MySQL 事务隔离级别 锁 高并发场景优化经验
好嘞!那咱们今天就彻底抛弃那些让人头大的学术名词,用最接地气、最拔草的方式,把"事务隔离级别"和"锁"这对数据库里的神仙伴侣给你讲得明明白白。
如果说"锁"是具体的武器和招式,那么"隔离级别"就是内功心法和指导思想。只讲锁不讲隔离级别,就像只练招式不修内功,注定走火入魔。
咱们直接"注入灵魂",从最高层的思想开始聊。
第一幕:隔离级别------老板对并发的"容忍底线"
数据库里为什么要有"事务隔离级别"?
想象一下,你的数据库是一个超级火爆的菜市场(高并发),无数个买菜的人(事务)同时在抢摊位上的菜(数据)。如果不加限制,场面一定会失控。
于是,数据库大老板制定了 4 个不同严厉程度的管理制度 ,这就是四种隔离级别。级别越高,规矩越死,速度越慢。
级别 1:Read Uncommitted(读未提交)------ 放任自流
- 大白话 :允许"看空气"。隔壁摊位的老王刚把菜放到篮子里,还没付钱呢(事务未提交),你就能看到并大喊:"老王买菜了!"结果老王一摸兜发现没带钱,又把菜放回去了(事务回滚)。你看到的成了空气。
- 专业黑话 :脏读(Dirty Read) 。
级别 2:Read Committed(读已提交)------ 睁眼说瞎话
- 大白话 :老王不付钱,你绝看不到。但这带来一个新问题:你刚看了一眼摊位,还有一颗白菜(第一次读);这时候隔壁小张过来神速付钱把白菜买走了(事务提交);你揉揉眼再看,白菜没了(第二次读)。
- 专业黑话 :不可重复读(Non-repeatable Read) 。同一条数据,前后两次读到的内容不一样。
3. Read Repeatable(可重复读 ------ MySQL默认级别)------ 活在自己的世界里
- 大白话 :为了解决上面的尴尬,老板给你发了个"VR眼镜"。只要你的事务没结束,你每一次看这个摊位,白菜都在那,哪怕现实中它早就被小张买走吃进肚子里了!
- 新Bug(幻读) :白菜虽然没变,但小张突然在隔壁空地上新摆了一个萝卜 并付了钱。你戴着VR眼镜本来觉得安全,结果一伸手,突然摸到了一个凭空出现的萝卜!
- 专业黑话 :幻读(Phantom Read) 。前后两次查询,虽然旧数据没变,但突然多出了 一到几条新数据。
4. Serializable(串行化)------ 绝对禁闭
- 大白话 :别抢了,所有人排成一队,一个一个来。我买完了,你再进场。
- 代价 :并发性能直接归零。
第二幕:锁------为了贯彻心法,掏出的物理武器
指导思想(隔离级别)有了,数据库怎么去实现它呢?靠的就是"锁"这个物理武器。
不同的隔离级别,底层掏出的锁是完全不一样的。我们以 MySQL 的 RC(读已提交) 和 RR(可重复读) 这两个最常用的级别来对比,看看锁是怎么配合灵魂演戏的。
武器 1:记录锁(Record Lock)------ 别动这头猪
- 操作 :
<span>WHERE id = 1 FOR UPDATE</span> - RC 和 RR 的共同选择 :不管在哪个级别,只要你明确指定了要改
<span>id = 1</span>这条记录,MySQL 就会在这条记录上斩下一把记录锁 。在你的事务结束前,谁也别想改它。
武器 2:间隙锁(Gap Lock)------ 圈地盘,谁也别想生孩子
- 操作 :
<span>WHERE id > 1 AND id < 5 FOR UPDATE</span>(假设数据库里只有 id=1 和 id=5 的数据) - RC(读已提交)的反应 :RC 耸耸肩说:"我只要保证大家不脏读就行,我管你生不生孩子。"于是 RC不加间隙锁 。别人随时可以插入
<span>id=2, 3, 4</span>的新数据。 - RR(可重复读)的反应 :RR 的终极任务是干掉"幻读" (不让你摸到凭空出现的萝卜)。它一拍桌子,直接在 (1, 5) 这个不存在的空隙里 拉了一道警戒线,这就是间隙锁 !
- 结果 :此时另一个事务如果想
<span>INSERT id=3</span>,对不起,直接被间隙锁拦截,在外面老老实实排队,直到你这边完事。幻读被完美解决!
武器 3:意向锁(Intention Lock)------ 进大门前的"打招呼"
很多人死活看不懂意向锁(IS/IX),其实它就是个前台告示牌 。
- 场景 :你打算去改
<span>id = 100</span>的行(需要加行锁)。这时候,另一个霸道总裁事务想搞大事情,执行了<span>LOCK TABLES users WRITE</span>(想锁整张表)。 - 没有意向锁的世界 :霸道总裁为了锁表,必须苦哈哈地去遍历这张表里的几百万行 ,挨个检查有没有人加了行锁。这数据库当场就得冒烟。
- 有意向锁的世界 :你在改
<span>id = 100</span>之前,数据库会自动在表门口 挂一个小牌子:"里面有人在改行数据哦!"(意向排他锁)。霸道总裁走到表门口,一看小牌子,扭头就去睡觉等待了,根本不用进表里去挨个查。
终幕:神仙伴侣的合体(总结)
所以,你发现了吗?
- 隔离级别是"目标" :业务上你能容忍多大的数据混乱,就选什么级别。
- 锁是"手段" :
- 你选了RC(读已提交) ,MySQL 就偷懒,只用记录锁 ,大家并发高,快乐起飞,但数据可能前后不一致。
- 你选了RR(可重复读) ,MySQL 为了尊严,掏出了记录锁 + 间隙锁(合称临键锁)的组合拳,把数据死死卡住,不给幻读任何机会,代价是大家经常要互相等待(甚至导致死锁)。 懂了事务隔离级别的"灵魂",再去看那些锁的招式,是不是觉得它们每一个的出现,都是那么顺理成章、被逼无奈了?
