前言
在MySQL性能优化的体系中,索引优化是成本最低、收益最高的手段。但绝大多数开发者对索引的理解停留在"给查询字段加索引"的表层,经常遇到"明明加了索引,SQL执行还是很慢"的问题。其核心原因,是没有吃透InnoDB存储引擎索引的底层存储逻辑,更没有理解回表操作才是SQL性能的隐形杀手。
一、InnoDB索引的底层基石:数据页结构
要理解索引的存储逻辑,首先要搞懂InnoDB的存储核心------数据页 。InnoDB是面向磁盘的存储引擎,内存与磁盘的数据交互以页为最小单位,默认页大小为16KB,也就是说,即使你只查询1行数据,InnoDB也会把这行数据所在的整个16KB页加载到内存中。
1.1 数据页的核心结构
一个完整的InnoDB数据页,由7个核心部分组成,其中与索引存储强相关的核心模块如下:
| 模块名称 | 大小 | 核心作用 |
|---|---|---|
| File Header | 38字节 | 存储页的通用信息,包括页号、上一页/下一页页号,实现页的双向链表结构 |
| Page Header | 56字节 | 存储页内的状态信息,包括页内记录数、空闲空间偏移量、目录槽数量等 |
| Infimum + Supremum Records | 26字节 | 页内的两条虚拟记录,Infimum是页内最小值,Supremum是页内最大值,作为记录遍历的上下边界 |
| User Records | 动态大小 | 实际存储行数据/索引数据的区域,记录之间通过单向链表连接,且严格按照索引键排序 |
| Page Directory | 动态大小 | 页内记录的稀疏目录,也叫"槽",每个槽存储对应记录的相对偏移量,用于页内记录的二分查找,将O(n)的链表遍历优化为O(logn)的二分查找 |
| File Trailer | 8字节 | 用于校验数据页的完整性,防止磁盘写入时的数据损坏 |
1.2 页结构的核心特性
- 双向链表结构:所有数据页通过File Header中的上一页/下一页页号,组成双向链表,无需物理存储连续,只需逻辑上有序。
- 页内记录有序:User Records中的记录,严格按照索引键的大小排序,通过单向链表连接。
- 稀疏目录加速查找:Page Directory的槽是稀疏索引,不会为每条记录都创建槽,而是每4-8条记录对应一个槽,通过二分查找槽,再遍历槽内的少量记录,大幅提升页内查找效率。
理解了页结构,你就会明白:InnoDB的索引,本质上就是由一个个数据页组成的、有序的B+树结构,所有的查询优化,最终都是为了减少磁盘IO的次数,也就是减少加载的数据页数量。
二、聚簇索引(Clustered Index)的底层存储结构
聚簇索引是InnoDB表的核心,InnoDB的表本质上是索引组织表(IOT) ,整张表的数据就是按照聚簇索引的顺序组织存储的。
2.1 聚簇索引的B+树结构
聚簇索引是一棵以主键为排序键的B+树,其结构分为非叶子节点和叶子节点两层核心:
- 非叶子节点 :仅存储主键值 + 对应子页的页号,不存储完整的行数据。非叶子节点的作用是作为索引的"导航目录",快速定位到对应的叶子节点。
- 叶子节点 :就是存储完整行数据的数据页,叶子节点之间通过双向链表连接,保证范围查询时可以快速遍历相邻页;页内的行数据通过单向链表连接,严格按照主键值升序排序。
我们用一个通俗的比喻:聚簇索引就像新华字典的拼音目录,拼音目录的顺序和字典正文的顺序完全一致,你通过拼音目录找到对应的页码,就能直接拿到正文的完整内容,不需要二次查找。
2.2 聚簇索引的结构可视化

2.3 聚簇索引的核心特性
-
唯一性:一张InnoDB表有且仅有一个聚簇索引,数据只能按照一种顺序排序存储。
-
默认生成规则:
- 优先使用用户显式定义的主键作为聚簇索引键;
- 若没有定义主键,InnoDB会选择第一个非空唯一索引作为聚簇索引键;
- 若既没有主键也没有非空唯一索引,InnoDB会隐式生成一个6字节的ROWID作为聚簇索引键。
-
查询高效性:通过聚簇索引查询数据时,只要定位到叶子节点,就能直接获取完整的行数据,无需二次IO,主键查询的性能是最高的。
-
插入性能依赖主键顺序:聚簇索引的叶子节点按主键排序,使用自增主键时,新数据会顺序追加到最新的页中,不会产生页分裂;使用随机主键(如UUID)时,新数据可能插入到已有页的中间,导致页分裂,严重影响插入性能。
三、二级索引(Secondary Index)的底层存储结构
二级索引也叫辅助索引、非聚簇索引,是基于聚簇索引之外创建的索引,一张表可以创建多个二级索引,最多支持64个。
3.1 二级索引的B+树结构
二级索引同样是一棵B+树,但其存储内容与聚簇索引有本质区别,核心分为两层:
- 非叶子节点 :仅存储索引列的值 + 对应子页的页号,按照索引列的值排序。
- 叶子节点 :不存储完整的行数据,仅存储索引列的值 + 聚簇索引的主键值,叶子节点之间同样通过双向链表连接,页内记录按照索引列的值排序,索引列值相同时,按照主键值排序。
