前言
当我们向MySQL发送一条SQL语句时,无论是简单的SELECT还是复杂的UPDATE,背后都有一套精密的执行流程。这套流程涉及客户端 、Server层 、存储引擎层 的协作,以及Buffer Pool 、Undo Log 、Redo Log 、Binlog等组件的配合。本文将从整体架构出发,深入剖析SQL语句(查询与修改)的完整底层执行逻辑,帮助你对MySQL有一个全局且深入的理解。
一、MySQL整体架构
MySQL采用分层架构 ,核心分为Server层 和存储引擎层 。
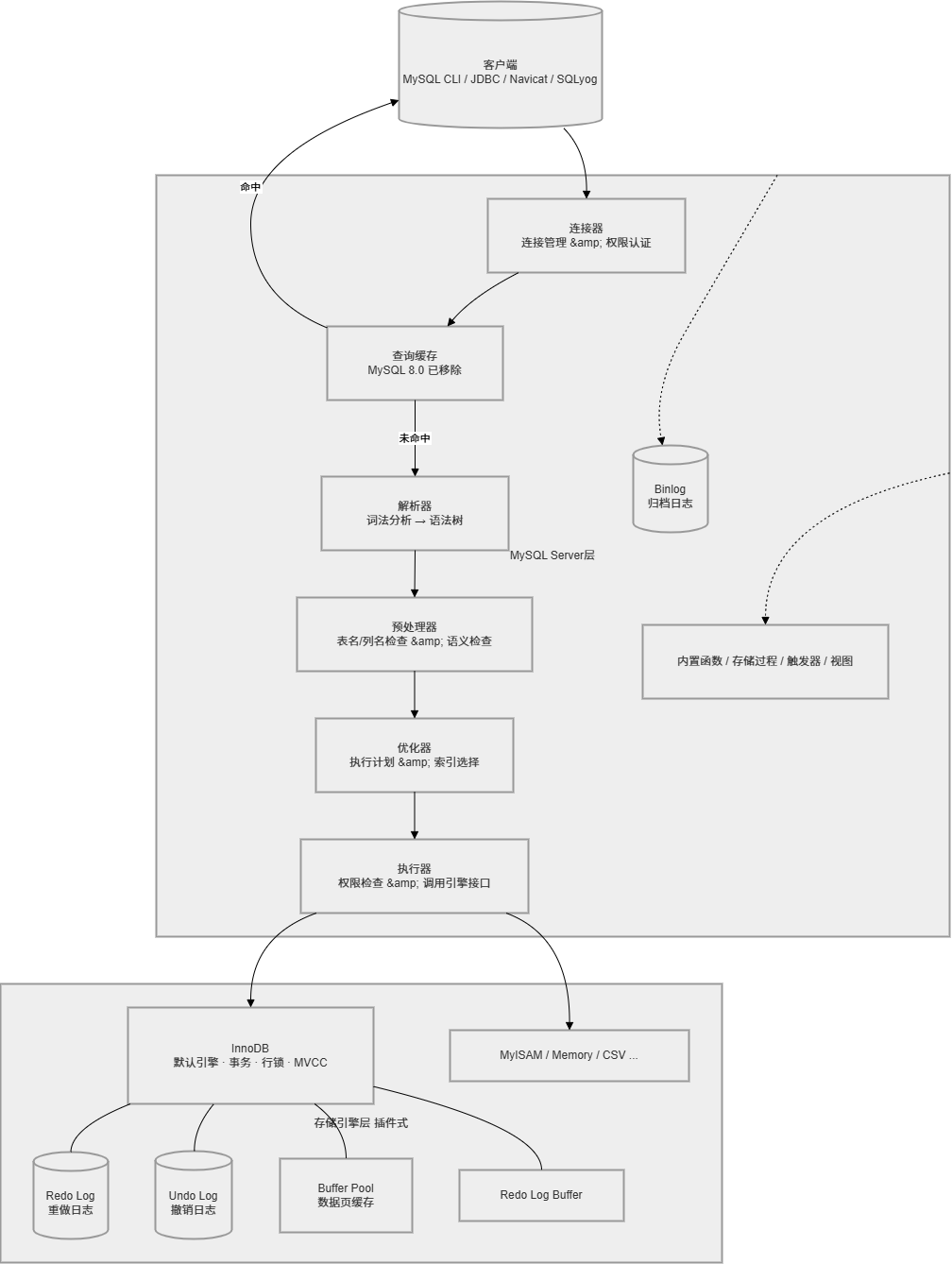
Server层
负责处理SQL语句的解析、优化、执行,以及权限管理、内置函数、存储过程等跨存储引擎 的功能。Server层有自己的日志------Binlog(归档日志)。
存储引擎层
负责数据的存储与检索 ,采用插件式 架构。最常用的是InnoDB (MySQL 5.5.5开始成为默认引擎),它支持事务、行级锁、外键,并提供Redo Log (重做日志)和Undo Log(撤销日志)来保证事务的ACID特性。
二、SQL完整执行流程图
下面是一张从客户端请求到结果返回 的完整流程图,它整合了查询和更新(特别是事务性更新)的所有关键步骤。对于查询语句,会跳过日志写入和两阶段提交部分。
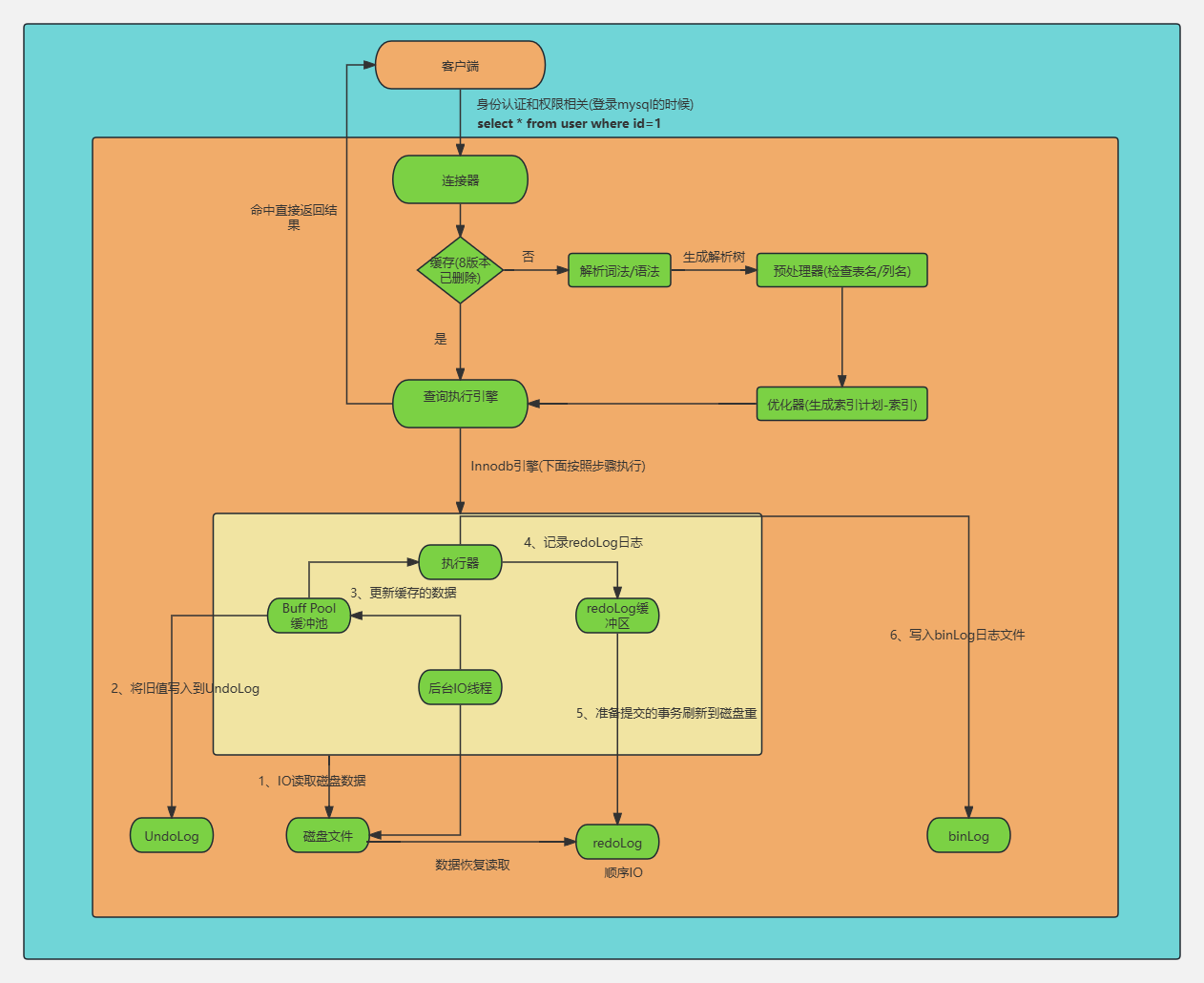
说明 :对于