电商场景绝对是高并发和锁冲突的"重灾区"。前一秒大家还在高高兴兴抢购,后一秒数据库可能就因为锁等待直接"宕机"了。
我们用刚才讲的"事务灵魂 + 锁武器"的逻辑,来看看电商最核心的 3 个高频翻车场景,以及大厂是怎么用大白话和一行行代码把它们优化掉的。
场景一:商品秒杀与扣减库存(高频热点行冲突)
❌ 翻车现场(悲观锁死扛)
很多刚入行的同学写扣库存,为了防止"超卖",直接上来就整大招:
SQL
sql
-- 事务开始
BEGIN;
-- 1. 查库存并死死锁住这条记录(悲观锁)
SELECT stock FROM sku_stock WHERE sku_id = 10086 FOR UPDATE;
-- 2. 内存里判断库存够不够,够的话就减库存
UPDATE sku_stock SET stock = stock - 1 WHERE sku_id = 10086;
COMMIT;- 灵魂拷问 :在 RR 或 RC 隔离级别下,这把
<span>FOR UPDATE</span>会给这条记录加排他锁(X锁) 。秒杀时几万人同时抢这一个<span>sku_id</span>,所有人都在门口排队死等这把锁。这就好比一万人排队上同一个厕所,后面的人等得不耐烦(连接超时),系统直接崩溃。
🚀 优化方案:利用数据库原子更新 + 扣减判断
根本不需要在外面用 <span>FOR UPDATE</span> 锁住不放!直接利用 MySQL 自带的行级锁原子性,把查和改合并成一步:
SQL
ini
-- 抛弃 FOR UPDATE,直接硬刚 UPDATE
UPDATE sku_stock
SET stock = stock - 1
WHERE sku_id = 10086 AND stock >= 1;- 妙在哪里 :MySQL 在执行这条
<span>UPDATE</span>时,会自动给这一行加锁,并在更新完后释放。通过<span>stock >= 1</span>这个条件,直接在数据库层把"超卖"拦截掉。Java 代码里只需要判断返回的"受影响行数(Affected Rows)"是否大于 0。如果等于 0,直接给前端返回"手慢了,商品已售罄!"
场景二:生成订单与防止重复提交(防重撞车)
❌ 翻车现场(间隙锁导致连环死锁)
用户狂点"提交订单"按钮,或者前端重试,导致两个一模一样的请求同时到达后端。为了防止生成两条重复的订单,有人这样写:
SQL
sql
-- 假设订单号 order_no 是唯一索引
BEGIN;
-- 1. 先查一下这个订单号存在不
SELECT id FROM orders WHERE order_no = '20260520XXXX' FOR UPDATE;
-- 2. 如果不存在,就插入
INSERT INTO orders (order_no, user_id) VALUES ('20260520XXXX', 123);
COMMIT;- 灵魂拷问 :还记得我们上面说的吗?在RR(可重复读) 隔离级别下,用
<span>FOR UPDATE</span>去查一个不存在 的记录,MySQL 会掏出什么武器?间隙锁(Gap Lock) ! - 如果请求 A 和请求 B 同时到了,A 查不到,加了间隙锁;B 也查不到,也加了间隙锁(间隙锁和间隙锁不冲突)。紧接着,A 准备执行
<span>INSERT</span>,被 B 的间隙锁挡住了,只能等;B 也准备执行<span>INSERT</span>,被 A 的间隙锁挡住了,也只能等。 - Boom!两个人都拿着钥匙等对方开门,当场触发死锁(Deadlock)。
🚀 优化方案:唯一索引 + 异常捕获(或者 RC 隔离级别)
别用 <span>FOR UPDATE</span> 去钓鱼执法了。直接利用数据库的唯一索引(Unique Key)硬碰硬:
SQL
sql
-- 1. 别查了,直接死磕插入
INSERT INTO orders (order_no, user_id) VALUES ('20260520XXXX', 123);在 Java 代码里,用 <span>try-catch</span> 抱住这个订单创建逻辑。如果抛出了 <span>DuplicateKeyException</span>(违反唯一约束异常),直接判定为"重复提交",优雅地给前端返回:"订单已处理,请勿重复提交"。连锁都不用加,性能拉满。
场景三:商户后台批量修改商品价格(大事务锁表)
❌ 翻车现场(一刀切的大事务)
运营小姐姐要在后台把某个分类下的 5000 个商品全部打 8 折。开发一想,简单啊,一个 <span>@Transactional</span> 搞定:
Java
scss
@Transactional
public void updateCategoryPrices(Long categoryId) {
// 1. 全表扫描或者大范围查询,锁死这批商品
List<Product> products = productRepository.findByCategoryIdForUpdate(categoryId);
for (Product p : products) {
p.setPrice(p.getPrice() * 0.8);
productRepository.save(p); // 挨个更新
// 2. 顺便调用一下外部的物流系统/短信通知接口(致命伤!)
thirdPartyService.syncPriceToPartner(p);
}
}- 灵魂拷问 :这个事务太"大"了!