继续用字典的比喻:二级索引就像新华字典的部首目录,部首目录里只有部首和对应的拼音页码,你通过部首目录找到对应的拼音页码后,还需要拿着拼音页码再去拼音目录(聚簇索引)里查找正文内容,这个二次查找的过程,就是回表。
3.2 二级索引的结构可视化

3.3 二级索引的核心特性
- 多索引支持:一张表可以创建多个二级索引,满足不同的查询场景。
- 存储冗余度低:二级索引的叶子节点仅存储索引列+主键,体积远小于聚簇索引,相同16KB的页可以存储更多的记录,内存命中率更高。
- 排序规则:先按照索引列的值排序,索引列值相同时,按照主键值排序,这也是为什么二级索引可以天然解决索引列值相同的排序问题。
- 主键依赖:二级索引的有效性完全依赖聚簇索引,聚簇索引的主键值发生变化时,所有二级索引的叶子节点都需要同步更新,这也是为什么不建议频繁更新主键的原因。
四、聚簇索引与二级索引的核心存储差异
我们用一张表,清晰拆解两者的核心差异,彻底厘清易混淆的知识点:
| 对比维度 | 聚簇索引 | 二级索引 |
|---|---|---|
| B+树非叶子节点存储内容 | 主键值 + 子页页号 | 索引列值 + 子页页号 |
| B+树叶子节点存储内容 | 完整的行数据 | 索引列值 + 主键值 |
| 单表数量 | 有且仅有1个 | 最多支持64个 |
| 排序依据 | 主键值升序 | 索引列值升序,相同值按主键值升序 |
| 查找完整行数据的方式 | 定位到叶子节点直接获取,无需二次IO | 仅能获取索引列和主键,需通过主键回表查询聚簇索引 |
| 存储体积 | 大,存储整行数据 | 小,仅存储索引列+主键,相同页可存储更多记录 |
| DML操作维护成本 | 主键更新会触发整行数据移动,页分裂成本高 | 插入/更新仅需维护对应索引树,多索引会叠加维护成本 |
| 叶子节点链表作用 | 支持全表扫描和主键范围查询 | 支持索引列的范围查询,无需遍历聚簇索引 |
五、回表操作的本质与性能开销
5.1 回表操作的本质
回表,就是当通过二级索引执行查询时,二级索引的叶子节点仅包含索引列和主键值,如果查询所需的列没有全部包含在二级索引中,InnoDB就必须拿着从二级索引中获取的主键值,再次去聚簇索引的B+树中查找对应的完整行数据,这个二次遍历聚簇索引B+树的过程,就是回表。
5.2 回表操作的完整流程
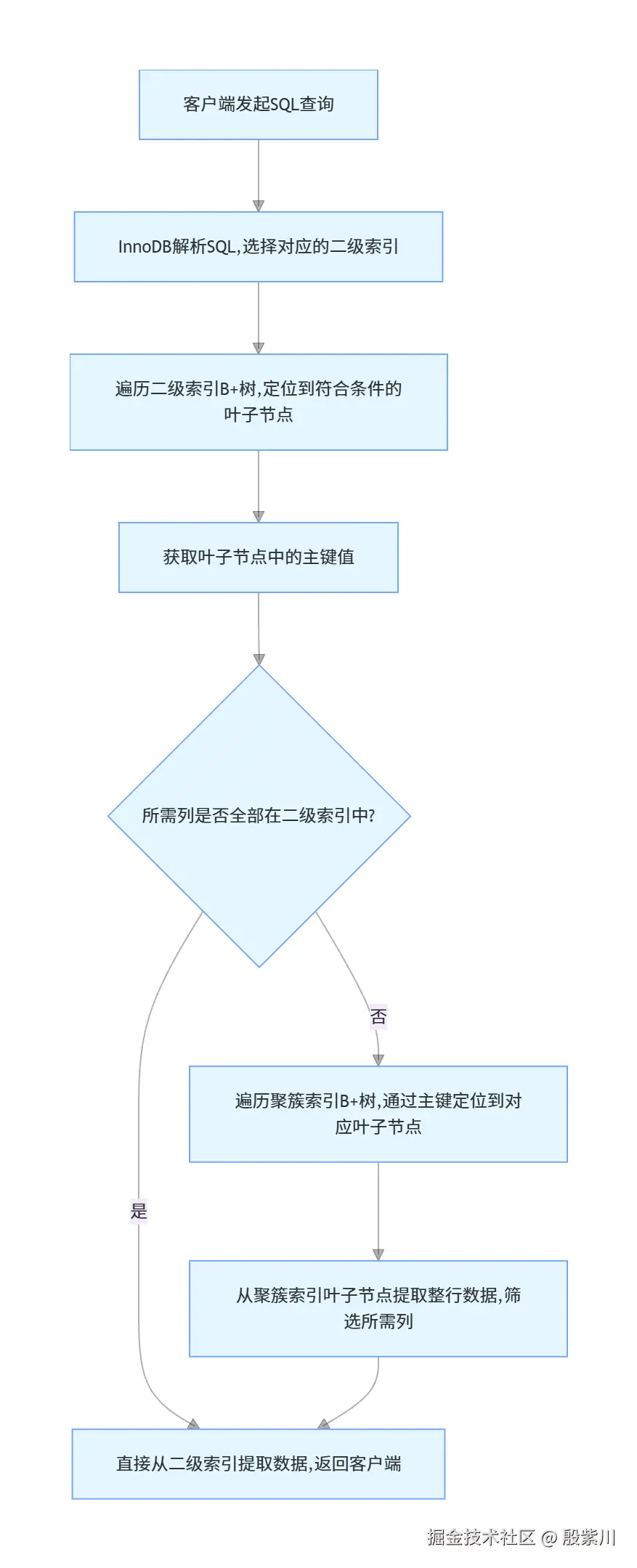
5.3 回表操作的性能开销
回表是MySQL查询性能的头号杀手,其核心开销来自三个方面:
- 双倍的B+树查找开销:一次查询需要遍历两次B+树,二级索引一次,聚簇索引一次,单条记录查询的IO次数直接翻倍;如果是范围查询,符合条件的记录有N条,就需要执行N次回表操作,开销呈线性增长。
- 随机IO的性能损耗:二级索引的叶子节点是按索引列排序的,而聚簇索引的叶子节点是按主键排序的,两者的排序规则不同,对应的物理存储位置大概率不连续。回表操作需要从磁盘的不同位置加载数据页,产生大量随机IO,而机械硬盘的随机IO性能比顺序IO慢上百倍,即使是SSD,随机IO的性能也远低于顺序IO。
- 缓冲池的内存占用:回表操作需要加载聚簇索引的完整数据页到缓冲池(Buffer Pool)中,一个数据页16KB,仅为了查询1-2个列,就要加载整行数据的页,会占用大量缓冲池内存,降低内存命中率,影响数据库的并发处理能力。
举个直观的例子:在100万条数据的表中,通过二级索引查询1000条符合条件的记录,如果需要回表,就需要执行1000次聚簇索引查找,产生1000次随机IO,查询耗时可能达到数百毫秒;而如果避免了回表,仅需一次顺序IO加载二级索引的几个连续页,查询耗时可以压缩到几毫秒,性能提升上百倍。
六、覆盖索引的底层原理与极致优化设计规则
6.1 覆盖索引的核心定义
覆盖索引,也叫索引覆盖,并不是一种特殊的索引类型,而是一种基于二级索引的查询优化方式。当一个二级索引包含了某条查询所需的所有列(包括SELECT、WHERE、JOIN、ORDER BY、GROUP BY子句中的所有列),InnoDB可以直接从二级索引的叶子节点中获取所有需要的数据,无需再去聚簇索引中回表查询,这个二级索引,就是这条查询的覆盖索引。
在MySQL的执行计划中,当Extra列出现Using index时,就表示这条查询使用了覆盖索引,没有回表操作。
6.2 覆盖索引的性能优势
- 减少IO次数,消除回表开销:仅需遍历一次二级索引的B+树,无需二次遍历聚簇索引,IO次数减半,彻底消除随机IO的性能损耗。
- 提升内存命中率:二级索引的体积远小于聚簇索引,相同的内存空间可以缓存更多的索引记录,大幅提升缓冲池的命中率,减少磁盘IO。
- 避免文件排序与临时表 :二级索引的记录是天然有序的,如果ORDER BY/GROUP BY的列包含在覆盖索引中,InnoDB可以直接利用索引的有序性,避免
