表更高(不用回头找前一个节点)。
-
循环链表:最后一个节点的指针指向第一个节点,形成一个环(糖葫芦首尾相连,能循环吃),适用于循环场景(比如循环任务调度)。
2.3 栈(Stack)

特点
比喻:栈是"叠盘子",只能把盘子放在最上面(入栈),也只能从最上面拿盘子(出栈),下面的盘子不能直接动;核心是"后进先出"(LIFO)------后放的盘子,先被拿走。
操作
-
入栈(push):把盘子叠在最上面(添加数据到栈顶)。
-
出栈(pop):把最上面的盘子拿走(删除栈顶数据)。
-
取栈顶(peek):看一眼最上面的盘子,不拿走(查看栈顶数据,不删除)。
通用场景
类比:叠盘子的"后进先出"对应场景的"回溯"需求:
-
函数调用栈:调用函数A,A调用B,B调用C,先执行完C,再执行B,最后执行A(后调用的函数先结束)。
-
括号匹配:比如"()\[\]{}",后出现的左括号,要先匹配右括号(比如最后一个左括号,对应第一个右括号)。
-
递归转迭代:递归本质是系统栈,当递归太深会溢出,用栈模拟递归过程(比如二叉树遍历)。
-
浏览器前进后退:打开页面A→B→C,后退先回到B,再回到A(后打开的页面先关闭)。
新手误区
误以为栈可以"随机访问":栈只能操作栈顶,不能直接访问中间的元素(比如不能直接拿叠在中间的盘子);混淆"栈"和"数组":数组可以随机访问,栈不行,两者底层结构不同。
2.4 队列(Queue)

特点
比喻:队列是"排队买票",只能从队尾排队(入队),从队头买票离开(出队),不能插队;核心是"先进先出"(FIFO)------先排队的人,先买票。
操作
-
入队(enqueue):到队尾排队(添加数据到队尾)。
-
出队(dequeue):从队头离开(删除队头数据)。
通用场景
类比:排队的"先进先出"对应场景的"顺序处理"需求:
-
任务排队:比如打印机打印任务,先提交的任务先打印;服务器处理请求,先收到的请求先处理。
-
消息队列:APP接收消息,先收到的消息先显示;分布式系统中,消息按顺序传递,避免混乱。
-
广度优先搜索(BFS):比如找最短路径,先访问当前节点的所有邻居,再访问邻居的邻居(像排队一样,依次处理)。
延伸
-
双端队列:既能从队头进出,也能从队尾进出(像双向排队,既能插队到队头,也能从队尾离开),兼顾栈和队列的特点(比如浏览器前进后退也能用双端队列实现)。
-
优先队列:不按"先进先出",按"优先级"出队(比如VIP排队,不管来的早晚,都比普通用户先买票),底层通常用堆实现。
三、非线性结构(数据呈层级 / 网状)
核心类比:非线性结构不像"排队",而是像"家谱"(层级)或"社交网络"(网状),数据之间是"一对多"或"多对多"的关系,没有固定的线性顺序。
3.1 哈希表 / 字典 / 映射
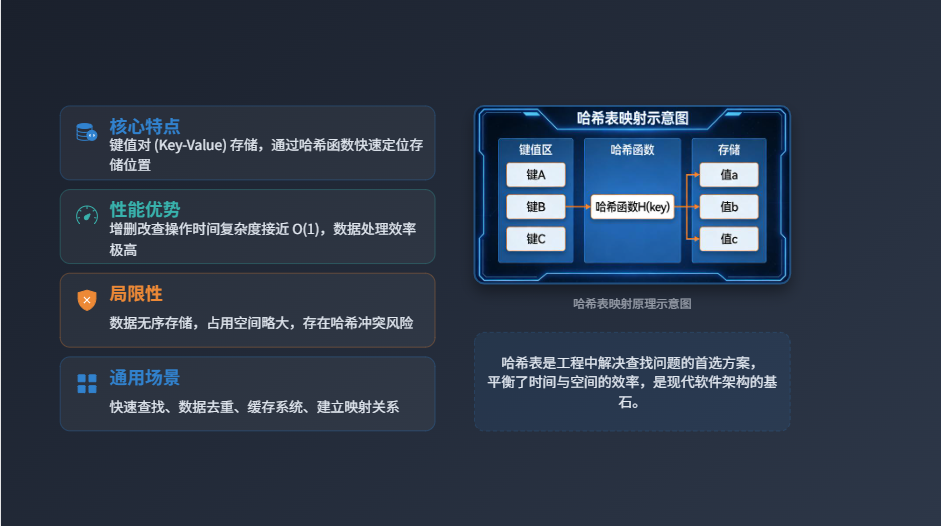