- 如果
<span>category_id</span>没加索引,直接全表所有记录加行锁 ,相当于锁表。 - 哪怕加了索引,这 5000 条记录也会被死死锁住。更要命的是,在循环里还调用了远程第三方接口(网络 I/O)。如果第三方接口响应慢,这几千条数据的锁就会一直挂着。此时,C端用户在前台连这些商品的详情页都打不开(因为被 X 锁挡住了) 。
- 如果
🚀 优化方案:化整为零 + 事务与长耗时操作剥离
大事务是数据库并发的头号杀手。优化的核心思想就是:快进快出,绝不在事务里谈恋爱(调外网接口)。
Java
scss
public void updateCategoryPricesOptimized(Long categoryId) {
// 1. 先把要修改的商品 ID 查出来(不加锁,RC/RR 下快照读不影响别人)
List<Long> productIds = productRepository.findIdsByCategoryId(categoryId);
// 2. 分批处理(化整为零),比如每 100 个商品一个独立的小事务
List<List<Long>> batches = Lists.partition(productIds, 100);
for (List<Long> batch : batches) {
// 调用带独立事务的方法,改完 100 个立马提交释放锁
productService.innerUpdatePriceBatch(batch);
// 3. 事务提交后,再异步通知第三方(不耽误数据库的事)
asyncNotifyThirdParty(batch);
}
}
@Transactional // 独立的小事务
public void innerUpdatePriceBatch(List<Long> batchIds) {
// 批量更新,尽量缩短锁持有时间
productRepository.updatePriceScale(batchIds, 0.8);
}💡 总结一句话
在电商高并发场景下,优化的精髓就一句话:
尽量少用
<span>FOR UPDATE</span>;能用一条<span>UPDATE</span>搞定的别写成先查再改;事务能多小就多小,千万别在事务里等网络请求。
数据库事务隔离级别深向对照表
在多用户并发访问数据库时,事务隔离级别(Transaction Isolation Levels)是控制数据一致性与系统并发性能的天平。以下是 SQL 92 标准定义的四种隔离级别的详细对照:
事务隔离级别对照表
| 编号 | 简写 | 学术名称 (Standard Name) | 核心解析 (Plain Explanation) | 缺陷防范 (Bugs Prevented) | 备注与生产建议 (Remarks & Best Practices) |
|---|---|---|---|---|---|
| 1 | RU | 读未提交(Read Uncommitted) | **"允许看空气"**事务 A 还没提交的修改,事务 B 就能看到并拿去用。 | ❌ 无法防止任何并发问题。可能导致脏读 、不可重复读 、幻读 。 | **极度危险!**生产环境基本不使用,仅在极少数对一致性毫无要求、只求极致吞吐量的特殊监控场景下可能露脸。 |
| 2 | RC | 读已提交(Read Committed) | **"不见兔子不撒鹰"**事务 A 必须确认提交后,事务 B 才能看到它修改后的最新数据。 | ✅ 解决:脏读 ❌ 无法解决:不可重复读 、幻读 | 主流数据库的宠儿 · Oracle、PostgreSQL、SQL Server 的默认隔离级别 。· 锁粒度极小,不使用间隙锁,高并发吞吐表现极佳。 |
| 3 | RR | 可重复读(Repeatable Read) | **"戴上 VR 眼镜"**只要事务不结束,你前后看同一条数据永远是一样的,不管别人在外面怎么改。 | ✅ 解决:脏读 、不可重复读 ❌ 无法解决:幻读 (但 MySQL 靠锁和 MVCC 搞定了) | MySQL (InnoDB) 的默认级别 · 在默认的 RR 级别下,MySQL 依靠 MVCC(多版本并发控制) 和 Next-Key Lock(临键锁) ,已经在实际上同时解决了幻读问题 。· 缺点是间隙锁容易引发死锁。 |
| 4 | SR | 可串行化(Serializable) | **"绝对禁闭/排队上车"**事务完全按先后顺序一个一个执行。只要有人在读,别人连改的权力都没有,全部排队。 | ✅ 解决所有并发问题:脏读 、不可重复读 、幻读 全部消除。 | 防线,但代价巨大· 靠强烈的行锁和表锁实现,并发性能暴跌。· 仅在对资金、账目要求绝对精准且并发极低的极特殊金融场景中选用。 |
辅助理解:隔离级别 vs 并发痛点
为了更直观地展示各隔离级别对高并发"翻车现场"的免疫情况,可以参考下表:
| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) | 锁退化与开销 |
|---|---|---|---|---|
| Read Uncommitted | ❌ 无法防御 | ❌ 无法防御 | ❌ 无法防御 | 极低(几乎无锁等待) |
| Read Committed | 防线 | ❌ 无法防御 | ❌ 无法防御 | 较低(仅使用记录锁) |
| Repeatable Read | 防线 | 防线 | ❌ 标准标准无法防 (MySQL 特例可防) | 中等(引入间隙锁,死锁风险增加) |
| Serializable | 防线 | 防线 | 防线 | 极高(全表/大范围排队,无并发可言) |
💡 核心专业词汇秒懂小册子
- 脏读 (Dirty Read) :读到了别人"写到一半、随时可能反悔(回滚)"的脏数据。
- 不可重复读 (Non-Repeatable Read) :针对UPDATE/DELETE 。在同一个事务里,两次读同一行数据,由于别人中途修改了,导致前后结果不一样。
- 幻读 (Phantom Read) :针对INSERT 。在同一个事务里,前后两次做范围查询,由于别人中途插入了新数据,导致后一次莫名其妙多出了几行 。
- MVCC (Multi-Version Concurrency Control) :多版本并发控制。通过保存数据的历史快照,实现"读不加锁,读写不冲突"的神仙技术(RC 和 RR 级别的底层核心)。
既然咱们已经用"占坑拉屎"的理论把高并发的精髓盘明白了,那数据库优化这事儿就变得很简单了:要么缩短占坑时间,要么让大家不用去抢同一个坑,甚至不进公厕。