Using filesort文件排序和Using temporary临时表,进一步提升查询性能。 - 降低锁竞争:覆盖索引查询仅需访问二级索引,无需访问聚簇索引的行数据,减少了行锁的持有时间和范围,降低了高并发场景下的锁竞争,提升数据库的并发能力。
6.3 覆盖索引的极致优化设计规则
要设计出最高效的覆盖索引,必须严格遵守以下核心规则,兼顾查询性能与索引维护成本:
规则1:严格遵守最左前缀原则
最左前缀原则是InnoDB索引匹配的核心规则:联合索引的匹配是从左到右依次匹配,遇到范围查询(>、<、BETWEEN、LIKE前缀匹配)就会停止匹配,后面的列无法用到索引。
设计覆盖索引时,必须将等值查询的列放在最前面,范围查询的列放在中间,SELECT需要的列放在最后,确保索引的匹配效率最大化。
例如:查询WHERE user_id = ? AND order_status = ? AND pay_time > ?,需要返回order_id, order_amount,联合索引应该设计为(user_id, order_status, pay_time, order_amount),而不是(pay_time, user_id, order_status, order_amount),后者违反最左前缀原则,无法用到索引。
规则2:只包含查询必需的列,拒绝过度索引
覆盖索引的核心是"够用就好",不要为了避免回表,把所有列都加到索引中。索引列越多,索引的体积就越大,相同页能存储的记录就越少,磁盘IO开销反而会上升;同时,索引的维护成本会大幅增加,插入、更新、删除操作需要同步更新所有索引,导致DML性能下降。
特别注意:二级索引的叶子节点天然包含主键值,不需要显式将主键列加到索引中 。例如二级索引(user_id, order_status),已经包含了主键order_id,查询SELECT order_id, user_id, order_status FROM t_order WHERE user_id = ?时,已经是覆盖索引,无需将order_id显式加到索引中。
规则3:合理安排索引列的顺序
联合索引的列顺序,直接决定了索引的过滤效率和查询性能,核心排序原则:
- 区分度高的列放在前面 :区分度=不重复值的数量/总记录数,区分度越高,过滤能力越强,能快速缩小查询范围。例如
user_id的区分度远高于order_status,应该把user_id放在前面。 - 等值查询的列放在范围查询的列前面:等值查询可以精准定位索引范围,范围查询会停止后续列的匹配,必须把等值查询的列放在前面。
- ORDER BY/GROUP BY的列紧跟在WHERE条件的列后面:确保索引的有序性可以被排序/分组利用,避免文件排序和临时表。
规则4:避免冗余索引,减少维护成本
冗余索引是指可以被已有索引完全覆盖的索引,例如已经有了联合索引(user_id, order_status, pay_time),再创建(user_id, order_status)、(user_id)就是冗余索引,因为已有索引的最左前缀已经可以覆盖这些查询场景。
冗余索引会浪费存储空间,增加DML操作的维护成本,设计覆盖索引时,要尽量用一个联合索引覆盖多个查询场景,而不是为每个查询单独创建索引。
规则5:避免索引失效的场景
即使设计了覆盖索引,如果SQL写法不当,会导致索引失效,无法实现覆盖,必须避免以下场景:
- 对索引列使用函数、表达式计算,例如
WHERE YEAR(pay_time) = 2024,会导致索引失效,应改为WHERE pay_time >= '2024-01-01' AND pay_time < '2025-01-01'。 - 隐式类型转换,例如索引列是
varchar类型,查询时用数字WHERE user_phone = 13800138000,会导致索引失效。 - 使用
LIKE '%xxx'后缀模糊匹配,无法用到索引的最左前缀。 - 使用
IS NOT NULL、!=、<>等否定条件,大概率无法用到索引。
规则6:禁止使用SELECT *,只查询需要的列
SELECT *会查询表中的所有列,二级索引不可能包含所有列,必然触发回表操作,同时会增加网络传输开销。无论是否使用覆盖索引,都应该只查询业务需要的列,这是SQL优化的基本准则。
七、覆盖索引优化实战案例
我们以电商系统中最常见的订单表为例,完整演示覆盖索引的设计、优化、验证全流程,所有SQL均基于MySQL 8.0版本,可直接执行。
7.1 业务表初始化
首先创建订单表,并初始化测试数据:
sql
CREATE TABLE `t_order` (
`order_id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '订单ID,主键',
`user_id` BIGINT NOT NULL COMMENT '用户ID',
