导读:多模态数据正成为企业核心资产,但规模化管理仍具挑战。自动驾驶在 PB 级图像、点云、视频等数据治理中积累了可复用经验。本文介绍某公司以 Apache Doris 统一标签、元数据、全文和向量检索,将查询从分钟级提升至秒级。
多模态数据正在成为各行业企业的核心资产,但大多数团队仍在摸索如何对其进行规模化管理。自动驾驶是少数已经在生产环境中,大规模面对并持续优化这一问题的领域之一:图像、点云、视频、信号以及结构化元数据每天都在同一套数据链路中流转。这个领域积累的工程经验,对其他行业同样具有重要的借鉴意义。
过去,这类能力往往依赖数仓、Elasticsearch、向量数据库等多套系统拼接完成。但当数据规模进入 PB 级、查询进入高并发交互式阶段后,多系统架构的性能、同步和运维成本都会迅速放大。
本文将介绍某自动驾驶公司如何以 Apache Doris 为核心重构数据平台,将标签、元数据、全文和向量四类检索能力收敛到同一套实时分析与检索引擎中,并将查询响应时间从分钟级压缩至秒级。
业务规模与数据挑战
本文案例来自一家领先的自动驾驶技术公司,专注于为乘用车提供高级驾驶辅助系统(ADAS)和高阶自动驾驶(AD)解决方案。其产品深度整合算法、软件与专用计算平台,覆盖从传感器感知、决策规划到车辆控制的完整链路,全面提升行驶安全性与驾乘体验。
目前,该公司的解决方案已在多家 OEM 合作伙伴的量产车型上落地部署。依托大规模的量产运营,公司积累了海量真实道路数据,并围绕这些数据构建起数据驱动的研发体系。
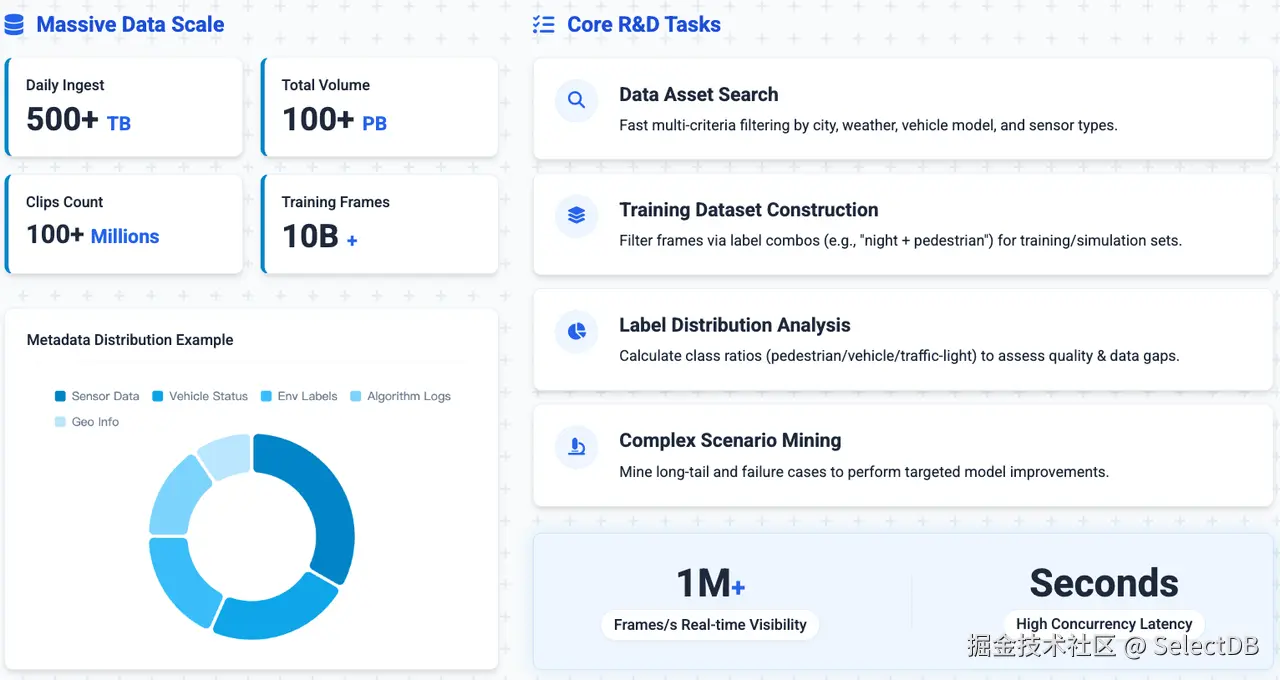
该公司每天生成数百 TB 的新数据,总存储量以 PB 计 。经过分割和清理后,原始传感器数据变成了片段:富含元数据的连续帧序列,这些数据是算法工程师日常研发的核心素材。片段数量已超过数亿,相应的训练帧数量达到了数千亿。