在电商、社交、金融等高并发场景下,还有 4 个非常经典的"翻车重灾区"。咱们继续用大白话,看看怎么解决这几个场景下的锁冲突。
场景四:账户余额充值与扣减(热点账户撞车)
❌ 翻车现场(全挤到同一个坑里)
有些大主播(比如大杨哥、李佳琦)或者大商户,大促期间全网的用户都在往他们的账户里打钱,或者系统在疯狂扣减他们的佣金。
SQL
sql
-- 几万个并发同时改这一个商户的余额
UPDATE user_account SET balance = balance + 100 WHERE merchant_id = 8888;- 灵魂拷问 :虽然这已经用了最快的"原子扣减模式",没有网络延迟,但这一行数据 在 MySQL 底层同时只能被一个事务加锁修改。几万并发卡在 MySQL 的行锁队列里,数据库 CPU 瞬间拉满,队列后面的请求还是会超时。
🚀 优化方案:分摊"小坑"(子账户/子行模式)
既然一个坑不够用,咱们就多建几个坑!把一条热点数据,拆成多条"子数据"。
- 操作方法 :在数据库里,给这个超级商户建立 10 条账户分片记录(比如
<span>slice_id</span>从 0 到 9)。 - Java 逻辑 :用户给商户充值时,Java 层随机生成一个 0~9 的随机数:
Java
scss
int randomSlice = new Random().nextInt(10);
// 每次充值,随机打到其中一个子账户上
accountRepository.updateBalanceSlice(merchant_id, randomSlice, amount);SQL
ini
-- 实际执行的 SQL
UPDATE merchant_account_slice
SET balance = balance + 100
WHERE merchant_id = 8888 AND slice_id = 3; -- 锁冲突直接降低到原来的 1/10!- 如何查总额 :商户在后台看总余额时,数据库执行
<span>SUM(balance) WHERE merchant_id = 8888</span>把 10 条记录加起来就行。用空间换时间 ,把并发压力直接分摊。
场景五:优惠卷/秒杀资格"每人限领一张"(防刷撞车)
❌ 翻车现场(用悲观锁去防守"不存在"的数据)
抢优惠券时,为了防止黑产用脚本黄牛号一秒钟发几百个请求把券刷走,开发写了这样的逻辑:
SQL
sql
-- 1. 先锁住这个用户领这个券的记录,看领过没有
SELECT id FROM user_coupon WHERE user_id = 123 AND coupon_id = 999 FOR UPDATE;
-- 2. 如果没领过,就插入一条
INSERT INTO user_coupon (user_id, coupon_id) VALUES (123, 999);- 灵魂拷问 :这跟我们之前说的订单去重一样。用户第一次 来领的时候,数据库里根本没有这条记录!你用
<span>FOR UPDATE</span>去查一个不存在的数据,在 RR 隔离级别下会直接触发间隙锁(Gap Lock) 。 - 如果这个用户并发点了两下,两个请求同时加了间隙锁,下一步同时执行
<span>INSERT</span>,直接死锁(Deadlock)连环爆炸 。为了防个刷子,把自己数据库搞崩溃了。
🚀 优化方案:把防守线推到"公厕外面"(Redis 挡枪)
这种"限领/防重"的判断,千万别让数据库冲在第一线 ,数据库的锁太贵了。请 Redis 过来当保安:
Java
ini
// 1. 利用 Redis 的原子性 SetNX(不存在才设置成功)
String redisKey = "lock:coupon:" + couponId + ":" + userId;
boolean isFirstClaim = redisTemplate.opsForValue().setIfAbsent(redisKey, "1", Duration.ofMinutes(5));
if (!isFirstClaim) {
return "您已经领过该优惠券啦!";
}
// 2. 成功拿到 Redis 绿卡的人,才允许进数据库执行 INSERT
couponRepository.save(new UserCoupon(userId, couponId));- 妙在哪里 :Redis 是内存操作,每秒扛 10 万并发轻轻松松。把"占坑"的动作直接在 Redis 内存里做完了,数据库只需要闭着眼睛做
<span>INSERT</span>,连锁都不用考虑,不仅不会死锁,性能还翻了几十倍。
场景六:历史订单/账单大范围查询(读写撞车)
❌ 翻车现场(老账单把新业务锁死)
运营或者财务要在后台导出过去 3 个月的全部订单流水,一写就是个大范围查询:
SQL
sql
SELECT * FROM orders WHERE created_at BETWEEN '2026-01-01' AND '2026-03-31';- 灵魂拷问 :如果这时候数据库刚好在做别的事,或者开发不小心加了
<span>FOR UPDATE</span>(或者在某些特定隔离级别和索引不当的情况下),这种大范围扫描会把大片大片的行和间隙全部锁死。 - 这边财务在慢吞吞地导报表,前台C端用户想下单、改订单状态,全部被卡住报超时。老数据把新业务给活活耗死了。
🚀 优化方案:读写分离 + 快照读(不占坑只看戏)
- 彻底划清界限(CQRS思想/读写分离) :在架构上,前台用户下单、支付,全部走主库(Master) ;后台导报表、对账、查历史订单,全部走从库(Slave)或者专用的数据分析数据库(如 ClickHouse、Elasticsearch)。从库哪怕锁翻天,也绝不影响主库的用户下单。
- 利用 MVCC(快照读) :在 MySQL 默认的 RR/RC 级别下,普通的
<span>SELECT</span>(不带<span>FOR UPDATE</span>)是不加任何锁的 。它读的是数据的历史快照(MVCC)。财务导报表时,明确要求不要加任何锁,安心"看戏"就行,让下单的请求在前面继续跑。
💡 核心总结
看了这么多大厂的真实优化案例,你会发现高并发架构的路线非常清晰:
- 能在内存解决的,绝不落到数据库 (比如:场景五用 Redis 挡枪)。
- 必须落到数据库的,尽量缩短锁时间 (比如:方案二的原子 UPDATE)。
- 实在是单行热点的,想办法拆成多行 (比如:场景四的账户分片)。
- 读多写少的场景,直接读写分离 (比如:场景六的从库导报表)。
说白了,就是把"拉屎"这件事分流、加速、甚至换地方,让数据库这个公厕永远保持高效率运转!