SELECT查询,上述流程中从写入Undo Log到Redo Log commit的步骤不会发生,执行器直接通过引擎接口读取数据并返回。
三、各步骤详细解说
1. 连接器
职责:管理客户端连接、验证身份、获取权限。
- 客户端通过
mysql -h$ip -P$port -u$user -p命令发起连接,连接器完成TCP握手后认证用户名和密码。 - 认证通过后,连接器会从权限表读取该用户拥有的权限,此后的所有操作都基于本次读取的权限(即使中途管理员修改了权限,也不影响已存在的连接)。
- 连接完成后,如果客户端长时间没有动作,连接器会自动断开,由参数
wait_timeout控制(默认8小时)。断开后再次发送请求会收到"Lost connection"错误。
明白了,需要在不破坏原有结构 的前提下,在"长连接 vs 短连接"及"长连接内存问题及解决"之后,新增一个小节 专门讲解连接池,并配图。我会保持你原有文字的完整性,新增内容紧跟在解决方案之后。
长连接 vs 短连接
- 长连接:连接成功后持续使用同一连接。建议使用,避免频繁建立连接的开销。
- 短连接:每次执行少量查询后断开,下次重建。不推荐。
长连接内存问题及解决
MySQL执行过程中临时使用的内存(如结果集、排序缓存)管理在连接对象中,只有连接断开才会释放。长连接累积可能导致内存暴涨,引发OOM或被系统杀掉。
解决方案:
- 定期断开长连接,释放内存。
- MySQL 5.7+ 可使用