特点
比喻:哈希表是"查字典",key是"拼音",value是"汉字";通过"拼音查字"(哈希函数),直接定位到汉字的位置,不用从头翻字典。 本质:键值对(key-value)存储,通过哈希函数将key转换成内存地址,定位数据位置。
优点
增删改查接近O(1),效率极高:不管数据量多大,只要知道key,就能快速找到value,类比"查字典比翻书找字快得多"。
缺点
-
无序:key-value的存储没有固定顺序,不能按"插入顺序"或"大小顺序"遍历(比如字典里的拼音不是按顺序排列的)。
-
占用空间略大:为了避免"哈希冲突",会预留一部分内存(类比字典留空白页,方便新增汉字)。
-
可能哈希冲突:不同的key,通过哈希函数算出的地址可能一样(比如两个不同的拼音,对应同一个字典页码),需要额外处理(比如链表法、开放地址法)。
通用场景
快速查找、去重、缓存、映射关系(比如:根据用户ID找用户信息、去重手机号、缓存常用数据、键值配对如"姓名-年龄")。
新手误区
误以为哈希表"绝对有序":很多语言的字典(比如Python的dict)现在支持插入顺序,但这是语言层面的优化,底层哈希表本身是无序的;误以为哈希表"没有冲突":只要数据量足够大,必然会出现冲突,只是语言帮我们处理了,不用手动实现。
3.2 树
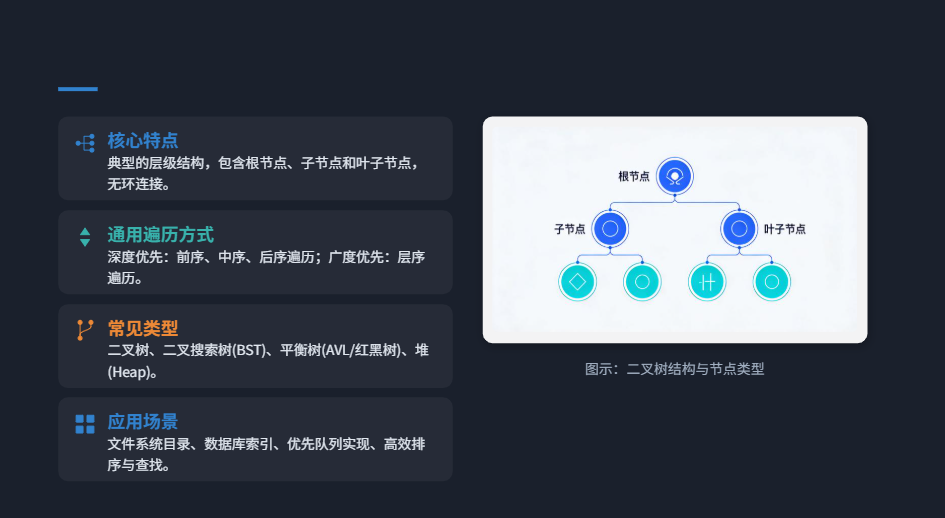
特点
比喻:树是"家谱",有一个"祖先"(根节点),每个祖先有多个"子女"(子节点),没有子女的是"晚辈"(叶子节点);层级分明,每个节点只有一个"父节点"(除了根节点),不能形成环(不能出现"子女是祖先的祖先")。 本质:层级结构,由根节点、子节点、叶子节点组成,数据之间是"一对多"的关系。
通用遍历
类比:遍历树就像"逛家谱",有4种常见方式,核心是"按什么顺序访问所有节点":
-
前序遍历:先看"祖先",再看"左子女",最后看"右子女"(先看爷爷,再看爸爸,再看叔叔,再看孙子)。
-
中序遍历:先看"左子女",再看"祖先",最后看"右子女"(先看爸爸,再看爷爷,再看叔叔)。
-
后序遍历:先看"左子女",再看"右子女",最后看"祖先"(先看孙子,再看爸爸,再看爷爷)。
-
层序遍历:按"辈分"依次访问,先看爷爷,再看爸爸和叔叔,再看孙子(像排队一样,按层级来)。
常见类型
-
二叉树:每个节点最多有两个子节点(左子节点、右子节点),是最基础、最常用的树结构。
-
二叉搜索树(BST):二叉树的升级版,左子节点的值 < 父节点的值,右子节点的值 > 父节点的值,查询效率高(类比"查家谱时,按辈分+年龄排序,快速找到某个人")。
-
平衡树(比如红黑树、AVL树):二叉搜索树的优化版,避免树"长歪"(比如所有节点都在一边,变成链表),保证查询、插入、删除效率稳定。