用 Mermaid 时序图来表达简直太合适了!行级锁在底层的"闪现"与"长挂",用时序图的生命周期激活条(Activation Box)能看得一清二楚。
我们把这两个方案放到时序图中对比,你重点看右侧 MySQL 内部那把锁(红线部分)的持续长度 :
方案一:FOR UPDATE 模式(长事务锁)
在方案一中,锁的生命周期横跨了多次网络交互和 Java 业务判断:
暂时无法在飞书文档外展示此内容
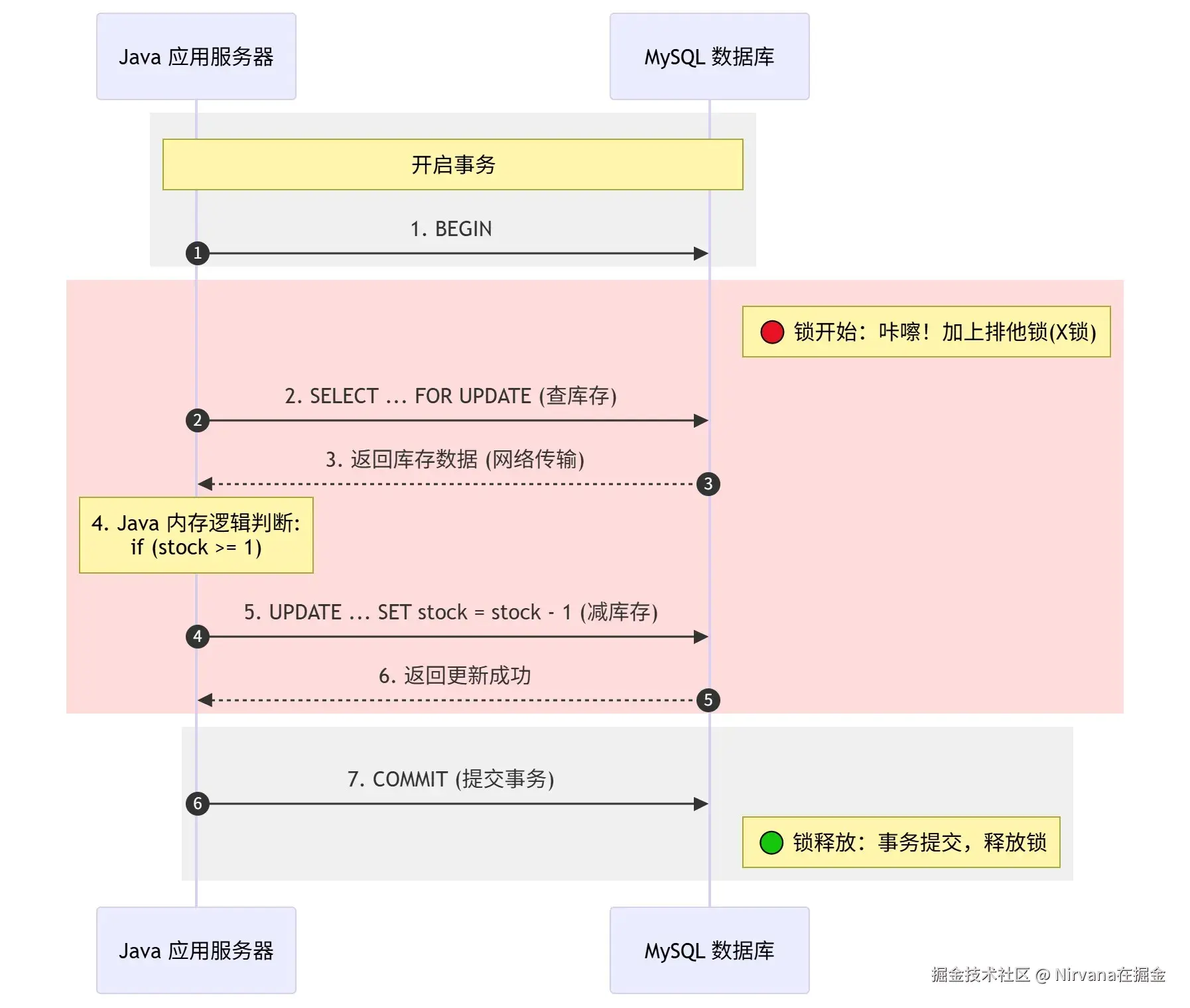 > 你看 :从第 2 步加锁,到第 7 步提交,**红色区域(锁住的时间)**包含了两次网络传输(第 3、5 步)和一次 Java 内存计算(第 4 步)。在高并发下,这里的每一步都会因为网络抖动或 CPU 忙碌而被无限放大。
> 你看 :从第 2 步加锁,到第 7 步提交,**红色区域(锁住的时间)**包含了两次网络传输(第 3、5 步)和一次 Java 内存计算(第 4 步)。在高并发下,这里的每一步都会因为网络抖动或 CPU 忙碌而被无限放大。
方案二:纯 UPDATE 模式(原子短锁)
在方案二中,锁被牢牢"憋"在 MySQL 内部,根本不给网络延迟耽误时间的机会:
暂时无法在飞书文档外展示此内容
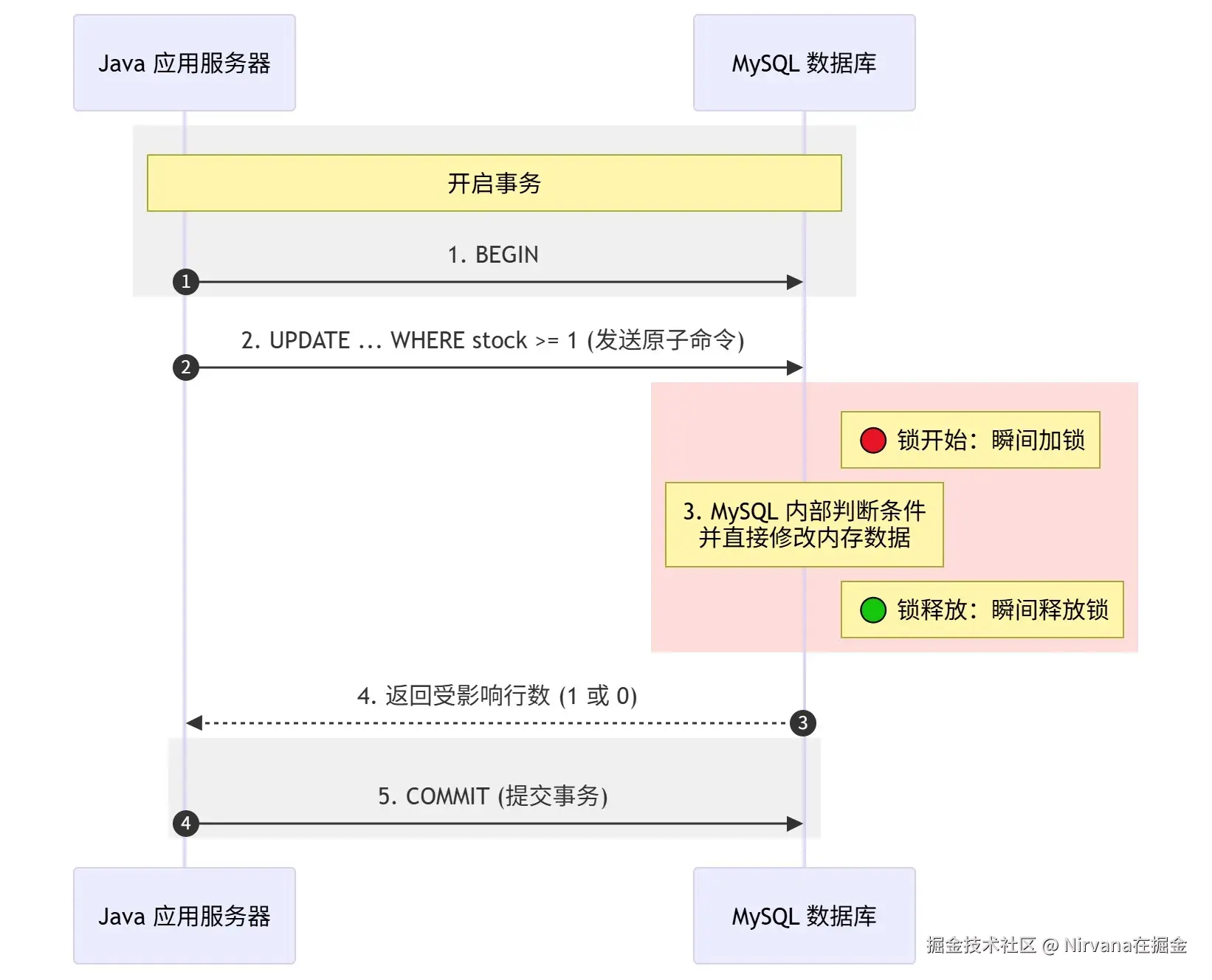 > 你看 :锁只在第 3 步**"闪现"了一下。Java 把命令发过去之后,MySQL 自己在肚子里加锁、判断、减库存、释放锁,一气呵成。等数据通过网络传回给 Java 时(第 4 步),这把锁 早就释放了**,下一个人已经进去了。