mysql_reset_connection()重新初始化连接资源(无需重连和权限验证)。
连接池(Connection Pool)
即使我们使用了长连接,每次新建连接仍然需要经历TCP握手、MySQL认证、权限读取等开销,在高并发场景下依然可能成为瓶颈。连接池是一种更高效的连接管理方案。
连接池的核心思想 :在应用服务器端预先创建并维护一组"已经建立好的数据库连接",当应用程序需要访问数据库时,直接从池中借用 一个空闲连接,使用完毕后归还到池中,而不是真正关闭连接。
连接池的优势:
- 减少连接建立开销:避免了频繁的TCP握手、MySQL认证、权限查询等耗时操作。
- 限制连接数量:可以设置最大连接数,防止过多连接压垮数据库。
- 统一管理连接生命周期:支持超时回收、连接有效性检测、自动重连等。
- 提升系统响应速度:请求到来时无需等待连接建立。
连接池的常见参数(以HikariCP、Druid为例):
maximumPoolSize:池中最大连接数minimumIdle:池中保持的最小空闲连接数connectionTimeout:获取连接的超时时间idleTimeout:空闲连接的最大存活时间
连接池工作流程示意:
MySQL 服务器
数据库连接池
应用程序
借用连接
借用连接
执行SQL
执行SQL
归还连接
变为空闲
线程1
线程2
线程3
连接1
空闲
连接2
使用中
连接3
空闲
连接4
空闲
接收SQL执行
为什么连接池能缓解长连接内存问题?