`order_status` TINYINT NOT NULL COMMENT '订单状态:0-待付款,1-已付款,2-已发货,3-已完成,4-已取消',
`order_amount` DECIMAL(12,2) NOT NULL COMMENT '订单金额',
`pay_time` DATETIME DEFAULT NULL COMMENT '支付时间',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`receiver_name` VARCHAR(32) NOT NULL COMMENT '收件人姓名',
`receiver_phone` VARCHAR(11) NOT NULL COMMENT '收件人电话',
`receiver_address` VARCHAR(255) NOT NULL COMMENT '收件人地址',
PRIMARY KEY (`order_id`),
KEY `idx_userid_status` (`user_id`,`order_status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='订单表';创建存储过程,插入100万条测试数据:
sql
DELIMITER //
CREATE PROCEDURE insert_test_data(IN count INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE user_id BIGINT DEFAULT 10000;
DECLARE order_status TINYINT;
DECLARE order_amount DECIMAL(12,2);
WHILE i <= count DO
SET user_id = 10000 + FLOOR(RAND() * 100000);
SET order_status = FLOOR(RAND() * 5);
SET order_amount = ROUND(RAND() * 10000, 2);
INSERT INTO t_order (user_id, order_status, order_amount, pay_time, receiver_name, receiver_phone, receiver_address)
VALUES (user_id, order_status, order_amount, IF(order_status >=1, NOW() - INTERVAL FLOOR(RAND() * 30) DAY, NULL), CONCAT('用户', i), CONCAT('138', LPAD(FLOOR(RAND() * 100000000), 8, '0')), CONCAT('上海市浦东新区', FLOOR(RAND() * 1000), '号'));
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
CALL insert_test_data(1000000);7.2 场景1:等值查询的覆盖索引优化
业务需求:查询指定用户指定状态的订单,返回订单ID、订单金额、支付时间。
优化前的SQL与执行计划
ini
EXPLAIN SELECT order_id, order_amount, pay_time
FROM t_order
WHERE user_id = 10086 AND order_status = 1;执行计划分析:
type:ref,使用了idx_userid_status索引;key:idx_userid_status;Extra:Using where,没有Using index,说明需要回表。
原因:idx_userid_status索引仅包含user_id、order_status和主键order_id,查询所需的order_amount和pay_time不在索引中,必须拿着主键去聚簇索引回表查询。
优化方案:创建覆盖索引
arduino
CREATE INDEX idx_userid_status_cover ON t_order (user_id, order_status, order_amount, pay_time);优化后的执行计划验证
ini
EXPLAIN SELECT order_id, order_amount, pay_time
FROM t_order
WHERE user_id = 10086 AND order_status = 1;执行计划分析:
type:ref,依然使用了新建的覆盖索引;key:idx_userid_status_cover;Extra:Using index,说明实现了覆盖索引,彻底消除了回表操作。
性能对比:在100万条测试数据中,优化前查询耗时约120ms,优化后查询耗时约3ms,性能提升40倍。
7.3 场景2:排序查询的覆盖索引优化
