1、问题
最近在项目中遇到这样的一个场景,根据文件类型分类统计本级及其下级的文件总数量,即本级的统计的总数包含下级的数据,
T1表是文件数据表,t2表是关系表
一开始的语句写法如下:
select tt.*,(select count(*) from t1 where t1.c1 in (select id
from t2 start with t2.id=tt.id connect by prior t2.id=t2.pid)) as cnt
from t2 tt;计划:
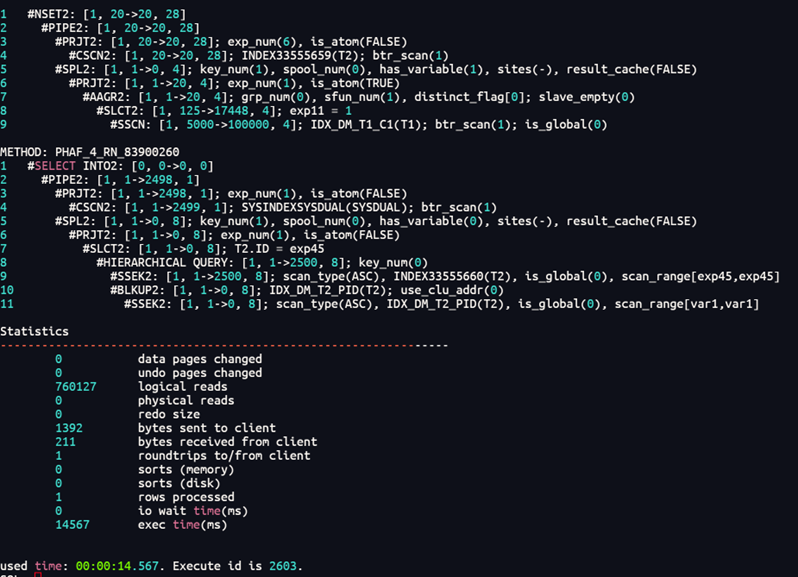
这里语句意思是每次主查询的id传入到标量子查询中求出其层次查询中相关的id,再去求其文件数据量。因此每次都要一次一次作为变量进行层次查询再统计文件数据量,因此我会思考能否一次性处理,层次查询关系能否先求其根级(即其顶头上司)?文件能否先分类统计,然后二者之间再关联统计?答案是可以的。
首先处理层级关系
select connect_by_root ID as fid,level,* from t2 start with t2.id is not null
connect by prior t2.id=t2.pid计划:

这里connect_by_root ID求每个id的根节点。
这里文件分类统计数量
select count(1) cnt,c1 from t1 group by c1;计划:

二者之间关联统计
select tt1.fid,nvl(sum(cnt),0) cnt
from (select connect_by_root ID as fid,level,* from t2 start with t2.id is not null
connect by prior t2.id=t2.pid) tt1 left join (select count(1) cnt,c1 from t1 group by c1)
tt on tt1.id=tt.c1
group by fid;计划:

2、改写
最终再整合改写为:
select tt3.*,tt2.cnt from t2 tt3 left join
(select tt1.fid,nvl(sum(cnt),0) cnt
from (select connect_by_root ID as fid,level,* from t2 start with t2.id is not null
connect by prior t2.id=t2.pid) tt1 left join (select count(1) cnt,c1 from t1 group by c1)
tt on tt1.id=tt.c1
group by fid)tt2 on tt3.id=tt2.fid计划: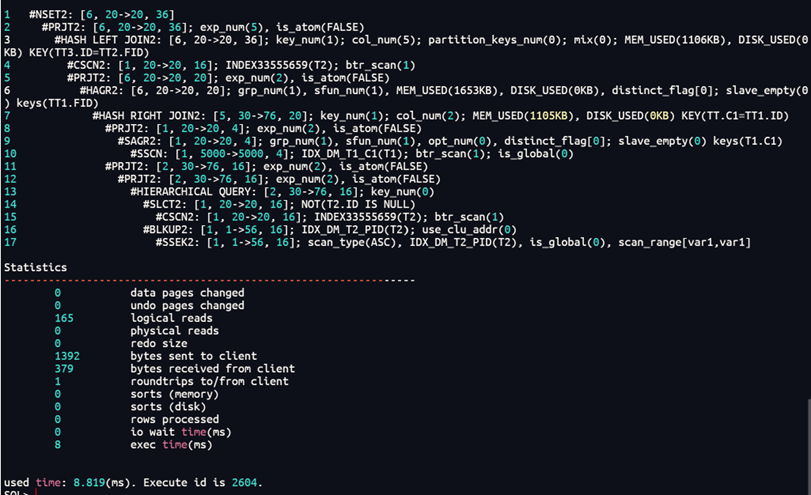
最终从14s提升至0.008s。
3、小结
这里利用的思路是先分类再汇总。
层次查询也是先分类的思路,求根节点即把每个节点分组归类于根节点;文件分类统计就很明显的分组统计做法。然后结合标量子查询和left join的相互转换思路,最终达到优化效果。
4、测试用例数据构造
drop table if exists t1;
create table t1(id int primary key,c1 int );
insert into t1 select level,dbms_random.value(1,20) from dual connect by level<=5000;
commit;
dbms_stats.gather_table_stats(USER,'T1',null,100);
drop table if exists t2;
create table t2(id int primary key,pid int ,f1 int ,state int );
insert into t2 select level+1,level,dbms_random.value(1,1000),dbms_random.value(1,5) from dual connect by level<=10;
commit;
insert into t2 select level+1+10,level-round(dbms_random.value(1,10),0),dbms_random.value(1,1000),dbms_random.value(1,5) from dual connect by level<=10;
commit;
dbms_stats.gather_table_stats(USER,'T2',null,100);
create index IDX_DM_T2_PID on T2(PID);
create index IDX_DM_T1_C1 on t1(c1);