算法工程师会持续与这些数据进行交互。日常工作包括:
- 数据资产检索:按城市、天气、车型、传感器类型和其他数十种属性查找片段;
- 训练集构建:通过标签组合(例如,夜间 + 行人)筛选帧数据,构建训练集或仿真测试集;
- 标签分布分析:统计数据集中各类标签(行人、车辆、交通灯等)的占比,评估数据质量并识别覆盖盲区;
- 难例挖掘:检索长尾场景或模型误判案例,为下一轮训练循环提供有针对性的优化素材。
上述工作对实时性要求极高:每秒处理百万帧数据的可见性,以及高并发下秒级甚至亚秒级响应。
多模态搜索的四种模式
自动驾驶数据的复杂性,在于需要检索的数据类型极为多样:图像、点云、视频、标签、日志,以及结构化或半结构化的元数据。几乎所有数据任务的本质都是检索,而这些检索需求可归纳为以下四类:
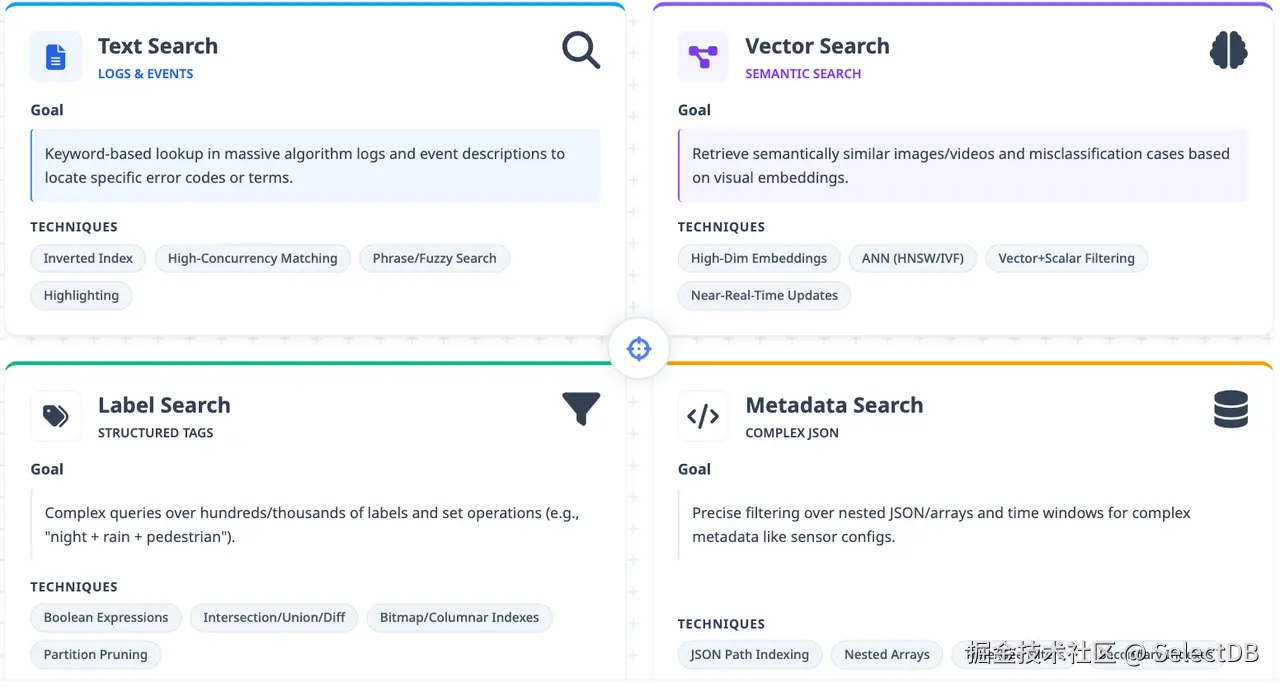
- 文本检索 :解决了查找包含特定关键字的数据的问题,例如日志中的错误代码或事件描述中的特定术语。它依赖于倒排索引,并优先考虑高效的关键字匹配。
- 向量检索:面向语义相似性搜索。视觉语言模型和深度学习特征提取器将图像、视频转化为高维向量。工程师通过向量检索找到历史上相似的场景,例如:某种危险驾驶情况的历史实例,或模型发生类似误判的案例。关注的是语义相似度,而非精确关键词匹配。
- 标签检索:标签检索面向训练帧上的结构化标注,如包含行人、夜间场景、雨天等。工程师通过标签组合(如复杂路口 + 交通灯)来构建数据集,标签维度可多达数百乃至数千个。系统需要支持对这些标签的快速集合运算(交集、并集、差集)。