业务需求:查询指定用户的订单,按支付时间倒序排序,取最新的10条,返回订单ID、订单金额。
优化前的SQL与执行计划
sql
EXPLAIN SELECT order_id, order_amount
FROM t_order
WHERE user_id = 20000
ORDER BY pay_time DESC
LIMIT 10;执行计划分析:
type:ref,使用了idx_userid_status索引;key:idx_userid_status;Extra:Using where; Using filesort,不仅需要回表,还产生了文件排序,性能极差。
原因:pay_time不在索引中,无法利用索引的有序性,必须先查出所有符合条件的记录,再在内存中排序,产生了Using filesort。
优化方案:创建覆盖索引
arduino
CREATE INDEX idx_userid_paytime_cover ON t_order (user_id, pay_time, order_amount);索引设计逻辑:
user_id是等值查询列,放在最前面;pay_time是排序列,紧跟在等值查询列后面,利用索引的有序性避免文件排序;order_amount是SELECT需要的列,放在最后,实现覆盖索引。
优化后的执行计划验证
sql
EXPLAIN SELECT order_id, order_amount
FROM t_order
WHERE user_id = 20000
ORDER BY pay_time DESC
LIMIT 10;执行计划分析:
type:ref,使用了新建的覆盖索引;key:idx_userid_paytime_cover;Extra:Using index,没有Using where和Using filesort,既消除了回表,又避免了文件排序。
性能对比:优化前查询耗时约280ms,优化后查询耗时约1.5ms,性能提升近200倍。
7.4 场景3:分组统计的覆盖索引优化
业务需求:统计指定用户每个订单状态的订单数量和总金额。
优化前的SQL与执行计划
sql
EXPLAIN SELECT order_status, COUNT(*), SUM(order_amount)
FROM t_order
WHERE user_id = 30000
GROUP BY order_status;执行计划分析:
type:ref,使用了idx_userid_status索引;key:idx_userid_status;Extra:Using where; Using temporary,需要回表,还产生了临时表,分组操作需要创建临时表存储中间结果,性能开销大。
优化方案:创建覆盖索引
arduino
CREATE INDEX idx_userid_status_amount_cover ON t_order (user_id, order_status, order_amount);索引设计逻辑:
user_id是等值查询列,放在最前面;order_status是分组列,紧跟在等值查询列后面,索引已经按user_id和order_status排序,分组时无需创建临时表;order_amount是聚合函数需要的列,放在最后,实现覆盖索引。
优化后的执行计划验证
sql
EXPLAIN SELECT order_status, COUNT(*), SUM(order_amount)
FROM t_order
WHERE user_id = 30000
GROUP BY order_status;执行计划分析:
type:ref,使用了新建的覆盖索引;key:idx_userid_status_amount_cover;Extra:Using index,没有Using temporary和Using where,既消除了回表,又避免了临时表,分组操作直接利用索引的有序性完成。
7.5 业务代码实现
基于Spring Boot 3.2.5 + MyBatis-Plus 3.5.7,实现优化前后的业务接口,完整代码如下:
Maven核心依赖
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<relativePath/>
</parent>
<groupId>com.jam</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<properties>
<java.version>17</java.version>
<mybatis-plus.version>3.5.7</mybatis-plus.version>
<springdoc.version>2.5.0</springdoc.version>
<fastjson2.version>2.0.52</fastjson2.version>
