从零推导出 Redis
1. 本地缓存:为什么需要它?
- 内存查询比磁盘快几个数量级,MySQL 数据主要放磁盘。
- 思路:把热点数据放在服务进程的内存中(字典结构),查询时先读内存,没命中再去 MySQL,查完顺手写入内存。
- 效果:大量请求直接走内存,MySQL 压力骤降。
👉 这种放在服务本机内存里的缓存,就叫本地缓存。
2. 远程缓存:解决多实例内存浪费
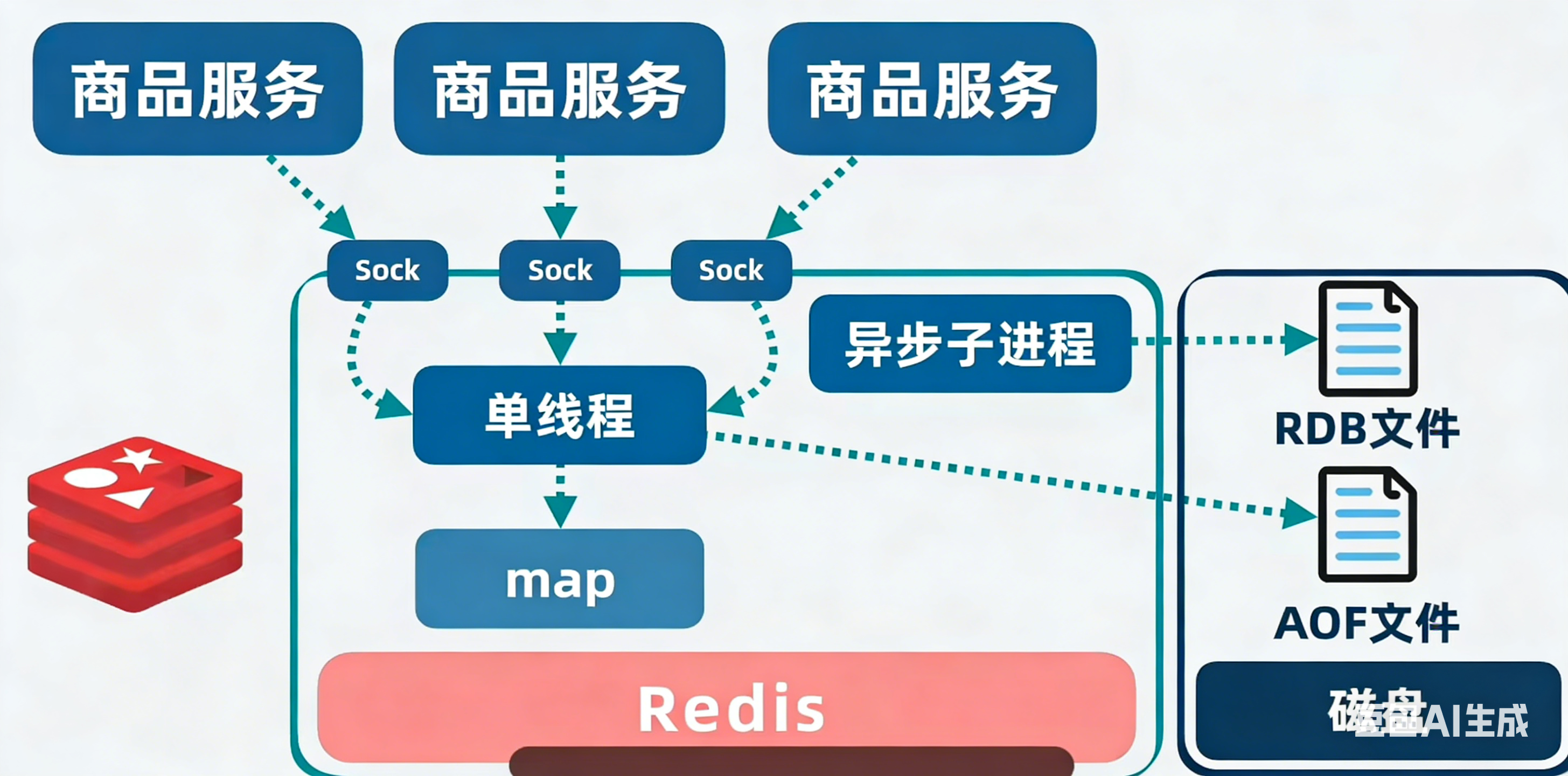
- 商品服务通常部署多个实例(高可用、扩容)。
- 若每个实例都独立缓存一份相同数据,内存浪费严重。
- 改进:把公共的缓存字典抽成一个独立服务 ,所有实例通过网络访问它。
👉 这就是远程缓存服务。 - 并发问题:多个网络连接同时读写同一份数据怎么办?