- 元数据检索:涵盖每次数据采集所附带的半结构化信息:车辆配置、软件版本、传感器标定参数、故障记录等,通常以带有复杂嵌套结构的 JSON 格式存储。工程师需要在其中进行精确过滤,例如:找出特定时间窗口内、特定车型发生某故障的所有采集记录。
在超大规模数据下同时支持四类检索模式,是整个架构设计的核心挑战。
原有架构:三套独立系统,数据割裂
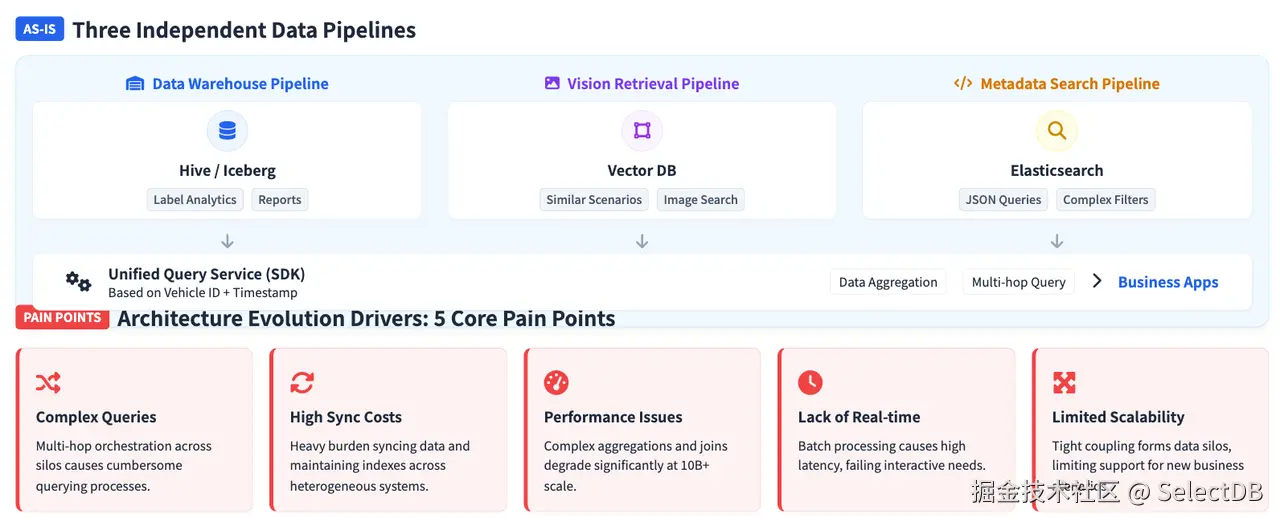
为处理上述不同类型的数据,该公司最初构建了三套独立的数据处理链路:
-
批量数据仓库链路 :结构化标签经 ETL 写入 Hive/Iceberg,用于标签分析、统计报表和数据集构建。该链路以批处理模式运行,延迟较高,无法满足交互式探索的实时需求。
-
图像和文本检索链路:从视频帧中提取的向量特征存储在专用向量数据库(Zilliz)中,支持向量与标量的混合检索,用于相似场景挖掘。但向量数据库与数据仓库完全分离,跨系统查询需要在两者之间搬运数据。
-
元数据检索链路 :车辆状态、事件记录和其他元数据存储在 Elasticsearch 中,利用其 JSON 检索能力提供服务。但 ES 在海量数据上的复杂聚合能力较弱,也无法与标签存储进行统一分析。
三套系统之上虽有统一的查询服务层,但实际工作流仍需工程师在多个系统之间来回切换。一个典型任务可能是:先在元数据系统中筛选数据资产,再到数仓中分析标签分布,最后去向量数据库中检索相似场景。这种多系统串行流程既慢又复杂。
三套平台之间的数据同步推高了运维成本,任何 Schema 变更都需要在多处协同更新。随着数据量增长至千亿级别,三套系统在查询性能和扩展能力上都面临日益严峻的压力。
统一架构:用 Apache Doris 承载标签、JSON、全文与向量检索
这次架构升级的关键,不是简单替换某一个存储系统,是致力于将分散在数仓、搜索引擎和向量数据库中的检索能力,统一到一套面向实时分析的 SQL 引擎中,使得多模态数据能够在同一查询上下文中被过滤、聚合、召回和分析。