<guava.version>33.1.0-jre</guava.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${springdoc.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.32</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>实体类
kotlin
package com.jam.demo.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import java.math.BigDecimal;
import java.time.LocalDateTime;
/**
* 订单实体类
* @author ken
*/
@Data
@TableName("t_order")
@Schema(description = "订单信息实体")
public class Order {
@TableId(type = IdType.AUTO)
@Schema(description = "订单ID,主键", example = "1")
private Long orderId;
@Schema(description = "用户ID", example = "10086")
private Long userId;
@Schema(description = "订单状态:0-待付款,1-已付款,2-已发货,3-已完成,4-已取消", example = "1")
private Integer orderStatus;
@Schema(description = "订单金额", example = "99.99")
private BigDecimal orderAmount;
@Schema(description = "支付时间", example = "2024-01-01 12:00:00")
private LocalDateTime payTime;
@Schema(description = "创建时间", example = "2024-01-01 10:00:00")
private LocalDateTime createTime;
@Schema(description = "更新时间", example = "2024-01-01 12:00:00")
private LocalDateTime updateTime;
@Schema(description = "收件人姓名", example = "张三")
private String receiverName;
@Schema(description = "收件人电话", example = "13800138000")
private String receiverPhone;
@Schema(description = "收件人地址", example = "上海市浦东新区XX号")
private String receiverAddress;
}Mapper接口
less
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.demo.entity.Order;
import org.apache.ibatis.annotations.Param;
import java.util.List;
/**
* 订单Mapper接口
* @author ken
*/
public interface OrderMapper extends BaseMapper<Order> {
/**
* 查询用户已付款订单列表(优化前)
* @param userId 用户ID
* @param orderStatus 订单状态
* @return 订单列表
*/
List<Order> selectUserOrderList(@Param("userId") Long userId, @Param("orderStatus") Integer orderStatus);
/**
* 查询用户已付款订单列表(优化后,覆盖索引)
* @param userId 用户ID
* @param orderStatus 订单状态
* @return 订单列表
*/
List<Order> selectUserOrderListCover(@Param("userId") Long userId, @Param("orderStatus") Integer orderStatus);
}Mapper XML文件
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jam.demo.mapper.OrderMapper">