- 连接池通常会设置
idleTimeout,空闲连接超过一定时间会被主动关闭并移除,从而释放连接所占用的MySQL内存(临时结果集、排序缓存等)。 - 同时,连接池可以定期执行
mysql_reset_connection()(如Druid的reset配置)来重置连接状态,避免内存累积。
注意 :连接池是应用层 的机制,而MySQL自身的
wait_timeout和mysql_reset_connection()是数据库层的机制。两者配合使用,可以更好地管理长连接资源。
2. 查询缓存(MySQL 8.0 已移除)
在MySQL 5.7及之前版本,连接完成后会先查询缓存。缓存以key-value形式存储,key是SQL语句,value是查询结果。
为什么不建议使用?
- 命中率低:只要表有更新(INSERT、UPDATE、DELETE),该表的所有查询缓存立即失效。
- 维护成本高:对更新频繁的表,缓存频繁失效,反而增加系统负担。
- MySQL 8.0 直接移除:官方认为其弊大于利。
按需使用方式(针对旧版本):
- 设置
query_cache_type = DEMAND,默认不缓存。 - 需要缓存的查询使用
SELECT SQL_CACHE * FROM ...。
3. 解析器
作用:将SQL字符串解析成MySQL能理解的结构。
- 词法分析 :将SQL拆分成
token,识别关键字(SELECT、UPDATE)、表名、列名、操作符等。 - 语法分析 :根据MySQL语法规则检查SQL结构是否正确。例如
SELECT * FORM user会报错,提示near 'FORM'。
如果语法错误,MySQL会返回
ERROR 1064 (42000): You have an error in your SQL syntax,并指出第一个出错位置。
4. 预处理器
预处理器在解析器之后执行,负责语义检查 和视图展开:
- 检查表名、列名是否存在。
- 检查用户是否有访问这些对象的权限(部分权限检查在此阶段进行)。
- 检查数据类型是否匹配。
- 如果SQL中使用了视图,将其展开为实际的基础表操作。
5. 优化器
职责 :基于解析树生成多个执行计划,并选择代价最小的一个。
优化器决策内容包括:
- 选择使用哪个索引(或者全表扫描)。
- 多表连接时的连接顺序 (例如
t1 join t2,先扫描t1还是t2)。 - 子查询优化、条件简化等。
示例:
sql
SELECT * FROM t1 JOIN t2 USING(id) WHERE t1.c=10 AND t2.d=20;两种执行方案:
- 先从t1取c=10的id,再关联t2,再判断d=20。
- 先从t2取d=20的id,再关联t1,再判断c=10。
优化器会根据表统计信息(如数据量、索引区分度)选择效率更高的方案。
6. 执行器
职责:按照优化器的执行计划,调用存储引擎接口来操作数据。
- 首先检查用户对目标表是否有执行权限(有些权限在预处理阶段已检查,但触发器这类运行时对象只能在此检查)。
- 打开表,根据存储引擎定义,循环调用引擎接口:
- 对于查询:调用引擎取第一行,判断是否符合WHERE条件,符合则放入结果集,否则跳过;然后取下一行,直到最后。
- 对于更新:调用引擎取到行数据,修改后调用引擎写入接口。
- 最后将结果集返回客户端。
如果启用了查询缓存且命中,权限验证会在缓存返回结果时进行。
四、存储引擎层(InnoDB)深入解析
当SQL是更新操作(INSERT/UPDATE/DELETE)时,执行器会调用InnoDB引擎接口,触发如下完整事务流程。如果是查询操作,则直接读取数据返回,不涉及日志写入。
4.1 读取数据到Buffer Pool
- Buffer Pool:InnoDB的内存缓冲池,以**页(Page)**为单位存储数据副本(默认16KB)。
- 执行器请求某行数据时,InnoDB先检查所需数据页是否在Buffer Pool中:
- 如果在(命中),直接使用内存中的数据。
- 如果不在,从磁盘读取数据页到Buffer Pool。
4.2 写入Undo Log
- Undo Log :记录数据修改之前的旧值,存储在Undo表空间。
- 作用 :
- 事务回滚:如果事务需要回滚,利用Undo Log将数据恢复原状。
- MVCC(多版本并发控制):为读操作提供数据的旧版本,实现可重复读等隔离级别。
- 例如:
UPDATE users SET balance = balance - 100 WHERE id = 1,Undo Log会记录id=1这行原来的balance值。
4.3 更新Buffer Pool中的数据
- 在Buffer Pool中直接修改数据页,此时内存中的数据和磁盘不一致 ,该页变为脏页。
- 为提高性能,修改不会立即写回磁盘,而是延迟到后台线程统一刷盘。
4.4 写入Redo Log Buffer
- Redo Log:物理日志,记录"在某个表空间的某个数据页的某个偏移量处做了什么修改",例如"在页100的偏移量200处写入值x"。
- 修改操作会先在内存的Redo Log Buffer中写入Redo日志,而不是直接写文件。
- WAL技术(Write-Ahead Logging):先写日志,后写磁盘,保证crash-safe。
4.5 Redo Log刷盘(Prepare阶段)
- 当事务提交时,Redo Log Buffer的内容会写入磁盘上的Redo Log文件(一组固定大小的文件,循环使用)。
- 刷盘时机由参数
innodb_flush_log_at_trx_commit控制:0:每秒写入一次,最不安全(可能丢失1秒事务)。1:每次事务提交都刷盘,最安全(默认值)。2:每次事务提交写入OS缓存,每秒刷盘,性能与安全折中。
- 此时Redo Log的状态标记为prepare(两阶段提交的第一步)。
4.6 写入Binlog
- Binlog :Server层的逻辑日志,记录SQL语句的原始逻辑(如"给id=1的balance减100"),以追加写方式记录,不会覆盖旧日志。
- 作用 :
- 主从复制:从库重放Binlog实现数据同步。
- 数据恢复:基于全量备份+Binlog增量恢复到任意时间点。
- 执行器生成Binlog并写入磁盘。
4.7 Redo Log标记Commit
- 当Binlog写入成功后,InnoDB会将Redo Log中对应的事务状态从prepare 改为commit。
- 这就是两阶段提交(2PC)的完成。目的是保证Redo Log和Binlog的逻辑一致性。
4.8 后台IO线程异步刷脏页
- 脏页:Buffer Pool中被修改但尚未写回磁盘的数据页。
- 后台线程会在以下时机将脏页刷回磁盘:
- Buffer Pool空间不足。
- 脏页比例超过阈值。
- 后台线程定期刷新。
- MySQL空闲时。
- Checkpoint机制标记哪些脏页已刷盘,以便崩溃恢复时知道从哪个Redo Log位置开始重做。
4.9 返回结果给客户端
- 执行器收到存储引擎提交完成的信号后,向客户端返回
Query OK, 1 row affected之类的执行结果。
你说得对,第一份文档(PDF)中对三大核心日志的讲解非常详尽,包括粉板比喻、WAL技术、两阶段提交、崩溃恢复规则等。我之前在"五、三大核心日志对比"部分确实过于简略了。现在我把这个章节按照第一份文档的详细程度进行完整扩展,保持与前面内容的风格一致。
以下是替换后的 第五章完整内容(你可以直接替换原博客中的对应章节):
五、三大核心日志详解
在MySQL(InnoDB引擎)中,Redo Log 、Undo Log 和 Binlog 共同保证了事务的ACID特性以及数据恢复、主从复制的能力。理解这三种日志的工作机制,是掌握MySQL内核的关键。
5.1 Redo Log(重做日志)------ 保证持久性
为什么需要Redo Log?