> 你看 :锁只在第 3 步**"闪现"了一下。Java 把命令发过去之后,MySQL 自己在肚子里加锁、判断、减库存、释放锁,一气呵成。等数据通过网络传回给 Java 时(第 4 步),这把锁 早就释放了**,下一个人已经进去了。
💡 总结
配合图看就很直观了:
- 方案一 :锁包裹了"网络 + Java + 数据库"。
- 方案二 :锁只包裹了"数据库内部内存操作"。
这就是为什么同样是加排他锁,方案二能支撑的并发量却能挂载成百上千倍提升的底层原因。
哈哈,完全理解!这种标准的技术文档,满篇都是排他锁、间隙锁、JPA、Repository、@Query......读起来就像在嚼干压缩饼干,既硬又卡嗓子,简直是"反人类"的催眠神作。
既然你觉得里面"锁的解释"和 "索引"这两块有价值,那咱们就执行"去油手术",把这两块最核心的骨架抽出来,用最接地气、最拔草的 大白话和图解帮你彻底理清楚。
第一部分:把那堆"恶心的锁"理清楚
文档里写了 6、7 种锁,其实在底层,它们不过是"2 种锁的性质"在 "3 种圈地范围"下的排列组合。
1. 先看"2 种锁的性质"(谁能进门?)
不管是锁一行还是锁全表,只有这两种性质:
- 共享锁(S锁 / 读锁) :"大家一起看戏,但谁也别想改。" 事务 A 加了读锁,事务 B 也能加读锁看数据,但想改数据?对不起,在里面排队等着。
- 排他锁(X锁 / 写锁) :"我在拉屎,反锁大门。" 只要事务 A 执行了
<span>FOR UPDATE</span>或者<span>UPDATE</span>,其他任何人连看(加读锁看)都不行,更别提改了。
2. 再看"3 种圈地范围"(地盘扣得多大?)