该公司此前已引入 Apache Doris 承担标签检索与分析工作。Doris 在这一场景中表现出色:其向量化执行引擎和 MPP 架构能够高效支持千亿级标签的实时聚合与过滤。这一能力已在大规模互联网用户画像与人群定向场景中得到充分验证。将 Doris 用于训练帧的标签组合查询后,数据集构建效率显著提升。
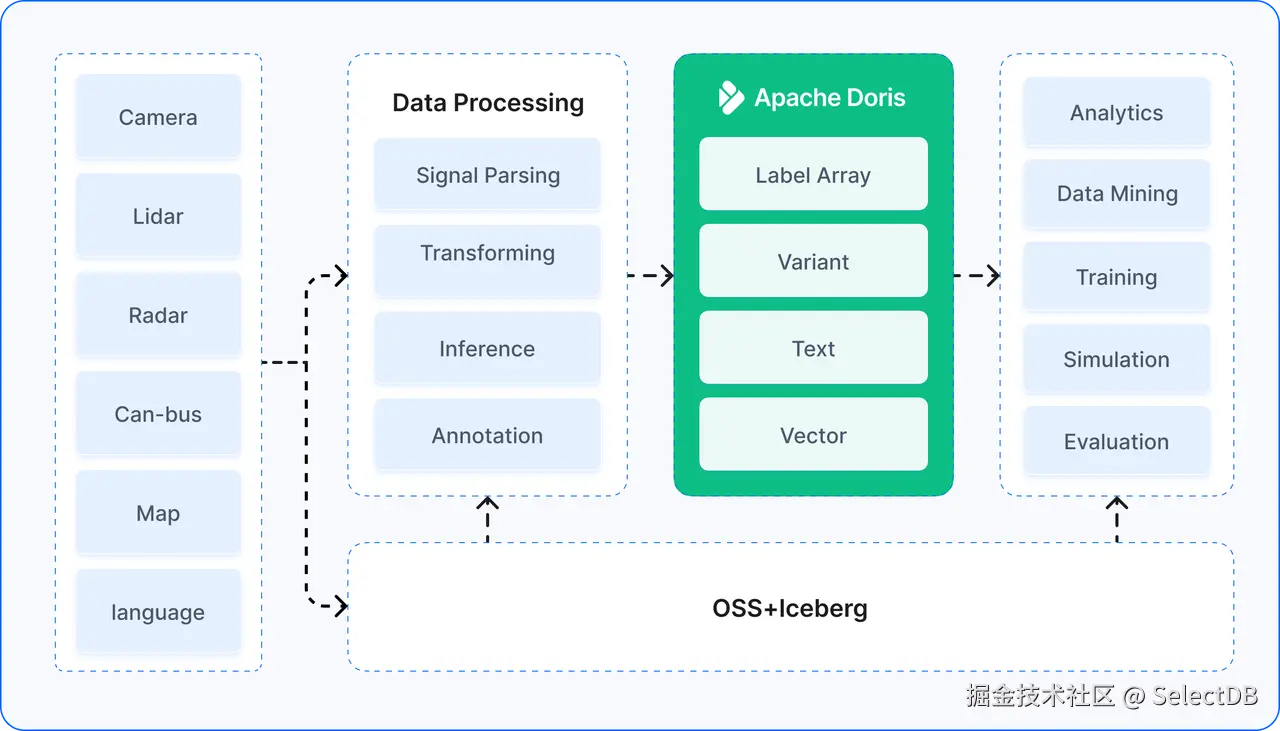
随着 Apache Doris 不断扩展能力边界,并在 SelectDB 等企业级产品与云服务形态中持续强化工程化落地能力,如引入基于倒排索引的全文检索、向量索引,以及高效的半结构化数据处理(含原生 JSON 支持),该公司看到了整合架构的机会。他们开始向以 Apache Doris 为单一多模态检索与分析引擎的统一架构迁移,将原先分散在数仓、向量数据库和 Elasticsearch 中的数据全面整合。
本次迁移遵循五项核心设计原则:
-
冷热数据分层:近期高频访问数据存储在高性能在线存储中,通过基于时间的分区和基于设备的分桶策略优化并发查询;历史数据迁移至低成本数据湖(Iceberg)进行长期留存。联邦查询能力能让用户通过相同的接口透明访问两层数据。
-
优化元数据检索 :针对 JSON 格式的元数据,Apache Doris 提供专用的 Variant 数据类型,原生存储 JSON 并结合倒排索引实现高效检索。复杂嵌套字段可直接在 SQL 中展开,并支持任意条件过滤,让千亿量级的元数据查询保持高响应性。
-
加速标签集操作 :帧级标签采用 Bitmap 数据结构建模:每个标签映射为一个帧 ID 的位图,标签组合查询转化为位图上的集合运算(交集、并集、补集)。即便在千亿量级数据下,复杂场景也能实现秒级响应。主键模型下的实时写入确保新标签数据秒级可见,每天可处理数百亿条标签更新。