想象一下,如果没有Redo Log,每一次更新操作都要直接写入磁盘:找到对应的数据页、修改、写回。这个过程涉及大量的随机I/O ,性能极差。MySQL的设计者借鉴了"酒店掌柜的粉板"思路,使用WAL技术(Write-Ahead Logging,预写日志)来提升效率。
孔乙己的粉板比喻 :酒店掌柜有一个粉板(白漆木板)用来记录客人赊账,如果赊账人不多,可以直接翻账本记账;但如果生意红火,掌柜会先在粉板上记一笔,等打烊后再把账本翻出来核对入账。粉板写得快,账本查得慢。MySQL也是如此:先写日志(粉板),后写磁盘(账本)。
Redo Log的工作原理
- 记录内容:物理日志,记录"在某个数据页的某个偏移量做了什么修改"。例如:"在表空间X的页面Y的偏移量Z处写入值W"。
- 存储位置 :磁盘上一组固定大小的文件(如
ib_logfile0、ib_logfile1),循环写入,写满后覆盖旧的日志。 - 写入流程 :
- 更新操作发生时,先写入内存中的 Redo Log Buffer。
- 事务提交时(或按配置策略),将Redo Log Buffer刷入磁盘Redo Log文件。
- 后台线程在系统空闲或Checkpoint时将Buffer Pool中的脏页真正刷回数据文件。
下图展示了Redo Log的循环写入结构:
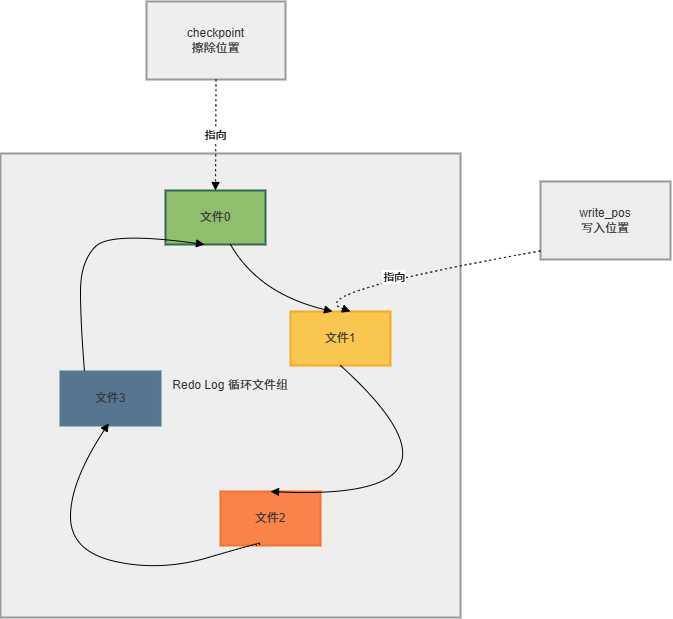
Redo Log的刷盘策略
参数 innodb_flush_log_at_trx_commit 控制刷盘时机:
| 值 | 含义 | 风险 | 性能 |
|---|---|---|---|
| 0 | 每秒写入一次Redo Log文件 | 崩溃可能丢失1秒事务 | 最高 |
| 1(默认) | 每次事务提交都刷盘 | 不丢失(最安全) | 较低 |
| 2 | 每次提交写入OS缓存,每秒刷盘 | 崩溃可能丢失1秒事务 | 较高 |
Redo Log如何实现crash-safe?
数据库异常重启后,InnoDB会扫描Redo Log,重放 所有已提交但尚未写入数据文件的操作,保证数据不丢失。这就是持久性的保障。
5.2 Binlog(归档日志)------ 主从复制与时间点恢复
Binlog是Server层 的日志,所有存储引擎都能使用。它记录的是逻辑修改,而非物理修改。
Binlog的特点
- 记录内容:逻辑日志,可以是SQL语句(STATEMENT格式)或行变更(ROW格式)或混合格式(MIXED)。例如:"给ID=2这行的c字段加1"。
- 写入方式 :追加写 ,文件写满后切换到下一个,永远不会覆盖旧的日志。
- 主要用途 :
- 主从复制:从库重放Binlog实现数据同步。
- 时间点恢复:基于全量备份 + Binlog增量恢复到任意时刻。
Binlog与Redo Log的核心区别
| 对比项 | Redo Log | Binlog |
|---|---|---|
| 所属层 | InnoDB引擎层 | Server层 |
| 日志类型 | 物理日志(页修改) | 逻辑日志(SQL/行变更) |
| 写入方式 | 循环写,固定大小 | 追加写,可多个文件 |
| 主要作用 | crash-safe,持久性 | 主从复制,归档恢复 |
| 是否支持事务 | 是(InnoDB特有) | 是(所有引擎) |
如何用Binlog恢复误删数据?