这就是文档里最唬人的"记录锁、间隙锁、临键锁"。咱们假设数据库里现在只有三条主键数据:<span>id = 1</span>,<span>id = 5</span>,<span>id = 10</span>。
- 记录锁(Record Lock) :精确打击。
- 大白话 :
<span>WHERE id = 5 FOR UPDATE</span>。 - 地盘 :就锁死
<span>id=5</span>这一行。别的地方(比如你想插入<span>id=3</span>)我不管。
- 大白话 :
- 间隙锁(Gap Lock) :防范未然,圈住空白地带。
- 大白话 :
<span>WHERE id > 1 AND id < 5 FOR UPDATE</span>。因为数据库里根本没有 2、3、4,所以它锁住的是 (1, 5) 之间这个"不存在的真空地带"。 - 目的 :老子在这儿盯尾盘呢,谁也别想往 (1, 5) 里面插新数据(防幻读)。
- 大白话 :
- 临键锁(Next-Key Lock) :全套组合拳。
- 大白话 :它是记录锁 + 间隙锁 。不仅锁住某个间隙,还把右边界的那条记录一起锁死。比如左开右闭区间
<span>(1, 5]</span>。MySQL 默认盯防范围就是这种锁。
- 大白话 :它是记录锁 + 间隙锁 。不仅锁住某个间隙,还把右边界的那条记录一起锁死。比如左开右闭区间
第二部分:锁与索引的"秘密联姻"
这是整篇文档最值钱、最需要理清的硬核逻辑:为什么无索引字段查询会"锁死全表"?
核心铁律:MySQL 的行锁,锁的不是数据本身,而是锁在"索引"上的!
为了让你看清"索引"怎么决定"锁的范围",我们把文档里的 4 个核心场景画成对比图。依然假设表里有 <span>id=1, 5, 10</span> 三条记录:
1. 主键 / 唯一索引查询(精准放行)
- 场景 :
<span>WHERE id = 5 FOR UPDATE</span> - 由于有主键索引 ,MySQL 顺着索引树一查,精准定位。
ini
【主键索引树】
id=1 id=5 id=10
│ │ │
[正常] [ 🔴 锁死 ] [正常]- 结果 :只锁
<span>id=5</span>这一行,其他人随便增删改别的数据,高并发爽歪歪。
2. 唯一索引查询------但"数据不存在"(触发间隙锁)
- 场景 :
<span>WHERE id = 3 FOR UPDATE</span>(数据库里没 id=3) - 由于有索引 ,MySQL 知道 3 应该在 1 和 5 之间,但没找到。为了防止你刚查完别人就插个 3 进去(防幻读),它把这个间隙锁死:
ini
【主键索引树】
id=1 ( 🔴 间隙锁:谁也别想往这插数据 ) id=5 id=10
│ │ │
[正常] [正常] [正常]- 结果 :锁住
<span>(1, 5)</span>这个间隙。别人想插入<span>id=2, 3, 4</span>会被阻塞,但改<span>id=5</span>或<span>id=10</span>是自由的。
3. 无索引字段查询(绝望的全表锁死)
这是最恶心、最需要规避的翻车现场。
- 场景 :
<span>WHERE name = '张三' FOR UPDATE</span>(注意:<span>name</span>字段没加索引 !) - MySQL 的绝望反应 :由于没有索引树可走,MySQL 无法精准定位。它只能进行全表扫描 。为了确保万无一失,InnoDB 只能把聚簇索引(主键)上的所有人全部锁死 !
ini
【没有索引,被迫进行全表扫描】
id=1 id=5 id=10 (表里所有的行...)
│ │ │
[ 🔴 锁死 ] [ 🔴 锁死 ] [ 🔴 锁死 ] [ 🔴 全部锁死 ]- 结果 :虽然你只想找"张三",但整个数据库表被你搞成了单线程。此时前台用户别说下单了,想改任何一条不相干的数据都会直接被卡死报错!这就是为什么规范里严禁对无索引字段使用
<span>FOR UPDATE</span>。
💡 终极理清小结
把那些恶心的术语剥离后,你只需要记住这三句话:
- 读锁(S)大家一起看,写锁(X)谁也别想动。
- 有索引,锁就只圈住那几行或那段间隙;没索引,锁就会像疯狗一样把整张表咬死。
- 大事务(占坑时间长)和无索引(锁全表)是毁掉数据库性能的两大"毒瘤"。
这么理下来,是不是感觉这篇文章其实也就这点核心干货,没那么高深莫测了?
这个场景不仅真实存在,而且在互联网高并发系统的"防重、防刷、幂等性控制"逻辑中,它是最经典、发生频率最高的死锁杀手 。
我们用电商里的"新用户首单立减 50 元"(限制每个人只能下一单)的实际业务场景,把代码、时序图和背后的锁逻辑给你一次性盘得透透的。
1. 真实业务代码(翻车现场)
为了防止羊毛党用脚本在同一微秒发两个请求来刷"首单立减",开发在 Java 里写了下面这段看似天衣无缝的"防重创建订单"代码。
Java
java
// 隔离级别:MySQL 默认的 RR(可重复读)
@Transactional
public void createFirstOrder(Long userId, OrderInfo orderInfo) {
// 1. 查一下这个用户以前有没有首单(userId 是非唯一普通索引)
// 故意用了 FOR UPDATE 钓鱼执法,想卡死并发
Order oldOrder = orderRepository.findByUserIdForUpdate(userId);
if (oldOrder != null) {
throw new BizException("您已经享受过首单优惠,无法再次下单!");
}
// 2. 如果没有首单,就高高兴兴去创建新订单
orderRepository.save(new Order(userId, orderInfo));
}2. 锁逻辑:为什么会"防守反击"当场暴毙?
