1、问题
最近遇到这样有趣的写法
with temp as
(select wm_concat(distinct code) code
from t1
)
select count(1) from (select distinct t2.id from t2,temp a where (a.code not like '%'||substr(t2.code,1,4)||'%')
) a计划:
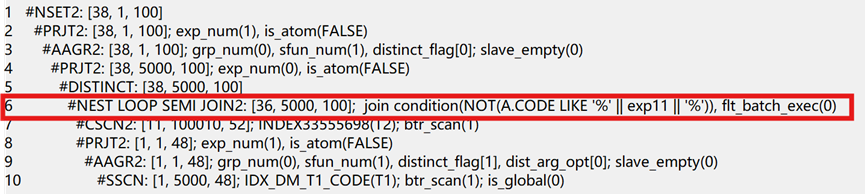
语句为了排除不在板块的单位,做法是先把单位code合并成一行进行模糊匹配排除。计划做成nest loop semi join2(嵌套循环),相当于一条一条去模糊匹配筛选排除,由此性能消耗高。
关联列一旦先合并处理之后,和其他表做关联时做成like关联匹配,这样的效率会低,因此不宜合并处理。
根据对语句的逻辑上理解,排除t2不在t1中的单位,且code的长度为4,"不在"可以转换成not exists,like关联转换成substr方式。
2、改写
select count(1)
from (select distinct t2.id
from t2
where not exists (select 1
from t1 a
where a.code=substr(t2.code,1,4)
and lengthb(t2.code)=4 )) aa计划:

性能提升几十倍。
3、小结
关联列一旦先合并处理之后,和其他表做关联时做成like关联匹配效率低,不宜这样处理。