-
堆:特殊的完全二叉树,分为大根堆(根节点是最大值)和小根堆(根节点是最小值),适用于排序、优先队列。
通用场景
文件系统(电脑文件夹:C盘→桌面→文档,层级结构)、目录结构、排序(堆排序)、优先队列(底层用堆)、查找优化(二叉搜索树比链表查询快)。
3.3 图

特点
比喻:图是"社交网络",每个人是"节点",人与人之间的"朋友关系"是"边";可以是单向朋友(A关注B,B不关注A,有向边),也可以是双向朋友(A和B互相关注,无向边),还可以给朋友关系分"亲密度"(带权边)。 本质:由节点(顶点)和边组成,可表示任意复杂关系,数据之间是"多对多"的关系。
分类
-
有向图:边有方向(比如A→B,只能从A到B,不能反过来),比如社交网络的"关注"关系。
-
无向图:边没有方向(比如A-B,A到B和B到A都可以),比如社交网络的"互相关注"关系。
-
带权图:边有"权重"(比如亲密度、距离),比如地图上的"道路"(边),权重是"距离"。
通用遍历
-
深度优先(DFS):类比"逛社交网络,先跟一个朋友聊到底,再回头找另一个朋友"------从一个节点出发,一直走到不能再走,再回溯,继续访问其他节点。
-
广度优先(BFS):类比"逛社交网络,先跟所有朋友打个招呼,再跟每个朋友的朋友打招呼"------从一个节点出发,先访问所有邻居,再访问邻居的邻居。
通用场景
路径规划(地图找最短路径)、社交关系分析(找两个人之间的朋友链)、网络拓扑(电脑网络的节点连接)、推荐系统(根据用户的关系推荐好友)。
四、通用逻辑与遍历方式
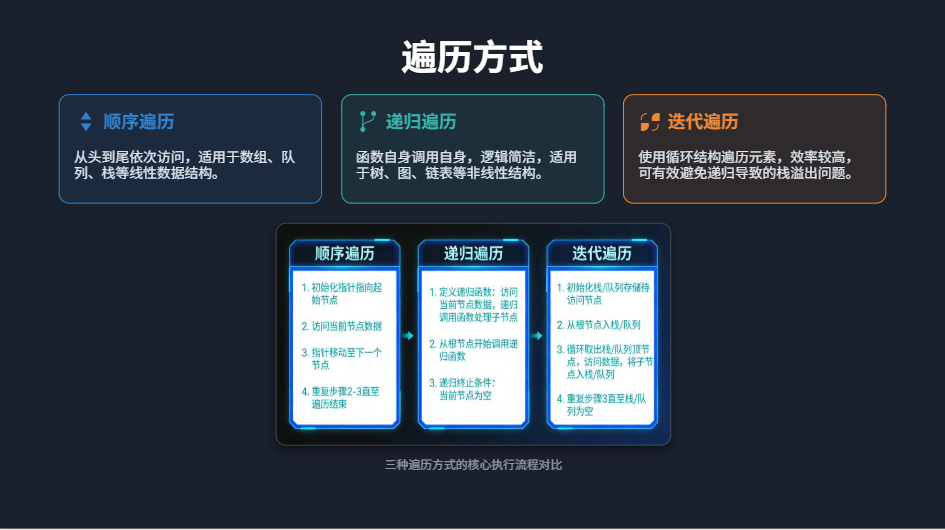
顺序遍历
本质:从头到尾依次访问,不跳步、不回溯,适用于线性结构(数组、队列、栈),类比"排队逐个点名,从第一个到最后一个"。
递归遍历
比喻:递归是"自己找自己帮忙"------比如找家谱里的所有人,你先找自己的子女,让每个子女再找他们的子女,直到没有子女为止。 本质:自身调用自身,适用于树、图、链表(非线性结构或长链表),代码简洁,但容易出现栈溢出(比如家谱太深,递归次数太多)。
迭代遍历
比喻:迭代是"自己动手,循环做事"------比如找家谱里的所有人,自己一个个找,记下来已经找过的人,不麻烦别人(不调用自己)。 本质:循环方式遍历,用循环代替递归,避免栈溢出,适用于所有结构,代码稍复杂,但更稳定。
通用边界处理

新手重点:边界处理是避免代码报错的关键,所有数据结构操作前,都要先判断这4种情况:
-
空结构:比如栈为空、链表为空,此时执行出栈、删除操作会报错。
-
单个元素:比如链表只有一个节点,删除后链表为空,需要单独处理。
-
首尾节点:比如链表的头节点(没有前一个节点)、尾节点(没有后一个节点),插入/删除时和中间节点不同。
-
