理解嵌入(Embedding)模型的原理其实不难,我们可以从最基础的概念讲起。这里会分几个步骤,尽量让你在10分钟内快速掌握它。
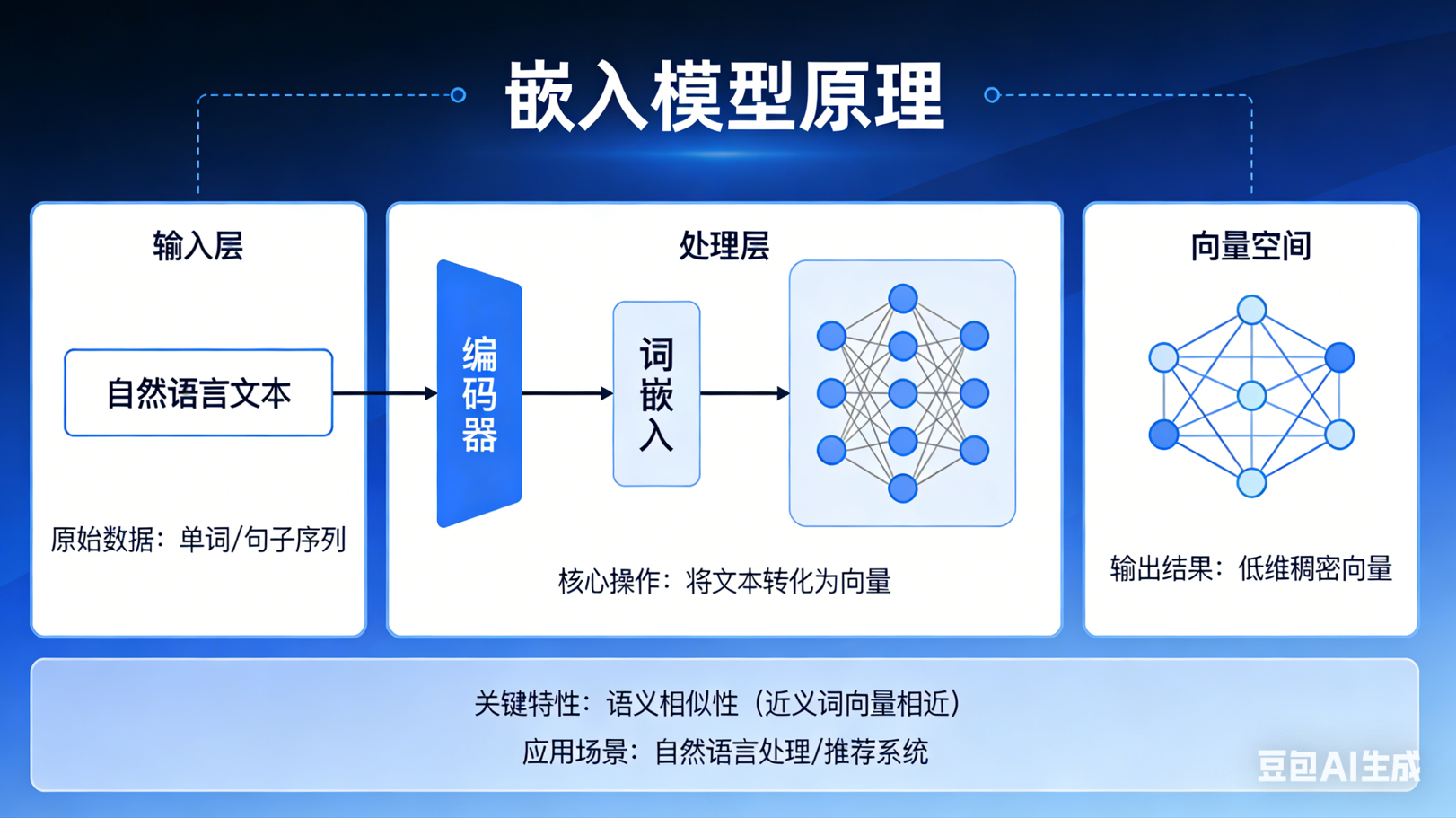
1️⃣ 什么是嵌入(Embedding)?