假设目前数据库里有这两条订单记录(userId 字段有普通索引):
- 记录 1:
userId = 10 - 记录 2:
userId = 20
现在来了一个新用户 userId = 15,他疯狂点击提交,两个请求 线程 A 和 线程 B 同时杀到:
- 第一阶段:两个人都来圈地(睁眼瞎阶段)
- 线程 A 执行
SELECT ... WHERE userId = 15 FOR UPDATE。因为数据库里根本没有 15,MySQL 在普通索引树上左右一看,15 在 10 到 20 之间。于是它在区间**** (10,20)**** 加了一把间隙锁(Gap Lock) 。 - 线程 B 随后也执行了相同的 SQL。因为"间隙锁和间隙锁之间互不冲突"(大家都是为了防守),MySQL 这个睁眼瞎允许 线程 B 也在区间**** (10,20)**** 加了一把间隙锁。
- 此时结果 :线程 A 和 线程 B 同时占有了** (10,20)** 的间隙锁。
- 线程 A 执行
- 第二阶段:防守反击,互相卡死(死锁阶段)
- 线程 A 往下走,准备插入
userId = 15的新纪录。在插入前,MySQL 会申请一个插入意向锁(Insert Intention Lock) 。但是,MySQL 一看:"等等,线程 B 还在这个间隙里拉着间隙锁呢,线程 A 你先在门口排队等着!" (线程 A 被线程 B 阻塞)。 - 线程 B 接着也想插入
userId = 15的新纪录。MySQL 一看:"等等,线程 A 也在这个间隙里拉着间隙锁呢,线程 B 你也给我排队等着!" (线程 B 被线程 A 阻塞)。
- 线程 A 往下走,准备插入
- 终局 :
- A 等 B 释放间隙锁,B 等 A 释放间隙锁。
- MySQL 瞬间警觉:"靠,顶牛了!"立刻触发死锁检测机制,强行回滚其中一个线程(抛出 Deadlock found 异常) ,放行另一个。
3. Mermaid 时序图:死锁的诞生
用时序图配合锁的生命周期,能更直观地看到这个互相卡死的全过程:
Code snippet
🚀 这种场景怎么优化?
既然知道是因为 FOR UPDATE 查不到数据时引发的间隙锁搞的鬼,优化的策略就非常清晰了:
解法一:还是请 Redis 出来当保安(最推荐)
不要在数据库里用 FOR UPDATE 做防重。分布式系统下,这种防重、防刷的逻辑在进入数据库之前就该被拦截:
Java
arduino
// 在进入数据库事务前,先用 Redis 锁住这个 userId 的分布式锁
String redisKey = "lock:first_order:" + userId;
boolean isFirst = redisTemplate.opsForValue().setIfAbsent(redisKey, "1", Duration.ofSeconds(5));
if (!isFirst) {
throw new BizException("重复提交,请稍后再试!");
}
// 拿到 Redis 锁的人,再进去做普通的 INSERT,这时候不需要任何 FOR UPDATE
orderRepository.save(new Order(userId));解法二:数据库硬刚------使用联合唯一索引(Unique Key)
如果我们把数据库的表结构改一下,让 user_id 和 coupon_type(或者首单标识)组合成一个联合唯一索引 。
这样我们在 Java 里连查都不用查 ,直接无脑 INSERT:
- 第一个请求进去了,插入成功。
- 第二个请求进去,直接触发唯一索引冲突报错(
DuplicateKeyException),Java 捕获这个异常并返回"请勿重复提交"。 - 为什么不会死锁? 因为唯一索引插入冲突时,在 RR 级别下会退化为读锁(S锁) ,虽然也可能引发其他死锁,但绝不会像间隙锁那样直接在线上批量对撞、成片崩溃。
这一波带上代码和时序图的拆解,对间隙锁这个"睁眼瞎"造成的死锁,应该彻底看个透彻了吧!
第二道防线:Token 令牌机制(最经典的通用方案)
这是最适合"表单提交、创建订单"的经典闭环方案,核心思想是:每次提交,必须对暗号。
- 步骤拆解 :
- 申请暗号 :用户进入下单页面时,Java 后端先生成一个全球唯一的字符串(比如
Token = UUID),存入 Redis 并设置 5 分钟过期,同时把这个 Token 传给前端。 - 携带暗号提交 :用户点击提交时,前端必须在 Header 或者参数里带上这个 Token。
- 后端验证(核心) :后端收到请求,去 Redis 里执行
DEL token(删除操作)。- 请求 A 进来了,成功删除了 Token,说明暗号有效,放行去业务层拉屎。
- 请求 B (重试请求)慢了一微秒进来,执行
DEL token发现返回 0(已经被 A 删了),直接拦截并报错:"请勿重复提交!"
- 申请暗号 :用户进入下单页面时,Java 后端先生成一个全球唯一的字符串(比如
- 代码灵魂 :一定要用 Redis 的原子性删除 或者
setIfAbsent。如果先查是否存在再去删除,在高并发下又会重蹈"间隙锁顶牛"的覆辙。
第二道防线:Token 令牌机制(最经典的通用方案)
这是最适合"表单提交、创建订单"的经典闭环方案,核心思想是:每次提交,必须对暗号。
- 步骤拆解 :
- 申请暗号 :用户进入下单页面时,Java 后端先生成一个全球唯一的字符串(比如
Token = UUID),存入 Redis 并设置 5 分钟过期,同时把这个 Token 传给前端。 - 携带暗号提交 :用户点击提交时,前端必须在 Header 或者参数里带上这个 Token。
- 后端验证(核心) :后端收到请求,去 Redis 里执行
DEL token(删除操作)。- 请求 A 进来了,成功删除了 Token,说明暗号有效,放行去业务层拉屎。
- 请求 B (重试请求)慢了一微秒进来,执行
DEL token发现返回 0(已经被 A 删了),直接拦截并报错:"请勿重复提交!"
- 申请暗号 :用户进入下单页面时,Java 后端先生成一个全球唯一的字符串(比如
- 代码灵魂 :一定要用 Redis 的原子性删除 或者
setIfAbsent。如果先查是否存在再去删除,在高并发下又会重蹈"间隙锁顶牛"的覆辙。