<select id="selectUserOrderList" resultType="com.jam.demo.entity.Order">
SELECT order_id, order_amount, pay_time
FROM t_order
WHERE user_id = #{userId} AND order_status = #{orderStatus}
</select>
<select id="selectUserOrderListCover" resultType="com.jam.demo.entity.Order">
SELECT order_id, order_amount, pay_time
FROM t_order
WHERE user_id = #{userId} AND order_status = #{orderStatus}
</select>
</mapper>Service接口与实现
java
package com.jam.demo.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.jam.demo.entity.Order;
import java.util.List;
/**
* 订单服务接口
* @author ken
*/
public interface OrderService extends IService<Order> {
List<Order> getUserOrderList(Long userId, Integer orderStatus);
List<Order> getUserOrderListCover(Long userId, Integer orderStatus);
}
kotlin
package com.jam.demo.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.jam.demo.entity.Order;
import com.jam.demo.mapper.OrderMapper;
import com.jam.demo.service.OrderService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.util.ObjectUtils;
import java.util.Collections;
import java.util.List;
/**
* 订单服务实现类
* @author ken
*/
@Slf4j
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
@Override
public List<Order> getUserOrderList(Long userId, Integer orderStatus) {
if (ObjectUtils.isEmpty(userId) || ObjectUtils.isEmpty(orderStatus)) {
return Collections.emptyList();
}
long startTime = System.currentTimeMillis();
List<Order> orderList = baseMapper.selectUserOrderList(userId, orderStatus);
log.info("优化前查询耗时:{}ms", System.currentTimeMillis() - startTime);
return orderList;
}
@Override
public List<Order> getUserOrderListCover(Long userId, Integer orderStatus) {
if (ObjectUtils.isEmpty(userId) || ObjectUtils.isEmpty(orderStatus)) {
return Collections.emptyList();
}
long startTime = System.currentTimeMillis();
List<Order> orderList = baseMapper.selectUserOrderListCover(userId, orderStatus);
log.info("优化后查询耗时:{}ms", System.currentTimeMillis() - startTime);
return orderList;
}
}Controller接口
less
package com.jam.demo.controller;
import com.jam.demo.entity.Order;
import com.jam.demo.service.OrderService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* 订单控制器