嵌入(Embedding)是将 高维数据 (比如文字、图片、音频等)转换成 低维向量(通常是固定长度的向量)的技术。
举个例子,我们通常用"词嵌入(word embedding)"来将每个词映射到一个 数字向量。这些数字向量表示了词语之间的关系。
2️⃣ 为什么要做嵌入?
计算机本身不能直接理解文字、图片等数据,它只能理解 数字 。为了让计算机能够处理这些高维数据,我们需要将它们转化为数字表示,而嵌入就是实现这一转化的方式。
举个例子:
- 比如"猫"和"狗"是两种不同的动物,我们通过嵌入技术把"猫"转成一个向量,"狗"转成另一个向量。虽然它们是不同的词,但它们的向量可能是相似的,因为它们在某些意义上相似(都属于"宠物")。
- 这样,计算机就能通过向量的 相似度 来理解词与词之间的关系。
3️⃣ 嵌入是怎么学的?
嵌入模型通常通过 训练 学到将词语(或其他数据)转换为向量的规则。常见的两种方法是:
- 基于上下文的嵌入:比如Word2Vec、GloVe等模型,通过词语的上下文来学习词语之间的关系。
- 基于任务的嵌入:比如BERT、GPT等深度学习模型,通过在特定任务中(如分类、生成)进行训练来学习嵌入。
例子:
- Word2Vec :假设我们要理解"猫"和"狗"之间的关系,Word2Vec会根据"猫"出现在"我喜欢养猫 和狗"这样的句子中的上下文,学习到"猫"和"狗"是相似的,并把它们映射到相似的向量空间。
4️⃣ 向量是怎么表示的?
一个"词向量"通常是一个 固定长度的数字数组,例如:
- "猫" :
[0.1, -0.2, 0.5, ...] - "狗" :
[0.12, -0.18, 0.52, ...]
这些向量的每个维度(数字)可以看做是一些隐含的特征,这些特征在模型的训练过程中学习到,并反映了词与词之间的关系。
5️⃣ 嵌入空间的特点
嵌入空间是一个 高维空间,向量的距离和方向可以反映数据之间的关系:
- 相似性:距离越近的向量表示词语之间越相似。
- 加法性:例如,"王" - "男" + "女" = "王后"。这就是嵌入空间中的一个有趣的性质,词向量不仅能表示相似性,还能通过数学运算(比如加减法)捕捉到一些关系。
6️⃣ 嵌入在实际应用中的作用
嵌入的作用可以通过几个典型应用来理解:
- 自然语言处理(NLP):通过将词或句子转换为向量,模型可以计算它们之间的相似度,进而进行情感分析、机器翻译等任务。
- 推荐系统:通过将用户和物品嵌入到同一个向量空间,系统可以根据用户历史行为(比如购买记录)推荐相关物品。
- 图像处理:通过嵌入技术,模型可以把图像数据转化为向量,从而进行图像分类、物体检测等任务。
7️⃣ 一个简单的类比
把嵌入想象成一个 词典 ,每个词有对应的数字向量。如果你知道"猫"的向量是 [0.1, -0.2, 0.5],而"狗"的向量是 [0.12, -0.18, 0.52],那么你可以通过计算它们之间的 距离 来知道它们是否相似。就像我们用字典查找词的定义一样,嵌入是用数字来表示这些"定义",并且这些数字可以帮助计算机更好地理解词语之间的关系。
8️⃣ 最后总结下吧
- 嵌入 是将高维的、复杂的数据(如词、图片等)转换为低维的、数值化的向量。
- 嵌入的好处是 保持数据的语义关系,使得计算机能够理解这些数据的相似性。
- 嵌入技术广泛应用于 自然语言处理、推荐系统、图像处理等领域。
通过嵌入,机器能够理解和操作信息的潜在结构,使得各种AI任务变得更加高效和准确。