假如某天中午12点误删了一张表,你可以在备份恢复时这样做:
- 找到最近的一次全量备份(比如昨晚0点的备份),恢复到临时库。
- 从备份时间点开始,将Binlog依次取出来,重放到中午误删表之前的那个时刻。
- 此时临时库就是误删前的状态,从中提取表数据,恢复到线上库。
5.3 Undo Log(撤销日志)------ 事务回滚与MVCC
Undo Log的作用
- 事务回滚 :当事务执行失败或主动
ROLLBACK时,根据Undo Log中记录的旧值 将数据恢复原状,保证原子性。 - MVCC(多版本并发控制) :为读操作提供数据的历史版本,实现可重复读等隔离级别,避免"读-写"冲突。
Undo Log的工作原理
- 记录内容 :逻辑日志,记录数据修改之前 的值。例如:
UPDATE users SET balance=100 WHERE id=1,Undo Log会记录id=1这行原本的balance值。 - 存储位置 :存储在Undo表空间(通常是独立的文件或共享表空间)。
- 生命周期 :
- 事务开始时,每次修改前先写入Undo Log。
- 事务提交后,Undo Log不会立即删除,因为可能有其他事务正在读取该旧版本(MVCC)。
- 当没有任何事务需要这些旧版本时,
purge线程会清理过期的Undo Log。
Undo Log与Redo Log的关系
- Undo Log记录"如何撤销修改"(即旧值),用于回滚和MVCC。
- Redo Log记录"如何重做修改"(即新值),用于崩溃恢复。
- 两者在InnoDB内部协调工作:事务提交时,先写Redo Log,再写Binlog(两阶段提交),而Undo Log在修改前就已写入。
5.4 两阶段提交(2PC)------ 保证Redo Log与Binlog一致
为什么需要两阶段提交?
如果不使用两阶段提交,要么先写Redo Log再写Binlog ,要么先写Binlog再写Redo Log 。这两种顺序在数据库崩溃时都会导致数据库状态与Binlog恢复出来的状态不一致。
下面我们仍以更新语句为例:
UPDATE T SET c = c + 1 WHERE ID = 2,当前 c = 0。
场景1:先写Redo Log后写Binlog,写完Redo Log后崩溃
执行过程:
- 写入Redo Log(此时
c = 1已记录)。 - 准备写Binlog,但MySQL进程异常重启(Binlog未写入)。
崩溃恢复后:
- Redo Log已持久化,InnoDB根据Redo Log恢复数据,
c = 1。 - Binlog中没有这条更新语句的记录。
后果:
- 主库数据为
c = 1。 - 如果后续使用Binlog恢复从库或进行时间点恢复,由于Binlog缺失这条语句,恢复出来的数据
c = 0。 - 主从不一致 / 备份与当前库不一致。
场景2:先写Binlog后写Redo Log,写完Binlog后崩溃
执行过程:
- 写入Binlog(记录了"将
c从0改为1")。 - 准备写Redo Log,但MySQL进程异常重启(Redo Log未写入)。
崩溃恢复后:
- Redo Log中没有该事务的任何记录,因此数据未被修改,
c = 0。 - Binlog中已经存在这条更新语句。
后果:
- 主库数据为
c = 0。 - 如果使用Binlog恢复从库或进行时间点恢复,会多执行一次 更新,恢复出来的数据
c = 1。 - 主从不一致 / 备份与当前库不一致。
两阶段提交如何解决这个问题?