→ 把所有读写命令放到同一个线程里串行处理,没有并发冲突,也没有线程切换开销。
3. 支持多种数据类型
- 初期只支持
key → string的字典。 - 实际编程中还需要队列、集合、有序集合等内存结构。
- 扩展 value 类型:
- List(先进先出队列)
- Set(去重)
- Zset(有序集合,可做排行榜)
- 缓存服务变得更强、更通用。
4. 内存过期策略
- 数据越来越多,内存有限。
- 为每个 key 加上过期时间 (TTL),由调用方通过
expire命令指定。 - 过期后自动删除,延缓内存增长。
5. 缓存淘汰策略
- 即使有过期时间,用户也可能不设置,或者还没来得及过期内存就满了。
- 在内存接近上限时,按一定策略删除部分数据:
- LRU(最近最少使用)------ 常见且实用
- 好处:不仅解决内存溢出,还能让缓存里始终保留热点数据。
6. 持久化:防止缓存重启后击穿数据库
- 若缓存服务重启,内存全丢,大量请求会直接打到 MySQL(缓存击穿)。
- 需要把内存数据保存到磁盘,重启后恢复。
两种常见持久化方式:
| 方式 | 原理 | 特点 |
|---|---|---|
| RDB | 定期生成全量内存快照,写入磁盘 | 类似游戏存档,恢复快,但两次存档之间的数据可能丢失 |
| AOF | 每次写操作追加到日志文件,定期刷盘 | 更完整,重启后重放日志恢复;文件过大时可重写压缩 |
- 实际生产环境往往两者结合使用。
7. 简化传输协议
- 远程缓存服务不需要 HTTP 的复杂特性(如 Header、Cookie、各种 Method)。
- 直接基于 TCP 设计一个极简协议:
set key value完成写入get key读取值
- 简单、高效,这就是 RESP 协议的前身。
8. Redis 是什么?
经过以上一步步演进,我们得到的就是 Redis:
Redis 是一个开源的、基于内存的、支持多种数据结构、具备过期淘汰策略和持久化能力、使用简单 TCP 协议的高性能键值存储系统。
它不仅是缓存,还可以做数据库、消息代理。
9. (补充)高可用与分布式
- 单机 Redis 仍有宕机风险。
- 工业级方案:
- 主从复制:读写分离,数据备份
- Sentinel(哨兵):自动故障切换
- Cluster(集群):数据自动分片,支持海量数据
这些能力让最初的"远程缓存服务"变成了真正的分布式系统。
对比总结:本地缓存 vs 远程缓存
| 维度 | 本地缓存 | 远程缓存(Redis) |
|---|---|---|
| 位置 | 服务进程内部 | 独立服务 |
| 访问速度 | 极快(纳秒级) | 较快(网络 + 内存,微秒级) |
| 多实例共享 | 否,各自独立浪费内存 | 是,统一一份数据 |
| 容量 | 受限于单机内存 | 可水平扩展(集群) |
| 持久化 | 一般无 | RDB / AOF 完善 |
| 典型代表 | Caffeine, Guava Cache | Redis, Memcached |