-
集成向量检索 :平台将向量索引能力原生内置,图像和文本特征向量与标量数据共同存储。这使得向量、标签与元数据可在单次查询中混合检索,消除了相似场景挖掘中的跨系统数据搬运,并为真正意义上的多模态联合查询奠定基础。
-
统一的查询引擎:单一 SQL 接口覆盖所有数据类型:标签、元数据和向量。工程师无需切换系统,在一次查询中即可完成复杂的数据探索。统一的索引与存储管理也显著降低了开发和运维成本。
落地效果
此次迁移之后,公司在各个方面都取得了可量化的显著提升:

- 查询性能大幅提升:从分钟级响应降至秒级,算法工程师现在可以实时探索不同标签组合下的数据分布,交互式分析成为可能。
- 数据准备周期大幅压缩:数据集采样从离线批处理转变为实时交互,原本数小时的工作压缩至数分钟;
- 生产级规模稳定支撑:统一系统可在七天窗口内稳定支撑近万亿条记录的检索,并发负载接近 1000 QPS;
- 运维复杂度显著下降:同一数据引擎承载标量、JSON 和向量检索,取代了三套独立系统,彻底消除了跨系统同步与维护的额外负担。
总结与展望
在自动驾驶领域,数据平台的核心挑战在于:构建一套能够同时处理文本、向量、标签和元数据,并在海量规模下支持高效检索与分析的统一系统。
从分散的架构转向融合的架构,不仅提升了查询性能和开发效率,更为更智能、更数据驱动的研发工作流奠定了坚实基础。
这些经验的适用范围远不止自动驾驶。任何面临多模态数据规模化管理挑战的行业:智慧城市、工业质检、内容推荐,以及日益兴起的 AI Agent 基础设施都面临同样的架构抉择。以 Apache Doris 为代表的统一实时分析平台,提供了一条经过生产验证的可行路径。