两阶段提交将Redo Log的写入拆分为 prepare 和 commit 两个阶段,并与Binlog的写入顺序严格绑定:
Binlog文件 InnoDB引擎 执行器 Binlog文件 InnoDB引擎 执行器 1. 写入Redo Log (prepare) OK 2. 写入Binlog OK 3. 提交事务 (Redo Log commit) 完成
这样,无论在哪个阶段发生崩溃,都能通过崩溃恢复规则保证数据一致性。
崩溃恢复规则
数据库重启后,InnoDB会扫描Redo Log,对每个事务的状态进行判断:
| Redo Log状态 | Binlog状态 | 恢复行为 |
|---|---|---|
有 commit 标记 |
任意 | 提交事务(Redo Log已完整) |
仅有 prepare,无 commit |
Binlog完整且存在 | 提交事务(说明Binlog已写入成功) |
仅有 prepare,无 commit |
Binlog不完整或不存在 | 回滚事务 |
如何判断Binlog是否完整?
Binlog中每条事务都有明确的开始和结束标记(如
XID_EVENT和QUERY_EVENT或COMMIT)。如果读取到完整的事务块,则认为完整。
不同崩溃场景的具体处理
场景A:Redo Log prepare 写入后、Binlog写入前崩溃
- Redo Log状态:
prepare,无commit - Binlog:尚未写入或写入不完整
- 恢复处理:回滚事务(因为Binlog不完整,从库/备份不应看到这次修改)
场景B:Binlog写入后、Redo Log commit 前崩溃
- Redo Log状态:
prepare,无commit - Binlog:完整存在
- 恢复处理:提交事务(因为Binlog已经记录了,必须保证主库与从库一致)
场景C:Redo Log commit 后崩溃
- Redo Log状态:
commit - Binlog:必然完整(因为commit前Binlog已写入)
- 恢复处理:直接提交(无需额外动作)
Redo Log与Binlog如何关联?
它们通过一个共同的字段------XID(事务ID)进行关联。
- 每个事务在开始时会被分配一个唯一的XID。
- Redo Log的prepare记录中会写入XID。
- Binlog的记录中也会包含同一个XID。
- 崩溃恢复时,MySQL顺序扫描Redo Log:
- 如果遇到
commit,直接提交。 - 如果遇到
prepare,则拿着XID去Binlog中查找对应的事务:- 找到且完整 → 提交
- 未找到或不完整 → 回滚
- 如果遇到
总结一下两阶段提交的核心价值
| 崩溃时机 | Redo Log | Binlog | 恢复后数据状态 | 与Binlog是否一致 |
|---|---|---|---|---|
| prepare后、Binlog前 | prepare | 无/不完整 | 回滚,数据不变 | 一致 |
| Binlog后、commit前 | prepare | 完整 | 提交,数据已改 | 一致 |
| commit后 | commit | 完整 | 提交,数据已改 | 一致 |
通过两阶段提交,MySQL保证了即使在崩溃恢复的场景下,主库的数据状态与Binlog重放出来的状态始终一致,这是主从复制和数据恢复正确性的基石。
5.5 三大日志总结对比
| 日志类型 | 所属组件 | 记录内容 | 写入方式 | 核心作用 | 是否支持事务 |
|---|---|---|---|---|---|
| Redo Log | InnoDB引擎 | 物理日志:数据页修改 | 循环写,固定大小 | 持久性、crash-safe | 是 |
| Undo Log | InnoDB引擎 | 逻辑日志:旧值记录 | 写入Undo表空间 | 事务回滚、MVCC | 是 |
| Binlog | Server层 | 逻辑日志:SQL/行变更 | 追加写,可切换文件 | 主从复制、时间点恢复 | 是(所有引擎) |
注意:MyISAM等引擎不支持Redo/Undo Log,因此不具备崩溃恢复能力和事务支持。Binlog对所有引擎都可用。
七、小结
一条SQL语句从客户端发出到最终返回结果,历经连接器→查询缓存(过时)→解析器→预处理器→优化器→执行器→存储引擎 。对于查询,存储引擎直接从Buffer Pool或磁盘读取数据返回;对于更新,InnoDB还会精心协调Buffer Pool、Undo Log、Redo Log(两阶段提交)、Binlog以及后台刷脏页,从而在保证高性能的同时,实现事务的ACID特性。