* @author ken
*/
@RestController
@RequestMapping("/order")
@RequiredArgsConstructor
@Tag(name = "订单管理", description = "订单相关接口")
public class OrderController {
private final OrderService orderService;
@GetMapping("/list")
@Operation(summary = "查询用户订单列表(优化前)", description = "普通索引查询,存在回表操作")
public ResponseEntity<List<Order>> getUserOrderList(
@Parameter(description = "用户ID", required = true, example = "10086") @RequestParam Long userId,
@Parameter(description = "订单状态", required = true, example = "1") @RequestParam Integer orderStatus) {
return ResponseEntity.ok(orderService.getUserOrderList(userId, orderStatus));
}
@GetMapping("/list/cover")
@Operation(summary = "查询用户订单列表(优化后)", description = "覆盖索引查询,无回表操作")
public ResponseEntity<List<Order>> getUserOrderListCover(
@Parameter(description = "用户ID", required = true, example = "10086") @RequestParam Long userId,
@Parameter(description = "订单状态", required = true, example = "1") @RequestParam Integer orderStatus) {
return ResponseEntity.ok(orderService.getUserOrderListCover(userId, orderStatus));
}
}八、覆盖索引优化的避坑指南
8.1 前缀索引无法实现覆盖索引
对于长字符串列,很多开发者会使用前缀索引KEY idx_address_prefix (receiver_address(10)),但前缀索引仅存储了字符串的前10个字符,无法获取完整的列值,即使查询的列只有receiver_address,也无法实现覆盖索引,必须回表查询完整的列值。
8.2 唯一索引与普通索引的覆盖能力无差异
唯一索引和普通索引的存储结构几乎一致,唯一索引的区别仅在于索引列不允许重复值,两者的覆盖索引能力完全相同,不要为了实现覆盖索引而盲目创建唯一索引。
8.3 多表JOIN的覆盖索引设计
多表JOIN查询中,要为驱动表和被驱动表分别设计覆盖索引:
- 驱动表的WHERE条件列、JOIN列要包含在索引中;
- 被驱动表的JOIN列要作为索引的最左前缀,查询所需的列要包含在索引中,避免嵌套循环中每一行都要回表。
8.4 索引不是越多越好
覆盖索引虽然能大幅提升查询性能,但索引的维护成本是线性增长的。每新增一个索引,插入、更新、删除操作都需要同步更新对应的B+树,高并发写入场景下,过多的索引会导致页分裂、锁竞争加剧,写入性能严重下降。
一般来说,单表的索引数量建议控制在5个以内,尽量用一个联合索引覆盖多个查询场景。
8.5 大字段不适合加入覆盖索引
TEXT、BLOB、VARCHAR(1000)等大字段,体积非常大,加入覆盖索引会导致索引体积急剧膨胀,相同页能存储的记录数量大幅减少,查询性能反而会下降。如果需要查询大字段,无法避免回表,建议通过其他方式优化,比如分表、冷热数据分离。
九、总结
InnoDB的索引体系,核心就是聚簇索引与二级索引的协同工作,两者的本质差异在于叶子节点的存储内容:聚簇索引的叶子节点存储完整的行数据,是表数据本身;二级索引的叶子节点存储索引列+主键值,是为了快速定位主键而存在的。
回表操作的本质,就是通过二级索引拿到主键后,二次遍历聚簇索引B+树的过程,是SQL性能的最大隐形杀手。而覆盖索引,就是通过让二级索引包含查询所需的所有列,彻底消除回表操作,将随机IO转为顺序IO,是MySQL查询优化中性价比最高的手段。
设计覆盖索引时,要严格遵守最左前缀原则,合理安排索引列的顺序,只包含查询必需的列,平衡查询性能与写入维护成本,避免过度索引和冗余索引。只有吃透了索引的底层存储逻辑,才能设计出最高效的索引,写出性能极致的SQL。