越界判断:比如数组下标超过长度、栈满了还入栈,都会报错,需要提前判断。
五、复杂度通用速览(语言无关)
| 结构 | 随机访问 | 增删 | 查询 |
|---|---|---|---|
| 数组 | O(1) | O(n) | O(n) |
| 链表 | O(n) | O(1) | O(n) |
| 栈 / 队列 | 不支持 | O(1) | O(n) |
| 哈希表 | 不支持 | O(1) | O(1) |
**说明:**O(1)表示"常数时间",和数据量无关;O(n)表示"线性时间",数据量越大,时间越长;哈希表的O(1)是"平均情况",冲突时会接近O(n)。
**核心洞察:**哈希表在增删改查方面表现出极高的效率(平均 O(1)),是高频查询场景的首选;数组在随机访问上具有天然优势(O(1)),适合需要快速读取的场景;链表则在频繁增删操作时更具灵活性。
六、数据结构选型通用原则
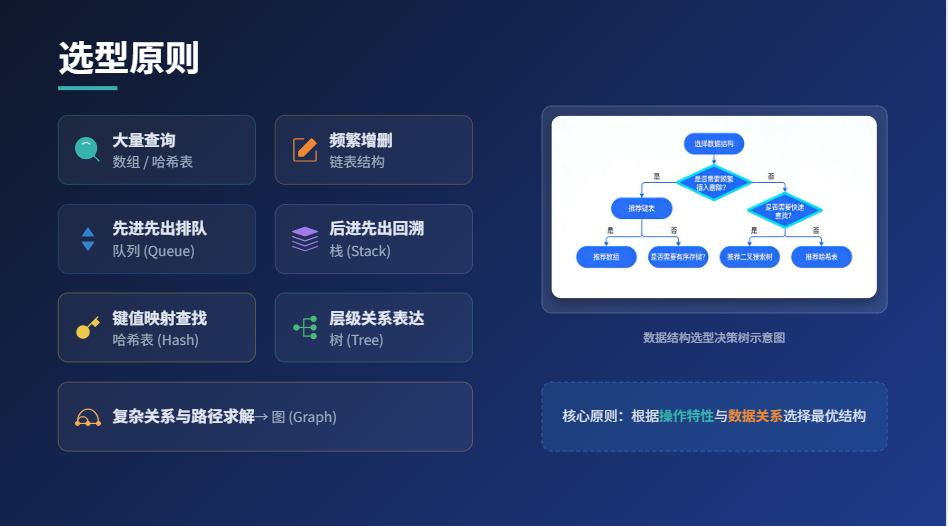
核心:根据"核心操作"选结构,不用追求"最先进",适合场景最重要,类比"仓库布局,根据找货、放货的频率选":
-
大量查询 → 数组 / 哈希表(数组有序,哈希表更快)。
-
频繁增删 → 链表(避免移动元素,效率高)。
-
先进先出排队 → 队列(比如任务处理、消息队列)。
-
后进先出回溯 → 栈(比如函数调用、括号匹配)。
-
键值映射快速查找 → 哈希表(比如缓存、用户信息查询)。
-
层级关系 → 树(比如文件系统、目录结构)。
-
复杂关系与路径 → 图(比如地图、社交网络)。
七、常见通用误区
-
盲目使用数组:若场景中存在频繁增删操作,仍选用数组会导致每次操作都需移动大量元素,大幅降低效率(例如用数组存储聊天记录,频繁发送、删除消息时,性能损耗明显)。
-
盲目使用哈希表:哈希表本身无序,若需求是按顺序遍历数据(如按插入顺序展示列表),则不适用,此时应优先选择数组或链表。
-
混淆栈与队列的规则:误用两者的进出逻辑,比如用栈实现排队类场景,会出现"后到先处理"的问题,与需求严重不符。
-
忽视边界处理:未妥善处理空结构、下标越界、首尾节点等边界情况,极易导致代码报错(例如栈为空时执行出栈操作、数组下标为负数等)。
-
只记语法不记底层:仅记住某一种语言的语法用法,未理解数据结构的底层逻辑,导致更换语言后无法灵活运用(比如只会用Java的ArrayList,不会用Python的list,核心是未掌握数组的底层原理)。
要点总结
理解数据结构的基本概念与实现原理 掌握数组、链表、栈、队列等线性结构的特性与应用场景 熟悉树、图等非线性结构的遍历与操作方式 了解哈希表、堆等高级数据结构的实现机制。建议通过编程练习巩固理论知识 尝试在不同场景中选择合适的数据结构 分析算法的时间复杂度与空间复杂度 参与实际项目应用所学数据结构知识